Using EXPLAIN PLAN
EXPLAIN PLAN is a SQL statement that causes Oracle to report the execution plan it would choose for any SELECT, INSERT, UPDATE, DELETE, or MERGE statement. An execution plans refers to the approach Oracle will take to retrieve the necessary data for a statement. One example of a plan would be to use an index to find the required rows. Another example of an execution plan would be to sequentially read all rows in the table. If you have a poorly performing SQL statement, you can use EXPLAIN PLAN to find out how Oracle is processing it. With that information, you may be able to take some corrective action to improve performance.
When you use EXPLAIN PLAN, Oracle doesn't display its execution strategy on the screen; instead, it inserts rows into a table. This table is referred to as the plan table , and you must query it properly to see the results. The plan table must exist; if you've never used EXPLAIN PLAN before, you may need to create the plan table first.
|

12.2.1 Creating the Plan Table
If you're running Oracle Database 10 g , the good news is you don't need to create a plan table. Instead, you can let the EXPLAIN PLAN statement create the table for you. If no plan table exists, EXPLAIN PLAN will create a global temporary plan table. The EXPLAIN PLAN results in such a table will remain for the duration of your session. The temporary table definition will be permanent.
If you're not running Oracle Database 10 g , or if you prefer working with a plan table that will hold results across more than one session until you delete them, you'll need to create a permanent plan table. For that, Oracle provides a script named utlxplan.sql , which resides in the $ORACLE_HOME/rdbms/admin directory for your database. You can run the script from SQL*Plus like this:
SQL> @$ORACLE_HOME/rdbms/admin/utlxplan Table created.
|
The columns in the plan table vary from release to release, as Oracle has tended to add columns over the years . Here is what the Oracle Database 10 g plan table looks like:
SQL> DESCRIBE plan_table Name Null? Type ----------------------------------------- -------- ---------------- STATEMENT_ID VARCHAR2(30) PLAN_ID NUMBER TIMESTAMP DATE REMARKS VARCHAR2(4000) OPERATION VARCHAR2(30) OPTIONS VARCHAR2(255) OBJECT_NODE VARCHAR2(128) OBJECT_OWNER VARCHAR2(30) OBJECT_NAME VARCHAR2(30) OBJECT_ALIAS VARCHAR2(65) OBJECT_INSTANCE NUMBER(38) OBJECT_TYPE VARCHAR2(30) OPTIMIZER VARCHAR2(255) SEARCH_COLUMNS NUMBER ID NUMBER(38) PARENT_ID NUMBER(38) DEPTH NUMBER(38) POSITION NUMBER(38) COST NUMBER(38) CARDINALITY NUMBER(38) BYTES NUMBER(38) OTHER_TAG VARCHAR2(255) PARTITION_START VARCHAR2(255) PARTITION_STOP VARCHAR2(255) PARTITION_ID NUMBER(38) OTHER LONG DISTRIBUTION VARCHAR2(30) CPU_COST NUMBER(38) IO_COST NUMBER(38) TEMP_SPACE NUMBER(38) ACCESS_PREDICATES VARCHAR2(4000) FILTER_PREDICATES VARCHAR2(4000) PROJECTION VARCHAR2(4000) TIME NUMBER(38) QBLOCK_NAME VARCHAR2(30)
The name of the table doesn't have to be plan_table , but that's the default and it's usually easiest to leave it that way. If for some reason you don't have access to the utlxplan.sql script, you can create the table manually. Be sure that the column names and datatypes match those shown here.
12.2.2 Explaining a Query
Once you have a plan table, getting Oracle to tell you the execution plan for any given query is an easy task. You need to prepend the EXPLAIN PLAN statement to the front of your query. The syntax for EXPLAIN PLAN looks like this:
EXPLAIN PLAN [SET STATEMENT_ID = ' statement_id '] [INTO table_name ] FOR statement ;
in which:
statement_id
Can be anything you like, and is stored in the STATEMENT_ID field of all plan table records related to the query you are explaining. It defaults to null.
table_name
Is the name of the plan table, and defaults to PLAN_TABLE. You need to supply this value if you have created your plan table with some name other than the default.
statement
Is the DML statement to be "explained." This can be an INSERT, UPDATE, DELETE, SELECT, or MERGE statement, but it must not reference any data dictionary views or dynamic performance tables.
