The ADO.NET Object Model
Overview
As a general rule, the most successful man in life is the man who has the best information.
-Benjamin Disraeli
ADO.NET is the latest in a long line of database-access technologies that began with the Open DataBase Connectivity (ODBC) API several years ago. Written as a C-style library, ODBC was designed to provide a uniform API to issue SQL calls to various database servers. In the ODBC model, database-specific drivers hide any difference and discrepancy between the SQL language used at the application level and the internal query engine. Next, COM landed in the database territory and started a colonization process that culminated with OLE DB.
OLE DB has evolved from ODBC and, in fact, the open database connectivity principle emerges somewhat intact in it. OLE DB is a COM-based API aimed at building a common layer of code for applications to access any data source that can be exposed as a tabular rowset of data. The OLE DB architecture is composed of two elements—a consumer and a provider. The consumer is incorporated in the client and is responsible for setting up COM-based communication with the data provider. The OLE DB data provider, in turn, receives calls from the consumer and executes commands on the data source. Whatever the data format and storage medium are, an OLE DB provider returns data formatted in a tabular layout—that is, with rows and columns.
Because it isn't especially easy to use and is primarily designed for coding from within C++ applications, OLE DB never captured the heart of programmers, even though it could guarantee a remarkable mix of performance and flexibility. ActiveX Data Objects (ADO)—roughly, a COM automation version of OLE DB—came a little later just to make the OLE DB technology accessible from Microsoft Visual Basic and ASP applications. When used, ADO acts as the real OLE DB consumer embedded in the host applications. ADO was invented in the age of connected, two-tier applications, and the object model design reflects that. ADO makes a point of programming redundancy: it usually provides more than just one way of accomplishing key tasks, and it contains a lot of housekeeping code. For all these reasons, although it's incredibly easy to use, an ADO-based application doesn't perform as efficiently as a pure OLE DB application.
ADO.NET is a data-access layer tailor-made for the .NET Framework. It was heavily inspired by ADO, which has emerged over the past few years as a very successful object model for writing data-aware applications. The key design criteria for ADO.NET are simplicity and performance. Those criteria typically work against each other, but with ADO.NET you get the power and performance of a low-level interface combined with the simplicity of a modern object model. Unlike ADO, though, ADO.NET has been purposely designed to observe general, rather than database-oriented, guidelines.
Several syntactical differences exist between the object models of ADO and ADO.NET. In spite of this, the functionalities of ADO and ADO.NET look much the same. This is because Microsoft put a lot of effort in aligning some programming aspects of the ADO.NET object model with ADO. In this way, data developers don't need to become familiar with too many new concepts to use ADO.NET and can work with a relatively short learning curve. With ADO.NET, you probably won't be able to reuse much of your existing code. You'll certainly be able, though, to reuse all your skills.
The NET Data Access Layer
The key improvements in ADO.NET are the rather powerful disconnected model exposed through the DataSet object, the strong integration with XML, and the seamless integration with the rest of the .NET Framework, including ASP.NET applications and Web services. Additionally, the performance of ADO.NET is very good, and the integration with Microsoft Visual Studio .NET is unprecedented. If you're writing a new application in the .NET Framework, deciding whether to use ADO.NET is a no-brainer.
| Note |
Using ADO in .NET applications is still possible, but for performance and consistency reasons its use should be limited to a very few and special cases. For example, ADO is the only way you have to work with server cursors, and ADOX is the variation of ADO that provides you with an object model for managing table structure and schema information. On the other hand, ADO recordsets can't be directly bound to ASP.NET or Microsoft Windows Forms databound controls. We'll cover data binding in Chapter 6 and Chapter 7. |
A key architectural element in the ADO.NET infrastructure is the managed provider, which can be considered as the .NET counterpart of the OLE DB provider. A managed data provider enables you to connect to a data source and retrieve and modify data. Compared to the OLE DB provider, a .NET managed provider has a simplified data-access architecture made of a smaller set of interfaces and based on .NET Framework data types. Figure 5-1 illustrates the internal structure of a .NET data provider.
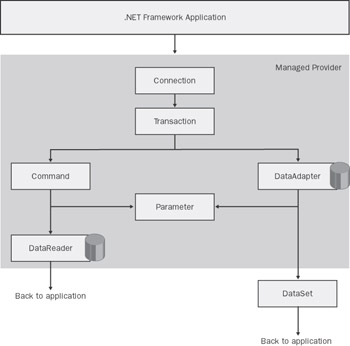
Figure 5-1: The connections between the .NET Framework classes that form a typical managed provider.
A COM-based OLE DB provider is a monolithic component. In contrast, a managed provider is made of a suite of classes, each of which represents a particular step in the connection model that a data-aware application implements. A managed provider is composed of classes used to connect to a particular data source, manage transactions, execute commands, and access result sets. For each of these steps, the managed provider supplies a particular class with its own set of properties, methods, and events. The union of these classes form the logical entity known as the managed provider for that data source.
| Note |
In the .NET Framework, each managed provider is characterized by a prefix that qualifies the various classes of the same type. For example, the class that manages connections to Microsoft SQL Server is named SqlConnection, while the class that opens a connection to an Oracle database is OracleConnection. In the former case, the prefix Sql is used; in the latter case, the prefix used is Oracle. |
Architecture of a NET Managed Provider
The classes in the managed provider interact with the specific data source and return data to the application using the data types defined in the .NET Framework. The logical components implemented in a managed provider are those graphically featured in Figure 5-1 and detailed in Table 5-1.
|
Component |
Description |
|---|---|
|
Command |
Represents a command that hits the underlying database server |
|
Connection |
Creates a connection with the specified data source, including SQL Server, Oracle, and any data source for which you can indicate either an OLE DB provider or an ODBC driver |
|
DataAdapter |
Represents a database command that executes on the specified database server and returns a disconnected set of records |
|
DataReader |
Represents a read-only, forward-only cursor created on the underlying database server |
|
Parameter |
Represents a parameter you can pass to the command object |
|
Transaction |
Represents a transaction to be made in the source database server |
The functionalities supplied by a .NET data provider fall into a couple of categories:
- Support for disconnected data—that is, the capability of populating the ADO.NET DataSet class with fresh data
- Support for connected data access, which includes the capability of setting up a connection and executing a command
Each managed provider that wraps a real-world database server implements all the objects in Table 5-1 in a way that is specific to the data source. The components listed in Table 5-1 are implemented based on methods and properties defined by the interface. lists possible interfaces for data providers.
|
Interface |
Description |
|---|---|
|
IDataAdapter |
Populates a DataSet object, and resolves changes in the DataSet object back to the data source |
|
IDataParameter |
Allows implementation of a parameter to a command |
|
IDataReader |
Reads a forward-only, read-only stream of data created after the execution of a command |
|
IDbCommand |
Represents a command that executes when connected to a data source |
|
IDbConnection |
Represents a unique session with a data source |
|
IDbDataAdapter |
Supplies methods to execute typical operations on relational databases (such as insert, update, select, and delete) |
|
IDbTransaction |
Represents a local, nondistributed transaction |
Note that all these interfaces except IDataAdapter are officially considered to be optional. However, any realistic data provider that manages a database server would implement them all. Managed providers that implement only the IDataAdapter interface are said to be simple managed providers.
Managed Providers vs. OLE DB Providers
OLE DB providers and managed data providers are radically different types of components that share a common goal—to provide a unique and uniform programming interface for data access. The differences between OLE DB providers and .NET data providers can be summarized in the following points:
- Component Technology OLE DB providers are in-process COM servers that expose a suite of COM interfaces to consumer modules. The dialog between consumers and providers takes place through COM and involves a number of interfaces. More roughly, the dialog is fairly formal and based on a rigid etiquette. The OLE DB specification stems from the Universal Data Access (UDA) vision, a Microsoft white paper in which data was perceived as being made of building blocks that ad hoc tools normalized to a common tabular format—the rowset. For this reason, the specification for OLE DB components were rather formal and even a bit quirky. A few years of real-world experience showed the specification to be much too complex, quirky, and error-prone for being ported as is to a new framework—specifically, the .NET Framework.
A .NET data provider contains the gist of OLE DB providers, just as OLE DB providers were based on the battle-tested characteristics of ODBC drivers. A managed data provider is not a monolithic component, but a suite of managed classes whose overall design looks into one particular data source rather than blinking at an abstract and universal data source.
- Internal Implementation Both types of providers end up making calls into the data-source programming API. In doing so, though, they provide a dense layer of code that separates the data source from the calling application. Learning from the OLE DB experience, Microsoft designed .NET data providers to be more agile and simple. Fewer interfaces are involved, and the conversation between the caller and the callee is more direct and as informal as possible. In OLE DB, data-access components are designed to provide a database-independent layer for accessing generic databases. The value of such a generic layer is that it provides nearly universal access. Its major drawback is the difficulty to deliver database-specific optimizations. In .NET, data access components are simpler and less general, but they're also more practical and effective.
- Application Integration Another aspect in .NET that makes the conversation between caller and callee more informal is the fact that managed providers return data using the same data structures that the application would use to store it. In OLE DB, the data-retrieval process is more flexible but also more complex because the provider packs data in flat memory buffers and leaves the consumer responsible for mapping that data into usable data structures, such as the ADO Recordset or a user-defined class. In .NET, the integration with the application is total and the managed provider packs return data in a ready-to-use format using types from the .NET Framework.
Calling into an OLE DB provider from within a .NET application is even more expensive because of the type and data conversion necessary to make the transition from the managed environment of the common language runtime (CLR) to the COM world. Calling a COM object from within a .NET application is possible through the COM interop layer, but doing so comes at a cost. In general, to access a data source from within a .NET application, you should always use a managed provider instead of OLE DB providers or ODBC drivers. You should be doing this primarily because of the transition costs, but also because managed providers are normally more modern tools based on an optimized architecture.
Not all data sources, though, have a managed provider available. In these cases, resorting to old-fashioned OLE DB providers or ODBC drivers is a pure necessity. For this reason, the .NET Framework encapsulates in managed wrapper classes the logic needed to call into a COM-style OLE DB provider or a C-style ODBC driver.
| Note |
Data-driven .NET applications are in no way limited to managed providers. They can access virtually any data source for which any of the following data-access components exists: a managed provider, OLE DB provider, or ODBC driver. In terms of raw performance, a managed provider is the fastest approach, but functionally speaking, others are effective as well. Note that in general you'll have a choice of multiple providers from various vendors. They'll certainly supply a common subset of functionality, but they won't necessarily supply the same set of features or the same implementation. |
Data Providers Available in the .NET Framework
The .NET Framework 1.0 supports only two managed providers—those for SQL Server 7.0 or later and those for the main OLE DB providers. A few months after the release of .NET Framework 1.0, Microsoft released as separate downloads a managed provider for ODBC data sources and for Oracle databases. In the .NET Framework 1.1, these additional data providers have been incorporated in the framework. Table 5-3 details the managed providers available in the .NET Framework 1.1.
|
Data Source |
Namespace |
Description |
|---|---|---|
|
SQL Server |
System.Data.SqlClient |
Targets SQL Server 7.0 and 2000, including XML extensions. To maximize performance, hooks up the database at the wire level using optimized packets. |
|
OLE DB providers |
System.Data.OleDb |
Targets OLE DB providers, including SQLOLEDB, MSDAORA, and the JET engine. |
|
ODBC drivers |
System.Data.Odbc |
Targets several ODBC drivers, including those for SQL Server, Oracle, and the Jet engine. |
|
Oracle |
System.Data.OracleClient |
Targets Oracle 9i, and supports all of its data types. |
The OLE DB and ODBC managed providers listed in Table 5-3 are not specific to a physical database server, but rather they serve as a bridge that gives instant access to a large number of existing OLE DB providers and ODBC drivers. When you call into OLE DB providers, your .NET applications jumps out of the managed environment and issues COM calls through the COM interop layer.
The managed providers for SQL Server and Oracle, on the other hand, hook up the database server directly to the wire level and obtain a substantial performance advantage. As of version 1.1 of the .NET Framework, Oracle and SQL Server are the only databases for which Microsoft supplies a direct data provider. Third-party vendors supply managed providers for a few other databases such as MySQL. For other major databases—such as IBM DB2, AS/400, Sybase, and Informix—managed providers have been announced and in some cases are already available in beta versions. Having them available on the market is only a matter of time.
Alternative Ways of Exposing Data
In .NET, managed providers are only the preferred way of exposing database contents—that is, data in a wire format or data that must be accessed concurrently and through transactions. If you just have generic data to publish (for example, a proprietary text or binary file), you should expose it as XML or by using a simple managed provider. If you have a store to expose, an OLE DB provider still makes sense because you plug into all the existing .NET and Win32 OLE DB consumers, from ADO-driven applications to the data transformation services and from SQL Server replication to the distributed query processor.
Data Sources You Access Through ADO NET
The .NET data provider is the managed component of choice for database vendors to expose their data in an effective way. Ideally, each database vendor should provide a .NET-compatible API that is seamlessly callable from within managed applications. Unfortunately, this is not yet the case. At this time, only a few database servers can be accessed through ADO.NET and managed providers, but the situation is expected to improve over the next few months as .NET takes root as a platform in the software community. If you look back at the state of the art for ODBC in the early 90s and for OLE DB in the late 90s, you'll see the same clear signs of a technology that is slowly but steadily gaining widespread acceptance. Let's review the situation for the major database management systems (DBMS).
Accessing SQL Server
As mentioned, Microsoft supplies a managed provider for SQL Server 7.0 and newer versions. Using the classes contained in this provider is by far the most effective way of accessing SQL Server. Figure 5-2 shows how SQL Server is accessed by .NET and COM clients.
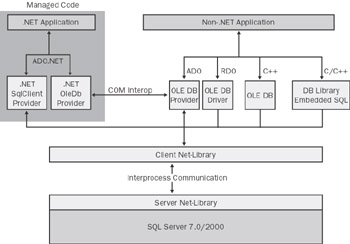
Figure 5-2: Accessing SQL Server by using the managed provider for OLE DB adds overhead because the objects called must pass through the COM interop layer.
A .NET application can access a SQL Server database by using either the native data provider or the COM OLE DB provider via the managed provider for OLE DB data sources. The rub is that the OLE DB provider—a component named SQLOLEDB—is a COM object that can be used only through the COM interop layer, which seamlessly provides for data and type marshaling. You should always use the native data provider. In general, you should have a good reason to opt for SQLOLEDB. A possible good reason is the need to use ADO rather than ADO.NET as the data-access library. As of version 1.1 of the .NET Framework, ADO.NET doesn't fully cover the same set of features available in ADO. For example, if you need to use server cursors, you must resort to ADO. In this case, you use OLE DB to read from and write to SQL Server.
