|
The DBMS will, of course, check its system tables to ensure that your username has the access rights necessary to execute the SQL statement you submit for processing. If you do not, the DBMS will abort execution of the statement with an error message similar to:
Server: Msg 229, Level 14, State 5, Line 1
SELECT permission denied on object 'authors', database
'pubs', owner 'dbo'.
In short, DBMS will not allow you to circumvent system security by using a fully qualified table name (..
).
Understanding Cartesian Products
The Cartesian product of two tables is a (third) table that contains all of the possible pairs of rows from the two source tables. Each row in the table produced by a Cartesian product consists of the columns from the first table followed by columns from the second table.
Understanding Cartesian products is important because whenever you execute an SQL query that has multiple tables in its FROM clause, the DBMS creates the Cartesian product of the source tables as an interim virtual table. The system then uses the interim table as the single source table for the column data values referenced by column name in the query's expressions.
Suppose, for example, that you have a CUSTOMERS table and an INVOICES table with the following data:
CUSTOMERS table INVOICES table
==================== ===================================
cust_ID cust_name inv_date inv_no cust_ID inv_total
------- ------------ ---------- ------ ------- ---------
101 Customer 101 01/02/2000 1 101 15874
202 Customer 202 01/05/2000 2 202 6859
205 Customer 205 03/05/2000 3 101 20225
09/05/2000 4 101 30228
09/27/2000 5 202 7400
If you execute the SELECT statement
SELECT * FROM customers, invoices
' cust_ID cust_name inv_date inv_no cust_ID inv_total
------- ------------ ---------- ------ ------- ---------
101 Customer 101 01/02/2000 1 101 15874.0000
101 Customer 101 01/05/2000 2 202 6859.0000
101 Customer 101 03/05/2000 3 101 20225.0000
101 Customer 101 09/05/2000 4 101 30228.0000
101 Customer 101 09/27/2000 5 202 7400.0000
202 Customer 202 01/02/2000 1 101 15874.0000
202 Customer 202 01/05/2000 2 202 6859.0000
202 Customer 202 03/05/2000 3 101 20225.0000
202 Customer 202 09/05/2000 4 101 30228.0000
202 Customer 202 09/27/2000 5 202 7400.0000
205 Customer 205 01/02/2000 1 101 15874.0000
205 Customer 205 01/05/2000 2 202 6859.0000
205 Customer 205 03/05/2000 3 101 20225.0000
205 Customer 205 09/05/2000 4 101 30228.0000
205 Customer 205 09/27/2000 5 202 7400.0000
Because the SELECT statement in the current example has no WHERE clause, its final results table includes all of the rows produced by the Cartesian product of the CUSTOMERS table and the INVOICES table in the query's FROM clause. (The "display all column values," [that is, the asterisk "*"] within the query's select clause tells the DBMS to include all the Cartesian product's columns in the results table as well.)
When you review the contents of the results table in the current example, you will see that computing the Cartesian product of the tables in a query's FROM clause produces a lot of unwanted rows. For example, customer 205 has no invoices in the INVOICES table, yet the results table has five invoice detail lines for customer 205. Similarly, customer 202 made two purchases (INV_NO 2 and INV_NO 5), yet the results table has detail lines showing that customer 202 is also responsible for INV_NO 1 and 4.
The Cartesian product of the tables in a SELECT statement's FROM clause is normally used as an interim table (albeit virtual) and is almost never intended as a query's final results table. Real-world multi-table SELECT statements almost always include a WHERE clause with search criteria that filter out the unwanted (nonsense) rows in the interim (Cartesian product) table. (You will learn all about using WHERE clause filters in multi-table queries in Tips 284–287.)
| |
Note |
Although the query in the current example shows the Cartesian product from a SELECT statement with two tables in its FROM clause, the DBMS will also generate a Cartesian product when executing a query involving three (or more) tables. For example, if you submit the SELECT statement
SELECT * FROM table_a, table_b, table_c
the DBMS will create the Cartesian product of TABLE_A and TABLE_B as a product table (TABLE_AB). It then creates the Cartesian product of the product table (TABLE_AB) and TABLE_C as a product table (TABLE_ABC). (If there were a fourth table (TABLE_D), the DBMS would create the Cartesian product of TABLE_ABC and TABLE_D to produce a product table [TABLE_ABCD], and so on.) As is the case with a two-table query, the DBMS uses the final Cartesian product (such as TABLE_ABC, in a three-table query) as the source table for the column data values referenced by column name in the query's expressions.
|
Using the FROM Clause to Perform a Multi table Query
A FROM clause, as its name implies, lists the tables from which the DBMS is to get the data values to use in a query. For example, a query with a single table in its FROM clause, such as
SELECT * FROM customers
is easy to understand—retrieve each row from the CUSTOMERS table and supply its column values to the "display all column values" (the asterisk (*)) expression in the query's SELECT clause.
If a query needs data from columns in multiple tables, the FROM clause (which always lists all of the sources of a query's data), will have more than one table. However, whether the FROM clause lists a single table or several tables, the various clauses in a SELECT statement act on data one row at a time. Therefore, if a FROM clause has multiple tables, the DBMS will compute the Cartesian product of the tables listed in the FROM clause to create a single table from which it can draw data one row at a time.
As you learned in Tip 281, "Understanding Cartesian Products," the interim (Cartesian product) table consists of all of the possible combinations of rows in the FROM clause tables. Each row is made up of all of the columns from all of the tables listed in the FROM clause.
For example, suppose that you have a STUDENTS table with 12,000 rows, each of which has 15 columns (attributes), and a CLASSES table with 1,000 rows with 5 columns per row. When you execute the query
SELECT * FROM students, classes
the DBMS creates a virtual table with 12,000,000 rows (12,000 × 1,000) and 20 columns per row (15 from STUDENTS plus 5 from CLASSES). If you add a third table, TEACHERS, which has 1,000 rows of 10 columns each, the DBMS will combine the three tables in the FROM clause of the query
SELECT * FROM students, classes, teachers
to produce an interim virtual table with 12,000,000,000 rows (12,000 × 1,000 × 1,000) and 30 columns (15 + 5 + 10) per row. As you can see, the Cartesian product of the tables listed in the FROM clause of a multi-table SELECT can become very large.
Of course, no DBMS product actually creates a physical table from the Cartesian product of the tables listed a query's FROM clause. However, multi-table queries involving large tables will sometimes take hours to run because the DBMS creates and stores in memory the portions of the virtual interim table that it needs to process data from multiple tables one composite row at a time.
The important thing to understand is that a multi-table query actually works with a single (albeit large) virtual table that the DBMS creates by taking the Cartesian product of the tables listed in the SELECT statement's FROM clause. This concept is important because it helps to explain why a multi-table query needs a WHERE clause to filter out unwanted rows.
Understanding Joins and Multi table Queries
In Tip 281, "Understanding Cartesian Products," and Tip 282, "Using the FROM Clause to Perform a Multi-table Query," you learned that the DBMS joins multiple tables listed in a SELECT statement's FROM clause by generating the Cartesian product of the tables.
SQL-92 refers to a Cartesian product as a CROSS JOIN. As such, the SELECT statement
SELECT * FROM students, classes
is equivalent to:
SELECT * FROM students CROSS JOIN classes
Each of the two example queries joins two tables (STUDENTS and CLASSES) to produce a third table that contains all of the possible pairs or rows from each of the original tables. As you learned in Tip 281, a CROSS JOIN (or Cartesian product) is seldom (if ever) the desired result when you pose a query-there are simply too many unwanted (and perhaps nonsensical) rows. Therefore, multi-table queries almost always include a WHERE clause to filter out rows whose column values do not represent the attributes of valid physical objects or concepts-such as the invoice detail rows for CUST_ID 205 in the interim source table of the example in Tip 281.
When executing a multi-table query, you normally want the DBMS to perform a natural join (or equi-join) instead of a cross join of the source tables. In an equi-join the DBMS filters out interim (joint) table rows that do not have matching values in one (or more) columns common to both tables. You learned how to set up a shared column relationship between tables when you read about the FOREIGN KEY constraint in Tip 173, "Understanding Foreign Keys."
In short, a FOREIGN KEY lets you set up a parent/child relationship between tables by duplicating the PRIMARY KEY (see Tip 171, "Understanding Primary Keys") column value from the parent table in a FOREIGN KEY (see Tip 173) column of the child table. Then you can use the syntax
SELECT { | *}
FROM ,
WHERE =
to write a two-table query that joins the row with the attributes (column values) from
that partially describe an object or concept to the row(s) in
with additional attributes (column values) pertaining to the same object or concept.
You will learn more about the various SQL joins (CROSS JOIN, NATURAL JOIN, INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, and UNION JOIN) in Tips 296-309. For now, the important thing to understand is that a join is used by a multi-table SELECT statement to combine related rows of values from different tables into a single virtual table. The DBMS then works with the joined rows in a single interim virtual table to produce the final query results table.
Using a WHERE Clause to Join Two Tables Related by a Single Column PRIMARY KEY FOREIGN KEY Pair
As you learned in Tip 283, "Understanding Joins and Multi-table Queries," when executing a multi-table query, the DBMS joins the rows in one table with the rows in another table to create an interim virtual table that has all of the data values from both of the source tables. Then the system uses the SELECT statement's clauses to filter and display the data values in the interim (joined) table.
The simplest form of a multi-table query is an equi-join (or natural join) based on a parent/child relationship between pairs of rows in two tables. The DBMS joins rows in the parent table with rows in the child table by matching PRIMARY KEY column values in the parent table with FOREIGN KEY column values in the child table. Figure 284.1 shows the relationship between a CUSTOMERS (parent) table and an INVOICES (child) table as defined by the values in the parent table's PRIMARY KEY column and the child table's FOREIGN KEY column.
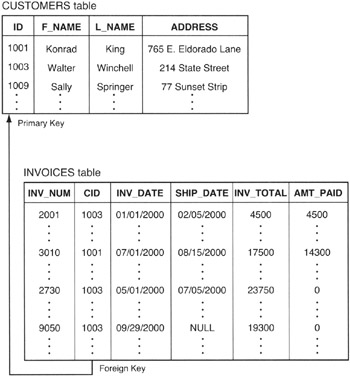 Figure 284.1: CUSTOMERS (parent) table and INVOICES (child) table related by common columns-ID in CUSTOMERS and INV_NUM in INVOICES Figure 284.1: CUSTOMERS (parent) table and INVOICES (child) table related by common columns-ID in CUSTOMERS and INV_NUM in INVOICES
To display a list of invoices and the name of the customer that placed each order, the DBMS must join each child row in the INVOICES table to its parent row in the CUSTOMERS table. For example, a query similar to
SELECT f_name, l_name, inv_num, inv_date,
(inv_total - amt_paid) AS 'Balance Due'
FROM invoices, customers
WHERE CID = ID
will perform an equi-join of the CUSTOMERS and INVOICES table. The query's FROM clause tells the DBMS to create an interim virtual table by joining the rows in the INVOICES table with the rows in the CUSTOMERS table. Next, the system uses the search criteria in the WHERE clause to filter out unwanted interim table rows. In an equi-join involving a parent and a child table, the DBMS passes to the SELECT clause only those interim (joined) table rows in which the FOREIGN KEY column matches the value of the PRIMARY KEY column. The equi-join query in the current example will produce a results table similar to:
f_name l_name inv_num inv_date Balance Due
------ -------- ------- ----------------------- -----------
Walter Winchell 2001 2000-01-01 00:00:00.000 .0000
Konrad King 3010 2000-07-01 00:00:00.000 3200.0000
Walter Winchell 2730 2000-05-01 00:00:00.000 23750.0000
Walter Winchell 9050 2000-09-29 00:00:00.000 19300.0000
SQL does not require that the SELECT clause include columns referenced in WHERE clause expressions. In fact, key columns (used to set up parent/child relationships between tables) are often ID numbers. Although numeric key values make it easy for computers to uniquely identify and pair related rows, they are of little value in a results table. After all, a person (vs. a machine) using query results is more likely to know and refer to a customer, employee, inventory item, and so on by name or description rather than by number.
Using a WHERE Clause to Join Two Tables Related by a Composite PRIMARY KEY FOREIGN KEY Pair
In Tip 174, "Understanding Referential Integrity Checks and Foreign Keys," you learned that the DBMS lets you INSERT a row in a child table only if the row's FOREIGN KEY column value matches the value in the PRIMARY KEY column of an existing row in a parent table. However, as you learned in Tip 284, "Using a WHERE Clause to Join Two Tables Related by a Single-Column PRIMARY KEY/FOREIGN KEY Pair," the system does not automatically use the matching PRIMARY KEY/FOREIGN KEY column value requirement to filter out unwanted rows in a query involving a parent/child table pair.
To exploit the parent/child relationship between two tables, you must perform an equi-join query. The search condition in the SELECT statement's WHERE clause tells the DBMS you want to work with only joined rows in which the PRIMARY KEY column value from the row in the parent table matches the FOREIGN KEY column value in the row from the child table.
For example, if you have an INVENTORY (child) table with a single-column FOREIGN KEY and an ITEM_MASTER (parent) table with a single-column PRIMARY KEY, you can use a SELECT statement similar to
SELECT inventory.item_number, description, qty_on_hand
FROM inventory, item_master
WHERE inventory.item_number = item_master.item_number
ORDER BY description
to display an item's description (from the ITEM_MASTER table) along with the quantity of the item you have in inventory (from the INVENTORY table) as a single, joined row in a results table.
As you learned in Tip 168, "Understanding Single-Column and Composite Keys," you sometimes have composite key values-tables in which the PRIMARY KEY (or FOREIGN KEY) value consists of multiple-column values. For example, suppose you purchase items with the same item number from different vendors and want to find out the quantity of each vendor's products you have on hand. If you use a composite PRIMARY KEY consisting of (ITEM_NUMBER,VENDOR_CODE), the preceding query with a single search criterion will produce an incorrect results table similar to
item_number description qty_on_hand
----------- -------------------- -----------
1 Item 1 from Vendor 1 111
2 Item 2 from Vendor 1 222
2 Item 2 from Vendor 1 111
2 Item 2 from Vendor 1 111
2 Item 2 from Vendor 2 222
2 Item 2 from Vendor 2 111
2 Item 2 from Vendor 2 111
3 Item 3 from Vendor 1 333
3 Item 3 from Vendor 3 333
when you actually have in inventory:
item_number description qty_on_hand
----------- -------------------- -----------
1 Item 1 from Vendor 1 111
2 Item 2 from Vendor 1 111
3 Item 3 from Vendor 1 111
2 Item 2 from Vendor 2 222
3 Item 3 from Vendor 3 333
To perform an equi-join query using the parent/child relationships defined by matching composite (multi-column) FOREIGN KEY/PRIMARY KEY values in related tables, the SELECT statement's WHERE clause must have a search condition that matches each pair of columns that make up the composite key. For example, if you have two tables related by a composite key such as (ITEM_NUMBER,VENDOR_CODE), execute a query similar to
SELECT inventory.item_number, description, qty_on_hand
FROM inventory, item_master
WHERE (inventory.item_number = item_master.item_number)
AND (inventory.vendor_code = item_master.vendor_code)
ORDER BY description
in which the WHERE clause search condition tells the DBMS to filter out all joined rows except those in which both pairs of columns that make up the composite FOREIGN KEY and PRIMARY KEY values have matching values. (If the composite keys consisted of three columns each, the WHERE clause would have three equality expressions [one for each matching column pair] joined by AND operators.)
