Iterating Through a Container
Problem
You have a range of iteratorsmost likely from a standard containerand the standard algorithms don't fit your needs, so you need to iterate through them.
Solution
Use an iterator or a const_iterator to access and advance through each of the elements in your container. In the standard library, algorithms and containers communicate using iterators, and one of the very ideas of the standard algorithms is that they insulate you from having to use iterators directly unless you are writing your own algorithm. Even so, you should understand the different kinds of iterators so you can use the standard algorithms and containers effectively. Example 7-1 presents some straightforward uses of iterators.
Example 7-1. Using iterators with containers
#include
#include
#include
#include
using namespace std;
static const int ARRAY_SIZE = 5;
template
FwdIter fixOutliersUBound(FwdIter p1,
FwdIter p2,
const T& oldVal,
const T& newVal) {
for ( ;p1 != p2; ++p1) {
if (greater(*p1, oldVal)) {
*p1 = newVal;
}
}
}
int main( ) {
list lstStr;
lstStr.push_back("Please");
lstStr.push_back("leave");
lstStr.push_back("a");
lstStr.push_back("message");
// Create an iterator for stepping through the list
for (list::iterator p = lstStr.begin( );
p != lstStr.end( ); ++p) {
cout << *p << endl;
}
// Or I can use a reverse_iterator to go from the end
// to the beginning. rbegin returns a reverse_iterator
// to the last element and rend returns a reverse_iterator
// to one-before-the-first.
for (list::reverse_iterator p = lstStr.rbegin( );
p != lstStr.rend( ); ++p) {
cout << *p << endl;
}
// Iterating through a range
string arrStr[ARRAY_SIZE] = {"My", "cup", "cup", "runneth", "over"};
for (string* p = &arrStr[0];
p != &arrStr[ARRAY_SIZE]; ++p) {
cout << *p << endl;
}
// Using standard algorithms with a standard sequence
list lstStrDest;
unique_copy(&arrStr[0], &arrStr[ARRAY_SIZE],
back_inserter(lstStrDest));
}
Discussion
An iterator is a type that is used to refer to a single object in a container. The standard containers use iterators as the primary means for accessing the elements they contain. An iterator behaves like a pointer: you dereference an iterator (using the * or -> operators) to access what it refers to, and you can move an iterator forward and backward with syntax that looks like pointer arithmetic. An iterator is not exactly like a pointer, however, for a few reasons. Before I get into that though, let's cover the essentials of how to use iterators.
Using iterators
You declare an iterator using the type that you plan on iterating through. For example, in Example 7-1 I am using a list, so I declare an iterator like this:
list::iterator p = lstStr.begin( );
The ::iterator part of this declaration may look a little unusual if you are not used to working with the standard containers. It is a nested typedef on the list class template created for just this reasonso that users of the container can create iterators for this particular instantiation of a template. This is a standardized convention that all of the standard containers obey; for example, you can declare an iterator to a list or to a set like this:
list::iterator p1; set::iterator p2;
To get back to the example, the iterator p is initialized with the first element in the sequence, which is returned by begin. To advance forward to the next element, use operator++. You can use preincrement (++p) or postincrement (p++), just as you would with a pointer to an array element, but preincrement doesn't create a temporary value to return each time, so it's more efficient and is the preferred approach. Postincrement (p++) has to create a temporary variable because it returns the value of p before the increment. However, it can't increment the value after it has returned, so it has to make a copy of the current value, increment the current value, then return the temporary value. Creating these temporary variables adds up after a while, so if you don't require postincrement behavior, use preincrement.
You will know when to stop advancing to the next element when you hit the end. Or, strictly speaking, when you hit one past the end. The convention with the standard containers is that there is a mystical value that represents one past the end of the sequence, and that value is returned by end. This works conveniently in a for loop, as in the example:
for (list::iterator p = lstStr.begin( );
p != lstStr.end( ); ++p) {
cout << *p << endl;
}
As soon as p equals end, you know that p can advance no further. If the container is empty, begin == end is true, so the body of the loop is never executed. (However, use the empty member function to test a container for emptiness, don't compare begin to end or check that size == 0).
That's the simple functional explanation of iterators, but that's not all. First, an iterator as declared a moment ago works as an rvalue or an lvalue, which means you can assign from its dereferenced value or assign to it. To overwrite every element in the string list, I could write something like this:
for (list::iterator p = lstStr.begin( );
p != lstStr.end( ); ++p) {
*p = "mustard";
}
Since *p refers to an object of type string, string::operator=(const char*) is used to assign the new string to the element in the container. But what if lstStr is a const object? In that case, an iterator won't work because dereferencing it returns a non-const object. You will need to use a const_iterator, which is an iterator that returns an rvalue only. Imagine that you decide to write a simple function for printing the contents of a container. Naturally, you will want to pass the container as a const reference:
template
void printElements(const T& cont) {
for(T::const_iterator p = cont.begin( );
p != cont.end( ); ++p) {
cout << *p << endl;
}
}
Using const in this situation is the right thing to do, and a const_iterator will make the compiler keep you honest if your code tries to modify *p.
