Application Security
Overview
Information system security issues are associated with applications software, whether the software is developed internally or acquired from an external source. This chapter addresses these security issues from the viewpoints of the developer, user, and information system security specialist. Thus, a CISSP should understand the following areas:
- Systems engineering
- The software life cycle development process
- The software process capability maturity model
- Object-oriented systems
- Artificial intelligence systems
- Database systems
- Database security issues
- Data warehousing
- Data mining
- Data dictionaries
- Application controls
Systems Engineering
Systems engineering is discussed in detail in the ISSEP Appendix D, but is summarized at the beginning of this section to provide a perspective on the application software life cycle process.
A common definition of systems engineering states that it is the branch of engineering concerned with the development of large and complex systems, where a system is understood to be an assembly or combination of interrelated elements or parts working together toward a common objective.
The International Council on Systems Engineering (INCOSE) states:
[S]ystems engineering integrates all the disciplines and specialty groups into a team effort forming a structured development process that proceeds from concept to production to operation. Systems engineering considers both the business and the technical needs of all customers with the goal of providing a quality product that meets the user needs.[*]
Chapter 3 of the Information Assurance Technical Forum (www.iatf.net) document 3.1 defines a generic systems engineering process that comprises the following components:
- Discover needs
- Define system requirements
- Design system architecture
- Develop detailed design
- Implement system
- Assess effectiveness
[*]www.incose.org.
The System Life Cycle or System Development Life Cycle (SDLC)
The System Life Cycle, or System Development Life Cycle (SDLC) as it is sometimes known, is also covered in Appendix D. The principal elements of the SDLC are given in NIST Special Publication 800-14, Generally Accepted Principles and Practices for Securing Information Technology Systems (National Institute of Standards and Technology, 1996) and NIST Special Publication 800-64, Security Considerations in the Information System Development Life Cycle (National Institute of Standards and Technology, 2003). The phases of the System Life Cycle as given in NIST SP 800-14 are:
- Initiation. The need for the system and its purpose are documented. A sensitivity assessment is conducted as part of this phase. A sensitivity assessment evaluates the sensitivity of the IT system and the information to be processed.
- Development/Acquisition. In this phase, the system is designed, developed, programmed, and acquired.
- Implementation. Installation, testing, security testing, and accreditation are conducted.
- Operation/Maintenance. The system performs its designed functions. This phase includes security operations, modification/addition of hardware and/or software, administration, operational assurance, monitoring, and audits.
- Disposal. System components and products, such as hardware, software, and information are disposed of; disks are sanitized; files are archived; and equipment is moved.
The Software Life Cycle Development Process
Software engineering can be defined as the science and art of specifying, designing, implementing, and evolving programs, documentation, and operating procedures so that computers can be made useful to people. This definition is a combination of popular definitions of engineering and software. One definition of engineering is the application of science and mathematics to the design and construction of artifacts that are useful to people. A definition of software is that it consists of the programs, documentation, and operating procedures by which computers can be made useful to people.
In software engineering, the term verification is defined as the process of establishing the truth of correspondence between a software product and its specification. Validation establishes the fitness or worth of a software product for its operational mission. Requirements, as defined in the Waterfall model,[*] are a complete, validated specification of the required functions, interfaces, and performance for the software product. Product design is a complete, verified specification of the overall hardware-software architecture, control structure, and data structure for the product.
Quality software is difficult to obtain without a development process. As with any project, two principal goals of software development are to produce a quality product that meets the customer’s requirements and to stay within the budget and time schedule. A succession of models has emerged over time, incorporating improvements in the development process.
Structured Programming Development (SDM) is a view of software development that comprises four major elements:
- Modularity - Partitioning program elements so that they are manageable and are amenable to testing for functionality and security
- Layering - Software modules are developed in layers with specific security features for each layer
- Characterizing data flows - Specifying data flows and data elements in a data dictionary and linking flow diagrams with the dictionary
- Identifying activities - Documenting development activities
In a different approach, an early software development model defined succeeding stages, taking into account the different staffing and planning that was required for each stage. The model was simplistic in that it assumed that each step could be completed and finalized without any effect from the later stages that may require rework. This model is shown in Figure 7-1.
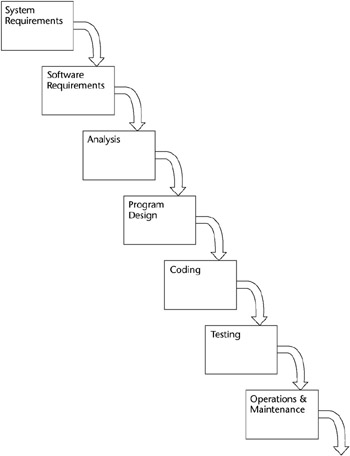
Figure 7-1: A simplistic software development model.
The Waterfall Model
Because subsequent stages, such as design, coding, and testing, in the development process may require modifying earlier stages in the model, the Waterfall model emerged. Under this model, software development can be managed if the developers are limited to going back only one stage to rework. If this limitation is not imposed (particularly on a large project with several team members), then any developer can be working on any phase at any time and the required rework might be accomplished several times. Obviously, this approach results in a lack of project control, and it is difficult to manage. The Waterfall model is shown in Figure 7-2.
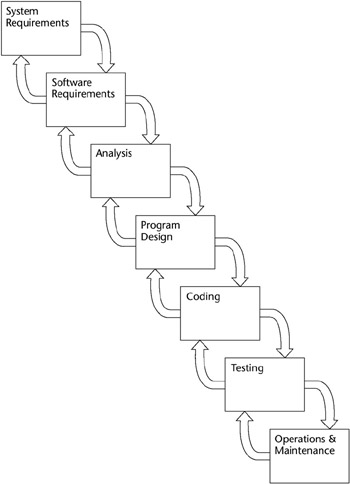
Figure 7-2: The Waterfall model.
One fundamental problem with these models is that they assume that a phase or stage ends at a specific time; however, this is not usually the case in real-world applications. If an ending phase is forcibly tied to a project milestone, the situation can be improved. If rework is required in this mode, the phase is not officially pronounced as ending. The rework must then be accomplished and the project milestone met before the phase is officially recognized as completed. In summary, the steps of the Waterfall model are:
- System feasibility
- Software plans and requirements
- Product design
- Detailed design
- Code
- Integration
- Implementation
- Operations and maintenance
In 1976, Barry Boehm reinterpreted the Waterfall model to have phases end at project milestones and to have the backward arrows represent back references for verification and validation (V&V) against defined baselines. Verification evaluates the product during development against the specification, and validation refers to the work product satisfying the real-world requirements and concepts. In simpler terms, Boehm states, “Verification is doing the job right, and validation is doing the right job.” These concepts are illustrated in Figure 7-3.
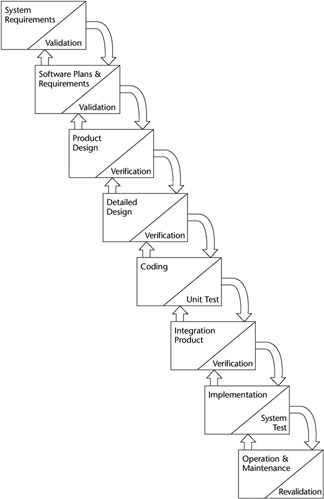
Figure 7-3: A modified Waterfall model incorporating V&V.