Consider the following query, which returns the total number of hours worked by each employee on each project:
SELECT employee_name, project_name, sum(hours_logged) FROM employee, project, project_hours WHERE employee.employee_id = project_hours.employee_id AND project.project_id = project_hours.project_id GROUP BY employee_name, project_name;
This query can be explained using the two statements shown in Example 12-2.
Example 12-2. Explaining a query
DELETE FROM plan_table WHERE statement_id = 'HOURS_BY_PROJECT'; EXPLAIN PLAN SET STATEMENT_ID = 'HOURS_BY_PROJECT' FOR SELECT employee_name, project_name, sum(hours_logged) FROM employee, project, project_hours WHERE employee.employee_id = project_hours.employee_id AND project.project_id = project_hours.project_id GROUP BY employee_name, project_name;
When you execute this EXPLAIN PLAN statement, you won't see any output because Oracle stores the query plan in the plan table. Retrieving and interpreting the results is your next task.
|
12.2.3 Interpreting the Results
Having issued an EXPLAIN PLAN, you retrieve and view the results by querying the plan table. The statement ID is the key to doing this. The plan table can contain execution plans for any number of queries. The rows for each query contain the statement ID you specified in your EXPLAIN PLAN statement, so you must use this same ID when querying the plan table to select the plan you are interested in seeing.
12.2.3.1 Using DBMS_XPLAN to display an execution plan
Beginning in Oracle9 i Database Release 2, you can display an execution plan with a call to DBMS_XPLAN.DISPLAY, which is a table function. Example 12-3 shows how to use that function to display the plan generated in Example 12-2. The SET LINESIZE 132 command is there because the results require a bit more than 80 characters per line. Figure 12-1 shows the resulting plan output.
Example 12-3. Invoking DBMS_XPLAN.DISPLAY to show an execution plan
SET LINESIZE 132 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY( 'PLAN_TABLE','HOURS_BY_PROJECT','TYPICAL') );
Figure 12-1. Execution plan generated by Example 12-2, as displayed by Example 12-3
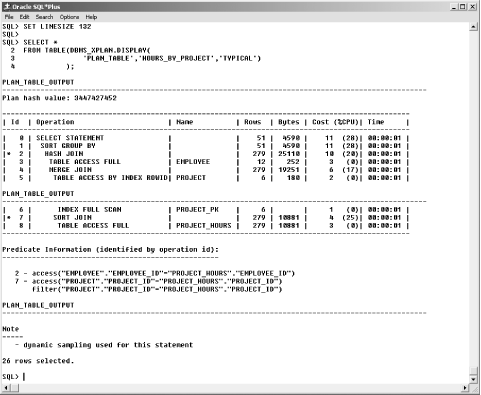
This is by far the easiest way to display execution plan details. It would be nice if the TYPICAL display fit within 80 columns, but it doesn't. You may wish to SET LINESIZE 132 prior to displaying a plan.
The three arguments to the DBMS_XPLAN.DISPLAY function are:
table_name
Don't forget to specify your plan table's name as uppercase unless you have a mixed- or lowercase plan table name.
statement_ID
This is the ID you gave in your EXPLAIN PLAN statement. Use NULL if you did not specify a statement ID.
format
The format keyword describes how much detail you wish to see. It will ordinarily be one of the following, in increasing order of detail: BASIC, TYPICAL, ALL. TYPICAL is the default. You may use SERIAL in cases in which you want TYPICAL output but without any information about parallel operations.
Oracle breaks query execution down into a series of nested steps, each of which feeds data to a parent step. The ultimate parent is the query itself, the output of which is returned to the application. You can see this nesting reflected in Figure 12-1.
|
12.2.3.2 Using a SELECT statement to display an execution plan
If you're running Oracle9i Database Release 1 or earlier, you'll need to use the traditional way to look at an execution plan, which is to display it using a hierarchical query. Example 12-4 shows a typical query used to display plan output.