The other thing you will need to do sooner or later is iterate through the container backward. You can do this with a normal iterator, but there is a reverse_iterator that was created for just this purpose. A reverse_iterator looks and feels like an ordinary iterator, except that increment and decrement work exactly opposite to an ordinary iterator, and instead of using a container's begin and end methods, you use rbegin and rend, which return reverse_iterators. A reverse_iterator views the sequence in the opposite direction. For example, instead of initializing a reverse_iterator with begin, you use rbegin, which returns a reverse_iterator that refers to the last element in the sequence. operator++ advances backward, or toward the beginning, in the sequence. rend returns a reverse_iterator that points to one-before-the-first element. Here's what it looks like:
for (list::reverse_iterator p = lstStr.rbegin( );
p != lstStr.rend( ); ++p) {
cout << *p << endl;
}
But you may not be able to use a reverse_iterator, in which case, you can use an ordinary iterator, as in:
for (list::iterator p = --lstStr.end( );
p != --lstStr.begin( ); --p) {
cout << *p << endl;
}
Finally, if you happen to know how far forward or backward you need to advance, you can use arithmetic with integral values to move more than one position forward or backward. Perhaps you want to get right to the middle of the list; you might do this:
size_t i = lstStr.size( ); list::iterator p = begin( ); p += i/2; // Move to the middle of the sequence
But beware: depending on the type of container you are using, this operation may be constant or linear complexity. If you are using a container that stores elements contiguously, such as a vector or deque, the iterator can calculate where it needs to jump to and do it in constant time. But if you are using a node-based container, such as a list, you can't use these random-access operations. Instead, you have to advance until you find the element you're after. This is expensive. This is why your requirements for how you iterate through a container or how you plan to find elements in it will dictate the best container to use for your situation. (See Chapter 6 for more information on how the standard containers work.)
When using containers that allow random access, you should prefer iterators to using operator[] with an index variable to access each element. This is especially important if you are writing a generic algorithm as a function template because not all containers support random-access iterators.
There are other things you can do with an iterator, but not just any iterator. iterators belong to one of five categories that have varying degrees of functionality. It's not as simple as a class hierarchy though, so that's what I describe next.
Iterator categories
Iterators supplied by different types of containers do not necessarily do all of the same things. For example, a vector::iterator lets you use operator+= to jump forward some number of elements, while a list::iterator does not. The difference between these two kinds of iterators is their category.
An iterator category is an interface conceptually (not technically; there is no use of abstract base classes to implement iterator categories). There are five categories, and each offers an increasing number of capabilities. They are, from least functional to most, as follows:
Input iterator
An input iterator supports advancing forward with p++ or ++p, and dereferencing with *p. You get back an rvalue when you dereference though. Input iterators are used for things like streams, where dereferencing an input iterator means pulling the next element off the stream, so you can only read a particular element once.
Output iterator
An output iterator supports advancing forward with p++ or ++p, and dereferencing with *p. It's different from an input iterator though, in that you can't read from one, you can only write to itand only write to an element once. Also unlike an input iterator, you get back an lvalue and not an rvalue, so you can assign to it but not read from it.
Forward iterator
A forward iterator merges the functionality of an input iterator and an output iterator: it supports ++p and p++, and you can treat *p as an rvalue or an lvalue. You can use a forward iterator anywhere you need an input or an output iterator, with the added benefit that you can read from or write to a dereferenced forward iterator as many times as you see fit.
Bidirectional iterator
As the name implies, a bidirectional iterator goes forward and backward. It is a forward iterator that adds the ability to go backward using --p or p--.
Random-access iterator
A random-access iterator does everything a bidirectional iterator does, but it also supports pointer-like operations. You can use p[n] to access the element that is n positions after p in the sequence, or you can add to or subtract from p with +, +=, -, or -= to move the iterator forward some number of elements in constant time. You can also compare two iterators p1 and p2 with <, >, <=, or >= to determine their relative order (as long as they both point to the same sequence).
Or maybe you like to see things in Venn diagrams. In that case, see Figure 7-1.