The SQL Server native provider not only avoids paying the performance tax of going down to COM, it also implements some little optimizations when preparing the command for SQL Server. For example, suppose you need to run the following statement:
SELECT * FROM Employees
If you run the command using the native managed provider, the SQL code that actually hits the server is slightly different:
exec sp_executesql N'SELECT * FROM Employees'
The sp_executesql system stored procedure brings advantages when a Transact-SQL statement that has parameter values as the only variation is repeatedly executed. Because the statement itself remains constant, the SQL Server query optimizer is likely to reuse the execution plan it has generated for the first execution. Note, though, that for this feature to work better you should use fully qualified object names in the statement string.
In addition, a statement that goes through the managed provider executes as a remote procedure call (RPC). A statement processed by the OLE DB provider runs as a Transact-SQL batch. The RPC protocol increases performance by eliminating much of the parameter processing and statement parsing done on the server.
| Note |
SQL Server can also be accessed using the Microsoft ODBC driver and the classes in the .NET data provider for ODBC. The classes are located in the System.Data.Odbc namespace in the .NET Framework 1.1. |
Accessing Oracle Databases
The .NET Framework 1.1 includes a managed provider for Oracle databases. The classes are located in the System.Data.OracleClient namespace in the System.Data.OracleClient assembly. Instead of using the managed provider, you can resort to the COM-based OLE DB provider (named MSDAORA) or the ODBC driver. Note, though, that the Microsoft OLE DB provider for Oracle does not support Oracle 9i and its specific data types. In contrast, Oracle 9i data types are fully supported by the .NET managed provider. So by using the .NET component to connect to Oracle you not only get a performance boost, but also increased programming power.
| Note |
The .NET data provider for Oracle requires that Oracle client software (version 8.1.7 or later) be installed on the system before you can use it to connect to an Oracle data source. |
Microsoft is not the only company to develop a .NET data provider for Oracle databases. A few months ago, Core Lab was probably the first vendor to ship such a provider—named OraDirect—whose details can be discovered by stepping through the appropriate links at http://www.crlab.com/oranet. Oracle also couldn't resist jumping in and developing its own .NET data provider immediately after the official release of the .NET Framework 1.0. The latest updates for this component, named Oracle Data Provider for .NET (ODP.NET), can be found at http://otn.oracle.com/ tech/windows/odpnet. ODP.NET features high performance access to the Oracle database while providing access to advanced Oracle functionality not otherwise available in .NET through OLE DB and ODBC layers. ODP.NET is part of the Oracle 9i Release 2 Client, but it can be used with any Oracle 8, Oracle 8i, or Oracle 9i database server. Unlike OLE DB and ODBC access layers, ODP.NET has many optimizations for retrieving and manipulating Oracle native types, such as any flavor of large objects (LOBs) and REF cursors. ODP.NET can participate in transactional applications with the Oracle database acting as the resource manager and the Microsoft Distributed Transaction Coordinator (DTC) coordinating transactions.
Using OLE DB Providers
The .NET data provider for OLE DB providers is a data-access bridge that allows .NET applications to call into data sources for which a COM OLE DB provider exists. While this approach is architecturally less effective than using native providers, it represents the only way to access those data sources when no managed providers are available.
The classes in the System.Data.OleDb namespace, though, don't support all types of OLE DB providers and have been optimized to work with only a few of them, as listed in Table 5-4.
|
Name |
Description |
|---|---|
|
Microsoft.Jet.OLEDB.4. 0 |
The OLE DB provider for the JET engine implemented in Microsoft Access |
|
MSDAORA |
The Microsoft OLE DB provider for Oracle 7 that partially supports some features in Oracle 8 |
|
SQLOLEDB |
The OLE DB provider for SQL Server 6.5 and newer |
The preceding list does not include all the OLE DB providers that really work through the OLE DB .NET data provider. However, only the components in Table 5-4 are guaranteed to work well in .NET. In particular, the classes in the System.Data.OleDb namespace don't support OLE DB providers that implement any of the OLE DB 2.5 interfaces for semistructured and hierarchical rowsets. This includes the OLE DB providers for Microsoft Exchange (EXOLEDB) and for Internet Publishing (MSDAIPP).
| Caution |
The OLE DB .NET data provider does not work with the OLE DB provider for ODBC (MSDASQL). To access an ODBC data source using ADO.NET, you should use the .NET data provider for ODBC. If you try to set the Provider attribute of the connection string to MSDASQL, a runtime error is thrown and no connection is ever attempted. |
In general, what really prevents existing OLE DB providers from working properly within the .NET data provider for OLE DB is the set of interfaces they really implement. Some OLE DB providers—for example, those written using the Active Template Library (ATL) or with Visual Basic and the OLE DB Simple Provider Toolkit—are likely to miss one or more COM interfaces that the .NET wrapper requires.
As of version 1.1 of the .NET Framework, there's no native managed data provider for the Jet engine and Microsoft Access databases. As a result, you should use the OLE DB provider.
Using ODBC Drivers
The .NET data provider for ODBC lets you access ODBC drivers from managed, ADO.NET-driven applications. Although the ODBC .NET data provider is intended to work with all compliant ODBC drivers, it is guaranteed to work well only with the drivers for SQL Server, Oracle, and Jet. Although ODBC might appear to now be an obsolete technology, it's still used in several production environments and for some vendors still represents the only way to connect to their products.
As mentioned earlier, you can't access an ODBC driver through an OLE DB provider. There's no technical reason behind this limitation—it's just a matter of common sense. In fact, calling the MSDASQL OLE DB provider from within a .NET application would drive your client through a double data-access bridge—one going from .NET to the OLE DB provider and one going one level down to the actual ODBC driver.
Accessing Other Data Sources
The list of databases for which a native managed provider exists is not limited to SQL Server and Oracle. The list, in fact, also includes MySQL, the most popular open-source database server. For more information about MySQL, visit the http:// www.mysql.com Web site. Recently, a third-party vendor—Core Lab—shipped MySqlDirect .NET, which is a managed provider that uses the native MySQL programming interface to access MySQL databases. The component is targeted to version 3.2 of MySQL and provides only a thin layer of code between ADO.NET and the database server. For more information about the product, go to http:// www.crlab.com/mysqlnet.
The availability of managed providers is rapidly and constantly evolving, and almost every day we read press releases from database vendors and third-party tool vendors announcing beta versions or plans for supporting the .NET data provider architecture. At the time of this writing, it is amazing to see that in the list of the released .NET data providers we find an open-source database like MySQL but not yet more traditional database servers such as Sybase, Informix, AS/400, and IBM DB2. You can still access those database management systems from within your .NET application by using either the corresponding OLE DB provider or an ODBC driver. However, note that IBM is working on a native DB2 .NET data provider. (For more information, see http://www7b.software.ibm.com/dmdd/downloads/dotnetbeta/ index.html.) In addition, DataDirect is expected to provide Sybase support soon. You should note that the key advantage of native .NET solutions is that no third-party drivers or bridge solutions are needed, which results in great performance.
Connecting to Data Sources
The beauty of the ADO.NET object model and managed data providers is that programmers always write their data-access code in the same way, regardless of whether the underlying data source is SQL Server, Oracle, or even MySQL. The programming model is based on a relatively standard sequence of steps that first creates a connection, then prepares and executes a command, and finally processes the data retrieved. In the rest of the chapter, we'll mostly discuss how data classes work with SQL Server 2000. However, we'll promptly point out any aspect that is significantly different than other .NET data providers. To start out, let's see how connections take place.
The SqlConnection Class
The first step in working with an ADO.NET-based application is setting up the connection with the data source. The class that represents a physical connection to SQL Server 2000 is SqlConnection, and it's located in the System.Data.SqlClient namespace. The class is sealed (that is, not inheritable), cloneable, and implements the IDbConnection interface. The class features two constructors, one of which is the default parameterless constructor. The second class constructor, on the other hand, takes a string containing the connection string:
public SqlConnection(); public SqlConnection(string);
The following code snippet shows the typical way to set up and open a SQL Server connection:
string nwind_string = "SERVER=localhost;DATABASE=northwind;UID=...;PWD=..."; SqlConnection nwind_conn = new SqlConnection(nwind_string); nwind_conn.Open();nwind_conn.Close();
Table 5-5 details the public properties defined on the SqlConnection class. The table also checks the properties the class provides through the IDbConnection interface. These properties are important because they form the subset of properties common to all connection classes in the .NET Framework.
|
Property |
IDbConnection Interface |
Description |
|---|---|---|
|
ConnectionString |
Yes |
Gets or sets the string used to open the database. |
|
ConnectionTimeout |
Yes |
Gets the seconds to wait while trying to establish a connection. |
|
Database |
Yes |
Gets the name of the database to be used. |
|
DataSource |
Gets the name of the instance of SQL Server to connect to. Normally corresponds to the Server connection string attribute. |
|
|
PacketSize |
Gets the size in bytes of network packets used to communicate with SQL Server. Set to 8192, it can be any value in the range from 512 to 32767. |
|
|
ServerVersion |
Gets a string containing the version of the current instance of SQL Server. The version string is in the form of major.minor.release. |
|
|
State |
Yes |
Gets the current state of the connection: open or closed. Closed is the default. |
|
WorkstationId |
Gets the network name of the client, which normally corresponds to the Workstation ID connection string attribute. |
The SqlConnection class is expected to signal any change of the internal state using the values in the ConnectionState enumeration. Many of the acceptable values, though, are reserved for future versions of the .NET Framework. The only state transitions that take place are from Closed to Open when the Open method is called, and from Open to Closed when Close is called.
An important characteristic to note about the properties of the connection classes is that they are all read-only except ConnectionString. In other words, you can configure the connection only through the tokens of the connection string, but you can read attributes back through handy properties. This characteristic of connection class properties in ADO.NET is significantly different than what you find in ADO, where many of the connection properties—for example, ConnectionTimeout and Database—were read/write.
Table 5-6 shows the methods available in the SqlConnection class.
|
Method |
IDbConnection Interface |
Description |
|---|---|---|
|
BeginTransaction |
Yes |
Begins a database transaction. Allows you to specify a name and an isolation level. |
|
ChangeDatabase |
Yes |
Changes the current database on the connection. Requires a valid database name. |
|
Close |
Yes |
Closes the connection to the database. Use this method to close an open connection. |
|
CreateCommand |
Yes |
Creates and returns a SqlCommand object associated with the connection. |
|
Dispose |
Calls Close. |
|
|
EnlistDistributed-Transaction |
If auto-enlistment is disabled, the method enlists the connection in the specified transaction. Supported only in version 1.1 of the .NET Framework. |
|
|
Open |
Yes |
Opens a database connection with the property settings specified by the ConnectionString. |
Note that if the connection goes out of scope, it is not automatically closed. Later on, but not especially soon, the garbage collector picks up the object instance, but the connection won't be closed because the garbage collector can't recognize the peculiarity of the object and handle it properly. Therefore, you must explicitly close the connection by calling Close or Dispose before the object goes out of scope.
The SqlConnection class fires three events: Disposed, InfoMessage, and StateChange. The event Disposed fires when the connection object is being disposed of by the garbage collector. The event InfoMessage reaches the client whenever SQL Server has a warning or nonblocking error. Finally, StateChange accompanies any valid state transition.
Configuring Connection Properties
The ConnectionString property is the configuration string used to open a SQL Server database. Made of semicolon-separated pairs of names and values, a connection string specifies settings for the SQL Server runtime. Typical information contained in a connection string includes the name of the database, location of the server, and user credentials. Other more operational information, such as connection timeout and connection pooling settings, can be specified too.
| Note |
Although some particular connection strings for the SQL Server .NET data provider might be nearly identical to OLE DB connection strings, in general the list of acceptable properties in the two cases is different. |
The ConnectionString property can be set only when the connection is closed. Many connection-string values have corresponding read-only properties in the connection class. These properties are updated when the connection string is set. The contents of the connection string are checked and parsed immediately after the ConnectionString property is set. Attribute names in a connection string are not case sensitive, and if a given name appears multiple times, the value of the last occurrence is used. Table 5-7 lists the keywords that are supported.
|
Keyword |
Description |
|---|---|
|
Application Name |
Name of the client application as it appears in the SQL Profiler. Defaults to .Net SqlClient DataProvider. |
|
AttachDBFileName or |
The full path name of the file (.mdf) to use as an attachable database file. |
|
Connection Timeout |
The number of seconds to wait for the connection to take place. Default is 15 seconds. |
|
Current Language |
The SQL Server language name. |
|
Database or Initial Catalog |
The name of the database to connect to. |
|
Encrypt |
Indicates whether SSL encryption should be used for all data sent between the client and server. Needs a certificate installed on the server. Default is false. |
|
Integrated Security or Trusted_Connection |
Indicates whether current Windows account credentials are used for authentication. When set to false, an explicit user ID and password need to be provided. The special value sspi equals true. Default is false. |
|
Network Library or net |
Indicates the network library used to establish a connection to SQL Server. Default is dbmssocn, which is based on TCP/IP. |
|
Packet Size |
Bytes that indicate the size of the packet being exchanged. Default is 8192. |
|
Password or pwd |
Password for the account logging on. |
|
Persist Security Info |
Indicates whether the managed provider should include password information in the string returned as the connection string. Default is false. |
|
Server or Data Source |
Name or network address of the instance of SQL Server to connect to. |
|
User ID or uid |
User name for the account logging on. |
|
Workstation ID |
Name of the machine connecting to SQL Server. |
The network DLL specified by the Network Library keyword must be installed on the system to which you connect. If you use a local server, the default library is dbmslpcn, which uses shared memory. For a list of options, consult the MSDN documentation.
Any attempt to connect to an instance of SQL Server should not exceed a given time. The Connection Timeout keyword controls just this. Note that a connection timeout of 0 causes the connection attempt to wait indefinitely rather than meaning no wait time.
You normally shouldn't change the default packet size, which has been determined based on average operations and workload. However, if you're going to perform bulk operations in which large objects are involved, increasing the packet size can be of help because it decreases the number of reads and writes.
Secure Connections
Depending on how you configure your instance of SQL Server, you can exploit trusted connections. When working with trusted connections, SQL Server ignores any explicit user ID and password set in the connection string. In this case, the current Windows account credentials are used to authenticate the request. Of course, you must have a login corresponding to those credentials. As we'll see in Chapter 15, for ASP.NET applications this means you must first add the ASPNET login for the databases you want to access programmatically.
When applications read the ConnectionString property, the get accessor of the property—that is, the piece of code that determines the value being returned—normally strips off any password information for security reasons. The Persist Security Info keyword allows you to change this setting. If you set it to true (which is strongly discouraged), the connection string is returned as-is and includes password information, if any.
