Working with XML
In this chapter, you find out how to work with XML-the best thing to happen to computing since the invention of the vacuum tubes, at least according to some over-enthusiastic prognosticators.
This chapter focuses on the basics of reading an XML document into memory and extracting data from it. With the background in this chapter, you shouldn't have much trouble studying the API documentation on your own to learn more about XML programming.
What Exactly Is XML, Anyway?
Most computer industry pundits agree that XML will completely change the way you work with computers. Here are just some of the ways XML will revolutionize the world of computers:
- Unlock all the vast warehouses of data that's locked up in the vaults of corporate mainframe computers.
- Enable every electronic device on the planet from the most complex supercomputers to desktop computers to cellphones to wrist watches to communicate with one another.
- Allow every computer program ever written to exchange data with every other computer program ever written.
- Probably cure cancer and solve the budget deficit, too.
Yawn.
So what is XML, really? Simply put, XML is a way to store and exchange information in a standardized way that's easy to create, retrieve, and transfer between different types of computer systems or programs.
When XML is stored in a file, the file is usually given the extension xml.
Tags
Like HTML, XML uses tags to mark the data. For example, here's a bit of XML that describes a book:
Java All-In-One Desk Reference For Dummies Lowe
This chunk of XML defines an element called Book, which contains information for a single book. The Book element, in turn, contains two subordinate elements: Title and Author.
Notice how each element begins with a tag that lists the element's name. This tag is called the start tag. The element ends with an element that repeats the element name, preceded by a slash (an end tag).
Everything that appears between the start tag and the end tag is the element's content. An element's content can consist of text data, or it can consist of one or more additional elements. In the latter case, the additional elements nested within an element are called child elements, and the element that contains them is called the parent element.
The highest-level element in an XML document is called the root element. A properly formed XML document consists of a single root element, which can contain elements nested within it. For example, suppose you want to create an XML document with information about two movies. The XML document might look something like this:
It's a Wonderful Life 1946 14.95 The Great Race 1965 12.95
Here the root element named Movies contains two Movie elements, each of which contains Title, Year, and Price elements.
| Tip |
Although XML superficially resembles HTML, you find two key differences between XML and HTML:
|
Attributes
Instead of using child elements, you can use attributes to provide data for an element. An attribute is a name and value pair that's written inside of the start tag for an element. For example, here's a Movie element that uses an attribute instead of a child element to record the year:
It's 14.95
Whether you use attributes or child elements is largely a matter of personal preference. Many XML purists say that you should avoid attributes, or use them only for identifying data such as identification numbers or codes. Others say to use attributes freely. In my experience, a few attributes here and there don't hurt, but I avoid them for the most part.
The movies xml file
For your reference, Listing 5-1 shows the movies.xml file that the programs that appear later in this chapter use.
Listing 5-1: The movies.xml File
It's a 14.95 The Great Race 12.95 Young Frankenstein 16.95 The Return of the Pink Panther 11.95 Star Wars 17.95 The Princess Bride 16.95 Glory 14.95 Apollo 13 19.95 The Game 14.95 The Fellowship of the Ring 19.95
Using a DTD
An XML document can have a DTD, which spells out exactly what elements can appear in an XML document and in what order the elements can appear. DTD stands for Document Type Definition, but that won't be on the test.
For example, a DTD for an XML document about movies may specify that each Movie element must have Title and Price subelements and an attribute named year. It can also specify that the root element is named Movies and consists of any number of Movie elements.
| REMEMBER |
The main purpose of the DTD is to spell out the structure of an XML document so that users of the document know how to interpret it. But another equally important use of the DTD is to validate the document to make sure it doesn't have any structural errors. For example, if you create a Movies XML document that has two titles for a movie, you can use the DTD to detect the error. |
You can store the DTD for an XML document in the same file as the XML data, but more often you store the DTD in a separate file. That way, you can use a DTD to govern the format of several XML documents of the same type. To indicate the name of the file that contains the DTD, you add a tag to the XML document. Here's an example:
Here the XML file is identified as a Movies document, whose DTD you can find in the file movies.dtd. Add this tag near the beginning of the movies.xml file, right after the tag.
