Amdahls Law
Amdahl s Law
Some problems can be solved faster with more resourcesthe more workers available for harvesting crops, the faster the harvest can be completed. Other tasks are fundamentally serialno number of additional workers will make the crops grow any faster. If one of our primary reasons for using threads is to harness the power of multiple processors, we must also ensure that the problem is amenable to parallel decomposition and that our program effectively exploits this potential for parallelization.
Most concurrent programs have a lot in common with farming, consisting of a mix of parallelizable and serial portions. Amdahl's law describes how much a program can theoretically be sped up by additional computing resources, based on the proportion of parallelizable and serial components. If F is the fraction of the calculation that must be executed serially, then Amdahl's law says that on a machine with N processors, we can achieve a speedup of at most:
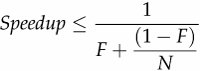
As N approaches infinity, the maximum speedup converges to 1/F, meaning that a program in which fifty percent of the processing must be executed serially can be sped up only by a factor of two, regardless of how many processors are available, and a program in which ten percent must be executed serially can be sped up by at most a factor of ten. Amdahl's law also quantifies the efficiency cost of serialization. With ten processors, a program with 10%serialization can achieve at most a speedup of 5.3 (at 53% utilization), and with 100 processors it can achieve at most a speedup of 9.2 (at 9% utilization). It takes a lot of inefficiently utilized CPUs to never get to that factor of ten.
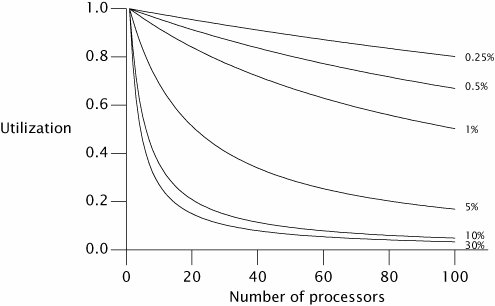
Figure 11.1 shows the maximum possible processor utilization for varying degrees of serial execution and numbers of processors. (Utilization is defined as the speedup divided by the number of processors.) It is clear that as processor counts increase, even a small percentage of serialized execution limits how much throughput can be increased with additional computing resources.
Figure 11.1. Maximum Utilization Under Amdahl's Law for Various Serialization Percentages.
Chapter 6 explored identifying logical boundaries for decomposing applications into tasks. But in order to predict what kind of speedup is possible from running your application on a multiprocessor system, you also need to identify the sources of serialization in your tasks.
Imagine an application where N threads execute doWork in Listing 11.1, fetching tasks from a shared work queue and processing them; assume that tasks do not depend on the results or side effects of other tasks. Ignoring for a moment how the tasks get onto the queue, how well will this application scale as we add processors? At first glance, it may appear that the application is completely parallelizable: tasks do not wait for each other, and the more processors available, the more tasks can be processed concurrently. However, there is a serial component as wellfetching the task from the work queue. The work queue is shared by all the worker threads, and it will require some amount of synchronization to maintain its integrity in the face of concurrent access. If locking is used to guard the state of the queue, then while one thread is dequeing a task, other threads that need to dequeue their next task must waitand this is where task processing is serialized.
The processing time of a single task includes not only the time to execute the task Runnable, but also the time to dequeue the task from the shared work queue. If the work queue is a LinkedBlockingQueue, the dequeue operation may block less than with a synchronized LinkedList because LinkedBlockingQueue uses a more scalable algorithm, but accessing any shared data structure fundamentally introduces an element of serialization into a program.
This example also ignores another common source of serialization: result handling. All useful computations produce some sort of result or side effectif not, they can be eliminated as dead code. Since Runnable provides for no explicit result handling, these tasks must have some sort of side effect, say writing their results to a log file or putting them in a data structure. Log files and result containers are usually shared by multiple worker threads and therefore are also a source of serialization. If instead each thread maintains its own data structure for results that are merged after all the tasks are performed, then the final merge is a source of serialization.
Listing 11.1. Serialized Access to a Task Queue.
public class WorkerThread extends Thread {
private final BlockingQueue queue;
public WorkerThread(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
while (true) {
try {
Runnable task = queue.take();
task.run();
} catch (InterruptedException e) {
break; /* Allow thread to exit */
}
}
}
}
|
|
All concurrent applications have some sources of serialization; if you think yours does not, look again. |
11.2.1. Example: Serialization Hidden in Frameworks
To see how serialization can be hidden in the structure of an application, we can compare throughput as threads are added and infer differences in serialization based on observed differences in scalability. Figure 11.2 shows a simple application in which multiple threads repeatedly remove an element from a shared Queue and process it, similar to Listing 11.1. The processing step involves only thread-local computation. If a thread finds the queue is empty, it puts a batch of new elements on the queue so that other threads have something to process on their next iteration. Accessing the shared queue clearly entails some degree of serialization, but the processing step is entirely parallelizable since it involves no shared data.
Figure 11.2. Comparing Queue Implementations.
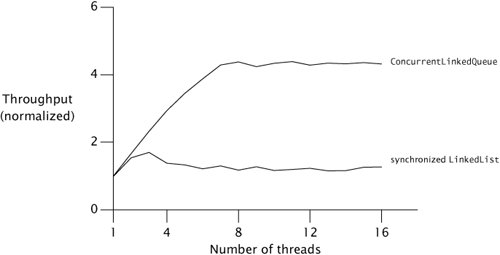
The curves in Figure 11.2 compare throughput for two thread-safe Queue implementations: a LinkedList wrapped with synchronizedList, and a ConcurrentLinkedQueue. The tests were run on an 8-way Sparc V880 system running Solaris. While each run represents the same amount of "work", we can see that merely changing queue implementations can have a big impact on scalability.