Connection Pooling
Connection pooling is a fundamental aspect of high-performance, scalable applications. All .NET data providers support connection pooling as Table 5-8 illustrates.
|
Provider |
Connection Pooling Managed By |
|---|---|
|
SQL Server |
Internal class |
|
Oracle |
Internal class |
|
OLE DB |
OLE DB Service component |
|
ODBC |
ODBC Driver Manager |
The .NET data providers for SQL Server and Oracle manage connection pooling internally using ad hoc classes. Both support local and distributed transactions. For distributed transactions, they automatically enlist in a transaction and obtain transaction details from Windows 2000 Component Services. If automatic enlistment is disabled through the connection string, the method EnlistDistributedTransaction allows you to accomplish that manually.
For the OLE DB data provider, connection pooling is implemented through the OLE DB service infrastructure for session pooling. Connection-string arguments (for example, OLE DB Service) can be used to enable or disable various OLE DB services including pooling. A similar situation occurs with ODBC, in which pooling is controlled by the ODBC driver manager.
Configuring Pooling
Some settings in the connection string directly affect the pooling mechanism. The parameters you can control to configure the environment are listed in Table 5-9.
|
Keyword |
Description |
|---|---|
|
Connection Lifetime |
Sets the maximum duration in seconds of the connection object in the pool. This value is used when the object is returned to the pool. If the creation time plus the lifetime is earlier than the current time, the object is destroyed. |
|
Connection Reset |
Determines whether the database connection is reset when being drawn from the pool. Default is true. |
|
Enlist |
Indicates that the pooler automatically enlists the connection in the creation thread's current transaction context. Default is true. |
|
Max Pool Size |
Maximum number of connections allowed in the pool. Default is 100. |
|
Min Pool Size |
Minimum number of connections allowed in the pool. Default is 0. |
|
Pooling |
Indicates that the connection object is drawn from the appropriate pool, or if necessary, is created and added to the appropriate pool. Default is true. |
To disable connection pooling, you set Pooling to false. When changing connection-string keywords—including connection-pooling keywords—Boolean values can also be set by using yes or no instead of true or false.
Getting and Releasing Objects
Each connection pool is associated with a distinct connection string and the transaction context. When a new connection is opened, if the connection string does not exactly match an existing pool, a new pool is created. Once created, connection pools are not destroyed until the process ends. This behavior does not affect the system performance because maintenance of inactive or empty pools requires only minimal overhead.
When a pool is created, multiple connection objects are created and added so that the minimum size is reached. Next, connections are added to the pool on demand, up to the maximum pool size. When a connection object is requested, it is drawn from the pool as long as a usable connection is available. A usable connection must currently be unused, have a matching or null transaction context, and have a valid link to the server. If no usable connection is available, the pooler attempts to create a new connection object. When the maximum pool size is reached, the request is queued and served as soon as an existing connection object is released to the pool. Connections are released when you call methods such as Close or Dispose. Connections that are not explicitly closed might not be returned to the pool unless the maximum pool size has been reached and the connection is still valid.
A connection object is removed from the pool if the lifetime has expired or if a severe error occurred. In this case, the connection is marked as invalid. The pooler periodically scavenges the various pools and permanently removes invalid connection objects.
| Caution |
Pay careful attention not to create a connection string programmatically by concatenating input data together. If you do, you should first validate the data you're putting in the connection string. This little precaution could save you from sneaky attacks through code injection. We'll say more about this in Chapter 15. |
Generic Database Programming
In ADO.NET, data access is strongly typed, in the sense that you must know at all times what data source you're targeting. In ADO, you could write data-access code that worked in a generic way, regardless of the actual database server. For example, the ADO object model provides unique connection and command objects that hide the characteristics of the underlying DBMS. Once you've set the Provider property on the Connection object, you're pretty much done. At that point, in fact, creating a Command object for SQL Server or Oracle requires the same code.
In ADO.NET, you can retain the same behavior only if you choose to use the .NET data provider for OLE DB. In this case, the programming model is exactly that which you might have experienced with ADO. But what if you want to use the native .NET data providers?
In ADO.NET, the connection object must be data-source specific, and there's no way for you to create a connection in an indirect way. However, once you hold a connection object, you can create and execute a command in a generic way regardless of the actual data source in use. Let's take a look at the following code snippet:
IDbConnection conn; if (useOracle) conn = (IDbConnection) new OracleConnection(oracle_conn_string); else // use SQL Server conn = (IDbConnection) new SqlConnection(sqlserver_conn_string); // Create the command IDbCommand cmd = conn.CreateCommand(cmd_text);
Based on a user setting, the code decides whether a connection to Oracle or SQL Server is to be used. Once created, the connection object is referenced through an interface type—the IDbConnection interface—which is common to all ADO.NET connection objects. To create a command—either an OracleCommand or SqlCommand object—you use the CreateCommand method and reference the command by using the IDbCommand interface.
After that, you can use the ExecuteReader or ExecuteNonQuery methods on the IDbCommand interface to execute the command. If you use ExecuteReader, you get back a sort of managed cursor—the data reader—and can access it generically using the IDataReader interface.
| Note |
You cannot fill a DataSet object by using a generic database programming pattern. In fact, you can't create the data adapter object in an indirect way as you can with a command. The reason is that, unlike the command object, in some cases the data adapter can create a connection internally and implicitly. To do so, though, it needs to work in a strongly typed way and know what the underlying database server is. |
Other Connection Objects
So far we've discussed the features of the ADO.NET connection objects mostly from a SQL Server perspective. The programming interface of ADO.NET connection objects is similar but not identical. So let's review what the main differences are in the various cases.
Oracle Connections
The class that represents a physical connection to an Oracle 8.x database is OracleConnection, which is located in the System.Data.OracleClient namespace. As mentioned earlier, bear in mind that the Oracle managed provider is implemented in the System.Data.OracleClient assembly. All the others, on the other hand, live in the System.Data assembly.
The OracleConnection class differs from other connection classes in the .NET Framework because it does not support the ConnectionTimeout and Database properties. If you set a timeout in the connection string, the value is simply ignored. Likewise, the class doesn't support a ChangeDatabase method.
| Note |
The PacketSize and WorkstationId properties are specific to the SQL Server data provider and aren't available on any other connection class, including OracleConnection. |
OLE DB Connections
The .NET data provider for OLE DB communicates to an OLE DB data source through both the OLE DB Service component, which provides connection pooling and transaction services, and the OLE DB provider for the data source. For this reason, the programming interface of the OleDbConnection class is slightly different and includes an extra property that just doesn't make sense for a DBMS-specific component. The property is read-only and named Provider. It returns the content of the Provider keyword in the connection string. The content of Provider is normally the program identifier (progID) of the OLE DB provider to use.
In addition, the OleDbConnection class features an OLE DB–specific method—GetOleDbSchemaTable—that returns a DataTable filled with schema information from a data source.
The data provider for OLE DB also provides a static method to release object pools that are in the process of being destroyed. The ReleaseObjectPool method gets into the game only after all active connections have been closed and the garbage collector has been invoked. At this time, the connection objects are released, but the resources reserved for the pools are not.
ODBC Connections
An OdbcConnection object represents a unique connection to a data source that is typically identified through an ODBC data source name (DSN) or a plain connection string. The class works by using resources such as ODBC environment and connection handles.
Unlike other connection classes, the OdbcConnection class features the Driver property to indicate the name of the driver in use and the ReleaseObjectPool static method to release the ODBC environment handle. After an environment handle is released, a request for a new connection creates a new environment.
Executing Commands
Once you have a physical channel set up between your client and the database, you can start preparing and executing commands. The ADO.NET object model provides two types of command objects—the traditional one-off command and the data adapter. The one-off command executes a statement (that is, a Transact-SQL command) or a stored procedure and returns a sort of cursor. Using that, you then scroll through the rows and read data. While the cursor is in use, the connection is busy and open. The data adapter, on the other hand, is a more powerful object that internally uses a command and a cursor. It retrieves and loads the data into a data container class—the DataSet. The client application can then process the data while disconnected from the source. The adapter can also be used to set up a batch update mechanism in which all the records changed in memory are submitted to the DBMS in a loop with autogenerated, but modifiable, commands.
The SqlCommand Class
The SqlCommand class represents a SQL Server statement or stored procedure. It is a cloneable and sealed class that implements the IDbCommand interface. A command executes in the context of a connection and, optionally, a transaction. This situation is reflected by the constructors available in the SqlCommand class:
public SqlCommand(); public SqlCommand(string); public SqlCommand(string, SqlConnection); public SqlCommand(string, SqlConnection, SqlTransaction);
The string argument denotes the text of the command to execute, whereas the SqlConnection parameter is the connection object to use. Finally, if specified, the SqlTransaction parameter represents the transactional context in which the command has to run. Unlike ADO command objects, ADO.NET command objects can never implicitly open a connection. The connection must be explicitly assigned to the command by the programmer and opened and closed with direct operations. The same holds true for the transaction.
Table 5-10 shows the attributes that comprise a command in the.NET data provider for SQL Server. The values in the IDbCommand Interface column indicate whether the property is part of the IDbCommand interface.
|
Property |
IDbCommand Interface |
Description |
|---|---|---|
|
CommandText |
Yes |
Gets or sets the statement or the stored procedure name to execute. |
|
CommandTimeout |
Yes |
Gets or sets the seconds to wait while trying to execute the command. Default is 30. |
|
CommandType |
Yes |
Gets or sets how the CommandText property is to be interpreted. Set to Text by default, which means the CommandText property contains the text of the command. |
|
Connection |
Yes |
Gets or sets the connection object used by the command. Null by default. |
|
Parameters |
Yes |
Gets the collection of parameters associated with the command. The actual type of the collection is SqlParameterCollection. Empty by default. |
|
Transaction |
Yes |
Gets or sets the transaction within which the command executes. The transaction must be connected to the same connection as the command. |
|
UpdatedRowSource |
Yes |
Gets or sets how query command results are applied to the row being updated. The value of this property is used only when the command runs within the Update method of the data adapter. Acceptable values are in the UpdateRowSource enumeration. |
Commands can be associated with parameters, and each parameter is rendered using a provider-specific object. For the SQL Server managed provider, the parameter class is SqlParameter. The command type determines the role of the CommandText property. The possible values for CommandType are:
- Text The default setting, which indicates the property contains Transact-SQL text to execute directly.
- StoredProcedure Indicates that the content of the property is intended to be the name of a stored procedure contained in the current database.
- TableDirect Indicates the property contains a comma-separated list containing the names of the tables to access. All rows and columns of the tables will be returned. Note that TableDirect is supported only by the data provider for OLE DB.
Table 5-11 details the methods available on the SqlCommand class.
|
Property |
IDbCommand Interface |
Description |
|---|---|---|
|
Cancel |
Yes |
Attempts to cancel the execution of the command. No exception is generated if the attempt fails. |
|
CreateParameter |
Yes |
Creates a new instance of a SqlParameter object. |
|
ExecuteNonQuery |
Yes |
Executes a nonquery command, and returns the number of rows affected. |
|
ExecuteReader |
Yes |
Executes a query, and returns a read-only cursor—the data reader—to the data. |
|
ExecuteScalar |
Yes |
Executes a query, and returns the value in the 0,0 position (first column of first row) in the result set. Extra data is ignored. |
|
ExecuteXmlReader |
Executes a query that returns XML data and builds an XmlReader object. |
|
|
Prepare |
Yes |
Creates a prepared version of the command in an instance of SQL Server. |
|
ResetCommandTimeout |
Resets the command timeout to the default. |
If the CommandType property is set to TableDirect, the Prepare method does nothing. A SqlCommand object executes Transact-SQL code statements wrapping the user-specified text with the system sp_executesql stored procedure. The command is sent to SQL Server using tabular data stream (TDS) packets and the RPC protocol.
Using Parameters
Parameterized commands define their own arguments by using instances of the SqlParameter class. Parameters have a name, value, type, direction, and size. In some cases, parameters can also be associated with a source column. A parameter is associated with a command by using the Parameters collection.
SqlParameter parm = new SqlParameter(); parm.ParameterName = "@employeeid"; parm.DbType = DbType.Int32; parm.Direction = ParameterDirection.Input; cmd.Parameters.Add(parm);
The following SQL statement uses a parameter:
SELECT * FROM employees WHERE employeeid=@employeeid
The .NET data provider for SQL Server identifies parameters by name, using the @ symbol to prefix them. In this way, the order in which parameters are associated with the command is not determinant.
| Note |
Named parameters are supported by the managed provider for Oracle but not by the providers for OLE DB and ODBC data sources. The OLE DB and ODBC data sources use positional parameters identified with the question mark (?) placeholder. The order of parameters is important. |
Ways to Execute
As Table 5-11 shows, a SqlCommand object can be executed in four different ways: ExecuteNonQuery, ExecuteReader, ExecuteScalar, and ExecuteXmlReader. The various executors work in much the same way, but they differ in the return values. Typically, you use the ExecuteNonQuery method to perform update operations such as those associated with statements like UPDATE, INSERT, and DELETE. In these cases, the return value is the number of rows affected by the command. For other types of statements, such as SET or CREATE, the return value is -1.
The ExecuteReader method is expected to work with query commands, and returns a data reader object—an instance of the SqlDataReader class. The data reader is a sort of read-only, forward-only cursor that client code scrolls and reads from. If you execute an UPDATE statement through ExecuteReader, the command is successfully executed but no affected rows are returned.
The ExecuteScalar method helps considerably when you have to retrieve a single value. It works great with SELECT COUNT statements or for commands that retrieve aggregate values. If you call the method on a regular query statement, only the value in the first column of the first row is read and all the rest are discarded. Using ExecuteScalar results in more compact code than you'd get by executing the command and manually retrieving the value in the top-left corner of the rowset.
These three executor methods are common to all command objects. The SqlCommand class also features the ExecuteXmlReader method. It executes a command that returns XML data, and it builds an XML reader so that the client application can easily navigate through the XML tree. The ExecuteXmlReader method is ideal to use with query commands that end with the FOR XML clause or with commands that query for text fields filled with XML data. Note that while the XmlReader object is in use, the underlying connection is busy.
Setting Up Transactions
A SQL Server native transaction is fully represented by an instance of the SqlTransaction class. The transaction object is obtained through the BeginTransaction method and can be given a name and an isolation level.
SqlTransaction tran; tran = conn.BeginTransaction(); cmd.Connection = conn; cmd.Transaction = tran;
You terminate a transaction explicitly by using the Commit or Rollback method. The SqlTransaction class supports named savepoints in the transaction that can be used to roll back a portion of the transaction. Named savepoints exploit a specific SQL Server feature—the SAVE TRANSACTION statement.
Other Command Objects
Let's look at the characteristics of other command objects that, for one reason or another, have not been covered so far.
