Using J2EE Services on the Object Tier
The object tier usually maps to a WebLogic cluster that houses the heavier J2EE services such as EJB and RMI objects, as well as the JMS resources. Because the EJB objects typically need JDBC access to the backend DBMS (data tier), the object tier in our multi-tier application setup also hosts the JDBC resources. Remember, a clustered architecture need not have an object tier. If your application doesn't use EJBs to encapsulate the business logic or doesn't require any asynchronous message handling, you easily can bypass the object tier. In that case, you could deploy the JDBC resources to the presentation tier directly.
Even if your application does make use of EJB objects and/or JMS resources, you still need not construct a separate object tier cluster. You could deploy your entire application (servlets, JSPs, EJBs, JMS destinations, etc.) to a single WebLogic cluster. We examine the trade-offs of this combined-tier architecture later in this chapter.
This section examines the object tier by first exploring the interplay between replica-aware stubs and WebLogic's clustered JNDI service. Then we review how EJB and RMI objects, JDBC, and JMS resources behave in a clustered environment.
14.4.1 Interacting with the Object Tier
Establishing the object tier cluster is no different from setting up the web/presentation tier. The object tier cluster, named OCluster here, is composed of two Managed Servers, ServerF and ServerG. Both servers coexist on another machine whose IP address is 10.0.10.12, and listen on ports 7001 and 7003 respectively. The cluster address for OCluster is 10.0.10.12:7001,10.010.12:7003. Figure 14-7 emphasizes the configuration of the object tier, as depicted earlier in Figure 14-1.
Figure 14-7. The object tier configuration
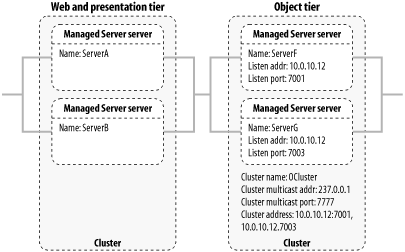
Objects that live in the presentation tier will need to reach resources deployed on the object tier. For instance, a servlet may need to access EJB objects or JDBC resources deployed to the object tier. Moreover, requests to these resources should be load-balanced across those various members of the object tier cluster. Clustered JNDI and replica-aware RMI stubs provide us with these capabilities.
Suppose you were to deploy a data source to OCluster. If a servlet in the presentation tier needs to use the data source, it should establish an initial context to OCluster, not an individual server within the cluster. In this case, the servlet would set up the JNDI context as follows:
// code running on the presentation tier, which establishes
// a context to the object tier using the object tier's cluster address
InitialContext ctx = new InitialContext("t3://10.0.10.12:7001,10.0.10.12:7003");
Remember that although we've specified the cluster address, the context eventually will be associated with a particular server in the list, round-robining between the servers each time we set up the initial JNDI context. By specifying the addresses of all the servers in the cluster, we allow for the Context object itself to fail over. Even though the JNDI context is initially bound to a particular server, because it is aware of the addresses of other servers in the list, it automatically can fail over to the next available server if the original server becomes unavailable.
Since we established a context on a member of the object tier, we now can look up resources bound to the cluster-wide JNDI tree, such as our JDBC data source:
DataSource ds = (DataSource) ctx.lookup("oreilly.DS")
This returns a cluster-aware data source stub. Because we've deployed the data source to the object tier cluster, the cluster-aware stubs that are bound to the local JNDI trees of ServerF and ServerG will have updated their internal tables to reflect the fact that the data source is available on both servers. Because the stub is cluster-aware, a client isn't concerned about where the data source is returned from, so long as it is a replica from one of the servers in the object tier. Moreover, because the stub holds the locations of all servers that host the resource, if one of the servers fails, the stub can route further requests to another server in the list. WebLogic transparently provides these load-balancing and failover features to all clients of the cluster.
