Entity-centric business service design (a step-by-step process)
Entity-centric business services represent the one service layer that is the least influenced by others. Its purpose is to accurately represent corresponding data entities defined within an organization's business models. These services are strictly solution- and business process-agnostic, built for reuse by any application that needs to access or manage information associated with a particular entity.
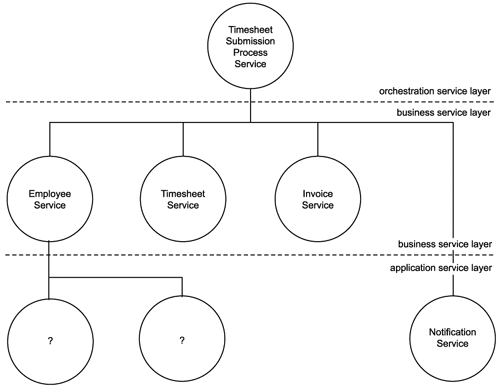
Figure 15.1. Entity-centric services establish the business service layer.
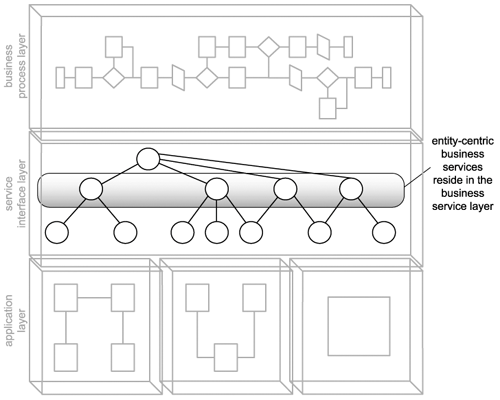
Because they exist rather atomically in relation to other service layers, it is beneficial to design entity-centric business services prior to others. This establishes an abstract service layer around which process and underlying application logic can be positioned.
15.2.1. Process description
Provided next is the step-by-step process description wherein we establish a recommended sequence of detailed steps for arriving at a quality entity-centric business service interface (Figure 15.2).
Figure 15.2. The entity-centric business service design process.
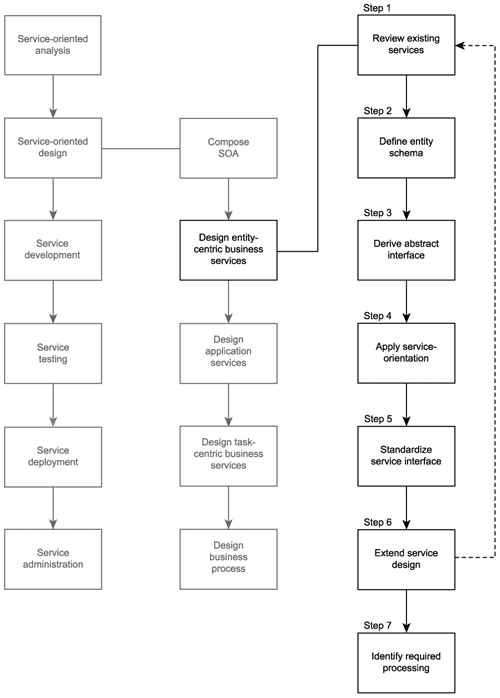
Note that the order in which these steps are provided is not set in stone. For example, you may prefer to define a preliminary service interface prior to establishing the actual data types used to represent message body content. Or perhaps you may find it more effective to perform a speculative analysis to identify possible extensions to the service before creating the first cut of the interface.
All of these can be legitimate approaches. The key is to ensure that in the end, design standards are applied equally to all service operations and that all processing requirements are accurately identified.
Let's begin now with the design of our entity-centric business service.
Step 1: Review existing services
Ideally, when creating entity-centric services, the modeling effort resulting in the service candidates will have taken any existing services into account. However, because service candidates tend to consist of operation candidates relevant to the business requirements that formed the basis of the service-oriented analysis, it is always worth verifying to ensure that some or all of the processing functionality represented by operation candidates does not already exist in other services.
Therefore, the first step in designing a new service is to confirm whether it is actually even necessary. If other services exist, they may already be providing some or all of the functionality identified in the operation candidatesorthey may have already established a suitable context in which these new operation candidates can be implemented (as new operations to the existing service).
