Remote Copy
| < Day Day Up > |
| Remote copy is the duplication of I/O from one set of disks to another similar set on a block level. All data written to the disks, including changes, will be reflected in the second set. This yields an exact duplicate of the first disks. Although similar to RAID 1 (as well as RAID 10 and RAID 0+1), remote copy differs in three important ways. First, it duplicates an entire set of disks, even those organized into a RAID group already. In a way, remote copy can be used as RAID of RAID. The second difference is that data is copied to a set of external disks. RAID duplicates data on the same bus in the same enclosure; remote copy duplicates data over a network to a remote location. That location may be right next to the primary array, in the next building, or hundreds of miles away. Data is protected not only through duplication, but also by distance. Finally, remote copy is a network application. It relies on network connections to transport data over a distance. This does not mean that the storage system must be a Storage Area Network (SAN), although this is quite common. It does mean that some network with sufficient bandwidth needs to be available to the remote copy agent. The goal of remote copy is to produce a set of disks that can replace the primary set immediately. Servers that use the disks can begin using the secondary set as soon as failure occurs. Terminology Alert Another term for remote copy is remote mirroring. Some vendors and analysts like to use the term remote copy to encompass the entire spectrum of data movement to remote disks. Others prefer to treat it as a product name, dissuading others from using it as a general term. For these reasons, the term remote mirroring is often used instead. The problem with the term remote mirroring is that it can be confused with the mirroring in RAID. They are different enough that the names should not be so similar. Remote copy, on the other hand, does not share that problem. FailoverFailover simply means that a new resource is always available if the primary one fails. Failover techniques are used to maintain network paths when cables break, to continue to provide power when a power supply fails, to allow a server to take over from a crashed one, and to allow access to data when an array goes down. There are a number of ways that failover can occur. It may be an automatic function in which consumers of a resource are immediately directed to the secondary set of resources. In other cases, a manual process has to occur to redirect consumers to the new resource. Components, such as power supplies, fail over immediately; others, such as hard drives, may not, depending on the design of the unit. Server system software determines the way that failover occurs when a set of drives fails. Most operating systems will immediately switch over to the backup drives in a RAID set. There are different ways that this occurs when networked storage fails. There is disruptive failover, and there is nondisruptive (also called stateful) failover. Nondisruptive failover maintains I/Os in progress and completes all transactions as though the failure had not occurred. Many IP routers and switches are capable of nondisruptive failover during path failure. This is not always the case for Fibre Channel switches. Very high-end FC directors provide for nondisruptive failover to a new path, whereas smaller switches and even some directors do not.
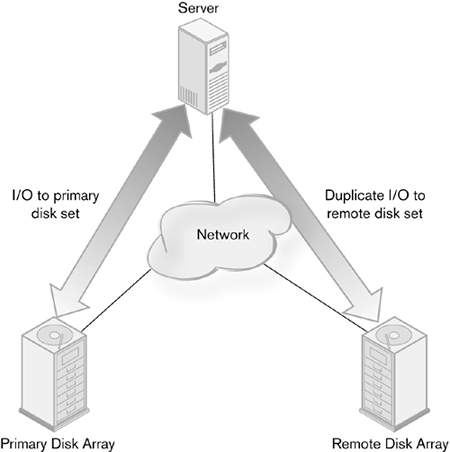
Remote Copy TopologiesTo perform remote copy, a system needs to have the primary disks, the disks to be copied to, a network connection between them, and a processor with software at each end to move the data and manage the process. Given these simple requirements, there are several ways that remote copy can be implemented. The two most common topologies for remote copy are host based and storage system based. A new model is emerging in which remote copy occurs within the storage network switch. Although unproven at this point, it promises to be an exciting new design option for those building remote copy systems. Host-BasedThe basic idea of remote copy is to duplicate the I/O between a host and a networked storage unit. The first way to accomplish this is called host-based remote copy (Figure 4-1). Software running on the host system sends two duplicate sets of I/O to two different storage devices. All I/O sent to the first disk array is then sent to the second array. Figure 4-1. Host-based remote copy