Earlier we observed how WebLogic avoids remote calls using object- or transaction-based collocation. These optimizations are ineffectual in a multi-tier application setup because the presentation and object tiers reside on separate clusters. This provides the scope for load balancing and failover for requests from the presentation tier to the object tier. On the other hand, in a combined-tier framework in which both servlets and EJBs are deployed homogeneously across the same cluster, no load balancing can occur when servlets invoke EJB methods. Because of WebLogic's collocation optimizations, an EJB method call from a servlet always is forwarded to the replica that is collocated with that servlet.
14.4.2 Clustering EJB and RMI
WebLogic's load-balancing and failover support for EJB and RMI objects stems from the replica-aware stubs that it uses. This section summarizes the load-balancing and failover features WebLogic provided for EJB and RMI objects. Chapter 4 and Chapter 10 cover this in more depth and explain how to configure your EJBs appropriately.
14.4.2.1 Load balancing and failover
Load balancing for EJBs occurs at both the EJB home and EJB object level. When a client looks up the JNDI tree for an EJB home object, it acquires a cluster-aware stub that can locate home objects on each server to which the EJB component was deployed. Likewise, the EJB object itself is represented by a replica-aware stub that automatically can fail over between method calls. Failover during method calls occurs only if the EJB methods are marked as being idempotent.
WebLogic 8.1 and 7.0 support several load-balancing schemes for EJB and RMI objects: round-robin, weight-based, random, and parameter-based routing. The round-robin algorithm is the default load-balancing strategy. WebLogic 8.1 supports three additional schemes: round-robin affinity, weight-based affinity, and random affinity.
14.4.2.2 EJB load balancing
WebLogic lets you adjust the default load-balancing strategy for a cluster. This default strategy applies to all clusterable services running on the cluster. Aall clusterable services use a round-robin algorithm as their default load-balancing strategy. The default strategy can be overridden on a per-service basis. For instance, when you compile a clusterable RMI object, you can explicitly select a load-balancing strategy for the generated RMI stub.
Every EJB component type supports load balancing at the home level. In order to enable cluster-aware EJB home stubs, specify true for the home-is-clusterable element in the EJB's weblogic-ejb-jar.xml descriptor file. The load-balancing scheme for the EJB home object will default to the load-balancing strategy you've configured for the cluster to which the EJB component is subsequently deployed. You also can change the load-balancing scheme for a particular EJB by specifying a value for the home-load-algorithm element in the weblogic-ejb-jar.xml descriptor file. Its value can be set to either RoundRobin, WeightBased, Random, RoundRobinAffinity, WeightBasedAffinity, or RandomAffinity. In addition, you can use the home-call-router-class-name element to specify a custom call router class for the home stub of a stateful session EJB or an entity EJB.
Here is a breakdown of other features particular to the different EJB types:
Stateless session beans
Stateless session EJBs support replica-aware EJB objects. To enable replica-aware EJB objects, specify true for the stateless-bean-is-clusterable element in the weblogic-ejb-jar.xml descriptor. To set the load-balancing strategy at the EJB object level, use the stateless-bean-load-algorithm element in the weblogic-ejb-jar.xml descriptor file. You also may use the stateless-bean-call-router-class-name element to specify a custom call router class for a stateless session EJB.
Stateful session beans
Because of the sticky nature of stateful session EJBs, method calls to a stateful session bean always are routed to the same EJB instance.
Entity beans
For read-only entity EJBs, WebLogic supports load balancing and failover on every method call, while read-write entity EJBs are pinned to a particular member of the cluster.
14.4.2.3 Failover for EJB and RMI objects
If an RMI stub makes a call to a service on one of the servers hosting the object and the call fails, the stub will detect the failure and retry the call on a different server.
As explained earlier in Chapter 10, automatic failover occurs only if WebLogic knows that the method call is idempotent. If a method is not marked as idempotent, WebLogic cannot be sure that by retrying the method on a different server it won't duplicate any changes made during the previous call. To avoid this potential mistake, WebLogic errs on the safe side and refuses to automatically failover on non-idempotent EJB methods. By default, all methods of stateless session EJB home objects and read-only entity beans are marked as idempotent.