In this modified version of the Waterfall model, the end of each phase is a point in time for which no iteration of phases is provided. Rework can be accomplished within a phase when the phase end review shows that it is required.
The Spiral Model
In 1988 at TRW, Boehm developed the Spiral model, which is actually a metamodel that incorporates a number of the software development models. This model depicts a spiral that incorporates the various phases of software development. As shown in Figure 7-4, the angular dimension represents the progress made in completing the phases, and the radial dimension represents cumulative project cost. The model states that each cycle of the spiral involves the same series of steps for each part of the project.
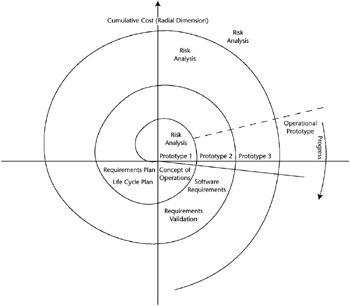
Figure 7-4: The Spiral model.
The lower-left quadrant focuses on developing plans that will be reviewed in the upper quadrants of the diagram prior to finalization of the plans. Then, after a decision to proceed with the project is made, the spiral is initiated in the upper-left quadrant. This particular quadrant defines the objectives of the part of the project being addressed, alternative means of accomplishing this part of the project, and the constraints associated with these alternatives.
The next step involves assessing the alternatives in regard to the project objectives and constraints. This assessment can include prototyping, modeling, and simulation. The purpose of this step is to identify and evaluate the risks involved, and it is shown in the upper right quadrant of the model. Once these issues are resolved, the next step in this procedure follows the traditional life cycle model approach. The lower right quadrant of the spiral depicts the final developmental phase for each part of the product. An important concept of the Spiral model is that the left horizontal axis depicts the major review that is required to complete each full cycle.
Cost Estimation Models
An early model for estimating the cost of software development projects was the Construction Cost Model (COCOMO) proposed by Barry Boehm.[*] The basic COCOMO estimates software development effort and cost as a function of the size of the software product in source instructions. It develops the following equations:
- MM, the number of man-months required to develop the most common type of software product, is given in terms of the number of thousands of delivered source instructions (KDSI) in the software product by
MM = 2.4 (KDSI)1.05
- TDEV, the development schedule in months
TDEV = 2.5(MM)0.38
In addition, Boehm has developed an Intermediate COCOMO that takes into account hardware constraints, personnel quality, use of modern tools, and other attributes and their aggregate impact on overall project costs. A Detailed COCOMO by Boehm accounts for the effects of the additional factors used in the intermediate model on the costs of individual project phases.
Another model, the function point measurement model, does not require the user to estimate the number of delivered source instructions. The software development effort is determined by using the following five user functions:
- External input types
- External output types
- Logical internal file types
- External interface file types
- External inquiry types
These functions are tallied and weighted according to complexity and used to determine the software development effort.
A third type of model applies the Rayleigh curve to software development cost and effort estimation. A prominent model using this approach is the Software Life Cycle Model (SLIM) estimating method. In this method, estimates based on the number of lines of source code are modified by the following two factors:
- The manpower buildup index (MBI), which estimates the rate of buildup of staff on the project
- A productivity factor (PF), which is based on the technology used
Information Security and the Life Cycle Model
As is the case with most engineering and software development practices, the earlier in the process a component is introduced, the better chance there is for success, lower development costs, and reduced rework. Information security is no exception. The conception, development, implementation, testing, and maintenance of information security controls should be conducted concurrently with the system software life cycle phases. This approach is conceptually shown in Figure 7-5.
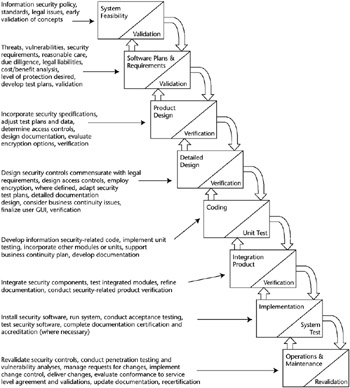
Figure 7-5: Security life cycle components.
Testing Issues
Testing of the software modules, or unit testing, should be addressed when the modules are being designed. Personnel separate from the programmers should conduct this testing. The test data is part of the specifications. Testing should not only check the modules using normal and valid input data; it should also check for incorrect types, out-of-range values, and other bounds and conditions. Live or actual field data is not recommended for use in the testing procedures because both data types may not cover out-of-range situations and the correct outputs of the test are unknown. Special test suites of data that exercise all paths of the software to the fullest extent possible and whose correct resulting outputs are known beforehand should be used.
The Software Maintenance Phase and the Change Control Process
In the life cycle models we have presented, the maintenance phase is listed at the end of the cycle with operations. One way of looking at the maintenance phase is to divide it into the following three subphases:
- Request control
- Change control
- Release control
The request control activity manages the users’ requests for changes to the software product and gathers information that can be used for managing this activity. The following steps are included in this activity:
- Establishing the priorities of requests
- Estimating the cost of the changes requested
- Determining the interface that is presented to the user
The change control process is the principal step in the maintenance phase. Issues that are addressed by change control include the following:
- Recreating and analyzing the problem
- Developing the changes and corresponding tests
- Performing quality control
In addition, there are also other considerations such as the following:
- The tool types to be used in implementing the changes
- The documentation of the changes
- The restriction of the changes’ effects on other parts of the code
- Recertification and accreditation, if necessary
Release control is associated with issuing the latest release of the software. This step involves deciding which requests will be included in the new release, archiving of the release, configuration management, quality control, distribution, and acceptance testing.
Configuration Management
In order to manage evolving changes to software products and to formally track and issue new versions of software products, configuration management is employed. According to the British Standards Institute,[*] configuration management is “the discipline of identifying the components of a continually evolving system for the purposes of controlling changes to those components and maintaining integrity and traceability throughout the life cycle.” The following definitions are associated with configuration management:
- Configuration item. A component whose state is to be recorded and against which changes are to be progressed
- Version. A recorded state of the configuration item
- Configuration. A collection of component configuration items that constitute a configuration item in some stage of its evolution (recursive)
- Building. The process of assembling a version of a configuration item from versions of its component configuration items
- Build list. The set of the versions of the component configuration items that is used to build a version of a configuration item
- Software library. A controlled area that is accessible only to approved users who are restricted to the use of approved procedures
The following procedures are associated with configuration management:
- Identify and document the functional and physical characteristics of each configuration item (configuration identification).
- Control changes to the configuration items and issue versions of configuration items from the software library (configuration control).
- Record the processing of changes (configuration status accounting).
- Control the quality of the configuration management procedures (configuration audit).
[*]W. W. Royce, “Managing the Development of Large Software Systems: Concepts and Techniques,” Proceedings, WESCON, August 1970.
