Test Execution
Overview
"Knowledge must come through action; you can have no test which is not fanciful, save by trial."
— Sophocles
"Take time to deliberate, but when the time for action has arrived, stop thinking and go in."
— Napoleon Bonaparte
Test execution is the process of executing all or a selected number of test cases and observing the results. Although preparation and planning for test execution occur throughout the software development lifecycle, the execution itself typically occurs at or near the end of the software development lifecycle (i.e., after coding).
Before Beginning Test Execution
When most people think of testing, test execution is the first thing that comes to mind. So, why is there an emphasis on execution? Well, not only is test execution the most visible testing activity, it also typically occurs at the end of the development lifecycle after most of the other development activities have concluded or at least slowed down. The focus then shifts to test execution, which is now on the critical path of delivery of the software. By-products of test execution are test incident reports, test logs, testing status, and results, as illustrated in Figure 7-1.
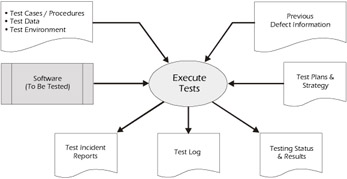
Figure 7-1: Executing the Tests
By now, you should know that we consider testing to be an activity that spans the entire software development lifecycle. According to Martin Pol, "test execution may only consume 40% or less of the testing effort," but it typically has to be concluded as quickly as possible, which means that there is often an intense burst of effort applied in the form of long hours and borrowed resources. Frequently, it also means that the test execution effort will be anxiously scrutinized by the developers, users, and management.
Deciding Who Should Execute the Tests
Who executes the tests is dependent upon the level of test. During unit test it is normal for developers to execute the tests. Usually each developer will execute their own tests, but the tests may be executed by another programmer using techniques like buddy testing (refer to Chapter 4 - Detailed Test Planning for more information on buddy testing). Integration tests are usually executed by the developers and/or the testers (if there is a test group). System tests could be executed by the developers, testers, end-users, or some combination thereof. Some organizations also use developers to do the system testing, but in doing so, they lose the fresh perspective provided by the test group.
Ideally, acceptance tests should be executed by end-users, although the developers and/or testers may also be involved. Table 7-1 shows one way that test execution may be divided, but there is really no definitive answer as to who should execute the tests. Ideally, we are looking for people with the appropriate skill set, although sometimes we're lucky to find somebody, anybody that's available.
|
Responsible Group |
Unit |
Integration |
System |
Acceptance |
|---|---|---|---|---|
|
Testers |
ü |
ü |
ü |
|
|
Developers |
ü |
ü |
ü |
|
|
End-Users |
ü |
ü |
During test execution, the manager of the testing effort is often looking for additional resources. Potential testers might include: members of the test team (of course), developers, users, technical writers, trainers, or help desk staff members. Some organizations even bring in college interns to help execute tests. College interns and new-hires can be used successfully if the test cases are explicit enough for them to understand and they've received training in how to write an effective incident report. We must be cautious, though, or we might spend more time training the neophyte testers than it's worth. On the other hand, having new testers execute tests is one way to quickly make them productive and feel like part of the team.
| Key Point |
"Newbies" make good candidates for usability testing because they're not contaminated by previous knowledge of the product. |
Deciding What to Execute First
| Key Point |
As a rule of thumb, we normally recommend that the regression test set (or at least the smoke test) be run in its entirety early on to flag areas that are obviously problematic. |
Choosing which test cases to execute first is a strategy decision that depends on the quality of the software, resources available, existing test documentation, and the results of the risk analysis. As a rule of thumb, we normally recommend that the regression test set (or at least the smoke test) be run in its entirety early on to flag areas that are obviously problematic. This strategy may not be feasible if the regression set is exceptionally large or totally manual. Then, the focus of the test should be placed on those features that were identified as high-risk during the software risk analysis described in Chapter 2. High-risk features will almost certainly contain all features that were extensively modified, since we know that changed features are typically assigned a higher likelihood of failure.
Writing Test Cases During Execution
Really, no matter how good you and your colleagues are at designing test cases, you'll always think of new test cases to write when you begin test execution (this is one of the arguments for techniques such as exploratory testing). As you run tests, you're learning more about the system and are in a better position to write the additional test cases. Unfortunately, in the heat of battle (test execution) when time is short, these tests are often executed with no record made of them unless an incident is discovered. This is truly unfortunate, because some of these "exploratory" test cases are frequently among the most useful ones created and we would like to add them to our test case repository, since we have a long-term goal of improving the coverage of the test set. One of our clients includes notes in the test log as a shorthand way of describing these exploratory test cases. Then, after release, they use the test log to go back and document the test cases and add them to the test case repository.
| Key Point |
No matter how good you and your colleagues are at designing test cases, you'll always think of new test cases to write when you begin test execution. |
Recording the Results of Each Test Case
Obviously, the results of each test case must be recorded. If the testing is automated, the tool will record both the input and the results. If the tests are manual, the results can be recorded right on the test case document. In some instances, it may be adequate to merely indicate whether the test case passed or failed. Failed test cases will also result in an incident report being generated. Often, it may be useful to capture screens, copies of reports, or some other output stream.
Test Log
The IEEE Std. 829-1998 defines the test log as a chronological record of relevant details about the execution of test cases. The purpose of the test log shown in Figure 7-2 is to share information among testers, users, developers, and others and to facilitate the replication of a situation encountered during testing.
IEEE Std. 829-1998 for Software Test Documentation
Template for Test Log
Contents
1.
Test Log Identifier
2.
Description
3.
Activity and Event Entries
Figure 7-2: Test Log Template from IEEE Std. 829-1998
In order for a test log to be successful, the people that must submit data into and eventually use the log must want to do so. Forcing participants to use a test log when they don't want to use it is seldom successful. In order to make it desirable, the test log must be easy to use and valuable to its users.
| Key Point |
Since the primary purpose of the test log is to share information rather than analyze data, we recommend making the log free form. |
Since the primary purpose of the test log is to share information rather than analyze data, we recommend making the log free form, instead of using fields or buttons, which are desirable in other areas such as defect tracking. If the testing team is small and co-located, the test log might be as simple as a spiral notebook in which testers and/or developers can make log entries. Alternatively, it might be more convenient to have a word-processed document or e-mailed form. If the team members are geographically separated, the test log would probably be better served in the form of a Web page or company intranet. Wherever it is, the test log should be easy to access and update. One of our clients, for example, has a continuously open active window on their monitor where a thought can be entered at any time.
Table 7-2 shows an example of a test log sheet. Notice that even though it mentions the writing up of PR#58, it doesn't go into any detail. The purpose of the log is not to document bugs (we have defect tracking systems for that), but rather to record events that you want to share among the team members or use for later recall. The larger the team and/or the project and the more geographically separated they are, the more important the log becomes.
|
Description: Online Trade |
Date: 01/06/2002 |
|
|---|---|---|
|
ID |
Time |
Activity and Event Entries |
|
1 |
08:00 |
Kicked off test procedure #18 (buy shares) with 64 users on test system. |
|
2 |
09:30 |
Test system crashed. |
|
3 |
10:00 |
Test system recovered. |
|
4 |
10:05 |
Kicked off test procedure #19 (sell shares). |
|
5 |
11:11 |
PR #58 written up. |
|
6 |
12:00 |
New operating system patch installed. |
Test Incident Reports
Incidents can be defined as any unusual result of executing a test (or actual operation). Incidents may, upon further analysis, be categorized as defects or enhancements, or merely retain their status as an incident if they're determined to be inconsequential or the result of a one-time anomaly. A defect (or bug) is a flaw in the software with the potential to cause a failure. The defect can be anywhere: in the requirements, design, code, test, and/or documentation. A failure occurs when a defect prevents a system from accomplishing its mission or operating within its specifications. Therefore, a failure is the manifestation of one or more defects. One defect can cause many failures or none, depending on the nature of the defect. An automated teller machine (ATM), for example, may fail to dispense the correct amount of cash, or an air defense system may fail to track an incoming missile. Testing helps you find the failure in the system, but then you still have to track the failure back to the defect.
| Key Point |
Some software testing books say, "The only important test cases are the ones that find bugs." We believe that proving that some attribute of the system works correctly is just as important as finding a bug. |
Defect tracking is an important activity and one that almost all test teams accomplish. Defect tracking is merely a way of recording software defects and their status. In most organizations, this process is usually done using a commercial or "home-grown" tool. We've seen many "home-grown" tools that were developed based on applications such as Infoman, Lotus Notes, Microsoft Access, and others.