Using a WHERE Clause to Join Three or More Tables Based on Parent Child Relationships
As you learned in Tip 284, "Using a WHERE Clause to join Two Tables Related by a Single-Column PRIMARY KEY/FOREIGN KEY Pair," and Tip 285, "Using a WHERE Clause to Join Two Tables Related by a Composite PRIMARY KEY/FOREIGN KEY Pair," the DBMS generates the Cartesian product of the tables listed in the SELECT statement's FROM clause each time the system executes a two table query. (You learned about Cartesian products in Tip 281, "Understanding Cartesian Products.") The DBMS then uses one or more search conditions in the query's WHERE clause to filter out joined yet unrelated pairs of rows. If you increase the number of tables joined in the query from two to three (or more), the DBMS still goes through the same process of generating the Cartesian product of the tables and then filtering out the joined yet unrelated rows from the interim virtual (Cartesian product) table.
Each search condition in the WHERE clause that is used to filter out unrelated joined rows must identify a pair of columns (one column from each pair of related tables) whose values must match if the joined row in the interim table expresses a valid parent/child relationship. For example, the WHERE clause in the two-table query
SELECT f_name, l_name, inv_num, inv_date,
(inv_total - amt_paid) AS 'Balance Due'
FROM invoices, customers
WHERE invoices.CID = customers.ID
filters out invoice detail rows joined to unrelated customer detail rows (and vice versa).
A parent/child relationship between two tables requires that a child's FOREIGN KEY value (INVOICES.CID) must match the parent's PRIMARY KEY value (CUTOMERS.ID). Therefore, the WHERE clause filter in the current example removes all joined rows in which the values in the PRIMARY KEY/FOREIGN KEY column pair do not match because these rows do not express a valid parent/child relationship between the two tables.
Similarly, to filter unwanted "garbage" rows out of the Cartesian product in a query on three (or more) tables, the WHERE clause must test pairs of column values that include at least one column from each of the source tables. For example, to get a list of customers including the invoice balances and salesperson's name, you can submit a three table query similar to:
SELECT f_name, l_name, inv_no, inv_date,
(inv_total - amt_paid) AS 'Balance Due',
RTRIM(first_name)+' '+last_name AS 'Salesperson'
FROM invoices, customers, employees
WHERE (customers.ID = invoices.CID)
AND (invoices.salesrep = employees.emp_ID)
The search condition in the WHERE clause filters out joined rows in which the ID (the PRIMARY KEY) from the CUSTOMERS (parent) table does not match the CID (the FOREIGN KEY) from the INVOICES (child) table, and joined rows in which the SALESREP (the FOREIGN KEY) from the INVOICES (child) table does not match the EMP_ID (the PRIMARY KEY) from the EMPLOYEES (parent) table.
As shown by the current example, the WHERE clause in a query on three (or more) tables does not have to test the same matching pair of column values for each table. The only requirement is that the WHERE clause must check the equality of at least one pair of FOREIGN KEY/PRIMARY KEY values from each set of parent/child tables listed in the query's FROM clause.
Using a WHERE Clause to Join Tables Based on Nonkey Columns
All of the WHERE clauses in the example multi-table queries in Tips 284-286 filtered out joined rows in which the FOREIGN KEY value from a child table did not match the PRIMARY KEY value from a parent table. However, SQL also lets you join rows based on matching values in other than PRIMARY KEY and FOREIGN KEY columns. Suppose, for example, that your company has a different set of training manuals for employees in each if its departments. The WHERE clause in the query
SELECT first_name, last_name, title
FROM manuals, employees
WHERE manuals.for_dept = employees.dept
will filter out those rows that join employees in one department with manuals for another department and will produce a results table similar to:
first_name last_name title
---------- --------- ----------------------------
Richard Kimbal Handling Complaints
Richard Kimbal Efficient Order Taking
Richard Kimbal Frequently Asked Questions
Hellen Waters Handling Complaints
Hellen Waters Efficient Order Taking
Hellen Waters Frequently Asked Questions
Ed Norton Prospecting
Ed Norton Working Callbacks
Ed Norton Making Referral Calls
Steve Forbes Prospecting
Steve Forbes Working Callbacks
Steve Forbes Making Referral Calls
Charles Coulter Mechanics of the Pre-Close
Charles Coulter Successful Closing Strategies
Charles Coulter Proper Menu Planning
Ralph Cramden Mechanics of the Pre-Close
Ralph Cramden Successful Closing Strategies
Ralph Cramden Proper Menu Planning
Joining tables based on matching nonkey column values generates a results table with joined rows that show many-to-many relationships between the two tables. For example, the results table in the current example shows that based on matching department values, each row from the MANUALS table is related to several rows from the EMPLOYEES table. Moreover, each row from the EMPLOYEES table has the same department as (and is therefore related to) several rows from the MANUALS table.
Joining tables based on matching pairs of PRIMARY KEY/FOREIGN KEY values, on the other hand, generates a results table that shows the one-to-many relationship between each row from the parent table and its children (related rows) in the child table. Or, looking at the relationships in reverse, the results table shows the many-to-one relationship between children (rows in the child table) related by a matching key value to a single (parent) row in the parent table.
Suppose, for example, that you have an EMPLOYEES parent table and a TIMECARDS child table. The SELECT statement
SELECT first_name, last_name, card_date, start_time,
stop time
FROM employees, timecards
WHERE employees.emp_ID = timecards.emp_ID
will join parent rows (from the EMPLOYEES table) with related child rows (from the TIMECARDS table, based on matching pairs of PRIMARY KEY (EMPLOYEES.EMP_ID) and FOREIGN KEY (TIMECARDS.EMP_ID) values. After the WHERE clause filters out joined, unrelated rows, the results table will show each row from the EMPLOYEES table (parent) joined (by a matching pair of key column values) to zero or more rows from the TIMECARDS (child) table. Or, said another way, the results table will show one or more rows from the TIMECARDS (child) table joined (by a matching pair of key column values) to one and only one of the rows from the EMPLOYEES (parent) table.
The important thing to understand from the preceding discussion of many-to-one and one-to-many relationships is that you write the SELECT statement's WHERE clause the same way whether you are joining tables based on matching pairs of key column values or matching pairs of nonkey column values. In both cases, the WHERE clause includes a comparison test that filters out joined rows in which the values in the pair of columns that join related rows in the two tables do not match.
Understanding Non Equi Joins
Although all of the example multi-table queries in Tips 284-287 joined tables based on the equality of pairs of columns common to both tables, SQL also lets you join tables based on nonequality relationships between pairs of columns. Suppose, for example, that you want to generate a list of employees and the company benefits to which each is entitled based on length of employment. Given an EMPLOYEES table and an unrelated BENEFITS table, you can execute the SELECT statement
SELECT first_name, last_name,
CAST((GETDATE() - date_hired) AS INTEGER)
AS 'Days Employed',
description AS 'Eligible For'
FROM employees, benefits
WHERE CAST((GETDATE() - date_hired) AS INTEGER) >=
days_on_job_required
ORDER BY emp_ID
to produce a results table similar to:
first_name last_name Days Employed Eligible For
---------- ---------- ------------- ---------------
Robert Cunningham 3440 Retirement Plan
Robert Cunningham 3440 Paid Vacation
Robert Cunningham 3440 Paid Sick Days
Robert Cunningham 3440 Paid Dental
Robert Cunningham 3440 Paid Medical
Lori Swenson 153 Paid Dental
Lori Swenson 153 Paid Medical
Richard Kimbal 93 Paid Dental
Richard Kimbal 93 Paid Medical
Glenda Widmark 32 Paid Medical
Each row in the results table joins an employee's name and length of employment (from the EMPLOYEES table) with each of the benefits to which the employee is entitled (from the BENEFITS table) based on length of employment.
Whether the multi-table query is based on an equi-join or a non-equi-join, a comparison test in the query's WHERE clause filters out the joined rows in which values in the pair of columns used to relate the two tables fail to satisfy the condition that defines the relationship between the tables.
In an equi-join, the WHERE clause uses the equality operator to compare values in the pair of columns used to relate the tables and filters out joined rows in which the paired columns have different values. Similarly, in the non-equi-join shown in the current example, the WHERE clauses uses the greater than or equal to (>=) comparison operator to filter out joined rows in which the value of the "Days Employed" expression is less than the value of the DAYS_ON_JOB_REQUIRED column (from the BENEFITS table).
The important thing to understand is that when executing a multi-table query, the DBMS always generates the Cartesian product of the tables listed in the SELECT statement's FROM clause. It then uses one or more search conditions in the WHERE clause to filter out the rows with values in related (paired) columns that do not satisfy the conditions of the comparison operator used to define the relationship between the two tables.
Using Qualified Column Names in Multi table Queries to Join Tables That Have the Same Names for One or More Columns
When writing a multi-table query, you can retrieve data from a table by using the name of the column in the SELECT statement if the name of the column with the data you want is unique to one of the tables joined in the query. For example, if you have a CUSTOMERS table and an EMPLOYEES as defined by the CREATE statements
CREATE TABLE customers CREATE TABLE employees
(cust_ID INTEGER, (emp_ID INTEGER,
cust_f_name VARCHAR(30), emp_f_name VARCHAR(30),
cust_l_name VARCHAR(30), emp_l_name VARCHAR(30))
salesperson INTEGER)
you can execute a SELECT that retrieves column data values by name alone, such as:
SELECT RTRIM(cust_f_name)+' '+cust_l_name AS 'Customer',
RTRIM(emp_f_name)+' '+emp_l_name AS 'Salesperson'
FROM customers, employees
WHERE salesperson = emp_ID
The DBMS automatically knows to retrieve the customer's first and last names (CUST_F_NAME and CUST_L_NAME) from the CUSTOMERS table, and the employee's first and last names (EMP_F_NAME and EMP_L_NAME) from the EMPLOYEES table. After all, the DBMS can find each of the column names used in the query in one and only one of the query's source tables.
If, on the other hand, you execute a multi-table query in which you need data from a column that has the same name in more than one of the tables joined in the query, you must use a qualified column name in the SELECT statement. A qualified column name, as you learned in Tip 228, "Understanding Column References," tells the DBMS both the name of the table and the name of the column from which it is to retrieve a data value.
For example, if the CUSTOMERS and EMPLOYEES tables were created with the CREATE statements
CREATE TABLE customers CREATE TABLE employees
(cust_ID INTEGER, (emp_ID INTEGER,
cust_f_name VARCHAR(30), f_name VARCHAR(30),
cust_l_name VARCHAR(30), l_name VARCHAR(30))
emp_ID INTEGER)
the DBMS would abort the execution of the SELECT statement
SELECT RTRIM(cust_f_name)+' '+cust_l_name AS 'Customer',
RTRIM(f_name)+' '+l_name AS 'Salesperson'
FROM customers, employees
WHERE emp_ID = emp_ID
and display an error message similar to
Server: Msg 209, Level 16 State 1, Line 1
Ambiguous column name 'emp_ID'.
Server: Msg 209, Level 16 State 1, Line 1
Ambiguous column name 'emp_ID'.
because the system cannot determine whether you want to use data values from the EMP_ID column of the CUSTOMERS table, or from the EMP_ID column of the EMPLOYEES table, or both in the query's WHERE clause.
To use data from a column whose name appears in more than one of the query's source tables, you must use a qualified column in the form:
.
Therefore, to correct the ambiguous reference to the EMP_ID column in the preceding example, rewrite the query as:
SELECT RTRIM(cust_f_name)+' '+cust_l_name AS 'Customer',
RTRIM(f_name)+' '+l_name AS 'Salesperson'
FROM customers, employees
WHERE customers.emp_ID = employees.emp_ID
When executing the revised (corrected) query, the DBMS knows to retrieve the EMP_ID value from the CUSTOMERS table for the expression on the left side of the equals (=) sign and to retrieve the EMP_ID value from the EMPLOYEES table for the expression on the right side of the equals (=) sign.
Using the ALL Keyword with an INTERSECT Operation to Include Duplicate Rows in the Query Results Table
As you learned in Tip 237, "Understanding the UNION, INTERSECT, and EXCEPT Operators," and Tip 238, "Using the INTERSECT Operator to Select Rows That Appear in All of Two or More Source Tables," you can use the INTERSECT operator to get a list of rows that appear in all of the results tables from two or more queries. For example, if you keep the list of your auto insurance customers in a table named AUTO_INS_CUSTOMERS and you keep the list of your home insurance customers in a union-compatible table named HOME_INS_CUSTOMERS, executing the query
(SELECT * FROM auto_ins_customers)
INTERSECT
(SELECT * FROM home_ins_customers)
will produce a results table that lists all customers that have both an auto insurance and a home insurance policy.
The INTERSECT operator, like the UNION operator, eliminates duplicate rows from its results table. As such, if you want to get a list of 18- to 21-year-old auto insurance customers who have had an accident and a traffic ticket within the past year, execute a query similar to:
(SELECT cust_ID FROM auto_ins_customers
WHERE age BETWEEN 18 AND 21)
INTERSECT
(SELECT cust_ID FROM traffic_violations
WHERE date_of_infraction >= (GETDATE() - 365))
INTERSECT
(SELECT cust_ID FROM auto_claims
WHERE date_of_claim >= (GETDATE() - 365))
Because the DBMS eliminates duplicate rows of query results, the results table for the current query will list a particular CUST_ID once and only once-whether the 18- to 21-year-old customer has had one ticket and one claim or five tickets and three claims within the past year.