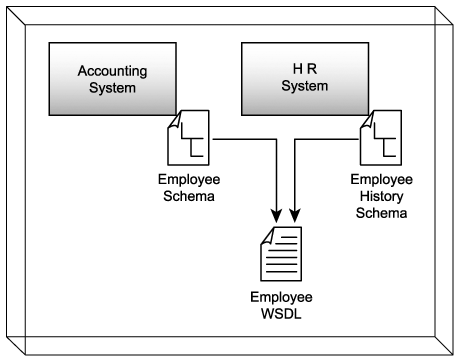
Step 2: Define the message schema types
It is useful to begin a service interface design with a formal definition of the messages the service is required to process. To accomplish this we need to formalize the message structures that are defined within the WSDL types area.
SOAP messages carry payload data within the Body section of the SOAP envelope. This data needs to be organized and typed. For this we rely on XSD schemas. A standalone schema actually can be embedded in the types construct, wherein we can define each of the elements used to represent data within the SOAP body.
In the case of an entity-centric service, it is especially beneficial if the XSD schema used accurately represents the information associated with this service's entity. This "entity-centric schema" can become the basis for the service WSDL definition, as most service operations will be expected to receive or transmit the documents defined by this schema.
Note that there is not necessarily a one-to-one relationship between entity-centric services and the entities that comprise an entity model. You might recall in the service modeling example from Chapter 12, we combined Employee and EmployeeHistory entities into one Employee Service. In this case, you can either create two separate schemas or combine them into one. The latter option is recommended only if you are confident you will never want to split these entities up again.
Note
As demonstrated in the upcoming example, the WSDL definition can import schemas into the types area. This can be especially beneficial when working with standardized schemas that represent entities. (See the Consider using modular WSDL documents guideline for more information.)
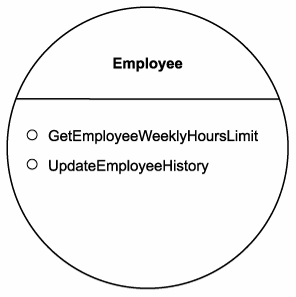
Step 3: Derive an abstract service interface
Next, we analyze the proposed service operation candidate and follow these steps to define an initial service interface:
- Confirm that each operation candidate is suitably generic and reusable by ensuring that the granularity of the logic encapsulated is appropriate. Study the data structures defined in Step 2 and establish a set of operation names.
- Create the portType (or interface) area within the WSDL document and populate it with operation constructs that correspond to operation candidates.
- Formalize the list of input and output values required to accommodate the processing of each operation's logic. This is accomplished by defining the appropriate message constructs that reference the XSD schema types within the child part elements.
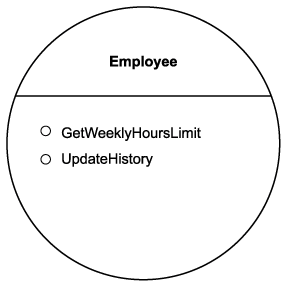
Step 4: Apply principles of service-orientation
Here's where we revisit the four service-orientation principles we identified in Chapter 8 as being those not provided by the Web services technology set:
- service reusability
- service autonomy
- service statelessness
- service discoverability
Reusability and autonomy, the two principles we already covered in the service modeling process, are somewhat naturally part of the entity-centric design model in that the operations exposed by entity-centric business services are intended to be inherently generic and reusable (and because the use of the import statement is encouraged to reuse schemas and create modular WSDL definitions). Reusability is further promoted in Step 6, where we suggest that the design be extended to facilitate requirements beyond those identified as part of our service candidate.
Because entity-centric services often need to be composed by a parent service layer and because they rely on the application service layer to carry out their business logic, their immediate autonomy is generally well defined. Unless those services governed by an entity-centric controller have unusual processing requirements or impose dependencies in some manner, entity-centric services generally maintain their autonomy.
It is for similar reasons as those just mentioned that statelessness is also relatively manageable. Entity-centric services generally do not possess a great deal of workflow logic and for those cases in which multiple application or business services need to be invoked to carry out an operation, it is preferred that state management be deferred as much as possible (to, for example, document-style SOAP messages).