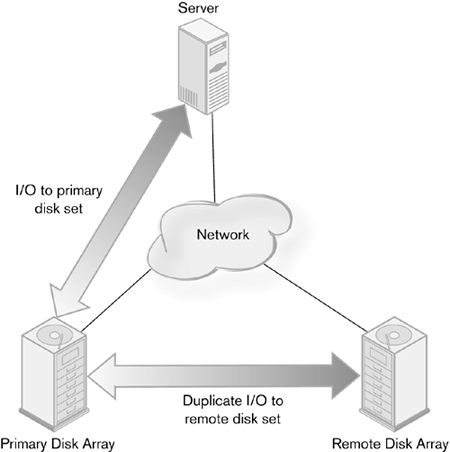
The remote copy software intercepts all I/O going to the primary disk array and sends exact copies of the I/O to the remote array. It then waits for acknowledgment of both I/Os. The advantages of this arrangement are that it is less expensive than other forms of remote copy and easy to implement. One need only load and configure the software on the host server and ensure functioning network paths, and the system is ready for operation. Performance, on the other hand, is usually worse than in other remote copy designs. The load on the server can be very heavy, because the host is responsible for sending two sets of I/Os and must wait for two sets of acknowledgments before it can process another one. Server performance is also diminished, owing to the amount of resources used by the remote copy software. Host-based remote copy also is not scalable. Software has to be loaded on every computer whose data is to be duplicated, even if they sit on the same network or SAN. Adding servers to this protection scheme means loading and configuring new software for each new server. Because this is a low-level system function, for some operating systems, installation also requires that the system kernel be rebuilt. That particular task can be slow and may lead to system problems. This form of remote copy is best used in situations where few hosts need to participate in remote copy and the amount of I/O is moderate. When the system scales above a few hosts, performance is inadequate, or a large number of hosts need to access a smaller number of disk arrays, host-based copy will not suffice. Disk SystemAnother common topology for remote copy has the I/O copy performed by the disk system. A host sends a single I/O to a single disk array. Using software embedded in the array, the I/O is duplicated to a remote set of disks over a network connection (Figure 4-2). The disk system then handles all errors and acknowledgments from the remote array. If data needs to be resent, the disk system handles that. The host does not need to become involved in the transactions. It knows about the local array but not the remote one. Figure 4-2. Storage system remote copy
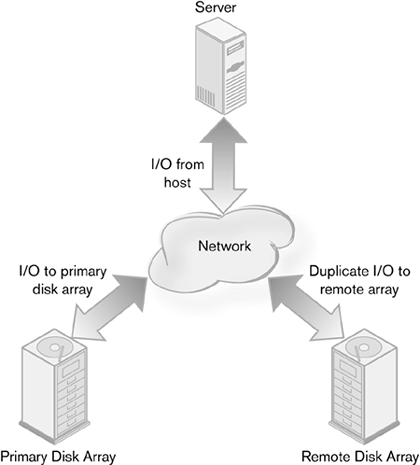
Whereas host-based remote copy is implemented as software on the host server, disk system remote copy is built into the disk array itself, usually by embedding a server in it. Some examples are EMC's Symmetrix Remote Data Facility (SRDF), Peer to Peer Remote Copy (PPRC) from IBM, and Hitachi Data Systems' TrueCopy. Performing remote copy in the disk system instead of the host allows for greater scalability, better overall system performance, and less disruption of the servers. Because the far endpoint of the connection the disk system, in this case does the actual copying of data, servers can be added without altering the remote copy facility. There is no impact on server resources, because they do not have to do the work of remote copy and are not waiting for acknowledgments. The impact on the disk array's performance is usually small, because the embedded server handles most of the heavy lifting. Only when there are a lot of errors or there is insufficient bandwidth to the remote device does performance degrade noticeably. The tradeoff for performance is cost. Remote copy embedded in a storage system is very expensive, from hundreds of thousands up to nearly a million dollars. Embedded remote copy systems are complex and difficult to install, manage, and