Introduction
A variety of techniques can be used to solve a problem. One common programming methodology is to divide the problem into smaller specific subtasks. Then, given the nature of the subtasks and the sequence in which they must be done, parcel them out to separate processes (generated via a fork system call). Then, if needed, have the processes communicate with one another using interprocess communication constructs. When each of the subtasks (processes) is finished, its solved portion of the problem is integrated into the whole to provide an overall solution. Indeed, this approach is the basis for distributed computation.
However, generating and managing individual processes consume system resources. As we have seen in previous chapters, there is a considerable amount of system overhead associated with the creation of a process. During its execution lifetime, the system must keep track of the current state, program counter, memory usage, file descriptors, signal tables, and other details of the process. Further, when the process exits, the operating system must remove the process-associated data structures and return the process's status information to its parent process, if still present, or to init . If we add to this the cost of the process communicating with other processes using standard interprocess communication facilities, we may find this approach too resource expensive.
Aware of such limitations, the designers of modern versions of UNIX anticipated the need for constructs that would facilitate concurrent solutions but not be as system- intensive as separate processes. As in a multitasking operating system where multiple processes are running concurrently (or pseudo-concurrently), why not allow individual processes the ability to simultaneously take different execution paths through their process space? This idea led to a new abstraction called a thread . Conceptually, a thread is a distinct sequence of execution steps performed within a process. In a traditional setting, with a UNIX process executing, say, a simple C/C++ program, there is a single thread of control. At any given time there is only one execution point (as referenced by the program counter). The thread starts at the first statement in main and continues through the program logic in a serial manner until the process finishes. In a multithreading (MT) setting, there can be more than one thread ofcontrol active within a process, each progressing concurrently. Be aware thatsome authors use the term multithreaded program to mean any program that uses two or more processes running concurrently that share memory and communicate with one another (such as what we did in Chapter 8). If the processes (with their threads) are executing and making progress simultaneously on separate processors, parallelism occurs.
There are certain problem types that lend themselves to a multithreaded solution. Problems that inherently consist of multiple, independent tasks are prime candidates. For example, monitor and daemon programs that manage a large number of simultaneous connections, concurrent window displays, and similar processes can be written using threads. Similarly, producerconsumer and clientserver type problems can have elegant multithreaded solutions. Additionally, some numerical computations (such as matrix multiplication) that can be divided into separate subtasks also benefit from multithreading. On the other side of the coin, there are many problems that must be done in a strict serial manner for which multithreading may produce a less efficient solution.
Each thread has its own stack, register set, program counter, thread-specific data, thread-local variables , thread-specific signal mask, and state information. However, all such threads share the same address space, general signal handling, virtual memory, data, and I/O with the other threads within the same process. In a multithreaded process each thread executes independently and asynchronously. In this setting communication between threads within the same process is less complex, as each can easily reference common data. However, as expected, many tasks handled by threads have sequences that must be done serially . When these sequences are encountered , synchronization problems concerning data accessupdatingcan arise. Most commonly the operating system uses a priority-based, preemptive, non-time -slicing algorithm to schedule thread activities. With preemptive scheduling the thread executes until it blocks or has used its allotted time. The term sibling is sometimes used to denote other peer threads, as there is no inherent parent/child relationship with threads.
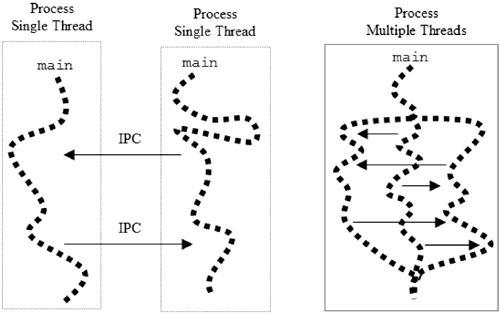
Figure 11.1 compares communications for multiple processes, each with a single thread, with that of a single process with multiple threads.
Figure 11.1. Conceptual communicationsmultiple single-threaded processes versus a single process with multiple threads.
At system implementation level there are two traditional approaches ormodels used to generate and manage threads. The first, the user -level model, runs on top of the existing operating system and is transparent to it. Theoperating system maintains a runtime system to manage thread activities. Library functions and system calls made within the thread are wrapped in special code to allow for thread run-time management. [1] Threads implemented in this manner have low system overhead and are easily extensible should additional functionality be needed. On occasion, the operating system may have difficulty efficiently managing a user-level-implemented thread that is not time sliced and contains CPU-intensive code. More importantly, user-level threads are designed to share resources with other threads within their process space when running on a single processor.
