Hack 41. Copy Web Pages into a Table


You can copy data from web pages into SQL using XSLT, which lets you pick and choose which parts of the web page to extract.
If the data in a web page is formatted consistently, you can write an XSLT stylesheet to convert it directly into SQL statements. You can target almost any kind of HTML web page, but it's easier if the source is well-formed XML (such as XHTML) and has a simple structure. Wikipedia (http://wikipedia.org) is ideal. To demonstrate this technique, let's start with the Wikipedia list of the top-grossing films worldwide (adjusted for inflation), shown in Figure 6-1.
Figure 6-1. Highest-grossing films according to Wikipedia
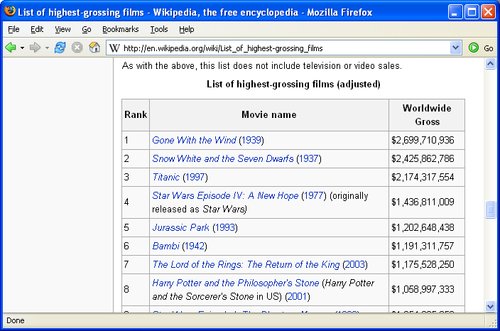
After you turn this web page into some INSERT statements, you'll be able to view the results with a SELECT statement:
1> SELECT * FROM film ORDER BY 2 DESC 2> GO title gross --------------------------------------------------- -------------- Gone With the Wind 2699710936 Snow White and the Seven Dwarfs 2425862786 Titanic 2174317554 Star Wars Episode IV: A New Hope 1436811009 Jurassic Park 1202648438 Bambi 1191311757 The Lord of the Rings: The Return of the King 1175528250 Star Wars Episode I: The Phantom Menace 1054205059
6.1.1. XSLT Processing
The technique used here is based on XSLT processing. An XSLT stylesheet describes a transformation from an XML source to some other format. Often XSLT is used to translate one XML format into another XML format; here you will be using it to translate XML (specifically XHTML) into SQL.
You will need an XSLT processor and an XSLT stylesheet for this process. If you are on a Windows system you can use msxsl.exe, available as a free download (search for msxsl.exe at http://www.msdn.com and for MSXML, which provides the libraries that msxsl.exe depends on). If you are using Linux or a Mac, the xsltproc utility will do the same job. Also, Xalan from Apache (http://xalan.apache.org) is available for most platforms. You will have to write a custom translation for each page format. If you are processing several pages with the same structure you can reuse the sheet, but if the source format changes you will have to change the sheet to accommodate it.
6.1.2. The Input Document
To extract data from an XHTML document you might need to use a little trial and error. You need to look at the raw HTML from the target page and identify the tag or tags that contain the data you are looking for.
Look at the HTML from Wikipedia; this section is part of a much larger document (http://en.wikipedia.org/wiki/List_of_highest-grossing_films):
You must identify enough of the surrounding structure to uniquely identify the text that you need. In this document you can see that the data for each row is contained in a tr element. The XPath expression, htm:tr, will match all such elements.
Unfortunately, this document includes several other tables and tr elements, so you must be more discriminating. The one table that you are interested in is uniquely identified by its caption. You can refine your XPath expression to:
htm:table[htm:caption='List of highest-grossing films (adjusted)' ]/htm:tr
The square brackets introduce a condition on the match. You are still matching TR nodes, but now you are insisting that the parent of the TR is a table and that the table has a caption child with the specified content.
This expression will still match too many tr elements. The first TR element of the table contains the headings and you do not want that to match. You can refine your XPath to ensure that only TR nodes that have TD children are matched:
htm:table[htm:caption='List of highest-grossing films (adjusted)' ]/htm:tr[htm:td]
Having identified the elements that represent each row of your table you can create a template to match them. The content of the template will be an SQL statement with xsl:value-of elements in place of actual data values.
