Test Implementation
Overview
"Just do it."
— Nike Advertisement
Test implementation is the process of acquiring test data, developing test procedures, preparing the test environment, and selecting and implementing the tools that will be used to facilitate this process. During this phase, test managers and testers are faced with a myriad of questions:
- What setup will be required for the test environment?
- How will the test data be obtained?
- Which test procedures will be automated?
- Which test tools will be used?
- How will the test set be verified?
This chapter describes a systematic approach, which will help you to identify these questions early in the software development lifecycle and plan realistic solutions before reaching the test execution phase.
| Key Point |
Test implementation is the process of acquiring test data, developing test procedures, preparing the test environment, and selecting and implementing the tools that will be used to facilitate this process. |
Test Environment
The test environment is the collection of data, hardware configurations, people (testers), interfaces, operating systems, manuals, facilities, and other items that define a particular level. In the planning chapters, we discussed the importance of choosing the right levels in order to avoid duplication of effort or missing some important aspect of the testing. An important exercise that test managers should undertake is to examine the current levels and attributes at each level of test. Table 6-1 shows some example environmental features and attributes for a product developed by one of our clients.
|
Attribute |
Level |
|||
|---|---|---|---|---|
|
Unit |
Integration |
System |
Acceptance |
|
|
People |
Developers |
Developers & Testers |
Testers |
Testers & Users |
|
Hardware O/S |
Programmers' Workbench |
Programmers' Workbench |
System Test Machine or Region |
Mirror of Production |
|
Cohabiting Software |
None |
None |
None/Actual |
Actual |
|
Interfaces |
None |
Internal |
Simulated & Real |
Simulated & Real |
|
Source of Test Data |
Manually Created |
Manually Created |
Production & Manually Created |
Production |
|
Volume of Test Data |
Small |
Small |
Large |
Large |
|
Strategy |
Unit |
Groups of Units/Builds |
Entire System |
Simulated Production |
As you can see in Table 6-1, the realism of the test environment approaches the production environment at higher levels of test. In fact, an important drill that test managers should undertake is to compare every facet of their system and acceptance test environments with the production environment and try to determine the differences (and therefore the risks). If a significant risk exists, the tester should try to find a way to mitigate that risk (refer to the Planning Risk section of Chapter 2 - Risk Analysis for more information).
| Key Point |
Cohabiting software is other applications that reside in the test environment, but don't interact with the application being tested. |
Case Studies 6-1 through 6-7 provide a series of examples that compare the acceptance testing environment of an insurance company to the production environment. The people, hardware, cohabiting software, interfaces, source and volume of data, and strategy are all attributes of the test environment. Keep in mind that in this example, the software is released immediately after successful conclusion of the acceptance test. Therefore, any differences between the acceptance test environment and the production environment represent untested attributes of the system.
People
An important part of every test environment is the people who are doing the testing. By testing, we mean not only the execution of the tests, but the design and creation of the test cases as well. There is really no right or wrong answer as to who should do the testing, but it is best be done by people who understand the environment at a given level. For example, unit testing is usually done by the developers because it is based on the program specifications and code, which are typically understood best by the developers. Unit testing also provides the developer with assurance that his or her code functions correctly and is ready to be integrated.
| Key Point |
The creation and execution of tests is best be done by the people who understand the environment associated with that level of test. |
Similarly, integration testing is usually done by groups of developers working in concert to determine if all of the software components and their interfaces function together correctly. Some organizations also use testers instead of, or in addition to, the developers because of a shortage of developers, lack of testing skill, or a problem in the past (i.e., the system was promoted to the test environment without adequate testing). We're advocates of having the developer do the integration testing; otherwise, developers can't be sure they're promoting a viable, integrated system.
At system test, it's not always clear who should do the testing. If there's no test group, the system testing must be accomplished by the developers or possibly the users (or their representatives). If an independent test group exists, their focus is often on system testing, because this is where the bulk of testing occurs. Other people such as developers, QA personnel, users, tech writers, help desk personnel, training personnel, and others often augment the system test group. This is done to add expertise to the test group or just because extra resources are needed.
Ideally people with knowledge of how the system will be used should do acceptance testing. This might be users, customer service representatives, trainers, marketing personnel as well as testers. If users are employed as testers, the issue is "which users?" If there are many different users of the system, it's likely that every one of them will use the system in a different manner. The key is to get users involved in testing who best represent the general user community, plus any other users that might use the system in a radically different mode.
Case Study 6-1: People in an Acceptance Testing Environment
Test Environment Attribute - People in an Acceptance Testing Environment - for ABC Insurance Company
Situation:
The testers are mostly former users of the system. Most of them have been testers for many years.
Analysis:
Certainly, turning motivated users into acceptance testers is one way to get business experience and realism in the testing environment. For the most part, these testers retain their empathy and user viewpoint throughout their career. However, as time goes by, the former users tend to have less and less current business experience.
Mitigation:
This company decided to bring in some current users to supplement the test team. Even though they lacked testing experience, they helped to emphasize the current needs of the users. Unfortunately, the three users who were chosen could not possibly represent the actual number of users (about 3,000) of the production system, who each had different needs and skill levels.
Hardware Configuration
An important part of the test environment is the hardware configuration(s). This is always important, but it's particularly important (and difficult) for those companies that are vendors of software. Each customer could potentially have slightly different configurations of hardware, operating systems, peripherals, etc. An excellent approach to take in this case is to develop "profiles" of different customers' environments. One company that we often visit has a Web site that literally has thousands of customers. Each customer potentially has a different configuration. This company, which happens to be a vendor of software, obviously has no control over its customers' environments.
