Access Control
The information security professional should be aware of access control requirements and their means of implementation to ensure a system’s confidentiality, integrity, and availability. In the world of networked computers, this professional should understand the use of access control in distributed as well as centralized architectures.
The professional should also understand the threats, vulnerabilities, and risks associated with the information system’s infrastructure and the preventive and detective measures that are available to counter them. In addition, the InfoSec professional should understand the application of penetration testing tools and intrusion detection systems.
Rationale
Controlling access to information systems and associated networks is necessary for the preservation of their confidentiality, integrity, and availability. Confidentiality ensures that the information is not disclosed to unauthorized persons or processes. We address integrity through the following three goals:
- Prevention of the modification of information by unauthorized users
- Prevention of the unauthorized or unintentional modification of information by authorized users
- Preservation of the internal and external consistency of information:
- Internal consistency ensures that internal data is consistent. For example, assume that an internal database holds the number of units of a particular item in each department of an organization. The sum of the number of units in each department should equal the total number of units that the database has recorded internally for the whole organization.
- External consistency ensures that the data stored in the database is consistent with the real world. Using the example previously discussed in (a), external consistency means that the number of items recorded in the database for each department is equal to the number of items that physically exist in that department.
Availability ensures that a system’s authorized users have timely and uninterrupted access to the information in the system. The additional access control objectives are reliability and utility.
These and other related objectives flow from the organizational security policy. This policy is a high-level statement of management intent regarding the control of access to information and the personnel who are authorized to receive that information.
Three things that you must consider for the planning and implementation of access control mechanisms are the threats to the system, the system’s vulnerability to these threats, and the risk that the threats might materialize. We further define these concepts as follows:
- Threat. An event or activity that has the potential to cause harm to the information systems or networks
- Vulnerability. A weakness or lack of a safeguard that can be exploited by a threat, causing harm to the information systems or networks
- Risk. The potential for harm or loss to an information system or network; the probability that a threat will materialize
Controls
Controls are implemented to mitigate risk and reduce the potential for loss. Controls can be preventive, detective, or corrective. Preventive controls are put in place to inhibit harmful occurrences; detective controls are established to discover harmful occurrences; and corrective controls are used to restore systems that are victims of harmful attacks.
Two important control concepts are the separation of duties and the principle of least privilege. Separation of duties requires that an activity or process has to be performed by two or more entities for successful completion. Thus, the only way that a security policy can be violated is if there is collusion among the entities. For example, in a financial environment, the person requesting that a check be issued for payment should not also be the person who has authority to sign the check. In least privilege, the entity that has a task to perform should be provided with the minimum resources and privileges required to complete the task for the minimum necessary period of time.
Control measures can be administrative, logical or technical, and physical in their implementation.
- Administrative controls include policies and procedures, security awareness training, background checks, work habit checks, a review of vacation history, and increased supervision.
- Logical or technical controls involve the restriction of access to systems and the protection of information. Examples of these types of controls are encryption, smart cards, access control lists, and transmission protocols.
- Physical controls incorporate guards and building security in general, such as the locking of doors, the securing of server rooms or laptops, the protection of cables, the separation of duties, and the backing up of files.
Controls provide accountability for individuals who are accessing sensitive information. This accountability is accomplished through access control mechanisms that require identification and authentication and through the audit function. These controls must be in accordance with and accurately represent the organization’s security policy. Assurance procedures ensure that the control mechanisms correctly implement the security policy for the entire life cycle of an information system.
In general, a group of processes that share access to the same resources is called a protection domain, and the memory space of these processes is isolated from other running processes.
Models for Controlling Access
Controlling access by a subject (an active entity such as an individual or process) to an object (a passive entity such as a file) involves setting up access rules. These rules can be classified into three categories or models:
- Mandatory Access Control. The authorization of a subject’s access to an object depends upon labels that indicate the subject’s clearance and the classification or sensitivity of the object. For example, the military classifies documents as unclassified, confidential, secret, and top secret. Similarly, an individual can receive a clearance of confidential, secret, or top secret and can have access to documents classified at or below his or her specified clearance level. Thus, an individual with a clearance of “secret” can have access to secret and confidential documents, with a restriction. This restriction is that the individual must have a need to know relative to the classified documents involved. Therefore, the documents must be necessary for that individual to complete an assigned task. Even if the individual is cleared for a classification level of information, the individual should not access the information unless there is a need to know. Rule-based access control is a type of mandatory access control, because rules determine this access (such as the correspondence of clearance labels to classification labels), rather than the identities of the subjects and objects alone.
- Discretionary Access Control. The subject has authority, within certain limitations, to specify what objects are accessible. For example, access control lists can be used. An access control list (ACL) is a list denoting which users have what privileges to a particular resource. For example, a tabular listing would show the subjects or users who have access to the object, FILE X, and what privileges they have with respect to that file. An access control triple consists of the user, the program, and the file, with the corresponding access privileges noted for each user. This type of access control is used in local, dynamic situations where the subjects must have the discretion to specify what resources certain users are permitted to access. When a user within certain limitations has the right to alter the access control to certain objects, this is termed user-directed discretionary access control. An identity-based access control is a type of discretionary access control based on an individual’s identity. In some instances, a hybrid approach is used that combines the features of user-based and identity-based discretionary access control.
- Non-Discretionary Access Control. A central authority determines which subjects can have access to certain objects based on the organizational security policy. The access controls might be based on the individual’s role in the organization (role-based) or the subject’s responsibilities and duties (task-based). In an organization where there are frequent personnel changes, non-discretionary access control is useful because the access controls are based on the individual’s role or title within the organization. These access controls do not need to be changed whenever a new person takes over that role. Another type of non-discretionary access control is lattice-based access control. In this type of control, a lattice model is applied. In a lattice model, there are pairs of elements that have the least upper bound of values and greatest lower bound of values. To apply this concept to access control, the pair of elements is the subject and object, and the subject has the greatest lower bound and the least upper bound of access rights to an object.
- Access control can also be characterized as context-dependent or content-dependent. Context-dependent access control is a function of factors such as location, time of day, and previous access history. It is concerned with the environment or context of the data. In content-dependent access control, access is determined by the information contained in the item being accessed.
Control Combinations
By combining preventive and detective control types with administrative, technical (logical), and physical means of implementation, the following pairings are obtained:
- Preventive/administrative
- Preventive/technical
- Preventive/physical
- Detective/administrative
- Detective/technical
- Detective/physical
Next, we discuss these six pairings and the key elements that are associated with their control mechanisms.
Preventive/Administrative
In this pairing, we place emphasis on “soft” mechanisms that support the access control objectives. These mechanisms include organizational policies and procedures, pre-employment background checks, strict hiring practices, employment agreements, friendly and unfriendly employee termination procedures, vacation scheduling, labeling of sensitive materials, increased supervision, security awareness training, behavior awareness, and sign-up procedures to obtain access to information systems and networks.
Preventive/Technical
The preventive/technical pairing uses technology to enforce access control policies. These technical controls are also known as logical controls and can be built into the operating system, can be software applications, or can be supplemental hardware/software units. Some typical preventive/technical controls are protocols, encryption, smart cards, biometrics (for authentication), local and remote access control software packages, callback systems, passwords, constrained user interfaces, menus, shells, database views, limited keypads, and virus scanning software. Protocols, encryption, and smart cards are technical mechanisms for protecting information and passwords from disclosure. Biometrics methods apply technologies such as fingerprint, retina, and iris scans to authenticate individuals requesting access to resources, and access control software packages manage access to resources holding information from subjects local to the information system or from those at remote locations. Callback systems provide access protection by calling back the number of a previously authorized location, but this control can be compromised by call forwarding. Constrained user interfaces limit the functions that a user can select; for example, some functions may be “grayed-out” on the user menu and cannot be chosen. Shells limit the system-level commands that an individual or process can use. Database views are mechanisms that restrict the information that a user can access in a database. Limited keypads have a small number of keys that the user can select, and the functions that are intended not to be accessible by the user are not represented on any of the available keys.
