An Overview of Clustering
A WebLogic domain can be extended to incorporate a cluster of servers, typically spread across different physical machines in a network. Usually, a cluster will host a well-defined set of services and J2EE components that form part of a larger application framework. Multiple clusters of server instances, called tiers, are often used to set up the application architecture. These tiers provide both a logical and a physical partitioning of application components that offers greater security, scalability, and fault tolerance. Once you set up the servers that belong to the cluster, you can use the Administration Console to manage its configuration and to monitor its runtime health.
14.1.1 Domains, Machines, and Clusters
As described in Chapter 13, a WebLogic domain can be composed of a number of WebLogic instances, and several of these servers may be grouped into clusters. For instance, you could set up a cluster of WebLogic servers, all of which host your web application and related resources. This cluster of servers could be fronted by a load balancer that distributes requests evenly across all the members of the cluster. The load balancer could itself be another WebLogic instance. All server instances must belong to the same WebLogic domain. Thus, a WebLogic cluster is a group of servers working together with services, such as clustered JNDI, to provide support for failover and load balancing. A domain may in turn have a number of WebLogic instances, several groups of which can be placed into different clusters.
Note that we refer to WebLogic instances as being part of a cluster, and not the machines hosting the WebLogic instances. This is because a physical machine may host multiple copies of WebLogic, and each such instance is considered a separate entity. When you define a WebLogic cluster, the servers participating in the cluster can be distributed across multiple machines or may reside on the same machine. The only caveat is that if a machine fails, all of the WebLogic instances running on the machine will become unavailable. If the cluster includes server instances that live on different machines, the clusterable services will still be available if one of the machines dies, even though the cluster may now operate with reduced capacity. For nonclusterable services, WebLogic provides a migration strategy, allowing you to migrate a service from a failed machine to another member of the cluster.
For components that need to replicate their state onto a secondary server instance, you can minimize the damage due to a machine failure by ensuring that the secondary server instance is chosen from a different physical machine. WebLogic implements this notion by introducing the concept of a Machine and replication groups. As explained in Chapter 13, a Machine is simply a tag that can be assigned to a WebLogic instance, which indicates the physical machine that hosts the server. WebLogic can then use this tag to select a clustered server on a different physical machine for holding the replicated state. Later in Section 14.7.2, we will see how replication groups let you specify the preferred servers for holding the backup state of a server.
14.1.2 Tiers
Layered architecture is a common design methodology used in software engineering. The software is decomposed logically into a number of layers (tiers), each layer providing a well-defined set of services. J2EE applications can be partitioned in the same way. A typical J2EE application includes multiple web components (servlets, JSPs, and filters), a number of EJBs that implement the business logic, and data access classes or EJBs that interface with the underlying data store. WebLogic's support for clustering enables you to physically partition these services across well-defined application tiers. In this context, a tier represents a number of WebLogic instances that behave in a similar way, each hosting the same set of applications and services. Clearly, it makes sense to map each tier to a different WebLogic cluster. A typical application setup would define at least one of the following tiers:
Web tier
Refers to the bank of servers that provide static content, such as HTML and images, to clients. The web tier is usually the first point of contact for clients, although client requests also may be directed transparently through firewalls and then distributed to these servers via a load balancer. The web tier usually is composed of a number of web servers.
Presentation tier
Refers to WebLogic instances that provide dynamic content. In our context, this applies to servers hosting the JSP pages and servlets. The presentation tier often is combined with the web tier, though this isn't necessary.
Object tier
Refers to WebLogic servers that host the RMI and EJB objects, which encapsulate the business logic of your application. If your application is a pure web application not utilizing any EJB or RMI objects, the object tier may not even be needed.
Data tier
Refers to the servers that provide access to the actual data store(s). This includes servers hosting your DBMS, LDAP store, and more.
Figure 14-1 illustrates an architecture composed of multiple tiers. Each tier is implemented as a separate cluster. We've combined the web and presentation tiers by creating a single WebLogic cluster that hosts all the servlets, JSPs, and HTTP servers. On the other hand, the object tier is mapped to a cluster of WebLogic instances that host the EJB and RMI objects, JMS servers, and JDBC resources. Both clusters can live on their own hardware and have their own set of WebLogic instances.
Figure 14-1. A multi-tier application setup using WebLogic clusters
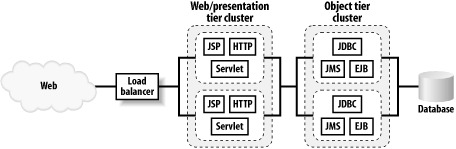
This multi-tier architecture opens up the opportunity to load-balance EJB method calls. A method call from a server in the presentation tier to a remote EJB on the object tier can be directed to any of the servers in that object tier. There is a trade-off, though although the calls to remote EJBs can be load-balanced, they always will involve network traffic because the servlets and EJBs live on separate tiers (clusters). As a result, EJB calls will be slower than if you collocated the EJBs with the web tier.