Case Study 7-1: On September 9, 1945, a moth trapped between relays caused a problem in Harvard University's Mark II Aiken Relay Calculator.
The First Computer Bug
I'm very proud of the fact that I got to meet Rear Admiral Grace Murray Hopper, the famous computer pioneer, on two separate occasions. On one of these meetings, I even received one of Admiral Hopper's "nanoseconds," a small piece of colored "bell" wire about a foot or so long, which Grace often gave to her many admirers to show them how far electricity would travel in one nanosecond.
Among Rear Admiral Grace Murray Hopper's many accomplishments were the invention of the programming language COBOL and the attainment of the rank of Rear Admiral in the U.S. Navy (one of the first women to ever reach this rank). But, ironically, Admiral Hopper is probably most famous for an event that occurred when she wasn't even present.
Admiral Hopper loved to tell the story of the discovery of the first computer bug. In 1945, she was working on the Harvard University Mark II Aiken Relay Calculator. On September 9 of that year, while Grace was away, computer operators discovered that a moth trapped between the relays was causing a problem in the primitive computer. The operators removed the moth and taped it to the computer log next to the entry, "first actual case of a bug being found." Many people cite this event as the first instance of using the term "bug" to mean a defect. The log with the moth still attached is now located in the History of American Technology Museum.
Even though this is a great story, it's not really the first instance of using the term "bug" to describe a problem in a piece of electrical gear. Radar operators in World War II referred to electronic glitches as bugs, and the term was also used to describe problems in electrical gear as far back as the 1900s. The following is a slide that I used in a presentation that I gave at a testing conference in the early 1980s shortly after meeting Admiral Grace Hopper.
— Rick Craig

IEEE Template for Test Incident Report
An incident report provides a formal mechanism for recording software incidents, defects, and enhancements and their status. Figure 7-3 shows the IEEE template for a Test Incident Report. The parts of the template in Figure 7-3 shown in italics are not part of the IEEE template, but we've found them to be useful to include in the Test Incident Report. Please feel free to modify this (or any other template) to meet your specific needs.
IEEE Std. 829-1998 for Software Test Documentation Template for Test Incident Report
Contents
1.
Incident Summary Report Identifier
2.
Incident Summary
3.
Incident Description
3.1
Inputs
3.2
Expected Results
3.3
Actual Results
3.4
Anomalies
3.5
Date and Time
3.6
Procedure Step
3.7
Environment
3.8
Attempts to Repeat
3.9
Testers
3.10
Observers
4.
Impact
5.
Investigation
6.
Metrics
7.
Disposition
Figure 7-3: Template for Test Incident Report from IEEE Std. 829-1998
Incident Summary Report Identifier
The Incident Summary Report Identifier uses your organization's incident tracking numbering scheme to identify this incident and its corresponding report.
Incident Summary
The Incident Summary is the information that relates the incident back to the procedure or test case that discovered it. This reference is often missing in many companies and is one of the first things that we look for when we're auditing their testing processes. Absence of the references on all incident reports usually means that the testing effort is largely ad hoc. All identified incidents should have a reference to a test case. If an incident is discovered using ad hoc testing, then a test case should be written that would have found the incident. This test case is important in helping the developer recreate the situation, and the tester will undoubtedly need to re-run the test case after any defect is fixed. Also, defects have a way of reappearing in production and this is a good opportunity to fill in a gap or two in the test coverage.
| Key Point |
All identified incidents should have a reference to a test case. If an incident is discovered using ad hoc testing, then a test case should be written that would have found the incident. |
Incident Description
The author of the incident report should include enough information so that the readers of the report will be able to understand and replicate the incident. Sometimes, the test case reference alone will be sufficient, but in other instances, information about the setup, environment, and other variables is useful. Table 7-3 describes the subsections that appear under Incident Description.
|
Section Heading |
Description |
|---|---|
|
4.1 Inputs |
Describes the inputs actually used (e.g., files, keystrokes, etc.). |
|
4.2 Expected Results |
This comes from the test case that was running when the incident was discovered. |
|
4.3 Actual Results |
Actual results are recorded here. |
|
4.4 Anomalies |
How the actual results differ from the expected results. Also record other data (if it appears to be significant) such as unusually light or heavy volume on the system, it's the last day of the month, etc. |
|
4.5 Date and Time |
The date and time of the occurrence of the incident. |
|
4.6 Procedure Step |
The step in which the incident occurred. This is particularly important if you use long, complex test procedures. |
|
4.7 Environment |
The environment that was used (e.g., system test environment or acceptance test environment, customer 'A' test environment, beta site, etc.) |
|
4.8 Attempts to Repeat |
How many attempts were made to repeat the test? |
|
4.9 Testers |
Who ran the test? |
|
4.10 Observers |
Who else has knowledge of the situation? |
Impact
The Impact section of the incident report form refers to the potential impact on the user, so the users or their representative should ultimately decide the impact of the incident. The impact will also be one of the prime determinants in the prioritization of bug fixes, although the resources required to fix each bug will also have an effect on the prioritization.
One question that always arises is, "Who should assign the impact rating?" We believe that the initial impact rating should be assigned by whoever writes the incident report. This means that if the incident is written as a result of an incorrect response to a test case, the initial assignment will be made by a tester.
Many people think that only the user should assign a value to the impact, but we feel that it's important to get an initial assessment of the impact as soon as possible. Most testers that we know can correctly determine the difference between a really critical incident and a trivial one. And, it's essential that incidents that have the potential to become critical defects be brought to light at the earliest opportunity. If the assignment of criticality is deferred until the next meeting of the Change Control Board (CCB) or whenever the user has time to review the incident reports, valuable time may be lost. Of course, when the CCB does meet, one of their most important jobs is to review and revise the impact ratings.
| Key Point |
It's essential that incidents that have the potential to become critical defects be brought to light at the earliest opportunity. |
A standardized organization-wide scale should be devised for the assignment of impact. Oftentimes, we see a scale such as Minor, Major, and Critical; Low, Medium, and High; 1 through 5; or a variety of other scales. Interestingly enough, we discovered a scale of 1 through 11 at one client site. We thought that was strange and when we queried them, they told us that they had so many bugs with a severity (or impact) of 10 that they had to create a new category of 11. Who knows how far they may have expanded their impact scale by now (…35, 36, 37)? It's usually necessary to have only four or five severity categories. We're not, for example, looking for a severity rating of 1 to 100 on a sliding scale. After all, how can you really explain the difference between a severity of 78 and 79? The key here is that all of the categories are defined.
If your categories are not defined, but just assigned on a rolling scale, then the results will be subjective and very much depend on who assigns the value. The imprecision in assigning impact ratings can never be totally overcome, but it can be reduced by defining the parameters (and using examples) of what minor, major, and critical incidents look like. Case Study 7-2 shows the categories chosen by one of our clients.
Case Study 7-2: Example Impact Scale
Example of Minor, Major, and Critical Defects
Minor:
Misspelled word on the screen.
Major:
System degraded, but a workaround is available.
Critical:
System crashes.
| Key Point |
The imprecision in assigning impact ratings can never be totally overcome, but it can be reduced by defining the parameters (and using examples) of what minor, major, and critical incidents look like. |
Investigation
The Investigation section of the incident report explains who found the incident and who the key players are in its resolution. Some people also collect some metrics here on the estimated amount of time required to isolate the bug.
