The roots of SOA (comparing SOA to past architectures)
We now actually jump back in our timeline to take a look at the differences between past architectural platforms and SOA. This is an interesting study from which we can identify how SOA derived many of its current characteristics.
Note
A number of traditional architectures are explained and illustrated in this section. However, the architectural details of SOA itself are not covered until later in this book. Reading this section is therefore not required to proceed with subsequent chapters. If you are not interested in learning about how SOA differs from other architectures, then feel free to skip ahead to Chapter 5.
4.3.1. What is architecture?
For as long as there have been computerized automation solutions, technology architecture has existed. However, in older environments, the construction of the solution was so straight forward that the task of abstracting and defining its architecture was seldom performed.
With the rise of multi-tier applications, the variations with which applications could be delivered began to dramatically increase. IT departments started to recognize the need for a standardized definition of a baseline application that could act as a template for all others. This definition was abstract in nature, but specifically explained the technology, boundaries, rules, limitations, and design characteristics that apply to all solutions based on this template. This was the birth of the application architecture.
Application architecture
Application architecture is to an application development team what a blueprint is to a team of construction workers. Different organizations document different levels of application architecture. Some keep it high-level, providing abstract physical and logical representations of the technical blueprint. Others include more detail, such as common data models, communication flow diagrams, application-wide security requirements, and aspects of infrastructure.
It is not uncommon for an organization to have several application architectures. A single architecture document typically represents a distinct solution environment. For example, an organization that houses both .NET and J2EE solutions would very likely have separate application architecture specifications for each.
A key part of any application-level architecture is that it reflects immediate solution requirements, as well as long-term, strategic IT goals. It is for this reason that when multiple application architectures exist within an organization, they are almost always accompanied by and kept in alignment with a governing enterprise architecture.
Enterprise architecture
In larger IT environments, the need to control and direct IT infrastructure is critical. When numerous, disparate application architectures co-exist and sometimes even integrate, the demands on the underlying hosting platforms can be complex and onerous. Therefore, it is common for a master specification to be created, providing a high-level overview of all forms of heterogeneity that exist within an enterprise, as well as a definition of the supporting infrastructure.
Continuing our previous analogy, an enterprise architecture specification is to an organization what an urban plan is to a city. Therefore, the relationship between an urban plan and the blueprint of a building are comparable to that of enterprise and application architecture specifications.
Typically, changes to enterprise architectures directly affect application architectures, which is why architecture specifications often are maintained by the same group of individuals. Further, enterprise architectures often contain a long-term vision of how the organization plans to evolve its technology and environments. For example, the goal of phasing out an outdated technology platform may be established in this specification.
Finally, this document also may define the technology and policies behind enterprise-wide security measures. However, these often are isolated into a separate security architecture specification.
Service-oriented architecture
Put simply, service-oriented architecture spans both enterprise and application architecture domains. The benefit potential offered by SOA can only be truly realized when applied across multiple solution environments. This is where the investment in building reusable and interoperable services based on a vendor-neutral communications platform can fully be leveraged. This does not mean that the entire enterprise must become service-oriented. SOA belongs in those areas that have the most to gain from the features and characteristics it introduces.
Note that the term "SOA" does not necessarily imply a particular architectural scope. An SOA can refer to an application architecture or the approach used to standardize technical architecture across the enterprise. Because of the composable nature of SOA (meaning that individual application-level architectures can be comprised of different extensions and technologies), it is absolutely possible for an organization to have more than one SOA.
Note that, as explained in the previous chapter, the Web services platform offers one of a number of available forms of implementation for SOA. It is the approach exclusively explored by this book, but other approaches, such as those provided by traditional distributed platforms, also exist. An important aspect of the terminology used in the upcoming sections and throughout this book is that our use of the term "SOA" implies the contemporary SOA model (based on Web services and service-orientation principles) established in Chapter 3.
4.3.2. SOA vs. client-server architecture
Just about any environment in which one piece of software requests or receives information from another can be referred to as "client-server." Pretty much every variation of application architecture that ever existed (including SOA) has an element of client-server interaction in it. However, the industry term "client-server architecture" generally refers to a particular generation of early environments during which the client and the server played specific roles and had distinct implementation characteristics.
Client-server architecture: a brief history
The original monolithic mainframe systems that empowered organizations to get seriously computerized often are considered the first inception of client-server architecture. These environments, in which bulky mainframe back-ends served thin clients, are considered an implementation of the single-tier client-server architecture (Figure 4.2).
