Designing Web Applications
In Web application design, most of the activities are the same as for any client/server system: partitioning the objects into the system's tiers and developing the necessary infrastructure and helper classes to add to the analysis model. In Web-centric systems, Web pages are first-class objects, and the WAE gives us a notation for including them in our design models.
Proper partitioning of the business objects in a Web application is critical and depends on the architecture. Objects may reside exclusively on the server, the client, or both. In a sophisticated Web application, input field validation objects and specialized user interface widgets will likely run on the client, whereas container objects, such as a customer list or a product catalog, will exist only on the server. Some objects, such as an invoice, may have lives in both. For example, a customer invoice object could exist on the server, where its life cycle and persistence are managed. This object could be sent to the client in the form of an XML document. The XML document could be used as the invoice's state and bring to life a client-side invoice object. That object would have some of the interfaces that the one on the server has. Sophisticated behaviors like this are what make modeling so invaluable.
When the job is at hand, partitioning objects is straightforward. Thin Web client applications place all objects behind the server, running either on the Web server or on another tier associated with the server. Thick Web client applications allow some objects to execute on the client. There are, however, strict rules governing the use of objects on the client. Web delivery applications have the most freedom in the placement of objects, being essentially distributed object systems that happen to use a browser.
Thick Web Client Applications
When designing thick Web client Web applications, a large number of the objects discovered during analysis can be easily partitioned in the first pass. For the most part, persistent objects, container objects, shared objects, and complex objects all belong on the server. Objects with associations to server resources, such as databases and legacy systems, also belong in the server tier. Objects that maintain static associations or dependencies with any of these objects must also exist on the server.
It is easier to identify which objects can exist on the client than to identify those that can't. An object can exist on the client if it has no associations or dependencies with objects on the server and has associations and dependencies only with other client resources, such as browsers and Java applets. Candidate objects for the partitioning on the client are field validation objects, user interface controls, and navigation assisting controls.
When we first think of objects on the client, there is no stipulation on how they are to be implemented. They are simply objects that are invoked during the browser's processing of the Web page. Client objects can be implemented with JavaScript, JavaBeans, applets, ActiveX (COM), or even plug-ins. During analysis, these objects simply represent a mechanism to implement a requirement or a use case scenario. During design, however, they need to be given an architectural underpinning. They need to be realizable.
Web Delivery Web Applications
The Web delivery architectural pattern is essentially a distributed object system that is based on a Web site. This type of application uses client and server communication protocols other than HTTP. Real objects can execute in the context of the client or the browser and therefore have access to its resources. These objects can also communicate directly with objects on the server or even other browsers.
Partitioning objects for this type of architecture depends mostly on the nature of the individual objects. One of the primary reasons for distributing objects to the client is to take some of the load off the server. It is also natural to place objects in the part of the system where they will be most effective. Putting a date validation object on the server, for example, doesn't seem like the brightest idea a designer might have. A date validation object is most useful on the client, where it can notify the user of an invalid date immediately, avoiding all the communication overhead of a server trip.
As a general rule, I like to place objects where they have the easiest access to the data and the collaborations they require to perform their responsibilities. If an object can exist on the client and if most, if not all, its associations are on client objects, that object is a likely candidate for placement on the client.
Identifying Web Pages
While the objects are being partitioned, Web pages are also being defined. This activity involves the discovery of Web pages and their relationships with one another and with the objects of the system. This step too depends heavily on the architectural pattern of the application. For instance, it is entirely possible for a Web delivery type of application to use only one Web page! This particular page would most certainly be loaded with complex objects and applets, yet for some situations, it could be the best solution.
A perfect example of these types of applications are those that make extensive use of Macromedia's Flash plug-ins. For example, my young son is a fan of Nick Jr.'s online Web site (www.nickjr.com). This site offers plenty of activities for young children, including multimedia storytelling and games. On this site, the vast majority of the functionality is managed by the Flash movie plug-ins, not Web page client- or server-side mechanisms. Most Web applications, however, use many single-purpose Web page components.