If you do not want the DBMS to eliminate duplicate rows from the results table generated from the INTERSECT of two or more sets of query results, use the ALL keyword in conjunction with the INTERSECT operator. For example, to list the CUST_ID in the results table once for each traffic violation or auto claim for 18- to 21-year-old customers who have had both a traffic violation and an accident claim within the past year, execute the INTERSECT query:
(SELECT cust_ID FROM auto_ins_customers
WHERE age BETWEEN 18 AND 21)
INTERSECT ALL
(SELECT cust_ID FROM traffic_violations
WHERE date_of_infraction >= (GETDATE() - 365))
INTERSECT ALL
(SELECT cust_ID FROM auto_claims
WHERE date_of_claim >= (GETDATE() - 365))
| |
Note |
If your DBMS, like MS-SQL Server, does not support the INTERSECT operator, you can use an AND Boolean operator to add a subquery that tests set membership to the query's WHERE clause in place of each INTERSECT pair. For example, the SELECT statement
SELECT cust_ID FROM auto_ins_customers
WHERE age BETWEEN 18 and 21
AND cust_ID IN (SELECT cust_ID FROM traffic_violations
WHERE date_of_infraction >=
(GETDATE() - 365))
AND cust_ID IN (SELECT cust_ID FROM auto_claims
WHERE date_of_claim >= (GETDATE() - 365)
will generate the list of 18- to 21-year-old customers who have had both a traffic citation and an auto insurance claim within the past year-just like the second INTERSECT query in the current tip.
|
Generating the results table from the INTERSECT ALL query in the current tip requires the UNION of two non-INTERSECT queries such as:
SELECT cust_ID FROM traffic_violations
WHERE date_of_infraction >= (GETDATE() - 365)
AND cust_ID IN (SELECT cust_ID FROM auto_ins_customers
WHERE age BETWEEN 18 and 21)
AND cust_ID IN (SELECT cust_ID FROM auto_claims
WHERE date_of_claim >= (GETDATE() - 365)
UNION ALL
SELECT cust_ID FROM auto_claims
WHERE date_of_claim >= (GETDATE() - 365)
AND cust_ID IN (SELECT cust_ID FROM auto_ins_customers
WHERE age BETWEEN 18 and 21)
AND cust_ID IN (SELECT cust_ID FROM traffic_violations
WHERE date_of_infraction >=
(GETDATE() - 365)
ORDER BY cust_ID
Using the CORRESPONDING Keyword in an INTERSECT Query on Non union Compatible Tables
By definition, two tables are union-compatible if both have the same number of columns and if the data type of each column in one table is the same as the data type of its corresponding column (by ordinal position) in the other table. If two tables are union-compatible, you can use the INTERSECT operator (which you learned about in Tip 238, "Using the INTERSECT Operator to Select Rows That Appear in All of Two or More Source Tables") on the rows returned by two SELECT statements such as
SELECT * FROM table_a
INTERSECT
SELECT * FROM table_b
to generate a results table that has all of the rows from TABLE_A that are also in TABLE_B.
If, on the other hand, you have two tables that are not union-compatible, you can still use the INTERSECT operator to find sets of data values common to both tables by adding the CORRESPONDING keyword to the INTERSECT query. Suppose, for example, that you want a list of your vendors that contribute to both the Republican and Democratic parties. As long as each of the columns with the same name in all of the tables also has an identical data type across the tables, a query such as
SELECT * FROM vendors
INTERSECT CORRESPONDING
SELECT * FROM republican_contributors
INTERSECT CORRESPONDING
SELECT * FROM democrat_contributors
will produce a results table similar to:
tax_ID vendor_name phone_number
---------- ----------------- --------------
88-5481815 'ABC Corporation' (748)-254-5565
88-5107204 'XYZ Corporation' (754)-875-5648
In the current example, the three tables have three columns with the same name (TAX_ID, VENDOR_NAME, PHONE_NUMBER), and only two rows have matching values in the three columns across the three tables. (When you execute an INTERSECT CORRESPONDING query, the DBMS checks for matching data values in [and displays] only the columns with identical names in all of the tables.)
When you want to display the data values from only some of the matching columns while still requiring that all matching corresponding columns have the same value, list the columns you want to display after one of the CORRESPONDING keywords in the INTERSECT CORRESPONDING query. For example, if you want to display only the VENDOR_NAME, change the query in the current example to:
SELECT * FROM vendors
INTERSECT CORRESPONDING
SELECT * FROM republican_contributors
INTERSECT CORRESPONDING (vendor_name)
SELECT * FROM democrat_contributors
The DBMS will then display only the VENDOR_NAME for those rows with the same combination of TAX_ID, VENDOR_NAME, and PHONE_NUMBER.
Using a Multi table JOIN Without a WHERE Clause to Generate a Cartesian Product
Whenever you tell the DBMS to execute a multi-table query, the system first generates the Cartesian product of the source tables listed in the SELECT statement's FROM clause. It then uses the search condition in the WHERE clause to filter out unwanted rows. Therefore, if you want to generate the Cartesian product of two or more tables, simply omit the WHERE clause normally present in a multi-table query.
For example, if you want to get a list of teachers and the classes they teach, execute a query similar to
SELECT class_ID,
RTRIM(first_name)+' '+last_name AS 'Instructor'
FROM classes, teachers
WHERE classes.instructor = teachers.ID
which joins each row of class information from the CLASSES table with the name of the instructor for the class from the TEACHERS table to produce a results table similar to:
class_ID Instructor
--------------- -------------
English 101 Ishud Reedmour
Composition 101 Wanda Wright
Math 101 Mathew Mattick
If you want the list of all possible combinations of classes and teachers (that is, the Cartesian product of selected columns from the CLASSES table and the TEACHERS table) instead, rewrite the query as
SELECT class_ID,
RTRIM(first_name)+' '+last_name AS 'Instructor'
FROM classes, teachers
to produce a (Cartesian product) results table similar to:
class_ID Instructor
--------------- --------------
English 101 Ishud Reedmour
Composition 101 Ishud Reedmour
Math 101 Ishud Reedmour
English 101 Wanda Wright
Composition 101 Wanda Wright
Math 101 Wanda Wright
English 101 Mathew Mattick
Composition 101 Mathew Mattick
Math 101 Mathew Mattick
Moreover, if you have a third table—STUDENTS, for example—simply add its name to the list of source tables in the query's FROM clause, and add the STUDENTS columns you want to see in the results table to the query's SELECT clause. For example, when the DBMS executes the query
SELECT class_ID,
RTRIM(first_name)+' '+last_name AS 'Instructor',
RTRIM(students.f_name)+' '+students.l_name AS 'Student'
FROM classes, teachers, students
it will first generate the Cartesian product of the CLASSES table and the TEACHERS table. Next, the system will generate the Cartesian product of that (Cartesian) product table and the STUDENTS table, to produce a results table similar to
class_ID Instructor Student
--------------- -------------- -------------
English 101 Ishud Reedmour Ima Pupil
Composition 101 Ishud Reedmour Ima Pupil
Math 101 Ishud Reedmour Ima Pupil
English 101 Wanda Wright Ima Pupil
Composition 101 Wanda Wright Ima Pupil
Math 101 Wanda Wright Ima Pupil
English 101 Mathew Mattick Ima Pupil
Composition 101 Mathew Mattick Ima Pupil
Math 101 Mathew Mattick Ima Pupil
English 101 Ishud Reedmour Uhara Student
Composition 101 Ishud Reedmour Uhara Student
Math 101 Ishud Reedmour Uhara Student
English 101 Wanda Wright Uhara Student
Composition 101 Wanda Wright Uhara Student
Math 101 Wanda Wright Uhara Student
English 101 Mathew Mattick Uhara Student
Composition 101 Mathew Mattick Uhara Student
Math 101 Mathew Mattick Uhara Student
given that Ima Pupil and Uhara Student are the only two names in the STUDENTS table.
| |
Note |
The Cartesian product of two (or more) tables actually consists of all possible combinations of rows from all of the tables with each row made up of the columns from all of the tables as well. Therefore, the preceding examples do not generate a true Cartesian product, since they show all possible combinations of rows but not the combination of all of the columns from all of the tables in each row. To get a true Cartesian product, use the "all columns" operator (the asterisk (*)) or list all (vs. some) of the column names in the query's SELECT clause. For example, rewrite the preceding example query as
SELECT * FROM classes, teachers, students
to generate the true Cartesian product of the CLASSES, TEACHERS, and STUDENTS tables.
|
Using Aliases (Correlation Names) as Shorthand for Table Names
If a column name used in an SQL statement has the same name in two or more of the statement's source tables, you must use a qualified column name. As you learned in Tip 289, "Using Qualified Column Names in Multi-table Queries That Join Tables That Have the Same Names for One or More Columns," a qualified column name includes both the name of the column and the name of the table whose data the query is to use.
Moreover, to reference a table owned by another user, you must use a fully qualified column name, which means your column reference must include the column name, the table name, and the username of the table's owner. Therefore, if you want to generate a list of birthdays and anniversaries using tables owned by another user (such ANNIVERSARY_BIRTHDAY owned by KONRAD, and EMPLOYEES owned by HR_ADMIN, for example), the column references in the query will be rather long:
SELECT
CONVERT(CHAR(12,konrad.anniversary_birthday.next_date,107)
AS 'Date', hr_admin.employees.emp_ID,
RTRIM(hr_admin.employees.first_name)+
' '+hr_admin.employees.last_name AS 'Employee Name',
konrad anniversary_birthday.relationship,
RTRIM(konrad.anniversary_birthday.first_name)+' '+
konrad.anniversary_birthday.last_name AS
'Family Member', konrad.anniversary_birthday.event,
CONVERT(INTEGER,DATENAME(year,
konrad.anniversary_birthday.next_date)) -
CONVERT(INTEGER,DATENAME(year,
konrad.anniversary_birthday.first_date)) AS 'Years'
FROM hr_admin.employees, konrad.anniversary_birthday
WHERE konrad.anniversary_birthday.next_date
BETWEEN GETDATE() AND (GETDATE() + 30)
AND hr_admin.employees.emp_ID =
konrad.anniversary_birthday.emp_ID
ORDER BY konrad.anniversary_birthday.next_date,
hr_admin.employees.emp_ID
Because typing a query with long qualified column names or several references to columns common to multiple tables can get quite tedious, SQL lets you use an alias (or correlation name) in place of any or all of the table names used in a statement. To define an alias you can use in place of a table name, simply type the alias after the name of the table in the statement's FROM clause. Thus, in the current example you would replace the FROM clause
FROM hr_admin.employees, konrad.anniversary_birthday
with the FROM clause
FROM hr_admin.employees e, konrad.anniversary_birthday ab
if you want to use the letter e as an alias for HR_ADMIN.EMPLOYEES table and the letters ab to mean KONRAD.ANNIVERSARY_BIRTHDAY table in the query. You could then rewrite the query in the current example as:
SELECT
CONVERT(CHAR(12,ab.next_date,107) AS 'Date', e.emp_ID,
RTRIM(e.first_name)+' '+e.last_name AS 'Employee Name',
ab.relationship,
RTRIM(ab.first_name)+' '+ab.last_name AS 'Family Member',
ab.event, CONVERT(INTEGER,DATENAME(year,ab.next_date)) -
CONVERT(INTEGER,DATENAME(year,ab.first_date)) AS 'Years'
FROM hr_admin.employees e, konrad.anniversary_birthday ab
WHERE ab.next_date BETWEEN GETDATE() AND (GETDATE() + 30)
AND e.emp_ID = ab.emp_ID
ORDER BY ab.next_date, e.emp_ID
The only restrictions on correlation names (aliases) are that you cannot use the same alias to refer to more than one of the tables listed in the FROM clause, and you cannot use both an alias and the table's long (full) name in the same statement.
Understanding One to Many and Many to One Joins
In a relational database, a one-to-many relationship is most often called a parent-child relationship because one parent can have many children, while a child can have only one parent. Arguably (in the real world), a child has two parents. However, only one of the parents brings the child into the world. Similarly, think of child rows as being the offspring from a single parent row. Figure 294.1 illustrates the one-to-many relationship (parent-to-children) between a row in the EMPLOYEES (parent) table and several rows in the TIMECARDS (child) table.
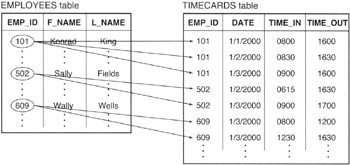
Figure 294.1: One-to-many relationships between (parent) rows in an EMPLOYEES table and (child) rows in a TIMECARDS table
The relationship between parent and child is represented by the value of a column (or set of columns) common to both tables. In the current example, a parent-child relationship exists between those rows in which the value in the EMP_ID column of the EMPLOYEES table matches the value in the EMP_ID column of the TIMECARDS table.
| |
Note |
SQL does not require that the column used to create the one-to-many relationship between parent and child tables have the same name in both tables. In the current example, the EMP_ID column in the EMPLOYEES table could have had another name (such as EMP_NUM, for example). The value in the column, not its name, defines the relational link between rows in one table and rows in another.
|
To exploit (or exercise) the one-to-many relationship, execute a query that equates the related column in one table with its counterpart in the other table. For example, the query
SELECT * FROM employees, timecards
WHERE employees.emp_ID = timecards.emp_ID
will produce a results table that joins each row in the parent table (EMPLOYEES) with one or more rows from the child table (TIMECARDS) based on a matching value in the pair of EMP_ID columns-one from each table.
Actually, as you learned in Tip 283, "Understanding Joins and Multi-table Queries," the DBMS first generates the Cartesian product of the TIMECARDS table and the EMPLOYEES table. It then filters out all rows except those in which the value in the EMP_ID column from EMPLOYEES matches the value in the EMP_ID column from TIMECARDS.
The end result of a one-to-many query is a results table similar to
emp_ID f_name l_name emp_ID date time_in time_out
------ ------ ------ ------ ---------- ------- --------
101 Konrad King 101 2000-01-01 800 1600
101 Konrad King 101 2000-01-02 830 1630
101 Konrad King 101 2000-01-03 900 1600
502 Sally Fields 502 2000-01-02 615 1630
502 Sally Fields 502 2000-01-03 700 1700
609 Wally Wells 609 2000-01-03 800 1200
609 Wally Wells 609 2000-01-03 1230 1630
which has only parent rows joined with one or more child rows. Therefore, you may find it easier to conceptualize a multi-table query as joining parent and child rows versus generating all possible combinations of joins and then filtering out unwanted rows that combine a parent row with a child row that belongs to a different parent.
If you reverse the links in Figure 294.1 (from TIMECARDS to EMPLOYEES), you can see that the child-to-parent relationship is many-to-one. Many (that is, one or more) rows in the child table relate (again by matching column value) to one and only one row in the parent table.
| |
Note |
Figure 294.1 shows the one-to-many relationship between EMPLOYEES and TIMECARDS rows by relating the PRIMARY KEY value in the parent table (EMPLOYEES) with a FOREIGN KEY value in the child table (TIMECARDS). However, SQL does not require that you use a pair of key columns to relate to tables. As long as one of the columns in the two related tables is constrained as UNIQUE or has no duplicate values, performing an equi-join on the source tables will produce a results table showing one-to-many relationships. If both tables have duplicate values in the column used to relate rows in an equi-join, the results table will show many-to-many relationships—which you will learn about in Tip 295, "Understanding Many-to-Many Joins."
|
Understanding Many to Many Joins
As you learned in Tip 294, "Understanding One-to-Many and Many-to-One Joins," a join (or multi-table query) is a two-step process. First, generate all possible pairs of rows from two related tables. Second, use the Boolean expression in the statement's WHERE clause to filter out the "garbage" rows. (Garbage rows are interim [virtual] table rows that join a row from one table with an unrelated row from the other table.)
In a one-to-many join, the WHERE clause filters out joined rows such that only those that join each row from the first table with one or more rows from the second table are left. Or, looking at the relationship in reverse, the WHERE clause filter leaves only joined rows in which each row from the second table is joined with one (and only one) row from the first table.
In a many-to-many join, on the other hand, the WHERE clause filter leaves not only rows in which each row from the first table is joined with one or more rows from the second table, but also rows in which each row from the second table is joined with one or more rows from the first table.
