Chapter 23: Parser Generation with flex and bison
In This Chapter
-
An Introduction to Lexical Analysis
-
An Introduction to Parser Generation
-
Lexer and Parser Integration
Introduction
The topic of parser construction using two very well-known tools will be the focus of this chapter. We ll take a quick tour of lexical analysis and grammar processing and then investigate the respective tools. We ll investigate a few examples, including a simple firewall configuration parser. The flex (fast lexical analyzer generator) and bison (GNU parser generator) will be the focus of this chapter.
Lexical Analysis and Grammar Parsing
Let s begin with a short introduction to parser construction. A parser gives us the ability to process a file that has a known structure and grammar. Rather than build this parser from scratch, we can use tools to specify the parser. This is both faster and a less error prone approach to parser construction and is therefore very useful.
Parsers are very useful, and we ll develop many of them in our careers. Though few of us will take on the task of building full-featured compilers, parsers are useful in a variety of areas. For example, configuration files for larger applications can require complex parsers to be built to describe how the application s behavior is specified. The techniques we ll discuss here make building these kinds of parsers a snap.
The first task in parsing is the tokenization of our input file. In this phase, we break our input file down into its representative chunks . For example, breaking down the C source fragment:
if (counter < 9) counter++;
would result in the tokens parsed:
'if', '(', 'counter', '<', '9', ')', 'counter', '++', ';' That s quite a few tokens, but we ll see why this is necessary shortly. Identifying how the tokens are made up is the specification part of lexical analysis. Further, the lexical analyzer will return metadata that describes what was parsed. For example, rather than the tokens, additional data is returned, such as:
IF_TOKEN OPEN_PAREN VARIABLE OP_LESSTHAN NUMBER CLOSE_PAREN VARIABLE UNARY_INC SEMICOLON
This is useful because when we re trying to understand whether the tokens have meaning, it s not important which variable we re dealing with, but just that we have a variable (identified by the VARIABLE token metadata).
Once we ve broken down our input file into tokens, these tokens can be passed to our grammar parser to understand if they are meaningful. For example, consider the following simple grammar to define an if statement:
IF_STMT: IF_TOKEN OPEN_PAREN TEST CLOSE_PAREN EXPRESSION SEMICOLON
This defines an if statement rule ( IF_STMT ), which specifies that we ll have an IF_TOKEN ( if ), a test expression surrounded by parents ( OPEN_PAREN TEST CLOSE__PAREN ), followed by an EXPRESSION terminated by a SEMICOLON . Further:
TEST: VARIABLE OPERATOR NUMBER OPERATOR: OP_EQUALITY OP_LESSTHAN OP_GREATERTHAN
defines that our test is represented by a variable, an operator (one of three), and a number. Finally, our simple EXPRESSION is:
EXPRESSION: VARIABLE UNARY_OP UNARY_OP: UNARY_INC UNARY_DEC
Now that we have our simple grammar rules specified, let s look at a couple of test fragments to see how it works. Consider our original code fragment. Figure 23.1 illustrates this if statement with its parse tree.
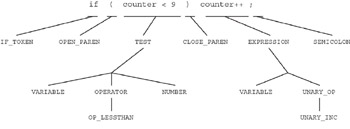
Figure 23.1: Parse tree for a sample C code fragment.
We can see in this diagram that each token from our C fragment is correctly recognized by our sample grammar. Each token is matched with our syntax and is therefore a proper line of C (in this simple example). Now let s look at another example, but in this case, an erroneous one ( Figure 23.2).
In this case, two errors are found. First, we parse down the TEST subtree and find an issue. The TEST is made up of a VARIABLE followed by an OPERATOR and ends with a NUMBER . We find our VARIABLE ( counter ), but upon trying to recognize the OPERATOR , we find something that is not matched ( != ). Since an invalid OPERATOR was defined, we d signal an error and exit (or more intelligently identify the error, but then try to move on with the parse to see if any other errors are to be found). In the next case, we expect an EXPRESSION following the CLOSE_PAREN . We try to recognize the EXPRESSION as a VARIABLE and a UNARY_OP , but instead find a UNARY_OP and then a VARIABLE . Both elements are recognized, but syntactically, they represent an error. Instead of first finding a VARIABLE , we see a UNARY_OP and signal the error.
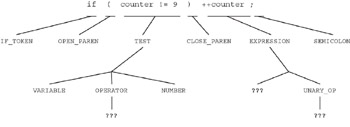
Figure 23.2: Incomplete parse tree for an erroneous C code fragment.
