Syntax
The following statements are available in PROC LIFEREG.
-
PROC LIFEREG < options > ;
-
BY variables ;
-
CLASS variables ;
-
INSET < keyword-list >< / options > ;
-
MODEL r esponse = < effects >< / options > ;
-
OUTPUT < OUT= SAS-data-set >
-
keyword = name < keyword = name >
-
< options > ;
-
-
PROBPLOT < / options > ;
-
WEIGHT variable ;
-
The PROC LIFEREG statement invokes the procedure. The MODEL statement is required and specifies the variables used in the regression part of the model as well as the distribution used for the error, or random, component of the model. Only a single MODEL statement can be used with one invocation of the LIFEREG procedure. If multiple MODEL statements are present, only the last is used. Main effects and interaction terms can be specified in the MODEL statement, similar to the GLM procedure. Initial values can be specified in the MODEL statement or in an INEST= data set. If no initial values are specified, the starting estimates are obtained by ordinary least squares. The CLASS statement determines which explanatory variables are treated as categorical. The WEIGHT statement identifies a variable with values that are used to weight the observations. Observations with zero or negative weights are not used to fit the model, although predicted values can be computed for them. The OUTPUT statement creates an output data set containing predicted values and residuals.
PROC LIFEREG Statement
-
PROC LIFEREG < options > ;
The PROC LIFEREG statement invokes the procedure. You can specify the following options in the PROC LIFEREG statement.
COVOUT
-
writes the estimated covariance matrix to the OUTEST= data set if convergence is attained.
DATA= SAS-data-set
-
specifies the input SAS data set used by PROC LIFEREG. By default, the most recently created SAS data set is used.
GOUT= graphics-catalog
-
specifies a graphics catalog in which to save graphics output.
INEST= SAS-data-set
-
specifies an input SAS data set that contains initial estimates for all the parameters in the model. See the section INEST= Data Set on page 2121 for a detailed description of the contents of the INEST= data set.
NAMELEN= n
-
specifies the length of effect names in tables and output data sets to be n characters , where n is a value between 20 and 200. The default length is 20 characters.
NOPRINT
-
suppresses the display of the output. Note that this option temporarily disables the Output Delivery System (ODS). For more information, see Chapter 14, Using the Output Delivery System.
ORDER=DATA FORMATTED FREQ INTERNAL
-
specifies the sorting order for the levels of the classification variables (specified in the CLASS statement). This ordering determines which parameters in the model correspond to each level in the data. The following table illustrates how PROC LIFEREG interprets values of the ORDER= option.
Value of ORDER=
Levels Sorted By
DATA
order of appearance in the input data set
FORMATTED
formatted value
FREQ
descending frequency count; levels with the most observations come first in the order
INTERNAL
unformatted value
By default, ORDER=FORMATTED. For FORMATTED and INTERNAL, the sort order is machine dependent. For more information on sorting order, refer to the chapter titled The SORT Procedure in the SAS Procedures Guide .
OUTEST= SAS-data-set
-
specifies an output SAS data set containing the parameter estimates, the maximized log likelihood , and, if the COVOUT option is specified, the estimated covariance matrix. See the section OUTEST= Data Set on page 2121 for a detailed description of the contents of the OUTEST= data set.
XDATA= SAS-data-set
-
specifies an input SAS data set that contains values for all the independent variables in the MODEL statement and variables in the CLASS statement for probability plotting. If there are covariates specified in a MODEL statement and a probability plot is requested with a PROBPLOT statement, you specify fixed values for the effects in the MODEL statement with the XDATA= data set. See the section XDATA= Data Set on page 2122 for a detailed description of the contents of the XDATA= data set.
BY Statement
-
BY variables ;
You can specify a BY statement with PROC LIFEREG to obtain separate analyses on observations in groups defined by the BY variables. When a BY statement appears, the procedure expects the input data set to be sorted in order of the BY variables.
If your input data set is not sorted in ascending order, use one of the following alternatives:
-
Sort the data using the SORT procedure with a similar BY statement.
-
Specify the BY statement option NOTSORTED or DESCENDING in the BY statement for the LIFEREG procedure. The NOTSORTED option does not mean that the data are unsorted but rather that the data are arranged in groups (according to values of the BY variables) and that these groups are not necessarily in alphabetical or increasing numeric order.
-
Create an index on the BY variables using the DATASETS procedure.
For more information on the BY statement, refer to the discussion in SAS Language Reference: Concepts . For more information on the DATASETS procedure, refer to the discussion in the SAS Procedures Guide .
CLASS Statement
-
CLASS variables ;
Variables that are classification variables rather than quantitative numeric variables must be listed in the CLASS statement. For each explanatory variable listed in the CLASS statement, indicator variables are generated for the levels assumed by the CLASS variable. If the CLASS statement is used, it must appear before the MODEL statement.