[*]Software Engineering Economics, B. W. Boehm (Prentice-Hall, 1981).
[*]“Information Security Management, British Standard 7799,” British Standards Institute, U.K., 1998.
The Software Capability Maturity Model (CMM)
The Software CMM is based on the premise that the quality of a software product is a direct function of the quality of its associated software development and maintenance processes. A process is defined by the Carnegie Mellon University Software Engineering Institute (SEI) as “a set of activities, methods, practices, and transformations that people use to develop and maintain systems and associated products”.[*]
The Software CMM was first developed by the SEI in 1986 with support from the Mitre Corporation. The SEI defines five maturity levels that serve as a foundation for conducting continuous process improvement and as an ordinal scale for measuring the maturity of the organization involved in the software processes. The following are the five maturity levels and their corresponding focuses and characteristics:
- Level 1: Initiating. Competent people and heroics; processes are informal and ad hoc.
- Level 2: Repeatable. Project management processes; project management practices are institutionalized.
- Level 3: Defined. Engineering processes and organizational support; technical practices are integrated with management practices.
- Level 4: Managed. Product and process improvement; product and process are quantitatively controlled.
- Level 5: Optimizing. Continuous process improvement; process improvement is institutionalized.
In the CMM for software, software process capability “describes the range of expected results that can be achieved by following a software process.” Software process capability is a means of predicting the outcome of the next software project conducted by an organization. Software process performance is the result achieved by following a software process. Thus, software capability is aimed at expected results, while software performance is focused on results that have been achieved.
Software process maturity, then, provides for the potential for growth in capability of an organization. An immature organization develops software in a crisis mode, usually exceeds budgets and time schedules, and software processes are developed in an ad hoc fashion during the project. In a mature organization, the software process is effectively communicated to staff, the required processes are documented and consistent, software quality is evaluated, and roles and responsibilities are understood for the project.
The Software CMM is a component that supports the concept of continuous process improvement. This concept is embodied in the SEI Process Improvement IDEAL Model and is shown in Figure 7-6.
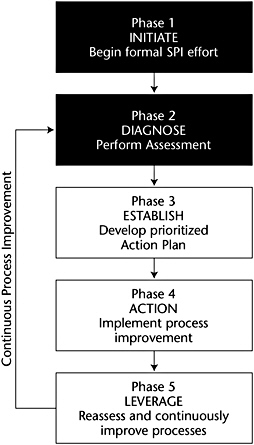
Figure 7-6: The IDEAL model.
Phase 1 of the IDEAL Model is the initiation phase in which management support is obtained for process improvement, the objectives and constraints of the process improvement effort are defined, and the resources and plans for the next phase are obtained.
Phase 2, diagnosis, identifies the appropriate appraisal method (such as CMM-based), identifies the project(s) to be appraised, trains the appraisal team, conducts the appraisal, and briefs management and the organization on the appraisal results.
In Phase 3, establishment, an action plan is developed based on the results of Phase 2, management is briefed on the action plan, and the resources and group(s) are coordinated to implement the action plan.
Phase 4 is the action phase, in which resources are recruited for implementation of the action plan, the action plan is implemented, the improvement effort is measured, and the plan and implementation are modified based on measurements and feedback.
Phase 5 is the leverage phase, which ensures that all success criteria have been achieved, all feedback is evaluated, the lessons learned are analyzed, the business plan and process improvement are compared for the desired outcome, and the next stage of the process improvement effort is planned.
The benefits of a long-term, formal software process improvement plan are as follows:
- Improved software quality
- Reduced life cycle time
- More accurate scheduling and meeting of milestones
- Management visibility
- Proactive planning and tracking
An evolution of the CMM methodology has resulted in the development of the Capability Maturity Model® Integration (CMMI®) by the SEI. As defined by the SEI, the CMMI “consists of best practices that address the development and maintenance of products and services covering the product life cycle from conception through delivery and maintenance.” The CMMI integrates the best practices and knowledge from the disciplines of software engineering, acquisition, and systems engineering. It has replaced the Software CMM.
[*]The Capability Maturity Model: Guidelines for Improving the Software Process, SEI (Addison-Wesley, 1995).
Agile Methodology
The CMMI approach represents a class of software development methodologies known as disciplined, heavyweight, or plan-driven, which focuses on the development processes used by an organization. This class also relies on detailed planning, finalizing requirements, and large amounts of documentation. An alternative technique that has emerged is called the agile methodology, also known as light or lightweight. Agile methods emphasize adaptability, flexibility, people, close interaction with the customer, short iteration cycles, constant testing, frequent delivery of code, and minimum necessary documentation. In fact, a large part of the documentation is the code itself. An agile approach strives to have enough process to successfully meet the project objectives, but not so much process that the project becomes bogged down in bureaucratic activities that do not directly contribute to the final result.
Agile methodologies have their roots in fast prototyping approaches and rapid development models. Agile or lightweight methods have the following characteristics:
- Iterative
- Self-organizing
- Incremental
- Emergence
The term emergence refers to the situation in which successful products “emerge” from large, complex projects whose outcome cannot be predicted in advance. This result is possible by having an adaptive environment where rules are used to guide individual behavior, but not the overall group. By following these rules, the composite individual behaviors combine to exhibit the desired group behavior.
A group of seventeen agile method proponents gathered at a ski resort in Utah in February 2001 and found common ground on the basic principles of the agile movement. As a result, they issued the Agile Software Development Manifesto (http://agilemanifesto.org/), which states:
“We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.”
The group called themselves the Agile Alliance and established a Web site (www.agilealliance.com/home) to promote and coordinate efforts on agile methods.
Object Oriented Systems
An object-oriented system has the potential characteristics of being more reliable and less prone to propagation of program change errors than conventional programming methods. In addition, it is effective in modeling of the “real world.” An object-oriented system can be thought of as a group of independent objects that can be requested to perform certain operations or exhibit specific behaviors. These objects cooperate to provide the system’s required functionality. The objects have an identity and can be created as the program executes (dynamic lifetime). To provide the desired characteristics of object-oriented systems, the objects are encapsulated; they can be accessed only through messages sent to them to request performance of their defined operations. The object can be viewed as a black box whose internal details are hidden from outside observation and cannot normally be modified. Grady Booch defines encapsulation as “The process of compartmentalizing the elements of an abstraction that constitute its structure and behavior; … [it] serves to separate the contractual interface of an abstraction and its implementation.” Objects also exhibit the substitution property, which means that objects providing compatible operations can be substituted for each other. According to Booch, “An object has a state, behavior, and identity.”[*]
The following definitions are fundamental to object-oriented systems:
- Message. A message is the communication to an object to carry out some operation.
- Method. A method is the code that defines the action an object performs in response to a message.
- Behavior. Behavior refers to the results exhibited by an object upon receipt of a message.
- Class. A class is a collection of the common methods of a set of objects that defines the behavior of those objects. Booch defines a class as “a set of objects that share a common structure and a common behavior.”
- Instance. Objects are instances of classes that contain their methods.
- Inheritance. Methods from a class are inherited by another subclass. Thus, the subclass inherits the behavior of the larger class, or superclass, as it is sometimes called.