Preventive/Physical
Many preventive/physical measures are intuitive. These measures are intended to restrict the physical access to areas with systems holding sensitive information. A circular security perimeter that is under access control defines the area or zone to be protected. Preventive/physical controls include fences, badges, multiple doors (placed one after the other so that an individual can be “trapped” in the space between the doors after entering one of them), magnetic card entry systems, biometrics (for identification), guards, dogs, environmental control systems (temperature, humidity, and so forth), and building and access area layout. Preventive/physical measures also apply to areas that are used for storage of the backup data files.
Detective/Administrative
Several detective/administrative controls overlap with preventive/administrative controls; that is, they can be applied to preventing future security policy violations or to detecting existing violations. Examples of such controls are organizational policies and procedures, background checks, vacation scheduling, the labeling of sensitive materials, increased supervision, security awareness training, and behavior awareness. Additional detective/administrative controls are job rotation, the sharing of responsibilities, and reviews of audit records.
Detective/Technical
The detective/technical control measures are intended to reveal violations of security policy by using technical means. These measures include intrusion detection systems and automatically generated violation reports from audit trail information. These reports can indicate variations from “normal” operation or detect known signatures of unauthorized access episodes. In order to limit the amount of audit information flagged and reported by automated violation analysis and reporting mechanisms, clipping levels can be set. Clipping levels are preset allowable thresholds on a reported activity. For example, if a clipping level of 3 is set for reporting failed logon attempts at a workstation, three or fewer logon attempts by an individual at a workstation would not be reported as a violation, thus eliminating the need for reviewing normal logon entry errors.
Due to the importance of the audit information, audit records should be protected at the highest level of sensitivity in the system.
Detective/Physical
Detective/physical controls usually require a human to evaluate the input from sensors or cameras to determine whether a real threat exists. Some of these control types are motion detectors, thermal detectors, and video cameras.
Access Control Attacks
It is important for the information security professional to understand and identify the different types of access control attacks. These attacks are summarized in the following sections.
Denial of Service Distributed Denial of Service (DoS DDoS)
A denial of service (DoS) attack targets availability by consuming an information system’s resources to the point where it cannot handle authorized transactions. A distributed DoS attack on a computing resource is launched from a number of other host machines. Attack software is usually installed on a large number of host computers, unbeknownst to their owners, and then activated simultaneously to launch communications to the target machine of such magnitude as to overwhelm the target machine.
Specific examples of DoS attacks are:
- Buffer Overflow. A process receives much more data than expected. If the process has no programmed routine to deal with this excessive amount of data, it acts in an unexpected way that the intruder can exploit. In some cases, malicious code contained in the overflow data can be executed and used to gain administrative privileges on an information system. A Ping of Death exploits the Internet Control Message Protocol (ICMP), which is used to determine whether there is a connection path to a remote site and whether there are network transmission problems. In this attack, an ECHO packet larger than the Internet Protocol (IP) specification of 65,535 bytes is sent. This illegal ECHO packet can cause an overflow of system buffers and lead to a system crash.
- SYN Attack. In this attack, an attacker exploits the use of the buffer space during a Transmission Control Protocol (TCP) session initialization handshake. The attacker floods the target system’s small in-process queue with large numbers of SYN (Synchronization) connection requests but does not respond with the required ACK message when a target system replies to those requests with SYN/ACK messages. This causes the target system to time out while waiting for the proper response, which makes the system crash or become unusable.
- Teardrop Attack. The length and fragmentation offset fields in sequential IP packets are modified. The target system then becomes confused and crashes after it receives contradictory instructions on how the fragments are offset on these packets.
- Smurf. This attack involves IP spoofing (discussed in a subsequent section) and ICMP to saturate a target network with traffic, thereby launching a DoS attack. It consists of three elements - the source site, the bounce site, and the target site. The attacker (the source site) sends a spoofed ping packet to the broadcast address of a large network (the bounce site). This modified packet contains the address of the target site as the source of the message. This causes the bounce site to broadcast the misinformation to all the devices on its local network. All these devices now respond with a reply to the target system, which is then saturated with those replies.
Back Door
A backdoor attack takes place using dial-up modems or asynchronous external connections. The strategy is to gain access to a network through bypassing of control mechanisms.
Spoofing
The term spoofing comes up often in any discussion of security. Literally, spoofing refers to an attacker deliberately inducing a user (subject) or device (object) into taking an incorrect action by giving it false information that imitates (“spoofs”) legitimate information. Intruders use IP spoofing to convince a system that it is communicating with a known, trusted entity in order to provide the intruder with access to the system. IP spoofing involves an alteration of a packet at the TCP level in order to attack Internet-connected systems that provide various TCP/IP services. The attacker sends a packet with an IP source address of a known, trusted host instead of its own IP source address to a target host. The target host may accept the packet and act upon it.
Man in the Middle
The man-in-the-middle attack involves an attacker, A, substituting his or her public key for that of another person, P. Then, anyone desiring to send an encrypted message to P using P’s public key is unknowingly using A’s public key instead. Therefore, A can read the message intended for P. A can then send the message on to P, encrypted in P’s real public key, and P will never be the wiser. Obviously, A could modify the message before resending it to P.
Replay
The replay attack occurs when an attacker intercepts and saves old messages and then tries to send them later, impersonating one of the participants. One method of making this attack more difficult to accomplish is through the use of a random number or string called a nonce. If Bob wants to communicate with Alice, he sends a nonce along with the first message to Alice. When Alice replies, she sends the nonce back to Bob, who verifies that it is the one he sent with the first message. Then Bob changes his nonce. Anyone trying to use these same messages later will not be using the newer nonce. Another approach to countering the replay attack is for Bob to add a timestamp to his message. This timestamp indicates the time that the message was sent. Thus, if the message is used later, the timestamp will show that an old message is being used.
TCP Hijacking
As an example of this type of attack, an attacker hijacks a session between a trusted client and network server. The attacking computer substitutes its IP address for that of the trusted client, and the server continues the dialog believing it is communicating with the trusted client. Simply stated, the steps in this attack are as follows:
- Trusted client connects to network server.
- Attack computer gains control of trusted client.
- Attack computer disconnects trusted client from network server.
- Attack computer replaces the IP address of trusted client with its own IP address and spoofs the client’s sequence numbers.
- Attack computer continues dialog with network server. (Network server believes it is still communicating with trusted client.)
Social Engineering
This attack uses social skills to obtain information such as passwords or personal identification numbers (PINs) to be used against information systems. For example, an attacker may impersonate someone in an organization and make phone calls to employees of that organization requesting passwords for use in maintenance operations. The following are additional examples of social engineering attacks:
- E-mails to employees from a cracker requesting their passwords to validate the organizational database after a network intrusion has occurred.
- E-mails to employees from a cracker requesting their passwords because work has to be done over the weekend on the system.
- E-mail or phone call from a cracker impersonating an official who is conducting an investigation for the organization and requires passwords for the investigation.
- Improper release of medical information to individuals posing as doctors and requesting data from patients’ records.
- A computer repair technician convinces a user that the hard disk on his or her PC is damaged and irreparable and installs a new hard disk for the user. The technician then takes the hard disk, extracts the information, and sells the information to a competitor or foreign government.
The best defense against social engineering attacks is an information security policy addressing such attacks and educating the users about these types of attacks.
Dumpster Diving
Dumpster diving involves the acquisition of information from paper documents that have been discarded by an individual or organization. In many cases, information found in trash can be very valuable to a cracker. Discarded information may include technical manuals, password lists, telephone numbers, and organization charts. It is important to note that one requirement for information to be treated as a trade secret is that the information be protected and not revealed to any unauthorized individuals. If a document containing an organization’s trade secret information is inadvertently discarded and found in the trash by another person, the other person can use that information, since it was not adequately protected by the organization.
Password Guessing
Because passwords are the most commonly used mechanism to authenticate users to an information system, obtaining passwords is a common and effective attack approach. Gaining access to a person’s password can be obtained by physically looking around the person’s desk for notes with the password, “sniffing” the connection to the network to acquire unencrypted passwords, social engineering, gaining access to a password database, or outright guessing. The last approach can be done in a random or systematic manner.
