Working with Random Access Files
The input and output streams in this chapter so far have been sequential access streamsstreams whose contents must be read or written sequentially. Although such streams are still incredibly useful, they are a consequence of sequential media, such as paper and magnetic tape. A random access file, on the other hand, permits nonsequential, or random, access to a file's contents.
So why might you need random access files? Consider the archive format called ZIP. A ZIP archive contains files and is typically compressed to save space. It also contains a dir-entry at the end that indicates where the various files contained within the ZIP archive begin. This is shown in Figure 94.
Figure 94. A ZIP archive.
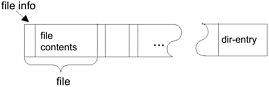
Suppose you want to extract a specific file from a ZIP archive. If you use a sequential access stream, you have to
- Open the ZIP archive.
- Search through the ZIP archive until you locate the file you want to extract.
- Extract the file.
- Close the ZIP archive.
Using this algorithm, you will have to read, on average, half of the ZIP archive before finding the file that you want to extract. You can extract the same file from the ZIP archive more efficiently by using the seek feature of a random access file and following these steps:
- Open the ZIP archive.
- Seek to the dir-entry and locate the entry for the file you want to extract from the ZIP archive.
- Seek (backward) within the ZIP archive to the position of the file to extract.
- Extract the file.
- Close the ZIP archive.
This algorithm is more efficient because you read only the dir-entry and the file that you want to extract.
The RandomAccessFile [1] class in the java.io package implements a random access file. Unlike the input and output stream classes in java.io, RandomAccessFile is used for both reading and writing files. You create a RandomAccessFile object with different arguments, depending on whether you intend to read or to write.
[1] http://java.sun.com/j2se/1.3/docs/api/java/io/RandomAccessFile.html
RandomAccessFile is somewhat disconnected from the input and output streams in java.io; that is, it doesn't inherit from InputStream or OutputStream. This has some disadvantages in that you can't apply the same filters to RandomAccessFiles that you can to streams. However, RandomAccessFile does implement the DataInput [2] and the DataOutput [3] interfaces, so if you design a filter that works for either DataInput or DataOutput, it will work on some sequential access files (the ones that implement DataInput or DataOutput) and on any RandomAccessFile.
[2] http://java.sun.com/j2se/1.3/docs/api/java/io/DataInput.html
[3] http://java.sun.com/j2se/1.3/docs/api/java/io/DataOutput.html
Using Random Access Files
The RandomAccessFile class implements both the DataInput and the DataOutput interfaces and therefore can be used for both reading and writing. RandomAccessFile is similar to FileInputStream and FileOutputStream in that you specify a file on the native file system to open when you create it. You can do this with a file name or a File [4] object. When you create a RandomAccessFile, you must indicate whether you will be just reading the file or also writing to it. (You have to be able to read a file in order to write to it.) The following code creates a RandomAccessFile to read the file named farrago.txt:
[4] http://java.sun.com/j2se/1.3/docs/api/java/io/File.html
new RandomAccessFile("farrago.txt", "r");
This statement opens the same file for both reading and writing:
new RandomAccessFile("farrago.txt", "rw");
After the file has been opened, you can use the read or write methods defined in the DataInput and DataOutput interfaces to perform I/O on the file.
RandomAccessFile supports the notion of a file pointer. The file pointer indicates the current location in the file, as illustrated in Figure 95. When the file is first created, the file pointer is set to 0, indicating the beginning of the file. Calls to the read or write methods adjust the file pointer by the number of bytes read or written.
Figure 95. A ZIP file has the notion of a current file pointer.
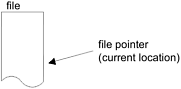
In addition to the normal file I/O methods for reading and writing that implicitly move the file pointer when the operation occurs, RandomAccessFile contains three methods for explicitly manipulating the file pointer:
- int skipBytes(int) Moves the file pointer forward the specified number of bytes
- void seek(long) Positions the file pointer just before the specified byte
- long getFilePointer() Returns the current byte location of the file pointer
Writing Filters for Random Access Files
Let's rewrite the example from the section How to Write Your Own Filter Streams (page 330) so that it works on RandomAccessFiles. Because RandomAccessFile implements the DataInput and the DataOutput interfaces, a side benefit is that the filtered stream will also work with other DataInput and DataOutput streams, including some sequential access streams, such as DataInputStream and DataOutputStream.
The example CheckedIODemo from the section How to Write Your Own Filter Streams (page 330) implements two filter streams that compute a checksum as data is read from or written to the stream. Those streams are CheckedInputStream and CheckedOutputStream.
In the new example, CheckedDataOutput is a rewrite of CheckedOutputStreamit computes a checksum for data written to the stream. However, it operates on DataOutput objects instead of on OutputStream objects. Similarly, CheckedDataInput modifies CheckedInputStream so that it now works on DataInput objects instead of on InputStream objects. All the example code is available in the example directory on this book's CD and online; see Code Samples (page 348).
CheckedDataOutput versus CheckedOutputStream
Let's look at how CheckedDataOutput differs from CheckedOutputStream. The first difference in these two classes is that CheckedDataOutput does not extend FilterOutputStream. Instead, it implements the DataOutput interface:
public class CheckedDataOutput implements DataOutput
Note
To keep the example code simple, in the sources on the CD, we did not require that the CheckedDataOutput class be declared to implement DataOutput, because the DataOutput interface specifies a lot of methods. However, the CheckedDataOutput class in the example does implement several of DataOutput's methods, to illustrate how it should work.
Next, CheckedDataOutput declares a private variable to hold a DataOutput object:
private DataOutput out;
This is the object to which data will be written.