The multi-tier scenario opens up other opportunities for enhanced scalability as well. For instance, if you find that most of your resources are being spent servicing EJBs, you can improve the capacity of the object tier by simply adding another server to it. You could even move a server from the presentation tier to the object tier. Later when we look at the Section 14.5, you'll find that this flexibility is absent. The multi-tier application setup just shown also improves availability. Servers in the presentation tier are shielded from server crashes in the object tier (and vice versa). If a server hosting EJB objects fails, the servers in the presentation tier are unaffected because subsequent requests are simply routed to other available servers in the object tier.
Partitioning your application setup into various tiers also has security implications. The multi-tier architecture shown in Figure 14-1 allows you to protect the physical servers in the object tier from direct access by external clients. Other scenarios, in which all of the separate tiers are collapsed into a single tier, may not permit this.
14.1.3 Load Balancing
Load balancing is about distributing work across multiple servers within a cluster. Ideally you want this work to be distributed evenly, to the capabilities and load on each server within the cluster. WebLogic is able to load-balance requests to members within a cluster when certain conditions are satisfied:
- First, WebLogic requires that (most) components be deployed homogeneously to each server in the cluster. In the multi-tier application setup illustrated in Figure 14-1, the web application is targeted to all servers that belong to the presentation tier cluster. Because of this, incoming requests can be distributed evenly across the different members of the presentation tier. Similarly, the EJB components are available on all members of the object tier cluster. Because of this, incoming EJB calls from the presentation tier (or any external client) can be distributed across the different servers in the object tier.
- When a component is deployed to a cluster, multiple copies of the component will be sitting on the different servers comprising the cluster. WebLogic uses the cluster-wide JNDI tree to record the availability of these replicas in the object tier, whereas a proxy plug-in typically holds the information about the availability of servers hosting the servlets and JSP pages.
- WebLogic also must be aware of the status of the components that have been deployed to the cluster. This information forms the basis on which a load balancer can decide which server instances should be used when a request is made to the cluster. WebLogic uses a variety of methods to determine the health status of servers, including multicast heartbeats. By knowing when a server instance is under heavy load while the others aren't, a load balancer is able to direct new requests to the other members of the cluster. Hardware load balancers often have this capability.
It also is important to understand when WebLogic avoids load balancing. In many cases, WebLogic simply locates a resource that resides on the same instance, instead of locating another replica of the same resource on other servers within the cluster. By doing this, WebLogic can optimize network traffic and transaction times, and serve requests in less time even if this means compromising on failover and scalability. You will see more examples of this optimization in later sections.
The ultimate goal of load balancing is to evenly distribute the load on all of the servers that host the various components of your enterprise application. A good load-balancing scheme can then provide the ideal opportunity for your application to scale. For instance, suppose you find that under heavy load the servers in the object tier all run at maximum capacity because of the intensive processing involved in your EJB methods. Now if you add another WebLogic instance to the object tier cluster, your application setup can take advantage of the additional resources automatically. The new server can participate in the overall load balancing and hopefully diminish the load on the original set of servers. Most importantly, this change can occur transparently without affecting any clients of the cluster.
14.1.4 Failover
High availability is another important benefit of a WebLogic cluster. By deploying components and installing services homogeneously across all members of a cluster, you incorporate a certain degree of redundancy into your application setup. This ensures that you can continue servicing users, even if one of the servers in the cluster goes down. WebLogic supports a number of clusterable services and provides high availability by including failover features in many of these services. For nonclusterable services, WebLogic still can support high availability by enabling you (the Administrator) to migrate the service onto another running instance within the cluster.
Central to WebLogic's support for failover is knowing where duplicate components are located, and also maintaining the operational state of these components. For instance, a hardware load balancer constantly can monitor the operational state of the servers in the presentation tier cluster. If one of the servers in the cluster becomes unavailable for some reason, the load balancer can avoid distributing requests to it. Likewise, a replica-aware EJB stub can load-balance a method call from a servlet or JSP (or any external client) across all server instances in the object tier that host the EJB component. If one of these servers fails, this change in the operational status of the cluster is communicated to all of the replica-aware stubs. Subsequent calls to the EJB then will be redirected to a running server instance.