Example 12-4. A query to display an execution plan
COLUMN id FORMAT 9999
COLUMN parent_id FORMAT 9999 HEADING "PID"
COLUMN "Query Plan" FORMAT A50
UNDEFINE s_statement_id
SELECT id, parent_id,
LPAD(' ', 2*(level-1)) operation ' ' options
' ' object_name ' '
DECODE(id, 0, 'Cost = ' position) "Query Plan"
FROM plan_table
START WITH id = 0 AND statement_id = '&&s_statement_id'
CONNECT BY prior id = parent_id AND statement_id = '&&s_statement_id';
The result of this query will be a report showing the steps in the execution plan, with each child step indented underneath its parent:
SQL> @ex12-3 Enter value for s_statement_id: HOURS_BY_PROJECT old 6: START WITH id = 0 AND statement_id = '&&s_statement_id' new 6: START WITH id = 0 AND statement_id = 'HOURS_BY_PROJECT' old 7: CONNECT BY prior id = parent_id AND statement_id = '&&s_statement_id' new 7: CONNECT BY prior id = parent_id AND statement_id = 'HOURS_BY_PROJECT' ID PID Query Plan ----- ----- -------------------------------------------------- 0 SELECT STATEMENT Cost = 11 1 0 SORT GROUP BY 2 1 HASH JOIN 3 2 TABLE ACCESS FULL EMPLOYEE 4 2 MERGE JOIN 5 4 TABLE ACCESS BY INDEX ROWID PROJECT 6 5 INDEX FULL SCAN PROJECT_PK 7 4 SORT JOIN 8 7 TABLE ACCESS FULL PROJECT_HOURS
Depending on your needs, you can include additional columns besides those shown here. Table 12-1 describes each of the plan table columns. Be aware that many columns, especially those involving cost, are not filled in by the rule-based optimizer.
|
Table 12-1. Plan table columns
|
Column |
Description |
|---|---|
|
STATEMENT_ID |
ID you gave the statement when you executed EXPLAIN PLAN. |
|
PLAN_ID |
Unique identifier that is automatically generated by the database each time you explain a plan. |
|
TIMESTAMP |
Date and time at which you executed the EXPLAIN PLAN statement. |
|
REMARKS |
Free-form comments inserted by the database. |
|
OPERATION |
Name of an operation to be performed. |
|
OPTIONS |
Variations on the OPERATION to be performed. |
|
OBJECT_NODE |
Name of a database link used to reference an object, or, for parallel queries, describes the order in which output from parallel operations is consumed. |
|
OBJECT_OWNER |
Owner of a table, index, or other object. |
|
OBJECT_NAME |
Name of a table, index, or other object on which an OPERATION is to be performed. |
|
OBJECT_ALIAS |
Alias associated with a table, view, or index in a SQL statement. This allows you to distinguish between multiple occurrences of the same object in a statement. For example, you can distinguish between multiple occurrences of the same table. |
|
OBJECT_INSTANCE |
Ordinal position of an object's name in the original statement. |
|
OBJECT_TYPE |
Additional information about an object. |
|
OPTIMIZER |
Current optimizer mode. |
|
SEARCH_COLUMNS |
Not currently used. |
|
ID |
Number assigned to each step in an execution plan. |
|
PARENT_ID |
ID of the parent step, which is the step that will consume the output from the current step. |
|
DEPTH |
Current depth of an operation in the hierarchical execution plan. |
|
POSITION |
Position of one operation with respect to other operations under the same parent. In the ultimate parent operation, the one with ID=0, this column provides the optimizer's estimated cost estimate for the statement as a whole. |
|
COST |
Optimizer's cost estimate for an operation. |
|
CARDINALITY |
Optimizer's estimate as to the number of rows to be accessed by an operation. |
|
BYTES |
Optimizer's estimate as to the number of bytes to be accessed by an operation. |
|
OTHER_TAG |
Contents of the OTHER column; will be one of the following values: SERIAL Serial execution. SERIAL_FROM_REMOTE Serial execution at a remote site. PARALLEL_FROM_SERIAL Serial execution, but the output will be distributed for parallel execution. PARALLEL_TO_SERIAL Parallel execution, but the output will be combined for serial execution. PARALLEL_TO_PARALLEL Parallel execution, and the output will be redistributed to a new set of parallel processes. PARALLEL_COMBINED_WITH_PARENT Parallel execution, and each parallel process will continue on to the next step in the plan, processing its own output. PARALLEL_COMBINED_WITH_CHILD Parallel execution in which the input comes from the same process. |