The decision whether or not to include a joined row from the interim (virtual) table in the final results table is based on the values in one or more pairs of columns common to both tables. When the DBMS executes either an equi-join (which you learned about in Tip 283, "Understanding Joins and Multi-table Queries") or a non—equi-join (which you learned about in Tip 288, "Understanding Non—Equi-Joins), the system filters out joined rows in which the values in the matching pair (or pairs) of columns used to relate the tables fails to satisfy the condition of the relational operator in the query's WHERE clause.
For example, when executing an equi-join such as
SELECT * FROM customers, autos_sold
WHERE customers.cust_ID = autos_sold.sold_to
the DBMS will generate an interim (virtual) table that has all possible pairs of rows from the CUSTOMERS table and the AUTOS_SOLD table. Then the system will use the WHERE clause to filter out all joined rows that do not have matching values in the CUST_ID and SOLD_TO columns.
Similarly, when executing a non—equi-join such as
SELECT * FROM customers, auto_inventory
WHERE customers.max_price >= auto_inventory.price
the DBMS will generate an interim (virtual) table that has all possible pairs of rows from the CUSTOMERS table and the AUTO_INVENTORY table. Next, the system will use the WHERE clause to filter out all joined rows in which the value in the MAX_PRICE column is less than the value in the PRICE column.
In both of these queries (or joins), the DBMS uses the value in a pair of columns (one column from each of the related tables) to decide which of the joined rows to keep in the results table. (In the first example, an equi-join, the pair of columns has to have matching values; in the second example, a non—equi-join, the value in one column has to be greater than or equal to the value in the other.)
Non—equi-joins (queries in which the Boolean operator in the WHERE clause is other than an equals [=] sign) always produce a results table with many-to-many relationships. For example, Figure 295.1 shows some of the joined rows that will pass through the WHERE clause filter into the results table of the second query in the current tip.
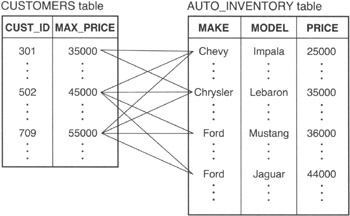
Figure 295.1: Many-to-many relationships between rows in a CUSTOMERS table and rows in an AUTO_INVENTORY table
As shown in Figure 295.1, the results table will have rows in which each row from the CUSTOMERS table is joined with one or more rows from the AUTO_INVENTORY table. Moreover, the results table will also have rows in which each row from the AUTO_INVENTORY table is joined with one or more rows from the CUSTOMERS table.
| |
Note |
The equi-join used as the first example in the current tip will perform a one-to-many join of the CUSTOMERS table and the AUTOS_SOLD table only if the values in either the CUST_ID column or the SOLD_TO column are unique. If you allow the user to add duplicate CUST_ID and SOLD_TO values, the equi-join query
SELECT * FROM customers, autos_sold
WHERE customers.cust_ID = autos_sold.sold_to
like the non—equi-join query
SELECT * FROM customers, auto_inventory
WHERE customers.max_price >= auto_inventory.price
will generate a results table that shows many-to-many join relationships in the joined rows.
|
Understanding the NATURAL JOIN
A NATURAL JOIN is a special type of equi-join with an implied WHERE clause that compares all columns in one table with corresponding columns that have the same name in another table for equality. Therefore, after the DBMS filters the product of the source tables through the natural join's implied WHERE clause, the final results table will have only joined rows in which all pairs of columns that have the same name in both two tables also have matching values.
Suppose, for example, that you have an EMPLOYEES table and a SALES table created by:
CREATE TABLE employees CREATE TABLE sales
(emp_ID INTEGER, (sales_date DATETIME,
f_name VARCHAR(30), amount_sold MONEY,
l_name VARCHAR(30)) emp_ID INTEGER,
office_ID INTEGER)
To get a list of employees and their sales for each office, you can submit a NATURAL JOIN similar to:
SELECT employees.emp_ID, sales.office_ID, f_name, l_name,
sales_date, amount_sold
FROM employees NATURAL JOIN sales
When the DBMS executes the query, it will join rows from the EMPLOYEES table with rows from the SALES table that have matching values in the pair of EMP_ID columns—the two columns that have the same name in both tables. Similarly, if the EMPLOYEES table also had an OFFICE_ID column, the NATURAL JOIN query in the current example would join rows in which both pairs of same name columns (EMP_ID and OFFICE_ID) had matching values in the two tables.
In effect, a NATURAL JOIN is equivalent to an equi-join with a WHERE clause that equates each pair of columns with the same name in both source tables. As such, you can rewrite the NATURAL JOIN in the current example as:
SELECT employees.emp_ID, sales.office_ID, f_name, l_name,
sales_date, amount_sold
FROM employees, sales
WHERE employees.emp_ID = sales.emp_ID
Or, if the EMPLOYEES table also had an OFFICE_ID column, you could rewrite the NATURAL JOIN of EMPLOYEES and SALES in the current example as:
SELECT employees.emp_ID, sales.office_ID, f_name, l_name,
sales_date, amount_sold
FROM employees, sales
WHERE employees.emp_ID = sales.emp_ID
AND employees.office_ID = sales.office_ID
| |
Note |
If your DBMS product, like MS-SQL Server, does not support the NATURAL JOIN operator, simply use an equi-join with a WHERE clause that uses AND operators to combine search conditions that equate each pair or columns with the same names in both tables. Whatever its form, the important thing to remember is that a NATURAL JOIN is a query that joins rows only if all pairs of columns with the same name in both source tables have matching values. Therefore, if you use a NATURAL JOIN, make sure that all related (joinable) columns have the same name in both tables and that all unrelated columns have names unique to each table.
|
Understanding the Condition JOIN
A condition join is a multi-table query that can use any of the relational operators (>, <, >=, <=, <>, and =) to relate a column in one table with the column value of a corresponding (related) column in another table. In short, a condition join is like an equi-join, except you can use any relational operator in a condition join, while you can use only the equality operator (=) in an equi-join. The only difference between a condition join and a multi-table query with a WHERE clause is that you will find the search condition used to relate the tables in the condition join's ON clause instead of a WHERE clause.
For example, the condition join
SELECT * FROM employees JOIN customers
ON (salesperson_ID = emp_ID)
will generate a results table with each row from the CUSTOMERS table joined to the row in the EMPLOYEES table in which the value in the EMP_ID column (from the row in the EMPLOYEES table) matches the SALESPERSON_ID (from the row in the CUSTOMERS table). As such, the condition join in the current example is functionally equivalent to the multi-table join:
SELECT * FROM employees, customers
WHERE salesperson_ID = emp_ID
Similarly, you can use a condition join such as
SELECT DISTINCT e.emp_ID e.f_name, e.l_name, e.total_sales
FROM NV_employees e JOIN AZ_employees
ON (e.total_sales > AZ_employees.total_sales)
to generate a list of Nevada office salespeople (from rows in the NV_EMPLOYEES table) whose TOTAL_SALES are greater than the TOTAL_SALES of at least one of the Arizona office salespeople (found in the AZ_EMPLOYEES table). Or, you could use the multi-table query
SELECT DISTINCT e.emp_ID e.f_name, e.l_name, total_sales
FROM NV_employees e, AZ_employees
WHERE e.total_sales > AZ_employees.total_sales
to produce the same result.
| |
Note |
If your DBMS product does not support a condition join, simply rewrite the condition join as a multi-table query with a WHERE clause. Put the search condition from the condition join's ON clause into the query's WHERE clause. The important thing to remember is that a condition join, like every other multi-table query or join, uses the search condition (whether in a WHERE clause or in an ON clause) to filter out any joined yet unrelated rows. The DBMS rejects joined, unrelated rows because their column values fail to satisfy the search condition in the WHERE clause (or in the ON clause).
|
Using the CROSS JOIN to Create a Cartesian Product
A CROSS JOIN (also called a cross product or a Cartesian product) of two tables is a third table that contains all possible pairs of rows from the two cross joined source tables. For example, if you have two tables, TABLE_1 and TABLE_2, each of which has two columns and three rows, the CROSS JOIN
SELECT * FROM table_1 CROSS JOIN table_2
will pair each of the rows in TABLE_1 with each of the rows in TABLE_2 to produce a results table with four columns and nine rows, as shown in Figure 298.1.
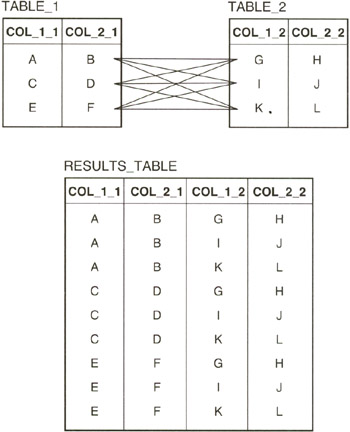
Figure 298.1: The CROSS JOIN of TABLE_ 1 and TABLE_2
| |
Note |
You can determine the number of columns in a CROSS JOIN (or Cartesian product) of two tables by adding the number of columns in the first table to the number of columns in the second table. Moreover, the number of rows in a CROSS JOINs results table will always be the number of rows in the first table multiplied by the number of rows in the second table.
|
If your DBMS product does not support the CROSS JOIN operator, you can still generate the Cartesian product of two tables by executing a multi-table query without a WHERE clause. Suppose, for example, that you have an ATHLETES table and want to pair each athlete with each row of events in a DECATHLON_EVENTS table. If your DBMS supports the CROSS JOIN operator, you can write the query as:
SELECT * FROM athletes CROSS JOIN decathlon_events
Or, you can generate the same results table with the multi-table query:
SELECT * FROM athletes, decathlon_events
As you learned from the multi-table queries in Tips 282–289, the CROSS JOIN (or Cartesian product) is rarely the final result you want from a query. However, the DBMS normally generates the CROSS JOIN of the tables in a SELECT statement's FROM clause as a first step in every query. The system then performs a sequence of steps that manipulate and filter the interim (virtual) Cartesian product table (of the source tables) to produce the joined rows in the final results table.
Understanding the Column Name JOIN
A column name join is very much like the NATURAL JOIN you learned about in Tip 296, "Understanding the NATURAL JOIN." While a NATURAL JOIN requires that all pairs of columns with the same name in both tables have matching values, a column name join lets you specify the pairs of same-name column values the DBMS is to compare. As a result, you can use the column name join to join not only tables that are joinable with a NATURAL JOIN, but also tables that are not. After all, if you write a column name join that requires a match of all pairs of columns with the same name in both tables, the column name join is in effect, a NATURAL JOIN. However, if you have a CUSTOMERS table and an EMPLOYEES table created by
CREATE TABLE customers CREATE TABLE employees
(cust_ID INTEGER, (emp_ID INTEGER,
f_name VARCHAR(30), f_name VARCHAR(30),
l_name VARCHAR(30)) l_name VARCHAR(30))
emp_ID INTEGER)
you cannot use the NATURAL JOIN
SELECT RTRIM(c.f_name)+' '+c.l_name AS 'Customer',
RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson'
FROM customers c NATURAL JOIN employees e
to get a combined list showing each customer's name and the name of the customer's salesperson. As you learned in Tip 296, the NATURAL JOIN requires that all pairs of same-name columns have matching values in joined rows. Therefore, the NATURAL JOIN of CUSTOMERS and EMPLOYEES in the current example will show only the customers that happen to have a salesperson whose first and last names match the customer's first and last name, respectively.
However, you can use a column name join such as
SELECT RTRIM(c.f_name)+' '+c.l_name AS 'Customer',
RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson'
FROM customers c JOIN employees e
USING (emp_ID)
to join the CUSTOMERS and EMPLOYEES tables in the current example. Instead of requiring matching values in all pairs of same-name columns, the USING clause in the current example query tells the DBMS to join rows that have matching values in the EMP_ID column (from each table)—whether the F_NAME and L_NAME column values match or not.
| |
Note |
If your DBMS, like MS-SQL Server, does not support the USING clause, use a condition join instead of a column name join. The only difference between the two types of joins is that the column name join implicitly specifies that the same name column(s) named in the USING clause must have matching values, while the condition join explicitly equates the pair of columns in an ON clause. As such, to convert the column name join in the current example to a condition join, simply rewrite the query as:
SELECT RTRIM(c.f_name)+' '+c.l_name AS 'Customer',
RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson'
FROM customers c JOIN employees e
ON (c.emp_ID = e.emp_ID)
|
Using an INNER JOIN to Select All Rows in One Table That Relate to Rows in Another Table
An INNER JOIN is a multi-table query in which the DBMS returns only related pairs of rows from the source tables—that is, the query's results table will contain only joined rows that satisfy the search condition in the query's ON clause. Conversely, if a row in either source table does not have a corresponding (related) row in the other table, the row is filtered out and therefore not included in the results table.
Suppose, for example, that you have stocks lists from two analysts, and you want to create a list of the stock recommendations they have in common. If one analyst's list is in table STOCK_LIST_A and the other analyst's list is in table STOCK_LIST_B, then an INNER JOIN of the two tables, such as
SELECT a.symbol,
a.buy_at AS 'Buy Price A', a.sell_at AS 'Sell Price A',
b.buy_at AS 'Buy Price B', b.sell_at AS 'Sell Price B'
FROM stock_list_a a INNER JOIN stock_list_b b
ON (a.symbol = b.symbol)
will display a results table similar to
symbol Buy Price A Sell Price A Buy Price B Sell Price B
------ --------- ------------ ----------- --------------
CSCO 50 60 55 70
LU 32 40 30 45
F 26 32 27 40
GM 60 69 58 63
VTSS 86 92 82 89
LEN 28 32 30 34
which lists only stock symbols and price information for those stocks in both STOCK_LIST_A and STOCK_LIST_B. Therefore, any row with a SYMBOL column value in either table that does not match the value in the SYMBOL column of a row in the other table will be filtered out and therefore not included as one of the joined rows in the final results table.
If you rewrite the INNER JOIN in the current example as an equivalent multi-table query such as
SELECT a.symbol,
a.buy_at AS 'Buy Price A', a.sell_at AS 'Sell Price A',
b.buy_at AS 'Buy Price B', b.sell_at AS 'Sell Price B'
FROM stock_list_a a, stock_list_b b
WHERE a.symbol = b.symbol
you can see that an INNER JOIN is just another syntax (or way of writing) the multi-table equi-join queries you learned about in Tips 282–289.
| |
Note |
By default, the DBMS will execute a multi-table query as an INNER JOIN unless you specify one of the OUTER JOIN queries you will learn about in Tips 302–305. Therefore, the query
SELECT * FROM table_a JOIN table_b
ON (table_a.column_to_relate = table_b.column_to_relate)
is equivalent to:
SELECT * FROM table_a INNER JOIN table_b
ON (table_a.column_to_relate = table_b.column_to_relate)
|
Understanding the Role of the USING Clause in an INNER JOIN
The USING clause in an INNER JOIN lists the pairs of same name columns whose values must match in order for the DBMS to include a joined row in the query's results table. In other words, the system generates the Cartesian product of the tables listed in the SELECT statement's FROM clause and then filters out any joined rows in which the pairs of same name columns listed in the USING clause do not have matching values.