Metrics
Initially, most testers automatically assume that every incident is a software problem. In some instances, the incident may be a hardware or environment problem, or even a testing bug! Some of our clients are very careful to record erroneous tests in the defect tracking system, because it helps them to better estimate their future testing (i.e., how many bad test cases are there?) and helps in process improvement. As an aside, one company told us that recording erroneous test cases helped give their testers a little extra credibility with the developers, since the testers were actually admitting and recording some of their own bugs. In most cases, though, testers don't normally like to record their own bugs, just as many developers don't like to record their own unit testing bugs.
| Key Point |
The Metrics section of the incident report can be used to record any number of different metrics on the type, location, and cause of the incidents. |
The Metrics section of the incident report can be used to record any number of different metrics on the type, location, and cause of the incidents. While this is an ideal place to collect metrics on incidents, be cautious not to go overboard. If the incident report gets too complicated or too long, testers, users, and developers will get frustrated and look for excuses to avoid recording incidents.
Case Study 7-3: What happens when there's a defect in the testware?
Good Initiative, But Poor Judgment
I learned that every bug doesn't have to be a software bug the hard way. In the late 1980's, I was the head of an independent test team that was testing a critical command and control system for the U.S. military. During one particularly difficult test cycle, we discovered an alarming number of bugs. One of my sergeants told me that I should go inform the development manager (who was a Brigadier General, while I was only a Captain) that his software was the worst on the planet. I remember asking the sergeant, "Are you sure all of the tests are okay?" and he replied, "Yes, sir. It's the software that's bad."
In officer training school we were taught to listen to the wisdom of our subordinate leaders, so I marched up to the General's office and said, "Sir, your software is not of the quality that we've come to expect." Well, you can almost guess the ending to this story. The General called together his experts, who informed me that most of the failures were caused by a glitch in our test environment. At that point, the General said to me, "Captain, good initiative, but poor judgment," before I was dismissed and sent back to my little windowless office.
The moral of the story is this: If you want to maintain credibility with the developers, make sure your tests are all valid before raising issues with the software.
— Rick Craig
Disposition (Status)
In a good defect tracking system, there should be the capability to maintain a log or audit trail of the incident as it goes through the analysis, debugging, correction, re-testing, and implementation process. Case Study 7-4 shows an example of an incident log recorded by one of our clients.
Case Study 7-4: Example Incident Log Entry
Example Incident Log
2/01/01 Incident report opened.
2/01/01 Sent to the CCB for severity assignment and to Dominic for analysis.
2/03/01 Dominic reports that the fix is fairly simple and is in code maintained by Hunter C.
2/04/01 CCB changed the severity to Critical.
2/04/01 Bug fix assigned to Hunter.
2/06/01 Bug fix implemented and inspection set for 2/10/01.
2/10/01 Passed inspection and sent to QA.
2/12/01 Bug fix is re-tested and regression run. No problems encountered.
2/12/01 Incident report closed.
| Note |
Closed incident reports should be saved for further analysis of trends and patterns of defects. |
Writing the Incident Report
| Key Point |
Most incident tracking tools are also used to track defects, and the tools are more commonly called defect tracking tools than incident tracking tools. |
We are often asked, "Who should write the incident report?" The answer is, "Whoever found the incident!" If the incident is found in the production environment, the incident report should be written by the user - if it's culturally acceptable and if the users have access to the defect tracking system. If not, then the help desk is a likely candidate to complete the report for the user. If the incident is found by a tester, he or she should complete the report. If an incident is found by a developer, it's desirable to have him or her fill out the report. In practice, however, this is often difficult, since most programmers would rather just "fix" the bug than record it. Very few of our clients (even the most sophisticated ones) record unit testing bugs, which are the most common type of bugs discovered by developers. If the bug is discovered during the course of a review, it should be documented by the person who is recording the minutes of the review.
| Key Point |
Very few of our clients record unit testing bugs, which are the most common type of bugs discovered by developers. |
It's a good idea to provide training or instructions on how to write an incident report. We've found that the quality of the incident report has a significant impact on how long it takes to analyze, recreate, and fix a bug. Specifically, training should teach the authors of the incident reports to:
- focus on factual data
- ensure the situation is re-creatable
- not use emotional language (e.g., bold text, all caps)
- not be judgmental
Attributes of a Defect Tracking Tool
Most organizations that we work with have some kind of defect tracking tool. Even organizations that have little else in the way of formal testing usually have some type of tracking tool. This is probably because in many organizations, management's effort is largely focused on the number, severity, and status of bugs.
| Key Point |
|
We also find that some companies use commercial defect tracking tools, while others create their own tools using applications that they're familiar with such as MS-Word, MS-Access, Lotus Notes, Infoman, and others. Generally, we urge companies to buy tools rather than make them themselves unless the client environment is so unique that there is no tool that will fit their requirements. Remember that if you build the tool yourself, you also have to document it, test it, and maintain it.
Ideally, a defect tracking tool should be easy to use, be flexible, allow easy data analysis, integrate with a configuration management system, and provide users with easy access. Ease of use is why so many companies choose to build their own defect tracking tool using some familiar product like Lotus Notes. If the tool is difficult to use, is time-consuming, or asks for a lot of information that the author of an incident report sees no need for, use of the tool will be limited and/or the data may not be accurate. Software engineers have a way of recording "any old data" in fields that they believe no one will use.
| Key Point |
Ideally, a defect tracking tool should be easy to use, be flexible, allow easy data analysis, integrate with a configuration management system, and provide users with easy access. |
A good defect tracking tool should allow the users to modify the fields to match the terminology used within their organization. In other words, if your organization purchases a commercial tool that lists severity categories of High, Medium, and Low, users should be able to easily change the categories to Critical, Major, Minor, or anything else they require.
| Key Point |
A good defect tracking tool should allow the users to modify the fields to match the terminology used within their organization. |
The tool should facilitate the analysis of data. If the test manager wants to know the distribution of defects against modules, it should be easy for him or her to get this data from the tool in the form of a table or chart. This means that most of the input into the tool must be in the form of discrete data rather than free-form responses. Of course there will always be a free-form description of the problem, but there should also be categories such as distribution, type, age, etc. that are discrete for ease of analysis. Furthermore, each record needs to have a dynamic defect log associated with it in order to record the progress of the bug from discovery to correction (refer to Case Study 7-4).
Ideally, the incident reports will be linked to the configuration management system used to control the builds and/or versions.
All users of the system must be able to easily access the system at all times. We have occasionally encountered organizations where incident reports could only be entered into the defect tracking system from one or two computers.
Using Multiple Defect Tracking Systems
Although we personally prefer to use a single defect tracking system throughout the organization, some organizations prefer to use separate defect tracking systems for production and testing bugs. Rather than being a planned event, separate defect tracking systems often evolve over time, or are implemented when two separate systems are initially created for separate purposes. For example, the production defect tracking system may have originally been designed for tracking support issues, but later modified to also track incidents. If you do use separate systems, it's beneficial to ensure that field names are identical for production and test bugs. This allows the test manager to analyze trends and patterns in bugs from test to production. Unfortunately, many of you are working in organizations that use entirely different vocabularies and/or metrics for bugs discovered in test versus those found by the user.
| Key Point |
Part of the process of analyzing an incident report is to determine if the failure was caused by a new bug, or if the failure is just another example of the same old bug. |
It's useful to analyze trends and patterns of the failures, and then trends and patterns of the defects. Generally, part of the process of analyzing an incident report is to determine if the failure was caused by a new bug, or if the failure is just another example of the same old bug. Obviously, the development manager is most concerned about the number of defects that need to be fixed, whereas the user may only be concerned with the number of failures encountered (even if every failure is caused by the same bug).
Testing Status and Results
One of the first issues that a test manager must deal with during test execution is finding a way to keep track of the testing status. How the testing status will be tracked should be explained in the master test plan (refer to Chapter 3 - Master Test Planning). Basically, testing status is reported against milestones completed; number, severity, and location of defects discovered; and coverage achieved. Some test managers may also report testing status based upon the stability, reliability, or usability of the system. For our purposes, however, we'll measure these "…ilities" based on their corresponding test cases (e.g., reliability test cases, usability test cases, etc.).