The approach taken by the test group was to survey a sample of the existing customer base and create a series of profiles that describe the various customer configurations. Since it's impossible to replicate thousands of these in the laboratory, the test group looked for common configurations and set up a number of them (about 20) in their laboratory. Even though the bulk of the functional testing was done on just one of these configurations, the automated regression test suite was run on each of the 20 configurations prior to deployment. A lab like this is also worth its weight in gold when a customer calls in with a problem. The help desk, developers, and testers are often able to replicate the customers' environment and therefore facilitate the isolation, correction, and testing of the problem.
| Key Point |
If there are many diverse users of the system, it's useful to create profiles of common customer environments. |
Obviously, not every test group has the luxury of creating an entire laboratory of test configurations. In that case, it's desirable to create a profile of a typical customer environment. If resources allow, it's also desirable to set up an environment that represents the minimum hardware configurations required to run the software under test.
Case Study 6-2: Hardware in an Acceptance Testing Environment
Test Environment Attribute - Hardware in an Acceptance Testing Environment - for ABC Insurance Company
Situation:
This was largely a client-server system. The servers were maintained by data processing professionals at regional sites. The clients were company-provided PCs. The testers used "exact" replicas of the hardware. All systems used the same operating system, but the memory, storage, and peripherals (especially printers and drivers) were different. The testers set up three different environments:
- "High-end," which represented the most powerful configuration found
- "Low-end," which represented the least powerful configuration found
- "Normal" configuration, which represented the average configuration found
Analysis:
This seems like a reasonable approach. On the previous release, the team had only used the "normal" configuration and there were lots of problems with users on "low-end" systems and with some peripherals. This test environment with three hardware configurations worked well for this company.
Mitigation:
Of course, this problem could also have been addressed by upgrading all clients to the same standard. That turned out to be politically impossible, since each region funded its own hardware purchases.
Cohabiting Software
Most applications that you test will ultimately be installed on a machine (PC, mainframe, client/server) that also serves as a host for other applications. This has important implications to the tester:
- Do the cohabiting applications share common files?
- Is there competition for resources between the applications?
The approach we recommend for testing cohabiting software is to make an inventory of the cohabiting applications used by the various users. If there are many users, this may have to be done on a sampling basis. It's also beneficial to create one or more profiles of the most common combinations of cohabiting applications employed by different users. The strategy is to test each of the cohabiting applications in the inventory (unless there are just too many) and the most common and important combinations (profiles). This can be done by having the various cohabiting software applications running during the execution of the system and/or acceptance test. Other organizations conduct a separate testing activity designed just to test the cohabiting software. This is frequently done using the regression test set. Sometimes, the testing of the profiles of cohabiting software can be combined with testing the various hardware profiles.
Case Study 6-3: Cohabiting Software in an Acceptance Testing Environment
Test Environment Attribute - Cohabiting Software in an Acceptance Testing Environment - for ABC Insurance Company
Situation:
Company regulations specified what software could be loaded onto the client machines. In reality, most of the users installed whatever additional software they wanted.
Analysis:
The system was tested on machines that had only the software under test (SUT) installed. There were isolated instances where the "additional" software installed by some users crashed the application or hindered its performance.
Mitigation:
Enforcing the regulations could have solved this problem. The testing solution could be to develop "profiles" of commonly user-installed software and test the interaction of various applications. In the end, the team felt that the problem was not severe enough to warrant the creation of profiles, and their (reasonable) solution was to urge all end-users to conform to company regulations or at least report what software was loaded. Interestingly, though, some of the problematic cohabiting software was unlicensed, which is an entirely different issue.
Interfaces
Testing interfaces (to other systems) is often difficult and is frequently a source of problems once systems are delivered. Interfaces between systems are often problematic because the systems may not have originally been built to work together, may use different standards and technology, and are frequently built and supported by different organizations. All of these things make the testing of interfaces difficult, but the problem is exacerbated because it's frequently necessary to conduct the tests using simulated rather than real interfaces, since the system(s) that are being interfaced may already be in production. Hence, the quality and effectiveness of interface testing is dependent on the quality of the simulated interface. (Do you remember all of the bugs that you found in the application you're testing? The simulated interfaces were created using the same types of tools, methods, and people.)
Case Study 6-4: Interfaces in an Acceptance Testing Environment
Test Environment Attribute - Interfaces in an Acceptance Testing Environment - for ABC Insurance Company
Situation:
The only interface that the clients had was with the server. The server interfaced with several other company systems. The test environment normally simulated the interfaces to these various production systems. On previous releases, some of the interfaces did not work correctly after installation in spite of the testing using the simulations.
Analysis:
This is a common and difficult situation. It's frequently impossible to have "live" interfaces with production systems due to the risk of corrupting actual processes or data.
Mitigation:
After the particularly troublesome release, the testers re-evaluated the realism of the interfaces and tried to more closely model the actual interface. This problem was serious enough that on future releases, the system was installed on a pilot site before being installed globally.
Source of Test Data
A goal of testing is to create the most realistic environment that resources allow and the risks dictate - this includes the test data. Data can be in the form of messages, transactions, records, files, etc. There are many sources of data, and most test groups will probably try to use several different sources. Real data is desirable in many instances because it's the most realistic. Unfortunately, there are lots of reasons why real data is inadequate or, in some instances, impossible to use. For example, if the latest release uses radically different data formats from the production data, then production data may not be a viable choice. In some cases (e.g., military), the data could be classified and would require that the test environment also be classified. This can greatly add to the cost of the tests and might mean that some of the staff cannot participate. In other environments, real data, although not classified, may be company sensitive (e.g., financial records) or personally sensitive (e.g., social security numbers). In this case, additional security precautions may be required if real data is used.
If there are a large number of different users who have different profiles of data, it may be more difficult or impossible to accurately model all of the real data. Different users may have different profiles of data (e.g., an insurance company in Colorado may have much more data relating to the insurance of snowmobiles than one in Florida). In any case, even a large sample of production data seldom provides all of the situations that are required for testing, which means that some data must be created by hand or using some type of test data generator.