|
PARTITION_START |
First partition in a range of partitions. A numeric value n indicates a starting partition identified at compile time. A value of "KEY" indicates that the starting partition will be identified at runtime based on partition key values. The value "ROW REMOVE_LOCATION" indicates that the starting partition will be determined at runtime based on each row to be retrieved. "INVALID" indicates that no range of partitions applies. |
|
PARTITION_STOP |
Last partition in a range of partitions. Takes on the forms n , "KEY," and "ROW REMOVE_LOCATION," as described for PARTITION_START. |
|
PARTITION_ID |
Step in the plan that will compute PARTITION_START and PARTITION_STOP. |
|
OTHER |
Other potentially useful information. See OTHER_TAG. |
|
DISTRIBUTION |
Method used to distribute rows from producer query servers to consumer query servers; value will be one of the following: PARTITION (ROWID) Rows are mapped to parallel servers based on table/index partitioning, using ROWID. PARTITION (KEY) Rows are mapped to parallel servers based on table/index partitioning, using a set of columns. HASH Rows are mapped to parallel servers using a hash function on a join key. RANGE Rows are mapped to parallel servers via sort-key ranges. ROUND-ROBIN Rows are mapped randomly to parallel servers. BROADCAST All rows in the table are sent to each parallel query server. QC (ORDER) Rows are sent, in order, to the query coordinator . QC (RANDOM) Rows are sent randomly to the query coordinator. |
|
CPU_COST |
CPU cost estimate that is proportional to the number of machine cycles required for an operation. |
|
IO_COST |
I/O cost estimate that is proportional to the number of data blocks read by an operation. |
|
TEMP_SPACE |
Estimate, in bytes, of the temporary disk space needed by an operation. |
|
ACCESS_PREDICATES |
Predicates used to identify rows required for a step. |
|
FILTER_PREDICATES |
Predicates used to filter rows from a step. |
|
PROJECTION |
Expressions generated by an operation. |
|
TIME |
Elapsed-time estimate for an operation, in seconds. |
|
QBLOCK_NAME |
Name of the query block, which you can specify yourself using the QB_NAME hint. |
12.2.3.3 Making sense of the results
The key to interpreting an execution plan is to understand that the display is hierarchical. A step may consist of one or more child steps, and these child steps are shown indented underneath their parent. Executing any given step involves executing all its children, so to understand the plan, you pretty much have to work your way out from the innermost step. For each step in the plan, you'll at least want to look at the operation name, at any options that apply, and at the object of the operation. You may also want to look at the optimizer's cost estimate. All of these are shown in Figure 12-1.
|
If you're using the cost-based optimizer, it will compute an estimated cost for each operation and for the statement as a whole. In Figure 12-1, the estimate cost for the SELECT STATEMENT operation is 11. This cost means nothing by itself, but the optimizer uses it to compare alternative plans resulting from the query. If you add a hint to the query that changes the cost estimate from 11 to 22, you've probably made your query's performance worse . If you make a change that drives your query's cost from 11 to 5, you've likely made an improvement. Don't fall into the trap, though, of comparing cost estimates from two, unrelated queries.
|
Table 12-2 provides a brief description of the various operations, together with their options, that you may see when querying the plan table. For more detailed information about any of these operations, refer to the Oracle Database Performance Tuning Guide (Oracle Corporation) .