An effective means to prevent password guessing is to place a limit on the number of user attempts to enter a password. For example, a limit could be set such that a user is “locked out” of a system for a period of time after three unsuccessful tries at entering the password. An interesting situation to consider in employing this type of control is the consequences of its use in a critical application such as a Supervisory Control and Data Acquisition (SCADA) System. SCADA systems are used to run real-time processes such as oil refineries, nuclear power stations, and chemical plants. Consider the consequences of a panicked operator trying to respond to an emergency in the plant, typing in his or her password incorrectly a number of times, and then being locked out of the system. Clearly, the lockout approach should be carefully evaluated before being applied to systems requiring rapid operator responses.
Brute Force
Brute force password guessing means just that: trying a random approach by attempting different passwords and hoping that one works. Some logic can be applied by trying passwords related to the person’s name, job title, hobbies, or other similar items.
Dictionary Attack
A dictionary attack is one in which a dictionary of common passwords is used in an attempt to gain access to a user’s computer and network. One approach is to copy an encrypted file that contains passwords and, applying the same encryption to a dictionary of commonly used passwords, compare the results. A specific example of this approach is the LC4 password auditing and recovery tool, which performs the encrypted file comparison against a dictionary of over 250,000 possible passwords.
Software Exploitation
Vulnerabilities in software can be exploited to gain unauthorized access to information systems’ resources and data. Some examples of software exploitation are:
- Novell Web Server. An attacker can cause a DoS buffer overflow by sending a large GET request to the remote administration port. This causes the data being sent to overflow the storage buffer and reside in memory as executable code.
- AIX Operating System. Passwords can be exposed by diagnostic commands.
- IRIX Operating System. A buffer overflow vulnerability enables an attacker to gain root access.
- Windows 9x. A vulnerability enables an attacker to locate system and screensaver passwords, thereby providing the attacker with means to gain unauthorized logon access.
- Windows NT. Privilege exploitation software used by attacker can gain administrative access to the operating system.
- Windows XP. TCP/IP vulnerabilities in Windows XP can allow remote users to take control of the computer. This vulnerability can be addressed by turning on the XP personal firewall.
Mobile Code
Mobile code is software that is received and executed on an information system from a remote source over a network. This transfer of code can be accomplished with or without actions from the user. Mobile code can perform useful functions or malicious actions. As an example of the latter, Java applets downloaded from a remote source and executed in the user’s Web browser can, under some circumstances, search the local hard drive and obtain sensitive information. The downloaded code might also contain viruses that can attack the local system.
Trojan Horses
Trojan horses, or Trojans, hide malicious code inside a host program that seems to do something useful. Once these programs are executed, the virus, worm, or other type of malicious code hidden in the Trojan horse program is released to attack the workstation, server, or network or to allow unauthorized access to those devices. Trojans are common tools used to create back doors into the network for later exploitation by crackers.
Trojan horses can be carried via Internet traffic such as FTP downloads or downloadable applets from Web sites, or distributed through e-mail.
Common Trojan horses and ports are:
- Trinoo: ports 1524, 27444, 27665, 31335
- Back Orifice: port 31337
- NetBus: port 12345
- SubSeven: ports 1080, 1234, 2773
Some Trojans are programmed to open specific ports to allow access for exploitation. If a Trojan is installed on a system, it often opens a high-numbered port. Then the open Trojan port can be scanned and located, enabling an attacker to compromise the system. Malicious scanning is discussed later in this chapter.
Logic Bomb
A logic bomb is an instantiation of a Trojan horse that is activated upon the occurrence of a particular event. For example, the malicious code might be set to run when a specific piece of code is executed or on a certain time and date. Similarly, a time bomb is set to activate after a designated period of time has elapsed.
System Scanning
No computer system connected to a public network is immune from malicious or indiscriminate scanning. System scanning is a process used to collect information about a device or network to facilitate an attack on the system. Attackers use it to discover what ports are open, what services are running, and what system software is being used. Scanning enables an attacker to detect and exploit known vulnerabilities within a target machine more easily.
Rather than an end in its own right, scanning is often one element of a network attack plan, consisting of:
- Network Reconnaissance. Through scanning, an intruder can find out valuable information about the target network such as:
- Domain names and IP blocks
- Intrusion detection systems
- Running services
- Platforms and protocols
- Firewalls and perimeter devices
- General network infrastructure
- Gaining System Access. Gaining access to a system can be achieved many ways, such as by:
- Session hijacking
- Password cracking
- Sniffing
- Direct physical access to an uncontrolled machine
- Exploiting default accounts
- Social engineering
- Removing Evidence of the Attack. After the attack, traces of the attack can be eliminated by:
- Editing and clearing security logs
- Compromising the Syslog server
- Replacing system files by using rootkit tools
- Creating legitimate accounts
- Leaving backdoor Trojan viruses such as SubSeven or NetBus
Security administrators should also use scanning to determine any evidence of compromise and identify vulnerabilities. Because scanning activity is often a prelude to a system attack, detecting malicious scans should be accompanied by monitoring and analysis of the logs and by blocking of unused and exposed ports.
Penetration Testing
Penetration testing can be employed in order to evaluate the resistance of an information system to attacks that can result in unauthorized access. In this approach, the robustness of an information system’s defense in the face of a determined cracker is evaluated. The penetration test, or ethical hacking as it is sometimes known, is conducted to obtain a high-level evaluation of a system’s defense or to perform a detailed analysis of the information system’s weaknesses. A penetration test can determine how a system reacts to an attack, whether or not a system’s defenses can be breached, and what information can be acquired from the system. There are three general types of penetration tests:
- Full-knowledge test. The penetration testing team has as much knowledge as possible about the information system to be evaluated. This type of test simulates the type of attack that might be mounted by a knowledgeable employee of an organization.
- Partial-knowledge test. The testing team has knowledge that might be relevant to a specific type of attack. The testing personnel will be provided with some information that is related to the specific type of information vulnerability that is desired.
- Zero-knowledge test. The testing team is provided with no information and begins the testing by gathering information on its own initiative.
Another category used to describe penetration test types is open-box versus closed-box testing. In an open-box test, the testing team has access to internal system code. Open-box testing is appropriate for use against general-purpose operating systems such as Unix or Linux. Conversely, in closed-box testing, the testing team does not have access to internal code. This type of testing is applied to specialized systems that do not execute user code.
Obviously, the team conducting the penetration test must do so with approval of the sponsoring organization and ensure that the test does not go beyond the limits specified by the organization. The penetration test should never cause damage or harm to the information system or its data.
Penetration tests comprise the following phases:
- Discovery. Information and data relevant to the organization and system to be evaluated is obtained through public channels, databases, Web sites, mail servers, and so on.
- Enumeration. The penetration testing team works to acquire network information, versions of software running on the target system, IDs, usernames, and so on.
- Vulnerability mapping. The testing team profiles the information system environment and identifies its vulnerabilities.
- Exploitation. The testing team attempts to exploit the system vulnerabilities and gain access privileges to the target system.
Identification and Authentication
Identification and authentication are the keystones of most access control systems. Identification is the act of a user professing an identity to a system, usually in the form of a username or user logon ID to the system. Identification establishes user accountability for the actions on the system. User IDs should be unique and not shared among different individuals. In many large organizations, user IDs follow set standards, such as first initial followed by last name. In order to enhance security and reduce the amount of information available to an attacker, the ID should not be representative of the user’s job title or function.
Authentication is verification that the user’s claimed identity is valid, and it is usually implemented through a user password at logon time. Authentication is based on the following three factor types:
- Type 1. Something you know, such as a personal identification number (PIN) or password
- Type 2. Something you have, such as an ATM card or smart card
- Type 3. Something you are (physically), such as a fingerprint or retina scan
Sometimes a fourth factor, something you do, is added to this list. Something you do may be typing your name or other phrases on a keyboard. Conversely, something you do can be considered something you are.
Two-factor authentication refers to the act of requiring two of the three factors to be used in the authentication process. For example, withdrawing funds from an ATM machine requires a two-factor authentication in the form of the ATM card (something you have) and a PIN (something you know).
Passwords
Passwords can be compromised and must be protected. In the ideal case, a password should be used only once. This “one-time password,” or OTP, provides maximum security because a new password is required for each new logon. A password that is the same for each logon is called a static password. A password that changes with each logon is termed a dynamic password. The changing of passwords can also fall between these two extremes. Passwords can be required to change monthly, quarterly, or at other intervals, depending on the criticality of the information needing protection and the password’s frequency of use. Obviously, the more times a password is used, the more chance there is of it being compromised. A passphrase is a sequence of characters that is usually longer than the allotted number for a password. The passphrase is converted into a virtual password by the system.