WebLogic still can failover on nonidempotent methods, but only in two exceptional cases. If a ConnectException or a MarshalException is thrown when a stub attempts to reach the object on the server side, the stub will fail over to a different server. Both of these exceptions can be thrown only before the EJB method begins its execution, and therefore no changes could have been initiated.
Failover manifests in different ways when it comes to EJB and RMI objects. Depending on the EJB type, an EJB may have replica-aware EJBHome and EJBObject stubs. As a result, failover and load balancing can occur when a client looks up the EJB's home object, or when it invokes an EJB method using its EJBObject stub. The varying types of failover are here:
Stateless session EJBs
As stateless session EJBs do not maintain any server-side state, the EJBObject stub returned by the EJB home object can route a method call to any server hosting the object. Failover occurs only on idempotent methods.
Stateful session EJBs
The EJBObject stub for a clustered stateful session EJB maintains the locations of the servers that hold the EJB's primary and secondary states. The EJB instance exists only on the server hosting the primary state, while its state may be replicated to a secondary server. Calls to the EJB object are routed to the server hosting the primary state. If the primary server fails for some reason, subsequent calls are then routed to the server hosting the secondary state. In this case, the EJB instance is re-created on the secondary server using the replicated session state, and a new server is chosen as the secondary server. Changes to the stateful session EJB instance are replicated either when a transaction commits, or after each method invocation if the client hasn't initiated a transaction.
Entity EJBs
For read-only entity beans, the EJBObject stub load-balances on every method call, and supports failover for idempotent methods. WebLogic avoids database reads by caching read-only beans on every server to which they've been deployed. For read-write entity beans, when an EJB home object finds or creates such an EJB instance, it obtains an instance from the same server and returns an EJBObject stub pinned to that server. Hence, for read-write entity beans, WebLogic supports load balancing and failover only at the home level, and not at the method call level (the EJBObject level).
14.4.2.4 Pinned objects and migration
In certain scenarios, it makes sense to maintain only a single copy of an object within a cluster. That is, the object is not replicated among all of the servers in the cluster. This can be achieved for RMI objects, and for certain J2EE services such as JMS servers and the JTA transaction recovery service. At any time, these pinned services are active on only a single server within the cluster.
Pinned services can be manually migrated from one server to another member of the same cluster. This migration cannot occur automatically; instead it has to be initiated by the administrator. WebLogic supports the migration of JMS servers and the JTA transaction recovery services; these services are called migratable services. Chapter 8 explains how to migrate a JMS server from one WebLogic instance to another.
Instead of replica-aware stubs, migratable services rely on migration-aware stubs. These stubs keep track of which server hosts the pinned service, and redirect all requests to that server. If the service is migrated to another clustered server, the stub transparently redirects further requests to the new server hosting the service.
You also can specify the list of servers to which a service may migrate by establishing a migratable target list. If you do not configure one or more migratable targets, the service may be migrated to any server in the cluster. Otherwise, it may migrate only to those specified in the target list.
14.4.3 Using JDBC Resources in a Cluster
WebLogic provides failover and high-availability features through JDBC multipools and cluster-aware data sources. Note that a JDBC connection established with the backend DBMS relies on state tied to the physical connection between the JDBC driver and the DBMS. This implies that WebLogic cannot offer failover for JDBC connections. If a client has acquired a JDBC connection and the DBMS to which it is attached or the server from where the connection was obtained fails, the connection is terminated and the client no longer is able to use that connection object.
WebLogic provides high-availability and load-balancing features at the connection pool level through the use of a multipool. A multipool is simply a pool of connection pools, each connection pool potentially drawing its connections from a different DBMS instance. A multipool may be used if the DBMS supports multiple replicated, synchronized database instances. If the multipool is configured for failover, then a connection always is drawn from the first connection pool until failure, after which the connection is drawn from the next pool in the list. If the multipool is configured for load balancing, requests for JDBC connections are distributed through the connection pools in a round-robin fashion.
Finally, JDBC DataSource objects deployed to a WebLogic cluster are replica-aware. In order to use connection pools and data sources in a clustered environment so that you can take advantage of these features, ensure that you deploy both the connection pool and the data source to the cluster, and not to individual servers within the cluster.