Figure 4.2. A typical single-tier client-server architecture.
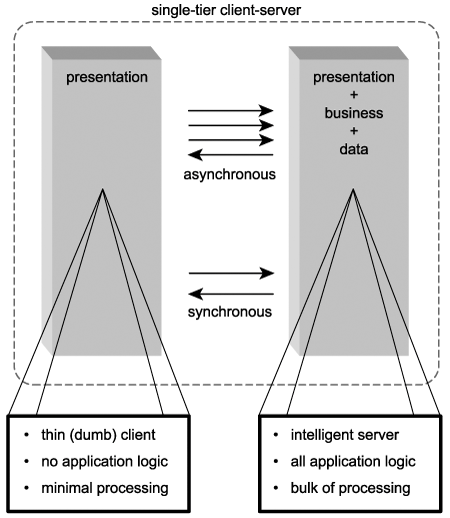
Mainframe systems natively supported both synchronous and asynchronous communication. The latter approach was used primarily to allow the server to continuously receive characters from the terminal in response to individual key-strokes. Only upon certain conditions would the server actually respond.
While its legacy still remains, the reign of the mainframe as the foremost computing platform began to decline when a two-tier variation of the client-server design emerged in the late 80s.
This new approach introduced the concept of delegating logic and processing duties onto individual workstations, resulting in the birth of the fat client. Further supported by the innovation of the graphical user-interface (GUI), two-tier client-server was considered a huge step forward and went on to dominate the IT world for years during the early 90s.
The common configuration of this architecture consisted of multiple fat clients, each with its own connection to a database on a central server. Client-side software performed the bulk of the processing, including all presentation-related and most data access logic (Figure 4.3). One or more servers facilitated these clients by hosting scalable RDBMSs.
Figure 4.3. A typical two-tier client-server architecture.
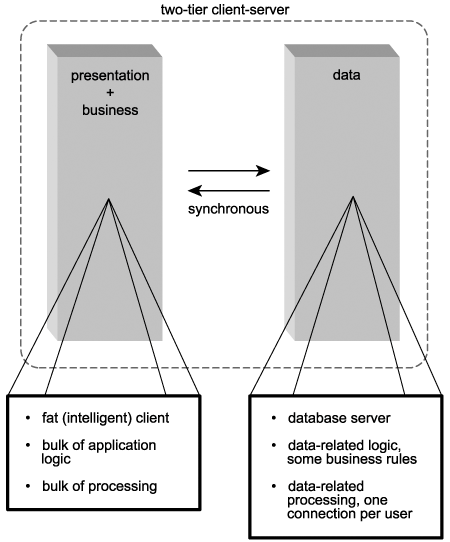
Let's look at the primary characteristics of the two-tier client-server architecture individually and compare them to the corresponding parts of SOA.
Application logic
Client-server environments place the majority of application logic into the client software. This results in a monolithic executable that controls the user experience, as well as the back-end resources. One exception is the distribution of business rules. A popular trend was to embed and maintain business rules relating to data within stored procedures and triggers on the database. This somewhat abstracted a set of business logic from the client and simplified data access programming. Overall, though, the client ran the show.
The presentation layer within contemporary service-oriented solutions can vary. Any piece of software capable of exchanging SOAP messages according to required service contracts can be classified as a service requestor. While it is commonly expected for requestors to be services as well, presentation layer designs are completely open and specific to a solution's requirements.
Within the server environment, options exist as to where application logic can reside and how it can be distributed. These options do not preclude the use of database triggers or stored procedures. However, service-oriented design principles come into play, often dictating the partitioning of processing logic into autonomous units. This facilitates specific design qualities, such as service statelessness and interoperability, as well as future composability and reusability.
Additionally, it is more common within an SOA for these units of processing logic to be solution-agnostic. This supports the ultimate goal of promoting reuse and loose coupling across application boundaries.
Application processing
Because most client-server application logic resides in the client component, the client workstation is responsible for the bulk of the processing. The 80/20 ratio often is used as a rule of thumb, with the database server typically performing twenty percent of the work. Despite that, though, it is the database that frequently becomes the performance bottleneck in these environments.