- Multiple inheritance. Multiple inheritance is the situation where a class inherits the behavioral characteristics of more than one parent class.
- Delegation. Delegation is the forwarding of a request by an object to another object or delegate. This forwarding is necessitated by the fact that the object receiving the request does not have a method to fulfill the request.
- Polymorphism. According to Booch, “A name may denote objects of many different classes that are related by some common superclass; thus, any object denoted by this name is able to respond to some common set of operations in a different way.”
- Polyinstantiation. Polyinstantiation is the development of a detailed version of an object from another object using different values in the new object. In database information security, this term is concerned with the same primary key for different relations at different classification levels being stored in the same database. For example, in a relational database, the name of a military unit may be classified Secret in the database and may have an identification number as the primary key. If another user at a lower classification level attempts to create a confidential entry for another military unit using the same identification number as a primary key, a rejection of this attempt would imply to the lower-level user that the same identification number existed at a higher level of classification. To avoid this inference channel of information, the lower-level user would be issued the same identification number for his or her unit, and the database management system would manage this situation in which the same primary key was used for two different units.
Relative to the software development life cycle phases, object orientation is applied in different phases as follows:
- Object-Oriented Requirements Analysis (OORA). Defines classes of objects and their interactions.
- Object-Oriented Analysis (OOA). In terms of object-oriented concepts, understanding and modeling a particular problem within a problem domain.
- Domain Analysis (DA). According to Booch, “Whereas OOA typically focuses upon one specific problem at a time, domain analysis seeks to identify the classes and objects that are common to all applications within a given domain.”
- Object-Oriented Design (OOD). Object is the basic unit of modularity; objects are instantiations of a class.
- Object-Oriented Programming (OOP). Emphasizes the employment of objects and methods rather than types or transformations, as in other programming approaches.
A simple example of a class might be Airplane. From this class, an object representing a particular airplane, with its make, model, and registration number, can be created. A method associated with this class would be carried out when the object received a message. From this class, subclasses FighterPlane, PassengerPlane, and CargoPlane can also be derived. Messages to an Airplane object can include Climb and Descend. The subclass FighterPlane would inherit these methods from Airplane and have a few others, such as Roll, that a CargoPlane, for example, might not have.
By reusing tested and reliable objects, applications can be developed in less time and at less cost. These objects can be controlled through an object program library that controls and manages the deposit and issuance of tested objects to users. To provide protection from disclosure and violations of the integrity of objects, security controls must be implemented for the program library.
In addition, objects can be made available to users through Object Request Brokers (ORBs). The purpose of the ORB is to support the interaction of objects in heterogeneous, distributed environments. The objects may be on different types of computing platforms. Therefore, ORBs act as the locators and distributors of objects across networks. ORBs are considered middleware because they reside between two other entities. ORBs can also provide security features, or the objects can call security services. An ORB is a component of the Object Request Architecture (ORA), which is a high-level framework for a distributed environment. The other components of the ORA are as follows:
- Object services
- Application objects
- Common facilities
The ORA is a product of the Object Management Group (OMG), a nonprofit consortium in Framingham, Massachusetts, that was put together in 1989 to promote the use of object technology in distributed computing systems (www.omg.org). Object Services support the ORB in creating and tracking objects as well as performing access control functions. Application Objects and Common Facilities support the end user and use the system services to perform their functions.
The OMG has also developed a Common Object Request Broker Architecture (CORBA), which defines an industry standard that enables programs written in different languages and using different platforms and operating systems to interface and communicate. To implement this compatible interchange, a user develops a small amount of initial code and an Interface Definition Language (IDL) file. The IDL file then identifies the methods, classes, and objects that are the interface targets. For example, CORBA can enable Java code to access and use objects whose methods are written in C++.
Another standard, the Component Object Model (COM), supports the exchange of objects among programs. This capability was formerly known as Object Linking and Embedding (OLE). As in the object-oriented paradigm, COM works with encapsulated objects. Communications with a COM object are through an interface contract between an object and its clients that defines the functions that are available in the object and the behavior of the object when the functions are called. A related interface based on COM developed by Microsoft to link information among various data base management systems is OLE DB. OLE DB supports access to data at other locations irrespective of type and format.
The Distributed Component Object Model (DCOM) defines the standard for sharing objects in a networked environment.
Additional interfaces that provide access to different types of data are listed as follows:
- Java Database Connectivity (JDBC) - An application programming interface (API) that enables a Java program to access databases.
- ActiveX Data Objects (ADO) - A Microsoft high level interface developed to support the development of database-related applications, including access to various types of data in different locations and formats
- eXtensible Markup Language (XML) - a standard data format developed by the World Wide Web Consortium for creating text files of structured data that can be accessed on the Web or on intranets. XML is a markup language that supports the definition of symbols by the user. XML documents can be displayed in a wide variety of formats in different applications.
- Security Association Markup Language (SAML) - a markup language based on XML that is used to represent security credentials in a standard format
- Security Object-oriented Database (SODA) Model - a model developed to address the security issues of object-oriented systems. It employs mandatory access control concepts and assigns data classification levels through inheritance. It was developed at Pennsylvania State University by Dr. Thomas Keefe.
Some examples of object-oriented systems are Simula 67, C++, and Smalltalk. Simula 67 was the first system to support object-oriented programming, but it was not widely adopted. However, its constructs influenced other object-oriented languages, including C++. C++ supports classes, multiple inheritance, strict type checking, and user-controlled management of storage. Smalltalk was developed at the Xerox Palo Alto Research Center (PARC) as a complete system. It supports incremental development of programs and runtime type checking.
Object orientation, thus, provides an improved paradigm that represents application domains through basic component definition and interfacing. It supports the reuse of software (objects), reduces the development risks for complex systems, and is natural in its representation of real world entities.
[*]G. Booch, “Object-Oriented Development,” IEEE Transactions on Software Engineering, vol. SE-12, n. 2, February 1986, pp. 211–221.
Artificial Intelligence Systems
An alternative approach for using software and hardware to solve problems is through the use of artificial intelligence systems. These systems attempt to mimic the workings of the human mind. Two types of artificial intelligence systems are covered in this section:
- Expert systems
- Neural networks
Expert Systems
An expert system exhibits reasoning similar to that of a human expert to solve a problem. It accomplishes this reasoning by building a knowledge base of the domain to be addressed in the form of rules and an inferencing mechanism to determine whether the rules have been satisfied by the system input.
Computer programs are usually defined as:
- algorithm + data structures = program
In an expert system, the relationship is:
- inference engine + knowledge base = expert system
The knowledge base contains facts and the rules concerning the domain of the problem in the form of if-then statements. The inference engine compares information it has acquired in memory to the if portion of the rules in the knowledge base to see whether there is a match. If there is a match, the rule is ready to “fire” and is placed in a list for execution. Certain rules may have a higher priority or salience, and the system will fire these rules before others that have a lower salience.