6.1.3. gross.xsl
Here is the stylesheet. You can save the sheet as the file gross.xsl:
INSERT INTO film VALUES ( '', ) GO
The file gross.xsl contains a single useful template. For every tr element in the document that matches the XPath expression, the template is activated. At each activation, the INSERT statement is generated and the xsl:value-of elements get instantiated with values calculated from the current node. The second template with match="text( )" is there to override the default behavior, which is to output all unmatched text content.
Notice the two xsl:value-of elements that return the title of the movie and the gross takings. The expression htm:td[2]/htm:i gives the text content of the i element contained in the second td element. This is the title of the movie. The gross figure is in the third TD element. The transformation removes the dollar signs and the commas using the translate function. This function maps corresponding characters in its second and third arguments; since the third argument is empty in this case, dollar signs and commas are removed.
The square brackets may contain either a condition or a number. When a number is given, as in htm:td[2], it is equivalent to htm:td[position( )=2].
Here is a sample of the output generated:
INSERT INTO film VALUES ( 'Gone With the Wind', 2699710936) GO INSERT INTO film VALUES ( 'Snow White and the Seven Dwarfs', 2425862786) GO
This example is intended for SQL Server; that's why there's a GO command to mark the end of each batch. Most other systems require a semicolon in place of the word GO.
6.1.4. Running the Hack
The XSLT processor will take a page directly from the Web, and you can store the results in the file gross.sql before loading it into SQL Server. In this example, the stylesheet, gross.xsl, is in the current directory, but it can be in any directory or even in a remote URL. You can run the hack from a Windows command prompt as follows:
C:>msxsl http://en.wikipedia.org/wiki/List_of_highest-grossing_films gross.xsl -o gross.sql C:>sqlcmd -E -S(local)SQLExpress -d dbname 1> CREATE TABLE film (title VARCHAR(256), gross BIGINT) 2> GO 1> QUIT C:>sqlcmd -E -S(local)SQLExpress -d dbname -i gross.sql (1 row affected) (1 row affected) (1 row affected) (1 row affected) (1 row affected) (1 row affected) (1 row affected) Msg 102, Level 15, State 1, Server PUMASQLEXPRESS, Line 3 Incorrect syntax near 's'. Msg 105, Level 15, State 1, Server PUMASQLEXPRESS, Line 3 Unclosed quotation mark after the character string ', 1058997333) '. (1 row affected) (1 row affected)
Notice that one of the films, Harry Potter and the Sorcerer's Stone, includes an apostrophe that has caused an error. We'll fix that in the next section. First, look at the equivalent Linux commands for sending data from a web page to MySQL (be sure to replace GO with a semicolon [;] in gross.xsl before you try to run this):
$ wget -O source.htm http://en.wikipedia.org/wiki/List_of_highest-grossing_ films --23:17:49-- http://en.wikipedia.org/wiki/List_of_highest-grossing_films => Qsource.htm' Resolving en.wikipedia.org... 145.97.39.155 Connecting to en.wikipedia.org|145.97.39.155|:80... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] [ <=> ] 34,831 27.48K/s 23:17:50 (27.41 KB/s) - Qsource.htm' saved [34831] $ xsltproc -o gross.sql gross.xsl source.htm $ mysql -u scott -ptiger dbname -e 'source gross.sql' ERROR 1064 (42000) at line 30 in file: 'gross.sql': You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 's Stone', 1058997333); INSERT INTO film VALUES ( 'Star ' at line 2
The preceding example uses the wget command to copy the web page to the filesystem and uses xsltproc to process the stylesheet (notice that the parameters are reversed compared to msxsl).
The unbalanced quote in the title "The Sorcerer's Stone" is causing the same problem here as it did with SQL Server.
6.1.4.1. Processing required
You can take care of quotes using the Perl one-liner on Windows (type cleans up some of the messy Unicode you might get out of msxsl.exe):
type gross.sql | perl -pe "s/'/''/g;s/''/'/;s/'',$/',/;" > grossQ.sql
On Linux, Unix, or Mac OS X, the command is:
perl -pe "s/'/''/g;s/''/'/;s/'',$/',/;" < gross.sql > grossQ.sql
This first substitution, s/'/''/g, replaces each single quote with two single quotes. This includes the first quotes and the last one, which should not be escaped. The next two substitutions, s/''/'/ and s/'',$/',/, put the first and the last quotes back as they were.