Table 6-2 lists some sources of data and their testing characteristics.
|
Production |
Generated |
Captured |
Manually Created |
Random |
|
|---|---|---|---|---|---|
|
Volume |
Too Much |
Controllable |
Controllable |
Too Little |
Controllable |
|
Variety |
Mediocre |
Varies |
Varies |
Good |
Mediocre |
|
Acquisition |
Easy |
Varies |
Fairly Easy |
Difficult |
Easy |
|
Validation (Calibration) |
Difficult |
Difficult |
Fairly Difficult |
Easy |
Very Difficult |
|
Change |
Varies |
Usually Easy |
Varies |
Easy |
Easy |
Production data is the most realistic but may not cover all of the scenarios that are required. Additionally, this type of data could be sensitive, difficult to ensure that it is all correct, and sometimes difficult to change. Production data may vary depending on the day of the week, month, or time of year. Similarly, there may be different data mixes at different client sites. Another issue for some organizations is that a copy of the production data may be prohibitively large and would, therefore, slow the execution of the test or require the use of a profiling or extract tool to reduce its size.
| Key Point |
Production data may vary depending on the day of the week, month, or time of year. |
Generated data typically requires a tool or utility to create it. The variability of generated data depends on the sophistication of the tool and the tester's specification of how the data is to be created. If a tool is used to create very specific types of data, it may almost be like hand-creating the data. A tool, for example, may be used to create large volumes of similar data or data that varies according to an algorithm. Realism of the data depends on the quality of the tool and how it's used.
Captured data is only as good as the source from which it came. No extra effort is required to obtain the data once it has been gathered the first time. Most tools allow testers to modify the data, but the ease of this task varies depending on the particular tool.
Manually created data is, sometimes, the only way to obtain the extremely unique data required by certain test cases. Unfortunately, creating data by hand is time consuming and tedious. Sometimes, this approach is not very realistic if the author of the data doesn't have a good understanding of the functionality of the system (e.g., the data might be in the correct format, but not representative of the real world).
Random data, although easy to obtain, is not very realistic because an unknown amount of data would be required to cover every situation. Random data is useful for stress or load testing, but even here, the type of data can sometimes affect the quality of the load test.
Most testers will probably want to use data from a variety of sources, depending on the level of test and the availability of different types of data. If production data is available, most high-level testers (i.e., system and acceptance) will use this as their primary source of data. However, they may still need to create some data by hand to exercise circumstances not represented by the production data, or use generated data for volume testing, etc.
Volume of Test Data
In our goal of creating a realistic environment (especially during system and acceptance testing), it's necessary to consider the volume of data that will be needed. Most organizations choose to use a limited volume of data during the execution of the structural and functional tests. This is done because the objective of most test cases can be achieved without large volumes of data, and using smaller volumes of data is quicker and uses fewer resources. Unfortunately, the volume of data can have a large impact on the performance of the system being tested and therefore needs to be addressed. Ideally, the test group would use a volume equal to the volume expected in production. This may be possible, but in some instances, resource constraints make this impossible and the test group will have to use smaller volumes (and accept the associated risk), or resort to using a load generation tool.
It's also important to note, though, that sometimes it's not enough to use an equivalent volume of data, but you must also consider the mix of the data. If production data is available, it can sometimes be used to get the correct mix.
Case Study 6-5: Data in an Acceptance Testing Environment
Test Environment Attribute - Data (Source and Volume) in an Acceptance Testing Environment - for ABC Insurance Company
Situation:
The team used copies of real production data from one of the regions. This data was the same data used in the previous release.
Analysis:
In this case, this strategy worked fine since the production data had enough variability and volume to satisfy their testing needs. Other companies that we've visited found that the data is different on different days of the week, months, etc., or is different at different client sites, or changes rapidly from release to release.
Mitigation:
None.
Strategy
In "Strategy," we discuss any additional considerations that the testing strategy has on the design of the test environment. For example, if buddy testing is used for unit testing, the environment must make it easy for programmers to access each other's specifications and code, and provide rules about how recommended changes will be communicated and made.
If the strategy for integration testing is to test progressively larger builds, the environment must support the testing of each successive build with data files that "cover" that build. For example, the test environment for 'Build C' will have to have data to cover the functionality added during that build. An example in the system test environment might be to create a small test environment for functional testing and a larger, more realistic environment for performance testing.
Similarly, if the system or acceptance testing is built around testing specific customer profiles, then the hardware and data in the test environment must match the profiles.
Case Study 6-6: Strategy in an Acceptance Testing Environment
Test Environment Attribute - Strategy in an Acceptance Testing Environment - for ABC Insurance Company
Situation:
The testers decided that the test cases would mirror the instructions that were used in the user's manual (e.g., create a policy, amend a policy, etc.).
Analysis:
This worked pretty well. It turns out that the (well-designed) user's manual covered most of the situations that a user might encounter. In fact, the user's manual itself looked remarkably like a set of high-level test cases or scenarios.
Mitigation:
None.
Model Office Concept
One concept that we've recently seen several times is the model office. The model office is really just what its name implies - a test environment (probably acceptance) that is set up exactly like a real office. If you were in the business of creating software for travel agencies, for example, your model office could be an office that is set up just like a real travel agency, right down to the travel posters on the wall. The office is typically arranged like the real environment and uses testers and customers who are as near the real thing as possible. For our travel agent, for example, the tester would be a real travel agent and the customer would be someone who went into the model office to plan a vacation to Tampa, Florida. The tests are complete, end-to-end processing of the customer's request using actual hardware, software, data, and other real attributes.
