Character Data
Numbers are only part of the data a typical Java program needs in order to read and write. Many programs also handle text, which is composed of characters. Since computers only really understand numbers, characters are encoded by assigning each character in a given script a number. For example, in the common ASCII encoding, the character A is mapped to the number 65; the character B is mapped to the number 66; the character C is mapped to the number 67; and so on. Different encodings may encode different scripts or may encode the same or similar scripts in different ways.
Java understands several dozen different character sets for a variety of languages, ranging from ASCII to the Shift Japanese Input System (SJIS) to Unicode. Internally, Java uses the Unicode character set. Unicode is a superset of the 1-byte Latin-1 character set, which in turn is an 8-bit superset of the 7-bit ASCII character set.
1.3.1. ASCII
ASCII, the American Standard Code for Information Interchange, is a 7-bit character set. Thus it defines 27, or 128, different characters whose numeric values range from 0 to 127. These characters are sufficient for handling most of American English. It's an often-used lowest common denominator format for different computers. If you were to read a byte value between 0 and 127 from a stream, then cast it to a char, the result would be the corresponding ASCII character.
ASCII characters 031 and character 127 are nonprinting control characters. Characters 3247 are various punctuation and space characters. Characters 4857 are the digits 09. Characters 5864 are another group of punctuation characters. Characters 6590 are the capital letters AZ. Characters 9196 are a few more punctuation marks. Characters 97122 are the lowercase letters az. Finally, characters 123126 are a few remaining punctuation symbols. The complete ASCII character set is shown in Table A-1 in the Appendix.
1.3.2. Latin-1
ISO 8859-1, Latin-1, is an 8-bit character set that's a strict superset of ASCII. It defines 28, or 256, different characters whose numeric values range from 0 to 255. The first 128 charactersthat is, those numbers with the high-order bit equal to 0correspond exactly to the ASCII character set. Thus 65 is ASCII A and Latin-1 A; 66 is ASCII B and Latin-1 B; and so on. Where Latin-1 and ASCII diverge is in the characters between 128 and 255 (characters with the high-order bit equal to 1). ASCII does not define these characters. Latin-1 uses them for various accented letters such as ü needed for non-English languages written in a Roman script, additional punctuation marks and symbols such as ©, and additional control characters. The upper, non-ASCII half of the Latin-1 character set is shown in Table A-2 in the Appendix. If you were to read an unsigned byte value from a stream, then cast it to a char, the result would be the corresponding Latin-1 character.
1.3.3. Unicode
Latin-1 suffices for most Western European languages (with the notable exception of Greek), but it doesn't have anywhere near the number of characters required to represent Cyrillic, Greek, Arabic, Hebrew, or Devanagari, not to mention pictographic languages like Chinese and Japanese. Chinese alone has over 80,000 different characters. To handle these scripts and many others, the Unicode character set was invented. Unicode has space for over one million different possible characters. Only about 100,000 are used in practice, the rest being reserved for future expansion. Unicode can handle most of the world's living languages and a number of dead ones as well.
The first 256 characters of Unicode are identical to the characters of the Latin-1 character set. Thus 65 is ASCII A and Unicode A; 66 is ASCII B and Unicode B, and so on.
Unicode is only a character set. It is not a character encoding. That is, although Unicode specifies that the letter A has character code 65, it doesn't say whether the number 65 is written using one byte, two bytes, or four bytes, or whether the bytes used are written in big- or little-endian order. However, there are certain standard encodings of Unicode into bytes, the most common of which are UTF-8, UTF-16, and UTF-32.
UTF-32 is the most naïve encoding. It simply represents each character as a single 4-byte (32-bit) int.
UTF-16 represents most characters as a 2-byte, unsigned short. However, certain less common Chinese characters, musical and mathematical symbols, and characters from dead languages such as Linear B are represented in four bytes each. The Java virtual machine uses UTF-16 internally. In fact, a Java char is not really a Unicode character. Rather it is a UTF-16 code point, and sometimes two Java chars are required to make up one Unicode character.