INSET Statement
-
INSET < keyword-list >< / options > ;
The box or table of summary information produced on plots made with the PROBPLOT statement is called an inset . You can use the INSET statement to customize the information that is displayed in the inset box as well as to customize the appearance of the inset box. To supply the information that is displayed in the inset box, you specify keywords corresponding to the information that you want shown. For example, the following statements produce a probability plot with the number of observations, the number of right-censored observations, the name of the distribution, and the estimated Weibull shape parameter in the inset.
proc lifereg data=epidemic; model life = dose / dist = Weibull; probplot ; inset nobs right dist shape; run;
By default, inset entries are identified with appropriate labels. However, you can provide a customized label by specifying the keyword for that entry followed by the equal sign (=) and the label in quotes. For example, the following INSET statement produces an inset containing the number of observations and the name of the distribution, labeled Sample Size and Distribution in the inset.
inset nobs='Sample Size' dist='Distribution';
If you specify a keyword that does not apply to the plot you are creating, then the keyword is ignored.
If you specify more than one INSET statement, only the first one is used.
The following table lists keywords available in the INSET statement to display summary statistics, distribution parameters, and distribution fitting information.
| CONFIDENCE | confidence coefficient for all confidence intervals |
| DIST | name of the distribution |
| INTERVAL | number of interval-censored observations |
| LEFT | number of left-censored observations |
| NOBS | number of observations |
| NMISS | number of observations with missing values |
| RIGHT | number of right-censored observations |
| SCALE | value of the scale parameter |
| SHAPE | value of the shape parameter |
| UNCENSORED | number of uncensored observations |
The following options control the appearance of the box. All options are specified after the slash (/) in the INSET statement.
CFILL= color
-
specifies the color for the filling box.
CFILLH= color
-
specifies the color for the filling box header.
CFRAME= color
-
specifies the color for the frame.
CHEADER= color
-
specifies the color for text in the header.
CTEXT= color
-
specifies the color for the text.
FONT= font
-
specifies the software font for the text.
HEIGHT= value
-
specifies the height of the text.
HEADER= quoted string
-
specifies text for the header or box title.
NOFRAME
-
omits the frame around the box.
POS= value < DATA PERCENT >
-
determines the position of the inset. The value can be a compass point (N, NE, E, SE, S, SW, W, NW) or a pair of coordinates (x, y) enclosed in parentheses. The coordinates can be specified in screen percent units or axis data units. The default is screen percent units.
REFPOINT= name
-
specifies the reference point for an inset that is positioned by a pair of coordinates with the POS= option. You use the REFPOINT= option in conjunction with the POS= coordinates. The REFPOINT= option specifies which corner of the inset frame you have specified with coordinates (x, y), and it can take the value of BR (bottom right), BL (bottom left), TR (top right), or TL (top left). The default is REFPOINT=BL. If the inset position is specified as a compass point, then the REFPOINT= option is ignored.
MODEL Statement
-
< label:> MODEL response < * censor (list) > =effects < / options > ;
-
< label:> MODEL (lower,upper)=effects < / options > ;
-
< label:> MODEL events/trials=effects < / options > ;
Only a single MODEL statement can be used with one invocation of the LIFEREG procedure. If multiple MODEL statements are present, only the last is used. The optional label is used to label the model estimates in the output SAS data set and OUTEST= data set.
The first MODEL syntax is appropriate for right censoring. The variable response is possibly right-censored. If the response variable can be right-censored, then a second variable, denoted censor , must appear after the response variable with a list of parenthesized values, separated by commas or blanks, to indicate censoring. That is, if the censor variable takes on a value given in the list, the response is a right-censored value; otherwise , it is an observed value.
The second MODEL syntax specifies two variables, lower and upper , that contain values of the endpoints of the censoring interval. If the two values are the same (and not missing), it is assumed that there is no censoring and the actual response value is observed. If the lower value is missing, then the upper value is used as a left-censored value. If the upper value is missing, then the lower value is taken as a right-censored value. If both values are present and the lower value is less than the upper value, it is assumed that the values specify a censoring interval. If the lower value is greater than the upper value or both values are missing, then the observation is not used in the analysis although predicted values can still be obtained if none of the covariates are missing. The following table summarizes the ways of specifying censoring.
| lower | upper | Comparison | Interpretation |
|---|---|---|---|
| not missing | not missing | equal | no censoring |
| not missing | not missing | lower < upper | censoring interval |
| missing | not missing | upper used as left-censoring value | |
| not missing | missing | lower used as right-censoring value | |
| not missing | not missing | lower > upper | observation not used |
| missing | missing | observation not used |
The third MODEL syntax specifies two variables that contain count data for a binary response. The value of the first variable, events , is the number of successes. The value of the second variable, trials , is the number of tries . The values of both events and ( trials-events ) must be nonnegative, and trials must be positive for the response to be valid. The values of the two variables do not need to be integers and are not modified to be integers.