In all these schemes, a front-end authentication device or a back-end authentication server, which services multiple workstations or the host, can perform the authentication.
Passwords can be provided by a number of devices, including tokens, memory cards, and smart cards.
Tokens
Tokens, in the form of small, hand-held devices, are used to provide passwords. The following are the four basic types of tokens:
- Static password tokens
- The owner authenticates himself to the token by typing in a secret password.
- If the password is correct, the token authenticates the owner to an information system.
- Synchronous dynamic password tokens, clock-based
- The token generates a new, unique password value at fixed time intervals that is synchronized with the same password on the authentication server (this password is the time of day encrypted with a secret key).
- The unique password is entered into a system or workstation along with an owner’s PIN.
- The authentication entity in a system or workstation knows an owner’s secret key and PIN, and the entity verifies that the entered password is valid and that it was entered during the valid time window.
- Synchronous dynamic password tokens, counter-based
- The token increments a counter value that is synchronized with a counter in the authentication server.
- The counter value is encrypted with the user’s secret key inside the token, and this value is the unique password that is entered into the system authentication server.
- The authentication entity in the system or workstation knows the user’s secret key, and the entity verifies that the entered password is valid by performing the same encryption on its identical counter value.
- Asynchronous tokens, challenge-response
- A workstation or system generates a random challenge string, and the owner enters the string into the token along with the proper PIN.
- The token generates performs a calculation on the string using the PIN and generates a response value that is then entered into the workstation or system.
- The authentication mechanism in the workstation or system performs the same calculation as the token using the owner’s PIN and challenge string and compares the result with the value entered by the owner. If the results match, the owner is authenticated.
Memory Cards
Memory cards provide nonvolatile storage of information but do not have any processing capability. A memory card stores encrypted passwords and other related identifying information. A telephone calling card and an ATM card are examples of memory cards.
Smart Cards
Smart cards provide even more capability than memory cards by incorporating additional processing power on the cards. These credit card-sized devices comprise microprocessor and memory and are used to store digital signatures, private keys, passwords, and other personal information.
Biometrics
An alternative to using passwords for authentication in logical or technical access control is biometrics. Biometrics is based on the Type 3 authentication mechanism - something you are. Biometrics is defined as an automated means of identifying or authenticating the identity of a living person based on physiological or behavioral characteristics. In biometrics, identification is a one-to-many search of an individual’s characteristics from a database of stored images. Authentication in biometrics is a one-to-one search to verify a claim to an identity made by a person. Biometrics is used for identification in physical controls and for authentication in logical controls.
There are three main performance measures in biometrics:
- False Rejection Rate (FRR) or Type I Error - The percentage of valid subjects that are falsely rejected
- False Acceptance Rate (FAR) or Type II Error - The percentage of invalid subjects that are falsely accepted.
- Crossover Error Rate (CER) - The FRR and FRR at the sensitivity at which the FRR equals the FAR
Almost all types of detection permit a system’s sensitivity to be increased or decreased during an inspection process. If the system’s sensitivity is increased, such as in an airport metal detector, the system becomes increasingly selective and has a higher FRR. Conversely, if the sensitivity is decreased, the FAR will increase. Thus, to have a valid measure of the system performance, the CER is used. We show these concepts in Figure 2-1.
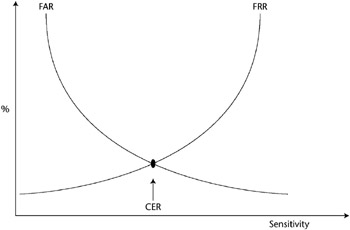
Figure 2-1: Crossover Error Rate (CER).
In addition to the accuracy of the biometric systems, there are other factors that must be considered. These factors include the enrollment time, the throughput rate, and acceptability. Enrollment time is the time that it takes to initially register with a system by providing samples of the biometric characteristic to be evaluated. An acceptable enrollment time is around two minutes. For example, in fingerprint systems the actual fingerprint is stored and requires approximately 250KB per finger for a high-quality image. This level of information is required for one-to-many searches in forensics applications on very large databases. In finger-scan technology, a full fingerprint is not stored; rather, the features extracted from this fingerprint are stored by using a small template that requires approximately 500 to 1,000 bytes of storage. The original fingerprint cannot be reconstructed from this template. Finger-scan technology is used for one-to-one verification by using smaller databases. Updates of the enrollment information might be required because some biometric characteristics, such as voice and signature, may change with time.
The throughput rate is the rate at which the system processes and identifies or authenticates individuals. Acceptable throughput rates are in the range of 10 subjects per minute. Acceptability refers to considerations of privacy, invasiveness, and psychological and physical comfort when using the system. For example, a concern with retina scanning systems might be the exchange of body fluids on the eyepiece. Another concern would be the retinal pattern, which could reveal changes in a person’s health, such as diabetes or high blood pressure.
Collected biometric images are stored in an area referred to as a corpus. The corpus is stored in a database of images. Potential sources of error are the corruption of images during collection and mislabeling or other transcription problems associated with the database. Therefore, the image collection process and storage must be performed carefully with constant checking. These images are collected during the enrollment process and thus are critical to the correct operation of the biometric device.
The following are typical biometric characteristics that are used to uniquely authenticate an individual’s identity:
- Fingerprints. Fingerprint characteristics are captured and stored. Typical CERs are 4% to 5%.
- Retinal scans. The eye is placed approximately two inches from a camera and an invisible light source scans the retina for blood vessel patterns. CERs are approximately 1.4%.
- Iris scans. Video camera remotely captures iris patterns and characteristics. CER values are around 0.5%.
- Hand geometry. Cameras capture three-dimensional hand characteristics with a CER of approximately 2%.
- Voice. Sensors capture voice characteristics, including throat vibrations and air pressure, when subject speaks a phrase. CERs are in the range of 10%.
- Handwritten signature dynamics. The signing characteristics of an individual making a signature are captured and recorded. Typical characteristics include writing pressure and pen direction. CERs are not published at this time.
Other types of biometric characteristics include facial and palm scans.
Single Sign On (SSO)
Single Sign-On (SSO) addresses the cumbersome situation of logging on multiple times to access different resources. A user must remember numerous passwords and IDs and might take a shortcut by creating passwords that may be open to exploitation. In SSO, a user provides one ID and password per work session and is automatically logged on to all the required applications. For SSO security, the passwords should not be stored or transmitted in the clear. SSO applications can run either on a user’s workstation or on authentication servers. The advantages of SSO include the ability to use stronger passwords, easier administration of changing or deleting the passwords, and less time required to access resources. The major disadvantage of many SSO implementations is that once a user obtains access to the system through the initial logon, the user can freely roam the network resources without any restrictions.
The Open Group has defined functional objectives in support of a user SSO interface. These objectives include the following:
- The interface shall be independent of the type of authentication information handled.
- The interface shall not predefine the timing of secondary sign-on operations.
- Support shall be provided for a subject to establish a default user profile.
Authentication mechanisms include items such as smart cards and magnetic badges. Strict controls must be placed to prevent a user from changing configurations that another authority sets. The scope of the Open Group SSO Standards is to define services in support of the following:
- “The development of applications to provide a common, single enduser sign-on interface for an enterprise”
- “The development of applications for the coordinated management of multiple user account management information bases maintained by an enterprise”
SSO can be implemented by using scripts that replay the users’ multiple logins or by using authentication servers to verify a user’s identity and encrypted authentication tickets to permit access to system services.
Enterprise Access Management (EAM) provides access control management services to Web-based enterprise systems that include SSO. SSO can be provided in a number of ways. For example, SSO can be implemented on Web applications residing on different servers in the same domain by using nonpersistent, encrypted cookies on the client interface. This task is accomplished by providing a cookie to each application that the user wishes to access. Another solution is to build a secure credential for each user on a reverse proxy that is situated in front of the Web server. The credential is then presented at each instance of a user attempting to access protected Web applications.
Kerberos, SESAME, KryptoKnight, and NetSP are authentication server systems with operational modes that can implement SSO.