Table 12-2. EXPLAIN PLAN operations
|
Operation |
Description |
Option |
|---|---|---|
|
AND-EQUAL |
This step will have two or more child steps, each of which returns a set of ROWIDs. The AND-EQUAL operation selects only those ROWIDs that are returned by all the child operations. |
None |
|
BITMAP |
Performs an operation involving one or more bitmaps, as described in the accompanying option. |
CONVERSION TO ROWIDS Converts a bitmap from a bitmap index to a set of ROWIDs that can be used to retrieve the actual data. CONVERSION FROM ROWIDS Converts a set of ROWIDs into a bitmapped representation. CONVERSION COUNT Counts the number of rows represented by a bitmap. INDEX SINGLE VALUE Retrieves the bitmap for a single key value. For example, if the field was a YES/NO field, and your query wanted only rows with a value of "YES," then this operation would be used. INDEX RANGE SCAN Similar to BITMAP INDEX SINGLE VALUE, but bitmaps are returned for a range of key values. INDEX FULL SCAN The entire bitmap index will be scanned. MERGE Merges two or more bitmaps together, and returns one bitmap as a result. This is an OR operation between two bitmaps. The resulting bitmap will select all rows from the first bitmap plus all rows from the second bitmap. MINUS Opposite of a MERGE, and may have two or three child operations that return bitmaps. The bitmap returned by the first child operation is used as a starting point. All rows represented by the second bitmap are subtracted from the first. If the column is nullable, then all rows with null values are also subtracted. OR Takes two bitmaps as input, ORs them together, and returns one bitmap as a result. The returned bitmap will select all rows from the first plus all rows from the second. AND Takes two bitmaps as input, ANDs them together, and returns one bitmap as a result. The returned bitmap will select all rows represented in both of the input bitmaps. KEY ITERATION Takes each row and finds that row's corresponding bitmap in a bitmap index. |
|
CONNECT BY |
Rows are being retrieved hierarchically because the query was written with a CONNECT BY clause. |
None |
|
CONCATENATION |
Multiple sets of rows are combined into one set, essentially a UNION ALL. |
None |
|
COUNT |
Counts the number of rows that have been selected from a table. |
STOPKEY The number of rows to be counted is limited by the use of ROWNUM in the query's WHERE clause. |
|
DOMAIN INDEX |
Retrieves ROWIDs from a domain index. |
None |
|
FILTER |
Takes a set of rows as input, and eliminates some of them based on a condition from the query's WHERE clause. |
None |
|
FIRST ROW |
Retrieves only the first row of a query's result set. |
None |
|
FOR UPDATE |
Locks rows that are retrieved. This would be the result of specifying FOR UPDATE in the original query. |
None |
|
HASH JOIN |
Joins two tables using a hash join method. |
ANTI Performs a hash anti-join (e.g., NOT EXISTS). SEMI Performs a hash semi-join (e.g., EXISTS). RIGHT ANTI Performs a hash right outer anti-join. RIGHT SEMI Performs a hash right outer semi-join. OUTER Performs a hash left outer join. RIGHT OUTER Performs a hash right outer join. |
|
INDEX |
Performs one of the index-related operations described in the Option column. |
UNIQUE SCAN The lookup of a unique value from an index. You will see this only when the index is unique; for example, an index used to enforce a primary key or a unique key. RANGE SCAN An index is being scanned for rows that fall into a range of values. The index is scanned in ascending order. RANGE SCAN DESCENDING Same as RANGE SCAN, but the index is scanned in descending order. FULL SCAN Scans all ROWIDs in an index, in ascending order. FULL SCAN DESCENDING Scans all ROWIDs in an index, in descending order. SKIP SCAN Retrieves ROWIDs from an index without using the leading column. Processing skips from one leading column to the next. FAST FULL SCAN Scans all ROWIDs in an index in whatever order they can be most efficiently read from the disk. No attempt is made to read in ascending or descending order. |
|
INLIST ITERATOR |
One or more operations are to be performed once for each value in an IN predicate. |
None |
|
INTERSECTION |