The constructor for CheckedDataOutput differs from CheckedOutputStream's constructor in that CheckedDataOutput is created on a DataOutput object rather than on an OutputStream:
public CheckedDataOutput(DataOutput out, Checksum cksum) {
this.cksum = cksum;
this.out = out;
}
This constructor does not call super(out) like the CheckedOutputStream constructor did, because CheckedDataOutput extends from Object rather than from a stream class.
Those are the only modifications made to CheckedOutputStream to create a filter that works on DataOutput objects.
CheckedDataInput versus CheckedInputStream
CheckedDataInput requires the same changes as CheckedDataOutput, as follows:
- CheckedDataInput does not derive from FilterInputStream. Instead, it implements the DataInput interface.
- CheckedDataInput declares a private variable to hold a DataInput object, which it wraps.
- The constructor for CheckedDataInput requires a DataInput object rather than an InputStream.
In addition to these changes, the read methods are changed. CheckedInputStream from the original example implements two read methods: one for reading a single byte and one for reading a byte array. The DataInput interface has methods that implement the same functionality, but they have different names and different method signatures. Thus, the read methods in the CheckedDataInput class have new names and method signatures:
public byte readByte() throws IOException {
byte b = in.readByte();
cksum.update(b);
return b;
}
public void readFully(byte[] b) throws IOException {
in.readFully(b, 0, b.length);
cksum.update(b, 0, b.length);
}
public void readFully(byte[] b, int off, int len) throws IOException {
in.readFully(b, off, len);
cksum.update(b, off, len);
}
Also, the DataInput interface declares many other methods that we don't implement for this example.
The Main Programs
Finally, this example has two main programs to test the new filters:
- CheckedDIDemo, which runs the filters on sequential access files (DataInputStream and DataOutputStream objects)
- CheckedRAFDemo, which runs the filters on random access files (RandomAccessFile objects)
These two main programs differ only in the type of object on which they open the checksum filters. CheckedDIDemo creates a DataInputStream and a DataOutputStream and uses the checksum filter on them, as in the following code:
in = new CheckedDataInput(new DataInputStream(
new FileInputStream("farrago.txt")), inChecker);
out = new CheckedDataOutput(new DataOutputStream(
new FileOutputStream("outagain.txt")), outChecker);
CheckedRAFDemo creates two RandomAccessFile objects: one for reading and one for writing. It uses the checksum filter on them as follows:
in = new CheckedDataInput(
new RandomAccessFile("farrago.txt", "r"), inChecker);
out = new CheckedDataOutput(
new RandomAccessFile("outagain.txt", "rw"), outChecker);
When you run either of these programs, you should see the following output:
Input stream check sum: 736868089 Output stream check sum: 736868089
Getting Started
- About the Java Technology
- How Will Java Technology Change My Life?
- First Steps (Win32)
- First Steps (UNIX/Linux)
- First Steps (MacOS)
- A Closer Look at HelloWorld
- Questions and Exercises
- Code Samples
Object-Oriented Programming Concepts
- What Is an Object?
- What Is a Message?
- What Is a Class?
- What Is Inheritance?
- What Is an Interface?
- How Do These Concepts Translate into Code?
- Summary
- Questions and Exercises
- Code Samples
Language Basics
Object Basics and Simple Data Objects
Classes and Inheritance
Interfaces and Packages
Handling Errors Using Exceptions
- What Is an Exception?
- The Catch or Specify Requirement
- Catching and Handling Exceptions
- Specifying the Exceptions Thrown by a Method
- How to Throw Exceptions
- Runtime Exceptions The Controversy
- Advantages of Exceptions
- Summary of Exceptions
- Questions and Exercises
- Code Samples
Threads: Doing Two or More Tasks at Once
- What Is a Thread?
- Using the Timer and TimerTask Classes
- Customizing a Threads run Method
- The Life Cycle of a Thread
- Understanding Thread Priority
- Synchronizing Thread
- Grouping Threads
- Summary of Threads
- Questions and Exercises
- Code Samples
I/O: Reading and Writing
- Overview of I/O Streams
- Using the Streams
- Object Serialization
- Working with Random Access Files
- And the Rest…
- Summary of Reading and Writing
- Questions and Exercises
- Code Samples
User Interfaces That Swing
- Overview of the Swing API
- Your First Swing Program
- Example Two: SwingApplication
- Example Three: CelsiusConverter
- Example Four: LunarPhases
- Example Five: VoteDialog
- Layout Management
- Threads and Swing
- Visual Index to Swing Components
- Summary
- Questions and Exercises
- Code Samples
Appendix A. Common Problems and Their Solutions
- Appendix A. Common Problems and Their Solutions
- Getting Started Problems
- General Programming Problems
- Applet Problems
- User Interface Problems
Appendix B. Internet-Ready Applets
- Appendix B. Internet-Ready Applets
- Overview of Applets
- AWT Components
- Taking Advantage of the Applet API
- Practical Consideration of Writing Applets
- Finishing an Applet
- Swing-Based Applets
- Code Samples
Appendix C. Collections
- Appendix C. Collections
- Introduction
- Interfaces
- Implementations
- Algorithms
- Custom Implementations
- Interoperability
Appendix D. Deprecated Thread Methods
- Appendix D. Deprecated Thread Methods
- Why Is Thread.stop Deprecated?
- Why Are Thread.suspend and Thread.resume Deprecated?
- What about Thread.destroy?
- Why Is Runtime.runFinalizersOnExit Deprecated?
Appendix E. Reference
EAN: 2147483647
Pages: 125