Oracle Commands
Oracle commands don't support a timeout, and in fact, the OracleCommand object doesn't expose the CommandTimeout property. In addition, the class features two extra executor methods—ExecuteOracleNonQuery and ExecuteOracleScalar. ExecuteOracleScalar differs from ExecuteScalar only because it returns an Oracle-specific data type. The difference between ExecuteNonQuery and ExecuteOracleNonQuery is more subtle.
public int ExecuteOracleNonQuery(out OracleString rowid);
If you're executing an UPDATE statement that affects exactly one row, the ExecuteOracleNonQuery method returns a Base64 string as an output parameter. This value identifies the modified row in the database and allows you to write subsequent, related queries in a more powerful way.
OLE DB Commands
The OleDbCommand class does not support the ExecuteXmlReader method and limits its support to the three basic executor methods in the IDbCommand interface. In addition, it recognizes TableDirect as a valid command type. As mentioned earlier, the OLE DB .NET provider does not support named parameters for statements and stored procedures. If parameters are to be used, you should use the question mark (?) placeholder, as shown in the following command:
SELECT * FROM Customers WHERE CustomerID = ?
As a result, the order in which OleDbParameter objects are added to the collection of parameters must correspond to the position of the question mark placeholder for the parameter.
ODBC Commands
Just like OleDbCommand, the OdbcCommand class doesn't support named parameters and resorts to the question-mark placeholder and position-based arguments. To execute a stored procedure, the OdbcCommand class requires the CommandText property to be set using standard ODBC escape sequences for stored procedures. Note that simply setting the property to the name of the stored procedure does not work. Use the following escape sequence for ODBC stored procedures:
{call sp_name(?, ?, ?)}
In this example, sp_name is the name of the stored procedure while the ? placeholder represents an argument to the procedure.
ADO NET Data Readers
In the .NET Framework, a reader is a generic type of object used to read data in a variety of formats. A reader is used to read bytes out of a binary stream, lines of text from a text writer, nodes from an XML document, and records from a database-provided stream of data. The data reader class is specific to a DBMS and works like a firehose-style cursor. It allows you to scroll through and read one or more result sets generated by a command. The data reader operates in a connected way and moves in a forward-only direction.
A data reader is instantiated during the execution of the ExecuteReader method. The results are stored in a buffer located on the client and are made available to the reader. The reader moves through the result set by using the Read method. By using the data reader object, you access data one record at a time as soon as it becomes available. An approach based on the data reader is effective both in terms of minimizing system overhead and improving performance. Only one record is cached at any time, and there's no wait time to have the entire result set loaded in memory. You should note that by default the cached record is accessible only after it has been completely loaded in memory. This might take a while and consume too much memory, if the query includes large binary large object (BLOB) fields. (More on this later in this chapter and also in Chapter 22.)
A data reader object is made of two interfaces—IDataReader and IDataRecord. IDataReader includes general-purpose properties and methods to read data. For example, it includes the methods Read and Close. IDataRecord supplies methods to extract values out of the current record. Table 5-12 shows the properties of the SqlDataReader class—that is, the data reader class for SQL Server.
|
Property |
Description |
|---|---|
|
Depth |
Returns 0. |
|
FieldCount |
Gets the number of columns in the current row. |
|
HasRows |
Gets a value that indicates whether the data reader contains one or more rows. This property is not supported in version 1.0 of the .NET Framework. |
|
IsClosed |
Gets a value that indicates whether the data reader is closed. |
|
Item |
Indexer property. Gets the value of a column in the original format. |
|
RecordsAffected |
Gets the number of rows modified by the execution of a batch command. |
The Depth property—a member of the IDataReader interface—is meant to indicate the level of nesting for the current row. The depth of the outermost table is always 0; the depth of inner tables grows by one. Most data readers, including the SqlDataReader and OracleDataReader classes, do not support multiple levels of nesting so that the Depth property always returns 0.
The RecordsAffected property cumulatively refers to the rows affected by any update statement executed in the command—typically, a batch or a stored procedure. The property, though, is not set until all rows are read and the data reader is closed. The default value of RecordsAffected is -1. Note that IsClosed and RecordsAffected are the only properties you can invoke on a closed data reader.
Table 5-13 lists the methods of the data reader.
|
Methods |
Description |
|---|---|
|
Close |
Closes the reader object. Note that closing the reader does not automatically close the underlying connection. |
|
GetBoolean |
Gets the value of the specified column as a Boolean. |
|
GetByte |
Gets the value of the specified column as a byte. |
|
GetBytes |
Reads a stream of bytes from the specified column into a buffer. You can specify an offset both for reading and writing. |
|
GetChar |
Gets the value of the specified column as a single character. |
|
GetChars |
Reads a stream of characters from the specified column into a buffer. You can specify an offset both for reading and writing. |
|
GetDataTypeName |
Gets the name of the back-end data type in the specified column. |
|
GetDateTime |
Gets the value of the specified column as a DateTime object. |
|
GetDecimal |
Gets the value of the specified column as a decimal. |
|
GetDouble |
Gets the value of the specified column as a double-precision floating-point number. |
|
GetFieldType |
Gets the Type object for the data in the specified column. |
|
GetFloat |
Gets the value of the specified column as a single-precision floatingpoint number. |
|
GetGuid |
Gets the value of the specified column as a globally unique identifier (GUID). |
|
GetInt16 |
Gets the value of the specified column as a 16-bit signed integer. |
|
GetInt32 |
Gets the value of the specified column as a 32-bit signed integer. |
|
GetInt64 |
Gets the value of the specified column as a 64-bit signed integer. |
|
GetName |
Gets the name of the specified column. |
|
GetOrdinal |
Given the name of the column, returns its ordinal number. |
|
GetSchemaTable |
Returns a DataTable object that describes the metadata for the columns managed by the reader. |
|
GetString |
Gets the value of the specified column as a string. |
|
GetValue |
Gets the value of the specified column in its original format. |
|
GetValues |
Copies the values of all columns in the supplied array of objects. |
|
IsDBNull |
Indicates whether the column contains null values. The type for a null column is System.DBNull. |
|
NextResult |
Moves the data reader pointer to the beginning of the next result set, if any. |
|
Read |
Moves the data reader pointer to the next record, if any. |
The SQL Server data reader also features a variety of other DBMS-specific get methods. They include methods such as GetSqlDouble, GetSqlMoney, GetSqlDecimal, and so on. The difference between the GetXXX and GetSqlXXX methods is in the return type. With the GetXXX methods, a base .NET Framework type is returned; with the GetSqlXXX methods, a .NET Framework wrapper for a SQL Server type is returned—such as SqlDouble, SqlMoney, or SqlDecimal. The SQL Server types belong to the SqlDbType enumeration.
All the GetXXX methods that return a value from a column identify the column through a 0-based index. Note that the methods don't even attempt a conversion; they simply return data as is and just make a cast to the specified type. If the actual value and the type are not compatible, an exception is thrown.
The GetBytes method is useful to read large fields one step at a time. However, the method can also be used to obtain the length in bytes of the data in the column. To get this information, pass a buffer that is a null reference and the return value of the method will contain the length.
Reading Data with the Data Reader
The key thing to remember when using a data reader is that you're working while connected. The data reader represents the fastest way to read data out of a source, but you should read your data as soon as possible and release the connection. One row is available at a time, and you must move through the result set by using the Read method. The following code snippet illustrates the typical loop you implement to read all the records of a query:
while (reader.Read()) {
// process record
}
You have no need to explicitly move the pointer ahead and no need to check for the end of the file. The Read method returns false if there are no more records to read. Unlike the ADO firehose-style cursor, the data reader features no bookmarks, no scrolling, and no bulk-reading methods such as ADO GetString and GetRows. In contrast, it provides a GetValues method to get all the column values in an array of objects.
| Tip |
Null values in the returned stream of data can be checked using a handful of methods on the data reader object and row object itself. For example, you can check a column value against null as shown in the following code snippet:
if (reader.IsDBNull(colIndex)) {...}
To set a null value, use the System.DBNull.Value expression, as in the following code snippet: param.Value = System.DBNull.Value; |
Command Behaviors
When calling the ExecuteReader method on a command object—on any command object regardless of the underlying DBMS—you can require a particular working mode known as a command behavior. ExecuteReader has a second overload that takes an argument of type CommandBehavior:
cmd.ExecuteReader(CommandBehavior.CloseConnection);
CommandBehavior is an enumeration. Its values are listed in Table 5-14.
|
Behavior |
Description |
|---|---|
|
CloseConnection |
Automatically closes the connection when the data reader is closed. |
|
Default |
No special behavior is required. Setting this option is functionally equivalent to calling ExecuteReader without parameters. |
|
KeyInfo |
The query returns only column metadata and primary key information. The query is executed without any locking on the selected rows. |
|
SchemaOnly |
The query returns only column metadata and does not put any lock on the database rows. |
|
SequentialAccess |
Enables the reader to load data as a sequential stream. This behavior works in conjunction with methods such as GetBytes and GetChars, which can be used to read bytes or characters having a limited buffer size for the data being returned. When this behavior is set, the record is not automatically and entirely cached in memory, but physical reading occurs as you access the various fields. |
|
SingleResult |
Only the first result set is returned. |
|
SingleRow |
The query is expected to return a single row. |
The sequential-access mode applies to all columns in the returned result set. This means you can access columns only in the order in which they appear in the result set. For example, you cannot read column #2 before column #1. More exactly, if you read or move past a given location you can no longer read or move back. This happens because when the SequentialAccess behavior is selected, record contents aren't cached by the reader object. Caching the contents of the records is what enables, for most behaviors, random access to the fields. Combined with the GetBytes method, sequential access can be helpful when you must read binary large objects with a limited buffer.
| Note |
You can specify SingleRow also when executing queries that are expected to return multiple result sets. In this case, all the generated result sets are correctly returned, but each result set has a single row. |
Closing the Reader
The data reader is not a publicly creatable object. It does have a constructor, but not one that is callable from within user applications. The data-reader constructor is marked as internal and can be invoked only from classes defined in the same assembly—System.Data. The data reader is implicitly instantiated when the ExecuteReader method is called. Opening and closing the reader are operations distinct from instantiation and must be explicitly invoked by the application. The Read method advances the internal pointer to the next readable record in the current result set. The Read method returns a Boolean value indicating whether or not more records can be read. While records are being read, the connection is busy and no operation, other than closing, can be performed on the connection object.
The data reader and the connection are distinct objects and should be managed and closed independently. Both objects provide a Close method that should be called twice—once on the data reader (first) and once on the connection. When the CloseConnection behavior is required, closing the data reader also closes the underlying connection. In addition, the data reader's Close method fills in the values for any command output parameters and sets the RecordsAffected property.
| Tip |
Because of the extra work Close always performs, closing a reader with success can sometimes be expensive, especially in cases of large and complicated queries. In situations in which you need to squeeze out every little bit of performance, and where the return values and the number of records affected are not significant, you can invoke the Cancel method of the associated SqlCommand object instead of Close. Cancel aborts the operation; however, if you call it after reading all rows, you can clean up the reader with less effort. |
Accessing Multiple Result Sets
Depending on the syntax of the query, multiple result sets can be returned. By default, the data reader is positioned on the first of them. You use the Read method to scroll through the various records in the current result set. When the last record is found, the Read method returns false and does not advance further. To move to the next result set, you should use the NextResult method. The method returns false if there are no more result sets to read. The following code shows how to access all records in all returned result sets:
SqlDataReader reader;
reader = cmd.ExecuteReader();
do {
// Move through the first result set
while (reader.Read())
{
// access the row
}
}
while (reader.NextResult())
reader.Close();
cmd.Connection.Close();
When reading the contents of a row, you can identify the column by either index or name. Using an index results in significantly faster code because the provider can go directly to the buffer. If the column name is specified, the provider uses the GetOrdinal method to translate the name into the corresponding index and then performs an index-based access. Note that for the SQL Server data reader, all the GetXXX methods actually call into the corresponding GetSqlXXX methods. A similar situation occurs for the Oracle data reader, in which the native data is always marshaled to the .NET Framework types. The OLE DB and ODBC readers have only a single set of get methods.
| Note |
The .NET Framework version 1.1 extends the programming interface of data readers by adding the HasRows method, which returns a Boolean value indicating whether or not there are more rows to read. However, the method doesn't tell anything about the number of rows available. Similarly, there is no method or trick to know in advance how many result sets have been returned. |
Obtaining Schema Information
All data reader classes supply a GetSchemaTable method that retrieves metadata information about the columns the query is going to read. GetSchemaTable returns a DataTable object—that is, a table with one row for each retrieved column and a fixed number of informative columns.
The metadata available can be catalogued in three categories: column metadata, database characteristics, and column attributes. Table 5-15 details the columns. Note that the column metadata is listed in alphabetical order, which is not the order in which they appear in the result set.
|
Metadata Column |
Description |
|---|---|
|
AllowDBNull |
Indicates whether the column allows null values. |
|
BaseCatalogName |
Set to null by default. Returns the name of the database that contains the table accessed by the query. |
|
BaseColumnName |
Set to null by default. Returns the original name of the column if an alias is used. |
|
BaseSchemaName |
Set to null by default. Returns the name of the owner (for example, dbo) of the database from which the column is retrieved. |
|
BaseServerName |
Set to null by default. Returns the name of the instance of DBMS used by the data reader. |
|
BaseTableName |
Returns the name of the table. |
|
ColumnName |
Name of the column as it appears in the query. If an alias has been used, the aliased name is returned. |
|
ColumnOrdinal |
0-based position of the column in the result set. |
|
ColumnSize |
Maximum size in bytes of the data allowed in the column. |
|
DataType |
Returns the .NET Framework type the column maps to. |
|
IsAliased |
Indicates whether the column is aliased in the result set. A column is aliased if renamed using the AS clause. The original name of aliased columns is stored in the BaseColumnName column. |
|
IsAutoIncrement |
Indicates whether the column is marked as auto-increment. |
|
IsExpression |
Indicates whether the content of the column is based on an expression. |
|
IsHidden |
Indicates whether the column is marked as hidden. |
|
IsIdentity |
Indicates whether the column is an identity column. |
|
IsLong |
Indicates whether the column contains BLOB data. Note, though, that the definition of a BLOB is provider-specific. |
|
IsKey |
Indicates whether the column is a key or part of a set of columns that together represent a key. |
|
IsReadOnly |
Indicates whether the column is read-only. |
|
IsRowVersion |
Indicates whether the column has a unique identifier value—that is, a row GUID. |
|
IsUnique |
Indicates whether the column can contain duplicates. |
|
NumericPrecision |
Set to null by default. Indicates the maximum precision of the column data. |
|
NumericScale |
Set to null by default. Indicates the number of digits to the right of the decimal point if the column type allows. |
|
ProviderType |
Indicates the type of the column data. The type is expressed as a numeric value corresponding to the type in the database-specific enumeration. For example, an integer column in a SQL Server table returns the value of SqlDbType.Int. |
Catalog and owner (schema) information can be retrieved only if explicitly mentioned in the command text. Writing the same query in the following ways affects the contents of the BaseXXX columns:
SELECT * FROM northwind.dbo.employees SELECT * FROM employees
In the first query, BaseCatalogName would be set to northwind and BaseSchemaName to dbo. In the second query, the same information wouldn't be retrieved. Note that this is true only if you're also using the KeyInfo command behavior.
| Tip |
The GetSchemaTable method for SQL Server returns more accurate data if you require the KeyInfo command behavior when calling ExecuteReader. The KeyInfo behavior can be combined with the default behavior so that you can execute a single command and obtain both schema and data: reader = cmd.ExecuteReader(CommandBehavior.KeyInfo | CommandBehavior.CloseConnection) The fields whose values are correctly returned only if the KeyInfo behavior is required are: IsKey, BaseTableName, IsAliased, IsExpression, and IsHidden. Note also that if KeyInfo is required, the key columns (if any) are always added at the bottom of the result set but no data is returned for them. |
Special Features of Data Readers
The characteristics of the various provider-specific data readers are nearly identical, with only some differences that are more architectural than functional. We've examined the SqlDataReader class, now let's examine the differences with other reader classes supported by the .NET Framework 1.1 data providers.