Listing 5-2 shows a DTD file for the movies.xml file that was shown in Listing 5-1.
Listing 5-2: A DTD File for the movies.xml File
Each of the ELEMENT tags in a DTD defines a type of element that can appear in the document and indicates what can appear as the content for that element type. The general form of the ELEMENT tag is this:
element (content)>
Use the rules listed in Table 5-1 to express the content.
For example, the first ELEMENT tag in the DTD I showed in Listing 5-2 says that a Movies element consists of zero or more Movie elements. The second ELEMENT tag says that a Movie element consists of a Title element followed by a Price element. The third and fourth ELEMENT tags say that the Title and Price elements consist of text data.
|
Content |
Description |
|---|---|
|
element* |
The specified element can occur zero or more times. |
|
element+ |
The specified element can occur 1 or more times. |
|
element? |
The specified element can occur 0 or 1 time. |
|
element1|element2 |
Either element1 or element2 can appear. |
|
element1, element2 |
Element1 followed by element2. |
|
#PCDATA |
Text data. |
|
ANY |
Any child elements are allowed. |
|
EMPTY |
No child elements of any type are allowed. |
| Tip |
If this notation looks vaguely familiar, it's because it is derived from regular expressions. |
The ATTLIST tag provides the name of each attribute. Its general form is this:
element attribute type default-value>
Here's a breakdown of this tag:
- element names the element whose tag the attribute can appear in.
- attribute provides the name of the attribute.
- type specifies what can appear as the attribute's value. The type can be any of the items listed in Table 5-2.
- default provides a default value and indicates whether the attribute is required or optional. default can be any of the items listed in Table 5-3.
|
Element |
The Attribute Value … |
|---|---|
|
CDATA |
Can be any character string. |
|
(string1|string2…) |
Can be one of the listed strings. |
|
NMTOKEN |
Must be a name token, which is a string made up of letters and numbers. |
|
NMTOKENS |
Must be one or more name tokens separated by white space. |
|
ID |
Is a name token that must be unique. In other words, no other element in the document can have the same value for this attribute. |
|
IDREF |
Must be the same as an ID value used elsewhere in the document. |
|
IDREFS |
Is a list of IDREF values separated by white space. |
|
Default |
Optional or Required? |
|---|---|
|
#REQUIRED |
Required. |
|
#IMPLIED |
Optional. |
|
value |
Optional. This value is used if the attribute is omitted. |
|
#FIXED value |
Optional. However, if included, it must be this value, and if omitted, this value is used by default. |
For example, here's the ATTLIST tag declaration from movies.dtd:
This declaration indicates that the attribute goes with the Movie element, is named year, can be any kind of data, and is required.
Here's an ATTLIST tag that specifies a list of possible values along with a default:
This form of the ATTLIST tag lets you create an attribute that's similar to an enumeration, with a list of acceptable values.
Processing XML in Two Ways
In general, you can process XML documents in a Java program with two approaches. These two approaches are referred to as DOM and SAX:
- DOM: DOM stands for Document Object Model. The basic idea of DOM is that you read an entire XML document from a file into memory, where the document is stored as a collection of objects that are structured as a tree. You can then process the elements of the tree (called nodes) however you wish. If you change any of the nodes, you can write the document back to a file.
- SAX: SAX stands for Simple API for XML. SAX is a read-only technique for processing XML that lets you read the elements of an XML document from a file and react to them as they come. Because SAX doesn't require that you store an entire XML document in memory at one time, it's often used for very large XML documents.
In this chapter, I cover the basics of using DOM to retrieve information from an XML document. DOM represents an XML document in memory as a tree of Node objects. For example, Figure 5-1 shows a simplified DOM tree for an XML document that has two Movie elements. Notice that the root element (Movies) is a node, each Movie element is a node, and each Title and Price element is a node. In addition, text values are stored as child nodes of the elements they belong to. Thus, the Title and Price elements each have a child node that contains the text for these elements.
