Hack 77. Fill in Missing Values in a Pivot Table


Microsoft Excel can generate pivot tables. You can't produce a pivot table using SQL alone, but you can use SQL to help Excel do a better job by supplying missing values.
A pivot table displays counts, sums, or averages arranged in a grid. You can't produce a pivot table automatically in SQL because the column headings, and indeed the number of columns, depend on the data in the table. You can build a table with column headings showing aggregates of different values [Hack #51], but you cannot have the columns generated automatically in SQL.
Creating a pivot table in Excel is not difficult, but it is time consuming. This is especially true if you are concerned with the format of your reports; getting the font sizes and the colors just the way you want them can be labor intensive. However, you can create a pivot table with a link (the data source) to a database table or query. This means that you can refresh the report to reflect the latest data with a single click.
Given a list of incidents, you might want to show severity broken down by location, as in Table 10-1. You could also show cause broken down by severity, or location broken down by cause.
| seq | severity | location | cause |
|---|---|---|---|
| 1 | Major | North | Accident |
| 2 | Medium | North | Fraud |
| 3 | Minor | South | Fraud |
| 4 | Minor | South | Accident |
| 5 | Minor | West | Accident |
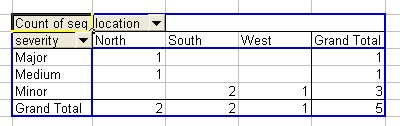
You can use Excel to generate a pivot table from the raw data, as shown in Figure 10-1.
Figure 10-1. Excel pivot table based on incident, showing severity broken down by location
Excel has a PivotTable Wizard that takes you through the process step by step. The wizard, shown in Figure 10-2, includes options to pull the source data from an ODBC source, and that includes pretty much every SQL product available. If you want to use this with MySQL, be sure to get the MySQL ODBC driver from http://dev.mysql.com/downloads/connector/odbc.
Figure 10-2. PivotTable Wizard
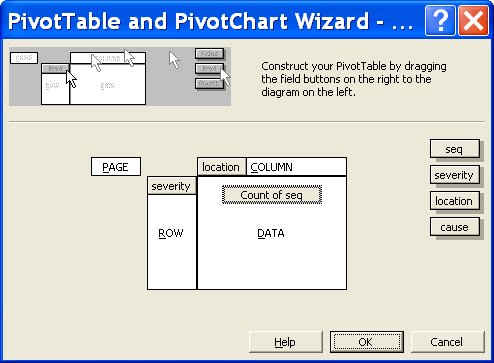
The wizard is intimidating at first, but with a little experimentation you can use it to produce useful business intelligence. The real value to this kind of report comes when the data is updated regularly and you can compare the most recent data with corresponding historical reports. This means that you have to produce the reports regularly; that is much easier if you automate the process.
10.1.1. Include Missing Values
In Figure 10-1 you might notice that the location East is missing. By chance, no rows in the supplied data set involve a location of East, so Excel does not show the missing column.
Missing columns or rows matter because the tables are particularly useful when you look at two versions side by side. When you compare this month's table with last month's table, the missing rows or columns make it harder to spot the patterns. In addition, the fact that zero events occurred in the East is important, possibly crucial, information.
Let's assume that you have a table, shown in Table 10-2, of all possible locations; this is likely, as the location column ought to reference this list as a foreign key.
| Location |
|---|
| North |
| East |
| South |
| West |
| Central |
An INNER JOIN to this table is redundant because it contains no data other than the ID of the location. However, a RIGHT OUTER JOIN to this table ensures that every location will be included:
mysql> SELECT seq, severity, location.id AS location, cause -> FROM incident RIGHT OUTER JOIN location -> ON (location=location.id); +------+----------+----------+----------+ | seq | severity | location | cause | +------+----------+----------+----------+ | NULL | NULL | Central | NULL | | NULL | NULL | East | NULL | | 1 | Major | North | Accident | | 2 | Medium | North | Fraud | | 3 | Minor | South | Fraud | | 4 | Minor | South | Accident | | 5 | Minor | West | Accident | +------+----------+----------+----------+
You could also specify the FROM clause as FROM location LEFT OUTER JOIN incident ON (location=location.id).
The missing locations have been included in the output, and the corresponding column will show up in the pivot table (see Figure 10-3). In addition, the NULL values in the seq column will translate to blank cells in Excel and they will not contribute to the count in the pivot table.
Figure 10-3. Pivot table with missing columns showing
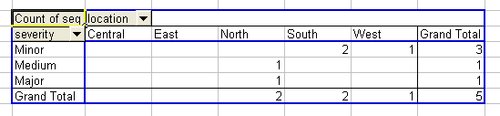
Using a RIGHT OUTER JOIN ensures that the locations that do not have any data still show up in the pivot table.