A two-tier client-server solution with a large user-base generally requires that each client establish its own database connection. Communication is predictably synchronous, and these connections are often persistent (meaning that they are generated upon user login and kept active until the user exits the application). Proprietary database connections are expensive, and the resource demands sometimes overwhelm database servers, imposing processing latency on all users.
Additionally, given that the clients are assigned the majority of processing responsibilities, they too often demand significant resources. Client-side executables are fully stateful and consume a steady chunk of PC memory. User workstations therefore often are required to run client programs exclusively so that all available resources can be offered to the application.
Processing in SOA is highly distributed. Each service has an explicit functional boundary and related resource requirements. In modeling a technical service-oriented architecture, you have many choices as to how you can position and deploy services.
Enterprise solutions consist of multiple servers, each hosting sets of Web services and supporting middleware. There is, therefore, no fixed processing ratio for SOAs. Services can be distributed as required, and performance demands are one of several factors in determining the physical deployment configuration.
Communication between service and requestor can be synchronous or asynchronous. This flexibility allows processing to be further streamlined, especially when asynchronous message patterns are utilized. Additionally, by placing a large amount of intelligence into the messages, options for achieving message-level context management are provided. This promotes the stateless and autonomous nature of services and further alleviates processing by reducing the need for runtime caching of state information.
Technology
The emergence of client-server applications promoted the use of 4GL programming languages, such as Visual Basic and PowerBuilder. These development environments took better advantage of the Windows operating system by providing the ability to create aesthetically rich and more interactive user-interfaces. Regardless, traditional 3GL languages, such as C++, were also still used, especially for solutions that had more rigid performance requirements. On the back-end, major database vendors, such as Oracle, Informix, IBM, Sybase, and Microsoft, provided robust RDBMSs that could manage multiple connections, while providing flexible data storage and data management features.
The technology set used by SOA actually has not changed as much as it has expanded. Newer versions of older programming languages, such as Visual Basic, still can be used to create Web services, and the use of relational databases still is commonplace. The technology landscape of SOA, though, has become increasingly diverse. In addition to the standard set of Web technologies (HTML, CSS, HTTP, etc.) contemporary SOA brings with it the absolute requirement that an XML data representation architecture be established, along with a SOAP messaging framework, and a service architecture comprised of the ever-expanding Web services platform.
Security
Besides the storage and management of data and the business rules embedded in stored procedures and triggers, the one other part of client-server architecture that frequently is centralized at the server level is security. Databases are sufficiently sophisticated to manage user accounts and groups and to assign these to individual parts of the physical data model.
Security also can be controlled within the client executable, especially when it relates to specific business rules that dictate the execution of application logic (such as limiting access to a part of a user-interface to select users). Additionally, operating system-level security can be incorporated to achieve a single sign-on, where application clearance is derived from the user's operating system login account information.
Though one could boast about the advantages of SOA, most architects envy the simplicity of client-server security. Corporate data is protected via a single point of authentication, establishing a single connection between client and server. In the distributed world of SOA, this is not possible. Security becomes a significant complexity directly relational to the degree of security measures required. Multiple technologies are typically involved, many of which comprise the WS-Security framework (explained in Chapters 7 and 17).
Administration
One of the main reasons the client-server era ended was the increasingly large maintenance costs associated with the distribution and maintenance of application logic across user workstations. Because each client housed the application code, each update to the application required a redistribution of the client software to all workstations. In larger environments, this resulted in a highly burdensome administration process.
Maintenance issues spanned both client and server ends. Client workstations were subject to environment-specific problems because different workstations could have different software programs installed or may have been purchased from different hardware vendors. Further, there were increased server-side demands on databases, especially when a client-server application expanded to a larger user base.
Because service-oriented solutions can have a variety of requestors, they are not necessarily immune to client-side maintenance challenges. While their distributed back-end does accommodate scalability for application and database servers, new administration demands can be introduced. For example, once SOAs evolve to a state where services are reused and become part of multiple service compositions, the management of server resources and service interfaces can require powerful administration tools, including the use of a private registry.
4.3.3. SOA vs. distributed Internet architecture
This comparison may seem like a contradiction, given that SOA can be viewed as a form of distributed Internet architecture and because we established earlier that previous types of distributed architecture also could be designed as SOAs. Though possible, and although there are distributed environments in existence that may have been heavily influenced by service-oriented principles, this variation of SOA is still a rarity. Consider the comparison provided here as one that contrasts traditional distributed Internet architecture in the manner it was most commonly designed.