The expert system operates in either a forward-chaining or backward-chaining mode. In a forward-chaining mode, the expert system acquires information and comes to a conclusion based on that information. Forward chaining is the reasoning approach that can be used when there are a small number of solutions relative to the number of inputs. In a backward-chaining mode, the expert system backtracks to determine whether a given hypothesis is valid. Backward chaining is generally used when there are a large number of possible solutions relative to the number of inputs.
Another type of expert system is the blackboard. A blackboard is an expert system–reasoning methodology in which a solution is generated by the use of a virtual “blackboard,” on which information or potential solutions are placed by a plurality of individuals or expert knowledge sources. As more information is placed on the blackboard in an iterative process, a solution is generated.
As with human reasoning, there is a degree of uncertainty in the conclusions of the expert system. This uncertainty can be handled through a number of approaches, such as Bayesian networks, certainty factors, or fuzzy logic.
Bayesian networks are based on Bayes’ theorem:
P{H|E} = P{E|H}*P(H)/ P(E)
that gives the probability of an event H given that an event E has occurred.
Certainty factors are easy to develop and use. These factors are the probability that a belief is true. For example, a probability of 85 percent can be assigned to Object A occurring under certain conditions.
Fuzzy logic is used to address situations where there are degrees of uncertainty concerning whether something is true or false. This situation is often the case in real-world situations. A fuzzy expert system incorporates fuzzy functions to develop conclusions. The inference engine steps in fuzzy logic are as follows:
- Fuzzification. The membership functions defined on the input variables are applied to their actual values to determine the degree of truth for each rule premise.
- Inference. The truth-value for the premise of each rule is computed and applied to the conclusion part of each rule. This results in one fuzzy subset to be assigned to each output variable for each rule.
- Composition. All the fuzzy subsets assigned to each output variable are combined together to form a single fuzzy subset for each output variable.
- Defuzzification. Used when it is useful to convert the fuzzy output set to a quantitative number. One approach to defuzzification is the centroid method. With this method, a value of the output variable is computed by finding the variable value of the center of gravity of the membership function for the fuzzy output value.
The Spiral model can be used to build an expert system. The following are the common steps when building a Spiral model:
- Analysis
- Specification
- Development
- Deployment
A key element in this process is the acquisition of knowledge. This activity involves interviewing experts in the domain field and obtaining data from other expert sources. Knowledge acquisition begins in the specification phase and runs into the development phase.
Verification and validation of an expert system are concerned with inconsistencies inherent in conflicting rules, redundant rules, circular chains of rules, and unreferenced values along with incompleteness resulting from unreferenced or unallowable data values.
Neural Networks
A neural network is based on the functioning of neurons - biological nerve cells. Signals are exchanged among neurons through electrical pulses, which first travel along the sending neuron’s axon until they arrive at connection points called synapses. When a pulse arrives at a synapse, it causes the release of a chemical neurotransmitter, which travels across the synaptic cleft to a dendrite of the receiving neuron. The neurotransmitter then causes a change in the dendrite membrane’s postsynaptic-potential (PSP). These PSPs are integrated by the neuron over time. If the integrated PSPs exceed a threshold, the neuron fires and generates an electrical pulse that travels down its axon to other neurons.
An analog of the biological neuron system is provided in Figure 7.7. Inputs Ii to the neuron are modified by weights, Wi and then summed in unit Σ. If the weighted sum exceeds a threshold, unit Σ will produce an output, Z. The functioning of this artificial neural network is shown in the following equation:
Z = W1 I1 +W2 I2 +...+ Wn I n
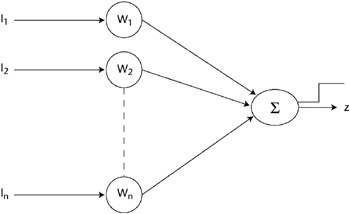
Figure 7-7: A single-layer artificial neural network.
If the sum of the weighted inputs then exceeds the threshold, the neuron will “fire” and there will be an output from that neuron. An alternative approach would be to have the output of the neuron be a linear function of the sum of the artificial neuron inputs.
Because there is only one summing node in Figure 7-7, this network is called a single-layer network. Networks with more than one level of summing nodes are called multilayer networks. The value of a neural network is its ability to dynamically adjust its weights in order to associate the given input vectors with corresponding output vectors. A training period is provided in which the neural network has the input vectors repeatedly presented and the weights dynamically adjusted according to the learning paradigm. The delta rule is an example of a learning rule. In the delta rule, the change in weight, Δij = R × Ii × (Tj – Zj) where R is the learning rate, Ii is the input vector, Tj is the target output vector, and Zj is the actual output of node Σ. For example, if a specific output vector were required for a specific input where the relationship between input and output was nonlinear, the neural network would be trained by applying a set of input vectors. Using the delta rule, the neural network would repetitively adjust the weights until it produced the correct output vector for each given input vector. The neural network would then be said to have learned to provide the correct response for each input vector.
Genetic Algorithms
Another type of artificial intelligence technology involves genetic algorithms. These algorithms are part of the general class known as evolutionary computing. Evolutionary computing uses the Darwinian principles of survival of the fittest, mutation, and the adaptation of successive generations of populations to their environment. The genetic algorithm implements this process through iteration of generations of a constant-size population of items or individuals. Each individual is characterized by a finite string of symbols called genomes. The genomes are used to represent possible solutions to a problem in a fixed search space. For example, if the fixed population of the first generation of individuals consists of random binary numbers and the problem is to find the minimum binary number that can be represented by an individual, each binary number is assigned a fitness value based on the individual’s binary number value. The smaller the binary number represented by a parent individual, the higher the level of fitness that is assigned to it. Through cross-breeding among the numbers (known as crossover), mutations of the numbers, and pairing of the numbers with high fitness ratings, the smallest value that can be represented by the number of bits in the binary number will emerge in later generations.
Knowledge Management
The term knowledge management refers to acquiring, maintaining, and using information comprising the “corporate memory” of an organization. This data can be stored in corporate databases, reside in employee knowledge, and be contained in other important organizational documents. A related concept is that of Knowledge Discovery Databases (KDD), which utilizes a variety of mathematical and automated analysis techniques to detect patterns in stored data and find solutions to critical problems.
Database Systems
A database system can be used as a general mechanism for defining, storing, and manipulating data without writing specific programs to perform these functions. A database management system (DBMS) provides high-level commands to operate on the data in the database. Some of the different types of databases are as follows:
- Hierarchical
- Mesh
- Object-oriented
- Relational
Much research on information security has been done with relational databases. The information security applications of relational databases are discussed in Chapter 2.
Database Security Issues
In a relational database, security can be provided through the use of views. A view is a virtual relation that combines information from other relations. A view can be used to restrict the data made available to users based on their privileges and need to know. A database information security vulnerability can be exploited through the DBMS. Designed to facilitate queries to the database, the DBMS can be a possible source of data compromise by circumventing the normal security controls. This type of intrusion is sometimes known as a bypass attack. In a related attempt to gain unauthorized access to data in the database, a query attack involves the use of query tools to view data normally protected by a trusted front end. The granularity of the access to objects in a database refers to the fineness in which this access can be controlled or limited. Other database security issues are aggregation and inference. Aggregation is the act of obtaining information of a higher sensitivity by combining information from lower levels of sensitivity. Inference is the ability of users to infer or deduce information about data at sensitivity levels for which they do not have access privileges. A link that enables inference to occur is called an inference channel.