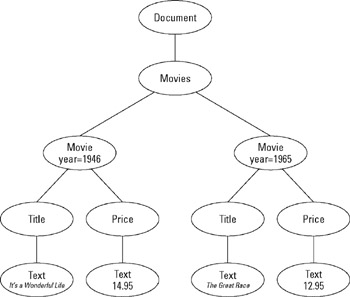
Figure 5-1: A DOM document tree.
Reading a DOM Document
Before you can process a DOM document, you have to read the document into memory from an XML file. You'd think that would be a fairly straightforward proposition, but unfortunately it involves some pretty strange incantations. Rather than go through all the classes and methods you have to use, I just look at the finished code for a complete method that accepts a String that contains a filename as a parameter and returns a document object as its return value. Along the way, you find out what each class and method does.
Here's the code:
private static Document getDocument(String name)
{
try
{
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
factory.setIgnoringComments(true);
factory.setIgnoringElementContentWhitespace(true);
factory.setValidating(true);
DocumentBuilder builder =
factory.newDocumentBuilder();
return builder.parse(new InputSource(name));
}
catch (Exception e)
{
System.out.println(e.getMessage());
}
return null;
}
Creating a document builder factory
The first statement of the preceding example calls the newInstance method of the DocumentBuilderFactory class to create a new DocumentBuilderFactory object. The job of the document builder factory is to create document builder objects that are able to read XML input and create DOM documents in memory.
Why not just call the DocumentBuilderFactory constructor? It turns out that DocumentBuilderFactory is an abstract class, so it doesn't have a constructor. newInstance is a static method that determines which class to create an instance of based on the way your system is configured.
Configuring the document builder factory
After you get a document builder factory, you can configure it so it reads the document the way you want. The next three statements configure three options that are applied to document builders created by this factory object:
factory.setIgnoringComments(true); factory.setIgnoringElementContentWhitespace(true); factory.setValidating(true);
Here's a closer look at these statements:
- The setIgnoringComments method tells the document builder to not create nodes for comments in the XML file. Most XML files don't contain comments, but if they do, they're not part of the data represented by the document, so they can be safely ignored. Setting this option causes them to be ignored automatically. (If you don't set this option, a node is created for each comment in the document. And because you can't predict when or where comments appear, your program has to check every node it processes to make sure it isn't a comment.)
- The setIgnoringElementContentWhitespace method causes the document builder to ignore any white space that isn't part of a text value. If you don't include this option, the DOM document includes nodes that represent white space. The only thing these white space nodes are good for is making the DOM document harder to process, so you should always set this option.
- The setValidating method tells the document builder to validate the input XML if it specifies a DTD. Validating the input can also dramatically simplify your program, because you know that the DOM document conforms to the requirements of the DTD. For example, if you're processing the movies.xml file shown earlier in Listing 5-1, you know for certain that the first child of a Movie element is a Title element and the second child is a Price element. Without the validation, all you know is that the first child of a Movie element should be a Title element, but you have to check it to make sure.
Creating a document builder and the document
After you set the options, you can call the newDocumentBuilder method to create a document builder:
DocumentBuilder builder = factory.newDocumentBuilder();
Here the document builder is referenced by a variable named builder.
Finally, you can create the DOM document by calling the parse method of the document builder. This method accepts an InputSource object as a parameter. Fortunately, the InputSource class has a constructor that takes a filename parameter and returns an input source linked to the file. So you can create the input source, parse the XML file, create a DOM document, and return the DOM document to the caller all in one statement:
return builder.parse(new InputSource(name));
Note that several of these methods throw exceptions. In particular, newDocumentBuilder throws ParserConfigurationException and parse throws IOException and SAXException. To keep this example simple, I caught all exceptions in one catch clause and printed the exceptions message to the console.
Using the getDocument method
By adding the getDocument method, you can create a DOM document from a file with a single statement, like this:
Document doc = getDocument("movies.xml");
Here the movies.xml file is read and a DOM document is created and assigned to the doc variable.
