The Unicode Character Set
The Unicode character set maps characters to integer code points. For instance, the Latin letter A is assigned the code point 65. The Greek letter S is assigned the code point 931. The musical symbol 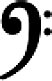 is assigned the code point 119,074. Unicode has room for over one million characters, which is enough to hold every character from all the world's scripts. The current version of Unicode (4.1) defines 97,655 different characters from many languages, including English, Russian, Arabic, Hebrew, Greek, Korean, Chinese, Japanese, and Sanskrit.
is assigned the code point 119,074. Unicode has room for over one million characters, which is enough to hold every character from all the world's scripts. The current version of Unicode (4.1) defines 97,655 different characters from many languages, including English, Russian, Arabic, Hebrew, Greek, Korean, Chinese, Japanese, and Sanskrit.
The first 128 Unicode characters (characters 0 through 127) are identical to the ASCII character set. The ASCII space is 32; therefore, 32 is the Unicode space. The ASCII exclamation point is 33, so 33 is the Unicode exclamation point, and so on. Table A-1 in Appendix A shows this character set. The next 128 Unicode characters (characters 128 through 255) have the same values as the equivalent characters in the Latin-1 character set defined by ISO standard 8859-1. Latin-1, a slight variation of which is used by Windows, adds the various accented characters, umlauts, cedillas, upside-down question marks, and other characters needed to write text in most Western European languages. Table A-2 shows these characters. The first 128 characters in Latin-1 are identical to the ASCII character set.
Unicode is divided into blocks. For example, characters 0 through 127 are the Basic Latin block and contain ASCII. Characters 128 through 255 are the Latin Extended-A block and contain the upper 128 characters of the Latin-1 character set. Characters 9984 through 10,175 are the Dingbats block and contain the characters in the popular Zapf Dingbats font. Characters 19,968 through 40,959 are the unified Chinese-Japanese-Korean ideograph block.
|

Although internally Java can handle full Unicode data (code points are just numbers, after all), not all Java environments can display all Unicode characters. The biggest problem is the lack of fonts. Few computers have fonts for all the scripts Java supports. Even computers that possess the necessary fonts can't install a lot of them because of their size. A normal, 8-bit outline font ranges from about 3060K. A Unicode font that omits the Han ideographs will be about 10 times that size. A Unicode font that includes the full range of Han ideographs will occupy between 5 and 7 MB. Furthermore, text display algorithms based on English often break down when faced with right-to-left languages like Hebrew and Arabic, vertical languages like the traditional Chinese used in Taiwan, or context-sensitive languages like Arabic.
Basic I/O
Introducing I/O
- Introducing I/O
- What Is a Stream?
- Numeric Data
- Character Data
- Readers and Writers
- Buffers and Channels
- The Ubiquitous IOException
- The Console: System.out, System.in, and System.err
- Security Checks on I/O
Output Streams
- Output Streams
- Writing Bytes to Output Streams
- Writing Arrays of Bytes
- Closing Output Streams
- Flushing Output Streams
- Subclassing OutputStream
- A Graphical User Interface for Output Streams
Input Streams
- Input Streams
- The read( ) Method
- Reading Chunks of Data from a Stream
- Counting the Available Bytes
- Skipping Bytes
- Closing Input Streams
- Marking and Resetting
- Subclassing InputStream
- An Efficient Stream Copier
Data Sources
File Streams
Network Streams
Filter Streams
Filter Streams
- Filter Streams
- The Filter Stream Classes
- The Filter Stream Subclasses
- Buffered Streams
- PushbackInputStream
- ProgressMonitorInputStream
- Multitarget Output Streams
- File Viewer, Part 2
Print Streams
Data Streams
- Data Streams
- The Data Stream Classes
- Integers
- Floating-Point Numbers
- Booleans
- Byte Arrays
- Strings and chars
- Little-Endian Numbers
- Thread Safety
- File Viewer, Part 3
Streams in Memory
- Streams in Memory
- Sequence Input Streams
- Byte Array Streams
- Communicating Between Threads Using Piped Streams
Compressing Streams
- Compressing Streams
- Inflaters and Deflaters
- Compressing and Decompressing Streams
- Zip Files
- Checksums
- File Viewer, Part 4
JAR Archives
- JAR Archives
- Meta-Information: Manifest Files and Signatures
- The jar Tool
- The java.util.jar Package
- JarFile
- JarEntry
- Attributes
- Manifest
- JarInputStream
- JarOutputStream
- JarURLConnection
- Pack200
- Reading Resources from JAR Files
Cryptographic Streams
- Cryptographic Streams
- Hash Functions
- The MessageDigest Class
- Digest Streams
- Encryption Basics
- The Cipher Class
- Cipher Streams
- File Viewer, Part 5
Object Serialization
- Object Serialization
- Reading and Writing Objects
- Object Streams
- How Object Serialization Works
- Performance
- The Serializable Interface
- Versioning
- Customizing the Serialization Format
- Resolving Classes
- Resolving Objects
- Validation
- Sealed Objects
- JavaDoc
New I/O
Buffers
- Buffers
- Copying Files with Buffers
- Creating Buffers
- Buffer Layout
- Bulk Put and Get
- Absolute Put and Get
- Mark and Reset
- Compaction
- Duplication
- Slicing
- Typed Data
- Read-Only Buffers
- CharBuffers
- Memory-Mapped I/O
Channels
- Channels
- The Channel Interfaces
- File Channels
- Converting Between Streams and Channels
- Socket Channels
- Server Socket Channels
- Datagram Channels
Nonblocking I/O
The File System
Working with Files
- Working with Files
- Understanding Files
- Directories and Paths
- The File Class
- Filename Filters
- File Filters
- File Descriptors
- Random-Access Files
- General Techniques for Cross-Platform File Access Code
File Dialogs and Choosers
Text
Character Sets and Unicode
- Character Sets and Unicode
- The Unicode Character Set
- UTF-16
- UTF-8
- Other Encodings
- Converting Between Byte Arrays and Strings
Readers and Writers
- Readers and Writers
- The java.io.Writer Class
- The OutputStreamWriter Class
- The java.io.Reader Class
- The InputStreamReader Class
- Encoding Heuristics
- Character Array Readers and Writers
- String Readers and Writers
- Reading and Writing Files
- Buffered Readers and Writers
- Print Writers
- Piped Readers and Writers
- Filtered Readers and Writers
- File Viewer Finis
Formatted I/O with java.text
- Formatted I/O with java.text
- The Old Way
- Choosing a Locale
- Number Formats
- Specifying Width with FieldPosition
- Parsing Input
- Decimal Formats
Devices
The Java Communications API
- The Java Communications API
- The Architecture of the Java Communications API
- Identifying Ports
- Communicating with a Device on a Port
- Serial Ports
- Parallel Ports
USB
- USB
- USB Architecture
- Finding Devices
- Controlling Devices
- Describing Devices
- Pipes
- IRPs
- Temperature Sensor Example
- Hot Plugging
The J2ME Generic Connection Framework
- The J2ME Generic Connection Framework
- The Generic Connection Framework
- ContentConnection
- Files
- HTTP
- Serial I/O
- Sockets
- Server Sockets
- Datagrams
Bluetooth
- Bluetooth
- The Bluetooth Protocol
- The Java Bluetooth API
- The Local Device
- Discovering Devices
- Remote Devices
- Service Records
- Talking to Devices
Character Sets