Because the model office has the look and feel of a production environment and uses real data, it provides developers and testers the opportunity to make changes to production system code, test it, and move it into the production environment without impacting the current production environment.
What Should Be Automated?
We're constantly frustrated when we visit a client site where testing is in its infancy - they have no test cases, no metrics, poor or no defect tracking - and all they want to know is what tool they should buy. Fred Brooks' famous quote says, "There is no silver bullet," and indeed that's the case with test tools.
Case Study 6-7: The tool will do all of the work. Or, will it?
Is Automation the "Silver Bullet?"
Way back in the early '80s, when I was a (really) young Captain of Marines, Mr. Bill Perry of the Quality Assurance Institute asked me to be a speaker at the Second Annual International Testing Conference. First of all, I was very flattered, but I was also pretty nervous at the thought of speaking in front of a large group of people (especially those very unpredictable civilian types). However, I overcame my fear and gave a presentation on a topic that was near and dear to my heart, "Test Automation."
But let me digress a bit. At that time, I was in charge of an Independent Test Group at the (now non-existent) United States Readiness Command. Even though I had a fairly large staff of testers, the size and importance of the application was huge and quite overwhelming. We decided that the answer to our problems was test automation, so we hired a couple of high-powered consultants to help us develop crude (by today's standards) code coverage tools, performance monitors, script recorders, test execution tools, and even a really crude screen capture facility. This was all really cutting-edge stuff for that era. Unfortunately, the tools required huge overhead in the form of effort and computer resources. We soon found ourselves purchasing computer time from the local university and spending almost all of our time "serving the tools," for they had certainly become our masters. I was truly enamored.
So, let's get back to the conference. What did I say? I started off with the antique slide you see below and explained to my audience that if your testing is automated, all you have to do is sit back, have the Corporal turn the crank, and measure the successes and failures. The tool will do all of the work! When I joined SQE a few years later, however, I was surprised to find my slide in one of their note sets with a new title! The cartoon was renamed "Automation is not the Answer," which reversed the meaning of my original slide and speech.
Well, now I'm a wily old Colonel instead of a naive young Captain, and I've learned that as important as testing tools and automation are, they are not THE answer to your problems. They are just one more tool in your bag of testing tricks.
- Rick Craig
A testing tool is a software application that helps automate some part of the testing process that would otherwise be performed manually. In this category, we also include tools that support testing, such as some configuration management tools, project management tools, defect tracking tools, and debugging tools.
| Key Point |
It's typically not fruitful, and probably not possible or reasonable, to automate every test. Obviously, if you're trying to test the human/machine interface, you can't automate that process since the human is a key part of the test. |
Automation is the integration of testing tools into the test environment in such a fashion that the test execution, logging, and comparison of results are done with minimal human intervention. Generally, most experienced testers and managers have learned (in the school of hard knocks) that it's typically not fruitful, and probably not possible or reasonable, to automate every test. Obviously if you're trying to test the human/machine interface, you can't automate that process since the human is a key part of the test. Similarly, usability testing is normally done manually for the same reasons.
Case Study 6-8: If you automate a bunch of garbage, all you end up with is fast trash.
Fast Trash
I had a friend who used to work for a large bank in Hong Kong as the Test Automation Director. Once, while I was consulting for his bank, James confided in me about the state of the practice at his bank. He said, "You know, Rick, here at the ABC bank, we do testing very poorly and it takes us a really long time." He went on to say, "My job is to automate all of the tests so that we can do the same bad job, but do it quicker." Naturally, I was a little skeptical, but James made a strong case for using the "extra" time he gained by automation for process improvement.
The next time I arrived in Hong Kong and met with James, he looked rather bedraggled and said, "You know, if you automate a bunch of garbage, all you end up with is fast trash."
- Rick Craig
Creating automated test scripts can often take more expertise and time than creating manual tests. Some test groups use the strategy of creating all tests manually, and then automating the ones that will be repeated many times. In some organizations, this automation may even be done by an entirely separate group. If you're working in an environment where it takes longer to write an automated script than a manual one, you should determine how much time is saved in the execution of the automated scripts. Then, you can use this estimate to predict how many times each script will have to be executed to make it worthwhile to automate. This rule of thumb will help you decide which scripts to automate. Unless there is very little cost in automating the script (perhaps using capture-replay, but don't forget the learning curve), it's almost always more efficient to execute the test manually if it's intended to be run only once.
Repetitive Tasks
Repetitive tasks, such as regression tests, are prime candidates for automation because they're typically executed many times. Smoke, load, and performance tests are other examples of repetitive tasks that are suitable for automation, as illustrated in Figure 6-1.
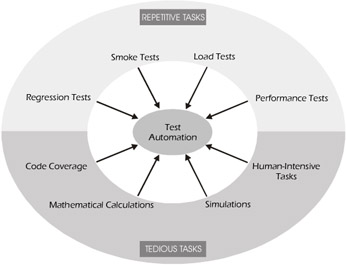
Figure 6-1: Repetitive and Tedious Tasks Are Prime Candidates for Automation
We usually recommend that smoke tests be included as a subset of the regression test set. If there isn't enough time to automate the entire regression test set, the smoke tests should be automated first since they will probably be run more than any other tests. Performance tests are typically much easier to execute using a tool and, in some environments, load testing may not be possible without a tool.
Tedious Tasks
Tedious tasks are also prime candidates for automation. Code coverage, mathematical calculations, simulations, and human-intensive tasks, as listed in Figure 6-1 above, are virtually impossible to do on any sizable scale without using a tool.