Measuring Testing Status
The testing status report (refer to Table 7-4) is often the primary formal communication channel that the test manager uses to inform the rest of the organization of the progress made by the testing team.
|
Project: Online Trade Date: 01/05/02 |
|||||
|---|---|---|---|---|---|
|
Feature Tested |
Total Tests |
# Complete |
% Complete |
# Success |
% Success (to date) |
|
Open Account |
46 |
46 |
100 |
41 |
89 |
|
Sell Order |
36 |
25 |
69 |
25 |
100 |
|
Buy Order |
19 |
17 |
89 |
12 |
71 |
|
… |
… |
… |
… |
… |
… |
|
… |
… |
… |
… |
… |
… |
|
… |
… |
… |
… |
… |
… |
|
Total |
395 |
320 |
81 |
290 |
91 |
Notice that Table 7-4 shows, at a glance, how much of the test execution is done and how much remains unfinished. Even so, we must be careful in how we interpret the data in this chart and understand what it is that we're trying to measure. For example, Table 7-4 shows that the testing of this system is 81% complete. But is testing really 81% complete? It really shows that 81% of the test cases have been completed, not 81% of the testing. You should remember that all test cases are definitely not created equal. If you want to measure testing status against a timeline, you must weight the test cases based on how long they take to execute. Some test cases may take only a few minutes, while others could take hours.
| Key Point |
If you want to measure testing status against a time line, you have to weight the test cases based on how long they take to execute, but if you want to measure status against functionality, then the test cases must be weighted based on how much of the functionality they cover. |
On the other hand, if you want to measure status against functionality (i.e., how much of the user's functionality has been tested?), then the test cases must be weighted based on how much of the functionality they cover. Some test cases may cover several important requirements or features, while others may cover fewer or less important features.
Test Summary Report
| Key Point |
The purpose of the Test Summary Report is to summarize the results of the testing activities and to provide an evaluation based on the results. |
The purpose of the Test Summary Report is to summarize the results of the testing activities and to provide an evaluation based on these results. The summary report provides advice on the release readiness of the product and should document any known anomalies or shortcomings in the product. This report allows the test manager to summarize the testing and to identify limitations of the software and the failure likelihood. There should be a test summary report that corresponds to every test plan. So, for example, if you are working on a project that had a master test plan, an acceptance test plan, a system test plan, and a combined unit/integration test plan, each of these should have its own corresponding test summary report, as illustrated in Figure 7-4.
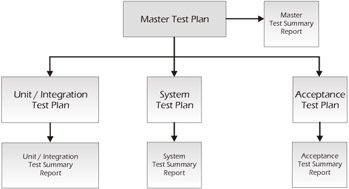
Figure 7-4: There Should Be a Test Summary Report for Each Test Plan
In essence, the test summary report is an extension of the test plan and serves to "close the loop" on the plan.
One complaint that we often hear about the test summary report is that, since it occurs at the end of the test execution phase, it's on the critical path of the delivery of the software. This is true, but we would also like to add that completing the test summary report doesn't take a lot of time. In fact, most of the information contained within the report is information that the test manager should be collecting and analyzing constantly throughout the software development and testing lifecycles. You could consider using most of the information in the test summary report as a test status report. Just think of the test summary report as a test status report on the last day of the project.
| Key Point |
Think of the Test Summary Report as a test status report on the last day of the project. |
Here's a tip that you may find useful - it works well for us. Once we begin the execution of the tests, we seldom have time to keep the test plan up-to-date. Instead of updating the plan, we keep track of the changes in the test summary report's Variances section, and after the software under test has moved on, we go back and update the plan.
The Test Summary Report shown in Figure 7-5 conforms to IEEE Std. 829-1998 for Software Test Documentation. Sections that are not part of the IEEE template are indicated in italics.
IEEE Std. 829-1998 for Software Test Documentation
Template for Test Summary Report
Contents
1.
Test Summary Report Identifier
2.
Summary
3.
Variances
4.
Comprehensive Assessment
5.
Summary of Results
5.1
Resolved Incidents
5.2
Unresolved Incidents
6.
Evaluation
7.
Recommendations
8.
Summary of Activities
9.
Approvals
Figure 7-5: Template for Test Summary Report from IEEE-829-1998
Test Summary Report Identifier
The Report Identifier is a unique number that identifies the report and is used to place the test summary report under configuration management.
Summary
This section summarizes what testing activities took place, including the versions/releases of the software, the environment and so forth. This section will normally supply references to the test plan, test-design specifications, test procedures, and test cases.
Variances
This section describes any variances between the testing that was planned and the testing that really occurred. This section is of particular importance to the test manager because it helps him or her see what changed and provides some insights into how to improve the test planning in the future.
Comprehensive Assessment
In this section, you should evaluate the comprehensiveness of the testing process against the criteria specified in the test plan. These criteria are based upon the inventory, requirements, design, code coverage, or some combination thereof. Features or groups of features that were not adequately covered need to be addressed here, including a discussion of any new risks. Any measures of test effectiveness that were used should be reported and explained in this section.
Summary of Results
Summarize the results of testing here. Identify all resolved incidents and summarize their resolution. Identify all unresolved incidents. This section will contain metrics about defects and their distribution (refer to the section on Pareto Analysis in this chapter).
Evaluation
Provide an overall evaluation of each test item, including its limitations. This evaluation should be based upon the test results and the item pass/fail criteria. Some limitations that might result could include statements such as "The system is incapable of supporting more than 100 users simultaneously" or "Performance slows to x if the throughput exceeds a certain limit." This section could also include a discussion of failure likelihood based upon the stability exhibited during testing, reliability modeling and/or an analysis of failures observed during testing.
Recommendations
We include a section called Recommendations because we feel that part of the test manager's job is to make recommendations based on what they discover during the course of testing. Some of our clients dislike the Recommendations section because they feel that the purpose of the testing effort is only to measure the quality of the software, and it's up to the business side of the company to act upon that information. Even though we recognize that the decision of what to do with the release ultimately resides with the business experts, we feel that the authors of the test summary report should share their insights with these decision makers.
Summary of Activities
Summarize the major testing activities and events. Summarize resource consumption data; for example, total staffing level, total machine time, and elapsed time used for each of the major testing activities. This section is important to the test manager, because the data recorded here is part of the information required for estimating future testing efforts.
Approvals
Specify the names and titles of all persons who must approve this report. Provide space for the signatures and dates. Ideally, we would like the approvers of this report to be the same people who approved the corresponding test plan, since the test summary report summarizes all of the activities outlined in the plan (if it's been a really bad project, they may not all still be around). By signing this document, the approvers are certifying that they concur with the results as stated in the report, and that the report, as written, represents a consensus of all of the approvers. If some of the reviewers have minor disagreements, they may be willing to sign the document anyway and note their discrepancies.
When Are We Done Testing?
So, how do we know when we're done testing? We'd like to think that this would have been spelled out in the exit criteria for each level. Meeting the exit criteria for the acceptance testing is normally the flag you're looking for, which indicates that testing is done and the product is ready to be shipped, installed, and used. We believe that Boris Beizer has nicely summed up the whole issue of when to stop testing:
| Key Point |
|
"There is no single, valid, rational criterion for stopping. Furthermore, given any set of applicable criteria, how each is weighed depends very much upon the product, the environment, the culture and the attitude to risk."
At the 1999 Application Software Measurement (ASM) Conference, Bob Grady identified the following key points associated with releasing a product too early:
- Many defects may be left in the product, including some "show-stoppers."
- The product might be manageable with a small number of customers with set expectations.
- A tense, reactive environment may make it difficult for team members to switch their focus to new product needs.
- The tense environment could result in increased employee turnover.
- Customers' frustration with the product will continue.