Now consider the severity values. The output in Figure 10-3 includes Minor, Medium, and Major severity levels. But a severity level of Mega is also a possibility; it happens that no Mega event is in this particular data set. If you want to include Mega in your output, another RIGHT OUTER JOIN will not work.
Look at what happens if you simply RIGHT OUTER JOIN the severity table (the severity table includes all four rows: Minor, Medium, Major, and Mega):
mysql> SELECT seq, severity.id AS severity -> , location.id AS location -> , cause -> FROM incident RIGHT OUTER JOIN location -> ON (location=location.id) -> RIGHT OUTER JOIN severity -> ON (severity=severity.id) -> ; +------+----------+----------+----------+ | seq | severity | location | cause | +------+----------+----------+----------+ | 1 | Major | North | Accident | | 2 | Medium | North | Fraud | | NULL | Mega | NULL | NULL | | 3 | Minor | South | Fraud | | 4 | Minor | South | Accident | | 5 | Minor | West | Accident | +------+----------+----------+----------+ 6 rows in set
You now have the Mega severity level included as required. But you have lost the locations East and Central. The first JOIN included the missing locations, with a NULL value in the severity column. The second RIGHT OUTER JOIN strips these rows out because a NULL in the left result set will not make it through the right join.
A FULL OUTER JOIN (available in SQL Server, Oracle, and PostgreSQL) will solve your problems. The FULL OUTER JOIN will include rows that have a NULL in the JOIN column in either of the tables being joined. Replacing the RIGHT OUTER JOIN with FULL OUTER JOIN in the preceding example produces all eight rows required.
Here is the FULL OUTER JOIN working with all four tables. Also included is the missing cause. The Process value is a possible cause that happened to not show up in the incident table:
SQL> SELECT seq, severity.id AS severity 2 , location.id AS location 3 , cause.id AS cause 4 FROM incident FULL OUTER JOIN location 5 ON (location=location.id) 6 FULL OUTER JOIN severity 7 ON (severity=severity.id) 8 FULL OUTER JOIN cause 9 ON (cause =cause.id); SEQ SEVERITY LOCATION CAUSE --- ---------- ---------- ---------- 1 Major North Accident 2 Medium North Fraud 3 Minor South Fraud 4 Minor South Accident 5 Minor West Accident East Central Mega Process 9 rows selected.
This output is perfect for the pivot table. It means that all possible columns and rows will show up on the reports. The extra rows that you introduce with the FULL OUTER JOINs will not affect the totals because a NULL value in the seq column ensures that they will not contribute to the count.
10.1.2. Use a Union
There is another approach to including the missing rows. This works with SQL Server, Oracle, and PostgreSQL, as well as MySQL and Access.
You can create a UNION that includes the incident table together with each of three tables: location, severity, and cause. For the three extra tables you must pad the result set using NULL values. This means that your output includes additional rows for locations, such as North and South, which showed up in the incident table anyway. The extra rows do not matter because they have a NULL in the seq column and will not contribute to the count. A pivot table based on this data set will include all of the required columns or rows for all three quantities: location, severity, and cause:
mysql> SELECT seq, severity, location, cause FROM incident -> UNION -> SELECT NULL,id, NULL, NULL FROM severity -> UNION -> SELECT NULL,NULL, id, NULL FROM location -> UNION -> SELECT NULL,NULL, NULL, id FROM cause; +------+----------+----------+----------+ | seq | severity | location | cause | +------+----------+----------+----------+ | 1 | Major | North | Accident | | 2 | Medium | North | Fraud | | 3 | Minor | South | Fraud | | 4 | Minor | South | Accident | | 5 | Minor | West | Accident | | NULL | Major | NULL | NULL | | NULL | Medium | NULL | NULL | | NULL | Mega | NULL | NULL | | NULL | Minor | NULL | NULL | | NULL | NULL | Central | NULL | | NULL | NULL | East | NULL | | NULL | NULL | North | NULL | | NULL | NULL | South | NULL | | NULL | NULL | West | NULL | | NULL | NULL | NULL | Accident | | NULL | NULL | NULL | Fraud | | NULL | NULL | NULL | Process | +------+----------+----------+----------+
SQL Fundamentals
- SQL Fundamentals
- Hack 1. Run SQL from the Command Line
- Hack 2. Connect to SQL from a Program
- Hack 3. Perform Conditional INSERTs