14.4.4 Clustering JMS
WebLogic's support for load balancing and failover for JMS resources is fundamentally different from the support offered for servlets, EJBs, and RMI objects. Because JMS is a pinned service, it can be associated only with a single WebLogic instance. We now look at WebLogic's load-balancing and failover features for various JMS resources: connection factories, JMS servers, destinations, and distributed destinations.
14.4.4.1 JMS servers and destinations
JMS servers are pinned services and can be targeted only to a single WebLogic instance. A JMS server may host multiple queues and topics; therefore, these destinations are bound to the JMS server in which they are defined. Failover at the JMS server level occurs when the administrator manually migrates the JMS service to another WebLogic instance. If the JMS server isn't migrated to another cluster member, the JMS server and the destinations it hosts become unreachable. If a JMS server goes down, any client connected to that JMS server or using a destination that resides on that JMS server also fails.
Thus, WebLogic doesn't provide automatic failover for JMS servers and destinations. You may consider these resources as being "highly available" because of the migration facility. Distributed destinations, as we shall see later in Section 14.4.4.3, do provide room for failover and load balancing.
14.4.4.2 Connection factories
JMS connection factories are used to manufacture connections to a JMS server. Even though a JMS server is pinned to a single WebLogic instance, you can deploy the connection factory to a WebLogic cluster. By assigning the JMS connection factory to a WebLogic cluster, you enable cluster-wide access to the JMS servers for all clients of the cluster. Each replica of the connection factory on any cluster member automatically can route the call to an appropriate WebLogic instance that does host the JMS server and required destination. So, it is the combination of two things that enable cluster-wide, transparent access to any client of the pinned JMS destination: deploying the connection factory to the cluster, and automatic routing of requests to the WebLogic instance that hosts the desired JMS destination. WebLogic lets you configure two flags for JMS connection factories Load Balancing and Server Affinity that further influence the behavior of distributed destinations.
14.4.4.3 Distributed destinations
WebLogic supports distributed destinations that also provide failover and load balancing for JMS queues and topics. A distributed destination is a named collection of physical destinations, all taken from the same cluster. For instance, you can define a distributed queue using several JMS queues, each of which may be hosted on different JMS servers within the same cluster.
If a producer sends a message to a distributed queue, a single physical queue is chosen to receive the message. The queue may be selected randomly or by using a weight-based, round-robin algorithm. Load balancing occurs because each physical queue may reside on a different JMS server. Every time a message is sent to a distributed queue, the message will be distributed across the various JMS servers hosting the physical queues.
If a producer sends a message to a distributed topic, the message is delivered to all physical topics that form the distributed topic. If the message is nonpersistent, it will be sent only to available JMS servers that host the physical topics. If the message is persistent, it is additionally stored and forwarded to other JMS destinations as and when their JMS servers become available. Remember, JMS messages can be stored only if you've configured a JMS store for the physical topic. For this reason, WebLogic always attempts to first forward the message to distributed members that utilize persistent stores.
When a queue receiver or topic subscriber is created on a distributed destination, a single physical member is chosen and the receiver is pinned to that member for the duration of its lifetime. This choice is made only once, at creation time. If the physical member fails, the receiver/subscriber receives an exception, at which time the application should re-create the receiver/subscriber. If other physical members are available, another member from the distributed destination is chosen and assigned to the client. The client then can continue to proceed as before. So, even though WebLogic doesn't provide automatic failover for distributed queue receivers and topic subscribers, it does offer clients the opportunity to re-create their session on a different member of the distributed destination.
Several other factors influence the behavior of distributed destinations:
- The Load Balancing setting on a JMS connection factory determines whether producers created by the connection factory will load-balance on every send( ) or publish( ). If this flag isn't enabled, load balancing occurs only on the first call to send( ) or publish( ) thereafter, all messages are sent to the same member destination.