Two rowsets are taken as input, and only rows that appear in both sets are returned. |
None |
|
MERGE JOIN |
Joins two rowsets based on some common value. Both rowsets will first have been sorted by this value. This is an inner join. |
OUTER Similar to a MERGE JOIN, but an outer join is performed. ANTI Indicates that an anti-join is being performed. SEMI Indicates that a semi-join is being performed. CARTESIAN Indicates that the merge-join technique is being used to generate a Cartesian product. |
|
MINUS |
This is the result of the MINUS operator. Two rowsets are taken as inputs. The resulting rowset contains all rows from the first input that do not appear in the second input. |
None |
|
NESTED LOOPS |
This operation will have two children, each returning a rowset. For every row returned by the first child, the second child operation will be executed. |
OUTER Represents a nested loop used to perform an outer join. |
|
PARTITION |
Executes an operation for one or more partitions. The PARTITION_START and PARTITION_STOP columns show the range of partitions over which the operation is performed. |
SINGLE The operation will be performed on a single partition. ITERATOR The operation will be performed on several partitions. ALL The operation will be performed on all partitions. INLIST The operation will be performed on the partitions, and is being driven by an IN predicate. INVALID Indicates no partitions are to be operated upon. |
|
PROJECTION |
Takes multiple queries as input and returns a single set of records. This is used with INTERSECTION, MINUS, and UNION operations. |
None |
|
PX ITERATOR |
Is a parallel query operation involving the division of work among multiple, query slave processes that run in parallel. |
BLOCK, CHUNK An object is divided into chunks that are then distributed to query slaves. |
|
PX COORDINATOR |
Represents a query coordinator, which controls all operations below it in the execution plan. |
None |
|
PX PARTITION |
Same as the PARTITION operation, but the work is spread over multiple, parallel processes. |
None |
|
PX RECEIVE |
Represents the receiving of data as it is being repartitioned among parallel processes. |
None |
|
PX SEND |
Represents the transmission of data as it is being repartitioned among parallel processes. |
None |
|
REMOTE |
Indicates that a rowset is being returned from a remote database. |
None |
|
SEQUENCE |
An Oracle sequence is being accessed. |
None |
|
SORT |
Sorts the result set or an intermediate result set. The sort may be either parallel or full. The purpose of the sort is described by the option that is given. |
AGGREGATE Applies a group function, such as COUNT, to a rowset, and returns only one row as the result. UNIQUE Sorts a rowset and eliminates duplicates. GROUP BY Sorts a rowset into groups. This is the result of a GROUP BY clause. JOIN Sorts a rowset in preparation for a join. See MERGE JOIN. ORDER BY Sorts a rowset in accordance with the ORDER BY clause specified in the query. |
|
TABLE ACCESS |
Data is read from a table, using the method indicated by the option that is always given for this operation. |
FULL Oracle will read all rows in the specified table. CLUSTER Oracle will read all rows in a table that match a specified index cluster key. HASH Oracle will read all rows in a table that match a specified hash cluster key. BY ROWID Oracle will retrieve a row from a table based on its ROWID. BY ROWID RANGE Rows will be retrieved corresponding to a range of ROWIDs. SAMPLE BY ROWID RANGE A sample of rows will be retrieved from a ROWID range. BY USER ROWID Rows are retrieved using ROWIDs supplied by the user (i.e., by the SQL statement). BY INDEX ROWID Rows are retrieved using ROWIDs returned by index searches. BY GLOBAL INDEX ROWID Rows are returned from a partitioned table using ROWIDs from global indexes. BY LOCAL INDEX ROWID Rows are returned from a partitioned table using ROWIDs from a combination of global and local indexes or from only local indexes. |
|
UNION |
Takes two rowsets, eliminates duplicates, and returns the result as one set. |
None |
|
VIEW |
Executes the query behind a view and returns the resulting rowset. |
Nonestatements |