Note that the tree illustrates two concepts in parsing. The endpoints of the tree ( leaves ) represent the symbols of the grammar, whereas the edges represent the derivation of the grammar to the endpoints. When a sequence of tokens is properly matched in the tree to a set of nodes, our tokens are recognized by the grammar.
Lexer and Parser Communication
In a typical compiler, there will be numerous phases (commonly six). The lexical analyzer and grammar parser are two of the phases in compiler construction, but for our purposes here, they are all that are required. For the parsing of configuration files, we ll need to break our file down into tokens and then parse these into a parse tree. This is illustrated in Figure 23.3.
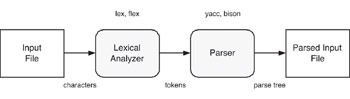
Figure 23.3: Typical phases in configuration parsing.
Given our input file, the lexical analyzer (or lexer) will take the file as characters and assemble them into tokens. The grammar parser takes the tokens and parses them into parse trees. Based upon the successful creation of the parse tree, we have syntactically correct code (or configuration). From here, we can utilize the parse tree to extract our configuration data.
| Note | The lexical analyzer ( flex ) takes a file of regular expressions and produces a finite automaton that recognizes the sequence of tokens for the target language. The parser generator ( bison ) takes a file defining a context free grammar and produces an LALR parser that recognizes the language. |
While we focus here on flex and bison , some may recognize these tools by their early UNIX names lex and yacc (yet-another-compiler-compiler). flex and bison are GNU projects, therefore we ll utilize them instead. We ll look at the each of the tools separately and then bring them together in a single configuration example.
flex
The fast lexical analyzer generator (or flex ) is a tool that uses a collection of regular expressions provided by the user to produce a lexical analyzer. The produced application can then be used to tokenize an input file from a sequence of characters to a sequence of tokens. The generated application is really nothing more than a finite state automaton derived from the set of regular expressions.
Let s now look at a simple example to understand what all of this means. First, the format of a flex input file has the format:
%{ <C declarations> %} <definitions> %% <rules> %% <user code> name definition
The rules section defines the set of regular expressions used to tokenize the input. These rules define the finite automata to parse the tokens and take the form:
pattern action
Finally, the last section is user code that will be integrated into the resulting lexical analyzer code. Now on to a real example. In Listing 23.1 we see a simple flex input file.
| |
1 : %{ 2 : #include <stdio.h> 3 : %} 4 : 5 : NUM [0-9] 6 : VAR [a-zA-Z] 7 : WS [ \t] 8 : 9 : %% 10 : set printf( "(STMT set) " ); 11 : {NUM}+ printf( "(NUM %s) ", yytext ); 12 : {VAR}+ printf( "(VAR %s) ", yytext ); 13 : - printf( "(OP minus) " ); 14 : \+ printf( "(OP plus) " ); 15 : = printf( "(OP equal) " ); 16 : ; printf( "(END stmt) " ); 17 : \n printf( "\n\n" ); 18 : {WS}+ /* Ignore whitespace */ 19 : <<EOF>> printf( "End of parse\n." ); yyterminate(); 20 : %% | |
At lines 13 and 15, we see some very simple recognizers. When we see a - symbol, we emit a minus string, and when we see a + (escaped with \ to delineate it from the one or more regex symbol), we emit a plus string. Line 17 looks for newlines and simply emits a newline to stdout .
One final point to note is line 19. This special symbol recognizes the end of the file, for which we simply end the session using the supplied yyterminate function.
Let s now look at how we can build and then test this lexer using stdin . To build our lexer, we simply provide the file ( ![]() example.fl ) to the flex utility, as:
example.fl ) to the flex utility, as:
# flex example.fl
The result is a file called lex.yy.c , which contains the lexer. We can now compile this file as follows :
# gcc -o example lex.yy.c -lfl
The trailing -lfl tells gcc to link in the flex library ( libfl.a ). Now we have an executable for which we can test. Let s look at a few examples typed from the shell (see Listing 23.2).
| |
1 : # ./example 2 : set counter = 0; 3 : (STMT set) (VAR counter) (OP equal) (NUM 0) (END stmt) 4 : 5 : set counter=0; 6 : (STMT set) (VAR counter) (OP equal) (NUM 0) (END stmt) 7 : 8 : set set = set; 9 : (STMT set) (STMT set) (OP equal) (STMT set) (END stmt) 10 : 11 : set a = a + 1; 12 : (STMT set) (VAR a) (OP equal) (VAR a) (OP plus) (NUM 1) (END stmt) 13 : 14 : abc123def 15 : (VAR abc) (NUM 123) (VAR def) 16 : 17 : End of parse 18 : #
| |
At line 1, we start the lexer and then begin providing input. Note at line 18 in Listing 23.1 that we ignore any whitespace that s encountered . This is why lines 2 and 5 of Listing 23.2 result in an identical set of tokens being generated. At line 8, we see the set reserved word used as a variable. The lexer simply parses this as a statement, which would presumably be caught by the grammar parser. The point here is that the lexer doesn t know and therefore simply parses the tokens as it sees them (even though they may not make sense).