For example, the USING clause in the query
SELECT class, section, description, title
FROM curriculum INNER JOIN book_list
USING (class)
tells the DBMS to generate a results table with only joined rows in which the value in the CLASS column from the CURRICULUM table matches the value in the CLASS column from the BOOK_LIST table.
| |
Note |
The column name(s) listed in a USING clause must appear in both of the tables listed in the FROM clause. Moreover, the column(s) must be defined as either of the same data type or of compatible data types.
|
If the relationship between the tables in a query is based on matching values in multiple same-name columns, the USING clause will have more than one column name. For example, if the required reading list for each section of a class is unique, then the query in the current example must be rewritten as
SELECT class, section, description, title
FROM curriculum INNER JOIN book_list
USING (class, section)
to indicate that both the SECTION column pair and the CLASS column pair must have matching values in order for the DBMS to include the joined row in the results table.
The important thing to remember is that the USING clause can specify table row relationships based only on the equality of values in same name column pairs. Therefore, the USING clause in the preceding query is equivalent to the ON clause in
SELECT class, section, description, title
FROM curriculum INNER JOIN book_list
ON ((curriculum.class = book_list.class) AND
(curriculum.section = book_list.section)
and the WHERE clause in:
SELECT class, section, description, title
FROM curriculum, book_list
WHERE (curriculum.class = book_list.class)
AND (curriculum.section = book_list.section)
| |
Note |
The USING clause really does not add any functionality to SQL. As a result, many DBMS products, such as MS-SQL Server, do not support it. After all, as you can see from the final two example queries in the current tip, you can use an ON clause or a WHERE clause to perform the same function as a USING clause. However, if your DBMS supports it, you may want to use the USING clause because it lets you write queries that are more compact and (perhaps) easier to understand.
|
Understanding the OUTER JOIN
Both inner joins and multi-table queries with a WHERE clause combine rows from multiple tables (two tables at a time) and generate results tables that contain only pairs of rows. In other words, if a row in either of the source tables does not have a match (or related row) in the other source table, the DBMS will not place the row in the final results table. As a result, unmatched rows from both tables appear to "vanish" when you execute a multi-table query or INNER JOIN.
An OUTER JOIN, on the other hand, tells the DBMS to generate a results table with not only pairs of related rows, but also unmatched rows from either of the two source tables. For example, if you have a STUDENTS table and a FACULTY table with the following data
STUDENTS table FACULTY table
f_name l_name major f_name l_name dept_head
------ -------- ----------- ------ -------- ---------
Sally Smith English Lori Raines English
Allen Winchell Mathematics Marcus Elliot Engineering
Bruce Dern Business Kelly Wells Mathematics
Susan Smith NULL Kris Matthews NULL
Howard Baker NULL Linda Price NULL
then the single-table queries
SELECT * FROM students
SELECT * FROM faculty
will generate results tables with five rows of data. However if you join rows from the STUDENTS table with rows from the FACULTY table using a multi-table query such as
SELECT RTRIM(s.f_name+' '+s.l_name AS 'Student', major,
dept_head, RTRIM(f.f_name)+' '+f.l_name AS 'Professor'
FROM students s, faculty f
WHERE major = dept_head
ORDER BY major, dept_head
then the DBMS will generate a results table with only two rows:
Student major dept_head Professor
-------------- ----------- ----------- -----------
Sally Smith English English Lori Raines
Allen Winchell Mathematics Mathematics Kelly Wells
The remaining three rows in the STUDENTS table seem to "vanish" because the DBMS cannot pair with rows in the FACULTY table by finding a matching DEPT_HEAD column value (from the FACULTY table) for the MAJOR column value (from the STUDENTS table). Similarly, the system filters out three unmatched rows from the FACULTY table for the same reason—no matching value in the MAJOR column (from the STUDENTS table) for the value in the DEPT_HEAD column (from the FACULTY table).
| |
Note |
The SQL standard specifies that the predicate NULL = NULL is FALSE. As a result, the WHERE clause filters out any rows that join a student without a major (that is, a row from the STUDENTS table with a NULL in the MAJOR column) with a faculty member who is not the head of a department (that is, a row from the FACULTY table with a NULL in the DEPT_HEAD column).
|
To list not only paired (related) rows but also unmatched rows from either table, rewrite the multi-table query (which is, in effect, an INNER JOIN based on the columns listed in the WHERE clause) with a FULL OUTER JOIN such as
SELECT RTRIM(s.f_name+' '+s.l_name AS 'Student', major,
dept_head, RTRIM(f.f_name)+' '+f.l_name AS 'Professor'
FROM students s FULL OUTER JOIN faculty f
ON (major = dept_head)
ORDER BY major, dept_head
to generate a results table similar to:
Student major dept_head Professor
-------------- ----------- ----------- -------------
NULL NULL NULL Kris Mathews
NULL NULL NULL Linda Price
Susan Smith NULL NULL NULL
Howard Baker NULL NULL NULL
NULL NULL Engineering Marcus Elliot
Bruce Dern Business NULL NULL
Sally Smith English English Lori Raines
Allen Winchell Mathematics Mahtematics Kelly Wells
The results table from the FULL OUTER JOIN has eight rows:
- Two joined (related) rows (Sally Smith and Allen Winchell) produced by the multi-table query (the INNER JOIN)
- Two unmatched rows (from the STUDENTS table) for students without a major (Susan Smith and Howard Baker)
- One unmatched row (from the STUDENTS table) for a student (Bruce Dern) with a MAJOR (Business) without a department head in the FACULTY table
- Two unmatched rows (from the FACULTY) table for professors who are not department heads (Kris Mathews and Linda Price)
- One unmatched row (from the FACULTY table) for a professor (Marcus Elliot) who is head of a department (Engineering) in which no students are majoring
Notice that the DBMS fills the remaining results table columns from the "other" table with NULL values in each of the unmatched rows. For example, Bruce Dern is a business major. However, since there is no DEPT_HEAD for the business department in the FACULTY table, the DBMS puts a NULL into the DEPT_HEAD and PROFESSOR columns (from the FACULTY table) in the joined row in the results table. Similarly, Kris Mathews is not the head of a department, so the DBMS puts a NULL in the STUDENT and MAJOR columns (from the STUDENTS table) in the joined row in the results table.
Understanding the LEFT OUTER JOIN
As you learned in Tip 302, "Understanding the OUTER JOIN," the results table from an INNER JOIN includes only pairs of related rows, while the results table from an OUTER JOIN includes both matched (related) rows and unmatched rows. The FULL OUTER JOIN in Tip 302 included unmatched rows from both tables in the final results table. If you want to include unmatched rows from only one of the two source tables involved in a join (or multi-table query), use either a LEFT OUTER JOIN or a RIGHT OUTER JOIN instead of a FULL OUTER JOIN.
A LEFT OUTER JOIN tells the DBMS to generate a results table that includes joined rows and any unmatched rows from the table listed to the left (that is, listed before) the keyword JOIN in the query's FROM clause.
Suppose, for example, that you want to join the list of all customer names and total purchases from a CUSTOMERS table with the name of salesperson to whom each customer is assigned from the EMPLOYEES table. However, since you want a list of all customers, you want the DBMS to include any customers not currently assigned to an active salesperson as well.
If you execute an INNER JOIN such as
SELECT cust_ID, RTRIM(c.f_name)+' '+c.l_name AS 'Customer',
total_purchases, emp_ID,
RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson'
FROM customers c JOIN employees e
ON (salesperson = emp_ID)
ORDER BY emp_ID DESC
the results table will display only the name, total purchases, and salesperson's name for customers currently assigned to a salesperson (that is, rows from the CUSTOMERS customer table with a SALESPERSON value that the DBMS can find in the EMP_ID column of the EMPLOYEES table). As a result, any CUSTOMERS table rows with a NULL SALESPERSON or an invalid SALESPERSON will not appear in the SELECT statement's results table.
However, if you execute the same basic query as a LEFT OUTER JOIN
SELECT cust_ID, RTRIM(c.f_name)+' '+c.l_name AS 'Customer',
total_purchases, emp_ID,
RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson'
FROM customers c LEFT OUTER JOIN employees e
ON (salesperson = emp_ID)
ORDER BY emp_ID DESC
the DBMS will generate a results table similar to
cust_ID Customer total_purchases emp_ID Salesperson
------- --------------- --------------- ------ -----------
6753 Sally Brown 95658.0000 NULL NULL
3758 Richard Stewart 15425.0000 NULL NULL
1001 Linda Reed 158112.0000 101 Konrad King
7159 Walter Fields 96835.0000 101 Konrad King
4859 Sue Coulter 45412.0000 101 Konrad King
2158 Jimmy Tyson 754515.0000 201 Kris Jamsa
5159 James Herrera 74856.0000 201 Kris Jamsa
which includes not only joined rows showing each customer and the customer's salesperson's name, but also any customers not yet assigned to a salesperson or that have values in the SALESPERSON column (from the CUSTOMERS table) that do not match any values in the EMP_ID column (from the EMPLOYEES table). Notice that the DBMS puts NULL values into the results table EMP_ID and SALESPERSON columns (from the EMPLOYEES table) in each of the unmatched rows from the CUSTOMERS table.
| |
Note |
The keyword LEFT in a LEFT OUTER JOIN tells you that the results table will include unmatched rows from the table to the LEFT of the keyword JOIN in the query's FROM clause. As such, if you changed the FROM clause in the current example to
FROM (employees e JOIN customers c)
you would get a different results table. The new results table, like the one in the current example, would still have the same pairs of joined rows. However, instead of unmatched CUSTOMERS table rows, the results table would include all unmatched from the EMPLOYEES table and no unmatched rows from the CUSTOMERS table.
|
Understanding the RIGHT OUTER JOIN
In Tip 303, "Understanding the LEFT OUTER JOIN," you learned that a LEFT OUTER JOIN tells the DBMS to generate a results table that includes all related rows from the query's source tables, and any unmatched rows from the table to the left of the keyword JOIN. Conversely, a RIGHT OUTER JOIN tells the DBMS to generate a results table that includes all related rows and any unmatched rows from the table to the right (that is, the table that follows) the keyword JOIN in the SELECT statement's FROM clause.
For example, if you work for a food delivery service that lends freezers to its customers, you can get a complete list of freezers the company owns along with the names of customers who have the freezer currently out on loan by executing a RIGHT OUTER JOIN such as
SELECT RTRIM(f_name)+' '+l_name AS 'Customers Name'
freezer_inventory.freezer_ID, date_purchased AS
'Purchased', cost, amt_repairs AS 'Repairs'
FROM customers RIGHT OUTER JOIN freezer_inventory
ON (customers.freezer_ID = freezer_inventory.freezer_ID)
ORDER BY freezer_inventory.freezer_ID
which will generate a results table similar to:
Customer Name freezer_ID Purchased Cost Repairs
--------------- ---------- ---------- -------- -------
NULL 11111 2000-10-11 155.9900 10.0000
Richard Stewart 15425 1999-01-01 179.9400 .0000
NULL 15915 1998-05-05 133.4500 .0000
NULL 16426 1998-07-05 100.4500 12.7500
NULL 21345 1996-09-09 100.4500 12.2300
NULL 22222 2000-04-07 255.5800 .0000
Sue Coulter 45412 1995-03-05 179.9400 45.8900
NULL 45413 1999-01-01 255.2800 .0000
NULL 74845 1997-04-01 99.9900 .0000
James Herrera 74856 1999-05-09 185.2500 12.2500
Sally Brown 95658 2000-06-01 188.8500 15.5500
Walter Fields 96835 2000-10-15 155.9900 75.5500
NULL 97999 1996-09-03 75.9800 44.2500
Notice that the DBMS places a NULL in the results table Customer Name column for each unmatched row from the FREEZER_INVENTORY table. Moreover, the system filters out any unmatched rows from the CUSTOMERS table. (Unmatched CUSTOMERS table rows in the results table would have a customer name and NULL values for the results table columns from the FREEZER_INVENTORY table (FREEZER_ID, PURCHASED, COST, and REPAIRS).
| |
Note |
If you are doing a RIGHT OUTER JOIN and the results table includes the column used to match (join) related rows in the query's source tables, be sure to use the column from the table listed to the right of the keyword JOIN in the SELECT statement's FROM clause. If you use the column from the table listed to the left of the JOIN instead, results table rows for unmatched rows from the right table will have a NULL value in the matching column. For example, if the SELECT clause in the preceding query listed CUSTOMERS.FREEZER_ID (the matching column from the left table) instead of FREEZER_INVENTORY.FREEZER_ID (the matching column from the right table) results table would show a NULL value for the freezer_ID column for freezers 11111, 15915, 16426, 21345, 22222, 45413, 74845, and 97999. As a result, you would not know the serial numbers for the freezers that should be in your warehouse. Moreover, you would not know the purchase date, initial cost, and cost of repairs for a particular freezer not currently on loan.
|
Understanding the FULL OUTER JOIN
The FULL OUTER JOIN combines the results of the LEFT OUTER JOIN (which you learned about in Tip 303, "Understanding the LEFT OUTER JOIN") and the RIGHT OUTER JOIN (which you learned about in Tip 304, "Understanding the RIGHT OUTER JOIN"). When the DBMS executes a FULL OUTER JOIN, it generates a results table that contains joined (related) rows along with any unmatched rows from both the table to the left and the table to the right of the keyword JOIN in the SELECT statement's FROM clause.
For example, to list all customer names from the CUSTOMERS table along with all freezers from the FREEZER_INVENTORY table, you could execute the FULL OUTER JOIN
SELECT RTRIM(f_name)+' '+l_name AS 'Customers Name'
customers.freezer_ID AS 'Cust_FID',
freezer_inventory.freezer_ID AS 'Inv_FID',
date_purchased AS 'Purchased', cost,
amt_repairs AS 'Repairs'
FROM customers FULL OUTER JOIN freezer_inventory
ON (customers.freezer_ID = freezer_inventory.freezer_ID)
ORDER BY freezer_inventory.freezer_ID
which will produce a results table similar to:
Customer Name Cust_FID Inv_FID Purchased Cost Repairs
--------------- -------- ------- ---------- -------- ------
Jimmy Tyson 754515 NULL NULL NULL NULL
Linda Reed 158112 NULL NULL NULL NULL
NULL NULL 11111 2000-10-11 155.9900 10.0000
Richard Stewart 15425 15425 1999-01-01 179.9400 .0000
NULL NULL 15915 1998-05-05 133.4500 .0000
NULL NULL 16426 1998-07-05 100.4500 12.7500
NULL NULL 21345 1996-09-09 100.4500 12.2300
NULL NULL 22222 2000-04-07 255.5800 .0000
Sue Coulter 45412 45412 1995-03-05 179.9400 45.8900
NULL NULL 45413 1999-01-01 255.2800 .0000
NULL NULL 74845 1997-04-01 99.9900 .0000
James Herrera 74856 74856 1999-05-09 185.2500 12.2500
Sally Brown 95658 95658 2000-06-01 188.8500 15.5500
Walter Fields 96835 96835 2000-10-15 155.9900 75.5500
NULL NULL 97999 1996-09-03 75.9800 44.2500
If you are using a FULL OUTER JOIN not only to display all rows in both tables (both matched and unmatched) but also to look for inconsistencies in related tables, be sure the results table includes all of the columns in the pair(s) of columns used to relate the tables.