Open Database Connectivity (ODBC) is a Microsoft-developed standard for supporting access to databases through different applications. This access must be controlled to avoid compromising the database.
Data Warehouse and Data Mining
A data warehouse is a repository of information from heterogeneous databases that is available to users for making queries. A more formal definition of a data warehouse is given by Bill Inmon, a pioneer in the field. He defines a data warehouse as a “subject-oriented, integrated, time-variant, non-volatile collection of data in support of management’s decision-making process.”
To create a data warehouse, data is taken from an operational database, redundancies are removed, and the data is “cleaned up” in general. This activity is referred to as normalizing the data. Then the data is placed into a relational database and can be analyzed by using On-Line Analytical Processing (OLAP) and statistical modeling tools. OLAP supports sorting through the data using sets of queries and collecting the necessary information to be analyzed. The data warehouse can be used as a Decision Support System (DSS), for example, by performing a time series analysis of the data. The data in the data warehouse must be maintained to ensure that it is timely and valid. The term data scrubbing refers to maintenance of the data warehouse by deleting information that is unreliable or no longer relevant.
A data mart is a database that comprises data or relations that have been extracted from the data warehouse. Information in the data mart is usually of interest to a particular group of people. For example, a data mart can be developed for all health care–related data. Searching among the data in the warehouse for data correlations and relationships that were unknown up until now is called data mining. The correlations or “data about data” are referred to as metadata. The information obtained from the metadata should, however, be sent back for incorporation into the data warehouse to be available for future queries and metadata analyses. The Dublin (Ohio) Core Metadata Initiative (DCMI) has developed a standard that addresses retrieval of information from various Internet sources. Data mining can be applied to information system security as an intrusion detection tool to discover abnormal system characteristics in order to determine whether there are aggregation or inference problems and for analyzing audit information.
Data Dictionaries
A data dictionary is a database for system developers. It records all the data structures used by an application. Advanced data dictionaries incorporate application generators that use the data stored in the dictionary to automate some of the program production tasks. The data dictionary interacts with the DBMS, the program library, applications, and the information security system. In some instances, the data dictionary system is organized into a primary data dictionary and one or more secondary data dictionaries. The primary data dictionary provides a baseline of data definitions and central control, and the secondary data dictionaries are assigned to separate development projects to provide backup to the primary dictionary and to serve as a partition between the development and test databases.
Application Controls
The goal of application controls is to enforce the organization’s security policy and procedures and to maintain the confidentiality, integrity, and availability of the computer-based information. Application security involves the input to the system, the data being processed, and the output of the system. The controls can be classified into preventive, detective, and corrective measures that apply to different security categories. These controls and categories are listed in Table 7-1.
|
APPLICATION CONTROL TYPE |
ACCURACY |
SECURITY |
CONSISTENCY |
|---|---|---|---|
|
Preventive |
Data checks, forms, custom screens, validity checks, contingency planning, backups |
Firewalls, reference monitors, sensitivity labels, traffic padding, encryption, data classification, one-time passwords, contingency planning, separation of development, application and test environments |
Data dictionary, programming standards, and database management system |
|
Detective |
Cyclic redundancy checks, structured walk-throughs, hash totals, and reasonableness checks |
Intrusion detection systems and audit trails |
Comparison controls, relationship tests, and reconciliation controls |
|
Corrective |
Backups, control reports, before/after imaging reporting, and checkpoint restarts |
Emergency response and reference monitor |
Program comments and database controls |
 Open table as spreadsheet
Open table as spreadsheetUsers running applications require the availability of the system. A service level agreement (SLA) guarantees the quality of a service to a subscriber by a network service provider. Defined service levels provide a basis for measuring the delivered services and are useful in anticipating, identifying, and correcting problems. Some of the metrics in service-level agreements are as follows:
- Turnaround times
- Average response times
- Number of online users
- System utilization rates
- System up times
- Volume of transactions
- Production problems
Distributed Systems
Distributed systems are commonplace and pose special challenges to information systems security implementation. Security in distributed systems should include access control mechanisms, identification, authentication, some type of intrusion detection capability, emergency response plans, logs, and audit trails.
The client/server model implements a type of distributed system. In this model, the client requests services and the server provides the requested service. The client provides the interface to the user, supports the entry of information, and provides the reports. The server provides access to data, holds the databases, provides data to the client, performs backups, and provides security services.
Distributed environments support agents. An agent is a surrogate program or process performing services in one environment on behalf of a principal in another environment. This behavior differs from that of a proxy in that a proxy acts on behalf of a principal, but it may hide the characteristics of that principal. Similarly, applets are small applications that may be written in various languages, which include C++ and Java. Both of these languages are object-oriented. C++ was developed at Bell Laboratories and is an extension of C. Java is a multithreaded, interpreted language that was developed at Sun Microsystems. A thread is considered a lightweight process and has a lower overhead for maintaining state and switching contexts. Multiple threads run in the protection domain of a task or process, and they share a single address space. An interpreted language executes each instruction in real-time. This action is referred to as run-time binding. A compiled language has all the high-level instructions translated into machine code (object code) by a compiler. Then the computer executes the code. With a compiler, the binding occurs at compile time. Compiled code poses more of a security risk than interpreted code because malicious code can be embedded in the compiled code and can be difficult to detect.
Java has some of the characteristics of both compiled and interpreted languages. Java code is converted (“compiled”) to byte code, which is independent of the underlying physical computer’s instruction set. The byte code is interpreted on different machines by the Java Virtual Machine (JVM), which is compiled for each kind of machine to run on that particular piece of hardware.
Applets can be accessed and downloaded from the World Wide Web (WWW) into a Web browser such as Netscape. This applet can execute in the network browser and may contain malicious code. These types of downloadable programs are also known as mobile code. For protection of the system, Java is designed to run applets in a constrained space in the client Web browser called a sandbox. A sandbox is an access control–based protection mechanism. The Java sandbox restricts the access that Java applets have to memory as well as other machine privileges. Java sandbox security is implemented by a Java security manager, a class loader, and verifier, also known as an interpreter. The security manager provides oversight and protection against Java code attempting to act maliciously, while the verifier provides memory protection, type checking, and bounds checking. The class loader dynamically loads and unloads classes from the run-time processes.
The Microsoft ActiveX environment also supports the downloading of mobile code (ActiveX controls) written in languages such as Visual BASIC or C++ to Web browsers, and thus has the potential for causing harm to a system. Instead of the restrictions of the Java sandbox, ActiveX establishes a trust relationship between the client and the server through the use of digital certificates, guaranteeing that the server is trusted. Recently, Java has begun to incorporate trusted code mechanisms into its applets, which can then be given greater privileges on the host machine. Some security controls that can be applied to mitigate the effects of malicious mobile code are as follows:
- Configure firewalls to screen applets.