Web page design elementsclient and server pagesare discovered by first looking at the UX model and understanding the software architecture document, which outlines the rules for when to create new Web page design elements and what responsibilities each has. In the early generations of Web applications, Web pages mapped one to one to what we now refer to as UX model screens. Each page was responsible for preparing its output by interacting with server-side objects. Today, architectures are more complex. Today's development environments and frameworks enable us to build more robust, sophisticated Web applications with the same effort we used to create simple ones just four years ago.
The two predominant Web architecture frameworks available today are J2EE and .NET. Their approaches to managing Web page requests differ slightly. Both still maintain the concept of a Web page and are moving to treat Web pages even more like true objects. The major difference between these approaches is subtle. In the .NET framework, the Web page is cohesive. Although made up of a variety of actual components.aspx files, Web page, code behind superclass, Web serverinserted client scripts, .resx resource filesthe general idea is to have a defined Web page be responsible for handling all client-side events. This means that a Web page should be responsible for handling its own form submissions.
The .NET framework provides a lot of support code that the normal developer never sees to facilitate the creation of event handlers for client-side controls. When an ASPX page is created and ASPX controls are placed in it, the Microsoft Development Environment (MDE) makes it very easy to define validation functions and to specify event handlers that are executed on the server. Achieving this can be a little tricky. The general strategy is to include references to JavaScript files that include a number of functions that are assigned as event handlers to the HTML elements. When an event is fired, the JavaScript functions are called, and these make the determination, based on properties set in the page, whether to submit the page's form back to the server for it to execute the real event handlers on the server. [5]
[5] The do auto post back property determines whether server-side event handlers are invoked immediately when the event is fired in the client.
In Figure 11-10, the ASPX file myPage.aspx is modeled with a «server page» stereotyped class. The C# code behind class myPage.cs is a superclass to the ASPX class and contains the majority of the event-handling code. The general strategy is for the code behind to contain the majority of the business logic interaction code and event-handling code and to leave the ASPX file to focus on building the output page. The ASPX file is written mostly in HTML.
Figure 11-10. .NET paradigm for handling user input
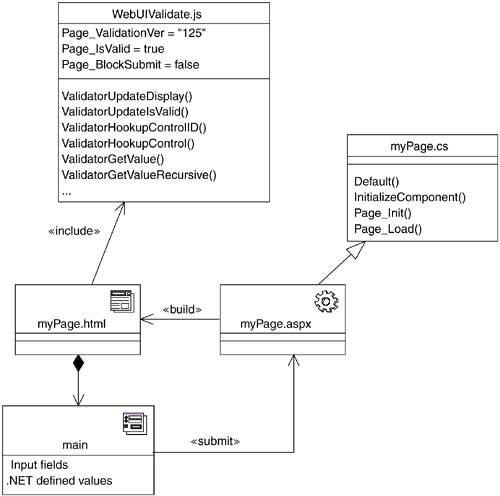
In Figure 11-10, the built client page includes a JavaScript file, WebUIValidate.js, which contains a number of JavaScript functions, some of which are assigned as event handlers to the client page's input fields and other HTML elements. The framework also inserts state information as HTML hidden input fields, used by the framework to synchronize the event handling.
Of course, not all user interaction is made with .NET-assisted event handling; many links point to other Web pages in the system. The general strategy is to have the code for accepting user input in the same page that delivered the page to the user.
In the J2EE world, the term JavaServer Pages Model 2 Architecture describes the general philosophy of separating the two mechanisms for accepting and processing input and building output. The general strategy is to use servlets for accepting all user-supplied input. A servlet is a completely Java-written component. There is no mix of HTML with the Java code, as in a JavaServer Page. With the submitted data accepted and processed, the servlet delegates the building of the response page to a JSP. JavaServer pages are more appropriate for building HTML output since the majority of the code in the component is often HTML. Figure 11-11 shows how a form submits its data to a servlet, which accepts the posted data, interacts with the necessary server-side objectsmost likely EJB Session beansto adjust the state of the server, and then forwards the remainder of the processing to a JavaServer Page.