Oracle Data Readers
The OracleDataReader class provides a personal set of GetXXX methods for its own internal types. Some of its methods are GetOracleBFile, GetOracleBinary, and GetOracleDateTime. In Oracle database programming, multiple result sets returned by a query or stored procedure are handled through multiple REF CURSOR objects. For the NextResult method to work properly with Oracle databases, you must associate as many output parameters to the command as there are expected result sets. An ADO.NET result set coincides with an Oracle REF CURSOR in the command text. The output parameter names must match the name of the cursors, while their type must be OracleType.Cursor. The following code shows how to run a stored procedure (or the command text) that references a couple of cursors named Employees and Orders:
// cmd is an OracleCommand object that points to a command or a
// stored procedure. It executes code that creates two REF CURSORs
// called Employees and Orders. Names must match.
OracleParameter p1 = cmd.Parameters.Add("Employees", OracleType.Cursor);
p1.Direction = ParameterDirection.Output;
OracleParameter p2 = cmd.Parameters.Add("Orders", OracleType.Cursor);
p2.Direction = ParameterDirection.Output;
OLE DB Data Readers
The OleDbDataReader is the only data reader that fully supports the Depth property. It is the only provider that admits hierarchical rowsets (or OLE DB chapters). An example of a hierarchical result set is what you obtain by putting the MSDataShape OLE DB provider to work on a SHAPE query. A hierarchical query includes one or more columns that are in effect embedded result sets. Each of these columns is exposed as an OleDbDataReader object within the main OleDbDataReader object. Of course, rows in the child readers have a higher depth level.
Another little difference between OleDbDataReader and other reader classes is that when using the OleDbDataReader class in sequential access mode, you can reread the current column value until reading past it. This is not possible with other readers, in which you can read a column value only once.
Finally, when the reader works in SingleRow mode, the .NET data provider for OLE DB uses this information to bind data using the OLE DB IRow interface if it is available. Using IRow instead of the default IRowset interface results in faster code.
ADO NET Data Adapters
In ADO.NET, the data adapter object acts as a two-way bridge between a data source and the DataSet object. The DataSet is a sort of disconnected, feature-rich container of data, and the adapter takes care of filling it and submitting its data back to the data source. Viewed from a higher level of abstraction, a data adapter is just a command. It differs from the data reader because it returns a disconnected set of records. In a certain way, the data reader and data adapter are the results of the ADO Recordset split into two. Born to be a simple COM wrapper around an SQL result set, the ADO Recordset soon became a rather bloated object incorporating three types of cursors—read-only, disconnected, and server.
Compared to ADO, the ADO.NET object model is simpler overall and, more importantly, made of simpler objects. Instead of providing a big monolithic object like the Recordset, ADO.NET supplies two smaller and highly specialized objects—the data reader and the DataSet. The data reader is generated by a direct query command; the DataSet is generated by a data adapter.
The big difference between commands and data adapters is mostly in the way each one returns the retrieved data. A query command returns a read-only cursor—the data reader. The data adapter performs its data access, grabs all the data, and packs it into an in-memory container—the DataSet. Under the hood, the data adapter is just an extra layer of abstraction built on top of the command/data reader pair. Internally, in fact, the data adapter just uses a command to query and a data reader to walk its way through the records and fill a user-provided DataSet.
The SqlDataAdapter Class
By definition, a data adapter is a class that implements the IDataAdapter interface. However, looking at the actual implementation of the adapters in the supported providers, you can see that multiple layers of code are used. In particular, all data adapter classes inherit from a base class named DbDataAdapter and implement the IDbDataAdapter interface. The relationship is shown in Figure 5-3.
Figure 5-3: The hierarchy of data adapters and implemented interfaces.
The DbDataAdapter class provides the basic implementation of the members defined in the IDataAdapter interface. All data adapters implemented in the .NET Framework 1.1 inherit from DbDataAdapter.
Programming the SQL Server Data Adapter
Table 5-16 shows the properties of the SqlDataAdapter class—that is, the data adapter class for SQL Server.
|
Property |
Description |
|---|---|
|
AcceptChangesDuringFill |
Gets or sets a value that indicates whether or not during the population of the in-memory row insertions must be committed. True by default. |
|
ContinueUpdateOnError |
Gets or sets a value that indicates whether in case of row conflicts the update continues or an exception is generated. Used during batch update. |
|
DeleteCommand |
Gets or sets a statement or stored procedure to delete records from the database. Used during batch update. Is a member of the IDbDataAdapter interface. |
|
InsertCommand |
Gets or sets a statement or stored procedure to insert new records in the database. Used during batch update. Is a member of the IDbDataAdapter interface. |
|
MissingMappingAction |
Gets or sets a value that determines the action to take when a table or column in the source data is not mapped to a corresponding element in the in-memory structure. Is a member of the IDataAdapter interface. |
|
MissingSchemaAction |
Gets or sets a value that determines the action to take when source data does not have a matching table or column in the corresponding in-memory structure. Is a member of the IDataAdapter interface. |
|
SelectCommand |
Gets or sets a statement or stored procedure to select records from the database. During batch update, the method is used to download metadata; it is used to select records in a query statement. Is a member of the IDbDataAdapter interface. |
|
TableMappings |
Gets a collection that provides the mappings between a source table and an in-memory table. Is a member of the IDataAdapter interface. |
|
UpdateCommand |
Gets or sets a statement or stored procedure to update records in the database. Used during batch update. Is a member of the IDbDataAdapter interface. |
A data adapter is a two-way channel used to read data from the data source into a memory table and to write in-memory data back to the data source. These two operations can be clearly identified in the list of properties. The four xxxCommand members of the IDbDataAdapter interface are used to control how in-memory data is written to the database. This is not really true of SelectCommand; although SelectCommand plays a role in the batch update process. The two MissingXXX properties and the TableMappings collection—the members of the IDataAdapter interface—represent how data read out of the data source is mapped onto client memory.
Once loaded in memory, the (disconnected) data is available for client-side updates. Batch update is the data-provider procedure that posts all the in-memory changes back to the data source. In doing so, a bunch of DBMS-specific commands are required to carry out the three basic operations—insert, update, and delete. The InsertCommand, UpdateCommand, and DeleteCommand properties are SqlCommand objects that do just this.
During the population step—that is, when the data adapter is used to load data into an ADO.NET container class—the state of the in-memory table (for example, a DataTable object) changes in response to the insertions. As we'll see in more detail in the "ADO.NET Container Objects" section, container objects implement a commit model and assign in-memory rows a state. The row state can be reset to unchanged by accepting the change. At least during the filling step, this setting can be controlled through the AcceptChangesDuringFill property. Table 5-17 lists the methods on the data adapter objects.
|
Method |
Description |
|---|---|
|
Fill |
Populates an in-memory table with rows read from the source. |
|
FillSchema |
Configures an in-memory table so that the schema matches the schema in the data source. |
|
GetFillParameters |
Returns the parameters the user set on the query statement. |
|
Update |
Updates the data source based on the current content of the specified in-memory table. It works by calling the respective INSERT, UPDATE, or DELETE statements for each inserted, updated, or deleted row, respectively, in the table. |
The data adapter uses the SelectCommand property to retrieve schema and data from the data source. The connection object associated with the SelectCommand does not need to be open. If the connection is closed before the reading occurs, it is opened to retrieve data and then closed. If the connection is open when the adapter works, it remains open.
Filling a DataSet Using a Data Adapter
A data adapter object uses the Fill method to populate an in-memory object with data retrieved through a query. The in-memory structure is a DataSet or DataTable object. As we'll see more clearly in a moment, the DataSet is the in-memory counterpart of a DBMS database. It might contain multiple tables (that is, multiple DataTable objects) and set up relationships and constraints between tables. Each table, in turn, is made of a number of columns and rows.
Filling a DataSet object ultimately means filling one of its tables. The data adapter can create a new table for each result set generated by the query. The table mapping code decides how. Mapping a result set to a DataSet is a process articulated in two phases: table mapping and column mapping. During the first step, the data adapter determines the name of the DataTable that will contain the rows in the current result set. By default, each DataTable is given a default name you can change at will. The default name of the DataTable depends on the signature of the Fill method that was used for the call. For example, let's consider the following two Fill calls:
DataSet ds = new DataSet(); adapter.Fill(ds); adapter.Fill(ds, "MyTable");
In the first call, the name of the first result set generated by the query defaults to Table. If the query produces multiple result sets, additional tables will be named Table1, Table2, and so on, appending a progressive index to the default name. In the second call, the first result set is named MyTable and the others are named after it: MyTable1, MyTable2, and so forth. The procedure is identical; what really changes in the two cases is the base name.
The names of the tables can be changed at two different moments. You can change them after the DataSet has been populated or, when using table mapping, you can define settings that will be used to name the tables upon creation. You define a table mapping on a data adapter object using the TableMappings property.
| Note |
You can also use the Fill method to populate a single DataTable. In this case, only the first result set is taken into account and only one mapping phase occurs—column mapping. DataTable dt = new DataTable(); adapter.Fill(dt); The preceding code shows how to use the Fill method to populate a DataTable. |
The Table Mapping Mechanism
The .NET data provider assigns a default name to each result set generated by the query. The default name is Table or any name specified by the programmer in the call to Fill. The adapter looks up its TableMappings collection for an entry that matches the default name of the result set being read. If a match is found, the data adapter reads the mapped name. Next, it attempts to locate in the DataSet a DataTable object with the name specified in the mapping, as shown in Figure 5-4.
Figure 5-4: Mapping a result set onto a DataSet object.
If the result set named Table has been mapped to Employees, a table named Employees is searched in the DataSet. If no such DataTable object exists, it gets created and filled. If such a DataTable exists in the DataSet, its content is merged with the contents of the result set.
The TableMappings property represents a collection object of type DataTableMappingCollection. Each contained DataTableMapping object defines a pair of names: a source table name and an in-memory table name. Here's how to configure a few table mappings:
DataSet ds = new DataSet();
DataTableMapping dtm1, dtm2, dtm3;
dtm1 = adapter.TableMappings.Add("Table", "Employees");
dtm2 = adapter.TableMappings.Add("Table1", "Products");
dtm3 = adapter.TableMappings.Add("Table2", "Orders");
adapter.Fill(ds);
It goes without saying that the default names you map onto your own names must coincide with the default names originated by the call to the Fill method. In other words, suppose you change the last line of the previous code snippet with the following one:
adapter.Fill(ds, "MyTable");
In this case, the code won't work any longer because the default names will now be MyTable, MyTable1, and MyTable2. For these names, the TableMappings collection would have no entries defined. Finally, bear in mind you can have any number of table mappings. The overall number of mappings doesn't necessarily have to be related to the expected number of result sets.
The Column-Mapping Mechanism
If table mapping ended here, it wouldn't be such a big deal for us. In fact, if your goal is simply to give a mnemonic name to your DataSet tables, use the following code. The final effect is exactly the same.
DataSet ds = new DataSet(); adapter.Fill(ds); ds.Tables["Table"].TableName = "Employees"; ds.Tables["Table1"].TableName = "Products";
The mapping mechanism, though, has another, rather interesting, facet: column mapping. Column mapping establishes a link between a column in the result set and a column in the mapped DataTable object. Column mappings are stored in the ColumnMappings collection property defined in the DataTableMapping class. The following code shows how to create a column mapping:
DataSet ds = new DataSet();
DataTableMapping dtm1;
dtm1 = adapter.TableMappings.Add("Table", "Employees");
dtm1.ColumnMappings.Add("employeeid", "ID");
dtm1.ColumnMappings.Add("firstname", "Name");
dtm1.ColumnMappings.Add("lastname", "FamilyName");
adapter.Fill(ds);
Figure 5-5 extends the previous diagram (Figure 5-4) and includes details of the column-mapping mechanism.
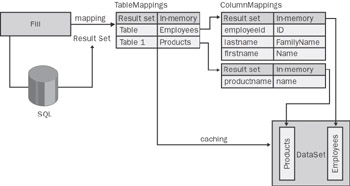
Figure 5-5: How the table and column mappings control the population of the DataSet.
In the preceding code, the source column employeeid is renamed to ID and placed in a DataTable named Employees. The name of the column is the only argument you can change at this level. Bear in mind that all this mapping takes place automatically within the body of the Fill method. When Fill terminates, each column in the source result set has been transformed into a DataTable column object—an instance of the DataColumn class.
Missing Mapping Action
The Fill method accomplishes two main operations. First, it maps the source result sets onto in-memory tables. Second, it fills the tables with the data fetched from the physical data source. While accomplishing either of these tasks, the Fill method could raise some special exceptions. An exception is an anomalous situation that needs to be specifically addressed codewise. When the adapter can't find a table or column mapping, or when a required DataTable or DataColumn can't be found, the data adapter throws a kind of lightweight exception.
Unlike real exceptions that must be resolved in code, this special breed of data adapter exceptions have to be resolved declaratively by choosing an action from a small set of allowable options. Data adapters raise two types of lightweight exceptions: missing mapping actions and missing schema actions.