Kerberos
Kerberos is a trusted, third party authentication protocol developed under Project Athena at the Massachusetts Institute of Technology (MIT). In Greek mythology, Kerberos is a three-headed dog who guards the entrance to the underworld.
Using symmetric-key cryptography, Kerberos authenticates clients to other entities on a network of which a client requires services. The rationale and architecture behind Kerberos can be illustrated by using a university environment as an example. In such an environment, there are thousands of locations for workstations, local networks, and PC clusters. Client locations and computers are not secure; thus, one cannot assume that the cabling is secure. Messages, therefore, are not secure from interception. A few specific locations and servers can be secured, however, and can serve as trusted authentication mechanisms for every client and service on that network. These centralized servers implement the Kerberos-trusted Key Distribution Center (KDC), Kerberos Ticket Granting Service (TGS), and Kerberos Authentication Service (AS). Windows 2000 provides Kerberos implementations.
The basic principles of Kerberos operation are as follows:
- The KDC knows the secret keys of all clients and servers on the network.
- The KDC initially exchanges information with the client and server by using these secret keys.
- Kerberos authenticates a client to a requested service on a server through TGS and by issuing temporary symmetric session keys for communications between the client and KDC, the server and the KDC, and the client and server.
- Communication then takes place between the client and the server by using those temporary session keys.
Table 2-1 explains the Kerberos terminology and symbols used in the following detailed discussion of this procedure.
|
KERBEROS |
ITEM SYMBOL |
|---|---|
|
Client |
C |
|
Client secret key |
Kc |
|
Client network address |
A |
|
Server |
S |
|
Client/TGS session key |
Kc, tgs |
|
TGS secret key |
Ktgs |
|
Server secret key |
Ks |
|
Client/server session key |
Kc, s |
|
Client/TGS ticket |
Tc, tgs |
|
Client to server ticket |
Tc, s |
|
Client to server authenticator |
Ac, s |
|
Starting and ending time ticket is valid |
v |
|
Timestamp |
t |
|
M encrypted in secret key of x |
[M] Kx |
|
Ticket Granting Ticket |
TGT |
|
Optional, additional session key |
Key |
 Open table as spreadsheet
Open table as spreadsheetKerberos Operation
Next, we examine, in more detail, the exchange of messages among the client, TGS Server, Authentication Server, and the server that is providing the service.
Client-TGS Server: Initial Exchange
To initiate a request for service from a server (or servers), the user enters an ID and password on the client workstation. The client temporarily generates the client’s secret key (Kc) from the password by using a one-way hash function. (The one-way hash function performs a mathematical encryption operation on the password that cannot be reversed.) The client sends a request for authentication to the TGS server by using the client’s ID in the clear. Note that no password or secret key is sent. If the client is in the Authentication Server database, the TGS server returns a client/TGS session key (Kc, tgs), which is encrypted in the secret key of the client, and a Ticket Granting Ticket (TGT) encrypted in the secret key (Ktgs) of the TGS server. Thus, neither the client nor any other entity except the TGS server can read the contents of the TGT because only the TGS server knows the Ktgs. The TGT consists of the client ID, the client network address, the starting and ending time that the ticket is valid (v), and the client/TGS session key. Symbolically, these initial messages from the TGS server to the client are represented as follows:
[Kc, tgs]Kc TGT = [c, a, v, Kc, tgs]Ktgs
The client decrypts the message containing the session key (Kc, tgs) with its secret key (Kc) and now uses this session key to communicate with the TGS server. Then the client erases its stored secret key to avoid compromising the secret key.
Client to TGS Server: Request for Service
When requesting access to a specific service on the network from the TGS server, the client sends two messages to the TGS server. In one message, the client submits the previously obtained TGT, which is encrypted in the secret key (K tgs) of the TGS server, and an identification of the server (S) from which service is requested. The other message is an authenticator, which is encrypted in the assigned session key (Kc, tgs). The authenticator contains the client ID, a timestamp, and an optional additional session key. These two messages are as follows:
TGT = s, [c, a, v, Kc, tgs]Ktgs Authenticator = [c, t, key]Kc, tgs
TGS Server to Client: Issuing of Ticket for Service
After receiving a valid TGT and an authenticator from the client requesting a service, the TGS server issues a ticket (Tc, s) to the client that is encrypted in the server’s secret key (Ks) and a client/server session key (Kc, s) that is encrypted in the client/TGS session key (Kc, tgs). These two messages are as follows:
Ticket Tc, s = s, [c, a, v, Kc, s]Ks [Kc, s]Kc, tgs
Client to Server Authentication: Exchange and Providing of Service
To receive service from the server (or servers), the client sends the ticket (Tc, s) and an authenticator to the server. The server decrypts the ticket with its secret key (Ks) and checks the contents. The contents contain the client’s address, the valid time window (v), and the client/server session key (Kc, s), which will now be used for communication between the client and server. The server also checks the authenticator, and if that timestamp is valid, it provides the requested service to the client. The client messages to the server are as follows:
Ticket Tc, s = s, [c, a, v, Kc, s]Ks Authenticator = [c, t, key]Kc, s
Kerberos Vulnerabilities
Kerberos addresses the confidentiality and integrity of information. It does not directly address availability and attacks, such as frequency analysis. Furthermore, because all the secret keys are held and authentication is performed on the Kerberos TGS and the authentication servers, these servers are vulnerable to both physical attacks and attacks from malicious code. Replay can be accomplished on Kerberos if the compromised tickets are used within an allotted time window. Because a client’s password is used in the initiation of the Kerberos request for the service protocol, password guessing can be used to impersonate a client.
The keys used in the Kerberos exchange are also vulnerable. A client’s secret key is stored temporarily on the client workstation and can be compromised as well as the session keys that are stored at the client’s computer and at the servers.
RFC 1510 provides additional information on Kerberos security features and issues.
SESAME
To address some of the weaknesses in Kerberos, the Secure European System for Applications in a Multi-vendor Environment (SESAME) project uses public-key cryptography for the distribution of secret keys and provides additional access control support. It uses the Needham-Schroeder protocol and a trusted authentication server at each host to reduce the key management requirements. SESAME employs the MD5 and crc32 one-way hash functions. In addition, SESAME incorporates two certificates or tickets. One certificate provides authentication as in Kerberos, and the other certificate defines the access privileges assigned to a client. One weakness in SESAME is that it authenticates by using only the first block of a message and not the complete message. SESAME is also subject to password guessing (like Kerberos).
The SESAME interface is provided by the Generic Security Services Application Programming Interface (GSS-API), which is an X/Open Standard.
KryptoKnight
The IBM KryptoKnight system provides authentication, SSO, and key distribution services. It was designed to support computers with widely varying computational capabilities. KryptoKnight uses a trusted Key Distribution Center (KDC) that knows the secret key of each party. One of the differences between Kerberos and KrytpoKnight is that there is a peer-to-peer relationship among the parties and the KDC. To implement SSO, the KDC has a party’s secret key, which is a one-way hash transformation of their password. The initial exchange from the party to the KDC is the user’s name and a value, which is a function of a nonce (a randomly-generated, one-time use authenticator) and the password. The KDC authenticates the user and sends the user a ticket encrypted with the user’s secret key. The user decrypts this ticket and can use it for authentication to obtain services from other servers on the system. NetSP is a product that is based on KryptoKnight and uses a workstation as an authentication server. NetSP tickets are compatible with a number of access control services, including the Resource Access Control Facility (RACF).
Access Control Methodologies
Access control implementations are as diverse as their requirements. However, access control can be divided into two domains: centralized access control and decentralized/distributed access control. In the following sections, we summarize the mechanisms to achieve both types.
Centralized Access Control
Centralized access control refers to providing secure access to remote users and providing for authentication, authorization, and accountability of the user. These services are usually referred to as AAA.
Dial-up users can use the standard open source Remote Authentication and Dial-In User Service (RADIUS). RADIUS incorporates an authentication server and dynamic passwords. In a typical RADIUS authentication transaction, a user enters logon credentials to a RADIUS client residing on a Network Access Server (NAS). A RADIUS server receives the authentication request from the NAS and is responsible for authenticating the user. The communication between the NAS and the RADIUS server are encrypted using a secret key known to both entities. RADIUS also provides authorization and accountability functions.