- Configure Web browsers to restrict or prevent the downloading of applets.
- Configure Web browsers to permit the receipt of applets only from trusted servers.
- Provide training to users to make them aware of mobile code threats.
A client/server implementation approach in which any platform can act as a client or server or both is called peer-to-peer.
Centralized Architecture
A centralized system architecture is less difficult to protect than a distributed system architecture because, in the latter, the components are interconnected through a network. Centralized systems provide for implementation of the local security and application system controls, whereas distributed systems have to deal with geographically separate entities communicating via a network or through many networks.
Real Time Systems
Another system classification, based on temporal considerations rather than on architectural characteristics, is that of real-time systems. Real-time systems operate by acquiring data from transducers or sensors in real time and then making computations and control decisions in a fixed time window. An example of such a system would be a “fly by wire” control of supersonic aircraft, where adjustment of the plane’s control surfaces is time-critical. Availability is crucial for such systems and, as such, can be addressed through Redundant Array of Independent Disks (RAID) technology, disk mirroring, disk duplexing, fault-tolerant systems, and recovery mechanisms to cope with system failures. In disk mirroring, a duplicate of the disk is used, and in disk duplexing, the disk controller is backed up with a redundant controller. A fault-tolerant system has to detect a fault and then take action to recover from that fault.
Assessment Questions
You can find the answers to the following questions in Appendix A.
|
1. |
What is a data warehouse?
|
|
|
2. |
What does normalizing data in a data warehouse mean?
|
|
|
3. |
What is a neural network?
|
|
|
4. |
A neural network learns by using various algorithms to:
|
|
|
5. |
The SEI Software Capability Maturity Model is based on the premise that:
|
|
|
6. |
In configuration management, a configuration item is:
|
|
|
7. |
In an object-oriented system, polymorphism denotes:
|
|
|
8. |
The simplistic model of software life cycle development assumes that:
|
|
|
9. |
What is a method in an object-oriented system?
|
|
|
10. |
What does the Spiral model depict?
|
|
|
11. |
In the software life cycle, verification:
|
|
|
12. |
In the software life cycle, validation:
|
|
|
13. |
In the modified Waterfall model:
|
|
|
14. |
Cyclic redundancy checks, structured walk-throughs, and hash totals are examples of what type of application controls?
|
|
|
15. |
In a system life cycle, information security controls should be:
|
|
|
16. |
The software maintenance phase controls consist of:
|
|
|
17. |
In configuration management, what is a software library?
|
|
|
18. |
What is configuration control?
|
|
|
19. |
What is searching for data correlations in the data warehouse called?
|
|
|
20. |
The security term that is concerned with the same primary key existing at different classification levels in the same database is:
|
|
|
21. |
What is a data dictionary?
|
|
|
22. |
Which of the following is an example of mobile code?
|
|
|
23. |
Which of the following is not true regarding software unit testing?
|
|
|
24. |
The definition “the science and art of specifying, designing, implementing, and evolving programs, documentation, and operating procedures whereby computers can be made useful to people” is that of:
|
|
|
25. |
In software engineering, the term verification is defined as:
|
|
|
26. |
The discipline of identifying the components of a continually evolving system for the purposes of controlling changes to those components and maintaining integrity and traceability throughout the life cycle is called:
|
|
|
27. |
The basic version of the Construction Cost Model (COCOMO), which proposes quantitative life cycle relationships, performs what function?
|
|
|
28. |
A refinement to the basic Waterfall model that states that software should be developed in increments of functional capability is called:
|
|
|
29. |
The Spiral model of the software development process uses which of the following metrics relative to the spiral?
|
|
|
30. |
In the Capability Maturity Model (CMM) for software, the definition “describes the range of expected results that can be achieved by following a software process” is that of:
|
|
Answers
|
1. |
Answer: b A data warehouse is a repository of information from heterogeneous databases. Answers a and d describe physical facilities for backup and recovery of information systems, and answer c describes a relation in a relational database. |
|
2. |
Answer: a The correct answer is a, removing redundant data. |
|
3. |
Answer: d A neural network is a hardware or software system that emulates the functioning of biological neurons. Answer a refers to an expert system, and answers b and c are distracters. |
|
4. |
Answer: a A neural network learns by using various algorithms to adjust the weights applied to the data. Answers b, c, and d are terminology referenced in expert systems. |
|
5. |
Answer: c The quality of a software product is a direct function of the quality of its associated software development and maintenance processes. Answer a is false because the SEI Software CMM relates the production of good software to having the proper processes in place in an organization and not to expert programs or heroes. Answer b is false because the Software CMM provides means to measure the maturity of an organization’s software processes. Answer d is false for the same reason as answer b. |
|
6. |
Answer: b A configuration item is a component whose state is to be recorded and against which changes are to be progressed. Answers a, c, and d are incorrect by the definition of a configuration item. |
|
7. |
Answer: a Polymorphism refers to objects of many different classes that are related by some common superclass that are able to respond to some common set of operations, defined for the superclass, in different ways depending on their particular subclasses. Answers b, c, and d are incorrect by the definition of polymorphism. |
|
8. |
Answer: b The simplistic model assumes that each step can be completed and finalized without any effect from the later stages that might require rework. Answer a is incorrect because no iteration is allowed for in the model. Answer c is incorrect because it applies to the modified Waterfall model. Answer d is incorrect because no iteration or reworking is considered in the model. |
|
9. |
Answer: c A method in an object-oriented system is the code that defines the actions that the object performs in response to a message. Answer a is incorrect because it defines a message. Answer b is a distracter, and answer d refers to multiple inheritance. |
|
10. |
Answer: a The spiral in the Spiral model incorporates various phases of software development. The other answers are distracters. |
|
11. |
Answer: d In the software life cycle, verification evaluates the product in development against the specification. Answer a defines validation. Answers b and c are distracters. |
|
12. |
Answer: a In the software life cycle, validation is the work product satisfying the real-world requirements and concepts. The other answers are distracters. |
|
13. |
Answer: b The modified Waterfall model was reinterpreted to have phases end at project milestones. Answer a is false because unlimited backward iteration is not permitted in the modified Waterfall model. Answer c is a distracter, and answer d is false because verification and validation are included. |
|
14. |
Answer: c Cyclic redundancy checks, structured walkthroughs, and hash totals are examples of detective accuracy controls. The other answers do not apply by the definition of the types of controls. |
|
15. |
Answer: c In the system life cycle, information security controls should be part of the feasibility phase. The other answers are incorrect because the basic premise of information system security is that controls should be included in the earliest phases of the software life cycle and not added later in the cycle or as an afterthought. |
|
16. |
Answer: a The software maintenance phase controls consist of request control, change control, and release control, by definition. The other answers are, therefore, incorrect. |
|
17. |
Answer: b In configuration management, a software library is a controlled area, accessible only to approved users who are restricted to the use of approved procedure. Answer a is incorrect because it defines a build list. Answer c is incorrect because it defines a backup storage facility. Answer d is a distracter. |
|
18. |
Answer: b Configuration control consists of controlling changes to the configuration items and issuing versions of configuration items from the software library. Answer a is the definition of configuration identification. Answer c is the definition of configuration status accounting, and answer d is the definition of configuration audit. |
|
19. |