Distributed Internet architecture: a brief history
In response to the costs and limitations associated with the two-tier client server architecture, the concept of building component-based applications hit the mainstream. Multi-tier client-server architectures surfaced, breaking up the monolithic client executable into components designed to varying extents of compliance with object-orientation.
Distributing application logic among multiple components (some residing on the client, others on the server) reduced deployment headaches by centralizing a greater amount of the logic on servers. Server-side components, now located on dedicated application servers, would then share and manage pools of database connections, alleviating the burden of concurrent usage on the database server (Figure 4.4). A single connection could easily facilitate multiple users.
Figure 4.4. A typical multi-tier client-server architecture.
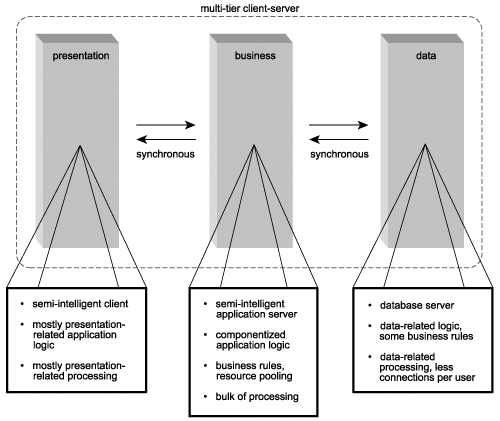
These benefits came at the cost of increased complexity and ended up shifting expense and effort from deployment issues to development and administration processes. Building components capable of processing multiple, concurrent requests was more difficult and problem-ridden than developing a straight-forward executable intended for a single user.
Additionally, replacing client-server database connections was the client-server remote procedure call (RPC) connection. RPC technologies such as CORBA and DCOM allowed for remote communication between components residing on client workstations and servers. Issues similar to the client-server architecture problems involving resources and persistent connections emerged. Adding to this was an increased maintenance effort resulting from the introduction of the middleware layer. For example, application servers and transaction monitors required significant attention in larger environments.
Upon the arrival of the World Wide Web as a viable medium for computing technology in the mid-to-late 90s, the multi-tiered client-server environments began incorporating Internet technology. Most significant was the replacement of the custom software client component with the browser. Not only did this change radically alter (and limit) user-interface design, it practically shifted 100% of application logic to the server (Figure 4.5).
Figure 4.5. A typical distributed Internet architecture.
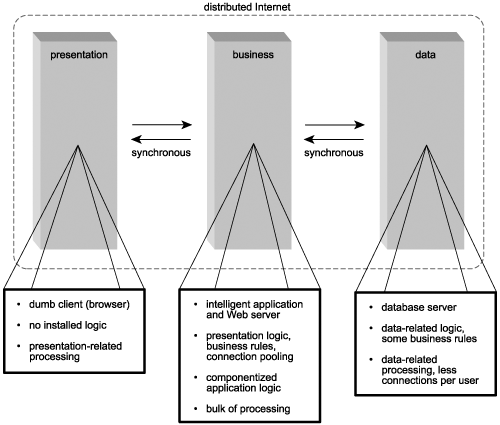
Distributed Internet architecture also introduced a new physical tier, the Web server. This resulted in HTTP replacing proprietary RPC protocols used to communicate between the user's workstation and the server. The role of RPC was limited to enabling communication between remote Web and application servers.
From the late 90s to the mid 2000s, distributed Internet architectures represented the de facto computing platform for custom developed enterprise solutions. The commoditization of component-based programming skills and the increasing sophistication of middleware eventually lessened some of the overall complexity.
How then, does this popular and familiar architecture compare with SOA? The following sections contrast distributed Internet architecture and SOA characteristics.
Note
Although multi-tier client-server is a distinct architecture in its own right, we do not provide a direct comparison between it and SOA. Most of the issues raised in the client-server and the distributed Internet architecture comparisons cover those that would be discussed in a comparison between multi-tier client-server and SOA.
Application logic
Except for some rare applications that embed proprietary extensions in browsers, distributed Internet applications place all of their application logic on the server side. Even client-side scripts intended to execute in response to events on a Web page are downloaded from the Web server upon the initial HTTP request. With none of the logic existing on the client workstation, the entire solution is centralized.