Users can also use Callback for remote access. In Callback, a remote user dials in to the authentication server, provides an ID and password, and then hangs up. The authentication server looks up the caller’s ID in a database of authorized users and obtains a phone number at a fixed location. (Note that the remote user must be calling from that location.) The authentication server then calls the phone number, the user answers, and then the user has access to the system. In some Callback implementations, the user must enter another password upon receiving a Callback. The disadvantage of this system is that the user must be at a fixed location whose phone number is known to the authentication server. A threat to Callback is that a cracker can arrange to have the call automatically forwarded to their number, enabling access to the system.
Two other approaches to remote access are the Password Authentication Protocol (PAP) and the Challenge Handshake Authentication Protocol (CHAP). In PAP, the user sends an ID and password in cleartext to the authentication server until authentication occurs or the user is rejected. CHAP improves on PAP by protecting the password from eavesdroppers and supporting the encryption of communication.
Other centralized AAA servers that are widely used are the Terminal Access Controller Access Control System (TACACS), TACACS+, and DIAMETER.
For networked applications TACACS, developed by Cisco Systems, employs a user ID and a static password for network access. TACACS+ provides even stronger protection through the use of tokens for two-factor, dynamic password authentication.
DIAMETER is based on RADIUS and functions in a peer-to-peer mode instead of the RADIUS client/server model. DIAMETER is capable of supporting multiple AAA accounts and can operate using proxy Brokers that can be protected by security protocols. DIAMETER also employs encryption to protect sensitive information.
Another type of authentication requirement is posed by using the Remote Procedure Call (RPC). RPC supports calling and executing an operation on a remote computer. For security purposes, the RPC server must authenticate the RPC client before the remote operation is executed. RPC uses public-key encryption to protect transmitted information.
Decentralized Distributed Access Control
One method of controlling access in a distributed system is through the Network Information Service (NIS), which provides the ability to share password files and other files over a network using a distributed database. In operation, NIS clients access a central database on an NIS server.
Another powerful approach to controlling the access to information in a decentralized environment is through the use of relational databases. The relational model developed by E. F. Codd of IBM (circa 1970) has been the focus of much research in providing information security. Other database models include models that are hierarchical, networked, object-oriented, and object-relational. The relational and object-relational database models support queries, while the traditional file systems and the object-oriented database model do not. The object-relational and object-oriented models are better suited to managing complex data, such as what is required for computer-aided design and imaging. Because the bulk of information security research and development has focused on relational databases, this section emphasizes the relational model.
Relational Database Security
A relational database model has three parts:
- Data structures called tables or relations
- Integrity rules on allowable values and value combinations in the tables
- Operators on the data in the tables
A database can be defined as a persistent collection of interrelated data items. Persistency is obtained through the preservation of integrity and through the use of nonvolatile storage media. The description of the database is a schema, and a Data Description Language (DDL) defines the schema. A database management system (DBMS) is the software that maintains and provides access to the database. For security, you can set up the DBMS so that only certain subjects are permitted to perform certain operations on the database. For example, a particular user can be restricted to certain information in the database and will not be allowed to view any other information.
A relation is the basis of a relational database and is represented by a two-dimensional table. The rows of the table represent records, or tuples, and the columns of the table represent the attributes. The number of rows in the relation is referred to as the cardinality, and the number of columns is the degree. The domain of a relation is the set of allowable values that an attribute can take. For example, a relation might be PARTS, as shown in Table 2-2, or ELECTRICAL ITEMS, as shown in Table 2-3.
|
PART NUMBER |
PART NAME |
PART TYPE |
LOCATION |
|---|---|---|---|
|
E2C491 |
Alternator |
Electrical |
B261 |
|
M4D326 |
Idle Gear |
Mechanical |
C418 |
|
E5G113 |
Fuel Gauge |
Electrical |
B561 |
|
SERIAL NUMBER |
PART NUMBER |
PART NAME |
PART COST |
|---|---|---|---|
|
S367790 |
E2C491 |
Alternator |
$200 |
|
S785439 |
E5D667 |
Control Module |
$700 |
|
S677322 |
E5W459 |
Window Motor |
$300 |
In each table, a primary key is required. A primary key is a unique identifier in the table that unambiguously points to an individual tuple or record in the table. A primary key is a subset of candidate keys within the table. A candidate key is an attribute that is a unique identifier within a given table. In Table 2-2, for example, the primary key would be the Part Number. If the Location of the part in Table 2-2 were unique to that part, it might be used as the primary key. Then the Part Numbers and Locations would be considered candidate keys, and the primary key would be taken from one of these two attributes. Now, assume that the Part Number attributes in Table 2-2 are the primary keys. If an attribute in one relation has values matching the primary key in another relation, this attribute is called a foreign key. A foreign key does not have to be the primary key of its containing relation. For example, the Part Number attribute E2C491 in Table 2-3 is a foreign key, because its value corresponds to the primary key attribute in Table 2-2.
Entity and Referential Integrity
Continuing with the example, if we designate the Part Number as the primary key in Table 2-2, then each row in the table must have a Part Number attribute. If the Part Number attribute is NULL, then Entity Integrity has been violated. Similarly, the Referential Integrity requires that for any foreign key attribute, the referenced relation must have a tuple with the same value for its primary key. Thus, if the attribute E2C491 of Table 2-3 is a foreign key of Table 2-2, then E2C491 must be a primary key in Table 2-2 to hold the referential integrity. Foreign key-to-primary key matches are important because they represent references from one relation to another and establish the connections among these relations.
Relational Database Operations
A number of operations in a relational algebra are used to build relations and operate on the data. Five of these operations are primitives, and the other operations can be defined in terms of those five. Later, we discuss in greater detail some of the more commonly applied operations. The operations include the following:
- Select (primitive)
- Project (primitive)
- Union (primitive)
- Difference (primitive)
- Product (primitive)
- Join
- Intersection
- Divide
- Views
For clarification, the Select operation defines a new relation based on a formula (for example, all the electrical parts whose cost exceeds $300 in Table 2-3). The Join operation selects tuples that have equal numbers for some attributes; for example, in Tables 2-2 and 2-3, Serial Numbers and Locations can be joined by the common Part Number. The Union operation forms a new relation from two other relations (for example, for relations that we call X and Y, the new relation consists of each tuple that is in either X or Y or both).
An important operation related to controlling the access of database information is the View. A View is defined from the operations of Join, Project, and Select. A View does not exist in a physical form, and it can be considered as a virtual table that is derived from other tables. (A relation that actually exists in the database is called a base relation.) These other tables could be tables that exist within the database or previously defined Views. You can think of a View as a way to develop a table that is going to be frequently used although it may not physically exist within the database. Views can be used to restrict access to certain information within the database, to hide attributes, and to implement content-dependent access restrictions. Thus, an individual requesting access to information within a database will be presented with a View containing the information that the person is allowed to see. The View will then hide the information that individual is not allowed to see. In this way, the View can be thought of as implementing Least Privilege.
In developing a query of the relational database, an optimization process is performed. This process includes generating query plans and selecting the best (lowest in cost) of the plans. A query plan is composed of implementation procedures that correspond to each of the low-level operations in that query. The selection of the lowest-cost plan involves assigning costs to the plan. Costs may be a function of disk accesses and CPU usage.
When querying a database for statistical information, individually identifiable information should be protected. Thus, requiring a minimum size for the query set (greater than one) offers protection against gathering information on one individual. In statistical database queries, a protection mechanism that is used to limit inferencing of information is the specification of a minimum query set size, but prohibiting the querying of all but one of the records in the database. This control thwarts an attack of gathering statistics on a query set size M, equal to or greater than the minimum query set size, and then requesting the same statistics on a query set size of M + 1. The second query set would be designed to include the individual whose information is being sought surreptitiously.
A bind is also applied in conjunction with a plan to develop a query. A bind creates the plan and fixes or resolves the plan. Bind variables are placeholders for literal values in a Structured Query Language (SQL) query being sent to the database on a server. The SQL statement is sent to the server for parsing, and then later values are bound to the placeholders and sent separately to the server. This separate binding step is the origin of the term bind variable.
Data Normalization
Normalization is an important part of database design that ensures that attributes in a table depend only on the primary key. This process makes it easier to maintain data and to have consistent reports.