A missing mapping action is required in two circumstances that can occur when the data adapter is collecting data to fill the DataSet. You need it if a default name is not found in the TableMappings collection, or if a column name is not available in the table's ColumnMappings collection. The data adapter's MissingMappingAction property is the tool you have for customizing the behavior of the data adapter in face of such an exception. Allowable values for the property, which are listed in Table 5-18, come from the MissingMappingAction enumeration.
|
Value |
Description |
|---|---|
|
Error |
An exception is generated if a missing column or table is detected. |
|
Ignore |
The unmapped column or table is ignored. |
|
Passthrough |
Default option, add the missing table or column to the structure. |
Unless you explicitly set the MissingMappingAction property prior to filling the data adapter, the property assumes a default value of Passthrough. As a result, missing tables and columns are added using the default name. If you set the MissingMappingAction property to Ignore, any unmapped table or column is simply ignored. No error is detected, but there will be no content for the incriminating result set (or one of its columns) in the target DataSet. If the MissingMappingAction property is set to Error, the adapter is limited to throwing a SystemException exception whenever a missing mapping is detected.
Once the data adapter is done with the mapping phase, it takes care of actually populating the target DataSet with the content of the selected result sets. Any required DataTable or DataColumn object that is not available in the target DataSet triggers another lightweight exception and requires another declarative action: the missing schema action.
Missing Schema Action
A missing schema action is required if the DataSet does not contain a table with the name that has been determined during the table-mapping step. Similarly, the same action is required if the DataSet table does not contain a column with the expected mapping name. MissingSchemaAction is the property you set to indicate the action you want to be taken in case of an insufficient table schema. Allowable values for the property come from the MissingSchemaAction enumeration and are listed in Table 5-19.
|
Value |
Description |
|---|---|
|
Error |
An exception is generated if a missing column or table is detected. |
|
Ignore |
The unmapped column or table is ignored. |
|
Add |
The default option. Completes the schema by adding any missing item. |
|
AddWithKey |
Also adds primary key and constraints. |
By default, the MissingSchemaAction property is set to Add. As a result, the DataSet is completed by adding any constituent item that is missing—DataTable or DataColumn. Bear in mind, though, that the schema information added in this way for each column is very limited. It simply includes name and type. If you want extra information—such as the primary key, autoincrement, read-only, and allow-null settings—use the AddWithKey option instead.
Note that even if you use the AddWithKey option, not all available information about the column is really loaded into the DataColumn. For example, AddWithKey marks a column as autoincrement, but it doesn't set the related seed and step properties. Also the default value for the source column, if any, is not automatically copied. Only the primary key is imported; any additional indexes you might have set in the database are not. As for the other two options, Ignore and Error, they work exactly as they do with the MissingMappingAction property.
Prefilling the Schema
MissingMappingAction and MissingSchemaAction are not as expensive as real exceptions, but they still affect your code. Put another way, filling a DataSet that already contains all the needed schema information results in faster code. The advantage of this approach is more evident if your code happens to repeatedly fill an empty DataSet with a fixed schema. In this case, using a global DataSet object pre-filled with schema information helps to prevent all those requests for recovery actions. The FillSchema method just ensures that all the required objects are created beforehand.
DataTable[] FillSchema(DataSet ds, SchemaType mappingMode);
FillSchema takes a DataSet and adds as many tables to it as needed by the query command associated with the data adapter. The method returns an array with all the DataTable objects created (only schema, no data). The mapping-mode parameter can be one of the values defined in the SchemaType enumeration. The SchemaType enumeration values are listed in Table 5-20.
|
Value |
Description |
|---|---|
|
Mapped |
Apply any existing table mappings to the incoming schema. Configure the DataSet with the transformed schema. Recommended option. |
|
Source |
Ignore any table mappings on the data adapter. Configure the DataSet using the incoming schema without applying any transformations. |
The Mapped option describes what happens when mappings are defined. Source, on the other hand, deliberately ignores any mappings you might have set. In this case, the tables in the DataSet retain their default name and all the columns maintain the original name they were given in the source tables.
How Batch Update Works
Batch update consists of the submission of an entire set of changes to the database. The batch update basically repeats the user actions that produced the changes but has the database—rather than the DataSet—as the target. Batch update assumes that the application enters its changes to the data set in an offline manner. In a multiuser environment, this might pose design problems if users concurrently access on the server the same data you're editing offline. When you post your changes on a record that another person has modified in the meantime, whose changes win out?
Data Conflicts and Optimistic Lock
The possibility of data conflicts represents a design issue, but it isn't necessarily a problem for the application. Batch update in a multiuser environment creates conflict only if the changes you enter are somewhat implied by the original values you have read. In such a case, if in the time elapsed between your fetch and the batch update someone else has changed the rows, you might want to reconsider or reject your most recent updates. Conflicts detected at update time might introduce significant overhead that could make the batch update solution much less exciting. In environments with a low degree of data contention, batch update can be effective because it allows for disconnected architectures, higher scalability, and considerably simpler coding.
To submit client changes to the server, use the data adapter's Update method. Data can be submitted only on a per-table basis. If you call Update without specifying any table name, a default name of Table is assumed. If no table exists with that name, an exception is raised.
adapter.Update(ds, "MyTable");
The Update method prepares and executes a tailor-made INSERT, UPDATE, or DELETE statement for each inserted, updated, or deleted row in the specified table. Rows are processed according to their natural order, and the row state determines the operation to accomplish. The Update method has several overloads and returns an integer, which represents the number of rows successfully updated.
When a row being updated returns an error, an exception is raised and the batch update process is stopped. You can prevent this from happening by setting the ContinueUpdateOnError property to true. In this case, the batch update terminates only when all the rows have been processed. Rows for which the update completed successfully are committed and marked as unchanged in the DataSet. For other rows, the application must decide what to do and restart the update if needed.
| Note |
The batch update is a loop that executes one user-defined database command for each inserted, modified, or deleted row in a DataSet table. In no way does the batch update process send the whole DataSet to the database for server-side processing. |
Command Builders
The data adapter provides a bunch of command properties—InsertCommand, DeleteCommand, and UpdateCommand—to let the programmer control and customize the way in which in-memory updates are submitted to the database server. These properties represent a quantum leap from ADO, in which update commands were SQL commands silently generated by the library. If you don't quite see the importance of this change, consider that with ADO.NET you can use stored procedures to perform batch updates and even work with non-SQL data providers.
The commands can also be generated automatically and exposed directly to the data-adapter engine. Command-builder objects do that for you. A command-builder object—for example, the SqlCommandBuilder class—cannot be used in all cases. The automatic generation of commands can take place only under certain circumstances. In particular, command builders do not generate anything if the table is obtained by joining columns from more than one table and if calculated—or aggregate—columns are detected. Command builders are extremely helpful and code-saving only when they are called to deal with single-table updates. How can a command builder generate update statements for a generic table? This is where the fourth command property—the SelectCommand property—fits in.
A command builder employs SelectCommand to obtain all the metadata necessary to build the update commands. To use command builders, you must set SelectCommand with a query string that contains a primary key and a few column names. Only those fields will be used for the update, and the insertion and key fields will be used to uniquely identify rows to update or delete. Note that the command text of SelectCommand runs in the provider-specific way that makes it return only metadata and no rows.
The association between the data adapter and the command builder is established through the builder's constructor, as shown in the following code:
SqlCommand cmd = new SqlCommand(); cmd.CommandText = "SELECT employeeid, lastname FROM Employees"; cmd.Connection = conn; adapter.SelectCommand = cmd; SqlCommandBuilder builder = new SqlCommandBuilder(adapter);
The builder requests metadata and generates the commands the first time they are required and then caches them. Each command is also exposed through a particular method—GetInsertCommand, GetUpdateCommand, and GetDeleteCommand. Note that these methods return temporary command objects but not the real command objects that will be used to carry the batch update on. For this reason, any changes made to the command objects obtained in this way are lost. If you want to use the autogenerated commands as a base for your own further changes, you should first assign them to the corresponding XXXCommand properties of the data adapter and then enter changes. The command builder won't overwrite any command property that is not null.
| Note |
The behavior of data adapters and command builders for other managed providers does not differ in a relevant way from what we described here for the SQL Server .NET data provider. |
The Case of Server Cursors
As of version 1.1 of the .NET Framework, ADO.NET does not support server cursors, such as the ADO adOpenKeyset and adOpenDynamic cursors. If you absolutely need that functionality in your application, there's probably no better choice than sticking to ADO. In a future version of the .NET Framework, the architecture of the .NET managed provider is expected to be enhanced to allow for server cursors. You should not expect it to be a general implementation of server cursors, though. Rather, it will be a database-specific implementation.
Server cursors will be exposed to applications through a new executor method in the provider's command class and return an instance of a new data-oriented class. For SQL Server, this class is tentatively named SqlResultSet.
ADO NET Container Objects
The System.Data namespace contains several collection-like objects that, combined, provide an in-memory representation of the DBMS relational programming model. The DataSet class looks like a catalog, whereas the DataTable maps to an individual table. The DataRelation class represents a relationship between tables, and the DataView creates a filtered view of a table's data. In addition, the System.Data namespace also supports constraints and a relatively simple model of indexing.
The facilities of the memory-resident database model tout a programming model in which disconnection is a key feature rather than a precise requirement. Using the DataSet model, for example, you can filter and sort the data on the client before it gets to the middle tier. Having such facilities available within the DataSet means that once the data is there, you don't need to go back to the database to get a different view on the data. The data stored in the DataSet is self-sufficient, which makes the whole model inherently disconnected.
The DataSet is great for storing state that survives across page requests—for example, cached catalog information, a shopping cart, or similar kinds of data. Storing a DataSet in ASP.NET global objects such as Session or Application doesn't have the same scalability implications that it had in ASP. ADO.NET objects are thread safe for read operations, but they need to be explicitly synchronized for write operations. The DataSet, though—and more generally, the disconnected model—is not appropriate for just any sort of Web application.
| Note |
It can be argued that in a Web application, using the DataSet as the data container attached to a command object might be a solution. This solution, though, is problematic if you consider Windows Forms applications in which you can leverage the power of the client. Generally, an interesting use of the DataSet that makes sense both for Web and desktop scenarios is in moving data around between components and tiers. The DataSet is great at encapsulating tables of data and relationships. It can also be passed around between tiers as a monolithic object. Finally, it can be serialized into and out of XML, meaning that data and related schema can be moved between tiers in a loosely coupled manner. |
The DataSet class is the principal component in the ADO.NET object model, but several others are satellite classes that play a fundamental role. ADO.NET container classes are listed Table 5-21.
|
Class |
Description |
|---|---|
|
DataSet |
An in-memory cache of data made of tables, relations, and constraints. Serializable and remotable, it can be filled from a variety of data sources and works regardless of which one is used. |
|
DataTable |
Logically equivalent to a disconnected ADO Recordset. Represents a relational table of data with a collection of columns and rows. |
|
DataColumn |
Represents a column in a DataTable object. |
|
DataRow |
Represents a row in a DataTable object. |
|
DataView |
Defined on top of a particular table. Creates a filtered view of data. Can be configured to support editing and sorting. The data view is not a copy of the data—just a mask. |
|
DataRelation |
Represents a relationship between two tables in the same DataSet. The relationship is set on a common column. |
|
UniqueConstraint |
Represents a restriction on a set of table columns in which all values must be unique. |
|
ForeignKeyConstraint |
Represents an action enforced on a set of table columns when a value or row is either deleted or updated. The columns must be in a primary key/foreign key relationship. |
A key point to remember about ADO.NET container classes is that they work regardless of the data source used. You can populate the tables in a DataSet by using the results of a SQL Server query as well as file system information or data read out of a real-time device. Even more importantly, none of the ADO.NET container classes retains information about the source. Like array or collection objects, they just contain data. Unlike array or collection objects, though, they provide facilities to relate and manage data in a database-like fashion.
| Note |
Of all the ADO.NET container classes, only DataSet and DataTable can be serialized using the .NET Framework formatters—the BinaryFormatter and SoapFormatter classes. Only the DataSet can be serialized to XML. The DataSet class supports two flavors of XML serialization—through the WriteXml method and through the XML serializer. |
The DataSet Object
The DataSet class inherits from the MarshalByValueComponent class and implements interfaces as shown in Figure 5-6.
Figure 5-6: The structure of the DataSet class.
The parent class provides the DataSet with the capability of being marshaled by value, meaning that a copy of the serialized object is passed down to remote callers. Other base behaviors are provided by the implemented interfaces. The IListSource interface makes it possible to return a data-bound list of elements, while the ISupportInitialize interface allows for a BeginInit and EndInit pair of methods to bracket initialization of properties. Finally, ISerializable makes the class capable of controlling how its data is serialized to a .NET formatter. Table 5-22 lists the properties of the DataSet class.
|
Property |
Description |
|---|---|
|
CaseSensitive |
Gets or sets a value that indicates whether string comparisons within DataTable objects are case sensitive. |
|
DataSetName |
Gets or sets the name of the DataSet. |
|
DefaultViewManager |
Gets the default view manager object—an instance of the DataViewManager class—that contains settings for each table in the DataSet. |
|
EnforceConstraints |
Gets or sets a value that indicates whether constraint rules are enforced when attempting any update operation. |
|
ExtendedProperties |
Gets the collection of customized user information associated with the DataSet. |
|
HasErrors |
Gets errors in any of the child DataTable objects. |
|
Locale |
Gets or sets the locale information used to compare strings within the tables. |
|
Namespace |
Gets or sets the namespace of the DataSet. |
|
Prefix |
Gets or sets the prefix that aliases the namespace of the DataSet. |
|
Relations |
Gets the collection of the relations set between pairs of child tables. |
|
Tables |
Gets the collection of contained tables. |
The Namespace and Prefix properties affect the way in which the DataSet serializes itself to XML. The name of the DataSet is also used to set the root node of the XML representation. If the DataSetName is empty, the NewDataSet string is used. The methods of the class are listed in Table 5-23.
|
Method |
Description |
|---|---|
|
AcceptChanges |
Commits all the changes made to all the tables in the DataSet since it was loaded or since the last time the method was called. |
|
Clear |
Removes all rows in all tables. |
|
Clone |
Copies the structure of the DataSet, including all table schemas, relations, and constraints. No data is copied. |
|
Copy |
Makes a deep copy of the object, including schema and data. |
|
GetChanges |
Returns a copy of the DataSet containing only the changes made to it since it was last loaded or since AcceptChanges was called. |
|
GetXml |
Returns the XML representation of the data stored. |
|
GetXmlSchema |
Returns the XSD schema for the XML string representing the data stored in the DataSet. |
|
HasChanges |
Indicates whether there are new, deleted, or modified rows in any of the contained tables. |
|
InferXmlSchema |
Replicates into the DataSet the table structure inferred from the specified XML document. |
|
Merge |
Merges the specified ADO.NET object (DataSet, DataTable, or an array of DataRow objects) into the current DataSet. |
|
ReadXml |
Populates the DataSet reading schema and data from the specified XML document. |
|
ReadXmlSchema |
Replicates into the DataSet the table structure read from the specified XML schema. |
|
RejectChanges |
Rolls back all the changes made to all the tables since it was created or since the last time AcceptChanges was called. |
|
Reset |
Empties tables, relations, and constraints, resetting the DataSet to its default state. |
|
WriteXml |
Serializes the DataSet contents to XML. |
|
WriteXmlSchema |
Writes the DataSet structure as an XML schema. |
To make a full, deep copy of the DataSet, you must resort to the Copy method. Only in this case, you duplicate the object. The following code does not duplicate the object:
DataSet tmp = ds;
If you simply assign the current DataSet reference to another variable, you duplicate the reference but not the object. Use the following code to duplicate the object:
DataSet tmp = ds.Copy();
The Copy method creates and returns a new instance of the DataSet object and ensures that all the tables, relations, and constraints are duplicated. The Clone method is limited to returning a new DataSet object in which all the properties have been replicated but no data in the tables is copied.