The throughput of ConcurrentLinkedQueue continues to improve until it hits the number of processors and then remains mostly constant. On the other hand, the throughput of the synchronized LinkedList shows some improvement up to three threads, but then falls off as synchronization overhead increases. By the time it gets to four or five threads, contention is so heavy that every access to the queue lock is contended and throughput is dominated by context switching.
The difference in throughput comes from differing degrees of serialization between the two queue implementations. The synchronized LinkedList guards the entire queue state with a single lock that is held for the duration of the offer or remove call; ConcurrentLinkedQueue uses a sophisticated nonblocking queue algorithm (see Section 15.4.2) that uses atomic references to update individual link pointers. In one, the entire insertion or removal is serialized; in the other, only updates to individual pointers are serialized.
11.2.2. Applying Amdahl's Law Qualitatively
Amdahl's law quantifies the possible speedup when more computing resources are available, if we can accurately estimate the fraction of execution that is serialized. Although measuring serialization directly can be difficult, Amdahl's law can still be useful without such measurement.
Since our mental models are influenced by our environment, many of us are used to thinking that a multiprocessor system has two or four processors, or maybe (if we've got a big budget) as many as a few dozen, because this is the technology that has been widely available in recent years. But as multicore CPUs become mainstream, systems will have hundreds or even thousands of processors. [3] Algorithms that seem scalable on a four-way system may have hidden scalability bottlenecks that have just not yet been encountered.
[3] Market update: at this writing, Sun is shipping low-end server systems based on the 8-core Niagara processor, and Azul is shipping high-end server systems (96, 192, and 384-way) based on the 24-core Vega processor.
When evaluating an algorithm, thinking "in the limit" about what would happen with hundreds or thousands of processors can offer some insight into where scaling limits might appear. For example, Sections 11.4.2 and 11.4.3 discuss two techniques for reducing lock granularity: lock splitting (splitting one lock into two) and lock striping (splitting one lock into many). Looking at them through the lens of Amdahl's law, we see that splitting a lock in two does not get us very far towards exploiting many processors, but lock striping seems much more promising because the size of the stripe set can be increased as processor count increases. (Of course, performance optimizations should always be considered in light of actual performance requirements; in some cases, splitting a lock in two may be enough to meet the requirements.)
Introduction
- Introduction
- A (Very) Brief History of Concurrency
- Benefits of Threads
- Risks of Threads
- Threads are Everywhere
Part I: Fundamentals
Thread Safety
- Thread Safety
- What is Thread Safety?
- Atomicity
- Locking
- Guarding State with Locks
- Liveness and Performance
Sharing Objects
Composing Objects
- Composing Objects
- Designing a Thread-safe Class
- Instance Confinement
- Delegating Thread Safety
- Adding Functionality to Existing Thread-safe Classes
- Documenting Synchronization Policies
Building Blocks
- Building Blocks
- Synchronized Collections
- Concurrent Collections
- Blocking Queues and the Producer-consumer Pattern
- Blocking and Interruptible Methods
- Synchronizers
- Building an Efficient, Scalable Result Cache
- Summary of Part I
Part II: Structuring Concurrent Applications
Task Execution
- Task Execution
- Executing Tasks in Threads
- The Executor Framework
- Finding Exploitable Parallelism
- Summary
Cancellation and Shutdown
- Cancellation and Shutdown
- Task Cancellation
- Stopping a Thread-based Service
- Handling Abnormal Thread Termination
- JVM Shutdown
- Summary
Applying Thread Pools
- Applying Thread Pools
- Implicit Couplings Between Tasks and Execution Policies
- Sizing Thread Pools
- Configuring ThreadPoolExecutor
- Extending ThreadPoolExecutor
- Parallelizing Recursive Algorithms
- Summary
GUI Applications
- GUI Applications
- Why are GUIs Single-threaded?
- Short-running GUI Tasks
- Long-running GUI Tasks
- Shared Data Models
- Other Forms of Single-threaded Subsystems
- Summary
Part III: Liveness, Performance, and Testing
Avoiding Liveness Hazards
Performance and Scalability
- Performance and Scalability
- Thinking about Performance
- Amdahls Law
- Costs Introduced by Threads
- Reducing Lock Contention
- Example: Comparing Map Performance
- Reducing Context Switch Overhead
- Summary
Testing Concurrent Programs
- Testing Concurrent Programs
- Testing for Correctness
- Testing for Performance
- Avoiding Performance Testing Pitfalls
- Complementary Testing Approaches
- Summary
Part IV: Advanced Topics
Explicit Locks
- Explicit Locks
- Lock and ReentrantLock
- Performance Considerations
- Fairness
- Choosing Between Synchronized and ReentrantLock
- Read-write Locks
- Summary
Building Custom Synchronizers
- Building Custom Synchronizers
- Managing State Dependence
- Using Condition Queues
- Explicit Condition Objects
- Anatomy of a Synchronizer
- AbstractQueuedSynchronizer
- AQS in Java.util.concurrent Synchronizer Classes
- Summary
Atomic Variables and Nonblocking Synchronization
- Atomic Variables and Nonblocking Synchronization
- Disadvantages of Locking
- Hardware Support for Concurrency
- Atomic Variable Classes
- Nonblocking Algorithms
- Summary
The Java Memory Model
EAN: 2147483647
Pages: 141