Grady also identified the following key points associated with releasing the product too late:
- Team members and users are confident in the quality of the product.
- Customer support needs are small and predictable.
- The organization may experience some loss of revenue, long-term market share, and project cancellations, thus increasing the overall business risk.
- The organization may gain a good reputation for quality, which could lead to capturing a greater market share in the long term.
When you consider the implications associated with releasing too early or too late, it's clear that important decisions (such as when to stop testing) should be based on more than one metric that way, one metric can validate the other metric. Some commonly used metrics are explained in the paragraphs that follow.
Defect Discovery Rate
Many organizations use the defect discovery rate as an important measure to assist them in predicting when a product will be ready to release. When the defect discovery rate drops below the specified level, it's often assumed (sometimes correctly) that the product is ready to be released. While a declining discovery rate is typically a good sign, one must remember that other forces (less effort, no new test cases, etc.) may cause the discovery rate to drop. This is why it is normally a good idea to base important decisions on more than one supporting metric.
Notice in Figure 7-6 that the number of new defects discovered per day is dropping and, if we assume that the effort is constant, the cost of discovering each defect is also rising.
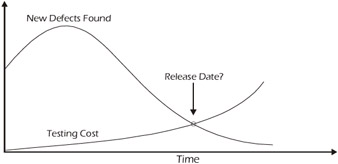
Figure 7-6: Defect Discovery Rate
At some point, therefore, the cost of continuing to test will exceed the value derived from the additional testing. Of course, all we can do is estimate when this will occur, since the nature (severity) of the undiscovered bugs is unknown. This can be offset somewhat if risk-based techniques are used. In fact, another useful metric to determine whether the system is ready to ship is the trend in the severity of bugs found in testing. If risk-based techniques are used, then we would expect not only the defect discovery rate to drop, but also the severity of the defects discovered. If this trend is not observed, then that's a sign that the system is not ready to ship.
Remaining Defects Estimation Criteria
One method of determining "when to ship" is to base the decision on an estimate of the number of defects expected. This can be accomplished by comparing the defect discovery trends with those from other, similar projects. This normally requires that an extensive amount of data has been collected and managed in the past, and will also require normalization of the data to take into account the differences in project scope, complexity, code quality, etc.
Running Out of Resources
It's true, running out of time or budget may be a valid reason for stopping. Many of us have certainly recommended the release of a product that we felt was fairly poor in quality because it was better than what the user currently had. Remember, we're not striving for perfection, only acceptable risk. Sometimes, the risk of not shipping (due to competition, failure of an existing system, etc.) may exceed the (business) risk of shipping a flawed product.
Case Study 7-5: In the world of software, timing can be everything.
Great Software, But Too Late
One of our clients several years ago made a PC-based tax package. They felt that they had created one of the best, easiest-to-use tax packages on the market. Unfortunately, by the time their product had met all of their quality goals, most people who would normally buy and use their product had already purchased a competitor's product. Our client was making a great product that was of very little use (since it was too late to market). The next year the company relaxed their quality goals (just a little), added resources on the front-end processes, and delivered a marketable product in a timely fashion.
Measuring Test Effectiveness
When we ask our students, "How many of you think that the time, effort, and money spent trying to achieve high-quality software in your organization is too much?" we get lots of laughs and a sprinkling of raised hands. When we ask the same question, but change the end of the sentence to "…too little?" almost everyone raises a hand. Changing the end of the sentence to "…about right?" gets a few hands (and smug looks). Generally, there may be one or two people who are undecided and don't raise their hands at all.
| Question #1 |
Do you think that the time, effort, and money spent trying to achieve high-quality software in your organization is:
|
Next, we ask the same people, "How many of you have a way to measure test effectiveness?" and we get almost no response. If you don't have a way to measure test effectiveness, it's almost impossible to answer question #1 with anything other than, "It's a mystery to me." Knowing what metrics to use to measure test effectiveness and implementing them is one of the greatest challenges that a test manager faces.
| Question #2 |
Do you have a way to measure test effectiveness? |
We've discovered the following key points regarding measures of test effectiveness:
- Many organizations don't consciously attempt to measure test effectiveness.
- All measures of test effectiveness have deficiencies.
- In spite of the weaknesses of currently used measures, it's still necessary to develop a set to use in your organization.
| Gilb's Law |
|
In this section, we'll analyze some of the problems with commonly used measures of test effectiveness, and conclude with some recommendations. In working with dozens of organizations, we've found that most attempts to measure test effectiveness fall into one of the three major categories illustrated in Figure 7-7.
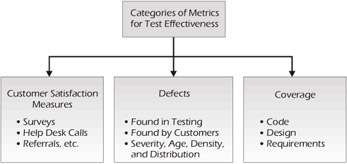
Figure 7-7: Categories of Metrics for Test Effectiveness
Customer Satisfaction Measures
Many companies use customer satisfaction measures to determine if their customers are happy with the software they have received. The most common customer satisfaction measures are usually gathered by analyzing calls to the help desk or by using surveys. Both of these measures have general deficiencies and other problems specific to testing. First, let's examine surveys.
Surveys
Surveys are difficult to create effectively. It's hard for most of us to know specifically what questions to ask and how to ask them. In fact, there's a whole discipline devoted to creating, using, and understanding surveys and their results. Case Studies 7-6 and 7-7 describe some of the pitfalls associated with designing and administering surveys.
Case Study 7-6: The Science of Survey Design
What Do You Mean, "I Need an Expert"?
When I was working on a large survey effort in the early 1990s, my colleague suggested that I should have a "survey expert" review my survey. I was a little miffed, since I had personally written the survey and I was sure that I knew how to write a few simple questions. Still, I found a "survey expert" at a local university and asked him to review my software survey. I was surprised when he had the nerve to say, "Come back tomorrow and I'll tell you how your respondents will reply to your survey." Sure enough, the next day he gave me a completed survey (and a bill for his services). I thought that he was pretty presumptuous since he was not a "software expert," but after administering the survey to a few of my colleagues, I was amazed that this professor had predicted almost exactly how they would respond!
How a respondent answers a survey is dependent on all kinds of issues like the order of the questions, use of action verbs, length of the survey, and length of the questions used. So, the moral of the story is this: If you want to do a survey, we recommend that you solicit help from an "expert."
— Rick Craig
Case Study 7-7: Personal Bias in Survey Design
The Waitress Knows Best
Another experience I had with a survey occurred several years ago at a restaurant that I own in Tampa called "Mad Dogs and Englishmen." My head waitress decided to create a customer satisfaction survey (on her own initiative). You have to love employees like that! The survey had two sections: one rated the quality of food as Outstanding, Excellent, Above Average, Average, and Below Average, and the other section rated service.
The service scale included Outstanding, Excellent, and Above Average. I asked her about the missing Average and Below Average categories and she assured me that as long as she was in charge, no one would ever get average or below-average service! I realized that the survey designer's personal bias can (and will) significantly influence the survey results!
— Rick Craig

| Key Point |
Customer satisfaction surveys don't separate the effectiveness of the test from the quality of the software. Customer satisfaction measures are probably useful for your company, and are of interest to the test manager, but don't, in themselves, solve the problem of how to measure test effectiveness. |
All issues of construction aside, surveys have more specific problems when you try to use them to measure the effectiveness of testing. The biggest issue, of course, is that it's theoretically possible that the developers could create a really fine system that would please the customer even if the testing efforts were shoddy or even non-existent. Customer satisfaction surveys do not separate the quality of the development effort from the effectiveness of the testing effort. So, even though surveys may be useful for your organization, they don't give the test manager much of a measure of the effectiveness of the testing effort. On the other hand, if the surveys are all negative, that gives the test manager cause for concern.