Figure 11-11. JavaServer Page Model 2 Architecture
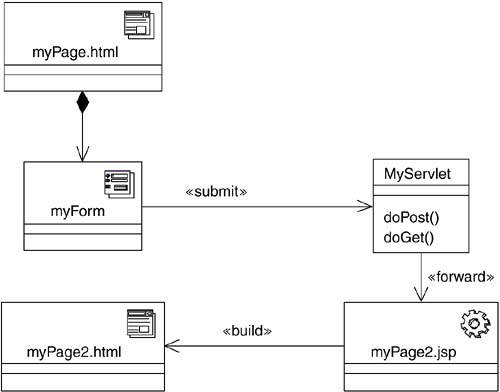
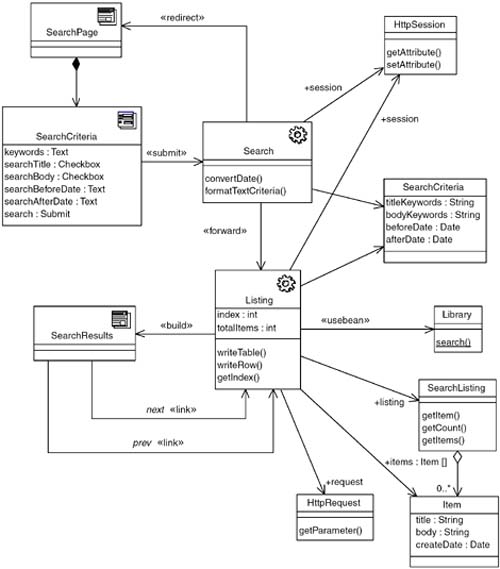
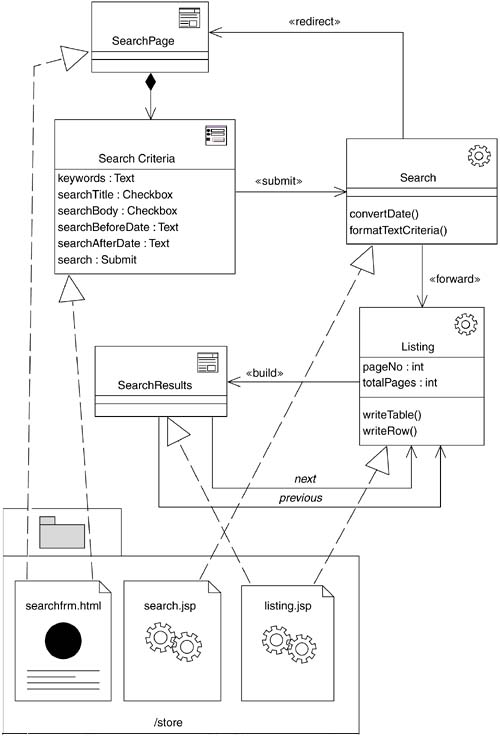
Figure 11-12 shows a portion of a design model for a classic search engine. In this diagram, the Web page with the search form is not built by a server page, so there is the option of using a «static page» component for its implementation. The search form submits its data to the Search «server page», which is responsible for accepting the search request and processing it but not for building the response page. That is the job of the Listing «server page». When the Search page has completed the search, control is forwarded to the Listing page, which uses the built-in session management mechanism for J2EE applications (HttpSession). The SearchResults client page implements a page-scrolling mechanismPaged Dynamic List, Page-by-Page Iteratorand has two «link» relationships to itself. The parameter tag value for each of these links has a value to indicate which direction to scroll: { parameters="scroll=next" } and { parameters="scroll=prev" }.
Figure 11-12. Design model fragment of catalog search functionality
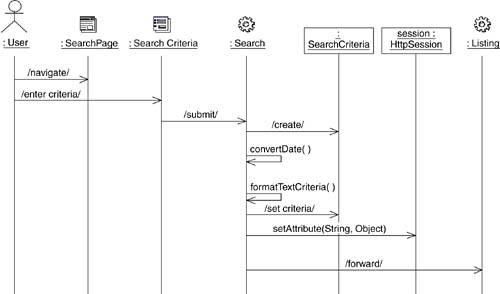
The expression of Web page designs is only half complete in class diagrams. Because they involve stereotyped classes, they can be referenced in interaction diagrams as well. Figure 11-13 shows the sequence diagram of a search collaboration. Even though this is a design model sequence diagram, nonoperation messages are sometimes drawn to simplify it. For example, the Search server page sends the /set criteria/ message to the SearchCriteria object. In reality, this is just an abbreviation of a number of setXXX() calls to the class, which are not necessary to enumerate in this diagram.
