Using vectors Efficiently
Problem
You are using vectors and you have tight space or time requirements and need to reduce or eliminate overhead.
Solution
Understand how a vector is implemented, know the complexity of insertion and deletion member functions, and minimize unnecessary memory churn with the reserve member function. Example 6-2 shows a few of these techniques in action.
Example 6-2. Using a vector efficiently
#include
#include
#include
using std::vector;
using std::string;
void f(vector& vec) { // Pass vec by reference (or
// pointer, if you have to)
// ...
}
int main( ) {
vector vec(500); // Tell the vector that you plan on
// putting a certain number of objects
// in it at construction
vector vec2;
// Fill up vec...
f(vec);
vec2.reserve(500); // Or, after the fact, tell the vector
// that you want the buffer to be big
// enough to hold this many objects
// Fill up vec2...
}
Discussion
The key to using vectors efficiently lies in knowing how they work. Once you have a good idea of how a vector is usually implemented, the performance hot spots become obvious.
How vectors work
A vector is, essentially, a managed array. More specifically, a vector is a chunk of contiguous memory (i.e., an array) that is large enough to hold n objects of type T, where n is greater than or equal to zero and is less or equal to an implementation-defined maximum size. n usually increases during the lifetime of the container as you add or remove elements, but it doesn't decrease. What makes a vector different from an array is the automatic memory management of that array, the member functions for inserting and retrieving elements, and the member functions that provide metadata about the container, such as the size (number of elements) and capacity (the buffer size), but also the type information: vector::value_type is T's type, vector::pointer is a pointer-to-T type, and so on. These last two, and several others, are part of every standard container, and they allow you to write generic code that works regardless of T's type. Figure 6-1 gives a graphical depiction of what some of vector's member functions provide, given a vector that has a size of 7 and a capacity of 10.
Figure 6-1. A vector's innards
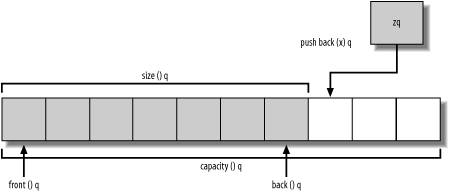
If you are curious how your standard library vendor has implemented vector, compile Example 6-1 and step into every vector member function call, or, open the header in your standard library implementation and take a look. It may not be the most reader-friendly code you've ever seen, but it should be enlightening. First, if you haven't looked at much library code, it will give you an idea of what implementation techniques are used to write efficient, portable, generic code. Second, it will give you a concrete understanding of whatever container you're using. If you are writing code that may need to run with different standard library implementations, you should do this anyway.
Regardless of the library vendor, however, most implementations of vector are similar. There is a member variable that points to an array of Ts, and the elements you add or assign are copy constructed or assigned into each array element.
Adding a T object to the buffer is usually done by using placement newso called because you give the type of object to be constructed as well as the address where it should be constructedto copy construct a new object in the next available slot. If, instead, you are assigning a new value to a slot explicitly by using its index (with operator[] or at), T's assignment operator is used. Note that in both cases what happens is that your object is cloned via copy construction or T::operator=. The vector does not simply store the address of the object you are adding. It is for this reason that any type stored in a vector must be copy constructible and assignable. These properties mean that an equivalent object of T can be created by calling T's copy constructor or assignment operator. This is important, because of the copy-in, copy-out semantics of vectorsif copy constructing or assigning one of your objects does not work properly, then what you get out of a vector might be different than what you put in. This is bad.
Once you have added a bunch of objects to a vector, its buffer becomes full and it must grow to accommodate any new objects. The algorithm for growth is implementation defined, but what usually happens is that the buffer size of n is increased to 2n + 1. The important concept here is how vector grows the buffer. You can't just tell the operating system to extend your hunk of heap memory indefinitely; you have to request a new chunk of memory that is bigger than the one you just had. As a result, the process of increasing the buffer size is as follows:
- Allocate memory for a new buffer.
- Copy the old data into the new buffer.
- Delete the old buffer.
This allows the vector to keep all of its objects in one contiguous chunk of memory.
Optimizing vector performance
The previous section should give you a good idea of how objects are stored in a vector. And from that overview, the major performance points should have jumped out at you, but in case they didn't, I'll discuss them.
To begin with, a vector (or any other standard library container) doesn't store your object, it stores a copy of your object. This means that each time you put something in a vector, you aren't really "putting" it anywhere; you're copying it somewhere else with its copy constructor or assignment operator. Similarly, when you retrieve a value from a vector, you are copying what is in the vector at that location to your local variable. Consider a simple assignment to a local variable from an element in a vector:
vector myVec; // Put some MyObj objects in myVec MyObj obj = myVec[10]; // Copy the object at index 10
This assignment calls obj's assignment operator with the object returned by myVec[10] as its righthand side. The performance overhead from lots of object copies will add up quickly, so it's best if you avoid it.