- The Server Affinity flag affects how clients of a distributed destination behave when they run on the same server as the connection factory. If the flag is enabled, WebLogic first will attempt to load-balance consumers and producers across physical destinations that are running on the same server. So, for instance, if the client was sending to a distributed queue and a physical queue member was hosted on the same WebLogic instance, the local queue member will be chosen over any other.
- Transaction affinity also plays a role here. When producing multiple messages to a distributed destination within a transacted session, WebLogic sends all messages to the same physical destination. Likewise, if a transacted session sends multiple messages to multiple distributed destinations, WebLogic will try to choose a set of member destinations, all served by the same WebLogic instance.
- When a client produces a message to a distributed queue, WebLogic will load-balance using only those physical members of the distributed queue that do have consumers. Physical members of a distributed queue that don't have any consumers are not considered for message production (unless all queues have no consumers). In addition, when you create a consumer on a distributed queue, WebLogic will attempt to create the consumer on physical queues that don't yet have any consumers.
All of these load-balancing and failover optimizations provided by WebLogic operate transparently to client code. However, a good understanding of these features enables you to properly assess the performance implications of your JMS setup within your object tier cluster.
14.4.5 Maintaining State in a Cluster
It is useful to think about how state is maintained in a cluster. There are essentially three types of state in a J2EE environment: stateless services, nonpersistent stateful services, and persistent state.
A stateless service doesn't capture any server-side state during its interactions with clients. Examples of stateless services include a JDBC connection factory, an EJB home object, a stateless session EJB, or a message-driven EJB. If you deploy a stateless service to a number of WebLogic instances, client requests can be forwarded to any of these servers, as it doesn't matter which one is chosen. In this case, clustering for a stateless service is just a matter of load-balancing requests among the servers hosting the service. Failover is possible only if the service fails before the request has been handled, or if the service is guaranteed to be idempotent. Although stateless services are easily clusterable, WebLogic doesn't simply hop around between all server instances hosting the service. As we have seen, WebLogic favors optimizations such as transaction collocation, which ensures that once a client has initiated a distributed transaction, all resources used during the lifetime of the transaction are collocated on the same server on which transaction was initiated. No persistence is needed, and load balancing is easy because any hosting server in the cluster can be chosen.
Nonpersistent stateful services are those in which the client-specific, server-side state information is not fundamentally persistent. For example, HTTP sessions do not have to be backed up to disk or to a database. Stateful session EJB instances are another example of nonpersistence state. In both of these cases, WebLogic lets you employ in-memory replication of the state, thereby avoiding persistence to disk. This offers you a speed advantage because the session-state information doesn't need to be kept in sync with a persistent store.
One consequence of session-state replication is that the locations of the primary and secondary servers need to be tracked. An arbitrary server can no longer be chosen, as it could for stateless services. We already have seen how WebLogic handles this additional complexity. In the case of HTTP sessions, WebLogic uses session cookies to ensure client requests stick to the HTTP session on the correct server in the presentation tier. For the object tier, it is the replica-aware stubs that hold the locations of the server hosting the primary and secondary state. In this case, persistence based on in-memory replication is relatively cheap. However, the load balancing is now confined to those servers that host the session-state information and its backup.
Persistent services, such as CMP entity beans and persistent JMS messaging, need to be backed up to some kind of store. Here WebLogic provides you with a number of features that effectively trade-off data consistency for scalability. For instance, read-only entity beans scale extremely well. Each cluster member can create instances of a read-only entity EJB independently and leave them cached. Read-only beans need not be persisted, and load balancing is inexpensive because any client request for the EJB can simply choose from one of the cached EJB instances without having to refresh the state from the persistent store. If there is a concern that the cached data may not be in sync with the underlying store, WebLogic lets you configure a refresh timeout interval or send multicast invalidations to other cached read-only entity EJB instances. To optimize data consistency checks, you may choose to enforce optimistic concurrency in your entity beans, whereby WebLogic defers all checks for data consistency until the point of transaction commit. Right at the other scale is the serialized entity bean. Here persistence is expensive (locking in order to maintain strict data consistency), as is replication.
