Building an Efficient, Scalable Result Cache
Nearly every server application uses some form of caching. Reusing the results of a previous computation can reduce latency and increase throughput, at the cost of some additional memory usage.
Listing 5.15. Coordinating Computation in a Cellular Automaton with CyclicBarrier.
public class CellularAutomata {
private final Board mainBoard;
private final CyclicBarrier barrier;
private final Worker[] workers;
public CellularAutomata(Board board) {
this.mainBoard = board;
int count = Runtime.getRuntime().availableProcessors();
this.barrier = new CyclicBarrier(count,
new Runnable() {
public void run() {
mainBoard.commitNewValues();
}});
this.workers = new Worker[count];
for (int i = 0; i < count; i++)
workers[i] = new Worker(mainBoard.getSubBoard(count, i));
}
private class Worker implements Runnable {
private final Board board;
public Worker(Board board) { this.board = board; }
public void run() {
while (!board.hasConverged()) {
for (int x = 0; x < board.getMaxX(); x++)
for (int y = 0; y < board.getMaxY(); y++)
board.setNewValue(x, y, computeValue(x, y));
try {
barrier.await();
} catch (InterruptedException ex) {
return;
} catch (BrokenBarrierException ex) {
return;
}
}
}
}
public void start() {
for (int i = 0; i < workers.length; i++)
new Thread(workers[i]).start();
mainBoard.waitForConvergence();}
}
}
|
Like many other frequently reinvented wheels, caching often looks simpler than it is. A naive cache implementation is likely to turn a performance bottleneck into a scalability bottleneck, even if it does improve single-threaded performance. In this section we develop an efficient and scalable result cache for a computationally expensive function. Let's start with the obvious approacha simple HashMapand then look at some of its concurrency disadvantages and how to fix them.
The Computable interface in Listing 5.16 describes a function with input of type A and result of type V. ExpensiveFunction, which implements Computable, takes a long time to compute its result; we'd like to create a Computable wrapper that remembers the results of previous computations and encapsulates the caching process. (This technique is known as memoization.)
Listing 5.16. Initial Cache Attempt Using HashMap and Synchronization.

public interface Computable {
V compute(A arg) throws InterruptedException;
}
public class ExpensiveFunction
implements Computable {
public BigInteger compute(String arg) {
// after deep thought...
return new BigInteger(arg);
}
}
public class Memoizer1 implements Computable {
@GuardedBy("this")
private final Map cache = new HashMap();
private final Computable c;
public Memoizer1(Computable c) {
this.c = c;
}
public synchronized V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if (result == null) {
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}
|
Memoizer1 in Listing 5.16 shows a first attempt: using a HashMap to store the results of previous computations. The compute method first checks whether the desired result is already cached, and returns the precomputed value if it is. Otherwise, the result is computed and cached in the HashMap before returning.
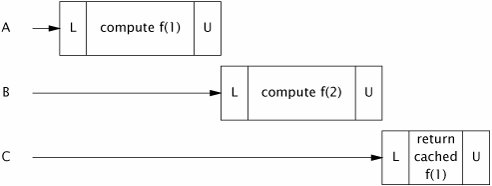
HashMap is not thread-safe, so to ensure that two threads do not access the HashMap at the same time, Memoizer1 takes the conservative approach of synchronizing the entire compute method. This ensures thread safety but has an obvious scalability problem: only one thread at a time can execute compute at all. If another thread is busy computing a result, other threads calling compute may be blocked for a long time. If multiple threads are queued up waiting to compute values not already computed, compute may actually take longer than it would have without memoization. Figure 5.2 illustrates what could happen when several threads attempt to use a function memoized with this approach. This is not the sort of performance improvement we had hoped to achieve through caching.
Figure 5.2. Poor Concurrency of Memoizer1.
Memoizer2 in Listing 5.17 improves on the awful concurrent behavior of Memoizer1 by replacing the HashMap with a ConcurrentHashMap. Since ConcurrentHashMap is thread-safe, there is no need to synchronize when accessing the backing Map, thus eliminating the serialization induced by synchronizing compute in Memoizer1.
Memoizer2 certainly has better concurrent behavior than Memoizer1: multiple threads can actually use it concurrently. But it still has some defects as a cachethere is a window of vulnerability in which two threads calling compute at the same time could end up computing the same value. In the case of memoization, this is merely inefficientthe purpose of a cache is to prevent the same data from being calculated multiple times. For a more general-purpose caching mechanism, it is far worse; for an object cache that is supposed to provide once-and-only-once initialization, this vulnerability would also pose a safety risk.