One other item to note (to further clarify how the lexer works) is the input shown at line 14. In this case, no whitespace is provided to delimit the input. The lexer correctly notes that alpha characters are VAR tokens and numeric characters represent NUM tokens. In this case, the three tokens are correctly parsed from the input without any reference to delimiters.
Finally, at line 16 of Listing 23.2, we perform a Ctrl+D to end the parse. The lexer catches this (via the << EOF >> symbol) and ends the parse session.
In these examples, the actions to the rule patterns have been to write to stdout . Later in this chapter, we ll look at how to connect the lexical analyzer to the grammar parser.
bison
Now that we have some understanding of the lexical analysis process, let s dig into grammar parsing. We ll evolve our last lexer to work with a new grammar parser built with bison .
The grammar parser that we ll build with bison works in concert with the lexical analyzer. It accepts the tokens recognized by the lexer and matches them with the grammar symbols to identify a properly structured input. The bison tool builds a bottom-up parser and, using a process known as shift-reduce , attempts to map all of the lexer data elements to grammar symbols.
A Simple Grammar
Let s first look at a simple example that models our input from Listing 23.2. What we want our grammar to represent is a set of set operations. These can take the form:
set counter = 1; set counter = counter + 1; set counter = lastcount; set delta = counter - lastcount;
In this very simple grammar, we can reduce to the following rules. First each statement starts with a set command followed by a variable and a = symbol. After the assignment operator, we have what we ll call an expression and terminate with a ; . So our first rule can take the form:
'set' VARIABLE '=' EXPRESSION ';'
Our EXPRESSION has one of four forms:
NUMBER VARIABLE VARIABLE OPERATOR NUMBER VARIABLE OPERATOR VARIABLE
Finally, we ll support two operators within an expression. It can be either an addition or a subtraction:
'+' '-'
This is reasonable so far for this very simple grammar. It should be clear now how the lexer and grammar parser work together. The lexer will break the input down into the necessary tokens, which the grammar parser takes, and using its rules, determines if the symbols can be recognized by the grammar.
Encoding the Grammar in bison
Let s now look at how the simple grammar can be represented for bison . The bison input file is similar to the flex input file. It starts with a section containing C code that is imported into the grammar parser, followed by a set of declarations:
%{ C Declarations %} Bison Declarations %% Grammar Rules %% C Code The bison input file can be quite a bit more complex than the flex input file, so let s continue our illustration with a real example. In this example, we ll provide a grammar for our previous set example. This is shown in Listing 23.3.
| |
1 : %{ 2 : #include <stdio.h> 3 : 4 : void yyerror( const char *str ) 5 : { 6 : fprintf( stderr, "error: %s\n", str ); 7 : } 8 : 9 : int main() 10 : { 11 : yyparse(); 12 : 13 : return 0; 14 : } 15 : %} 16 : 17 : %token SET NUMBER VARIABLE OP_MINUS OP_PLUS ASSIGN END 18 : 19 : %% 20 : 21 : statements: 22 : statements statement 23 : ; 24 : 25 : 26 : statement: 27 : SET VARIABLE ASSIGN expression END 28 : { 29 : printf("properly formed\n"); 30 : } 31 : ; 32 : 33 : 34 : expression: 35 : NUMBER 36 : 37 : VARIABLE 38 : 39 : VARIABLE operator NUMBER 40 : 41 : VARIABLE operator VARIABLE 42 : ; 43 : 44 : 45 : operator: 46 : OP_MINUS 47 : 48 : OP_PLUS 49 : ; | |
The bulk of our bison input file is the rules that make up the grammar. The rules section begins at the first %% symbol in the file (line 19). Our first rule is the statements rule (lines 21 “23). A rule is made up of a name followed by a colon and then a series of tokens or nonterminals with an optional action sequence (within a set of braces), terminated by a ; . The statements rule has two possibilities. The blank after the colon means that there may be no more tokens to parse (end of file) or ( ) or another possibility. If we had placed statement as the only possibility, then we could parse a single statement and no more. By specifying statements before statement , we allow the possibility of parsing more than one statement in our input.