Introduction
Web Applications
- Web Applications
- Packaging and Deployment
- Configuring Web Applications
- Servlets and JSPs
- JSP Tag Libraries
- Session Tracking
- Session Persistence
- Clusters and Replicated Persistence
- Configuring a Simple Web Cluster
- Security Configuration
- Monitoring Web Applications
Managing the Web Server
- Managing the Web Server
- Configuring WebLogics HTTP Server
- Virtual Hosting
- HTTP Access Logs
- Understanding Proxies
- Web Server Plug-ins
Using JNDI and RMI
- Using JNDI and RMI
- Using WebLogics JNDI
- Using JNDI in a Clustered Environment
- Using WebLogics RMI
- Using WebLogics RMI over IIOP
JDBC
- JDBC
- Overview of JDBC Resources
- Configuring JDBC Connectivity
- WebLogics Wrapper Drivers
- Rowsets
- Clustering and JDBC Connections
Transactions
J2EE Connectors
- J2EE Connectors
- Assembling and Deploying Resource Adapters
- Configuring Resource Adapters
- WebLogic-Specific Configuration Options
- Using the Resource Adapter
- Monitoring Connections
JMS
- JMS
- Configuring JMS Resources
- Optimizing JMS Performance
- Controlling Message Delivery
- JMS Programming Issues
- Clustered JMS
- WebLogics Messaging Bridge
- Monitoring JMS
JavaMail
Using EJBs
- Using EJBs
- Getting Started
- Development Guidelines
- Managing WebLogics EJB Container
- Configuring Entity Beans
- EJBs and Transactions
- EJBs and Clustering
Using CMP and EJB QL
- Using CMP and EJB QL
- Building CMP Entity Beans
- Features of WebLogics CMP
- Container-Managed Relationships
- EJB QL
Packaging and Deployment
- Packaging and Deployment
- Packaging
- Deployment Tools
- Application Deployment
- WebLogics Classloading Framework
- Deployment Considerations
- Split Directory Development
Managing Domains
- Managing Domains
- Structure of a Domain
- Designing a Domain
- Creating Domains
- Domain Backups
- Handling System Failure
- Domain Network Configuration
- Node Manager
- The Server Life Cycle
- Monitoring a WebLogic Domain
Clustering
- Clustering
- An Overview of Clustering
- A Closer Look at the Frontend Tier
- Load-Balancing Schemes
- Using J2EE Services on the Object Tier
- Combined-Tier Architecture
- Securing a Clustered Solution
- Machines, Replication Groups, and Failover
- Network Configuration
- Monitoring Clusters
Performance, Monitoring, and Tuning
- Performance, Monitoring, and Tuning
- Tuning WebLogic Applications
- Tuning the Application Server
- Tuning the JVM
SSL
- SSL
- An Overview of SSL
- Configuring WebLogics SSL
- Programmatic SSL
- Mapping Certificates to WebLogic Users
Security
- Security
- The Java Security Manager
- Connection Filtering
- The Security Provider Architecture
- The Providers
- Configuring Trust Between Two Domains
- JAAS Authentication in a Client
- Creating a Custom Authentication Provider
- Creating an Identity Assertion Provider
XML
- XML
- JAXP
- Built-in Processors
- The XML Registry
- XML Application Scoping
- WebLogics Streaming API
- WebLogics XPath API
- Miscellaneous Extensions
Web Services
- Web Services
- Using the Web Services Framework
- Web Service Design Considerations
- Implementing the Backend Components
- Datatypes
- Implementing Clients
- Reliable SOAP Messaging
- SOAP Message Handlers
- Security
- UDDI
- Internationalization and Character Sets
JMX
- JMX
- The MBean Architecture
- Accessing MBean Servers
- Accessing MBeans
- Examples
- MBean Notifications
- Monitor MBeans
- Timer MBeans
Logging and Internationalization
- Logging and Internationalization
- The Logging Architecture
- Listening for Log Messages
- Generating Log Messages
SNMP
EAN: 2147483647
Pages: 187