For example, if the results table in the current example displayed only the FREEZER_ID from the FREEZER_INVENTORY table, it would not show that CUSTOMERS table rows for Jimmy Tyson and Linda Reed have invalid freezer ID numbers in the FREEZER_ID column. A results table without the CUST_FID column (the FREEZER_ID from the CUSTOMERS table) would tell you only that the two customers did not have a freezer with a FREEZER_ID that matched one of the FREEZER_ID values in the FREEZER_INVENTORY table.
Conversely, if the results table had only the CUST_FID (the FREEZER_ID from the CUSTOMERS table) and not the INV_FID (the FREEZER_ID column from the FREEZER_INVENTORY table), you could still tell that Jimmy and Linda had invalid freezer ID numbers. (Unmatched rows from the CUSTOMERS table with an invalid FREEZER_ID in the CUSTOMERS table would have a non-NULL value in the CUST_FID column NULL values for the PURCHASED, COSTS, and REPAIRS columns in the results table.) However, without an INV_FID column, the results table would show only the FREEZER_ID values for the freezers currently on loan, since the DBMS would put a NULL in the CUST_FID column for each unmatched row from the FREEZER_INVENTORY table.
Understanding MS SQL Server OUTER JOIN Notation
When you learned how to write LEFT OUTER JOIN, RIGHT OUTER JOIN, and FULL OUTER JOIN queries in Tips 303-305, all of the examples used an ON clause to specify the relationship for joining matching pairs of rows. However, MS-SQL Server also lets you write LEFT and RIGHT OUTER JOIN queries as multi-table SELECT statements with a WHERE clause.
If you attach an asterisk (*) to the comparison operator in a SELECT statement's WHERE clause, the DBMS treats the multi-table query as an OUTER JOIN. As shown in Table 306.1, the position of the asterisk (*) (to the left or to the right of the comparison operator) tells the DBMS the type of OUTER JOIN you want to perform.
Table 306.1: MS-SQL Server WHERE Clause OUTER JOIN Notation
|
Type of OUTER JOIN
|
WHERE Clause Operators
|
|
LEFT OUTER JOIN
|
*=, *<, *>, *<=, *>=, *<>
|
|
RIGHT OUTER JOIN
|
=*, <*, >*, <=*, >=*, <>*
|
For example, you can write the LEFT OUTER JOIN used as an example in Tip 303, "Understanding the LEFT OUTER JOIN," as a multi-table SELECT statement by attaching an asterisk (*) to the left of the equality (=) comparison operator in the query's WHERE clause:
SELECT cust_ID, RTRIM(c.f_name)+' '+c.l_name AS 'Customer',
total_purchases, emp_ID,
RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson'
FROM customers c, employees e
WHERE salesperson *= emp_ID
ORDER BY emp_ID DESC
Similarly, if you attach an asterisk (*) to the right of an equality operator (=) operator in a SELECT statement's WHERE, MS-SQL Server will execute a RIGHT OUTER JOIN. Therefore, you can write the RIGHT OUTER JOIN used as an example in Tip 304, "Understanding the RIGHT OUTER JOIN," as:
SELECT RTRIM(f_name)+' '+l_name AS 'Customers Name'
freezer_inventory.freezer_ID, date_purchased AS
'Purchased', cost, amt_repairs AS 'Repairs'
FROM customers, freezer_inventory
WHERE customers.freezer_ID =* freezer_inventory.freezer_ID
ORDER BY freezer_inventory.freezer_ID
You may be surprised to find (as I was) that MS-SQL Server does not have a WHERE clause operator for a FULL OUTER JOIN. I fully expected the DBMS to use an asterisk (*) on both sides of the comparison operator in the WHERE clause to specify a FULL OUTER JOIN. After all, the FULL OUTER JOIN is a combination of the LEFT OUTER JOIN and the RIGHT OUTER JOIN. Therefore, one would think that the "combination" FULL OUTER JOIN notation would be an asterisk (*) on both sides of the comparison operator in the query's WHERE clause. (After all, the LEFT OUTER JOIN has an asterisk [*] to the left of the comparison operator [*=], and the RIGHT OUTER JOIN has an asterisk [*] to the right of the comparison operator [=*]).
Joining More Than Two Tables in a Single Query
Whether executing an OUTER JOIN or an INNER JOIN, the DBMS always performs its joins two tables at a time. Therefore, to JOIN three or more tables in a single query will require multiple JOIN clauses that combine pairs of source tables, pairs of (interim) joined tables, or a single source table with an interim joined table.
Suppose, for example, that you keep information on the stocks you own in a PORTFOLIO table, and you want to know if insider trading activity (noted in an INSIDER_TRADES table) is at all related to the analyst recommendations (stored in an ANALYST_RECOM-MENDATIONS) table. To answer your question, the DBMS must join the three tables, two tables at a time. First, write a two-table INNER JOIN such as
SELECT p.symbol, trade_type, share_ct, position
FROM portfolio p INNER JOIN insider_trades it
ON p.symbol = it.symbol
ORDER BY p.symbol
to get a list of stocks in the PORTFOLIO table that also have insider trading activity in the INSIDER_TRADES table. The INNER JOIN tells the DBMS to filter out any rows from the PORTFOLIO table that do not have a related row (by matching SYMBOL column values) in the INSIDER_TRADES table, and vice versa. Next, add a LEFT OUTER JOIN that will relate the joined (PORTFOLIO/INSIDER_TRADES) rows in the interim table (by matching SYMBOL column values) with rows in the ANALYST_RECOMMENDATIONS table:
SELECT p.symbol, trade_type, share_ct, position,
recommendation
FROM portfolio p INNER JOIN insider_trades it
ON p.symbol = it.symbol
LEFT OUTER JOIN analyst_recommendations ar
ON p.symbol = ar.symbol
ORDER BY p.symbol
| |
Note |
The LEFT OUTER JOIN in current example tells the DBMS that you want the query results to include all matched rows from the ANALYST_RECOMMENDATIONS table and any unmatched joined rows from the INNER JOIN of the PORTFOLIO table and the INSIDER_TRADES table. If you used an INNER JOIN instead of the LEFT OUTER JOIN, the final results table would include only stocks from the PORTFOLIO table that had both insider trades (from the INSIDER_TRADES table) and analyst recommendations (from the ANALYST_RECOMMENDATIONS table). However, the original query was "Are analyst recommendations related to insider trades?" Therefore, you really need a final results table that includes not only your insider-traded stocks with (matching) analyst recommendations, but also all of your insider-traded stocks without (matching) analyst recommendations.
|
After the DBMS puts all of your insider-traded stocks in the final results table, you can compare the number of insider trades matched with analyst recommendations to the number that are not.
Now, suppose you want to submit a query that can be answered only by joining multiple joined tables instead of by joining a source table to a joined table (as shown in the preceding example). For example, to get a list of stocks in your PORTFOLIO table that have matching rows in the INSIDER_TRADES table or matching rows in the ANALYST_REC-OMMENDATIONS, submit a query similar to
SELECT (CASE WHEN p1.symbol IS NULL THEN p2.symbol
ELSE p1.symbol
END) AS 'Stock',
trade_type, share_ct, position, recommendation
FROM (portfolio p1 INNER JOIN insider_trades it
ON p1.symbol = it.symbol)
FULL OUTER JOIN
(portfolio p2 INNER JOIN analyst_recommendations ar
ON p2.symbol = ar.symbol)
ON p1.symbol = p2.symbol
ORDER BY Stock
which performs a FULL OUTER JOIN of the joined rows from the INNER JOIN of rows from the PORTFOLIO table with rows from the INSIDER_TRADES table, and the joined rows from the INNER JOIN of rows from the PORTFOLIO table with rows from the ANALYST_RECOMMENDATIONS table.
The important thing to understand is that the DBMS always executes a JOIN two tables at a time. However, the two tables you tell the DBMS to join can be two individual source tables, an individual source table and a joined table, or two joined tables. As such, your query can join any number of tables—just be aware that the DBMS works its way through joining them, two tables at a time.
Understanding Non equality INNER and OUTER JOIN Statements
All of the INNER JOIN and OUTER JOIN examples in Tips 300–305 used the equality (=) comparison operator to join rows in one table with related rows in another based on matching pairs of column values. However, both INNER JOIN and OUTER JOIN queries also let you join pairs of rows based on column value relationships other than equality.
Suppose, for example, that an airline wants to generate a list of customers and the rewards they have earned based on the balance in each customer's frequent flier account. An INNER JOIN such as
SELECT member_ID,
RTRIM(f_name)+' '+l_name AS 'Member Name', miles_earned,
miles_required, description AS 'Reward Earned'
FROM frequent_fliers INNER JOIN rewards
ON miles_earned >= miles_required
ORDER BY l_name, f_name, member_ID, miles_required
will generate a results table that lists customer IDs, names, account balances, and rewards earned for all customers eligible for at least one reward.
In the current example, the relationship between a row in the FREQUENT_FLIER table and a row in the REWARDS table is not based on matching MILES_EARNED and MILES_REQUIRED column values alone. Rather, the final results table will include not only rows in which the two columns have matching values, but also rows in which the value in the MILES_EARNED column is greater than the value in the MILES_REQUIRED column.
You can also use nonequality comparison operators in OUTER JOIN queries. For example, if a real estate firm wants to prepare a list of its listed properties and prospective buyers, the FULL OUTER JOIN query
SELECT address, RTRIM(f_name)+' '+l_name AS 'Buyer',
min_sales_price AS 'Seller Minimum',
max_purchase_price AS 'Buyer Maximum',
(max_purchase_price - min_sales_price) AS 'Spread'
FROM listings FULL OUTER JOIN buyers
ON (max_purchase_price >= min_sales_price)
AND (size_required <= square_footage)
AND (bedrooms_required <= num_bedrooms)
ORDER BY address DESC, buyer
will generate a results table that not only matches each potential buyer with listings within the buyer's price range and specifications, but also lists properties with no prospects and buyers with requirements not satisfied by any of the listed properties.
The important thing to understand is that you can use any of the comparison operators (=, <, >, <=, >=, and <>) in the ON clause of an INNER and an OUTER join to express the relationship between pairs of columns in related rows.
Understanding the UNION JOIN
The UNION JOIN, unlike the other joins you learned about in Tips 296-305, makes no attempt to match and actually join a row from one source table with one or more rows from the other source table. Instead, the UNION join simply creates a results table that contains the rows of columns from the first table plus the rows of columns from the second table.
For example, the UNION JOIN
SELECT * FROM portfolio_a a UNION JOIN portfolio_b b
will generate a single results table with all of the rows and columns from both the PORTFOLIO A table and the PORTFOLIO_B table, as shown in Figure 309.1.
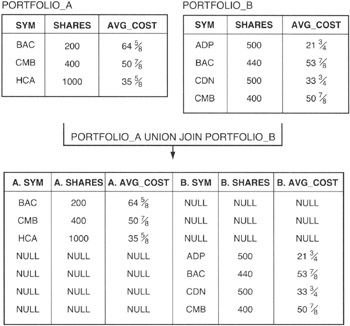
Figure 309.1: The source and results tables for a two-table UNION JOIN
While an OUTER JOIN supplies only NULL values for the other table's columns in unmatched rows, every row in a UNION JOIN consists of the column values from one table joined to NULL column values for the other table. In the current example of a UNION JOIN, the DBMS inserts all of the rows from PORTFOLIO_A—joined to a row with a NULL value for each of the columns in PORTFOLIO_B—into the results table. Then the system inserts each of the rows from PORTFOLIO_B—joined to a row with a NULL value for each of the columns in PORTFOLIO_A into the results table.
A UNION JOIN is handy when you want to work with all of the rows from two or more (perhaps union-incompatible) tables as if they were a single table—without losing the ability to tell which rows came from which table.
| |
Note |
The results table from a UNION JOIN of two tables is not the same the results table generated by the DBMS when you use the UNION operator to SELECT all rows that appear in either or both of the same two tables. (You learned about the UNION operator in Tip 216, "Using the UNION Operator to Select All Rows That Appear in Any or All of Two or More Tables.") Unlike the results table for the UNION JOIN shown in Figure 309, a UNION query of the same two tables
SELECT * FROM portfolio_a
UNION
SELECT * FROM portfolio_b
generates a results table similar to:
SYM SHARES AVG_COST
--- ------ --------
BAC 200 64 5/16
CMB 400 50 7/8
HCA 1000 33 5/8
ADP 500 21 3/4
BAC 440 53 7/16
CDN 500 33 3/4
While the results table from the UNION JOIN has seven rows of six columns each, the DBMS generates a results table with six rows of three columns each when you use the UNION operator to combine the rows in the two tables instead.
|
Using the COALESCE Expression to Refine the Results of a UNION JOIN
In Tip 309, "Understanding the UNION JOIN," you learned that the UNION JOIN of two (or more) tables creates a results table with the rows and columns from all of the source tables. Each row in the results table contains the column values from one of the rows in the source table joined with NULL column values for each of the columns in each of the query's other source tables. As such, the UNION JOIN generates a final results table with a lot of null values.
For example, the UNION JOIN query
SELECT * FROM
joint_acct j UNION JOIN SEP_acct s UNION JOIN IRA_acct i
will generate a results table similar to:
sym shares avg_cst sym shares avg_cst sym shares avg_cst
---- ------ ------- ---- ------ ------- ---- ------ -------
BAC 200 64.625 NULL NULL NULL NULL NULL NULL
CMB 400 50.875 NULL NULL NULL NULL NULL NULL
HCA 1000 35.625 NULL NULL NULL NULL NULL NULL
NULL NULL NULL ADP 500 21.75 NULL NULL NULL
NULL NULL NULL BAC 440 53.875 NULL NULL NULL
NULL NULL NULL CDN 500 33.75 NULL NULL NULL
NULL NULL NULL NULL NULL NULL F 500 41.125
NULL NULL NULL NULL NULL NULL HCA 300 27.375
NULL NULL NULL NULL NULL NULL CMB 400 50.875
The large number of NULL values in the final results table makes it hard to discern any meaningful information from its contents. The expression "can't see the forest for the trees" comes to mind.