Avoiding Testing Tool Traps
There are a multitude of reasons why the use of testing tools may fail. While some of these obstacles may seem easy to overcome on the surface, they're often deep-rooted within an organization's culture and may be difficult to resolve. According to a survey conducted at the 1997 Rational ASQ Conference, 28% of respondents said they didn't use automated testing tools due to lack of management support or budget; 18% said adequate tools weren't available; 13% said their current testing effort was too disorganized to use automated tools; 7% said their current manual testing was adequate; 5% said they didn't know that tools were available; and 0% said they didn't see any benefit to using tools. Chapter 11 - Improving the Testing Process has more information on how to identify and manage some of these obstacles.
No Clear Strategy
| Key Point |
In most instances, it's necessary to first define the process and then choose a tool to facilitate that process. |
One of the greatest pitfalls is implementing a tool without a clear idea of how the testing tool can help contribute to the overall success of the testing effort. It's important that tools be chosen and implemented so that they contribute to the overall strategy as outlined in the master test plan. For the most part, it's not a good strategy to choose a tool and then modify your procedures to match the tool (well, you will almost always have to do this a little bit). The idea is to get a tool that helps you implement your testing strategy, not that of the tool vendor. An exception (there are always exceptions) might be if you have no processes at all in place for a certain function. For example, if your organization has no defect tracking system in place, it might be reasonable to choose a popular tool and create your defect tracking process around that of the tool. We reiterate, though, that in most instances it's necessary to first define the process and then choose a tool to facilitate that process.
Great Expectations
Management (especially upper management) expects that after the purchase of a tool, the testing will be better and faster and cheaper - usually by an entire order of magnitude and usually immediately. While some projects may achieve this triad of success, most should consider one or two of these a success. The actual level of improvement expected (or required) needs to be quantified, otherwise it's not possible to determine if the tool implementation was actually successful. For more hints on where and how to quantify expectations, refer to Chapter 11 - Improving the Testing Process.
Lack of Buy In
The developers and testers that can potentially benefit from the use of a tool must be convinced that the tool will help them, that it is within their capability to use, and that they'll receive adequate training on how to use the tool. Would-be users are much less likely to enthusiastically learn and use the tool if their requirements and opinions are not taken into account during the tool selection and procurement.
Poor Training
| Key Point |
The amount of time and training required to implement and use tools successfully is frequently underestimated. |
Most test managers understand that testers must be trained on how to use new tools. Unfortunately, the amount of time and training is often underestimated. Similarly, training sometimes occurs too early and a significant time gap exists between the training and the first use of the tool. Training without immediate use is usually not very valuable. In fact, as a rough rule of thumb, if more than 6 months have passed since the training without using the tool, the potential users can be considered largely untrained.
Another training issue is how to use the tool to actually test software. In this case, we don't mean how to actually set up the tool or press the keys but, rather, we're talking about how the tool helps the testers select the test cases, set up the test cases, and determine the results - in other words, "how to test."
Automating the Wrong Thing
One common pitfall that should be avoided is automating the wrong thing. In the section What Should Be Automated, we concluded that there are a variety of human-intensive and repetitive tasks that are good candidates for automation. But there are also situations where automation is not as useful. For example, test cases that are intended to be run only once are not a good choice for automation. When a system is changing rapidly, it usually ends up taking more resources to automate the tests, since even the regression tests are unstable. Obviously, any tests designed to exercise the human interface with the system cannot be automated.
Choosing the Wrong Tool
| Key Point |
Not having a clear idea of the strategy on how to use the tool can result in choosing the wrong tool. |
If an attempt is made to automate the wrong thing, there's a good chance that the wrong tool will be chosen. In order to choose the right tool, it's important that requirements be formulated for the selection and use of the tool. It's important to note that as with all software requirements, it is necessary to prioritize them. There may be no one tool (of a certain type) that fulfills all of the requirements. Different potential users of the tool may also have different needs, so it may be possible (and unfortunate) that more than one of the same kind of tool may have to be selected, especially if there are many different environments in which the application being tested must run.
Ease of Use
Another major issue in tool selection is ease of use and the technical bent of the testing staff. Some testers may have been (or still are) developers. Some organizations may purposely choose testers with a development background, while other organizations may choose testers based on their business acumen. These testers may or may not like the idea of becoming "programmers," and in spite of what many vendors may say, using some tools requires the users to do some high-level programming.
Case Study 6-10: Some organizations enlist developers to assist in the automation of tests.
Using Developers As Test Automation Engineers
We once heard a speaker from a large telecom company describe their test automation efforts. Apparently, their testers came mostly from the user community and weren't comfortable using automated testing tools. The test manager arranged to have a developer assigned to each testing team to help them automate the manual scripts they had written. Not only did it hasten the automation of the tests, but it also sent a very clear message to the testers, "that your time is so important that we've gotten a developer to work with you." Unfortunately, some of the developers that had been sent to help the testers acted like they had received a prison sentence.
Even if your testers are programmers or former programmers, some tools are just hard to use. This is frustrating and may result in "shelfware."
Choosing the Wrong Vendor
This is a touchy subject, but we have to admit that all vendors do not meet the same standards. When choosing a vendor, it's important to choose one that the group is comfortable working with. The responsiveness of the tool vendor is a key factor in the long-term success of a tool. Another important issue in selecting a vendor is the training/consulting that they supply. Here are some things to consider when choosing a vendor:
- Do they only show the testing staff how to use the tool on "canned" examples, or do they actually provide training on your application?
- Are they available for assistance in the implementation of the tool?
- How difficult is it to get on-site assistance after the tool is purchased?
- When the tool is being demonstrated, does the vendor only send sales people or do they also send technical people who can answer in-depth questions?
- Do the vendors have an annual user's conference and/or regional users' groups? We have found that companies that do often have a greater customer focus than those that don't.