Normalizing data in the database consists of three steps:
- Eliminating any repeating groups by putting them into separate tables
- Eliminating redundant data (occurring in more than one table)
- Eliminating attributes in a table that are not dependent on the primary key of that table
SQL
Developed at IBM, SQL is a standard data manipulation and relational database definition language. The SQL Data Definition Language creates and deletes views and relations (tables). SQL commands include SELECT, UPDATE, DELETE, INSERT, GRANT, and REVOKE. The latter two commands are used in access control to grant and revoke privileges to resources. Usually, the owner of an object can withhold or transfer GRANT privileges related to an object to another subject. If the owner intentionally does not transfer the GRANT privileges that are relative to an object to the individual A, however, A cannot pass on the GRANT privileges to another subject. In some instances, though, this security control can be circumvented. For example, if A copies the object, A essentially becomes the owner of that object and thus can transfer the GRANT privileges to another user, such as user B.
SQL security issues include the granularity of authorization and the number of different ways you can execute the same query.
Object-Oriented Databases (OODB)
Relational database models are ideal for business transactions, where most of the information is in text form. Complex applications involving multimedia, computer-aided design, video, graphics, and expert systems are more suited to an object-oriented database (OODB). For example, an OODB places no restrictions on the types or sizes of data elements, as is the case with relational databases. An OODB has the characteristics of ease of reusing code and analysis, reduced maintenance, and an easier transition from analysis of the problem to design and implementation. Its main disadvantages are a steep learning curve, even for experienced traditional programmers, and a high overhead of hardware and software required for development and operation.
Object-Relational Databases
The object-relational database is the marriage of object-oriented and relational technologies and combines the attributes of both. This model was introduced in 1992 with the release of the UniSQL/X unified relational and object-oriented database system. Hewlett Packard then released OpenODB (later called Odapter), which extended its AllBase relational Database Management System.
Thin-Client Systems
A thin-client approach to distributed access control involves having a stripped-down client computer that sends and receives keystroke information only. The thin-client device, sometimes referred to as a Network Computer (NC), communicates with a server that provides processing, storage, and printing capability for the client. The client has a reduced exposure to security risks because it does not have large amounts of memory and peripherals such as floppy disk, CD, and DVD drives.
In the thin-client model, access control and other security services are provided by the server and not by the client device.
Security Domain
A security domain is another distributed process security control in which information system resources are organized into separate, protected address spaces. Formally, a security domain is defined as computer resources that have the same mission and operate under the same management and information security policy. Security domains can also be established based on the sensitivity of the information in the domain. As with classified data, subjects that are assigned privileges in security domains of high sensitivity can access security domains of lower sensitivity, but the converse is not permitted.
Intrusion Detection
An Intrusion Detection System (IDS) is a system that monitors network traffic or monitors host audit logs in order to determine whether any violations of an organization’s security policy have taken place. An IDS can detect intrusions that have circumvented or passed through a firewall or that are occurring within the local area network behind the firewall.
A truly effective IDS will detect common attacks as they occur, which includes distributed attacks. This type of IDS is called a network-based IDS because it monitors network traffic in real time. Conversely, a host-based IDS resides on centralized hosts.
Network-Based IDS
A network-based IDS usually provides reliable, real-time information without consuming network or host resources. A network-based IDS is passive when acquiring data. Because a network-based IDS reviews packets and headers, it can also detect DoS attacks. Furthermore, because this IDS is monitoring an attack in real time, it can also respond to an attack in progress to limit damage.
A problem with a network-based IDS system is that it will not detect attacks against a host made by an intruder who is logged in at the host’s terminal. If a network IDS along with some additional support mechanism determines that an attack is being mounted against a host, it is usually not capable of determining the type or effectiveness of the attack being launched.
Host-Based IDS
A host-based IDS can review the system and event logs in order to detect an attack on the host and to determine whether the attack was successful. (It is also easier to respond to an attack from the host.) Detection capabilities of host-based ID systems are limited by the incompleteness of most host audit log capabilities.
IDS Detection Methods
An IDS detects an attack through two major mechanisms: signature-based intrusion detection (ID) or statistical anomaly–based ID. These approaches are also termed Knowledge-based and Behavior-based ID, respectively, and are reinforced in Chapter 3.
Signature-Based ID
In a signature-based ID, signatures or attributes that characterize an attack are stored for reference. Then, when data about events is acquired from host audit logs or from network packet monitoring, this data is compared with the attack signature database. If there is a match, a response is initiated. A weakness of this approach is the failure to characterize slow attacks that extend over a long time period. To identify these types of attacks, large amounts of information must be held for extended time periods.
Another issue with signature-based IDs is that only attack signatures that are stored in their databases are detected.
Statistical Anomaly–Based ID
With this method, an IDS acquires data and defines a normal usage profile for the network or host that is being monitored. This characterization is accomplished by taking statistical samples of the system over a period of normal use. Typical characterization information used to establish a normal profile includes memory usage, CPU utilization, and network packet types. With this approach, new attacks can be detected because they produce abnormal system statistics. Some disadvantages of a statistical anomaly–based ID are that it will not detect an attack that does not significantly change the system operating characteristics, or it might falsely detect a nonattack event that has caused a momentary anomaly in the system.
Some Access Control Issues
As we discussed earlier in this chapter, the cost of access control must be commensurate with the value of the information being protected. The value of this information is determined through qualitative and quantitative methods. These methods incorporate factors such as the cost to develop or acquire the information, the importance of the information to an organization and its competitors, and the effect on the organization’s reputation if the information is compromised.
Access control must offer protection from an unauthorized, unanticipated, or unintentional modification of information. This protection should preserve the data’s internal and external consistency. The confidentiality of the information must also be similarly maintained, and the information should be available on a timely basis. These factors cover the integrity, confidentiality, and availability components of information system security.
Accountability is another facet of access control. Individuals on a system are responsible for their actions. This accountability property enables system activities to be traced to the proper individuals. Accountability is supported by audit trails that record events on the system and on the network. Audit trails can be used for intrusion detection and for the reconstruction of past events. Monitoring individual activities, such as keystroke monitoring, should be accomplished in accordance with the company policy and appropriate laws. Banners at logon time should notify the user of any monitoring being conducted.
The following measures compensate for both internal and external access violations:
- Backups
- RAID (Redundant Array of Independent Disks) technology
- Fault tolerance
- Business continuity planning
- Insurance
Assessment Questions
You can find the answers to the following questions in Appendix A.
|
1. |
The goals of integrity do not include:
|
|
|
2. |
Kerberos is an authentication scheme that can be used to implement:
|
|
|
3. |
The fundamental entity in a relational database is the:
|
|
|
4. |
In a relational database, security is provided to the access of data through:
|
|
|
5. |
In biometrics, a one-to-one search to verify an individual’s claim of an identity is called:
|
|
|
6. |
Biometrics is used for identification in the physical controls and for authentication in the:
|
|
|
7. |
Referential integrity requires that for any foreign key attribute, the referenced relation must have:
|
|
|
8. |
A password that is the same for each logon is called a:
|
|
|
9. |
Which one of the following is not an access attack?
|
|
|
10. |
An attack that uses a detailed listing of common passwords and words in general to gain unauthorized access to an information system is best described as:
|
|
|
11. |
A statistical anomaly–based intrusion detection system:
|
|
|
12. |
Which one of the following definitions best describes system scanning?
|
|
|
13. |
In which type of penetration test does the testing team have access to internal system code?
|
|
|
14. |
A standard data manipulation and relational database definition language is:
|
|
|
15. |
An attack that can be perpetrated against a remote user’s callback access control is:
|
|
|
16. |
The definition of CHAP is:
|
|
|
17. |
Using symmetric-key cryptography, Kerberos authenticates clients to other entities on a network and facilitates communications through the assignment of:
|
|
|
18. |
Three things that must be considered for the planning and implementation of access control mechanisms are:
|
|
|
19. |
In mandatory access control, the authorization of a subject to have access to an object is dependent upon:
|
|
|
20. |
The type of access control that is used in local, dynamic situations where subjects have the ability to specify what resources certain users can access is called:
|
|
|
21. |
Role-based access control is useful when:
|
|
|
22. |
Clipping levels are used to:
|
|
|
23. |
Identification is:
|
|
|
24. |
Authentication is:
|
|
|
25. |
An example of two-factor authentication is:
|
|
|
26. |
In biometrics, a good measure of the performance of a system is the:
|
|
|
27. |
In finger scan technology:
|
|
|
28. |
An acceptable biometric throughput rate is:
|
|
|
29. |
Which one of the following is not a type of penetration test?