Also, note that you must provide three import statements to use the getDocument method:
import javax.xml.parsers.*; import org.w3c.dom.*; import org.xml.sax.*;
DocumentBuilder and DocumentBuilderFactory are in the javax.xml.parsers package, Document is in org.w3c.dom, and InputSource is in org.xml.sax.
| Tip |
Remember how I said I wouldn't use SAX in this chapter? I lied. The parse method of the DocumentBuilder class uses SAX to read the XML file while it builds the DOM object. |
Reading DOM Nodes
After you have a DOM document in memory, you can easily retrieve data from the document's nodes. The DOM API is based on interfaces rather than classes, so each node of the DOM document is represented by an object that implements one or more DOM interfaces. The following paragraphs give you an overview of the interfaces you need to work with:
- Document: The entire document is represented by an object that implements the Document interface. The method you use most from this interface is getDocumentElement, which returns an Element object that represents the document's root node. After you have the root node, you can then navigate to other nodes in the document to get the information you're looking for.
- Node: The Node interface represents a node in the DOM document. This interface provides methods that are common to all nodes. Table 5-4 lists the most useful of these methods. This table also lists some of the fields' values that the getNodeType method can return.
Table 5-4: The Node Interface
 Open table as spreadsheet
Open table as spreadsheetMethod
Description
NodeList getChildNodes()
Gets a NodeList object that contains all of this node's child nodes.
Node getFirstChild()
Gets the first child of this node.
Node getLastChild()
Gets the last child of this node.
int getNodeType()
Gets an int that indicates the type of the node. The value can be one of the fields listed later in this table.
String getNodeValue()
Gets the value of this node, if the node has a value.
Node getNextSibling()
Gets the next sibling node.
Node getPrevSibling()
Gets the previous sibling node.
boolean hasChildNodes()
Determines whether the node has any child nodes.
Field
Description
ATTRIBUTE_NODE
The node is an attribute node.
CDATA_SECTION_NODE
The node contains content data.
COMMENT_NODE
The node is a comment.
DOCUMENT_NODE
The node is a document node.
ELEMENT_NODE
The node is an element node.
TEXT_NODE
The node is a text node.
- Element: The Element interface represents nodes that correspond to elements in the XML document. Element extends Node, so any object that implements Element is also a Node. Table 5-5 lists some of the more useful methods of this interface.
Table 5-5: The Element Interface
Open table as spreadsheetMethod
Description
String getAttribute (String name)
Gets the value of the specified attribute.
NodeList getElementsBy TagName(String name)
Gets a NodeList object that contains all of the element nodes that are contained within this element and have the specified name.
boolean hasAttribute (String name)
Determines whether the element has the specified attribute.
- Text: The text content of an element is not contained in the element itself, but in a Text node that's stored as a child of the element. The Text interface has a few interesting methods you may want to look up, but for most applications, you just use the getNodeValue method inherited from the Node interface to retrieve the text stored by a text node.
- NodeList: A NodeList is a collection of nodes that's returned by methods such as the getChildNodes method of the Node interface or the getElementsByTagName of the Element interface. NodeList has just two methods: item(int i), which returns the node at the specified index, and getLength(), which returns the number of items in the list. (Like almost every other index in Java, the first node is index 0, not 1.)
Processing elements
Assuming you use a DTD to validate the XML file when you build the document, you can usually navigate your way around the document to pick up information you need without resorting to NodeList objects. For example, here's a routine that simply counts all the Movie elements in the movies.xml file (shown earlier in Listing 5-1) after it's been parsed into a Document object named doc:
int count = 0;
Element root = doc.getDocumentElement();
Node movie = root.getFirstChild();
while (movie != null)
{
count++;
movie = movie.getNextSibling();
}
System.out.println("There are " + count + " movies.");
This method first calls the getFirstChild method to get the first child of the root element. Then it uses each child element's getNextSibling method to get the next element that's also a child of the root element.
If you run a program that contains these lines, the following line appears on the console:
There are 10 movies.
This program doesn't do anything with the Movie elements other than count them, but you soon see how to extract data from the Movie elements.
An alternative way to process all the elements in the movies.xml file is to use the getChildNodes method to return a NodeList object that contains all the elements. You can then use a for loop to access each element individually. For example, here's a snippet of code that lists the name of each element:
Element root = doc.getDocumentElement();
NodeList movies = root.getChildNodes();
for (int i = 0; i < movies.getLength(); i++)
{
Node movie = movies.item(i);
System.out.println(movie.getNodeName());
}
Here the item method is used in the for loop to retrieve each Movie element. If you run a program that contains these lines, ten lines with the word Movie are displayed in the console window.