maintain. For large installations with many servers, large amounts of storage and data, and high availability and data protection needs, the cost is usually worth it. Network-Based CopyUntil recently, the endpoints of a storage system have been the only devices with intelligence enough to perform remote copy functions. Storage switches were fairly dumb, with no extra processing power for hosted applications. Even the most advanced switch was concerned primarily with moving frames around the network as quickly and efficiently as possible. Features common on other types of network switches, such as traffic shaping and security, were nonexistent. Starting in 2002, Cisco Systems and Brocade Communications introduced a different concept for Fibre Channel storage switches. They created intelligent storage switches with high-end management, traffic management, and other common network features. In addition to these features, the switches had the ability to host other hardware or software, giving them the ability to perform even more intelligent functions. With the ability to add functionality to the network, companies that make remote copy products have been porting their products to these new switch platforms. This presents a whole new way of doing remote copy, turning it into a network service available to all nodes in the storage network. With remote copy software sitting on the switch, any I/O could be intercepted and copied to remote disk array, yet be completely transparent to the hosts and the primary disk array (Figure 4-3). Through traffic shaping and caching techniques, performance could be maintained at a high level. Figure 4-3. Switch-based remote copy
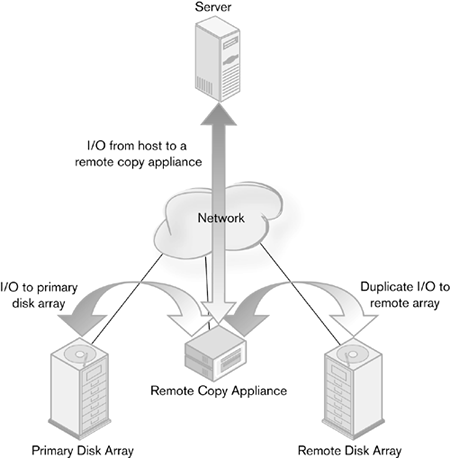
Switches have the advantage of being able to manage traffic. With remote copy embedded in a switch, it has the opportunity to provide Quality of Service (QoS) to fit the remote copy application. The other remote copy topologies do not give the switch clues as to what the traffic is and require manual traffic shaping and QoS. There is a downside to moving copy functions to the storage switch. Too much activity outside of core switching will degrade performance in the switch, dragging down all nodes. Instead of affecting the performance of a host or disk array, the excess activity could make the whole network slow if there is a lot of duplicate I/O, especially if there are many transmission errors to contend with. Another form of network-based remote copy uses a storage appliance to perform the remote copy. A specialized storage network device or server copies the I/O to a remote disk array by intercepting traffic to the primary one. The device uses the network in the same way as the host and disk system remote copy topologies (Figure 4-4). Figure 4-4. Remote copy using a storage network appliance
The appliance topology has certain advantages over the switch topology. The most important one is that it does not affect switch performance. A dumb switch can also be used, because the intelligence is in the appliance. Not having to use an intelligent switch helps keep costs lower, because those features are paid for on every port, not just the ones that remote copy uses. A network appliance used for remote copy may also house other types of network services. Combining these storage network services allows for the creation of large managed pools of storage with a high level of data protection. Like all network devices, the remote copy appliance suffers from reliance on a device external to the central switch. It is limited in how it can take advantage of other network resources housed within the switch platform. QoS and traffic shaping do not happen in conjunction with the remote copy service. Redundant appliances are also necessary to guard against the appliance itself becoming a single point of failure. Because most appliances have a limited number of ports, redundant units are necessary to guard against simple link failure. |
| < Day Day Up > |
EAN: 2147483647
Pages: 122