|
|
|
30. |
Object-Oriented Database (OODB) systems:
|
|
|
31. |
A minimally configured information entry and retrieval device that relies on a remote server for its primary processing, security, storage, and printing functions is called a:
|
|
Answers
|
1. |
Answer: a Accountability is holding individuals responsible for their actions. Answers b, c, and d are the three goals of integrity. |
|
2. |
Answer: d Kerberos is a third-party authentication protocol that can be used to implement SSO. Answer a is incorrect because public-key cryptography is not used in the basic Kerberos protocol. Answer b is a public-key-based capability, and answer c is a one-way transformation used to disguise passwords or to implement digital signatures. |
|
3. |
Answer: b The fundamental entity in a relational database is the relation, in the form of a table. Answer a is the set of allowable attribute values, and answers c and d are distracters. |
|
4. |
Answer: b Views enable access to data in their underlying tables to be controlled. Candidate keys (answer a) are the set of unique keys from which the primary key is selected. Answer c Joins (answer c) are operations that can be performed on the database, and the attributes (answer d) denote the columns in the relational table. |
|
5. |
Answer: b Answer b is correct. Answer a is a review of audit system data, usually done after the fact. Answer c is holding individuals responsible for their actions, and answer d is obtaining higher-sensitivity information from a number of pieces of information of lower sensitivity. |
|
6. |
Answer: c The correct answer is c (logical controls). The other answers are different categories of controls where preventive controls attempt to eliminate or reduce vulnerabilities before an attack occurs; detective controls attempt to determine that an attack is taking place or has taken place; and corrective controls involve taking action to restore the system to normal operation after a successful attack. |
|
7. |
Answer: a The correct answer is a. Answers b and c are incorrect because a secondary key is not a valid term. Answer d is a distracter because referential integrity has a foreign key referring to a primary key in another relation. |
|
8. |
Answer: b The correct answer is b. In answer a, the password changes at each logon. A passphrase (answer c) is a long word or phrase that is converted by the system to a password. A one-time pad (answer d) consists of using a random key only once when sending a cryptographic message. |
|
9. |
Answer: d The correct answer is d, a distracter. A penetration test is conducted to obtain a high level evaluation of a system’s defense or to perform a detailed analysis of the information system’s weaknesses. A penetration test can determine how a system reacts to an attack, whether or not a system’s defenses can be breached, and what information can be acquired from the system. It is performed with the approval of the target organization. |
|
10. |
Answer: c In a dictionary attack (answer c), a dictionary of common words and passwords are applied to attempt to gain unauthorized access to an information system. In password guessing (answer a), the attacker guesses passwords derived from sources such as notes on the user’s desk, the user’s birthday, a pet’s name, applying social engineering techniques, and so on. Answer b refers to exploiting software vulnerabilities, and answer d, spoofing, is a method used by an attacker to convince an information system that it is communicating with a known, trusted entity. |
|
11. |
Answer: a A statistical anomaly–based intrusion detection system acquires data to establish a normal system operating profile. Answer b is incorrect because it is used in signature-based intrusion detection. Answer c is incorrect because a statistical anomaly–based intrusion detection system will not detect an attack that does not significantly change the system operating characteristics. Similarly, answer d is incorrect because the statistical anomaly–based IDS is susceptible to reporting an event that caused a momentary anomaly in the system. |
|
12. |
Answer: d Answer d is correct. Answer a describes a back door attack, answer b is a replay attack, and answer c refers to dumpster diving. |
|
13. |
Answer: c The correct answer is c, open-box testing. In closed-box testing (answer a), the testing team does not have access to internal system code. The other answers are distracters. |
|
14. |
Answer: b All answers other than SQL (b) do not apply. |
|
15. |
Answer: a The correct answer is a. A cracker can have a person’s call forwarded to another number to foil the callback system. Answer b is incorrect because it is an example of malicious code embedded in useful code. Answer c is incorrect because it might enable bypassing controls of a system through a means used for debugging or maintenance. Answer d is incorrect because it is a distracter. |
|
16. |
Answer: b |
|
17. |
Answer: b Session keys are temporary keys assigned by the KDC and used for an allotted period of time as the secret key between two entities. Answer a is incorrect because it refers to asymmetric encryption, which is not used in the basic Kerberos protocol. Answer c is incorrect because it is not a key, and answer d is incorrect because a token generates dynamic passwords. |
|
18. |
Answer: b Threats define the possible source of security policy violations; vulnerabilities describe weaknesses in the system that might be exploited by the threats; and the risk determines the probability of threats being realized. All three items must be present to meaningfully apply access control. Therefore, the other answers are incorrect. |
|
19. |
Answer: a Mandatory access controls use labels to determine whether subjects can have access to objects, depending on the subjects’ clearances. Answer b, roles, is applied in nondiscretionary access control, as is answer c, tasks. Answer d, identity, is used in discretionary access control. |
|
20. |
Answer: d Answer d is correct. Answers a and b require strict adherence to labels and clearances. Answer c is a made-up distracter. |
|
21. |
Answer: b Role-based access control is part of nondiscretionary access control. Answers a, c, and d relate to mandatory access control. |
|
22. |
Answer: c Clipping levels are used for reducing the amount of data to be evaluated by definition. Answer a is incorrect because clipping levels do not relate to letters in a password. Answer b is incorrect because clipping levels in this context have nothing to do with controlling voltage levels. Answer d is incorrect because they are not used to limit callback errors. |
|
23. |
Answer: d A user presents an ID to the system as identification. Answer a is incorrect because presenting an ID is not an authentication act. Answer b is incorrect because a password is an authentication mechanism. Answer c is incorrect because it refers to cryptography or authentication. |
|
24. |
Answer: a Answer a is correct. Answer b is incorrect because it is an identification act. Answer c is incorrect because authentication can be accomplished through the use of a password. Answer d is incorrect because authentication is applied to local and remote users. |
|
25. |
Answer: c The correct answer is c. These items are something you know and something you have. Answer a is incorrect because essentially, only one factor is being used - something you know (password). Answer b is incorrect for the same reason. Answer d is incorrect because only one biometric factor is being used. |
|
26. |
Answer: b Answer b is correct. The other items are made-up distracters. |
|
27. |
Answer: b In finger scan technology, the features extracted from the fingerprint are stored. Answer a is incorrect because the equivalent of the full finger-print is not stored in finger scan technology. Answers c and d are incorrect because the opposite is true of finger scan technology. |
|
28. |
Answer: c |
|
29. |
Answer: a The correct answer is a, a distracter. |
|
30. |
Answer: c Answer c is correct. The other answers are false because for answer a, relational databases are ideally suited to text-only information. For b and d, OODB systems have a steep learning curve and consume a large amount of system resources. |
|
31. |
Answer: c Answer c is correct. Answers a and b are computing systems with extensive storage and processing capabilities. Answer d is a made up distracter. |
Part One - Focused Review of the CISSP Ten Domains
- Information Security and Risk Management
- Access Control
- Telecommunications and Network Security
- Cryptography
- Security Architecture and Design
- Operations Security
- Application Security
- Business Continuity Planning and Disaster Recovery Planning
- Legal, Regulations, Compliance, and Investigations
- Physical (Environmental) Security
Part Two - The Certification and Accreditation Professional (CAP) Credential
- Understanding Certification and Accreditation
- Initiation of the System Authorization Process
- The Certification Phase
- The Accreditation Phase
- Continuous Monitoring Process
- Appendix A Answers to Assessment Questions
- Appendix B Glossary of Terms and Acronyms
- Appendix C The Information System Security Architecture Professional (ISSAP) Certification
- Appendix D The Information System Security Engineering Professional (ISSEP) Certification
- Appendix E The Information System Security Management Professional (ISSMP) Certification
- Appendix F Security Control Catalog
- Appendix G Control Baselines
EAN: 2147483647
Pages: 239