- Can the tool be modified to meet your needs? Some vendors are willing to help modify the tool for your particular needs and environment, while other vendors are not. If the tool works for you "as is" off-the-shelf, then this is not an issue. However, if you do need to have it modified, this can be a disqualifier for that vendor.
| Key Point |
Ask the tool vendor how they test their own software. This may give you valuable insight into how good their software really is. |
| Key Point |
|
Sometimes, it may be easier to choose different tools from the same vendor if they must work together. For example, a defect tracking tool may work with the configuration management tool from the same vendor, but not with another vendor's. Choosing the same vendor also allows the testers to become more familiar with the vendor's help desk, their personnel, and any particular design quirks of their tools. Some vendors may also provide a price break for buying multiple tools.
It's an excellent idea to ask the tool vendor to explain how they test their own software. Are their developers trained in testing methodologies and techniques? Can they explain their measures of test effectiveness? Are they ISO certified? What CMM level have they achieved? We wouldn't disqualify a vendor for not being ISO certified or at a low CMM level, but we might have more interest in one that is.
Another good idea is to ask other testing organizations how they like the vendor and their products. One good place to do this is at testing conferences like Software Testing Analysis and Review (STAR), EuroSTAR, Quality Week, The Test Automation Conference, Quality Assurance Institute (QAI) Conferences, and others. Not only can you see many tools demonstrated, but you'll also have the opportunity to talk to people who have actually purchased and used the tool. Don't forget, though, that their needs are not necessarily the same as yours.
| Key Point |
It's an excellent idea to ask the tool vendor to explain how they test their software. |
Unstable Software
| Key Point |
If the application being tested is unstable or changing rapidly, automating the test scripts may be difficult. |
Another important consideration in deciding whether or not to automate test cases is the stability of the software under test. If the software that is brought into the test environment is of poor quality or is changing rapidly for any reason, some of the test cases will potentially have to be changed each time the software under test (SUT) is changed. And, if the automated scripts take longer to write than manual scripts, then the SUT may not be a good candidate for automation. Some of our clients feel that automated scripts can be created as quickly as manual ones. In other words, they create the tests using a tool, rather than writing the tests and then automating them. This process is similar to us typing this text as we think of the sentences, rather than writing it down and later transcribing it. For these companies, it's just as easy and more economical to automate most tests (with the exception of some usability tests), including those that may only be executed once or twice.
The first foray many testing groups take into test automation is in the area of regression testing. The idea behind regression testing is that the regression tests are run after changes (corrections and additions) are made to the software to ensure that the rest of the system still works correctly. This means that we would like the regression test set to be fairly constant or stable. Since we know that creating automated scripts can sometimes take longer than creating manual ones, it doesn't make a lot of sense to automate the regression test set for an application that is changing so rapidly and extensively that the regression test cases are in a constant state of flux.
| Key Point |
Regression tests are tests that are run after changes (corrections and editions) are made to the software to ensure that the rest of the system still works correctly. |
Doing Too Much, Too Soon
Just as with any process improvement, it's generally a good idea to start small and limit the changes. Normally, we'd like to try the new tool out on a pilot project rather than do a global implementation. It's also generally a good idea to introduce one, or at least a limited number, of tools at one time. If multiple tools are implemented simultaneously, there's a tendency to stretch resources, and it becomes difficult to judge the impact of any one tool on the success of the testing effort.
Underestimating Time Resources
Poor scheduling and underestimating the amount of time and/or resources required for proper implementation can have a significant impact on the success or failure of a test tool. If a tool is purchased for a particular project, but isn't implemented on that project, there's little chance that it will be implemented on any other project. In reality, the tool will probably sit on the test bench or stay locked in the software cabinet until it's obsolete.
Implementing tools can take a long time. Some of our clients report that they spend years (that's not a typo) implementing a tool across an entire organization. Even implementing a tool in a small organization can take weeks or even months. You have to ensure that you have buy-in for that extended effort.
| Key Point |
If a tool is purchased for a particular project, but isn't implemented on that project, there's little chance that it will be implemented on any other project. |
Inadequate or Unique Test Environment
Now it's time to defend the tool vendors for a moment. Some testing organizations purchase tools that they aren't equipped to use, or their test environment is incapable of effectively utilizing these tools. By environment, we're talking about databases, files, file structures, source code control, configuration management, and so on. It's necessary to get your own development and testing environments in order if you want to successfully implement testing tools.
| Key Point |
If you build your own tools, you also have to test them, document them, and maintain them. |
One common test management issue is, "Should we build, buy, or as we (sometimes jokingly) say, 'steal' the tool?" We recommend that in almost every case it's better to buy the tool than to make it. Just think of all of the things that you don't like to do that are required if you build the tool yourself: document it, test it and maintain it. Joking aside, the vendors have amortized their development and testing of the tool across multiple users, where you would be making it for a limited audience. You wouldn't normally create your own word processor, would you? Of course, there are exceptions: If you have a very unique environment (embedded systems, for example), it might mean that you have to build the tool since there may not be any commercially available. Another example might be where you want to capitalize on some existing expertise and/or infrastructure. Let's say that your company is accustomed to using some kind of groupware like Lotus Notes. If it's difficult to introduce technical change in your organization, it might be worthwhile to build a defect tracking system on top of the groupware (assuming you can't find an off-the-shelf defect tracking system based on the groupware).