Help Desk Calls
Another customer satisfaction measure that is sometime used is the number of calls to the help desk. This metric suffers from the same problem as a survey - it doesn't separate the quality of the software from the effectiveness of the testing effort. Each call must be analyzed in order to determine the root cause of the problem. Was there an insufficient amount of training? Are there too many features? Although most companies are immediately concerned when the help desk is swamped right after a new release, how would they feel if no one called? If nobody called, there would be no data to analyze and no way to discover (and resolve) problems. Even worse, though, maybe the application is so bad that nobody is even using it.
| Key Point |
Customer satisfaction measures are useful for your organization and are of interest to the test manager, but don't, in themselves, solve the problem of how to measure test effectiveness. |
One final problem with the customer satisfaction measures that we've just discussed (i.e., surveys and help desk calls) is that they're both after the fact. That is, the measures are not available until after the product is sold, installed, and in use. Just because a metric is after the fact doesn't make it worthless, but it does lessen its value considerably.
Customer satisfaction measures are useful for your organization, and are of interest to the test manager, but don't, in themselves, solve the problem of how to measure test effectiveness.
Defect Measures
Another group of measures commonly used for test effectiveness are built around the analysis of defects.
Number of Defects Found in Testing
Some test managers attempt to use the number of defects found in testing as a measure of test effectiveness. The first problem with this, or any other measure of defects, is that all bugs are not created equal. It's necessary to "weight" bugs and/or use impact categories such as all "critical" bugs. Since most defects are recorded with a severity rating, this problem can normally be overcome.
| Key Point |
Another problem with defect counts as a measure of test effectiveness is that the number of bugs that originally existed significantly impacts the number of bugs discovered (i.e., the quality of the software). |
Another problem with defect counts as a measure of test effectiveness is that the number of bugs that originally existed significantly impacts the number of bugs discovered (i.e., the quality of the software). Just as in the customer satisfaction measures, counting the number of bugs found in testing doesn't focus on just testing, but is affected by the initial quality of the product being tested.
Some organizations successfully use the number of defects found as a useful measure of test effectiveness. Typically, they have a set of test cases with known coverage (coverage is our next topic) and a track record of how many bugs to expect using various testing techniques. Then, they observe the trends in defect discovery versus previous testing efforts. The values have to be normalized based upon the degree of change of the system and/or the quantity and complexity of any new functionality introduced.
Figure 7-8 shows the defect discovery rates of two projects. If the projects are normalized based on size and complexity, one can assume that 'Project B' will contain a number of defects similar to 'Project A'. Consequently, the curves described by each of these projects should also be similar.
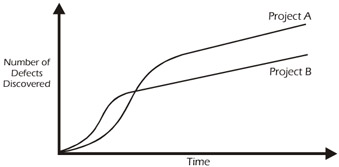
Figure 7-8: Defect Discovery Rates for Projects A and B
If the testing effort on 'Project B' finds significantly fewer bugs, this might mean that the testing is less effective than it was on 'Project A'. Of course, the weakness in this metric is that the curve may be lower because there were fewer bugs to find! This is yet another reason why decisions shouldn't be based solely on a single metric.
Another, more sophisticated, example of measuring defects is shown in Table 7-5. Here, a prediction of the number of bugs that will be found at different stages in the software development lifecycle is made using metrics from previous releases or projects. Both of these models require consistent testing practices, covering test sets, good defect recording, and analysis.
|
Total # Predicted |
Predicted (P) Versus Actual (A) |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
P |
A |
P |
A |
P |
A |
P |
A |
P |
A |
||
|
Jan |
Feb |
Mar |
Apr |
May |
|||||||
|
Requirements Review |
20 |
20 |
14 |
||||||||
|
Design Review |
35 |
5 |
0 |
15 |
15 |
||||||
|
Test Design |
65 |
25 |
30 |
10 |
|||||||
|
Code Inspections |
120 |
60 |
60 |
||||||||
|
Unit Test |
80 |
||||||||||
|
System Test |
40 |
||||||||||
|
Regression Test |
10 |
||||||||||
|
Acceptance Test |
5 |
||||||||||
|
6 Months Production |
15 |
||||||||||
|
Totals |
390 |
25 |
14 |
40 |
45 |
70 |
60 |
||||
Production Defects
A more common measure of test effectiveness is the number of defects found in production or by the customer. This is an interesting measure, since the bugs found by the customer are obviously ones that were not found by the tester (or at least were not fixed prior to release). Unfortunately, some of our old problems such as latent and masked defects may have appeared.
Another issue in using production defects as a measure of test effectiveness is that it's another "after the fact" measure and is affected by the quality of the software. We must measure severity, distribution, and trends from release to release.
Defect Removal Efficiency (DRE)
A more powerful metric for test effectiveness (and the one that we recommend) can be created using both of the defect metrics discussed above: defects found during testing and defects found during production. What we really want to know is, "How many bugs did we find out of the set of bugs that we could have found?" This measure is called Defect Removal Efficiency (DRE) and is defined in Figure 7-9.

Figure 7-9: Formula for Defect Removal Efficiency (DRE)
| Note |
Dorothy Graham calls DRE Defect Detection Percentage (DDP). We actually prefer her naming convention because it's more descriptive of the metric. That is, Defect Removal Efficiency does not really measure the removal of defects, only their detection. |
The number of bugs not found is usually equivalent to the number of bugs found by the customers (though the customers may not find all of the bugs either). Therefore, the denominator becomes the number of bugs that could have been found. DRE is an excellent measure of test effectiveness, but there are many issues that you must be aware of in order to use it successfully:
- The severity and distribution of the bugs must be taken into account. (Some organizations treat all defects the same, i.e., no severity is used, based on the philosophy that the ratio of severity classes is more or less constant).
- How do you know when the customer has found all of the bugs? Normally, you would need to look at the trends of defect reporting by your customers on previous projects or releases to determine how long it takes before the customer has found "most" of the bugs. If they are still finding a bug here and there one year later, it probably won't significantly affect your metrics. In some applications, especially those with many users, most of the bugs may be reported within a few days. Other systems with fewer users may have to go a few months to have some assurance that most of the bugs have been reported.
Key Point In his book A Manager's Guide to Software Engineering, Roger Pressman calls DRE "the one metric that we can use to get a 'bottom-line' of improving quality."
- It's after the fact (refer to the bullet item above). Metrics that are "after the fact" do not help measure the test effectiveness of the current project, but they do let test managers measure the long-term trends in the test effectiveness of their organizations.
Key Point Metrics that are "after the fact" do not help measure the test effectiveness of the current project, but they do let test managers measure the long-term trends in the test effectiveness of their organizations.
- When do we start counting bugs (e.g., during unit, integration, system, or acceptance testing? during inspections? during ad hoc testing?), and what constitutes a bug-finding activity? It's important to be consistent. For example, if you count bugs found in code inspections, you must always count bugs found in code inspections.
- Some bugs cannot be found in testing! Due to the limitations of the test environment, it's possible, and even likely, that there is a set of bugs that the tester could not find no matter what he or she does. The test manager must decide whether or not to factor these bugs out. If your goal is to measure the effectiveness of the testing effort without considering what you have to work with (i.e., the environment), the bugs should be factored out. If your goal is to measure the effectiveness of the testing effort including the environment (our choice), the bugs should be left in. After all, part of the job of the tester is to ensure that the most realistic test environment possible is created.
DRE Example
Figure 7-10 is an example of a DRE calculation. Horizontal and upward vertical arrows represent bugs that are passed from one phase to the next.
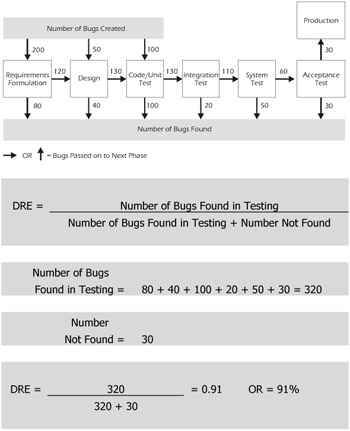
Figure 7-10: DRE Example
| Key Point |
In their book Risk Management for Software Projects, Alex Down, Michael Coleman, and Peter Absolon report that the DRE for the systems they are familiar with is usually in the range of 65–70%. |
Defect Removal Efficiency (DRE) is also sometimes used as a way to measure the effectiveness of a particular level of test. For example, the system test manager may want to know what the DRE is for their system testing. The number of bugs found in system testing should be placed in the numerator, while those same bugs plus the acceptance test and production bugs should be used in the denominator, as illustrated in the example below.