Answer: b Searching for data correlations in the data warehouse is called data mining. Answer a is incorrect because data warehousing is creating a repository of information from heterogeneous databases that is available to users for making queries. Answer c is incorrect because a data dictionary is a database for system developers. Answer d is incorrect because configuration management is the discipline of identifying the components of a continually evolving system for the purposes of controlling changes to those components and maintaining integrity and traceability throughout the life cycle. |
|
20. |
Answer: d The security term that is concerned with the same primary key existing at different classification levels in the same database is polyinstantiation. Answer a is incorrect because polymorphism is defined as objects of many different classes that are related by some common superclass so that any object denoted by this name is able to respond in its own way to some common set of operations. Answer b is incorrect because normalization refers to removing redundant or incorrect data from a database. Answer c is incorrect because inheritance refers to methods from a class inherited by a subclass. |
|
21. |
Answer: a A data dictionary is a database for system developers. Answers b, c, and d are distracters. |
|
22. |
Answer: c Examples of mobile code are Java applets and ActiveX controls downloaded into a Web browser from the World Wide Web. Answers a, b, and d are incorrect because they are types of code that are not related to mobile code. |
|
23. |
Answer: c Live or actual field data are not recommended for use in testing, because they do not thoroughly test all normal and abnormal situations, and the test results are not known beforehand. Answers a, b, and d are true of testing. |
|
24. |
Answer: b The definition of software engineering in answer b is a combination of popular definitions of engineering and software. One definition of engineering is “the application of science and mathematics to the design and construction of artifacts that are useful to people.” A definition of software is that it “consists of the programs, documentation and operating procedures by which computers can be made useful to people.” Answer a, SA/SD, deals with developing specifications that are abstractions of the problem to be solved and are not tied to any specific programming languages. Thus, SA/SD, through data flow diagrams (DFDs), shows the main processing entities and the data flow between them without any connection to a specific programming language implementation. An object-oriented system (answer c) is a group of independent objects that can be requested to perform certain operations or exhibit specific behaviors. These objects cooperate to provide the system’s required functionality. The objects have an identity and can be created as the program executes (dynamic lifetime). To provide the desired characteristics of object-oriented systems, the objects are encapsulated (i.e., they can be accessed only through messages sent to them to request performance of their defined operations). The object can be viewed as a black box whose internal details are hidden from outside observation and cannot normally be modified. Objects also exhibit the substitution property, which means that objects providing compatible operations can be substituted for each other. In summary, an object-oriented system contains objects that exhibit the following properties:
Answer d, functional programming, uses only mathematical functions to perform computations and solve problems. This approach is based on the assumption that any algorithm can be described as a mathematical function. Functional languages have the characteristics that:
|
|
25. |
Answer: a In the Waterfall model (W. W. Royce, “Managing the Development of Large Software Systems: Concepts and Techniques,” Proceedings, WESCON, August 1970), answer b defines the term requirements. Similarly, answer c defines the term validation, and answer d is the definition of product design. In summary, the steps of the Waterfall model are:
In this model, each phase finishes with a verification and validation (V&V) task that is designed to eliminate as many problems as possible in the results of that phase. |
|
26. |
Answer: d Answer d is correct, as is demonstrated in Configuration Management of Computer-Based Systems (British Standards Institution, 1984). Answers a, b, and c are components of the maintenance activity of software life cycle models. In general, one can look at the maintenance phase as the progression from request control, through change control, to release control. Request control (answer b) is involved with the users’ requests for changes to the software. Change control (answer a) involves the analysis and understanding of the existing code, the design of changes, and the corresponding test procedures. Release control (answer c) involves deciding which requests are to be implemented in the new release, performing the changes, and conducting testing. |
|
27. |
Answer: b The Basic COCOMO Model, set forth in Software Engineering Economics, B. W. Boehm (Prentice-Hall, 1981), proposes two equations that compute the number of man-months and the development schedule in months needed to develop a software product, given the number of thousands of delivered source instructions (KDSI) in the product. In addition, Boehm has developed an intermediate COCOMO Model that takes into account hardware constraints, personnel quality, use of modern tools, and other attributes and their aggregate impact on overall project costs. A detailed COCOMO Model, also by Boehm, accounts for the effects of the additional factors used in the intermediate model on the costs of individual project phases. Answer b describes a function point measurement model that does not require the user to estimate the number of delivered source instructions. The software development effort is determined using the follow-ing five user functions:
These functions are tallied and weighted according to complexity and used to determine the software development effort. Answer c describes the Rayleigh curve applied to software development cost and effort estimation. A prominent model using this approach is the Software Life Cycle Model (SLIM) estimating method. In this method, estimates based on the number of lines of source code are modified by the following two factors:
Answer d is a distracter. |
|
28. |
Answer: d The advantages of incremental development include the ease of testing increments of functional capability and the opportunity to incorporate user experience into a successively refined product. Answers a, b, and c are distracters. |
|
29. |
Answer: d The radial dimension represents cumulative cost, and the angular dimension represents progress made in completing each cycle of the spiral. The Spiral model is actually a meta-model for software development processes. A summary of the stages in the spiral is as follows:
Answers a, b, and c are distracters. |
|
30. |
Answer: b A software process is a set of activities, methods, and practices that are used to develop and maintain software and associated products. Software process capability is a means of predicting the outcome of the next software project conducted by an organization. Software process performance (answer c) is the result achieved by following a software process. Thus, software capability is aimed at expected results while software performance is focused on results that have been achieved. Software process maturity (answer d) is the extent to which a software process is:
Software process maturity, then, provides for the potential for growth in capability of an organization. An immature organization develops software in a crisis mode, usually exceeds budgets and time schedules, and develops software processes in an ad hoc fashion during the project. In a mature organization, the software process is effectively communicated to staff, the required processes are documented and consistent, software quality is evaluated, and roles and responsibilities are understood for the project. Answer a is a distracter, but it is discussed in question 24. |
Part One - Focused Review of the CISSP Ten Domains
- Information Security and Risk Management
- Access Control
- Telecommunications and Network Security
- Cryptography
- Security Architecture and Design
- Operations Security
- Application Security
- Business Continuity Planning and Disaster Recovery Planning
- Legal, Regulations, Compliance, and Investigations
- Physical (Environmental) Security
Part Two - The Certification and Accreditation Professional (CAP) Credential
- Understanding Certification and Accreditation
- Initiation of the System Authorization Process
- The Certification Phase
- The Accreditation Phase
- Continuous Monitoring Process
- Appendix A Answers to Assessment Questions
- Appendix B Glossary of Terms and Acronyms
- Appendix C The Information System Security Architecture Professional (ISSAP) Certification
- Appendix D The Information System Security Engineering Professional (ISSEP) Certification
- Appendix E The Information System Security Management Professional (ISSMP) Certification
- Appendix F Security Control Catalog
- Appendix G Control Baselines
EAN: 2147483647
Pages: 239