The statement rule (lines 26 “31) permits the parse of a single kind of statement (a variable assignment). Our statement must begin with a set command followed by a variable name and an assignment operator. We then see an expression rule, which will be used to cover a number of different possibilities. Our statement ends with a semicolon (represented here as an END token). Note here that we provide an optional action sequence for the statement. If our rule matches without encountering any errors, the optional command is performed within the parser. Here we simply emit that the input provided was properly formed within the grammar.
The expression rule (lines 34 “42) defines the varieties of expressions that are possible (the right value, or rvar , of our statement). There are four possibilities that we consider legal. It can be a number, another variable, a sum of a variable and a variable or number, or a difference between a variable and a variable or number. The operator rule (lines 45 “49) covers the two types of operators that are legal (a - as defined by the OP_MINUS token or a + as defined by OP_PLUS ).
The goal of this parse, as defined by the code that we ve inserted into the grammar, is simply to identify a properly formed statement.
| Note | bison grammars are expressed in a machine-readable Backus-Naur Form (or BNF). A BNF is a formal syntax used to express context-free grammars and is a widely used notation to express grammars for computer programming languages. |
Hooking the Lexer to the Grammar Parser
Now that we have our grammar parser done, let s look at how to modify the lexer so that both know about the proper set of tokens and also how to connect the lexer to the parser. Let s start by looking at the upgraded flex input file, and we ll describe the changes to support the connectivity.
| |
1 : %{ 2 : #include <stdio.h> 3 : #include "grammar.tab.h" 4 : %} 5 : 6 : NUM [0-9] 7 : VAR [a-zA-Z] 8 : WS [ \t] 9 : 10 : %% 11 : set return SET; 12 : {NUM}+ return NUMBER; 13 : {VAR}+ return VARIABLE; 14 : - return OP_MINUS; 15 : \+ return OP_PLUS; 16 : = return ASSIGN; 17 : ; return END; 18 : \n /* Ignore whitespace */ 19 : {WS}+ /* Ignore whitespace */ 20 : %% | |
The first point to note is that in order to know which tokens (constant names) the parser generator is using we must include them in the lexer. When the parser generator is built with bison , it also generates a header file that contains the tokens that were specified (via the %token symbol). These can now be included within the flex input file to connect them together. In the compile phase of the lexer, we can easily find if there are disconnects (due to missing symbol errors).
The second point to note is that we re no longer just printing the token that was recognized, but instead returning the token to the caller. The caller in this case will be the parser generator.
Now let s walk through the process of building a parser from both the flex and bison input files. In this example, our bison grammar input file is named ![]() grammar.y , and our flex input file is called
grammar.y , and our flex input file is called ![]() tokens.l . We start by building the parser itself because the lexer is dependent upon the header file generated here:
tokens.l . We start by building the parser itself because the lexer is dependent upon the header file generated here:
# ls grammar.y tokens.l # bison -d grammar.y # ls grammar.tab.c grammar.tab.h grammar.y tokens.l #
We tell bison (via the -d flag) to generate the extra output file (which contains our macro definitions) so that we can hook it up to the lexer. We see here that two files were created: grammar.tab.c and grammar.tab.c . The C source file is our parser source, and the .h file our macro definitions file.
Next, let s build our lexer using flex :
# flex tokens.l # ls # grammar.tab.c grammar.tab.h grammar.y lex.yy.c tokens.l
We invoke flex with our flex input file, which results in a new file called lex.yy.c . This is our lexical analyzer. Finally, we can build these together with gcc and generate our parser as:
# gcc grammar.tab.c lex.yy.c -o parser -lfl
Now we have our parser executable in a file called parser . Let s try it out and see how it works (see Listing 23.5).
| |
# ./parser set counter = 1; properly formed set counter = counter + 1; properly formed set counter = lastCount; properly formed set deltaCount = counter - lastCount; properly formed set set = set; error: parse error #
| |
We can see from this use that it properly recognizes our grammar. When we encounter an error, it simply exits with a status. We can also exit the parser by pressing Ctrl+D.
Note that our last example, where an error was detected , presents an interesting case. The set token is valid as far as variables go (given our variable rule in the lexer at line 13 of Listing 23.4), but given the precedence of our regular expressions, it s detected as the SET token rather than a variable. Given our grammar, this is defined as an error.
So now we ve built a parser that will identify whether the input is correct given the tokens that can be recognized and the grammar. The next step is actually doing something with the data, which we ll look at in the next section.
EAN: 2147483647
Pages: 203