[1] For example, calls that would normally block (such as read ) are wrapped in code that allows them to be non-blocking .
The second approach is the kernel-level model. In this implementation, the operating system is aware of each thread. While the management of kernel-level threads is less intensive than that of individual processes, it is still more expensive than user-level-based threads. A kernel that offers direct thread support must contain system-level code for each specified thread function. However, kernel-level threads can support parallelism with multiple threads running on multiple processors.
In an attempt to incorporate the best of both approaches, many thread implementations are composites (hybrids). In one implementation the system binds each user-level thread to a kernel-level thread on a one-to-one basis. Windows NT and OS/2 use this approach. Another approach is to have the system multiplex user-level threads with a single kernel-level thread ( many-to-one ). A more common composite model relies on the support of multiple user-level threads with a pool of kernel-level threads. The kernel-level threads are run as lightweight processes (LWP) and are scheduled and maintained by the operating system. In a multiprocessor setting some operating systems allow LWPs to be bound to a specific CPU.
Older versions of Linux supported user-level threads. In newer versions of Linux there are kernel threads. However, these threads are used by the operating system to execute kernel- related functions and are not directly associated with the execution of a user's program. Multithreaded support is offered through LWPs. Linux uses a system specific (non-portable) clone system call to generate an LWP for the thread. Threaded applications should use one of the standardized thread APIs described in the next paragraph. By comparison, Sun's Solaris uses a variation of the kernel-level scheme whereby the user can specify a one-to-one binding or use the default many-to-many mapping. While Sun's approach is more flexible, it is more complex to implement and requires the interaction of two scheduling routines (user and kernel).
From a programming standpoint, there is a variety of thread APIs. Two of the more common are POSIX (Portable Operating System Interface) Pthreads and Sun's thread library (UNIX International, or UI). By far, POSIX threads (based on POSIX 1003.1 standards generated by the IEEE Technical Committee on Operating Systems) are the most widely implemented thread APIs. The POSIX standard 1003.1c is an extension of the 1003.1 and includes additional interface support for multi-threading .
In current versions of Linux (such as Red Hat 5.0 and later) the POSIX 1003.1c thread API is implemented using the LinuxThreads library, which isincluded in the glibc2 GNU library. In the Sun Solaris environment, both the POSIX and Sun thread libraries are supported, since Sun's effort at producing thread libraries predates the POSIX standards and many of the POSIX constructs have a strong Sun flavor. We will concentrate on POSIX threads, asthey are guaranteed to be fully portable to other environments that are POSIX-compliant. The POSIX thread functions, except for semaphore manipulation, begin with the prefix pthread , while POSIX thread constants begin with the prefix PTHREAD_. The thread-related functions (over 100) are found in section 3thr of the manual pages.
Note that all programs using POSIX thread functions need the preprocessor directive #include for the inclusion of thread prototypes . If the code will contain reentrant functions, [2] the defined constant #define _REENTRANT should be placed prior to all includes and program code. A list of supported reentrant functions can be found by interrogating the /usr/lib/libc.a library. For example,
[2] A reentrant function supports access by multiple threads and maintains the integrity of its data across consecutive calls. Functions that reentrant should not in turn call a function that is non-reentrant.
linux$ ar t /usr/lib/libc.a grep '_r.o' pr -n -2 -t 1 random_r.o 32 getspnam_r.o 2 rand_r.o 33 sgetspent_r.o 3 drand48_r.o 34 fgetspent_r.o 4 erand48_r.o 35 getnssent_r.o 5 lrand48_r.o 36 gethstbyad_r.o 6 nrand48_r.o 37 gethstbynm2_r.o 7 mrand48_r.o 38 gethstbynm_r.o 8 jrand48_r.o 39 gethstent_r.o 9 srand48_r.o 40 getnetbyad_r.o 10 seed48_r.o 41 getnetent_r.o 11 lcong48_r.o 42 getnetbynm_r.o 12 tmpnam_r.o 43 getproto_r.o 13 strtok_r.o 44 getprtent_r.o 14 ctime_r.o 45 getprtname_r.o 15 readdir_r.o 46 getsrvbynm_r.o 16 readdir64_r.o 47 getsrvbypt_r.o 17 getgrent_r.o 48 getservent_r.o 18 getgrgid_r.o 49 getrpcent_r.o 19 getgrnam_r.o 50 getrpcbyname_r.o 20 fgetgrent_r.o 51 getrpcbynumber_r.o 21 getpwent_r.o 52 ether_aton_r.o 22 getpwnam_r.o 53 ether_ntoa_r.o 23 getpwuid_r.o 54 getnetgrent_r.o 24 fgetpwent_r.o 55 getaliasent_r.o 25 getlogin_r.o 56 getaliasname_r.o 26 ttyname_r.o 57 nscd_getpw_r.o 27 mntent_r.o 58 nscd_getgr_r.o 28 efgcvt_r.o 59 nscd_gethst_r.o 29 qefgcvt_r.o 60 getutent_r.o 30 hsearch_r.o 61 getutid_r.o 31 getspent_r.o 62 getutline_r.o
As shown, reentrant functions have _r appended to their non-reentrant name .
