Text
Text can be thought of as the output from a typewriter (remember typewriters?). That is, text is just characters, with no special formatting other than spaces, tabs, and newlines. Text is typically saved to a file (often called a flat file or an ASCII file).
On most Windows systems, text files commonly (but not always) have the file extension .txt. Double-click on a file with that extension in Windows Explorer, and Notepad, the default application for .txt files, will open. .NET programs can capture text in String objects.
In a single-byte character set, each text character is defined by one byte of data. The maximum one byte number in hexadecimal is FF, or 255 in decimal. Thus, using a zero-based index, a maximum of 256 different characters can be represented in a single byte character set, since each character must be uniquely indexed. The index assigned to a character is called the code point or character code.
The most commonly used single byte character set in the PC world is the American Standards Committee for Information Interchange (ASCII) character set. The first 128 characters, corresponding to seven bit bytes (maximum hex value of 7F), are more or less standardized and are usually considered low-order ASCII characters. The upper 128 characters are not part of the ASCII standard, although many well established character sets use all 256 characters.
|

The low-order ASCII characters are listed in Appendix A.
An alternative to a single-byte character set is a two-byte character set. Two-byte character sets can provide up to 65,536 characters. The most common two-byte character set is the Unicode character set, which is a superset of the ASCII character set.
The Unicode technology was introduced to allow easier representation of languages other than English, especially Asian languages such as Chinese and Japanese, which may not have limited alphabets. Unicode also allows character sets of Western languages, such as Spanish, that have a wide range of styles and special characters within a single character set.
To enter any character from the keyboard, either ASCII or Unicode, press and hold the Alt key while pressing the four digits of the decimal value on the numeric keypad (not the number keys at the top of the keyboard). Pad the beginning of the decimal value with zeros to make four digits. So, for example, to enter a backslash character, which is hex 5C or decimal 92, press Alt 0092.
You can view and place any character, either ASCII or Unicode, from any character set loaded in your system, into any Windows application. To do so, use the Windows-provided Character Map applet accessible from the Start button, and then Programs  Accessories System Tools Character Map.
Accessories System Tools Character Map.
You can convert back and forth between the hex value of a character and the character it represents. This is done somewhat differently in C# and VB.NET.
In C#, you cast from one representation to another, as in the following line of code from Example 9-14 in Chapter 4.
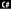
strMsg += " " + "KeyChar Code: " + ((int)keyChar).ToString( ) + " ";
where keyChar is an object of type char. This char is converted to an int, and then that int is appended to the string using the static ToString method (which is actually not necessary here, since C# will automatically convert to a string any expression appended to a string with the + operator).
The equivalent line of code in VB.NET is as follows:
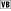
strMsg += vbTab + "KeyChar Code: " + AscW(keyChar).ToString( ) + vbCrLf
where the AscW function converts the character code into its integer value, for it to be then converted to a string. AscW returns an integer representing a Unicode character code between 0 and 65535. The similar function Asc returns a value between 0 and 255 for single byte character sets, and between -32768 and 32767 for double byte character sets. For the low-order characters, they are equivalent.
To convert in the opposite direction in C#, cast an integer to a char. For example:
(char)65
would return an "A".
In VB.NET, use the Chr and ChrW functions, which both take integer arguments representing a character code and return a char. ChrW takes a Unicode character code as an argument, while Chr takes either a single- or double-byte character code.
|
Windows Forms and the .NET Framework
Getting Started
Visual Studio .NET
- Overview
- Start Page
- Projects and Solutions
- The Integrated Development Environment (IDE)
- Building and Running
Events
Windows Forms
- Windows Forms
- Web Applications Versus Windows Applications
- The Forms Namespace
- Form Properties
- Forms Inheritance
- User Interface Design
Dialog Boxes
- Dialog Boxes
- Modal Versus Modeless
- Form Properties
- DialogResult
- Termination Buttons
- Apply Button
- CommonDialog Classes
Controls: The Base Class
Mouse Interaction
Text and Fonts
Drawing and GDI+
Labels and Buttons
Text Controls
Other Basic Controls
TreeView and ListView
List Controls
Date and Time Controls
Custom Controls
- Custom Controls
- Specializing an Existing Control
- Creating a User Control
- Creating Custom Controls from Scratch
Menus and Bars
ADO.NET
- ADO.NET
- Bug Database: A Windows Application
- The ADO.NET Object Model
- Getting Started with ADO.NET
- Managed Providers
- Binding Data
- Data Reader
- Creating a DataGrid
Updating ADO.NET
- Updating ADO.NET
- Updating with SQL
- Updating Data with Transactions
- Updating Data Using DataSets
- Multiuser Updates
- Command Builder
Exceptions and Debugging
- Exceptions and Debugging
- Bugs Versus Exceptions
- Exceptions
- Throwing and Catching Exceptions
- Bugs
- Debugging in Visual Studio .NET
- Assert Yourself
Configuration and Deployment
EAN: 2147483647
Pages: 148