Put pointers in the vector instead of the objects themselves to reduce copy overhead. Storing pointers will require fewer CPU cycles to add or retrieve data, because pointers are quicker to copy than objects, and it will reduce the memory required by the vector's buffer. Just remember that if you add pointers to a standard library container, the container doesn't delete them when it's destroyed. Containers destroy only the objects they contain, i.e., the variable holding the addresses of the objects pointed to, but a container doesn't know that what it's storing is a pointer or an object, all it knows is that it's some object of type T.
Resizing the memory buffer is also not cheap. Copying every element in the buffer is a lot of work, and such a thing is best avoided. To protect against this, specify the buffer size explicitly. There are a couple of ways to do this. The simplest way to do it is during construction:
vector vec(1000);
This reserves enough space for 1,000 strings and it initializes each slot in the buffer with string's default constructor. With this approach, you pay for constructing each of these objects, but you add some measure of safety by initializing every element in the buffer with an empty string. This means that if you reference an element that hasn't been assigned, you simply get an empty object.
If you want to initialize the buffer to something special, you can pass in the object that you want to copy into each slot in the buffer:
string defString = "uninitialized"; vector vec(100, defString); string s = vec[50]; // s = "uninitialized"
With this form, vec will copy construct 100 elements from defString.
The other way to reserve buffer space is to call the reserve member function sometime after the vector has been constructed:
vector vec; vec.reserve(1000);
The biggest difference between calling reserve and specifying the size at construction is that reserve doesn't initialize the slots in the buffer with anything. Specifically, this means that you shouldn't reference indexes where you haven't already put something:
vector vec(100); string s = vec[50]; // No problem: s is now an empty string vector vec2; vec2.reserve(100); s = vec2[50]; // Undefined
Using reserve or specifying a number of default objects at construction will help you avoid nasty buffer reallocation. That helps with performance, but also avoids another problem: anytime a buffer is reallocated, any iterators you may have that refer to its elements become invalid.
Finally, inserting anywhere but the end of a vector is not a good idea. Look again at Figure 6-1. Since a vector is just an array with some other bells and whistles, it should be easy to see why you should insert only at the end. The objects in the vector are stored contiguously, so when you insert anywhere but at the end, say, at index n, the objects from n+1 to the end must be shifted down by one (toward the end) to make room for the new item. This operation is linear, which means it is expensive for vectors of even modest size. Deleting an element in a vector has a similar effect: it means that all indexes larger than n must be shifted up one slot. If you need to be able to insert and delete anywhere but the end of a container, you should use a list instead.
Building C++ Applications
- Introduction to Building
- Obtaining and Installing GCC
- Building a Simple Hello, World Application from the Command Line
- Building a Static Library from the Command Line
- Building a Dynamic Library from the Command Line
- Building a Complex Application from the Command Line
- Installing Boost.Build
- Building a Simple Hello, World Application Using Boost.Build
- Building a Static Library Using Boost.Build
- Building a Dynamic Library Using Boost.Build
- Building a Complex application Using Boost.Build
- Building a Static Library with an IDE
- Building a Dynamic Library with an IDE
- Building a Complex Application with an IDE
- Obtaining GNU make
- Building A Simple Hello, World Application with GNU make
- Building a Static Library with GNU Make
- Building a Dynamic Library with GNU Make
- Building a Complex Application with GNU make
- Defining a Macro
- Specifying a Command-Line Option from Your IDE
- Producing a Debug Build
- Producing a Release Build
- Specifying a Runtime Library Variant
- Enforcing Strict Conformance to the C++ Standard
- Causing a Source File to Be Linked Automatically Against a Specified Library
- Using Exported Templates
Code Organization
- Introduction
- Making Sure a Header File Gets Included Only Once
- Ensuring You Have Only One Instance of a Variable Across Multiple Source Files
- Reducing #includes with Forward Class Declarations
- Preventing Name Collisions with Namespaces
- Including an Inline File
Numbers
- Numbers
- Introduction
- Converting a String to a Numeric Type
- Converting Numbers to Strings
- Testing Whether a String Contains a Valid Number
- Comparing Floating-Point Numbers with Bounded Accuracy
- Parsing a String Containing a Number in Scientific Notation
- Converting Between Numeric Types
- Getting the Minimum and Maximum Values for a Numeric Type
Strings and Text
- Strings and Text
- Introduction
- Padding a String
- Trimming a String
- Storing Strings in a Sequence
- Getting the Length of a String
- Reversing a String
- Splitting a String
- Tokenizing a String
- Joining a Sequence of Strings