Getting attribute values
To get the value of an element's attribute, call the getAttribute method and pass the name of the attribute as the parameter. This returns the string value of the attribute. You can then convert this value to another type if necessary. Note that the value may include some white space, so you should run the value through the trim method to get rid of any superfluous white space.
Here's an example that gets the year attribute from each movie in the movies.xml file and determines the year of the oldest movie in the collection:
Element root = doc.getDocumentElement();
Element movie = (Element)root.getFirstChild();
int oldest = 9999;
while (movie != null)
{
String s = movie.getAttribute("year");
int year = Integer.parseInt(s);
if (year < oldest)
oldest = year;
movie = (Element)movie.getNextSibling();
}
System.out.println("The oldest movie in the file "
+ "is from " + oldest + ".");
The year attribute is extracted with these two lines of code:
String s = movie.getAttribute("year");
int year = Integer.parseInt(s);
The first line gets the string value of the year attribute, and the second line converts it to an int.
Notice the extra casting that's done in this method. It's necessary because the movie variable has to be an Element type so you can call the getAttribute method. However, the getNextSibling method returns a Node, not an Element. As a result, the compiler doesn't let you assign the node to the movie variable unless you first cast it to an Element.
Getting child element values
You might be surprised to learn that the text content of an element is not stored with the element. Instead, it's stored in a child node of type Text. For example, consider the following XML:
The Princess Bride
This element results in two nodes in the XML document: an Element node named Title, and a Text node that contains the text The Princess Bride.
Thus, if you have a Title element in hand, you must first get the Text element before you can get the text content. For example:
Node textElement = titleElement.getFirstChild(); String title = textElement.getNodeValue();
If you prefer to write your code a little more tersely, you can do it in a single statement like this:
String title = titleElement.getFirstChild().getNodeValue();
If you find this incantation a little tedious and you're doing a lot of it in your program, write yourself a little helper method. For example:
private static String getTextValue(Node n)
{
return n.getFirstChild().getNodeValue();
}
Then you can get the text content for an element by calling the getTextValue method, like this:
String title = getTextValue(titleElement);
After you get the text content, you can parse it to a numeric type if you need to.
Putting It All Together A Program That Lists Movies
Now that you've seen the various interfaces and classes you use to get data from an XML file, Listing 5-3 shows a complete program that reads the movies.xml file (shown earlier in Listing 5-1) and lists the title, year, and price of each movie on the console. When you run this program, the following appears on the console:
1946: It's 1965: The Great Race ($12.95) 1974: Young Frankenstein ($16.95) 1975: The Return of the Pink Panther ($11.95) 1977: Star Wars ($17.95) 1987: The Princess Bride ($16.95) 1989: Glory ($14.95) 1995: Apollo 13 ($19.95) 1997: The Game ($14.95) 2001: The Fellowship of the Ring ($19.95)
Listing 5-3: Reading an XML Document
import javax.xml.parsers.*; → 1
import org.xml.sax.*;
import org.w3c.dom.*;
import java.text.*;
public class ListMoviesXML
{
private static NumberFormat cf =
NumberFormat.getCurrencyInstance();
public static void main(String[] args) → 11
{
Document doc = getDocument("movies.xml");
Element root = doc.getDocumentElement();
Element movieElement = (Element)root.getFirstChild();
Movie m;
while (movieElement != null)
{
m = getMovie(movieElement);
String msg = Integer.toString(m.year);
msg += ": " + m.title;
msg += " (" + cf.format(m.price) + ")";
System.out.println(msg);
movieElement =
(Element)movieElement.getNextSibling();
}
}
private static Document getDocument(String name) →29
{
try
{
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
factory.setIgnoringComments(true);
factory.setIgnoringElementContentWhitespace(true);
factory.setValidating(true);
DocumentBuilder builder =
factory.newDocumentBuilder();
return builder.parse(new InputSource(name));
}
catch (Exception e)
{
System.out.println(e.getMessage());
}
return null;
}
private static Movie getMovie(Element e) →49