Typically your clients will need to maintain conversational state on the server side when interacting with your application. The J2EE framework offers several mechanisms for managing client-specific session information on the server side, such as HTTP sessions and stateful session beans. In such cases, simply knowing which servers have failed is not enough. For high availability, you need to be able to preserve the user's conversational state, even in the event of a server failure. WebLogic can preserve the client's session-state information by duplicating the state for example, onto a secondary server. In the presentation tier cluster, the HTTP session state held on a primary server can be replicated to a secondary server within the cluster. If the primary server maintaining the HTTP session fails, subsequent requests to the cluster automatically are directed to the secondary server, which then can use the backup of the session-state information. This form of in-memory replication was explained in Chapter 2. WebLogic implements a similar mechanism for other stateful components that live in the object tier.
Introduction
Web Applications
- Web Applications
- Packaging and Deployment
- Configuring Web Applications
- Servlets and JSPs
- JSP Tag Libraries
- Session Tracking
- Session Persistence
- Clusters and Replicated Persistence
- Configuring a Simple Web Cluster
- Security Configuration
- Monitoring Web Applications
Managing the Web Server
- Managing the Web Server
- Configuring WebLogics HTTP Server
- Virtual Hosting
- HTTP Access Logs
- Understanding Proxies
- Web Server Plug-ins
Using JNDI and RMI
- Using JNDI and RMI
- Using WebLogics JNDI
- Using JNDI in a Clustered Environment
- Using WebLogics RMI
- Using WebLogics RMI over IIOP
JDBC
- JDBC
- Overview of JDBC Resources
- Configuring JDBC Connectivity
- WebLogics Wrapper Drivers
- Rowsets
- Clustering and JDBC Connections
Transactions
J2EE Connectors
- J2EE Connectors
- Assembling and Deploying Resource Adapters
- Configuring Resource Adapters
- WebLogic-Specific Configuration Options
- Using the Resource Adapter
- Monitoring Connections
JMS
- JMS
- Configuring JMS Resources
- Optimizing JMS Performance
- Controlling Message Delivery
- JMS Programming Issues
- Clustered JMS
- WebLogics Messaging Bridge
- Monitoring JMS
JavaMail
Using EJBs
- Using EJBs
- Getting Started
- Development Guidelines
- Managing WebLogics EJB Container
- Configuring Entity Beans
- EJBs and Transactions
- EJBs and Clustering
Using CMP and EJB QL
- Using CMP and EJB QL
- Building CMP Entity Beans
- Features of WebLogics CMP
- Container-Managed Relationships
- EJB QL
Packaging and Deployment
- Packaging and Deployment
- Packaging
- Deployment Tools
- Application Deployment
- WebLogics Classloading Framework
- Deployment Considerations
- Split Directory Development
Managing Domains
- Managing Domains
- Structure of a Domain
- Designing a Domain
- Creating Domains
- Domain Backups
- Handling System Failure
- Domain Network Configuration
- Node Manager
- The Server Life Cycle
- Monitoring a WebLogic Domain
Clustering
- Clustering
- An Overview of Clustering
- A Closer Look at the Frontend Tier
- Load-Balancing Schemes
- Using J2EE Services on the Object Tier
- Combined-Tier Architecture
- Securing a Clustered Solution
- Machines, Replication Groups, and Failover
- Network Configuration
- Monitoring Clusters
Performance, Monitoring, and Tuning
- Performance, Monitoring, and Tuning
- Tuning WebLogic Applications
- Tuning the Application Server
- Tuning the JVM
SSL
- SSL
- An Overview of SSL
- Configuring WebLogics SSL
- Programmatic SSL
- Mapping Certificates to WebLogic Users
Security
- Security
- The Java Security Manager
- Connection Filtering
- The Security Provider Architecture
- The Providers
- Configuring Trust Between Two Domains
- JAAS Authentication in a Client
- Creating a Custom Authentication Provider
- Creating an Identity Assertion Provider
XML
- XML
- JAXP
- Built-in Processors
- The XML Registry
- XML Application Scoping
- WebLogics Streaming API
- WebLogics XPath API
- Miscellaneous Extensions
Web Services
- Web Services
- Using the Web Services Framework
- Web Service Design Considerations
- Implementing the Backend Components
- Datatypes
- Implementing Clients
- Reliable SOAP Messaging
- SOAP Message Handlers
- Security
- UDDI
- Internationalization and Character Sets
JMX
- JMX
- The MBean Architecture
- Accessing MBean Servers
- Accessing MBeans
- Examples
- MBean Notifications
- Monitor MBeans
- Timer MBeans
Logging and Internationalization
- Logging and Internationalization
- The Logging Architecture
- Listening for Log Messages
- Generating Log Messages
SNMP
EAN: 2147483647
Pages: 187