Figure 7-1. Iterator categories
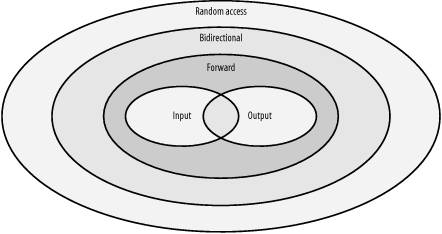
Most of the standard containers support at least bidirectional iterators, some (vector and deque) provide random-access iterators. The iterator category a container supports is specified in the standard.
Most of the time, you will use iterators for the simpler tasks: finding an element and erasing it, or otherwise doing something to it. For this you need only a forward iterator, which is available from all containers. But when you need to write a nontrivial algorithm, or use one from the standard library, you will often require more than a simple forward iterator. But how do you specify what you need? That's where iterator categories come in.
The different categories of iterators allow standard (or nonstandard) algorithms to specify the range of functionality they require. Generally, standard algorithms operate on ranges specified with iterators, and not entire containers. The declaration of a standard algorithm tells you what category of iterator it expects. For example, std::sort requires random-access iterators, since it needs to be able to reference nonadjacent elements in constant time. Thus, the declaration for sort looks like this:
template void sort(RandomAccessIterator first, RandomAccessIterator last);
By the name of the iterator type, you can see that it expects it to be a random-access iterator. If you try to compile sort on an iterator category other than random access, it will fail, because lesser iterator categories do not implement the pointer-arithmetic-like operations.
The iterator category provided by a particular container and that required by a particular standard algorithm is what determines which algorithms work with which containers. Many of the standard algorithms are the subject of the rest of this chapter. Table 7-1 shows the abbreviations I use in the rest of this chapter for the kinds of iterators each algorithm accepts as arguments.
This recipe discussed iterators as they are used with containers. The iterator pattern is not specific to containers, and thus there are other kinds of iterators. There are stream iterators, stream buffer iterators, and raw storage iterators, but those are not covered here.
See Also
Chapter 6
Building C++ Applications
- Introduction to Building
- Obtaining and Installing GCC
- Building a Simple Hello, World Application from the Command Line
- Building a Static Library from the Command Line
- Building a Dynamic Library from the Command Line
- Building a Complex Application from the Command Line
- Installing Boost.Build
- Building a Simple Hello, World Application Using Boost.Build
- Building a Static Library Using Boost.Build
- Building a Dynamic Library Using Boost.Build
- Building a Complex application Using Boost.Build
- Building a Static Library with an IDE
- Building a Dynamic Library with an IDE
- Building a Complex Application with an IDE
- Obtaining GNU make
- Building A Simple Hello, World Application with GNU make
- Building a Static Library with GNU Make
- Building a Dynamic Library with GNU Make
- Building a Complex Application with GNU make
- Defining a Macro
- Specifying a Command-Line Option from Your IDE
- Producing a Debug Build
- Producing a Release Build
- Specifying a Runtime Library Variant
- Enforcing Strict Conformance to the C++ Standard
- Causing a Source File to Be Linked Automatically Against a Specified Library
- Using Exported Templates
Code Organization
- Introduction
- Making Sure a Header File Gets Included Only Once
- Ensuring You Have Only One Instance of a Variable Across Multiple Source Files
- Reducing #includes with Forward Class Declarations
- Preventing Name Collisions with Namespaces
- Including an Inline File
Numbers
- Numbers
- Introduction
- Converting a String to a Numeric Type
- Converting Numbers to Strings
- Testing Whether a String Contains a Valid Number
- Comparing Floating-Point Numbers with Bounded Accuracy
- Parsing a String Containing a Number in Scientific Notation
- Converting Between Numeric Types
- Getting the Minimum and Maximum Values for a Numeric Type
Strings and Text
- Strings and Text
- Introduction
- Padding a String
- Trimming a String
- Storing Strings in a Sequence
- Getting the Length of a String
- Reversing a String
- Splitting a String
- Tokenizing a String
- Joining a Sequence of Strings
- Finding Things in Strings
- Finding the nth Instance of a Substring
- Removing a Substring from a String
- Converting a String to Lower- or Uppercase
- Doing a Case-Insensitive String Comparison
- Doing a Case-Insensitive String Search
- Converting Between Tabs and Spaces in a Text File
- Wrapping Lines in a Text File
- Counting the Number of Characters, Words, and Lines in a Text File
- Counting Instances of Each Word in a Text File
- Add Margins to a Text File
- Justify a Text File
