Fairness
The ReentrantLock constructor offers a choice of two fairness options: create a nonfair lock (the default) or a fair lock. Threads acquire a fair lock in the order in which they requested it, whereas a nonfair lock permits barging: threads requesting a lock can jump ahead of the queue of waiting threads if the lock happens to be available when it is requested. (Semaphore also offers the choice of fair or nonfair acquisition ordering.) Nonfair ReentrantLocks do not go out of their way to promote bargingthey simply don't prevent a thread from barging if it shows up at the right time. With a fair lock, a newly requesting thread is queued if the lock is held by another thread or if threads are queued waiting for the lock; with a nonfair lock, the thread is queued only if the lock is currently held.[4]
[4] The polled tryLock always barges, even for fair locks.
Wouldn't we want all locks to be fair? After all, fairness is good and unfairness is bad, right? (Just ask your kids.) When it comes to locking, though, fairness has a significant performance cost because of the overhead of suspending and resuming threads. In practice, a statistical fairness guaranteepromising that a blocked thread will eventually acquire the lockis often good enough, and is far less expensive to deliver. Some algorithms rely on fair queueing to ensure their correctness, but these are unusual. In most cases, the performance benefits of nonfair locks outweigh the benefits of fair queueing.
Figure 13.2 shows another run of the Map performance test, this time comparing HashMap wrapped with fair and nonfair ReentrantLocks on a four-way Opteron system running Solaris, plotted on a log scale.[5] The fairness penalty is nearly two orders of magnitude. Don't pay for fairness if you don't need it.
[5] The graph for ConcurrentHashMap is fairly wiggly in the region between four and eight threads. These variations almost certainly come from measurement noise, which could be introduced by coincidental interactions with the hash codes of the elements, thread scheduling, map resizing, garbage collection or other memory-system effects, or by the OS deciding to run some periodic housekeeping task around the time that test case ran. The reality is that there are all sorts of variations in performance tests that usually aren't worth bothering to control. We made no attempt to clean up our graphs artificially, because real-world performance measurements are also full of noise.
Figure 13.2. Fair Versus Nonfair Lock Performance.
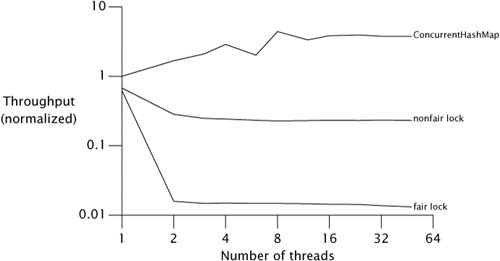
One reason barging locks perform so much better than fair locks under heavy contention is that there can be a significant delay between when a suspended thread is resumed and when it actually runs. Let's say thread A holds a lock and thread B asks for that lock. Since the lock is busy, B is suspended. When A releases the lock, B is resumed so it can try again. In the meantime, though, if thread C requests the lock, there is a good chance that C can acquire the lock, use it, and release it before B even finishes waking up. In this case, everyone wins: B gets the lock no later than it otherwise would have, C gets it much earlier, and throughput is improved.
Fair locks tend to work best when they are held for a relatively long time or when the mean time between lock requests is relatively long. In these cases, the condition under which barging provides a throughput advantagewhen the lock is unheld but a thread is currently waking up to claim itis less likely to hold.
Like the default ReentrantLock, intrinsic locking offers no deterministic fairness guarantees, but the statistical fairness guarantees of most locking implementations are good enough for almost all situations. The language specification does not require the JVM to implement intrinsic locks fairly, and no production JVMs do. ReentrantLock does not depress lock fairness to new lowsit only makes explicit something that was present all along.
Choosing Between Synchronized and ReentrantLock |
Introduction
- Introduction
- A (Very) Brief History of Concurrency
- Benefits of Threads
- Risks of Threads
- Threads are Everywhere
Part I: Fundamentals
Thread Safety
- Thread Safety
- What is Thread Safety?
- Atomicity
- Locking
- Guarding State with Locks
- Liveness and Performance
Sharing Objects
Composing Objects
- Composing Objects
- Designing a Thread-safe Class
- Instance Confinement
- Delegating Thread Safety
- Adding Functionality to Existing Thread-safe Classes
- Documenting Synchronization Policies
Building Blocks
- Building Blocks
- Synchronized Collections
- Concurrent Collections
- Blocking Queues and the Producer-consumer Pattern
- Blocking and Interruptible Methods
- Synchronizers
- Building an Efficient, Scalable Result Cache
- Summary of Part I
Part II: Structuring Concurrent Applications
Task Execution
- Task Execution
- Executing Tasks in Threads
- The Executor Framework
- Finding Exploitable Parallelism
- Summary
Cancellation and Shutdown
- Cancellation and Shutdown
- Task Cancellation
- Stopping a Thread-based Service
- Handling Abnormal Thread Termination
- JVM Shutdown
- Summary
Applying Thread Pools
- Applying Thread Pools
- Implicit Couplings Between Tasks and Execution Policies
- Sizing Thread Pools
- Configuring ThreadPoolExecutor
- Extending ThreadPoolExecutor
- Parallelizing Recursive Algorithms
- Summary
GUI Applications
- GUI Applications
- Why are GUIs Single-threaded?
- Short-running GUI Tasks
- Long-running GUI Tasks
- Shared Data Models
- Other Forms of Single-threaded Subsystems
- Summary
Part III: Liveness, Performance, and Testing
Avoiding Liveness Hazards
Performance and Scalability
- Performance and Scalability
- Thinking about Performance
- Amdahls Law
- Costs Introduced by Threads
- Reducing Lock Contention
- Example: Comparing Map Performance
- Reducing Context Switch Overhead
- Summary
Testing Concurrent Programs
- Testing Concurrent Programs
- Testing for Correctness
- Testing for Performance
- Avoiding Performance Testing Pitfalls
- Complementary Testing Approaches
- Summary
Part IV: Advanced Topics
Explicit Locks
- Explicit Locks
- Lock and ReentrantLock
- Performance Considerations
- Fairness
- Choosing Between Synchronized and ReentrantLock
- Read-write Locks
- Summary
Building Custom Synchronizers
- Building Custom Synchronizers
- Managing State Dependence
- Using Condition Queues
- Explicit Condition Objects
- Anatomy of a Synchronizer
- AbstractQueuedSynchronizer
- AQS in Java.util.concurrent Synchronizer Classes
- Summary
Atomic Variables and Nonblocking Synchronization
- Atomic Variables and Nonblocking Synchronization
- Disadvantages of Locking
- Hardware Support for Concurrency
- Atomic Variable Classes
- Nonblocking Algorithms
- Summary
The Java Memory Model
EAN: 2147483647
Pages: 141