Figure 11-13. Search catalog sequence diagram using stereotyped elements
The scenario continues in another diagram since sequence diagrams at the design model level tend to get very wide because of all the object instances. It's a good idea to keep the breadth of your sequence diagrams manageable. If you have to scroll back and forth horizontally all the time, it makes it difficult to get any value out of the diagram.
Figure 11-14 shows how the Listing page builds the response HTML. This diagram shows how the list page is responsible for getting the current index: by examining the request parameters for the direction of the scroll and the current index cached in the session. The actual SearchCriteria object is stored in the session and passed to the Library, which returns a collection of items that the Listing page uses to build the table and rows in the response.
Figure 11-14. Build Listing sequence diagram
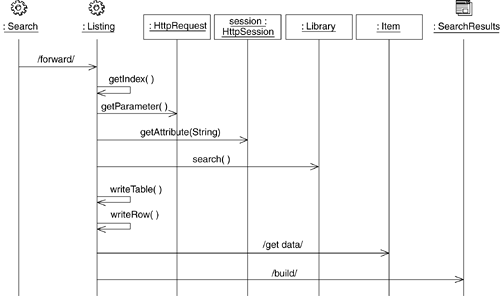
Figure 11-15 shows how the Web components match up with the classes. In this diagram, the components are all under the physical root at the same level. The physical root is named /store, which also happens to be the context. So a client browser would request the search page by using the URL http://localhost/store/searchform.html. (Of course, a real host name would need to be supplied to get this to work.)
Figure 11-15. Component view realizations of logical-view classes
Client-Side Scripting
Designing Web applications that have dynamic client pages requires careful attention to the partitioning of the objects. In thin Web client applications, there was no temptation to draw associations between client objects and server objects because there were essentially no user-definable client objects to begin with! Thick Web client applications, however, can have all sorts of objects and activity on the client.
Figure 11-16 shows a simple class diagram with a «client page» that has two defined JavaScript functions. This diagram also shows an «object» stereotyped association to the PolynomialView applet class. The client page also has an HTML form included with it. In this example, the applet is a second-order polynomial graph viewer. The applet draws a simple graph on the screen (Figure 11-17, based on the values supplied in the HTML form.
Figure 11-16. Modeling applets and other embedded controls
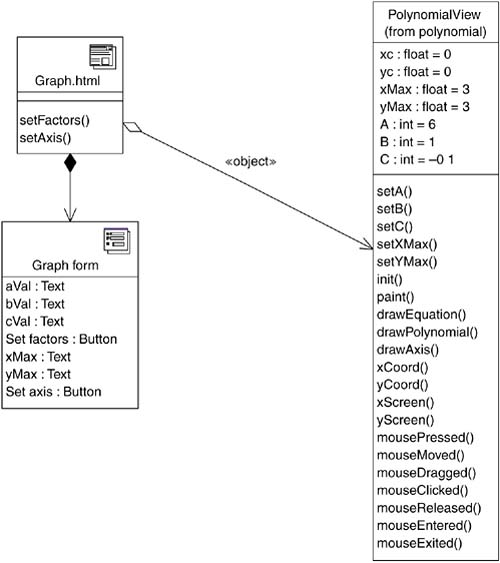
Figure 11-17. Applet as part of an HTML page
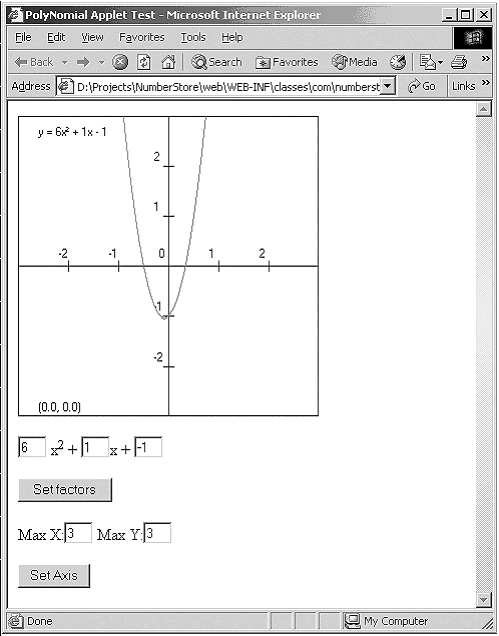
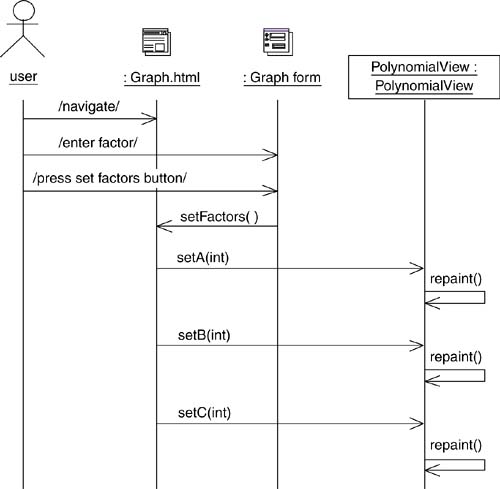
Figure 11-18 shows a sequence diagram that explains how JavaScript functions in the client page call operations on the applet. The message /enter factor/ is shorthand notation indicating that the user enters values in the form. The user clicks a button in the page, the event handler for the click message, setFactors(), calls several setX() operations on the applet. Each of these set operations forces a repaint() of the display.[6]