- Squeeze Whitespace to Single Spaces in a Text File
- Autocorrect Text as a Buffer Changes
- Reading a Comma-Separated Text File
- Using Regular Expressions to Split a String
Dates and Times
- Dates and Times
- Introduction
- Obtaining the Current Date and Time
- Formatting a Date/Time as a String
- Performing Date and Time Arithmetic
- Converting Between Time Zones
- Determining a Days Number Within a Given Year
- Defining Constrained Value Types
Managing Data with Containers
- Managing Data with Containers
- Introduction
- Using vectors Instead of Arrays
- Using vectors Efficiently
- Copying a vector
- Storing Pointers in a vector
- Storing Objects in a list
- Mapping strings to Other Things
- Using Hashed Containers
- Storing Objects in Sorted Order
- Storing Containers in Containers
Algorithms
- Algorithms
- Introduction
- Iterating Through a Container
- Removing Objects from a Container
- Randomly Shuffling Data
- Comparing Ranges
- Merging Data
- Sorting a Range
- Partitioning a Range
- Performing Set Operations on Sequences
- Transforming Elements in a Sequence
- Writing Your Own Algorithm
- Printing a Range to a Stream
Classes
- Classes
- Introduction
- Initializing Class Member Variables
- Using a Function to Create Objects (a.k.a. Factory Pattern)
- Using Constructors and Destructors to Manage Resources (or RAII)
- Automatically Adding New Class Instances to a Container
- Ensuring a Single Copy of a Member Variable
- Determining an Objects Type at Runtime
- Determining if One Objects Class Is a Subclass of Another
- Giving Each Instance of a Class a Unique Identifier
- Creating a Singleton Class
- Creating an Interface with an Abstract Base Class
- Writing a Class Template
- Writing a Member Function Template
- Overloading the Increment and Decrement Operators
- Overloading Arithmetic and Assignment Operators for Intuitive Class Behavior
- Calling a Superclass Virtual Function
Exceptions and Safety
- Exceptions and Safety
- Introduction
- Creating an Exception Class
- Making a Constructor Exception-Safe
- Making an Initializer List Exception-Safe
- Making Member Functions Exception-Safe
- Safely Copying an Object
Streams and Files
- Streams and Files
- Introduction
- Lining Up Text Output
- Formatting Floating-Point Output
- Writing Your Own Stream Manipulators
- Making a Class Writable to a Stream
- Making a Class Readable from a Stream
- Getting Information About a File
- Copying a File
- Deleting or Renaming a File
- Creating a Temporary Filename and File
- Creating a Directory
- Removing a Directory
- Reading the Contents of a Directory
- Extracting a File Extension from a String
- Extracting a Filename from a Full Path
- Extracting a Path from a Full Path and Filename
- Replacing a File Extension
- Combining Two Paths into a Single Path
Science and Mathematics
- Science and Mathematics
- Introduction
- Computing the Number of Elements in a Container
- Finding the Greatest or Least Value in a Container
- Computing the Sum and Mean of Elements in a Container
- Filtering Values Outside a Given Range
- Computing Variance, Standard Deviation, and Other Statistical Functions
- Generating Random Numbers
- Initializing a Container with Random Numbers
- Representing a Dynamically Sized Numerical Vector
- Representing a Fixed-Size Numerical Vector
- Computing a Dot Product
- Computing the Norm of a Vector
- Computing the Distance Between Two Vectors
- Implementing a Stride Iterator
- Implementing a Dynamically Sized Matrix
- Implementing a Constant-Sized Matrix
- Multiplying Matricies
- Computing the Fast Fourier Transform
- Working with Polar Coordinates
- Performing Arithmetic on Bitsets
- Representing Large Fixed-Width Integers
- Implementing Fixed-Point Numbers
Multithreading
- Multithreading
- Introduction
- Creating a Thread
- Making a Resource Thread-Safe
- Notifying One Thread from Another
- Initializing Shared Resources Once
- Passing an Argument to a Thread Function
Internationalization
- Internationalization
- Introduction
- Hardcoding a Unicode String
- Writing and Reading Numbers
- Writing and Reading Dates and Times
- Writing and Reading Currency
- Sorting Localized Strings
XML
- XML
- Introduction
- Parsing a Simple XML Document
- Working with Xerces Strings
- Parsing a Complex XML Document
- Manipulating an XML Document
- Validating an XML Document with a DTD
- Validating an XML Document with a Schema
- Transforming an XML Document with XSLT
- Evaluating an XPath Expression
- Using XML to Save and Restore a Collection of Objects
Miscellaneous
- Miscellaneous
- Introduction
- Using Function Pointers for Callbacks
- Using Pointers to Class Members
- Ensuring That a Function Doesnt Modify an Argument
- Ensuring That a Member Function Doesnt Modify Its Object
- Writing an Operator That Isnt a Member Function
- Initializing a Sequence with Comma-Separated Values
Index
EAN: 2147483647
Pages: 241