The emphasis is therefore on:
- how application logic should be partitioned
- where the partitioned units of processing logic should reside
- how the units of processing logic should interact
From a physical perspective, service-oriented architecture is very similar to distributed Internet architecture. Provider logic resides on the server end where it is broken down into separate units. The differences lie in the principles used to determine the three primary design considerations just listed.
Traditional distributed applications consist of a series of components that reside on one or more application servers. Components are designed with varying degrees of functional granularity, depending on the tasks they execute, and to what extent they are considered reusable by other tasks or applications. Components residing on the same server communicate via proprietary APIs, as per the public interfaces they expose. RPC protocols are used to accomplish the same communication across server boundaries. This is made possible through the use of local proxy stubs that represent components in remote locations (Figure 4.6).
Figure 4.6. Components rely on proxy stubs for remote communication.
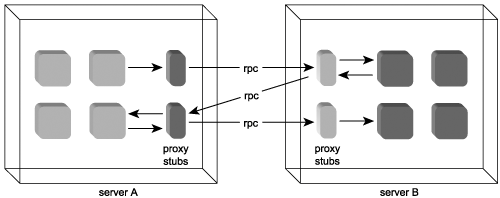
At design time, the expected interaction components will have with others is taken into accountso much so that actual references to other physical components can be embedded within the programming code. This level of design-time dependence is a form of tight-coupling. It is efficient in that little processing is wasted in trying to locate a required component at runtime. However, the embedded coupling leads to a tightly bound component network that, once implemented, is not easily altered.
Contemporary SOAs still employ and rely on components. However, the entire modeling approach now takes into consideration the creation of services that encapsulate some or all of these components. These services are designed according to service-orientation principles and are strategically positioned to expose specific sets of functionality. While this functionality can be provided by components, it also can originate from legacy systems and other sources, such as adapters interfacing with packaged software products, or even databases.
The purpose of wrapping functionality within a service is to expose that functionality via an open, standardized interfaceirrespective of the technology used to implement the underlying logic. The standardized interface supports the open communications framework that sits at the core of SOA. Further, the use of Web services establishes a loosely coupled environment that runs contrary to many traditional distributed application designs. When properly designed, loosely coupled services support a composition model, allowing individual services to participate in aggregate assemblies. This introduces continual opportunities for reuse and extensibility.
Another significant shift related to the design and behavior of distributed application logic is in how services exchange information. While traditional components provide methods that, once invoked, send and receive parameter data, Web services communicate with SOAP messages. Even though SOAP supports RPC-style message structures, the majority of service-oriented Web service designs rely on document-style messages. (This important distinction is explored in subsequent chapters.)
Also messages are structured to be as self-sufficient as possible. Through the use of SOAP headers, message contents can be accompanied by a wide range of meta information, processing instructions, and policy rules. In comparison to data exchange in the pure component world, the messaging framework used by SOA is more sophisticated, bulkier, and tends to result in less individual transmissions.
Finally, although reuse is also commonly emphasized in traditional distributed design approaches, SOA fosters reuse and cross-application interoperability on a deep level by promoting the creation of solution-agnostic services.
Application processing
Regardless of platform, components represent the lion's share of application logic and are therefore responsible for most of the processing. However, because the technology used for inter-component communication differs from the technology used to accomplish inter-service communication, so do the processing requirements.
Distributed Internet architecture promotes the use of proprietary communication protocols, such as DCOM and vendor implementations of CORBA for remote data exchange. While these technologies historically have had challenges, they are considered relatively efficient and reliable, especially once an active connection is made. They can support the creation of stateful and stateless components that primarily interact with synchronous data exchanges (asynchronous communication is supported by some platforms but not commonly used).
SOA, on the other hand, relies on message-based communication. This involves the serialization, transmission, and deserialization of SOAP messages containing XML document payloads. Processing steps can involve the conversion of relational data into an XML-compliant structure, the validation of the XML document prior and subsequent to transmission, and the parsing of the document and extraction of the data by the recipient. Although advancements, such as the use of enterprise parsers and hardware accelerators are on-going, most still rank RPC communication as being noticeably faster than SOAP.
Because a network of SOAP servers can effectively replace RPC-style communication channels within service-oriented application environments, the incurred processing overhead becomes a significant design issue. Document and message modeling conventions and the strategic placement of validation logic are important factors that shape the transport layer of service-oriented architecture.