Discoverability is an important part of both the design of entity-centric services and their post-deployment utilization. As we mentioned in Step 1, we need to ensure that a service design does not implement logic already in existence. A discovery mechanism would make this determination much easier. Similarly, one measure we can take to make a service more discoverable to others is to supplement it with metadata details using the documentation element, as explained in the Document services with metadata guideline.
Step 5: Standardize and refine the service interface
Depending on your requirements, this can be a multi-faceted step involving a series of design tasks. Following is a list of recommended actions you can take to achieve a standardized and streamlined service design:
- Review existing design standards and guidelines and apply any that are appropriate. (Use the guidelines and proposed standards provided at the end of this chapter as a starting point.)
- In addition to achieving a standardized service interface design, this step also provides an opportunity for the service design to be revised in support of some of the contemporary SOA characteristics we identified in the Unsupported SOA characteristics section of Chapter 9.
- If your design requirements include WS-I Basic Profile conformance, then that can become a consideration at this stage. Although Basic Profile compliance requires that the entire WSDL be completed, what has been created so far can be verified.
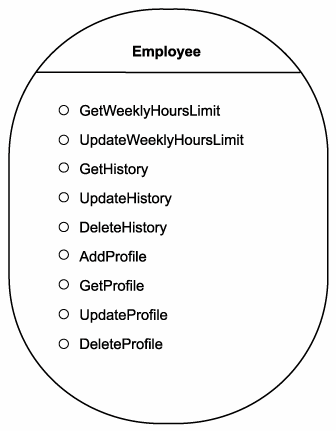
Step 6: Extend the service design
The service modeling process tends to focus on evident business requirements. While promoting reuse always is encouraged, it often falls to the design process to ensure that a sufficient amount of reusable functionality will be built into each service. This is especially important for entity-centric business services, as a complete range of common operations typically is expected by their service requestors.
This step involves performing a speculative analysis as to what other types of features this service, within its predefined functional context, should offer.
There are two common ways to implement new functionality:
- add new operations
- add new parameters to existing operations
While the latter option may streamline service interfaces, it also can be counter-intuitive in that too many parameters associated with one operation may require that service requestors need to know too much about the service to effectively utilize it.
Adding operations is a straight-forward means of providing evident functions associated with the entity. The classic set of operations for an entity-centric service is:
- GetSomething
- UpdateSomething
- AddSomething
- DeleteSomething
Security requirements notwithstanding, establishing these standard operations builds a consistent level of interoperability into the business service layer, facilitating ad-hoc reusability and composition.
Note
Despite the naming suggestions listed here, when designing business services to reflect existing entity models, it is often beneficial to carry over the naming conventions already established (even if this means adjusting existing naming standards accordingly).
If entirely new tasks are defined, then they can be incorporated by new operations that follow the same design standards as the existing ones. If new functional requirements are identified that relate to existing operations, then a common method of extending these operations is to add input and output values. This allows an operation to receive and transmit a range of message combinations. Care must be taken, though, to not overly complicate operations for the sake of potential reusability. It often is advisable to subject any new proposed functionality to a separate analysis process.
Also, while it is desirable and recommended to produce entity-centric services that are completely self-sufficient at managing data associated with the corresponding entity domain, there is a key practical consideration that should be factored in. For every new operation you add, the means by which that operation completes its processing also needs to be designed and implemented. This boils down to the very probable requirement for additional or extended application services. As long as the overhead for every new operation is calculated and deemed acceptable, then this step is advisable.
Note that upon identifying new operations, Steps 1 through 5 need to be repeated to properly shape and standardize added extensions.
Step 7: Identify required processing
While the service modeling process from our service-oriented analysis may have identified some key application services, it may not have been possible to define them all.
Now that we have an actual design for this new business service, you can study the processing requirements of each of its operations more closely. In doing so, you should be able to determine if additional application services are required to carry out each piece of exposed functionality. If you do find the need for new application services, you will have to determine if they already exist, or if they need to be added to the list of services that will be delivered as part of this solution.
|
SUMMARY OF KEY POINTS |
|---|
|
Introduction
- Why this book is important
- Objectives of this book
- Who this book is for
- What this book does not cover
- How this book is organized
- Additional information
Case Studies
- Case Studies
- How case studies are used
- Case #1 background: RailCo Ltd.