Merging DataSet Objects
A merge operation is typically accomplished by a client application to update an existing DataSet object with the latest changes read from the data source. The Merge method should be used to fuse together two DataSet objects that have nearly identical schemas. The two schemas, though, are not strictly required to be identical.
The first step in the merge operation compares the schemas of the involved DataSet objects to see whether they match. If the DataSet to be imported contains new columns or a new table source, what happens depends on the missing schema action specified. By default, any missing schema element is added to the target DataSet, but you can change the behavior by choosing the Merge overload that allows for a MissingSchemaAction parameter.
As the second step, the Merge method attempts to merge the data by looking at the changed rows in the DataSet to be imported. Any modified or deleted row is matched to the corresponding row in the existing DataSet by using the primary key value. Added rows are simply added to the existing DataSet and retain their primary key value.
The merge operation is an atomic operation that must guarantee integrity and consistency only at its end. For this reason, constraints are disabled during a merge operation. However, if at the end of the merge the original constraints can't be restored—for example, a unique constraint is violated—an exception is thrown, but no uploaded data gets lost. In this case, the Merge method completely disables constraints in the DataSet. It sets the EnforceConstraints property to false and marks all invalid rows in error. To restore constraints, you must first resolve errors.
The DataSet Commit Model
When the DataSet is first loaded, all the rows in all tables are marked as unchanged. The state of a table row is stored in a property named RowState. Allowable values for the row state are in the DataRowState enumeration listed in Table 5-24.
|
Value |
Description |
|---|---|
|
Added |
The row has been added to the table. |
|
Deleted |
The row is marked for deletion from the parent table. |
|
Detached |
Either the row has been created but not yet added to the table or the row has been removed from the rows collection. |
|
Modified |
Some columns within the row have been changed. |
|
Unchanged |
No changes have been made since the last call to AcceptChanges. This is also the state of all rows when the table is first created. |
The AcceptChanges method has the power to commit all the changes and accept the current values as the new original values of the table. After AcceptChanges is called, all changes are cleared. The RejectChanges method, on the other hand, rolls back all the pending changes and restores the original values. Note that the DataSet retains original values until changes are committed or rejected.
The commit model is applicable at various levels. In particular, by calling AcceptChanges or RejectChanges on the DataSet object, you commit or roll back changes for all the rows in all the contained tables. If you call the same methods on a DataTable object, the effect is for all the rows in the specified table. Finally, you can also accept or reject changes for an individual row in a particular table.
Serializing Contents to XML
The contents of a DataSet object can be serialized as XML in two ways, which I'll call stateless and stateful. Although these expressions are not common throughout the ADO.NET documentation, I feel that they perfectly describe the gist of the two possible approaches. A stateless representation takes a snapshot of the current instance of the data and renders it according to a particular XML schema—the ADO.NET normal form—as shown in the following code:
... ...
The root node appears after the DataSetName property. Nodes one level deeper represent rows of all tables and are named as the table. Each row node contains as many children as there are columns in the row. This code snippet refers to a DataSet with two tables—Employees and Orders—with two and three columns, respectively. That kind of string is what the GetXml method returns and what the WriteXml method writes out when the default write mode is chosen.
dataSet.WriteXml(fileName); dataSet.WriteXml(fileName, mode);
A stateful representation, on the other hand, contains the history of the data in the object and includes information about changes as well as pending errors. Table 5-25 summarizes the writing options available for use with WriteXml through the XmlWriteMode enumeration.
|
Write Mode |
Description |
|---|---|
|
IgnoreSchema |
Writes the contents of the DataSet as XML data without schema. |
|
WriteSchema |
Writes the contents of the DataSet, including an inline XSD schema. The schema cannot be inserted as XDR, nor can it be added as a reference. |
|
DiffGram |
Writes the contents of the DataSet as a DiffGram, including original and current values. |
IgnoreSchema is the default option. The following code demonstrates the typical way to serialize a DataSet to an XML file:
StreamWriter sw = new StreamWriter(fileName); dataset.WriteXml(sw); // defaults to XmlWriteMode.IgnoreSchema sw.Close();
A DiffGram is an XML serialization format that includes both the original values and current values of each row in each table. In particular, a DiffGram contains the current instance of rows with the up-to-date values plus a section where all the original values for changed rows are grouped. Each row is given a unique identifier that is used to track changes between the two sections of the DiffGram. This relationship looks a lot like a foreign-key relationship. The following listing outlines the structure of a DiffGram:
The root node can have up to three children. The first is the DataSet object with its current contents, including newly added rows and modified rows (but not deleted rows). The actual name of this subtree depends on the DataSetName property of the source DataSet object. If the DataSet has no name, the subtree's root is NewDataSet. The subtree rooted in the node contains enough information to restore the original state of all modified rows. For example, it still contains any row that has been deleted as well as the original content of any modified row. All columns affected by any change are tracked in the subtree. The last subtree is , and it contains information about any errors that might have occurred on a particular row.
| Note |
The XML serialization of the DataSet object is a relatively large topic that deserves much more space than this section allows. The topic is covered in detail in Chapters 9 and 10 of my book, Applied XML Programming for Microsoft .NET (Microsoft Press, 2002). |
The DataTable Object
The DataTable object represents one table of in-memory data. Mostly used as a container of data within a DataSet, the DataTable is also valid as a stand-alone object that contains tabular data. The internal structure of the class is identical to that depicted in Figure 5-6 for the DataSet. The DataTable and DataSet are the only ADO.NET objects that can be remoted and serialized.
Just as with a DataSet, a DataTable can be created programmatically. In this case, you first define its schema and then add new rows. The following code snippet shows how to create a new table within a DataSet:
DataSet ds = new DataSet();
DataTable tableEmp = new DataTable("Employees");
tableEmp.Columns.Add("ID", typeof(int));
tableEmp.Columns.Add("Name", typeof(string));
ds.Tables.Add(tableEmp);
The table is named Employees and features two columns—ID and Name. The table is empty because no rows have been added yet. To add rows, you first create a new row object by using the NewRow method:
DataRow row = tableEmp.NewRow(); row["ID"] = 1; row["Name"] = "Joe Users"; tableEmp.Rows.Add(row);
The DataTable contains a collection of constraint objects that can be used to ensure the integrity of the data and signals changes to its data-firing events. Let's have a closer look at the programming interface of the DataTable, beginning with properties. Table 5-26 lists the properties of the DataTable class.
|
Property |
Description |
|---|---|
|
CaseSensitive |
Gets or sets whether string comparisons are case-sensitive. |
|
ChildRelations |
Gets the collection of child relations for this table. |
|
Columns |
Gets the collection of columns that belong to this table. |
|
Constraints |
Gets the collection of constraints maintained by this table. |
|
DataSet |
Gets the DataSet this table belongs to. |
|
DefaultView |
Gets the default DataView object for this table. |
|
DisplayExpression |
Gets or sets a display string for the table. Used in the ToString method together with TableName. |
|
ExtendedProperties |
Gets the collection of customized user information. |
|
HasErrors |
Gets a value that indicates whether there are errors in any of the rows. |
|
Locale |
Gets or sets locale information used to compare strings. |
|
MinimumCapacity |
Gets or sets the initial starting size for the table. |
|
Namespace |
Gets or sets the namespace for the XML representation of the table. |
|
ParentRelations |
Gets the collection of parent relations for this table. |
|
Prefix |
Gets or sets the prefix that aliases the table namespace. |
|
PrimaryKey |
Gets or sets an array of columns that function as the primary key for the table. |
|
Rows |
Gets the collection of rows that belong to this table. |
|
TableName |
Gets or sets the name of the DataTable object. |
The ExtendedProperties property is a collection shared by several ADO.NET objects, including DataSet and DataColumn. It manages name/value pairs and accepts values of object type. You can use this collection as a generic cargo variable in which to store any user information. Although the ExtendedProperties collection can accept any object, you should always store strings. If you use something other than strings, you might run into troubles if the DataTable gets serialized at some time. When the table is serialized, any item in the ExtendedProperties collection is serialized as a string using the output of the ToString method. This fact doesn't ensure that the object will be correctly restored during the deserialization step. The methods of the DataTable class are listed in Table 5-27.
|
Method |
Description |
|---|---|
|
AcceptChanges |
Commits all the pending changes made to the table. |
|
BeginInit |
Begins the initialization of the table. Used when the table is used on a form or by another component. |
|
BeginLoadData |
Turns off notifications, index maintenance, and constraints while loading data. |
|
Clear |
Removes all the data from the table. |
|
Clone |
Clones the structure of the table. Copies constraints and schema, but doesn't copy data. |
|
Compute |
Computes the given expression on the rows that meet the specified filter criteria. Returns the result of the computation as an object. |
|
Copy |
Copies both the structure and data for the table. |
|
EndInit |
Ends the initialization of the table. Closes the operation started with BeginInit. |
|
EndLoadData |
Turns on notifications, index maintenance, and constraints after loading data. |
|
GetChanges |
Gets a copy of the table containing all changes made to it since it was last loaded or since AcceptChanges was called. |
|
GetErrors |
Gets an array of all the DataRow objects that contain errors. |
|
ImportRow |
Performs a deep copy of a DataRow, and loads it into the table. Settings, including original and current values, are preserved. |
|
LoadDataRow |
Finds and updates a specific row. If no matching row is found, a new row is created using the given values. Uses the primary keys to locate the row. |
|
NewRow |
Creates a new DataRow object with the schema as the table. |
|
RejectChanges |
Rolls back all changes that have been made to the table since it was loaded or since the last time AcceptChanges was called. |
|
Reset |
Resets the DataTable object to its default state. |
|
Select |
Gets the array of DataRow objects that match the criteria. |
Any row in the DataTable is represented by a DataRow object, whereas the DataColumn object represents a column. The Select method implements a simple but effective query engine for the rows of the table. The result set is an array of DataRow objects. The filter string is expressed in an internal language that looks like that used to build WHERE clauses in a SQL SELECT statement. The following line of code is a valid expression that selects all records in which the ID is greater than 5 and the name begins with A:
tableEmp.Select("ID >5 AND Name LIKE 'A%'");
Refer to the .NET Framework documentation for the full syntax supported by the Select method. Note that it's the same language you can use to define expression-based DataTable columns.
Performing Computations
The Compute method of the DataTable class calculates a value by applying a given expression to the table rows that match a specified filter. Expressions can include any sort of Boolean and arithmetic operators, but they can also include more interesting aggregate functions such as Min, Max, Count, and Sum, plus a few more statistical operators such as average, standard deviation, and variance. The following code counts the rows in which the Name column begins with A:
int numRecs = (int) tableEmp.Compute("Count(ID)", " Name LIKE 'A%'");
The Compute method has two possible overloads—one that takes only the expression to compute and one that also adds a filter string, as shown in the preceding code. Note that all aggregate functions can operate on a single column. This means you can directly compute the sum on two columns, as in the following pseudo-code:
Sum(quantity * price)
To compute functions on multiple columns, you can leverage the capabilities of the DataColumn object and, in particular, its support for dynamic expressions. For example, you can define an in-memory column named order_item_price as follows:
tableEmp.Columns.Add("order_item_price", typeof(double), "quantity*price");
At this point, you can compute the sum of that column using the following expression:
Sum(order_item_price)
Columns of a Table
A DataColumn object represents the schema of a column in a DataTable object. It provides properties that describe the characteristics and capabilities of the column. The DataColumn properties include AllowDBNull, Unique, ReadOnly, DefaultValue, and Expression. As discussed earlier, some of these properties are automatically set with the corresponding information read from the data source—at least when the data source is a database.
A DataColumn object has a name and type; sometimes it can also have an associated expression. The content of an expression-based column is a function of one or more columns combined with operators and aggregates to form a full expression. When an expression-based column is created, ADO.NET precalculates and caches all the values for the column as if they were native data. At the same time, ADO.NET tracks the columns involved and monitors them for changes. It does so by registering an internal handler for the DataTable's RowChanged event. When a row changes in one of the columns involved in the expression, the computed column is automatically refreshed.
Expression-based columns are extremely powerful for setting up more effective and practical forms of data binding, as we'll see in the next chapter. In addition, expression-based columns work side by side with table relations and, using both, you can implement really powerful features. We'll demonstrate this later in the "Data Relations" section.
Rows of a Table
The data in a table is represented with a collection of DataRow objects. A row has a state, an array of values, and possibly error information. The DataTable maintains various versions of the row. You can query for a particular version at any time using the Item accessor property. The following code snippet shows how to read the original value of a column in a particular DataRow object. By default, you are returned the current value.
Response.Write(row["Name", DataRowVersion.Original].ToString());
All the values in a row can be accessed either individually or as a whole. When accessing all the values in a row, you use the ItemArray property, which passes you an array of objects, one for each column. The ItemArray property is a quick way to read values from a row and to set all the columns on a row in a single shot.
The DataRow class doesn't have a public constructor. As a result, a data row can be created only implicitly using the NewRow method on a base table. The NewRow method populates the DataRow object with as many entries as there are columns in the DataTable. In this case, the table provides the schema for the row, but the row is in no way a child of the table. To add a row to a DataTable, you must explicitly add it to the Rows collection.
tableEmp.Rows.Add(row);
Note that a DataRow object cannot be associated with more than one table at a time. To load a row into another table, you can use the ImportRow method, which basically duplicates the DataRow object and loads it into the specified table. A row can be detached from its parent table using the Remove method. If you use the Delete method, on the other hand, the row will be marked for deletion but still remain part of the table.
| Note |
Objects removed from a parent collection are not automatically destroyed or, at least, not until they go out of scope and become fodder for the garbage collector. This consideration holds true for several ADO.NET objects including, but not limited to, the DataRow. A DataTable, for example, can be detached from the DataSet by simply removing it from the Tables collection. However, this doesn't mean that the DataTable is automatically deleted as an object. |
Table Constraints
A constraint is a logical rule set on a table to preserve the integrity of the data. For example, a constraint determines what happens when you delete a record in a table that is related to another one. The .NET Framework supports two types of constraints—ForeignKeyConstraint and UniqueConstraint.