Fortunately, you can use the COALESCE expression (which you learned about in Tip 112, "Using the COALESCE Expression to Replace NULL Values") to filter out the NULL values from the final results table. For example, if you rewrite the preceding UNION JOIN as
SELECT
COALESCE (j.symbol, s.symbol, i.symbol) AS 'Symbol',
COALESCE (j.account, s.account, i.account) AS 'Account',
COALESCE (j.shares, s.shares, i.shares) AS 'Shares',
COALESCE (j.avg_cst, s.avg_cst, i.avg_cst) AS 'Avg Cost'
FROM (SELECT 'Joint Acct' AS 'Account', j.*) j,
UNION JOIN (SELECT 'SEP Acct' AS 'Account', s.*) s,
UNION JOIN (SELECT 'IRA Acct' AS 'Account', i.*) i
ORDER BY symbol, account
the query's COALESCE expressions will select the one non-NULL value from each set of columns—thereby filtering out the NULL values from the (now) interim results table from the UNION JOIN clauses to generate a final results table similar to:
Symbol Account Shares Avg Cost
------ ---------- ------ --------
ADP SEP Acct 500 21.7500
BAC Joint Acct 200 64.6250
BAC SEP Acct 440 53.8750
CDN SEP Acct 500 33.7500
CMB IRA Acct 400 50.8750
CMB Joint Acct 400 50.8750
F IRA Acct 500 41.1250
HCA IRA Acct 300 27.3750
HCA Joint Acct 1000 35.6250
Moreover, you need only change the ORDER BY clause to
ORDER BY account, symbol
to sort the list of stocks in order by account—thereby making it easier to see which stocks you are holding in which account.
Understanding the Role of the FROM Clause in a JOIN Statement
The FROM clause in a JOIN, or multi-table SELECT statement, is the virtual table from which the DBMS retrieves the rows of column values it uses as input for the remaining clauses in the query. Suppose, for example, that you have a GRADES table and a STUDENTS table created by:
CREATE TABLE grades CREATE TABLE students
course_ID VARCHAR(15), (SID INTEGER,
section SMALLINT, f_name VARCHAR(20),
student_ID INTEGER, l_name VARCHAR(20))
professor_ID INTEGER,
grade NUMERIC)
If you submit an INNER JOIN query such as
SELECT RTRIM(f_name)+' '+l_name AS 'Student', course_ID,
section, grade
FROM grades JOIN students ON student_ID = SID
the DBMS will generate a results table that lists student names, classes, and grades.
When executing a query, the BMS first creates a virtual table by joining the rows from the tables listed in the FROM clause that satisfy the search condition(s) in the ON clause. In the current example, the DBMS creates a virtual table consisting of rows from the GRADES table joined with rows from the STUDENTS table in which the value in the STUDENT_ID column from the GRADES table matches the value in the SID column of the STUDENTS table.
Next, the system passes column values from each joined row in the virtual table (and not each of the physical source tables) to the SELECT clause, which filters out unwanted columns and displays the rest in the results table. In the current example, the SELECT clause filters out all but the F_NAME, L_NAME, COURSE_ID, SECTION, and GRADE column values from the joined rows in the GRADES+STUDENTS virtual table.
Similarly, if you have the names of the school's teachers in a PROFESSORS table, you can use a query similar to
SELECT RRIM(s.f_name)+' '+s.l_name AS 'Student', course_ID,
section, grade, RTRIM(p.f_name)+' '+p.l_name AS 'Teacher'
FROM (grades JOIN students s ON student_ID = SID)
JOIN professors p ON professor_ID = PID
to display the name of the professor who taught the class next to the class ID, student name, and grade.
In the current example, the FROM clause tells the DBMS to create a virtual table with joined rows from the STUDENTS and GRADES table, as it did in the preceding example. Next, the DBMS creates another virtual table by joining rows from the PROFESSORS table with joined rows in the STUDENTS+GRADES virtual table in which the value in the PID column from a row in the PROFESSOR table matches the value in the PROFESSOR_ID column from a joined row in the (virtual) STUDENTS+GRADES table.
Therefore, although the FROM clause in a query such as
SELECT * FROM students, grades
WHERE student_ID = SID
ORDER BY student_ID
might give you the impression that a FROM clause simply lists the names of source table(s) used by a SELECT statement, the FROM is actually the virtual table with the joined rows that serve as the data source for the query. The DBMS first creates a virtual table either from the Cartesian product of the tables listed in the FROM clause or by joining matching rows from related tables as specified in each JOIN statement in the FROM clause. Next the system uses the other clauses in the SELECT statement to filter unwanted rows and columns out of the virtual table and adds the remaining column values as rows to the final results table.
Using the * Operator to Specify All Columns in All or Only in Some Tables in a Multiple Table JOIN
As you learned in Tip 90, "Using the SELECT Statement to Display All Column Values," the asterisk (*) "all columns" operator gives you a shortcut way to tell the DBMS to that you want to include all of a table's columns in the query's results table. For example, the results table for the SELECT statement
SELECT * FROM students
includes all of the columns in the STUDENTS table. Similarly, the results table for the query
SELECT * FROM students, grades
WHERE SID = student_ID
includes all of the columns from the STUDENTS table followed by all of the columns from the GRADES table. If you execute a query for three (or more) tables with only the asterisk (*) all columns operator in the SELECT clause, the results table will include all of the columns from the first table listed in the FROM clause, followed by all of the columns from the second table listed in the FROM clause, followed by all of the columns from the third table listed in the FROM clause, and so on.
To display all of the columns from only some of the tables listed in the FROM clause, use a qualified all columns operator. As you learned in Tip 289, "Using Qualified Column Names in Multi-table Queries That Join Tables That Have the Same Names for One or More Columns," a qualified column name is a column name that includes the name of the table in which the column is located. Similarly, a qualified all columns operator includes the name of the table from which the DBMS is to display all column values. Thus, to display all columns from the STUDENTS table, you could execute a SELECT statement such as:
SELECT students.* FROM students
which uses the qualified all columns operator STUDENTS.* to tell the DBMS to display all of the column values in the STUDENTS table. Similarly, if you want to display all of the columns in the STUDENTS table while displaying only two of the columns from the GRADES table, you can execute a query similar to
SELECT students.*, grade FROM students, grades
WHERE SID = student_ID
which uses the qualified all columns operator to tell the DBMS to display all columns from the STUDENTS table along with only the COURSE_ID and GRADE columns from the GRADES table.
Using a Table Alias to Perform a Single table JOIN (i e Self JOIN)
Strange as it sounds, some multi-table queries (or joins) involve a relationship a table has with itself (vs. with another table). Suppose, for example, that you offer your customers an incentive to recommend your company to people they know. If you keep track of the referring customer's ID number in a column of the CUSTOMERS table (such as REFERRER, for example), you can submit a query similar to
SELECT cust_ID, RTRIM(f_name)+' '+l_name AS 'Customer',
referrer AS 'Referred By'
FROM customers
WHERE referrer IS NOT NULL
ORDER BY "Referred By"
to generate a results table that displays the CUST_ID of the referrer next to the name of each customer that was referred by another customer. However, to list the name of each referrer instead of the CUST_ID number, you will need to join each row in the CUSTOMERS table that has a non-NULL value in the REFERRER column with the row in the CUSTOMERS table that has a matching value in the CUST_ID column. In other words, you need to JOIN rows in the CUSTOMERS table with other rows in the CUSTOMERS table based on matching REFERRER and CUST_ID column values.
Based on what you learned (in Tip 282, "Using the FROM Clause to Perform a Multi-table Query," and Tip 311, "Understanding the Role of the FROM Clause in a JOIN Statement") about the role of the FROM clause in multi-table queries and JOIN statements, you might assume you can join rows in a table with other rows in the same table by simply including the same table name twice in the FROM clause of a SELECT statement such as:
SELECT cust_ID, RTRIM(f_name)+' '+l_name AS 'Customer',
RTRIM(f_name)+' '+l_name AS 'Referred By'
FROM customers, customers
WHERE referrer = cust_ID
ORDER BY "Referred BY"
When executing the query, the DBMS should first CROSS JOIN the rows in the table with itself. Then the system should use the search condition in the WHERE clause to filter out unwanted joined rows from the (virtual) interim table—those in which the value in the CUST_ID column does not match the value in the REFERRER column.
Unfortunately, SQL will not let you list the same table name more than once in a single FROM clause. As a result, when you submit the preceding example query to the DBMS for execution, the system will display an error message similar to:
Server: Msg 1013, Level 15, State 1, Line 4
Tables 'customers' and 'customers' have the same exposed
names. Use correlation names to distinguish them.
Moreover, if you simply drop the second CUSTOMERS reference from the FROM clause, the DBMS will execute the query. However, as the system goes through the CUSTOMERS table one row at a time, it will display the names from CUSTOMERS table rows in which the REFERRER is the same as the CUST_ID. Since a customer cannot referrer himself (or herself), the query (with only a single reference to CUSTOMERS in the FROM clause) will execute successfully, but will not provide the desired customer names.
To join a table with itself, SQL requires that you use an alias or correlation name for the second reference to the same table. In this way, the DBMS can join two tables with different names when processing the query's FROM clause. Thus, a SELECT statement such as
SELECT customers.cust_ID, RTRIM(customers.f_name)+
' '+customers.l_name AS 'Customer',
RTRIM(referrers.f_name)+' '+referrers.l_name
AS 'Referred By'
FROM customers, customers referrers
WHERE customers.referrer = referrers.CUST_ID
ORDER BY "Referred By"
which defines the REFERRERS alias for the CUSTOMERS table, will display referrer's name next to the name of each customer your company now has as a result of the referrer's recommendation.
In the current example, the DBMS generates the Cartesian product of the CUSTOMERS table and the (imaginary, duplicate) REFERRERS table. Then the system filters out those joined rows from the interim (virtual) CUSTOMERS+REFERRERS table in which the value of the REFERRER column from the CUSTOMERS table is not equal to the CUST_ID from the (imaginary) REFERRERS table.
Similarly, you can use a query such as
SELECT c.cust_ID, RTRIM(c.f_name)+' '+c.l_name
AS 'Customer',
(SELECT count(*) FROM customers r
WHERE r.referrer = c.cust_ID) AS 'Referral Count'
FROM customers c
WHERE c.cust_ID IN (SELECT referrer FROM customers)
ORDER BY "Referral Count" DESC
to get a count of customer referrals you received from each referrer. (The WHERE clause in the example eliminates from the results table those customers who have not given you any referrals.)
Understanding Table Aliases
In Tip 313, "Using a Table Alias to a Single-table JOIN," you learned that SQL requires that you use a second name, or alias, whenever you want to perform a self-join that relates rows in a table to other rows in the same table. You can, however, use an alias (also called a correlation name) for a table name in any query—whether SQL requires it or not.
Suppose, for example, that you want to list the names and phone numbers from the rows in a PROSPECTS table owned by another user, SUSAN. You can execute a query similar to
SELECT RTRIM(susan.prospects.f_name)+
' '+susan.prospects.l_name AS 'Prospect'
susan.prospects.phone_number
FROM susan.prospects
ORDER BY 'Prospect'
in which you type the fully qualified column reference throughout the query. (As you learned in Tip 228, "Understanding Column References," you have to specify the fully qualified column name [which includes the username of the table owner, the table name, and the column name] when referencing a column in a table owned by another user.)
Alternatively, you can shorten the column name references in the query to
SELECT RTRIM(sp.f_name)+' '+sp.l_name AS 'Prospect',
sp.phone_number
FROM susan.prospects sp
ORDER BY 'Prospect'
by defining an alias for the table name in the SELECT statement's FROM clause. To define a table alias (or correlation name), type the alias you want to use immediately after the name of the table in the SELECT statement's FROM clause. You can then use the alias in place of the table name (or the fully qualified table name, such as SUSAN.PROSPECTS, in the current example), throughout the query.
The benefit of using table aliases is more readily apparent when you write a query that displays several columns from the JOIN of two or more tables (especially if the tables have long names or are owned by other usernames). Suppose, for example, that you are the sales manager and want to generate a list of the duplicate phone numbers among the PROSPECTS tables belonging to the three salespeople (FRANK, SUSAN, and RODGER) you manage. If you execute a query such as
SELECT RTRIM(COALESCE(frank.prospects.f_name,
rodger.prospects.f_name,susan.prospects.f_name))+' '+
COALESCE(frank.prospects.l_name,rodger.prospects.l_name,
susan.prospects.l_name) AS 'Prospect',
COALESCE(frank.prospects.phone_number,
rodger.prospects.phone_number,
susan.prospects.phone_number) AS 'Phone Number',
(CASE WHEN frank.prospects.phone_number IS NOT NULL
THEN 'Frank ' ELSE '' END)+
(CASE WHEN rodger.prospects.phone_number IS NOT NULL
THEN 'Rodger ' ELSE '' END)+
(CASE WHEN susan.prospects.phone_number IS NOT NULL
THEN 'Susan' ELSE '' END) AS 'Being Called By'
FROM ((frank.prospects FULL JOIN rodger.prospects ON
frank.prospects.phone_number =
rodger.prospects.phone_number)
FULL JOIN susan.prospects ON
frank.prospects.phone_number =
susan.prospects.phone_number
OR rodger.prospects.phone_number =
susan.prospects.phone_number)
WHERE frank.prospects.phone_number =
rodger.prospects.phone_number
OR frank.prospects.phone_number =
susan.prospects.phone_number
OR rodger.prospects.phone_number =
susan.prospects.phone_number
ORDER BY "Being Called By", 'Prospect'
the DBMS will display a results table similar to:
Prospect Phone Number Called By
-------------- -------------- ------------------
Bill Barteroma (222)-222-2222 Frank Rodger Susan
Steve Kernin (555)-555-5555 Frank Rodger Susan
Frank Burns (111)-222-1111 Frank Susan
Hawkeye Morgan (333)-222-3333 Frank Susan
Steve Pierce (444)-222-4444 Frank Susan
Walter Phorbes (666)-666-6666 Rodger Susan
You can use aliases for each of the three table names and then shorten the query to:
SELECT RTRIM(COALESCE(fp.f_name,rp.f_name,sp.f_name))+' '+
COALESCE(fp.l_name,rp.l_name,sp.l_name) AS 'Prospect',
COALESCE(fp.phone_number,rp.phone_number,sp.phone_number)
AS 'Phone Number',
(CASE WHEN fp.phone_number IS NOT NULL
THEN 'Frank ' ELSE '' END)+
(CASE WHEN rp.phone_number IS NOT NULL
THEN 'Rodger ' ELSE '' END)+
(CASE WHEN sp.phone_number IS NOT NULL
THEN 'Susan' ELSE '' END) AS 'Being Called By'
FROM ((frank.prospects fp FULL JOIN rodger.prospects rp
ON fp.phone_number = rp.phone_number)
FULL JOIN susan.prospects sp
ON fp.phone_number = sp.phone_number
OR rp.phone_number = sp.phone_number)
WHERE fp.phone_number = rp.phone_number
OR fp.phone_number = sp.phone_number
OR rp.phone_number = sp.phone_number
ORDER BY "Being Called By", 'Prospect'
As you can see, using FP, RP, and SP (as aliases) in place of the fully qualified table names in the query not only makes the column name references shorter and less tedious to type, but also makes the query easier to read.
Understanding the Ambiguous Nature of ANY and How SQL Implements It to Mean SOME
In the English language, the word any can have one of two different meanings depending on the context in which it is used.