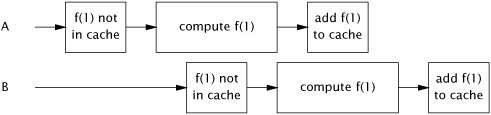
The problem with Memoizer2 is that if one thread starts an expensive computation, other threads are not aware that the computation is in progress and so may start the same computation, as illustrated in Figure 5.3. We'd like to somehow represent the notion that "thread X is currently computing f (27)", so that if another thread arrives looking for f (27), it knows that the most efficient way to find it is to head over to Thread X's house, hang out there until X is finished, and then ask "Hey, what did you get for f (27)?"
Figure 5.3. Two Threads Computing the Same Value When Using Memoizer2.
Listing 5.17. Replacing HashMap with ConcurrentHashMap.
public class Memoizer2 implements Computable {
private final Map cache = new ConcurrentHashMap();
private final Computable c;
public Memoizer2(Computable c) { this.c = c; }
public V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if (result == null) {
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}
|
We've already seen a class that does almost exactly this: FutureTask. FutureTask represents a computational process that may or may not already have completed. FutureTask.get returns the result of the computation immediately if it is available; otherwise it blocks until the result has been computed and then returns it.
Memoizer3 in Listing 5.18 redefines the backing Map for the value cache as a ConcurrentHashMap> instead of a ConcurrentHashMap. Memoizer3 first checks to see if the appropriate calculation has been started (as opposed to finished, as in Memoizer2). If not, it creates a FutureTask, registers it in the Map, and starts the computation; otherwise it waits for the result of the existing computation. The result might be available immediately or might be in the process of being computedbut this is transparent to the caller of Future.get.
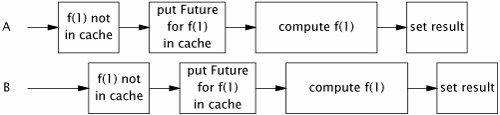
The Memoizer3 implementation is almost perfect: it exhibits very good concurrency (mostly derived from the excellent concurrency of ConcurrentHashMap), the result is returned efficiently if it is already known, and if the computation is in progress by another thread, newly arriving threads wait patiently for the result. It has only one defectthere is still a small window of vulnerability in which two threads might compute the same value. This window is far smaller than in Memoizer2, but because the if block in compute is still a nonatomic check-thenact sequence, it is possible for two threads to call compute with the same value at roughly the same time, both see that the cache does not contain the desired value, and both start the computation. This unlucky timing is illustrated in Figure 5.4.
Figure 5.4. Unlucky Timing that could Cause Memoizer3 to Calculate the Same Value Twice.
Listing 5.18. Memoizing Wrapper Using FutureTask.
public class Memoizer3 implements Computable {
private final Map> cache
= new ConcurrentHashMap>();
private final Computable c;
public Memoizer3(Computable c) { this.c = c; }
public V compute(final A arg) throws InterruptedException {
Future f = cache.get(arg);
if (f == null) {
Callable eval = new Callable() {
public V call() throws InterruptedException {
return c.compute(arg);
}
};
FutureTask ft = new FutureTask(eval);
f = ft;
cache.put(arg, ft);
ft.run(); // call to c.compute happens here
}
try {
return f.get();
} catch (ExecutionException e) {
throw launderThrowable(e.getCause());
}
}
}
|
Memoizer3 is vulnerable to this problem because a compound action (put-if-absent) is performed on the backing map that cannot be made atomic using locking. Memoizer in Listing 5.19 takes advantage of the atomic putIfAbsent method of ConcurrentMap, closing the window of vulnerability in Memoizer3.
Caching a Future instead of a value creates the possibility of cache pollution: if a computation is cancelled or fails, future attempts to compute the result will also indicate cancellation or failure. To avoid this, Memoizer removes the Future from the cache if it detects that the computation was cancelled; it might also be desirable to remove the Future upon detecting a RuntimeException if the computation might succeed on a future attempt. Memoizer also does not address cache expiration, but this could be accomplished by using a subclass of FutureTask that associates an expiration time with each result and periodically scanning the cache for expired entries. (Similarly, it does not address cache eviction, where old entries are removed to make room for new ones so that the cache does not consume too much memory.)
With our concurrent cache implementation complete, we can now add real caching to the factorizing servlet from Chapter 2, as promised. Factorizer in Listing 5.20 uses Memoizer to cache previously computed values efficiently and scalably.