In particular, the ForeignKeyConstraint class sets the rules that govern how the table propagates changes to related tables. For example, suppose you have two related tables, one with employees and one with orders. What happens when an employee is deleted? Should you delete all the related records too? The ForeignKeyConstraint object associated with the Employees table will determine what is related to it in the Orders table. You create a ForeignKeyConstraint object as shown below:
DataColumn c1 = tableEmp.Columns("empID");
DataColumn c2 = tableOrd.Columns("empID");
ForeignKeyConstraint fk = new ForeignKeyConstraint("EmpOrders", c1, c2);
// configure the constraint object
tableOrd.Constraints.Add(fk);
The ForeignKeyConstraint constructor takes the name of the object plus two DataColumn objects. The first DataColumn object represents the column (or the columns) on the parent table; the second DataColumn object represents the column (or the columns) in the child table. The constraint is added to the child table and is configured using the UpdateRule, DeleteRule, and AcceptRejectRule properties. While setting the UpdateRule and DeleteRule properties, you use values taken from the Rule enumeration. AcceptRejectRule is the enumeration used to look for the AcceptRejectRule property of the same name. For updates and deletions, the child table can cascade the change or set the involved rows to null or default values. Alternately, the child table can simply ignore the changes. The AcceptRejectRule property is processed when the AcceptChanges method is called on the parent row to commit changes. The choices for the constraint are limited to either cascading or ignoring changes.
The UniqueConstraint class ensures that a single column (or an array of columns) have unique, nonduplicated values. There are several ways to set a unique constraint. You can create one explicitly using the class constructor and adding the resulting object to the Constraints collection of the DataTable.
UniqueConstraint uc;
uc = new UniqueConstraint(tableEmp.Columns("empID"));
tableEmp.Constraints.Add(uc);
A unique constraint can also be created implicitly by setting the Unique property of the column to true. In contrast, setting the Unique property to false resets the constraint. In addition, adding a column to the in-memory primary key for a table would automatically create a unique constraint for the column. Note that a primary key on a DataTable object is an array of DataColumn objects that is used to index and sort the rows. The Select method on the DataTable exploits the index as well as other methods on the DataView class do.
| Note |
When you define a DataColumn as the primary key for a DataTable object, the table automatically sets the AllowDBNull property of the column to false and the Unique property to true. If the primary key is made of multiple columns, only the AllowDBNull property is automatically set to false. |
Data Relations
A data relation represents a parent/child relationship between two DataTable objects in the same DataSet. In the .NET Framework, a data relation is represented by a DataRelation object. You set a relation between two tables based on matching columns in the parent and child tables. The matching columns in the two related tables can have different names, but they must have the same type. All the relations for the tables in a DataSet are stored in the Relations collection. Table 5-28 lists the properties of the DataRelation class.
|
Property |
Description |
|---|---|
|
ChildColumns |
Gets the child DataColumn objects for the relation. |
|
ChildKeyConstraint |
Gets the ForeignKeyConstraint object for the relation. |
|
ChildTable |
Gets the child DataTable object for the relation. |
|
DataSet |
Gets the DataSet to which the relation belongs. |
|
ExtendedProperties |
Gets the collection that stores user information. |
|
Nested |
Gets or sets a value that indicates whether the relation should render its data as nested subtrees when the DataSet is rendered to XML. (More on this later in the "Serializing a Data Relation" section.) |
|
ParentColumns |
Gets the parent DataColumn objects for the relation. |
|
ParentKeyConstraint |
Gets the UniqueConstraint object that ensures unique values on the parent column of the relation. |
|
ParentTable |
Gets the parent DataTable object for the relation. |
|
RelationName |
Gets or sets the name of the DataRelation object. The name is used to identify the relation in the Relations collection of the parent DataSet object. |
When a DataRelation is created, two constraints are silently created. A foreign-key constraint is set on the child table using the two columns that form the relation as arguments. In addition, the parent table is given a unique constraint that prevents it from containing duplicates. The constraints are created by default, but by using a different constructor you can instruct the DataRelation to skip that step. The DataRelation class has no significant methods.
Creating a Data Relation
The DataRelation class can be seen as the memory counterpart of a database table relationship. However, when a DataSet is loaded from a database, DBMS-specific relationships are not processed and loaded. As a result, data relations are exclusively in-memory objects that must be created explicitly with code. The following snippet shows how:
DataColumn c1 = tableEmp.Columns("empID");
DataColumn c2 = tableOrd.Columns("empID");
DataRelation rel = new DataRelation("Emp2Orders", c1, c2);
DataSet.Relations.Add(rel);
Given two tables, Employees and Orders, the preceding code sets up a relationship between the two based on the values of the common column empID. What are the practical advantages of such a relation? After the relation is set, the parent DataTable knows that each row might have a bunch of child related rows. In particular, each employee in the Employees table has an array of related rows in the Orders table. The child rows are exactly those where the value of the Orders.empID column matches empID column on the current Employees row.
ADO.NET provides an automatic mechanism to facilitate the retrieval of these related rows. The method is GetChildRows, and it's exposed by the DataRow class. GetChildRows takes a relation and returns an array filled with all the DataRow objects that match.
foreach(DataRow childRow in parentRow.GetChildRows("Emp2Orders"))
{
// Process the child row
}
Another important facility ADO.NET provides for data relations has to do with table calculations and expression-based columns.
Performing Calculations on Relations
A common task in many real-world applications entails that you manage two related tables and process, given a parent row, the subset of child records. In many situations, processing the child rows just means performing some aggregate computations on them. This is just one of facilities that ADO.NET and relations provide for free. Let's suppose that, given the previous employees-to-orders relation, you need to compute the total of orders issued by a given employee. You could simply add a dynamically computed column to the parent table and bind it to the data in the relation:
tableEmp.Columns.Add("Total", typeof(int),
"Sum(child(Emp2Orders).Amount)");
| Caution |
Although powerful and easy to use, ADO.NET disconnected features are not all extremely useful in ASP.NET applications. To exploit a relation to its fullest, you need to have full tables in memory or, at least, all the records in both tables that you need to display. As you surely understand, although this is possible, it makes the SQL code significantly more complex. But there's a subtler point to consider. A relation implies multiple tables, which implies multiple SELECT statements. In highly concurrent environments, this requires a rather heavy serializable transaction. Should you resort to an old-fashioned query using INNER JOIN in spite of the redundant data it returns? Not necessarily; returning multiple result sets in a single call would require less bandwidth and the same transactional penalty. |
The new column Total contains, for each employee, a value that represents the sum of all the values in the Amount column for the child rows of the relation. In other words, now you have a column that automatically computes the total of orders issued by each employee. The keyword child is a special syntax element of the language that ADO.NET expressions support. Basically, the child keyword takes a relation name and returns an array of DataRow objects that is the child of that relation.
Serializing a Data Relation
The Nested property on the DataRelation object affects the way in which the parent DataSet is rendered to XML. By default, the presence of a relation doesn't change the XML schema used to serialize a DataSet. All the tables are therefore rendered sequentially under the root node. A nested relation changes this default schema. In particular, a nested relation is rendered hierarchically with child rows nested under the parent row.
A DataSet with Employees and Orders tables is rendered according to the following pattern:
If a relation exists between the tables and is set as nested, the XML schema changes as follows:
The child rows are taken out of their natural place and placed within the subtree that represents the parent row.
The DataView Object
The DataView class represents a customized view of a DataTable. The relationship between DataTable and DataView objects is governed by the rules of a well-known design pattern: the document/view model. The DataTable object acts as the document, whereas the DataView behaves as the view. At any moment, you can have multiple, different views of the same underlying data. More importantly, you can manage each view as an independent object with its own set of properties, methods, and events.
The view is implemented by maintaining a separate array with the indexes of the original rows that match the criteria set on the view. By default, the table view is unfiltered and contains all the records included in the table. By using the RowFilter and RowStateFilter properties, you can narrow the set of rows that fit into a particular view. Using the Sort property, you can apply a sort expression to the rows in the view. Table 5-29 lists the properties of the DataView class.
|
Property |
Description |
|---|---|
|
AllowDelete |
Gets or sets a value that indicates whether deletes are allowed in the view. |
|
AllowEdit |
Gets or sets a value that indicates whether edits are allowed in the view. |
|
AllowNew |
Gets or sets a value that indicates whether new rows can be added through the view. |
|
ApplyDefaultSort |
Gets or sets a value that indicates whether to use the default sort. |
|
Count |
Gets the number of rows in the view after the filter has been applied. |
|
DataViewManager |
Gets the DataViewManager object associated with this view. |
|
Item |
An indexer property. Gets a row of data from the underlying table. |
|
RowFilter |
Gets or sets the expression used to filter out rows in the view. |
|
RowStateFilter |
Gets or sets the row state filter used in the view. |
|
Sort |
Gets or sets the sorting of the view in terms of columns and order. |
|
Table |
Gets or sets the source DataTable for the view. |
The filter can be an expression, the state of the rows, or both. The RowStateFilter property, in particular, takes its acceptable values from the DataViewRowState enumeration and allows you to filter based on the original or current values of the row, or on modified, added, or deleted rows. The RowFilter property supports the same syntax as the DataTable's Select method.
A DataView does not contain copies of the table's rows. It is limited to storing an array of indexes that is updated whenever any of the filter properties is set. The DataView object is already connected to the underlying DataTable, of which it represents a possibly filtered and/or sorted view. The AllowXXX properties only let you control whether the view is editable or not. By default, the view is fully editable. Table 5-30 lists the methods of the DataView class.
|
Method |
Description |
|---|---|
|
AddNew |
Adds a new row to the view and the underlying table. |
|
BeginInit |
Begins the initialization of the view. |
|
CopyTo |
Copies items from the view into an array. |
|
Delete |
Deletes the row at the specified index in the view. The row is deleted from the table too. |
|
EndInit |
Ends the initialization of the view. |
|
Find |
Finds a row in the view by the specified key value. |
|
FindRows |
Returns an array of row objects that match the specified key value. |
|
GetEnumerator |
Returns an enumerator object for the DataView. |
Both the AddNew and Delete methods affect the underlying DataTable object. Multiple changes can be grouped using the pair BeginInit/EndInit.
Navigating the View
The contents of a DataView object can be scrolled through a variety of programming interfaces, including collections, lists, and enumerators. The GetEnumerator method, in particular, ensures that you can walk your way through the records in the view using the familiar for...each statement. The following code shows how to access all the rows that fit into the view:
DataView myView = new DataView(table);
foreach(DataRowView rowview in myView)
{
// dereferences the DataRow object
DataRow row = rowview.Row;
}
When client applications access a particular row in the view, the DataView class expects to find it in an internal cache of rows. If the cache is not empty, the specified row is returned to the caller via an intermediate DataRowView object. The DataRowView object is a kind of wrapper for the DataRow object that contains the actual data. You access row data through the Row property. If the row cache is empty, the DataView class fills it up with an array of DataRowView objects, each of which references an original DataRow object. The row cache is refreshed whenever the sort expression or the filter string are updated. The row cache can be empty either because it has never been used or because the sort expression or the filter string have been changed in the meantime. Figure 5-7 illustrates the internal architecture of a DataView object.
Figure 5-7: The internal structure of a DataView object.
Finding Rows
The link between the DataTable and the DataView is typically established at creation time through the constructor:
public DataView(DataTable table);
However, you could also create a new view and associate it with a table at a later time using the DataView's Table property. For example:
DataView dv = new DataView(); dv.Table = dataSet.Tables["Employees"];
You can also obtain a DataView object from any table. In fact, the DefaultView property of a DataTable object just returns a DataView object initialized to work on that table.
DataView dv = dt.DefaultView;
Originally, the view is unfiltered and the index array contains as many elements as the rows in the table. To quickly find a row, you can either use the Find or FindRows method. The Find method takes one or more values and returns an array with the indexes of the rows that match. The FindRows method works in much the same way, but it returns an array of DataRowView objects rather than indexes. Both methods accept a sort key value to identify the rows to return.
| Note |
The contents of a DataView can be sorted by multiple fields by using the Sort property. You can assign to Sort a comma-separated list of column names, and even append them with DESC or ASC to indicate the direction. |
Conclusion
The ADO.NET object model is made of two main subtrees—the managed providers and the database-agnostic container classes. Managed providers are the new type of data source connectors and replace the COM-based OLE DB providers of ADO and ASP. As of today, very few managed providers exist to connect to commercial DBMS. The .NET Framework version 1.1 includes two native providers—one for SQL Server and one for Oracle—and support for all OLE DB providers and ODBC drivers. Third-party vendors also support MySQL and provide alternative providers for Oracle. (Providers for other popular DBMS systems are in the works.)
A managed provider is faster and more apt than any other database technology for data access tasks. Especially effective with SQL Server, it hooks up at the wire level and removes any sort of abstraction layer. In this way, a managed provider makes it possible for ADO.NET to return to callers the same data types they would use to refresh the user interface. Functionally speaking, managed providers don't provide the same set of features as ADO. In particular, server cursors and the schema object model are not supported in this version of ADO.NET but are expected for the next major release.
A managed provider supplies objects to connect to a data source, execute a command, and then grab or set some data. The ADO.NET object model provides a special type of command—the data adapter—which is different because it returns a disconnected container object—the DataSet. Central to the ADO.NET infrastructure, the DataSet can be considered the in-memory counterpart of a DBMS catalog. Disconnected programming is useful and powerful but not always suited for simple and not too heavily layered Web applications.
In the next chapter, we'll see practical examples of how to bind data to user interface controls and we'll start seeing why disconnected data containers are not always the most effective tools to use over the Web to manage large quantities of data.
Resources
- Microsoft ADO.NET, by David Sceppa (Microsoft Press, 2002)
- Pragmatic ADO.NET, by Shawn Wildermuth (Addison-Wesley, 2002)
- Applied XML Programming for Microsoft .NET, by Dino Esposito (Microsoft Press, 2002%
Part I - Building an ASP.NET Page
Part II - Adding Data in an ASP.NET Site
- The ADO.NET Object Model
- Creating Bindable Grids of Data
- Paging Through Data Sources
- Real-World Data Access
Part III - ASP.NET Controls
Part IV - ASP.NET Application Essentials
- Configuration and Deployment
- The HTTP Request Context
- ASP.NET State Management
- ASP.NET Security
- Working with the File System
- Working with Web Services
Part V - Custom ASP.NET Controls
- Extending Existing ASP.NET Controls
- Creating New ASP.NET Controls
- Data-Bound and Templated Controls
- Design-Time Support for Custom Controls
Part VI - Advanced Topics
Index
EAN: 2147483647
Pages: 209