You should use your command-line SQL utility [Hack #1] to run the command DELETE FROM film before you load grossQ.sql or you will end up with some duplicates from your previous attempt.
6.1.5. Hacking the Hack
Pages from Wikipedia are valid XHTML, and that makes them particularly suitable for this technique. If your source document is not well formed the XSLT process will halt with an error.
You can clean up many badly formed web pages using the Tidy program from Dave Raggett (http://tidy.sourceforge.net). If you use this program with the - asxhtml and -numeric switches the output is suitable for XSLT processing.
You can use the Linux utility xmllint to get XPath expressions that describe the location of your data.
The Internet Movie Database (IMDb) has a similar list of top-grossing films at http://www.imdb.com/boxoffice/alltimegross?region=world-wide, and this presents more of a challenge.
You can download the page as before:
$ wget -O gross1.htm 'http://www.imdb.com/boxoffice/alltimegross?region=world-wide' --12:29:42-- http://www.imdb.com/boxoffice/alltimegross?region=world-wide => Qgross1.htm' Resolving www.imdb.com... done. Connecting to www.imdb.com[207.171.166.140]:80... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] [ <=> ] 80,936 233.15K/s 12:29:43 (233.15 KB/s) - Qgross1.htm' saved [80936]
You can try to run this through Tidy, but when you do you get a bunch of errors and warnings. You can ignore the warnings but you must take care of the errors:
$ tidy q -numeric -asxhtml gross1.htm line 2 column 1 - Warning: missing declaration line 23 column 1 - Warning: is not approved by W3C line 85 column 1 - Warning: missing before line 110 column 6 - Error: discarding unexpected ...
The error on line 110 is caused by an improperly nested tag. Tidy can cope with many common XML errors, but not that one. The quick and dirty solution to the unrecognized or badly nested tag is simply to get rid of it and hope that you don't lose any important data. grep will do that, and you can follow that up with a more successful run of Tidy:
$ grep -v '' gross1.htm |grep -v 'imdb:roundend' > gross2.htm $ tidy -o gross3.htm -q -asxhtml -numeric gross2.htm line 2 column 1 - Warning: missing declaration line 23 column 1 - Warning: is not approved by W3C line 85 column 1 - Warning: missing
| Rank | Movie name | Worldwide Gross |
|---|---|---|
| 1 | <a href="/wiki/Gone_with_the_Wind_%28film%29">Gone With the Wind</a> (<a href="/wiki/1939">1939</a>) | $2,699,710,936 |
| 2 | <a href="/wiki/Snow_White_and_the_Seven_Dwarfs_%281937_film%29">Snow White and the Seven Dwarfs</a> (<a href="/wiki/1937">1937</a>) | $2,425,862,786 |
| line 86 column 1 - Warning: discarding unexpected | line 85 column 1 - Warning: missing before |
...
The Tidy program now gives even more warnings than before, but no errors, and gross3.htm now contains valid XML that you can process with XSLT. Instead of examining the file by hand, you can get xmllint to find the structures you need; see Hack #35, "Explore a Document Tree with the xmllint Shell," in XML Hacks by Michael Fitzgerald (O'Reilly), for more information on this:
$ xmllint --shell gross3.htm / > grep Potter /html/body/div[2]/layer/table[3]/tr/td/table[2]/tr/td[2]/table/tr/td[1] /table[1]/tr [4]/td[2]/a : t-- 37 Harry Potter and the Sorcerer's Stone /html/body/div[2]/layer/table[3]/tr/td/table[2]/tr/td[2]/table/tr/td[1] /table[1]/tr [8]/td[2]/a : t-- 35 Harry Potter and the Goblet of Fire /html/body/div[2]/layer/table[3]/tr/td/table[2]/tr/td[2]/table/tr/td[1] /table[1]/tr [10]/td[2]/a : t-- 39 Harry Potter and the Chamber of Secrets /html/body/div[2]/layer/table[3]/tr/td/table[2]/tr/td[2]/table/tr/td[1] /table[1]/tr [18]/td[2]/a : t-- 40 Harry Potter and the Prisoner of Azkaban... / > grep 968,657,891 /html/body/div[2]/layer/table[3]/tr/td/table[2]/tr/td[2]/table/tr/td[1] /table[1]/tr [4]/td[3] : t-- 12 $968,657,891
You use the grep command to identify strings that you know to be in the document. In the preceding sequence, the string Potter crops up in several movie titles and the figure 968,657,891 appears as the box office takings for the first Potter film.