This messaging framework promotes the creation of autonomous services that support a wide range of message exchange patterns. Though synchronous communication is fully supported, asynchronous patterns are encouraged, as they provide further opportunities to optimize processing by minimizing communication. Further supporting the statelessness of services are various context management options that can be employed, including the use of WS-* specifications, such as WS-Coordination and WS-BPEL, as well as custom solutions.
Technology
The technology behind distributed Internet architecture went through a number of stages over the past few years. Initial architectures consisted of components, server-side scripts, and raw Web technologies, such as HTML and HTTP. Improvements in middleware allowed for increased processing power and transaction control. The emergence of XML introduced sophisticated data representation that actually gave substance to content transmitted via Internet protocols. The subsequent availability of Web services allowed distributed Internet applications to cross proprietary platform boundaries.
Because many current distributed applications use XML and Web services, there may be little difference between the technology behind these solutions and those based on SOA. One clear distinction, though, is that a contemporary SOA will most likely be built upon XML data representation and the Web services technology platform. Beyond a core set of Internet technologies and the use of components, there is no governance of the technology used by traditional Internet applications. Thus XML and Web services are optional for distributed Internet architecture but not for contemporary SOA.
Security
When application logic is strewn across multiple physical boundaries, implementing fundamental security measures such as authentication and authorization becomes more difficult.
In a two-tiered client-server environment, an exclusive server-side connection easily facilitates the identification of users and the safe transportation of corporate data. However, when the exclusivity of that connection is removed, and when data is required to travel across different physical layers, new approaches to security are needed. To ensure the safe transportation of information and the recognition of user credentials, while preserving the original security context, traditional security architectures incorporate approaches such as delegation and impersonation. Encryption also is added to the otherwise wide open HTTP protocol to allow data to be protected during transmission beyond the Web server.
SOAs depart from this model by introducing wholesale changes to how security is incorporated and applied. Relying heavily on the extensions and concepts established by the WS-Security framework, the security models used within SOA emphasize the placement of security logic onto the messaging level. SOAP messages provide header blocks in which security logic can be stored. That way, wherever the message goes, so does its security information. This approach is required to preserve individual autonomy and loose coupling between services, as well as the extent to which a service can remain fully stateless.
Administration
Maintaining component-based applications involves keeping track of individual component instances, tracing local and remote communication problems, monitoring server resource demands, and, of course, the standard database administration tasks. Distributed Internet architecture further introduces the Web server and with it an additional physical environment that requires attention while solutions are in operation. Because clients, whether local or external to an organization, connect to these solutions using HTTP, the Web server becomes the official first point of contact. It must therefore be designed for scalabilitya requirement that has led to the creation of Web server farms that pool resources.
Enterprise-level SOAs typically require additional runtime administration. Problems with messaging frameworks (especially when working with asynchronous exchange patterns) can more easily go undetected than with RPC-based data exchanges. This is because so many variations exist as to how messages can be interchanged. RPC communication generally requires a response from the initiating component, indicating success or failure. Upon encountering a failure condition, an exception handling routine kicks in. Exception handling with messaging frameworks can be more complex and less robust. Although WS-* extensions are being positioned to better deal with these situations, administration effort is still expected to remain high.
Other maintenance tasks, such as resource management (similar to component management), are also required. However, to best foster reuse and composability, a useful part of an administration infrastructure for enterprises building large amounts of Web services is a private registry. UDDI is one of the technologies used for standardizing this interface repository, which can be manually or programmatically accessed to discover service descriptions.
4.3.4. SOA vs. hybrid Web service architecture
In the previous section we mentioned how more recent variations of the distributed Internet architecture have come to incorporate Web services. This topic is worth elaborating upon because it has been (and is expected to continue to be) at the root of some confusion surrounding SOA.
First, the use of Web services within traditional architectures is completely legitimate. Due to the development support for Web services in many established programming languages, they easily can be positioned to fit in with older application designs. And, for those legacy environments that do not support the custom development of Web services, adapters are often available.
Note
Although we are focusing on distributed Internet architecture here, there are no restrictions for two-tier client-server applications to be outfitted with Web services.
Web services as component wrappers
The primary role of Web services in this context has been to introduce an integration layer that consists of wrapper services that enable synchronous communication via SOAP-compliant integration channels (Figure 4.7). In fact, the initial release of the SOAP specification and the first generation of SOAP servers were specifically designed to duplicate RPC-style communication using messages.