For example, if you ask, "Do any of you know how to write an SQL query?" you are using any as an existential quantifier, in that you want to know if there is at least one person (among those you are addressing) who knows how to write an SQL query. Conversely, if you say, "I have more fun writing SQL statements than any of you," you are using any as a universal quantifier to mean that you have more fun writing SQL statements than every person in your audience.
SQL lets you use the existential connotation of the keyword ANY in conjunction with one of the six comparison operators (=, <>, <, <=, >, and >=) to compare a single value to a column of data values generated by a subquery. If at least one of the comparisons of the single value to a data value in the set data values from the subquery evaluates to TRUE, then the entire ANY test evaluates to TRUE.
For example, if you have a list of stock symbols and prices in a PORTFOLIO table, and a list of symbols and historical price information in a PRICE_HISTORY table, you could execute a query such as
SELECT symbol, current_price FROM portfolio
WHERE current_price >= ANY
(SELECT closing_price 1.5 FROM price_history
WHERE price_history.symbol = portfolio.symbol
AND price_history.trade_date >= (GETDATE() - 180))
to get a list of stock symbols and current prices for stocks with a current price that is greater by 50 percent or more than at least one of the same stock's closing prices during the past 6 months (180 days).
When executing the query, the DBMS tests the data values in the CURRENT_PRICE column of the PORTFOLIO one row at a time. The system retrieves a stock symbol from the SYMBOL column and its price from the CURRENT_PRICE column of a row in the PORTFOLIO table. Then the subquery generates a list with the stock's CLOSING_PRICE values multiplied by 1.5 (150 percent) for each day during the past 6 months (180 days). If there is any (that is, at least one) CURRENT_PRICE value that is greater than or equal to a computed value in the CLOSING_PRICE list (generated by the subquery), the DBMS includes the stock SYMBOL and its CURRENT_PRICE in the results table. If the CURRENT_PRICE is less than all of the computed CLOSING PRICE * 150% values in the list generated by the subquery, then the system does not include the stock's SYMBOL and CURRENT_PRICE in the results table.
Another way to write the same query is
SELECT symbol, current_price FROM portfolio
WHERE current_price >= SOME
(SELECT closing_price * 1.5 FROM price_history
WHERE price_history.symbol = portfolio.symbol AND
price_history.date >= (GETDATE() - 180))
which reads: "List the stock SYMBOL and CURRENT_PRICE of each stock whose CURRENT_PRICE is 150 percent or more of some of the values in the list of CLOSING_PRICE values for the same stock the stock during the past 6 months (180 days)."
| |
Note |
Although the SQL-92 standard specifies the keyword SOME as an alternative to the keyword ANY, some DBMS products do not yet support the use of SOME. Check your system documentation. If your DBMS product lets you do so, use the keyword SOME in place of the keyword ANY because SOME is less confusing—unlike "any" it can never mean "all."
|
Using EXISTS Instead of COUN(*) to Check Whether a Subquery Returns at Least One Row
The COUNT(*) function, as its name implies, returns the count of the rows in a table that satisfy the search condition(s) in a WHERE clause. The EXISTS predicate, meanwhile, is a BOOLEAN expression that evaluates to TRUE if a subquery generates at least one row of query results. As such, the predicate
WHERE 0 < (SELECT COUNT(*) FROM
WHERE )
is equivalent to:
WHERE EXISTS (SELECT * FROM
WHERE )
When the subquery in the first WHERE clause returns no rows, its COUNT(*) function returns 0 and the WHERE clause evaluates to FALSE. Similarly, if an identical subquery used in the second WHERE clause returns no rows, EXISTS will (by definition) evaluate to FALSE, which will, in turn, cause the WHERE clause to evaluate to FALSE.
Conversely, if the subquery in the first WHERE clause returns one or more rows, its COUNT(*) function will return a value greater than 0, which, in turn, will cause the WHERE clause to evaluate to TRUE. Similarly, if an identical subquery used in the second WHERE clause returns one or more rows, EXISTS will (by definition) evaluate to TRUE; in turn, this will cause the WHERE clause to evaluate to TRUE.
Therefore, if you want a list of policy holders that have had a least one accident during the past year, you can use the COUNT(*) function in a query similar to:
SELECT cust_ID, f_name, l_name FROM customers
WHERE 0 < (SELECT COUNT(*) FROM claims
WHERE claims.date_of_claim >= (GETDATE() - 365)
AND claims.cust_ID = customers.cust_ID)
Or, you can use a similar query with an EXISTS predicate instead of the COUNT(*) > 0 comparison test:
SELECT cust_ID, f_name, l_name FROM customers
WHERE
EXISTS (SELECT * FROM claims
WHERE claims.date_of_claim >= (GETDATE() - 365)
AND claims.cust_ID = customers.cust_ID)
After you submit either query to the DBMS, the system goes through the CUSTOMERS table one row at a time and executes the subquery in the WHERE clause for each row in the CUSTOMERS table.
When executing the subquery in the first SELECT statement, the system counts the number of rows in the CLAIMS table that have both a DATE_OF_CLAIM within the past year and a CUST_ID column value matching the value in the CUST_ID column of the row from the CUSTOMERS table being processed. If the COUNT(*) function returns a value greater than 0, the WHERE clause evaluates to TRUE and the DBMS adds the customer's CUST_ID and name to the results table.
When processing the second SELECT statement, the DBMS can abort execution of the sub-query as soon as it finds the first row in the CLAIMS table that satisfies the search conditions in the subquery's WHERE clause. If the subquery returns any rows at all, the EXISTS predicate evaluates to TRUE and the system adds the customer's CUST_ID and name from the CUSTOMERS table to the query's results table.
So, should you use EXISTS or COUNT to determine whether at least one row in a table satisfies the search condition in the subquery's WHERE clause? The simple answer is: If you need the COUNT(*) of rows that satisfy the search criteria, use COUNT(*). Otherwise, use EXISTS.
Arguably, using EXISTS to check for the existence of a row that satisfies the WHERE clause search criteria makes the query easier to read than using the comparison of 0 < COUNT(*). Moreover, depending on the strength of the optimizer that your DBMS uses, EXISTS may actually execute faster than COUNT(*), especially if the table in the subquery has a lot of rows.
Remember, the purpose of the COUNT(*) function is to count the number of rows in a table that satisfy the search condition in the (sub)query's WHERE clause. As such, when you use COUNT(*) to check for the existence of at least one row that satisfies the WHERE clause search criteria, some DBMS products will read every row in the (sub)query's table, counting those that satisfy the search criteria in the WHERE clause. Only after it completes its (time-consuming) full-table scan does COUNT(*) return the number of rows that satisfy the WHERE clause search criteria. (If COUNT(*) returns a value of 0, then the WHERE clause evaluates FALSE, and vice versa.)
The EXISTS predicate, on the other hand, does not use any data values returned by the sub-query's SELECT * clause. Moreover, the DBMS does not care about the exact number of rows in the subquery's table that satisfy the search condition in its WHERE clause. As such, the DBMS can stop retrieving and filtering rows from the subquery's source table as soon as it finds the first row whose column values satisfy the search conditions in the subquery's WHERE clause.
In short EXISTS, may outperform the COUNT(*) function when used to determine whether at least one row satisfies the criteria in a subquery's WHERE clause. EXISTS needs to process only 2 rows in a 10,000,000-row table if the second row satisfies the search condition in the WHERE clause. The COUNT(*) function, on the other hand, must read all 10,000,000 rows and then compare the count of rows that satisfy the search condition(s) to 0.
Understanding Why the Expression NULL = NULL Evaluates to FALSE
As you learned in Tip 30, "Understanding the Value of NULL," the value of NULL is not 0. In fact, NULL really has no specific value because a NULL in a column (or expression) represents a missing or unknown quantity. Moreover, whenever an expression uses one of the six SQL comparison operators (=,<>,>,>=,<,<=) to compare a NULL value with any other value (including another NULL), the expression always evaluates to NULL.
For example, the results table for the query
SELECT * FROM customers
WHERE salesperson = NULL
will always have no rows because the expression in the WHERE clause will never evaluate to TRUE. (Because the WHERE clause search condition uses the equality (=) comparison operator to compare a NULL value to another value, the WHERE clause will always evaluate to NULL, not to TRUE.)
The WHERE clause in the current example evaluates to NULL even if the DBMS encounters a row from the CUSTOMERS table that has a NULL value in its SALESPERSON column. That's strange behavior, considering that the search condition in the WHERE clause becomes
NULL = NULL
when the value in the SALESPERSON column is NULL. However, because the values on both sides of the equals (=) sign are unknown, the system cannot tell whether one NULL (unknown) value is equal to the other. As such, the expression
NULL = NULL
evaluates neither to TRUE nor to FALSE, but to NULL.
| |
Note |
To query a table for rows with a NULL value in a specific column, you must use the IS NULL value test that you learned about in Tip 97, "Understanding NULL Value Conditions When Selecting Rows Using Comparison Predicates." For example, to get a list of CUSTOMERS table rows with a NULL in the SALESPERSON column, rewrite the query in the current example as:
SELECT * FROM customers
WHERE salesperson IS NULL
|
Understanding When to Use the ON Clause and When to Use the WHERE Clause
An ON clause is always used as a filter for one of the JOIN clauses that you learned about in Tips 300-305. A WHERE clause, meanwhile, is used to filter unwanted rows returned by both single-table and multi-table queries. Therefore, an ON clause (if present) must always follow a JOIN clause. A WHERE clause, on the other hand, can be used in both queries with a JOIN clause and those without.
The ON clause in an INNER JOIN query is functionally equivalent to a WHERE clause with an identical search condition. Therefore, if you want to generate a results table listing the name of each instructor (from a TEACHERS table) next to the description of the class(es) (from the CLASSES table) that each professor teaches, this INNER JOIN (with an ON clause)
SELECT course_ID, description,
RTRIM(f_name)+' '+l_name AS Instructor
FROM classes JOIN teachers
ON classes.professor_ID = teachers.PID
and this multi-table SELECT statement (with a WHERE clause)
SELECT course_ID, description,
RTRIM(f_name)+' '+l_name AS Instructor
FROM classes, teachers
WHERE classes.professor_ID = teachers.PID
will produce the same results table.
Conversely, when executing one of the OUTER JOIN queries (LEFT, RIGHT, or FULL OUTER JOIN) using a WHERE clause with identical search conditions instead of an ON clause will not produce the same results table. In an OUTER JOIN, both the ON clause and the WHERE clause filter out rows that do not satisfy one or more of the search conditions in the WHERE clause. However, rows filtered out (that is, rejected) by a WHERE clause in an OUTER JOIN are not included in the results table. Meanwhile, the ON clause in an OUTER JOIN first filters out unwanted rows and then includes some or all of the rejected rows as NULL-valued columns in the results table.
For example, suppose that some professors in the TEACHERS table have not yet been assigned to teach a class. The LEFT OUTER JOIN (without a WHERE clause) shown in the top pane of the MS-SQL Server Query Analyzer window shown in Figure 318.1 will produce the results table shown in Figure 318.1's lower pane.
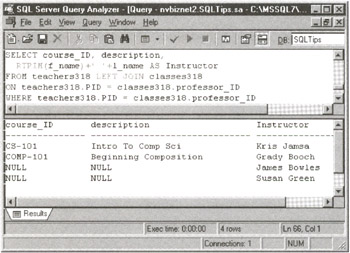
Figure 318.1: The MS-SQL Server Query Analyzer Window for a LEFT OUTER JOIN of two tables
Conversely, this LEFT OUTER JOIN (with a WHERE clause)
SELECT course_ID, description,
RTRIM(f_name)+' '+l_name AS Instructor
FROM teachers LEFT JOIN classes
ON teachers.PID = classes.professor_ID
WHERE teachers.PID = classes.professor_ID
will produce a results table similar to this:
course_ID description Instructor
--------- -------------------------------- -----------
CS-101 Introduction To Computer Science Kris Jamsa
COMP101 Beginning Composition Grady Booch
This results table has no NULL values in any of its columns.
Understanding How to Use Nested Queries to Work with Multiple Tables at Once
A subquery or nested query is a SELECT statement within another SQL statement. Although a nested query is always a SELECT statement, the enclosing SQL statement (which contains the nested SELECT statement (or subquery) may be a DELETE, an INSERT, an UPDATE, or another SELECT statement. In fact, a nested query may even be a subquery within another subquery.
Because the enclosing SQL statement and its subquery can each work on different tables, you can sometimes use a (single-table) query that contains a (single table) subquery in place of a (two-table) JOIN. For example, you can use a nested query instead of a JOIN to relate information in two tables when you want to include data values from only one of the tables in the query results. As an example, this nested query
SELECT CID AS 'Cust ID',
RTRIM(f_name)+' '+l_name AS 'Customer'
FROM customers
WHERE EXISTS (SELECT * FROM trades
WHERE trade_date >= GETDATE() - 365
AND cust_ID = CID
will list the names of all customers that made at least one stock trade during the past year.
Conversely, when you need to generate a results table with values from more than one table, you will often have to execute either a JOIN or a multi-table query with a WHERE clause. For example, you would use a query such as
SELECT trade_date, symbol, shares * price AS 'Total Trade',
CID, RTRIM(f_name)+' '+l_name AS 'Customer'
FROM customers JOIN trades
ON CID = cust_ID
WHERE shares * price > 100000
AND trade_date >= GETDATE() -365
ORDER BY Customer
to join rows from the CUSTOMERS table with rows from the TRADES table to generate a list of customer names and trade dollar values of any trades of $100,000 or more made within the past year.
Multi-table queries and nested subqueries are not, however, mutually exclusive. Suppose, for example, that you want to include aggregate totals such as a SUM() of the dollar amount and a COUNT() of the number of trades, along with the other information in the preceding example. A query such as
SELECT trade_date, symbol, shares * price AS 'Total Trade',
(SELECT COUNT(*) FROM trades
WHERE trade_date > GETDATE() - 365
AND cust_ID = CID) AS 'Count'
(SELECT SUM(price) * SUM(shares),
FROM trades
WHERE trades.trade_date >= GETDATE() - 365
AND cust_ID = CID) AS 'Total $ Volume),
CID AS 'Cust ID'-, TRIM(f_name)+' '+l_name AS 'Customer'
FROM customers JOIN trades
ON CID = cust_CID
WHERE shares * price >= 100000
AND trade_date >= GETDATE() -365
ORDER BY Customer
will execute the same two-table JOIN found in the preceding example. However, the query's results table includes the values returned by the two aggregate function subqueries (in the SELECT cause).
In short, a nested query works independent of the enclosing SQL statement and can make use of any of the column values from the tables listed in the enclosing statement's FROM clause. You can use nested queries to perform multi-table operations without having to JOIN rows in multiple related tables. However, if you need data values from multiple tables, or if you want individual column values and aggregate function values in the same row in the results table, you can nest a subquery with the aggregate function that you need in the SELECT clause of a multi-table query or JOIN.
Understanding SQL Subqueries
|