- Hack 4. UPDATE the Database
- Hack 5. Solve a Crossword Puzzle Using SQL
- Hack 6. Dont Perform the Same Calculation Over and Over
Joins, Unions, and Views
- Joins, Unions, and Views
- Hack 7. Modify a Schema Without Breaking Existing Queries
- Hack 8. Filter Rows and Columns
- Hack 9. Filter on Indexed Columns
- Hack 10. Convert Subqueries to JOINs
- Hack 11. Convert Aggregate Subqueries to JOINs
- Hack 12. Simplify Complicated Updates
- Hack 13. Choose the Right Join Style for Your Relationships
- Hack 14. Generate Combinations
Text Handling
- Text Handling
- Hack 15. Search for Keywords Without LIKE
- Hack 16. Search for a String Across Columns
- Hack 17. Solve Anagrams
- Hack 18. Sort Your Email
Date Handling
- Date Handling
- Hack 19. Convert Strings to Dates
- Hack 20. Uncover Trends in Your Data
- Hack 21. Report on Any Date Criteria
- Hack 22. Generate Quarterly Reports
- Hack 23. Second Tuesday of the Month
Number Crunching
- Number Crunching
- Hack 24. Multiply Across a Result Set
- Hack 25. Keep a Running Total
- Hack 26. Include the Rows Your JOIN Forgot
- Hack 27. Identify Overlapping Ranges
- Hack 28. Avoid Dividing by Zero
- Hack 29. Other Ways to COUNT
- Hack 30. Calculate the Maximum of Two Fields
- Hack 31. Disaggregate a COUNT
- Hack 32. Cope with Rounding Errors
- Hack 33. Get Values and Subtotals in One Shot
- Hack 34. Calculate the Median
- Hack 35. Tally Results into a Chart
- Hack 36. Calculate the Distance Between GPS Locations
- Hack 37. Reconcile Invoices and Remittances
- Hack 38. Find Transposition Errors
- Hack 39. Apply a Progressive Tax
- Hack 40. Calculate Rank
Online Applications
- Online Applications
- Hack 41. Copy Web Pages into a Table
- Hack 42. Present Data Graphically Using SVG
- Hack 43. Add Navigation Features to Web Applications
- Hack 44. Tunnel into MySQL from Microsoft Access
- Hack 45. Process Web Server Logs
- Hack 46. Store Images in a Database
- Hack 47. Exploit an SQL Injection Vulnerability
- Hack 48. Prevent an SQL Injection Attack
Organizing Data
- Organizing Data
- Hack 49. Keep Track of Infrequently Changing Values
- Hack 50. Combine Tables Containing Different Data
- Hack 51. Display Rows As Columns
- Hack 52. Display Columns As Rows
- Hack 53. Clean Inconsistent Records
- Hack 54. Denormalize Your Tables
- Hack 55. Import Someone Elses Data
- Hack 56. Play Matchmaker
- Hack 57. Generate Unique Sequential Numbers
Storing Small Amounts of Data
- Storing Small Amounts of Data
- Hack 58. Store Parameters in the Database
- Hack 59. Define Personalized Parameters
- Hack 60. Create a List of Personalized Parameters
- Hack 61. Set Security Based on Rows
- Hack 62. Issue Queries Without Using a Table
- Hack 63. Generate Rows Without Tables
Locking and Performance
- Locking and Performance
- Hack 64. Determine Your Isolation Level
- Hack 65. Use Pessimistic Locking
- Hack 66. Use Optimistic Locking
- Hack 67. Lock Implicitly Within Transactions
- Hack 68. Cope with Unexpected Redo
- Hack 69. Execute Functions in the Database
- Hack 70. Combine Your Queries
- Hack 71. Extract Lots of Rows
- Hack 72. Extract a Subset of the Results
- Hack 73. Mix File and Database Storage
- Hack 74. Compare and Synchronize Tables
- Hack 75. Minimize Bandwidth in One-to-Many Joins
- Hack 76. Compress to Avoid LOBs
Reporting
- Reporting
- Hack 77. Fill in Missing Values in a Pivot Table
- Hack 78. Break It Down by Range
- Hack 79. Identify Updates Uniquely
- Hack 80. Play Six Degrees of Kevin Bacon
- Hack 81. Build Decision Tables
- Hack 82. Generate Sequential or Missing Data
- Hack 83. Find the Top n in Each Group
- Hack 84. Store Comma-Delimited Lists in a Column
- Hack 85. Traverse a Simple Tree
- Hack 86. Set Up Queuing in the Database
- Hack 87. Generate a Calendar
- Hack 88. Test Two Values from a Subquery
- Hack 89. Choose Any Three of Five
Users and Administration
- Users and Administration
- Hack 90. Implement Application-Level Accounts
- Hack 91. Export and Import Table Definitions
- Hack 92. Deploy Applications
- Hack 93. Auto-Create Database Users
- Hack 94. Create Users and Administrators
- Hack 95. Issue Automatic Updates
- Hack 96. Create an Audit Trail
Wider Access
- Wider Access
- Sharing Data Across the Internet
- Hack 97. Allow an Anonymous Account
- Hack 98. Find and Stop Long-Running Queries
- Hack 99. Dont Run Out of Disk Space
- Hack 100. Run SQL from a Web Page
Index
EAN: 2147483647
Pages: 147