{
// get the year attribute
String yearString = e.getAttribute("year");
int year = Integer.parseInt(yearString);
// get the Title element
Element tElement = (Element)e.getFirstChild();
String title = getTextValue(tElement).trim();
// get the Price element
Element pElement =
(Element)tElement.getNextSibling();
String pString = getTextValue(pElement).trim();
double price = Double.parseDouble(pString);
return new Movie(title, year, price);
}
private static String getTextValue(Node n) → 65
{
return n.getFirstChild().getNodeValue();
}
private static class Movie → 70
{
public String title;
public int year;
public double price;
public Movie(String title, int year, double price)
{
this.title = title;
this.year = year;
this.price = price;
}
}
}
Because all the code in this program is elsewhere in this chapter, the following paragraphs just provide a simple description of what each method in this program does:
|
→ 1 |
Wow, that's a lot of packages to import. Too bad Java's designers couldn't have put all of these XML classes in one big package. |
|
→ 11 |
The main method starts by calling the getDocument method to get a Document object from the file movies.xml. Then it gets the root element and uses a while loop to spin through all the child elements, which you know to be Movie elements because the document was validated when it was parsed. As each Movie element is processed, it is passed to the getMovie method, which extracts the year attribute and the title and price elements and returns a Movie object. Then the movie is printed on the console. |
|
→ 29 |
The getDocument method accepts a filename as a parameter and returns a Document object. Before it creates the DocumentBuilder object, it sets the configuration options so that comments and white space are ignored and the XML file is validated. Because the XML file is validated, you must create a DTD file (like the file in Listing 5-2). You must also begin the XML file with a DOCTYPE declaration (such as ). |
|
→ 49 |
The getMovie method is passed an Element object that represents a Movie element. It extracts the year attribute, gets the text value of the title element, and parses the text value of the price element to a double. It then uses these values to create a new Movie object, which is then returned to the caller. |
|
→ 65 |
The getTextValue method is simply a little helper method that gets the text content from a node. This method assumes that the node has a child node that contains the text value, so you shouldn't call this method unless you know that to be the case. (Because the XML document was validated, you do.) |
|
→ 70 |
The Movie class is a private inner class that represents a single movie. It uses public fields to hold the title, year, and price, and provides a simple constructor that initializes these fields. |
Book I - Java Basics
Book II - Programming Basics
- Book II - Programming Basics
- Java Programming Basics
- Working with Variables and Data Types
- Working with Numbers and Expressions
- Making Choices
- Going Around in Circles (Or, Using Loops)
- Pulling a Switcheroo
- Adding Some Methods to Your Madness
- Handling Exceptions
Book III - Object-Oriented Programming
- Book III - Object-Oriented Programming
- Understanding Object-Oriented Programming
- Making Your Own Classes
- Working with Statics
- Using Subclasses and Inheritance
- Using Abstract Classes and Interfaces
- Using the Object and Class Classes
- Using Inner Classes
- Packaging and Documenting Your Classes
Book IV - Strings, Arrays, and Collections
- Book IV - Strings, Arrays, and Collections
- Working with Strings
- Using Arrays
- Using the ArrayList Class
- Using the LinkedList Class
- Creating Generic Collection Classes
Book V - Programming Techniques
Book VI - Swing
- Book VI - Swing
- Swinging into Swing
- Handling Events
- Getting Input from the User
- Choosing from a List
- Using Layout Managers
Book VII - Web Programming
Book VIII - Files and Databases
- Book VIII - Files and Databases
- Working with Files
- Using File Streams
- Database for $100, Please
- Using JDBC to Connect to a Database
- Working with XML
Book IX - Fun and Games
EAN: 2147483647
Pages: 332
- Supporting Multicast Transport in MPLS Layer 3 VPNs
- Comparing IPsec Remote Access VPNs with Other Types of Remote Access VPNs
- Comparing SSL VPNs to Other Types of Remote Access VPNs
- Using Clientless SSL Remote Access VPNs (WebVPN) on the Cisco VPN 3000 Concentrator
- Designing and Building SSL Remote Access VPNs (WebVPN)