[6] After viewing this sequence diagram, it was clear that I had designed this applet poorly, but I'll leave it up to you to redesign. All the code for this example is available as a download at www.wae-uml.org.
Figure 11-18. Sequence diagram showing applet and DOM communication
Overview of Modeling and Web-Related Technologies
- What This Book Is About
- Role of Modeling
- Role of Process
- Influences of Architecture
- Web Application Basics
- HTTP
- HTML
- Web Applications
- Summary
- Discussion
- Activities
- Dynamic Clients
- Document Object Model
- Scripting
- JavaScript Objects
- Custom JavaScript Objects
- Events
- Java Applets
- ActiveX/COM
- Summary
- Discussion
- Activities
- Beyond HTTP and HTML
- Distributed Objects
- XML
- Web Services
- Summary
- Discussion
- Activities
- Security
- Types of Security Risk
- Technical Risk
- Server-Side Risks
- Client-Side Risks
- Security Strategies
- Modeling Secure Systems
- Summary
- Discussion
- Activities
Building Web Applications
- Building Web Applications
- The Process
- Overview of Software Development
- Software Development for Web Applications
- The Artifacts
- Summary
- Discussion
- Activities
- Defining the Architecture
- Architectural Viewpoints
- Architecture Activities
- Web Application Presentation Tier: Architectural Patterns
- Summary
- Discussion
- Activities
- Requirements and Use Cases
- The Vision
- Requirements
- Glossary
- Gathering and Prioritizing Requirements
- Use Cases
- The Use Case Model
- The User Experience
- Summary
- Discussion
- Activities
- The User Experience
- Artifacts of the UX Model
- UX Modeling with UML
- Summary
- Activities
- Analysis
- Iteration
- Analysis Model Structure
- UX Model Mapping
- Architecture Elaboration
- Summary
- Discussion
- Activities
- Design
- Web Application Extension for UML
- Designing Web Applications
- Mapping to the UX Model
- Integrating with Content Management Systems
- Guidelines for Web Application Design
- Summary
- Discussion
- Activities
- Advanced Design
- HTML Frames
- Advanced Client-Side Scripting
- Virtual and Physical HTTP Resources
- JavaServer Page Custom Tags
- Summary
- Discussion
- Activities
- Implementation
- Number Store Main Control Mechanism
- Glossary Application Tag Libraries
- Summary
- Discussion
- Activities
- Overview
- HTML to UML
- UML to HTML
- Mapping Web Elements to UML, and Vice Versa
- Vision
- Background
- Requirements and Features
- Software Architecture Document
- Sample Screen Shots
- Controlled Controllers Pattern
- Use Case View
- Analysis Model Classes
- Analysis Model Collaborations
- Master Template Pattern
- Overview
- Use Case View
- Logical View
- Glossary Application
- Requirements and Use Case Model
- User Experience Model
- Design Model
- Sample Screen Shots
EAN: 2147483647
Pages: 141