Finally, UTF-8 is a relatively efficient encoding (especially when most of your text is ASCII) that uses one byte for each of the ASCII characters, two bytes for each character in many other alphabets, and three-to-four bytes for characters from Asian languages. Java's .class files use UTF-8 internally to store string literals.
1.3.4. Other Encodings
ASCII, Latin-1, and Unicode are hardly the only character sets in common use, though they are the ones handled most directly by Java. There are many other character sets, both that encode different scripts and that encode the same scripts in different ways. For example, IBM mainframes have long used a non-ASCII character set called EBCDIC. EBCDIC has most of the same characters as ASCII but assigns them to different numbers. Macintoshes commonly use an 8-bit encoding called MacRoman that matches ASCII in the lower 128 places and has most of the same characters as Latin-1 in the upper 128 characters, though in different positions. DOS (including the DOS shell in Windows) uses character sets such as Cp850 that include box drawing characters such as 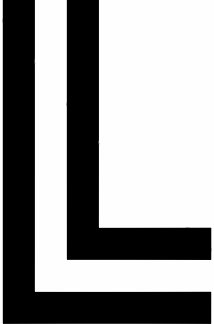 and
and  . Big-5 and SJIS are encodings of Chinese and Japanese, respectively, that include most of the numerous characters used in those scripts.
. Big-5 and SJIS are encodings of Chinese and Japanese, respectively, that include most of the numerous characters used in those scripts.
The exact details of each encoding are fairly involved and should really be handled by experts. Fortunately, the Java class library includes a set of reader and writer classes written by such experts. Readers and writers convert to and from bytes in particular encodings to Java chars without any extra effort. For similar reasons, you should use a writer rather than an output stream to write text, as discussed in Chapter 20.
1.3.5. The char Data Type
Text in Java is primarily composed of the char primitive data type, char arrays, and Strings, which are stored as arrays of chars internally. Just as you need to understand bytes to really grasp how input and output streams work, so too do you need to understand chars to understand how readers and writers work.
In Java, a char is a 2-byte, unsigned integerthe only unsigned type in Java. Thus, possible char values range from 0 to 65,535. Each char represents a particular character in the Unicode character set. chars may be assigned to by using int literals in this range; for example:
char copyright = 169;
chars may also be assigned to by using char literalsthat is, the character itself enclosed in single quotes:
char copyright = '©';
Sun's javac compiler can translate many different encodings to Unicode by using the -encoding command-line flag to specify the encoding in which the file is written. For example, if you know a file is written in ISO 8859-1, you might compile it as follows:
% javac -encoding 8859_1 CharTest.java
The list of available encodings is given in Table A-4.
With the exception of Unicode itself, most character sets understood by Java do not have equivalents for all the Unicode characters. To encode characters that do not exist in the character set you're programming with, you can use Unicode escapes. A Unicode escape sequence is an unescaped backslash, followed by any number of u characters, followed by four hexadecimal digits specifying the character to be used. For example:
char copyright = 'u00A9';
Unicode escapes may be used not just in char literals, but also in strings, identifiers, comments, and even in keywords, separators, operators, and numeric literals. The compiler translates Unicode escapes to actual Unicode characters before it does anything else with a source code file.
|

Basic I/O
Introducing I/O
- Introducing I/O
- What Is a Stream?