The object code library for POSIX thread functions must be linked in at compile time using the compiler switch -lpthread . Additionally, _POSIX_C_SOURCE [3] should be defined if strict compliance to POSIX standards is required. For example,
[3] On occasion, using the -D_POSIX_C_SOURCE flag will get us into trouble, as certain defined data types (such as timeval ) do not seem to be officially defined when specifying ANSI C.
linux$ cat demo.c #define _REENTRANT #include . . . linux$ g++ demo.cxx -D_POSIX_C_SOURCE -lpthread
Threads and their use are a complex topic. This chapter presents the basics of POSIX threadstheir generation, scheduling, synchronization, and use. Readers wishing to gain additional insight on the topic are encouraged to read current texts that address thread programming, such as Comer et al., 2001; Nichols et al., 1996; Kleiman et al., 1996; Mitchell et al., 2000; Norton et al., 1997; Lewis et al., 1996; Northrup, 1996; and Wall, 2000, as well as the online documentation (manual pages) and vendor-supplied system support documentation.
Programs and Processes
- Introduction
- Library Functions
- System Calls
- Linking Object Code
- Managing Failures
- Executable File Format
- System Memory
- Process Memory
- The u Area
- Process Memory Addresses
- Creating a Process
- Summary
- Key Terms and Concepts
Processing Environment
- Introduction
- Process ID
- Parent Process ID
- Process Group ID
- Permissions
- Real and Effective User and Group IDs
- File System Information
- File Information
- Process Resource Limits
- Signaling Processes
- Command-Line Values
- Environment Variables
- The /proc Filesystem
- Summary
- Key Terms and Concepts
Using Processes
- Introduction
- The fork System Call Revisited
- exec s Minions
- Using fork and exec Together
- Ending a Process
- Waiting on Processes
- Summary
- Key Terms and Concepts
Primitive Communications
- Introduction
- Lock Files
- Locking Files
- More About Signals
- Signal and Signal Management Calls
- Summary
- Key Terms and Concepts
Pipes
Message Queues
- Introduction
- IPC System Calls: A Synopsis
- Creating a Message Queue
- Message Queue Control
- Message Queue Operations
- A ClientServer Message Queue Example
- Message Queue Class
- Summary
- Key Terms and Concepts
Semaphores
- Introduction
- Creating and Accessing Semaphore Sets
- Semaphore Control
- Semaphore Operations
- Semaphore Class
- Summary
- Key Terms and Concepts
Shared Memory
- Introduction
- Creating a Shared Memory Segment
- Shared Memory Control
- Shared Memory Operations
- Using a File as Shared Memory
- Shared Memory Class
- Summary
- Key Terms and Concepts
Remote Procedure Calls
- Introduction
- Executing Remote Commands at a System Level
- Executing Remote Commands in a Program
- Transforming a Local Function Call into a Remote Procedure
- Debugging RPC Applications
- Using RPCGEN to Generate Templates and a MAKEFILE
- Encoding and Decoding Arbitrary Data Types
- Using Broadcasting to Search for an RPC Service
- Summary
- Key Terms and Concepts
Sockets
- Introduction
- Communication Basics
- IPC Using Socketpair
- Sockets: The Connection-Oriented Paradigm
- Sockets: The Connectionless Paradigm
- Multiplexing I/O with select
- Peeking at Data
- Out of Band Messages
- Summary
- Key Terms and Concepts
Threads
- Introduction
- Creating a Thread
- Exiting a Thread
- Basic Thread Management
- Thread Attributes
- Scheduling Threads
- Using Signals in Threads
- Thread Synchronization
- Thread-Specific Data
- Debugging Multithreaded Programs
- Summary
- Nomenclature and Key Concepts
Appendix A. Using Linux Manual Pages
Appendix B. UNIX Error Messages
Appendix C. RPC Syntax Diagrams
Appendix D. Profiling Programs
EAN: 2147483647
Pages: 136