The effects following the equal sign are the covariates in the model. Higher-order effects, such as interactions and nested terms, are allowed in the list, similar to the GLM procedure. Variable names and combinations of variable names representing higher-order terms are allowed to appear in this list. Class variables can be used as effects, and indicator variables are generated for the class levels. If you do not specify any covariates following the equal sign, an intercept-only model is fit.
Examples of three valid MODEL statements are
a: model time*flag(1,3)=temp; b: model (start, finish)=; c: model r/n=dose;
Model statement a indicates that the response is contained in a variable named time and that, if the variable flag takes on the values 1 or 3, the observation is right-censored. The explanatory variable is temp , which could be a class variable. Model statement b indicates that the response is known to be in the interval between the values of the variables start and finish and that there are no covariates except for a default intercept term . Model statement c indicates a binary response, with the variable r containing the number of responses and the variable n containing the number of trials.
The following options can appear in the MODEL statement.
| Task | Option | |
|---|---|---|
| Model specification | ||
| set the significance level | ALPHA= | |
| specify distribution type for failure time | DISTRIBUTION= | |
| request no log transformation of response | NOLOG | |
| initial estimate for intercept term | INTERCEPT= | |
| hold intercept term fixed | NOINT | |
| initial estimates for regression parameters | INITIAL= | |
| initialize scale parameter | SCALE= | |
| hold scale parameter fixed | NOSCALE | |
| initialize first shape parameter | SHAPE1= | |
| hold first shape parameter fixed | NOSHAPE1 | |
| Model fitting | ||
| set convergence criterion | CONVERGE= | |
| set maximum iterations | MAXITER= | |
| set tolerance for testing singularity | SINGULAR= | |
| Output | ||
| display estimated correlation matrix | CORRB | |
| display estimated covariance matrix | COVB | |
| display iteration history, final gradient, and second derivative matrix | ITPRINT | |
ALPHA= value
-
sets the significance level for the confidence intervals for regression parameters and estimated survival probabilities. The value must be between 0 and 1. By default, ALPHA = 0.05.
CONVERGE= value
-
sets the convergence criterion. Convergence is declared when the maximum change in the parameter estimates between Newton-Raphson steps is less than the value specified. The change is a relative change if the parameter is greater than 0.01 in absolute value; otherwise, it is an absolute change. By default, CONVERGE=1E ˆ’ 8.
CONVG= value
-
sets the relative Hessian convergence criterion. value must be between 0 and 1. After convergence is determined with the change in parameter criterion specified with the CONVERGE= option, the quantity
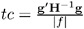 is computed and compared to value , where g is the gradient vector, H is the Hessian matrix for the model parameters, and f is the log-likelihood function. If tc is greater than value , a warning that the relative Hessian convergence criterion has been exceeded is displayed. This criterion detects the occasional case where the change in parameter convergence criterion is satisfied, but a maximum in the log-likelihood function has not been attained. By default, CONVG=1E ˆ’ 4.
is computed and compared to value , where g is the gradient vector, H is the Hessian matrix for the model parameters, and f is the log-likelihood function. If tc is greater than value , a warning that the relative Hessian convergence criterion has been exceeded is displayed. This criterion detects the occasional case where the change in parameter convergence criterion is satisfied, but a maximum in the log-likelihood function has not been attained. By default, CONVG=1E ˆ’ 4.
CORRB
-
produces the estimated correlation matrix of the parameter estimates.
COVB
-
produces the estimated covariance matrix of the parameter estimates.
DISTRIBUTION= distribution-type
DIST= distribution-type
D= distribution-type
-
specifies the distribution type assumed for the failure time. By default, PROC LIFEREG fits a type 1 extreme value distribution to the log of the response. This is equivalent to fitting the Weibull distribution, since the scale parameter for the extreme value distribution is related to a Weibull shape parameter and the intercept is related to the Weibull scale parameter in this case. When the NOLOG option is specified, PROC LIFEREG models the untransformed response with a type 1 extreme value distribution as the default. See the section Supported Distributions on page 2111 for descriptions of the distributions. The following are valid values for distribution-type :
EXPONENTIAL
the exponential distribution, which is treated as a restricted Weibull distribution
GAMMA
a generalized gamma distribution (Lawless, 1982, p. 240). The standard two-parameter gamma distribution is not available in PROC LIFEREG.