Listing 5.19. Final Implementation of Memoizer.
public class Memoizer implements Computable {
private final ConcurrentMap> cache
= new ConcurrentHashMap>();
private final Computable c;
public Memoizer(Computable c) { this.c = c; }
public V compute(final A arg) throws InterruptedException {
while (true) {
Future f = cache.get(arg);
if (f == null) {
Callable eval = new Callable() {
public V call() throws InterruptedException {
return c.compute(arg);
}
};
FutureTask ft = new FutureTask(eval);
f = cache.putIfAbsent(arg, ft);
if (f == null) { f = ft; ft.run(); }
}
try {
return f.get();
} catch (CancellationException e) {
cache.remove(arg, f);
} catch (ExecutionException e) {
throw launderThrowable(e.getCause());
}
}
}
}
|
Listing 5.20. Factorizing Servlet that Caches Results Using Memoizer.
@ThreadSafe
public class Factorizer implements Servlet {
private final Computable c =
new Computable() {
public BigInteger[] compute(BigInteger arg) {
return factor(arg);
}
};
private final Computable cache
= new Memoizer(c);
public void service(ServletRequest req,
ServletResponse resp) {
try {
BigInteger i = extractFromRequest(req);
encodeIntoResponse(resp, cache.compute(i));
} catch (InterruptedException e) {
encodeError(resp, "factorization interrupted");
}
}
}
|
Introduction
- Introduction
- A (Very) Brief History of Concurrency
- Benefits of Threads
- Risks of Threads
- Threads are Everywhere
Part I: Fundamentals
Thread Safety
- Thread Safety
- What is Thread Safety?
- Atomicity
- Locking
- Guarding State with Locks
- Liveness and Performance
Sharing Objects
Composing Objects
- Composing Objects
- Designing a Thread-safe Class
- Instance Confinement
- Delegating Thread Safety
- Adding Functionality to Existing Thread-safe Classes
- Documenting Synchronization Policies
Building Blocks
- Building Blocks
- Synchronized Collections
- Concurrent Collections
- Blocking Queues and the Producer-consumer Pattern
- Blocking and Interruptible Methods
- Synchronizers
- Building an Efficient, Scalable Result Cache
- Summary of Part I
Part II: Structuring Concurrent Applications
Task Execution
- Task Execution
- Executing Tasks in Threads
- The Executor Framework
- Finding Exploitable Parallelism
- Summary
Cancellation and Shutdown
- Cancellation and Shutdown
- Task Cancellation
- Stopping a Thread-based Service
- Handling Abnormal Thread Termination
- JVM Shutdown
- Summary
Applying Thread Pools
- Applying Thread Pools
- Implicit Couplings Between Tasks and Execution Policies
- Sizing Thread Pools
- Configuring ThreadPoolExecutor
- Extending ThreadPoolExecutor
- Parallelizing Recursive Algorithms
- Summary
GUI Applications
- GUI Applications
- Why are GUIs Single-threaded?
- Short-running GUI Tasks
- Long-running GUI Tasks
- Shared Data Models
- Other Forms of Single-threaded Subsystems
- Summary
Part III: Liveness, Performance, and Testing
Avoiding Liveness Hazards
Performance and Scalability
- Performance and Scalability
- Thinking about Performance
- Amdahls Law
- Costs Introduced by Threads
- Reducing Lock Contention
- Example: Comparing Map Performance
- Reducing Context Switch Overhead
- Summary
Testing Concurrent Programs
- Testing Concurrent Programs
- Testing for Correctness
- Testing for Performance
- Avoiding Performance Testing Pitfalls
- Complementary Testing Approaches
- Summary
Part IV: Advanced Topics
Explicit Locks
- Explicit Locks
- Lock and ReentrantLock
- Performance Considerations
- Fairness
- Choosing Between Synchronized and ReentrantLock
- Read-write Locks
- Summary
Building Custom Synchronizers
- Building Custom Synchronizers
- Managing State Dependence
- Using Condition Queues
- Explicit Condition Objects
- Anatomy of a Synchronizer
- AbstractQueuedSynchronizer
- AQS in Java.util.concurrent Synchronizer Classes
- Summary
Atomic Variables and Nonblocking Synchronization
- Atomic Variables and Nonblocking Synchronization
- Disadvantages of Locking
- Hardware Support for Concurrency
- Atomic Variable Classes
- Nonblocking Algorithms
- Summary
The Java Memory Model
EAN: 2147483647
Pages: 141
- Key #3: Work Together for Maximum Gain
- Beyond the Basics: The Five Laws of Lean Six Sigma
- Making Improvements That Last: An Illustrated Guide to DMAIC and the Lean Six Sigma Toolkit
- The Experience of Making Improvements: What Its Like to Work on Lean Six Sigma Projects
- Six Things Managers Must Do: How to Support Lean Six Sigma