You can see that there are "Potter" titles in tr[4]/td[2]/a and tr[8]/td[2]/a, and in two other places. Each is in a nest of tables four deep. The figure 968,657,891 appears in the gross value for the first Potter film. That value crops up in TR[4]/td[3] and it is the tr[4] node that contains the film title. You can use this information to create your template in the XSL sheet. This sheet has much in common with the previous one.
This time we've not tried to be smart about the XPath expression, so this sheet will be more fragile with respect to trivial formatting changes made by IMDb. The match expression in the template is simply the pattern given by xmllint, but with the namespace htm: prepended to each element name. Save this in a file named imdb.xsl:
INSERT INTO film VALUES ( '', );
The translate function is doing precisely the same job as before, stripping out the dollar signs and the commas. There are line-end characters in the titles this time and the normalize-space function takes care of those. You need to use the [position( )>1] condition to skip the first tr in the list returned; the first row holds the headers. You can run the sheet using xsltproc:
$ xsltproc imdb.xsl gross3.htm > gross4.sql
You will have the same problem with single quotes in movie titles, and you can solve it the same way:
$ perl -pe "s/'/''/g;s/''/'/;s/'',/',/" < gross4.sql > gross5.sql
Finally, you can put your data into MySQL and look at the results:
$ mysql u scott ptiger scott < gross5.sql $ mysql -u scott -ptiger scott -e 'select * from film' +----------------------------------------------------+------------+ | title | gross | +----------------------------------------------------+------------+ | Titanic | 1835300000 | | The Lord of the Rings: The Return of the King | 1129219252 | | Harry Potter and the Sorcerer's Stone | 968657891 | ...
SQL Fundamentals
- SQL Fundamentals
- Hack 1. Run SQL from the Command Line
- Hack 2. Connect to SQL from a Program
- Hack 3. Perform Conditional INSERTs
- Hack 4. UPDATE the Database
- Hack 5. Solve a Crossword Puzzle Using SQL
- Hack 6. Dont Perform the Same Calculation Over and Over
Joins, Unions, and Views
- Joins, Unions, and Views
- Hack 7. Modify a Schema Without Breaking Existing Queries
- Hack 8. Filter Rows and Columns
- Hack 9. Filter on Indexed Columns
- Hack 10. Convert Subqueries to JOINs
- Hack 11. Convert Aggregate Subqueries to JOINs
- Hack 12. Simplify Complicated Updates
- Hack 13. Choose the Right Join Style for Your Relationships
- Hack 14. Generate Combinations
Text Handling
- Text Handling
- Hack 15. Search for Keywords Without LIKE
- Hack 16. Search for a String Across Columns
- Hack 17. Solve Anagrams
- Hack 18. Sort Your Email
Date Handling
- Date Handling
- Hack 19. Convert Strings to Dates
- Hack 20. Uncover Trends in Your Data
- Hack 21. Report on Any Date Criteria
- Hack 22. Generate Quarterly Reports
- Hack 23. Second Tuesday of the Month
Number Crunching
- Number Crunching
- Hack 24. Multiply Across a Result Set
- Hack 25. Keep a Running Total
- Hack 26. Include the Rows Your JOIN Forgot
- Hack 27. Identify Overlapping Ranges
- Hack 28. Avoid Dividing by Zero
- Hack 29. Other Ways to COUNT