- Finding Things in Strings
- Finding the nth Instance of a Substring
- Removing a Substring from a String
- Converting a String to Lower- or Uppercase
- Doing a Case-Insensitive String Comparison
- Doing a Case-Insensitive String Search
- Converting Between Tabs and Spaces in a Text File
- Wrapping Lines in a Text File
- Counting the Number of Characters, Words, and Lines in a Text File
- Counting Instances of Each Word in a Text File
- Add Margins to a Text File
- Justify a Text File
- Squeeze Whitespace to Single Spaces in a Text File
- Autocorrect Text as a Buffer Changes
- Reading a Comma-Separated Text File
- Using Regular Expressions to Split a String
Dates and Times
- Dates and Times
- Introduction
- Obtaining the Current Date and Time
- Formatting a Date/Time as a String
- Performing Date and Time Arithmetic
- Converting Between Time Zones
- Determining a Days Number Within a Given Year
- Defining Constrained Value Types
Managing Data with Containers
- Managing Data with Containers
- Introduction
- Using vectors Instead of Arrays
- Using vectors Efficiently
- Copying a vector
- Storing Pointers in a vector
- Storing Objects in a list
- Mapping strings to Other Things
- Using Hashed Containers
- Storing Objects in Sorted Order
- Storing Containers in Containers
Algorithms
- Algorithms
- Introduction
- Iterating Through a Container
- Removing Objects from a Container
- Randomly Shuffling Data
- Comparing Ranges
- Merging Data
- Sorting a Range
- Partitioning a Range
- Performing Set Operations on Sequences
- Transforming Elements in a Sequence
- Writing Your Own Algorithm
- Printing a Range to a Stream
Classes
- Classes
- Introduction
- Initializing Class Member Variables
- Using a Function to Create Objects (a.k.a. Factory Pattern)
- Using Constructors and Destructors to Manage Resources (or RAII)
- Automatically Adding New Class Instances to a Container
- Ensuring a Single Copy of a Member Variable
- Determining an Objects Type at Runtime
- Determining if One Objects Class Is a Subclass of Another
- Giving Each Instance of a Class a Unique Identifier
- Creating a Singleton Class
- Creating an Interface with an Abstract Base Class
- Writing a Class Template
- Writing a Member Function Template
- Overloading the Increment and Decrement Operators
- Overloading Arithmetic and Assignment Operators for Intuitive Class Behavior
- Calling a Superclass Virtual Function
Exceptions and Safety
- Exceptions and Safety
- Introduction
- Creating an Exception Class
- Making a Constructor Exception-Safe
- Making an Initializer List Exception-Safe
- Making Member Functions Exception-Safe
- Safely Copying an Object
Streams and Files
- Streams and Files
- Introduction
- Lining Up Text Output
- Formatting Floating-Point Output
- Writing Your Own Stream Manipulators
- Making a Class Writable to a Stream
- Making a Class Readable from a Stream
- Getting Information About a File
- Copying a File
- Deleting or Renaming a File
- Creating a Temporary Filename and File
- Creating a Directory
- Removing a Directory
- Reading the Contents of a Directory
- Extracting a File Extension from a String
- Extracting a Filename from a Full Path
- Extracting a Path from a Full Path and Filename
- Replacing a File Extension
- Combining Two Paths into a Single Path
Science and Mathematics
- Science and Mathematics
- Introduction
- Computing the Number of Elements in a Container
- Finding the Greatest or Least Value in a Container
- Computing the Sum and Mean of Elements in a Container
- Filtering Values Outside a Given Range
- Computing Variance, Standard Deviation, and Other Statistical Functions
- Generating Random Numbers
- Initializing a Container with Random Numbers
- Representing a Dynamically Sized Numerical Vector
- Representing a Fixed-Size Numerical Vector
- Computing a Dot Product
- Computing the Norm of a Vector
- Computing the Distance Between Two Vectors
- Implementing a Stride Iterator
- Implementing a Dynamically Sized Matrix
- Implementing a Constant-Sized Matrix
- Multiplying Matricies
- Computing the Fast Fourier Transform
- Working with Polar Coordinates
- Performing Arithmetic on Bitsets
- Representing Large Fixed-Width Integers
- Implementing Fixed-Point Numbers
Multithreading
- Multithreading
- Introduction
- Creating a Thread
- Making a Resource Thread-Safe
- Notifying One Thread from Another
- Initializing Shared Resources Once
- Passing an Argument to a Thread Function
Internationalization
- Internationalization
- Introduction
- Hardcoding a Unicode String
- Writing and Reading Numbers
- Writing and Reading Dates and Times
- Writing and Reading Currency
- Sorting Localized Strings
XML
- XML
- Introduction
- Parsing a Simple XML Document
- Working with Xerces Strings
- Parsing a Complex XML Document
- Manipulating an XML Document
- Validating an XML Document with a DTD
- Validating an XML Document with a Schema
- Transforming an XML Document with XSLT
- Evaluating an XPath Expression
- Using XML to Save and Restore a Collection of Objects
Miscellaneous
- Miscellaneous
- Introduction
- Using Function Pointers for Callbacks
- Using Pointers to Class Members
- Ensuring That a Function Doesnt Modify an Argument
- Ensuring That a Member Function Doesnt Modify Its Object
- Writing an Operator That Isnt a Member Function
- Initializing a Sequence with Comma-Separated Values
Index
EAN: 2147483647
Pages: 241