Figure 4.7. Wrapper services encapsulating components.
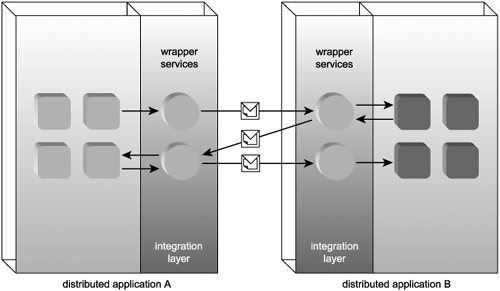
These integration channels are primarily utilized in integration architectures to facilitate communication with other applications or outside partners. They also are used to enable communication with other (more service-oriented) solutions and to take advantage of some of the features offered by third-party utility Web services. Regardless of their use or purpose within traditional architectures, it is important to clarify that a distributed Internet architecture that incorporates Web services in this manner does not qualify as a true SOA. It is simply a distributed Internet architecture that uses Web services.
Instead of mirroring component interfaces and establishing point-to-point connections with Web services, SOA provides strong support for a variety of messaging models (based on both synchronous and asynchronous exchanges). Additionally, Web services within SOAs are subject to specific design requirements, such as those provided by service-orientation principles. These and other characteristics support the pursuit of consistent loose coupling. Once achieved, a single service is never limited to point-to-point communication; it can accommodate any number of current and future requestors.
Web services within SOA
While SOAs can vary in size and quality, there are tangible characteristics that distinguish an SOA from other architectures that use Web services. Much of this book is dedicated to exploring these characteristics. For now it is sufficient to state that fundamentally, SOAs are built with a set of Web services designed to collectively automate (or participate in the automation of) one or more business processesand that SOA promotes the organization of these services into specialized layers that abstract specific parts of enterprise automation logic.
Also by standardizing on SOA across an enterprise, a natural interoperability emerges that transcends proprietary application platforms. This allows for previously disparate environments to be composed in support of new and evolving business automation processes.
4.3.5. Service-orientation and object-orientation (Part I)
Note that this section title is "Service-orientation and object-orientation," as opposed to "Service-orientation vs. object-orientation." That distinction was made to stress the fact that the relationship between these two schools of thought is not necessarily a competitive one.
In fact, object-oriented programming is commonly used to build the application logic encapsulated within Web services. However, how the object-oriented programming methodology differs fundamentally from service-orientation is worth exploring. An understanding of their differences will help you make them work together.
Below is a list comparing aspects of these design approaches. (Whereas service-orientation is based on the design of services, object-orientation is centered around the creation of objects. Because comparing services to objects can be confusing, the term "units of processing logic" is used.)
- Service-orientation emphasizes loose coupling between units of processing logic (services). Although object-orientation supports the creation of reusable, loosely coupled programming routines, much of it is based on predefined class dependencies, resulting in more tightly bound units of processing logic (objects).
- Service-orientation encourages coarse-grained interfaces (service descriptions) so that every unit of communication (message) contains as much information as possible for the completion of a given task. Object-oriented programming fully supports fine-grained interfaces (APIs) so that units of communication (RPC or local API calls) can perform various sized tasks.
- Service-orientation expects the scope of a unit of processing logic (service) to vary significantly. Object-oriented units of logic (objects) tend to be smaller and more specific in scope.
- Service-orientation promotes the creation of activity-agnostic units of processing logic (services) that are driven into action by intelligent units of communication (messages). Object-orientation encourages the binding of processing logic with data, resulting in highly intelligent units (objects).
- Service-orientation prefers that units of processing logic (services) be designed to remain as stateless as possible. Object-orientation promotes the binding of data and logic, resulting in the creation of more stateful units (objects). (However, more recent component-based design approaches deviate from this tendency.)
- Service-orientation supports the composition of loosely coupled units of processing logic (services). Object-orientation supports composition but also encourages inheritance among units of processing logic (objects), which can lead to tightly coupled dependencies.
You may have noticed that we avoided referencing specific object-orientation principles, such as encapsulation, inheritance, and aggregation. Because we have not yet fully described the principles of service-orientation, we cannot compare the respective paradigms on this level. Chapter 8 explains the individual service-orientation principles in detail and then continues this discussion in the Service-orientation and object-orientation (Part II) section.
|
SUMMARY OF KEY POINTS |
|---|
|
Introduction
- Why this book is important
- Objectives of this book
- Who this book is for
- What this book does not cover
- How this book is organized
- Additional information
Case Studies
- Case Studies
- How case studies are used
- Case #1 background: RailCo Ltd.