Poor Timing
Timing is everything. Trying to implement a major tool or automation effort in the midst of the biggest software release of all time is not a good strategy. We understand that there never really seems to be a good time to implement a tool (or improve processes or train people), but you have to use your common sense here. For example, many companies were buying (and sometimes using) regression testing tools to help in their Y2K testing. In most instances, starting in the fall of 1998, we stopped recommending that our clients buy these tools for the purpose of reaching their millennium goals, because we felt that implementing the tool at that late juncture would take too much of their remaining time. This time would be better spent on creating and running tests manually.
| Key Point |
Timing is everything. Trying to implement a major tool or automation effort in the midst of the biggest software release of all time is not a good strategy. |
Cost of Tools
Another reason that tool implementation never gets off the ground is cost. There are the obvious costs of licensing plus the not-so-obvious costs of implementing and training, which may actually exceed the licensing costs. Because some tools may cost thousands of dollars per copy, there may be a tendency to restrict the number of copies purchased, which can be very frustrating if the testers have to take turns to access the tool. While it may not be necessary to have a copy for every tester, there have to be enough to preclude testers from "waiting around" for access to the tool. We know of clients who have had testers queue up to enter defects into the only workstation with the defect tracking tool installed.
| Key Point |
Some vendors offer network licensing, which may be more economical than buying individual copies of a tool. |
Evaluating Testware
It should be clear to most testers and test managers that in the process of testing an application, the testers are also evaluating the work of the people who specified the requirements, design, and code. But who evaluates the work of the testers? In some organizations, an evaluation may be done by the QA department, but ultimately, it's the customers or end-users who judge the work done by the testers. Among his clients, Capers Jones states that "…the number of enterprises that have at least some bad test cases is approximately 100%. However, the number of clients that measure test case quality is much smaller: only about 20 enterprises out of 600 or so." Our colleague, Martin Pol, has stated that 20% of all defects are testing defects. Even though we believe that for the most part testers are smarter, better looking, and, in general, just better people than the general population (just kidding), they too are only human and can make mistakes. The intellectual effort in testing an application is often as great as the effort to create it in the first place, and, therefore, someone should evaluate the work of the testers.
| Key Point |
The intellectual effort in testing an application is often as great as the effort to create it in the first place and, therefore, someone should evaluate the work of the testers. |
Quality Assurance Group
Some organizations may have a quality assurance group that evaluates the quality of the testing effort. Other organizations use post-project reviews to evaluate (after the fact) the effectiveness of the development and testing efforts. Measures of test effectiveness such as coverage and defect removal efficiency are important topics in and of themselves. For more information about these topics, refer to the section on Measuring Test Effectiveness in Chapter 7 - Test Execution. In addition to these topics, however, it's also important to understand that there are a variety of other techniques that can be used to evaluate the effectiveness of testware. Generally speaking, you can evaluate your testware using many of the same techniques that are used to test the software.
Reviews
Reviews of test documents can be a useful way to analyze the quality of the testing. Walkthroughs, inspections, peer reviews, and buddy checks can be used to review test plans, test cases, procedures, etc. These reviews should include interested parties outside of the test group such as users, business analysts, and developers. You'll benefit from the diverse range of ideas while, at the same time, achieving buy-in for the testing effort.
| Key Point |
Some organizations find it useful to review test documents and the corresponding development documents at the same time. |
Dry Runs
| Key Point |
A test set is a group of test cases that cover a feature or system. |
It's often useful to conduct a dry run of the test cases, possibly on a previous version of the software. Even though the previous version is different and, therefore, some of the tests will (and should) fail because of these differences, many test cases should pass. The testers can then analyze the failed tests in order to determine if any of the failures can be attributed to incorrect tests, and subsequently upgrade the test set.
Traceability
Traceability is the process that ultimately leads to the coverage metrics described in the Test Effectiveness section. For our particular purposes, we simply want to ensure that the test cases can be mapped to the requirements, design, or code in order to maintain traceability. Tables 6-3, 6-4, and 6-5 list some sample requirements for an ATM, some sample test cases that might be used to test those requirements, and the resulting traceability matrix.
|
Requirement |
Description |
|
|---|---|---|
|
1.0 |
A valid user must be able to withdraw up to $200 or the maximum amount in the account. |
|
|
1.1 |
Withdrawal must be in increments of $20. |
|
|
1.2 |
User cannot withdraw more than account balance. |
|
|
1.3 |
If the maximum amount in the account is less than $200, user may withdraw an amount equal to the largest sum divisible by 20, but less than or equal to the maximum amount. |
|
|
1.4 |
User must be validated in accordance with Requirement 16. |
|
|
2.0 |
A valid user may make up to 5 withdrawals per day. |
|
|
… |
||
|
… |
|
Test Case |
Description |
|||
|---|---|---|---|---|
|
TC-01 |
Withdraw $20 from a valid account that contains $300. |
|||
|
TC-02 |
Withdraw $25 from a valid account that contains $300.
|
|||
|
TC-03 |
Withdraw $400 from a valid account that contains $300.
|
|||
|
TC-04 |
Withdraw $160 from a valid account that contains $165. |
|||
|
… |
|
Attribute |
TC #1 |
TC# 2 |
TC #3 |
TC #4 |
TC #5 |
|---|---|---|---|---|---|
|
Requirement 1.0 |
|||||
|
ü |
ü |
|||
|
ü |
||||
|
ü |
||||
|
Requirement 2.0 |
|||||
|
… |
|||||
|
… |
|||||
|
Requirement 16.0 |
ü |
ü |
ü |
ü |
ü |
|
Design 1.0 |
|||||
|
ü |
||||
|
ü |
||||
|
… |
|||||
|
… |
Table 6-5 shows a simplified requirements and design traceability matrix for our ATM example. Notice that it takes more than one test case to test Requirement 1.1. Also notice that test cases TC-01 through TC-04 are also used to test Requirement 16.0 in addition to testing the other requirements.
Defect Seeding
Defect seeding is a technique that was developed to estimate the number of bugs resident in a piece of software. This technique may seem a little more off the wall than other techniques for evaluating testware, and it's definitely not for everyone. Conceptually, a piece of software is "seeded" with bugs and then the test set is run to find out how many of the seeded bugs were discovered, how many were not discovered, and how many new (unseeded) bugs were found. It's then possible to use a simple mathematical formula to predict the number of bugs remaining. The formulae for calculating these values are shown in Figure 6-2.