- Hack 30. Calculate the Maximum of Two Fields
- Hack 31. Disaggregate a COUNT
- Hack 32. Cope with Rounding Errors
- Hack 33. Get Values and Subtotals in One Shot
- Hack 34. Calculate the Median
- Hack 35. Tally Results into a Chart
- Hack 36. Calculate the Distance Between GPS Locations
- Hack 37. Reconcile Invoices and Remittances
- Hack 38. Find Transposition Errors
- Hack 39. Apply a Progressive Tax
- Hack 40. Calculate Rank
Online Applications
- Online Applications
- Hack 41. Copy Web Pages into a Table
- Hack 42. Present Data Graphically Using SVG
- Hack 43. Add Navigation Features to Web Applications
- Hack 44. Tunnel into MySQL from Microsoft Access
- Hack 45. Process Web Server Logs
- Hack 46. Store Images in a Database
- Hack 47. Exploit an SQL Injection Vulnerability
- Hack 48. Prevent an SQL Injection Attack
Organizing Data
- Organizing Data
- Hack 49. Keep Track of Infrequently Changing Values
- Hack 50. Combine Tables Containing Different Data
- Hack 51. Display Rows As Columns
- Hack 52. Display Columns As Rows
- Hack 53. Clean Inconsistent Records
- Hack 54. Denormalize Your Tables
- Hack 55. Import Someone Elses Data
- Hack 56. Play Matchmaker
- Hack 57. Generate Unique Sequential Numbers
Storing Small Amounts of Data
- Storing Small Amounts of Data
- Hack 58. Store Parameters in the Database
- Hack 59. Define Personalized Parameters
- Hack 60. Create a List of Personalized Parameters
- Hack 61. Set Security Based on Rows
- Hack 62. Issue Queries Without Using a Table
- Hack 63. Generate Rows Without Tables
Locking and Performance
- Locking and Performance
- Hack 64. Determine Your Isolation Level
- Hack 65. Use Pessimistic Locking
- Hack 66. Use Optimistic Locking
- Hack 67. Lock Implicitly Within Transactions
- Hack 68. Cope with Unexpected Redo
- Hack 69. Execute Functions in the Database
- Hack 70. Combine Your Queries
- Hack 71. Extract Lots of Rows
- Hack 72. Extract a Subset of the Results
- Hack 73. Mix File and Database Storage
- Hack 74. Compare and Synchronize Tables
- Hack 75. Minimize Bandwidth in One-to-Many Joins
- Hack 76. Compress to Avoid LOBs
Reporting
- Reporting
- Hack 77. Fill in Missing Values in a Pivot Table
- Hack 78. Break It Down by Range
- Hack 79. Identify Updates Uniquely
- Hack 80. Play Six Degrees of Kevin Bacon
- Hack 81. Build Decision Tables
- Hack 82. Generate Sequential or Missing Data
- Hack 83. Find the Top n in Each Group
- Hack 84. Store Comma-Delimited Lists in a Column
- Hack 85. Traverse a Simple Tree
- Hack 86. Set Up Queuing in the Database
- Hack 87. Generate a Calendar
- Hack 88. Test Two Values from a Subquery
- Hack 89. Choose Any Three of Five
Users and Administration
- Users and Administration
- Hack 90. Implement Application-Level Accounts
- Hack 91. Export and Import Table Definitions
- Hack 92. Deploy Applications
- Hack 93. Auto-Create Database Users
- Hack 94. Create Users and Administrators
- Hack 95. Issue Automatic Updates
- Hack 96. Create an Audit Trail
Wider Access
- Wider Access
- Sharing Data Across the Internet
- Hack 97. Allow an Anonymous Account
- Hack 98. Find and Stop Long-Running Queries
- Hack 99. Dont Run Out of Disk Space
- Hack 100. Run SQL from a Web Page
Index
EAN: 2147483647
Pages: 147