- Case #2 background: Transit Line Systems Inc.
Part I: SOA and Web Services Fundamentals
Introducing SOA
- Introducing SOA
- Fundamental SOA
- Common characteristics of contemporary SOA
- Common misperceptions about SOA
- Common tangible benefits of SOA
- Common pitfalls of adopting SOA
The Evolution of SOA
- The Evolution of SOA
- An SOA timeline (from XML to Web services to SOA)
- The continuing evolution of SOA (standards organizations and contributing vendors)
- The roots of SOA (comparing SOA to past architectures)
Web Services and Primitive SOA
- Web Services and Primitive SOA
- The Web services framework
- Services (as Web services)
- Service descriptions (with WSDL)
- Messaging (with SOAP)
Part II: SOA and WS-* Extensions
Web Services and Contemporary SOA (Part I: Activity Management and Composition)
- Web Services and Contemporary SOA (Part I: Activity Management and Composition)
- Message exchange patterns
- Service activity
- Coordination
- Atomic transactions
- Business activities
- Orchestration
- Choreography
Web Services and Contemporary SOA (Part II: Advanced Messaging, Metadata, and Security)
- Web Services and Contemporary SOA (Part II: Advanced Messaging, Metadata, and Security)
- Addressing
- Reliable messaging
- Correlation
- Policies
- Metadata exchange
- Security
- Notification and eventing
Part III: SOA and Service-Orientation
Principles of Service-Orientation
- Principles of Service-Orientation
- Service-orientation and the enterprise
- Anatomy of a service-oriented architecture
- Common principles of service-orientation
- How service-orientation principles inter-relate
- Service-orientation and object-orientation (Part II)
- Native Web service support for service-orientation principles
Service Layers
- Service Layers
- Service-orientation and contemporary SOA
- Service layer abstraction
- Application service layer
- Business service layer
- Orchestration service layer
- Agnostic services
- Service layer configuration scenarios
Part IV: Building SOA (Planning and Analysis)
SOA Delivery Strategies
- SOA Delivery Strategies
- SOA delivery lifecycle phases
- The top-down strategy
- The bottom-up strategy
- The agile strategy
Service-Oriented Analysis (Part I: Introduction)
- Service-Oriented Analysis (Part I: Introduction)
- Service-oriented architecture vs. Service-oriented environment
- Introduction to service-oriented analysis
- Benefits of a business-centric SOA
- Deriving business services
Service-Oriented Analysis (Part II: Service Modeling)
- Service-Oriented Analysis (Part II: Service Modeling)
- Service modeling (a step-by-step process)
- Service modeling guidelines
- Classifying service model logic
- Contrasting service modeling approaches (an example)
Part V: Building SOA (Technology and Design)
Service-Oriented Design (Part I: Introduction)
- Service-Oriented Design (Part I: Introduction)
- Introduction to service-oriented design
- WSDL-related XML Schema language basics
- WSDL language basics
- SOAP language basics
- Service interface design tools
Service-Oriented Design (Part II: SOA Composition Guidelines)
- Service-Oriented Design (Part II: SOA Composition Guidelines)
- Steps to composing SOA
- Considerations for choosing service layers
- Considerations for positioning core SOA standards
- Considerations for choosing SOA extensions
Service-Oriented Design (Part III: Service Design)
- Service-Oriented Design (Part III: Service Design)
- Service design overview
- Entity-centric business service design (a step-by-step process)
- Application service design (a step-by-step process)
- Task-centric business service design (a step-by-step process)
- Service design guidelines
Service-Oriented Design (Part IV: Business Process Design)
- Service-Oriented Design (Part IV: Business Process Design)
- WS-BPEL language basics
- WS-Coordination overview
- Service-oriented business process design (a step-by-step process)
Fundamental WS-* Extensions
- Fundamental WS-* Extensions
- You mustUnderstand this
- WS-Addressing language basics
- WS-ReliableMessaging language basics
- WS-Policy language basics
- WS-MetadataExchange language basics
- WS-Security language basics
SOA Platforms
Appendix A. Case Studies: Conclusion
EAN: 2147483647
Pages: 150