Figure 6-2: Formulae for Calculating Seed Ratio and Estimated Number of Real Defects Still Present
| Key Point |
Most articles about defect seeding seem to be written by college professors and graduate students. Perhaps this means that defect seeding is only used in the world of academia? |
For example, if an organization inserted 100 seed bugs and later were only able to locate 75 of the seeded bugs, their seed ratio would be 0.75 (or 75%). If the organization had already discovered 450 "real" defects, then using the results from the seeding experiment, it would be possible to extrapolate that the 450 "real" defects represented only 75% of all of the real defects present. Then, the total number of real defects would be estimated to be 600. Since only 450 of the potential 600 real defects have been found, it appears that the product still has 150 "real" defects waiting to be discovered plus 25 seed bugs that still exist in the code. Don't forget to remove the seed bugs!
In our experience, seeding doesn't work very well as a means of predicting the number of undiscovered bugs, because it's virtually impossible to create the seeded bugs as creatively as programmers do in real life. In particular, seeded bugs seldom replicate the complexity, placement, frequency, etc. of developer-created defects. Still, this technique can be used to "test" the testware. Software with seeded or known bugs is subjected to the test set to determine if all of the seeded bugs are discovered. If some of the bugs are not found, the test set may be inadequate. If all of the bugs are found, the test set may or may not be adequate. (Great, just what we need - a technique that shows us when we've done a bad job, but can't confirm when we've done a good job!)
| Key Point |
Seeded bugs seldom replicate the complexity, placement, frequency, etc. of developer-created defects. |
Case Study 6-11: What do software bugs and fish have in common?
The Genesis of Defect Seeding
I've been telling a story in my classes for the last several years about the genesis of defect seeding in software. I tell my students that software defect seeding is a technique borrowed from the State Fishery Department. The fishery department would catch a batch of fish, tag them, and then release them. Later, a second batch of fish would be caught and the ratio of tagged to untagged fish was noted. It's then a simple mathematical calculation to determine the population of fish in the lake.
Some wise person, as I tell my class, decided to try this technique with software. After the software is seeded with bugs and tested, the ratio of seeded to unseeded bugs is computed. Using the same mathematical formula as our friends in the fisheries, we should be able to predict the number of bugs in the software. Well, apparently bugs are different from fish, because it didn't work nearly as well with software as it did with fish. No doubt, this technique failed because nobody can seed the software with bugs as creatively as programmers do.
While re-reading the book Software Defect Removal by Robert H. Dunn, I was surprised to learn that indeed software defect seeding did come from the work of scientists measuring populations of fish. The first suggestion of seeding software with defects seems to come from the work of Harlan Mills around 1970.
- Rick Craig
Some organizations also use software with known or seeded bugs as a training vehicle for new testers. The neophyte testers are asked to test a piece of software to see if they can find all of the bugs.
For all practical purposes, most of you don't have the time or resources to do defect seeding, and the technique is definitely not at the top of our priority list. Besides, isn't it just a little scary to put bugs in the software on purpose? Can you imagine what would happen if these bugs were shipped to customers by mistake? We know of one company where this actually happened.
| Key Point |
Some organizations use software with known or seeded bugs as a training vehicle for new testers. |
Mutation Analysis
Mutation analysis is sometimes used as a method of auditing the quality of unit testing. Basically, to do mutation analysis, you insert a mutant statement (e.g., bug) into a piece of code (e.g., a unit) and run the unit test cases to see if the mutant is detected, as illustrated in Figure 6-3.
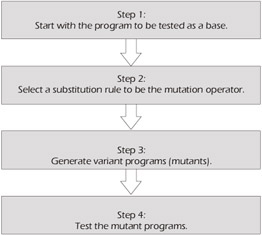
Figure 6-3: Steps in the Mutation Analysis Process
If the unit test set is comprehensive, the mutant should always be found. If the mutant is not found, the unit test set is not comprehensive. The converse, however, is not true. Just because the mutant is discovered, doesn't mean the test set is comprehensive.
| Key Point |
Mutation analysis is sometimes used as a method of auditing the quality of unit testing. |
Mutation analysis is only effective in organizations that have already achieved high levels of code coverage, since mutation analysis is based on the premise that virtually all lines of code have been covered and we're just looking for an anomaly. Our research has shown that only 25% of organizations do any form of formal unit testing. It's very likely that the coverage is so low for the 75% of organizations that don't do any formal unit testing, that it's actually a surprise if the mutant is found rather than if it isn't found.
So, it's our opinion that mutation analysis is primarily of value to organizations that are already doing comprehensive unit testing. We believe that these "advanced" organizations are also likely to be the ones using code coverage tools and therefore don't need mutation analysis anyway. The bottom line on mutation analysis is that unless you have a lot of time on your hands, move on to something more useful, like code coverage.
| Key Point |
Mutation analysis is only effective in organizations that have already achieved high levels of code coverage, since mutation analysis is based on the premise that virtually all lines of code have been covered and we're just looking for an anomaly. |
Testing Automated Procedures
When test procedures are automated, they effectively become software - just like the software under test. You can employ the same techniques for testing automated procedures that you would use for any other piece of software.
Preface
- An Overview of the Testing Process
- Risk Analysis
- Master Test Planning
- Detailed Test Planning
- Analysis and Design
- Test Implementation
- Test Execution
- The Test Organization
- The Software Tester
- The Test Manager
- Improving the Testing Process
- Some Final Thoughts…
- Appendix A Glossary of Terms
- Appendix B Testing Survey
- Appendix C IEEE Templates
- Appendix D Sample Master Test Plan
- Appendix E Simplified Unit Test Plan
- Appendix F Process Diagrams
EAN: 2147483647
Pages: 114