System Test DRE Example
Figure 7-11 is an example of a system test DRE calculation. Horizontal and upward vertical arrows represent bugs that are passed from one phase to the next.
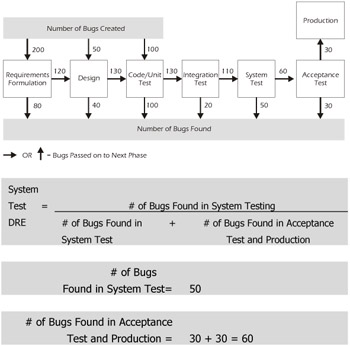
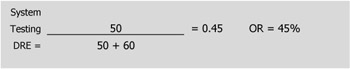
Figure 7-11: System Test DRE Example
Unit Testing DRE
When measuring the DRE of unit testing, it will be necessary to factor out those bugs that could not be found due to the nature of the unit test environment. This may seem contradictory to what we previously recommended, but we don't want the developer to have to create a "system" test environment and, therefore, there will always be bugs that cannot be found in unit testing (e.g., bugs related to the passing of data from one unit to another).
Defect Age
Another useful measure of test effectiveness is defect age, often called Phase Age or PhAge. Most of us realize that the later we discover a bug, the greater harm it does and the more it costs to fix. Therefore, an effective testing effort would tend to find bugs earlier than a less effective testing effort would.
| Key Point |
The later we discover a bug, the greater harm it does and the more it costs to fix. |
Table 7-6 shows a scale for measuring defect age. Notice that this scale may have to be modified to reflect the phases in your own software development lifecycle and the number and names of your test levels. For example, a requirement defect discovered during a high-level design review would be assigned a PhAge of 1. If this defect had not been found until the Pilot, it would have been assigned a PhAge of 8.
|
Phase Created |
Phase Discovered |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
Requirements |
High-Level Design |
Detailed Design |
Coding |
Unit Testing |
Integration Testing |
System Testing |
Acceptance Testing |
Pilot |
Production |
||
|
Requirements |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
High-Level Design |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
||
|
Detailed Design |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|||
|
Coding |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
||||
|
Summary |
|||||||||||
Table 7-7 shows an example of the distribution of defects on one project by phase created and phase discovered. In this example, there were 8 requirements defects found in high-level design, 4 during detailed design, 1 in coding, 5 in system testing, 6 in acceptance testing, 2 in pilot, and 1 in production. If you've never analyzed bugs to determine when they were introduced, you may be surprised how difficult a job this is.
|
Phase Created |
Phase Discovered |
Total Defects |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
Requirements |
High-Level Design |
Detailed Design |
Coding |
Unit Testing |
Integration Testing |
System Testing |
Acceptance Testing |
Pilot |
Production |
||
|
Requirements |
0 |
8 |
4 |
1 |
0 |
0 |
5 |
6 |
2 |
1 |
27 |
|
High-Level Design |
0 |
9 |
3 |
0 |
1 |
3 |
1 |
2 |
1 |
20 |
|
|
Detailed Design |
0 |
15 |
3 |
4 |
0 |
0 |
1 |
8 |
31 |
||
|
Coding |
0 |
62 |
16 |
6 |
2 |
3 |
20 |
109 |
|||
|
Summary |
0 |
8 |
13 |
19 |
65 |
21 |
14 |
9 |
8 |
30 |
187 |
Defect Spoilage
Spoilage is a metric that uses the Phase Age and distribution of defects to measure the effectiveness of defect removal activities. Other authors use slightly different definitions of spoilage. Tom DeMarco, for example, defines spoilage as "the cost of human failure in the development process," in his book Controlling Software Projects: Management, Measurement, and Estimates. In their book Software Metrics: Establishing a Company-Wide Program, Robert Grady and Deborah Caswell explain that Hitachi uses the word spoilage to mean "the cost to fix post-release problems." Regardless of which definition of spoilage you prefer, you should not confuse spoilage with Defect Removal Efficiency (DRE), which measures the number of bugs that were found out of the set of bugs that could have been found.
| Key Point |
Spoilage is a metric that uses Phase Age and distribution of defects to measure the effectiveness of defect removal activities. |
Table 7-8 shows the defect spoilage values for a particular project, based on the number of defects found weighted by defect age. During acceptance testing, for example, 9 defects were discovered. Of these 9 defects, 6 were attributed to defects created during the requirements phase of this project. Since the defects that were found during acceptance testing could have been found in any of the seven previous phases, the requirements defects that remained hidden until the acceptance testing phase were given a weighting of 7. The weighted number of requirements defects found during acceptance testing is 42 (i.e., 6 x 7 = 42).
|
Phase Discovered |
Spoilage = Weight/Total Defects |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
Phase Created |
Requirements |
High-Level Design |
Detailed Design |
Coding |
Unit Testing |
Integration Testing |
System Testing |
Acceptance Testing |
Pilot |
Production |
|
|
Requirements |
0 |
8 |
8 |
3 |
0 |
0 |
30 |
42 |
16 |
9 |
116 / 27 = 4.3 |
|
High-Level Design |
0 |
9 |
6 |
0 |
4 |
15 |
6 |
14 |
8 |
62 / 20 = 2.1 |
|
|
Detailed Design |
0 |
15 |
6 |
12 |
0 |
0 |
6 |
42 |
81 / 31 = 2.6 |
||
|
Coding |
0 |
62 |
32 |
18 |
8 |
15 |
120 |
255 / 109 = 2.3 |
|||
|
Summary |
514 / 187 = 2.7 |
||||||||||
The Defect Spoilage is calculated using the formula shown in Figure 7-12.

Figure 7-12: Formula for Defect Spoilage
Generally speaking, lower values for spoilage indicate more effective defect discovery processes (the optimal value is 1). As an absolute value, the spoilage has little meaning. However, it becomes valuable when used to measure a long-term trend of test effectiveness.
Defect Density and Pareto Analysis
Defect Density is calculated using the formula shown in Figure 7-13.

Figure 7-13: Formula for Defect Density
| Key Point |
J.M. Duran admonished us to concentrate on the vital few, not the trivial many. Later, Thomas J. McCabe extended the Pareto Principle to software quality activities. To learn more about the history of the Pareto Principle and see some actual examples, read The Pareto Principle Applied to Software Quality Assurance by Thomas J. McCabe and G. Gordon Schulmeyer in the Handbook of Software Quality Assurance. |
Unfortunately, defect density measures are far from perfect. The two main problems are in determining what is a defect and what is a line of code. By asking, "What is a defect?" we mean "What do we count as a defect?"
- Are minor defects treated the same as critical defects, or do we need to weight them?
- Do we count unit testing bugs or only bugs found later?
- Do we count bugs found during inspection? During ad hoc testing?
Similarly, measuring the size (i.e., lines of code or function points) of the module is also a problem, because the number of lines of code can vary based on the skill level of the programmer and the language that was used.
Figure 7-14 shows the defect density per 1,000 lines of code in various modules of a sample project. Notice that Module D has a high concentration of bugs. Experience has shown that parts of a system where large quantities of bugs have been discovered will continue to have large numbers of bugs even after the initial cycle of testing and correcting of bugs. This information can help the tester focus on problematic (i.e., error prone) parts of the system. Similarly, instead of plotting defect density on the histogram as in Figure 7-14, the causes of the defects could be displayed in descending order of frequency (e.g., functionality, usability, etc.). This type of analysis is known as Pareto Analysis and can be used to target areas for process improvement.