- Numeric Data
- Character Data
- Readers and Writers
- Buffers and Channels
- The Ubiquitous IOException
- The Console: System.out, System.in, and System.err
- Security Checks on I/O
Output Streams
- Output Streams
- Writing Bytes to Output Streams
- Writing Arrays of Bytes
- Closing Output Streams
- Flushing Output Streams
- Subclassing OutputStream
- A Graphical User Interface for Output Streams
Input Streams
- Input Streams
- The read( ) Method
- Reading Chunks of Data from a Stream
- Counting the Available Bytes
- Skipping Bytes
- Closing Input Streams
- Marking and Resetting
- Subclassing InputStream
- An Efficient Stream Copier
Data Sources
File Streams
Network Streams
Filter Streams
Filter Streams
- Filter Streams
- The Filter Stream Classes
- The Filter Stream Subclasses
- Buffered Streams
- PushbackInputStream
- ProgressMonitorInputStream
- Multitarget Output Streams
- File Viewer, Part 2
Print Streams
Data Streams
- Data Streams
- The Data Stream Classes
- Integers
- Floating-Point Numbers
- Booleans
- Byte Arrays
- Strings and chars
- Little-Endian Numbers
- Thread Safety
- File Viewer, Part 3
Streams in Memory
- Streams in Memory
- Sequence Input Streams
- Byte Array Streams
- Communicating Between Threads Using Piped Streams
Compressing Streams
- Compressing Streams
- Inflaters and Deflaters
- Compressing and Decompressing Streams
- Zip Files
- Checksums
- File Viewer, Part 4
JAR Archives
- JAR Archives
- Meta-Information: Manifest Files and Signatures
- The jar Tool
- The java.util.jar Package
- JarFile
- JarEntry
- Attributes
- Manifest
- JarInputStream
- JarOutputStream
- JarURLConnection
- Pack200
- Reading Resources from JAR Files
Cryptographic Streams
- Cryptographic Streams
- Hash Functions
- The MessageDigest Class
- Digest Streams
- Encryption Basics
- The Cipher Class
- Cipher Streams
- File Viewer, Part 5
Object Serialization
- Object Serialization
- Reading and Writing Objects
- Object Streams
- How Object Serialization Works
- Performance
- The Serializable Interface
- Versioning
- Customizing the Serialization Format
- Resolving Classes
- Resolving Objects
- Validation
- Sealed Objects
- JavaDoc
New I/O
Buffers
- Buffers
- Copying Files with Buffers
- Creating Buffers
- Buffer Layout
- Bulk Put and Get
- Absolute Put and Get
- Mark and Reset
- Compaction
- Duplication
- Slicing
- Typed Data
- Read-Only Buffers
- CharBuffers
- Memory-Mapped I/O
Channels
- Channels
- The Channel Interfaces
- File Channels
- Converting Between Streams and Channels
- Socket Channels
- Server Socket Channels
- Datagram Channels
Nonblocking I/O
The File System
Working with Files
- Working with Files
- Understanding Files
- Directories and Paths
- The File Class
- Filename Filters
- File Filters
- File Descriptors
- Random-Access Files
- General Techniques for Cross-Platform File Access Code
File Dialogs and Choosers
Text
Character Sets and Unicode
- Character Sets and Unicode
- The Unicode Character Set
- UTF-16
- UTF-8
- Other Encodings
- Converting Between Byte Arrays and Strings
Readers and Writers
- Readers and Writers
- The java.io.Writer Class
- The OutputStreamWriter Class
- The java.io.Reader Class
- The InputStreamReader Class
- Encoding Heuristics
- Character Array Readers and Writers
- String Readers and Writers
- Reading and Writing Files
- Buffered Readers and Writers
- Print Writers
- Piped Readers and Writers
- Filtered Readers and Writers
- File Viewer Finis
Formatted I/O with java.text
- Formatted I/O with java.text
- The Old Way
- Choosing a Locale
- Number Formats
- Specifying Width with FieldPosition
- Parsing Input
- Decimal Formats
Devices
The Java Communications API
- The Java Communications API
- The Architecture of the Java Communications API
- Identifying Ports
- Communicating with a Device on a Port
- Serial Ports
- Parallel Ports
USB
- USB
- USB Architecture
- Finding Devices
- Controlling Devices
- Describing Devices
- Pipes
- IRPs
- Temperature Sensor Example
- Hot Plugging
The J2ME Generic Connection Framework
- The J2ME Generic Connection Framework
- The Generic Connection Framework
- ContentConnection
- Files
- HTTP
- Serial I/O
- Sockets
- Server Sockets
- Datagrams
Bluetooth
- Bluetooth
- The Bluetooth Protocol
- The Java Bluetooth API
- The Local Device
- Discovering Devices
- Remote Devices
- Service Records
- Talking to Devices
Character Sets