- Case #2 background: Transit Line Systems Inc.
Part I: SOA and Web Services Fundamentals
Introducing SOA
- Introducing SOA
- Fundamental SOA
- Common characteristics of contemporary SOA
- Common misperceptions about SOA
- Common tangible benefits of SOA
- Common pitfalls of adopting SOA
The Evolution of SOA
- The Evolution of SOA
- An SOA timeline (from XML to Web services to SOA)
- The continuing evolution of SOA (standards organizations and contributing vendors)
- The roots of SOA (comparing SOA to past architectures)
Web Services and Primitive SOA
- Web Services and Primitive SOA
- The Web services framework
- Services (as Web services)
- Service descriptions (with WSDL)
- Messaging (with SOAP)
Part II: SOA and WS-* Extensions
Web Services and Contemporary SOA (Part I: Activity Management and Composition)
- Web Services and Contemporary SOA (Part I: Activity Management and Composition)
- Message exchange patterns
- Service activity
- Coordination
- Atomic transactions
- Business activities
- Orchestration
- Choreography
Web Services and Contemporary SOA (Part II: Advanced Messaging, Metadata, and Security)
- Web Services and Contemporary SOA (Part II: Advanced Messaging, Metadata, and Security)
- Addressing
- Reliable messaging
- Correlation
- Policies
- Metadata exchange
- Security
- Notification and eventing
Part III: SOA and Service-Orientation
Principles of Service-Orientation
- Principles of Service-Orientation
- Service-orientation and the enterprise
- Anatomy of a service-oriented architecture
- Common principles of service-orientation
- How service-orientation principles inter-relate
- Service-orientation and object-orientation (Part II)
- Native Web service support for service-orientation principles
Service Layers
- Service Layers
- Service-orientation and contemporary SOA
- Service layer abstraction
- Application service layer
- Business service layer
- Orchestration service layer
- Agnostic services
- Service layer configuration scenarios
Part IV: Building SOA (Planning and Analysis)
SOA Delivery Strategies
- SOA Delivery Strategies
- SOA delivery lifecycle phases
- The top-down strategy
- The bottom-up strategy
- The agile strategy
Service-Oriented Analysis (Part I: Introduction)
- Service-Oriented Analysis (Part I: Introduction)
- Service-oriented architecture vs. Service-oriented environment
- Introduction to service-oriented analysis
- Benefits of a business-centric SOA
- Deriving business services
Service-Oriented Analysis (Part II: Service Modeling)
- Service-Oriented Analysis (Part II: Service Modeling)
- Service modeling (a step-by-step process)
- Service modeling guidelines
- Classifying service model logic
- Contrasting service modeling approaches (an example)
Part V: Building SOA (Technology and Design)
Service-Oriented Design (Part I: Introduction)
- Service-Oriented Design (Part I: Introduction)
- Introduction to service-oriented design
- WSDL-related XML Schema language basics
- WSDL language basics
- SOAP language basics
- Service interface design tools
Service-Oriented Design (Part II: SOA Composition Guidelines)
- Service-Oriented Design (Part II: SOA Composition Guidelines)
- Steps to composing SOA
- Considerations for choosing service layers
- Considerations for positioning core SOA standards
- Considerations for choosing SOA extensions
Service-Oriented Design (Part III: Service Design)
- Service-Oriented Design (Part III: Service Design)
- Service design overview
- Entity-centric business service design (a step-by-step process)
- Application service design (a step-by-step process)
- Task-centric business service design (a step-by-step process)
- Service design guidelines
Service-Oriented Design (Part IV: Business Process Design)
- Service-Oriented Design (Part IV: Business Process Design)
- WS-BPEL language basics
- WS-Coordination overview
- Service-oriented business process design (a step-by-step process)
Fundamental WS-* Extensions
- Fundamental WS-* Extensions
- You mustUnderstand this
- WS-Addressing language basics
- WS-ReliableMessaging language basics
- WS-Policy language basics
- WS-MetadataExchange language basics
- WS-Security language basics
SOA Platforms
Appendix A. Case Studies: Conclusion
EAN: 2147483647
Pages: 150