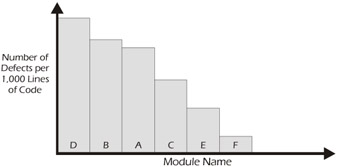
Figure 7-14: Defect Density in Various Modules
The bottom line is that defect measures can and should be used to measure the effectiveness of testing, but by themselves, they're inadequate and need to be supplemented by coverage metrics.
Coverage Measures
Coverage metrics are probably the most powerful of all measures of test effectiveness, since they are not necessarily "after the fact" and are not affected by the quality of the software under test. High-level coverage metrics such as requirements and/or inventory coverage can be done as soon as the test cases are defined. In other words, you can measure the coverage of the test cases created before the code is even written!
| Key Point |
Requirements coverage can be measured before the code is even written. |
Coverage can be used to measure the completeness of the test set (i.e., the test created) or of the tests that are actually executed. We can use coverage as a measure of test effectiveness because we subscribe to the philosophy that a good test case is one that finds a bug or demonstrates that a particular function works correctly. Some authors state that the only good test case is the one that finds a bug. We contend that if you subscribe to that philosophy, coverage metrics are not useful as a measurement of test effectiveness. (We reckon that if you knew in advance where the bugs were, you could concentrate on only writing test cases that found bugs - or, better yet, just fix them and don't test at all.)
Requirements and Design Coverage
How to measure requirements, inventory, design, and code coverage was discussed in Chapter 5 - Analysis and Design. At the very least, every testing methodology that we are familiar with subscribes to requirements coverage. Unfortunately, it's possible to "test" every requirement and still not have tested every important condition. There may be design issues that are impossible to find during the course of normal requirements-based testing, which is why it's important for most testing groups to also measure design coverage. Table 7-9 shows a matrix that combines requirements and design coverage.
|
Attribute |
TC #1 |
TC # 2 |
TC #3 |
TC #4 |
TC #5 |
|---|---|---|---|---|---|
|
Requirement 1 |
ü |
ü |
ü |
ü |
|
|
Requirement 2 |
ü |
ü |
|||
|
Requirement 3 |
ü |
ü |
|||
|
Requirement 4 |
ü |
ü |
ü |
ü |
|
|
Design 1 |
ü |
ü |
|||
|
Design 2 |
ü |
ü |
ü |
||
|
Design 3 |
ü |
It's quite clear, however, that if requirements coverage is not achieved, there will be parts of the system (possibly very important parts) that are not tested!
Code Coverage
Many testing experts believe that one of the most important things a test group can do is to measure code coverage. These people may be touting code coverage as a new silver bullet, but actually, code coverage tools have been in use for at least as long as Rick has been a test manager (20 years). The tools in use today, however, are much more user-friendly than earlier tools. Table 7-10 is a conceptual model of the output of a code coverage tool. These tools can measure statement, branch, or path coverage.
|
Statement |
Test Run |
Covered? |
||
|---|---|---|---|---|
|
TR #1 |
TR# 2 |
TR #3 |
||
|
A |
ü |
ü |
ü |
Yes |
|
B |
ü |
ü |
Yes |
|
|
C |
ü |
Yes |
||
|
D |
No |
|||
|
E |
ü |
Yes |
||
|
Total |
60% |
20% |
60% |
80% |
The reports are clearer and easier to interpret, but the basic information is almost the same. Code coverage tools tell the developer or tester which statements, paths, or branches have and have not been exercised by the test cases. This is obviously a good thing to do, since any untested code is a potential liability.
Code Coverage Weaknesses
Just because all of the code has been executed does not, in any way, assure the developer or tester that the code does what it's supposed to do. That is, ensuring that all of the code has been exercised under test does not guarantee that it does what the customers, requirements, and design need it to do.
Figure 7-15 shows a fairly typical progression in software development. The users' needs are recorded as requirements specifications, which in turn are used to create the design, and from there, the code is written. All of the artifacts that are derived from the users' needs can and should be tested. If test cases are created from the code itself, the most you can expect to prove is that the code "does what it does" (i.e., it functions, but not necessarily correctly).
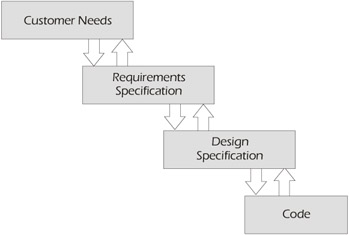
Figure 7-15: Test Verification
By testing the design, you can show that the system matches the design and the code matches the design, but you can't prove that the design meets the requirements. Test cases based upon the requirements can demonstrate that the requirements have been met and the design matches the requirements. All of these verification steps should be done and, ultimately, it's important to create test cases based upon the code, the design, and the requirements. Just because a code coverage tool is used, doesn't mean that the test cases must be derived solely from the code.
| Key Point |
Just because a code coverage tool is used, doesn't mean that the test cases must be derived solely from the code. |
In some organizations, code coverage becomes the ultimate metric. Some organizations may be struggling to move from say 85% to 90% coverage regardless of the cost. While that may be good, we think it's important to ensure that we have tested the "right" 90%. That is to say, even using code coverage metrics requires that we use some kind of risk-based approach. This is true even if a goal of 100% code coverage is established, because it's advantageous to test (and fix problems) in the critical components first.
Another issue when using code coverage tools is that the test cases may have to be executed one additional time, since most code coverage tools require the source code to be instrumented. Therefore, if a defect is discovered while using a code coverage tool, the test will have to be run again without the tool in order to ensure that the defect is not in the instrumentation itself.
Generally, we have found that code coverage is most effective when used at lower levels of test (e.g., unit and integration). These levels of test are normally conducted by the developer, which is good because the analysis of the parts of the code that were not tested is best done by the people with intimate knowledge of the code. Even when using a code coverage tool, unit test cases should first be designed to cover all of the attributes of the program specification before designing test cases based on the code itself.
| Key Point |
Even when using a code coverage tool, unit test cases should first be designed to cover all of the attributes of the program specification before designing test cases based on the code itself. |
As with most projects, you've got to crawl before you run. Trying to get a high level of code coverage is fine in organizations that have already established a fairly comprehensive set of test cases. Unfortunately, many of the companies that we have visited have not even established a test set that is comprehensive enough to cover all of the features of the system. In some cases, there are entire modules, programs, or subsystems that are not tested. It's fine to say that every line of code should be tested, but if there are entire subsystems that have no test cases, it's a moot point.
Code Coverage Strengths
Code coverage measures put the focus on lower levels of tests and provide a way to determine if and how well they've been done. Many companies do little unit testing, and code coverage tools can help highlight that fact. Global coverage can also be used as a measure of test effectiveness.
Global Code Coverage
The global coverage number can be used as a measure of test effectiveness, and it can highlight areas that are deficient in testing. This measure of test effectiveness, like all of the others we've discussed, has some problems. While it is useful to see that the coverage has increased from 50% to 90%, it's not as clear how valuable it is to go from 50% to 51%. In other words, if risk-based techniques that ensure that the riskiest components are tested first are used, then every increase has a more or less "known" value. If tests are not based on risk, it's harder to know what an increase in coverage means. It's also interesting to note that it costs more to go from, for example, 95% to 100% coverage than it did to go from 50% to 55% coverage. If risk-based techniques were used, the last gain might not "buy" us as much, since the last 5% tested is also (we hope) the least risky. Perhaps we're just trying to weigh the value of these added tests against the resources required to create and run them. At the end of the day, though, that's what testing is all about!
| Key Point |
Global code coverage is the percent of code executed during the testing of an entire application. |
Preface
- An Overview of the Testing Process
- Risk Analysis
- Master Test Planning
- Detailed Test Planning
- Analysis and Design
- Test Implementation
- Test Execution
- The Test Organization
- The Software Tester
- The Test Manager
- Improving the Testing Process
- Some Final Thoughts…
- Appendix A Glossary of Terms
- Appendix B Testing Survey
- Appendix C IEEE Templates
- Appendix D Sample Master Test Plan
- Appendix E Simplified Unit Test Plan
- Appendix F Process Diagrams
EAN: 2147483647
Pages: 114