LLOGISTIC
a loglogistic distribution
LNORMAL
a lognormal distribution
LOGISTIC
a logistic distribution (equivalent to LLOGISTIC when the NOLOG option is specified)
NORMAL
a normal distribution (equivalent to LNORMAL when the NOLOG option is specified)
WEIBULL
a Weibull distribution. If NOLOG is specified, it fits a type 1 extreme value distribution to the raw, untransformed data.
-
By default, PROC LIFEREG transforms the response with the natural logarithm before fitting the specified model when you specify the GAMMA, LLOGISTIC, LNORMAL, or WEIBULL option. You can suppress the log transformation with the NOLOG option. The following table summarizes the resulting distributions when the preceding distribution options are used in combination with the NOLOG option.
DISTRIBUTION=
NOLOG specified?
Resulting distribution
EXPONENTIAL
No
Exponential
EXPONENTIAL
Yes
One-parameter extreme value
GAMMA
No
Generalized gamma
GAMMA
Yes
Generalized gamma with untransformed responses
LOGISTIC
No
Logistic
LOGISTIC
Yes
Logistic (NOLOG has no effect)
LLOGISTIC
No
Log-logistic
LLOGISTIC
Yes
Logistic
LNORMAL
No
Lognormal
LNORMAL
Yes
Normal
NORMAL
No
Normal
NORMAL
Yes
Normal (NOLOG has no effect)
WEIBULL
No
Weibull
WEIBULL
Yes
Extreme value
INITIAL= values
-
sets initial values for the regression parameters. This option can be helpful in the case of convergence difficulty. Specified values are used to initialize the regression coefficients for the covariates specified in the MODEL statement. The intercept parameter is initialized with the INTERCEPT= option and is not included here. The values are assigned to the variables in the MODEL statement in the same order in which they are listed in the MODEL statement. Note that a class variable requires k ˆ’ 1 values when the class variable takes on k different levels. The order of the class levels is determined by the ORDER= option. If there is no intercept term, the first class variable requires k initial values. If a BY statement is used, all class variables must take on the same number of levels in each BY group or no meaningful initial values can be specified. The INITIAL= option can be specified as follows .
Type of List
Specification
list separated by blanks
initial=3 4 5
list separated by commas
initial=3,4,5
xtoy
initial=3 to 5
xtoybyz
initial=3 to 5 by 1
combination of methods
initial=1,3 to 5,9
By default, PROC LIFEREG computes initial estimates with ordinary least squares. See the section Computational Method on page 2108 for details.
Note: The INITIAL= option is overwritten by the INEST= option. See the section INEST= Data Set on page 2121 for details.
INTERCEPT= value
-
initializes the intercept term to value . By default, the intercept is initialized by an ordinary least squares estimate.
ITPRINT
-
displays the iteration history, the final evaluation of the gradient, and the final evaluation of the negative of the second derivative matrix, that is, the negative of the Hessian.
MAXITER= n
-
sets the maximum allowable number of iterations during the model estimation. By default, MAXITER=50.
NOINT
-
holds the intercept term fixed. Because of the usual log transformation of the response, the intercept parameter is usually a scale parameter for the untransformed response, or a location parameter for a transformed response.
NOLOG
-
requests that no log transformation of the response variable be performed. By default, PROC LIFEREG models the log of the response variable for the GAMMA, LLOGISTIC, LOGNORMAL, and WEIBULL distribution options.
NOSCALE
-
holds the scale parameter fixed. Note that if the log transformation has been applied to the response, the effect of the scale parameter is a power transformation of the original response. If no SCALE= value is specified, the scale parameter is fixed at the value 1.
NOSHAPE1
-
holds the first shape parameter, SHAPE1, fixed. If no SHAPE1= value is specified, SHAPE1 is fixed at a value that depends on the DISTRIBUTION type.
SCALE= value
-
initializes the scale parameter to value . If the Weibull distribution is specified, this scale parameter is the scale parameter of the type 1 extreme value distribution, not the Weibull scale parameter. Note that, with a log transformation, the exponential model is the same as a Weibull model with the scale parameter fixed at the value 1.
SHAPE1= value
-
initializes the first shape parameter to value . If the specified distribution does not depend on this parameter, then this option has no effect. The only distribution that depends on this shape parameter is the generalized gamma distribution. See the Supported Distributions section on page 2111 for descriptions of the parameterizations of the distributions.
SINGULAR= value
-
sets the tolerance for testing singularity of the information matrix and the crossproducts matrix for the initial least-squares estimates. Roughly, the test requires that a pivot be at least this value times the original diagonal value. By default, SINGULAR=1E ˆ’ 12.
OUTPUT Statement
-
OUTPUT < OUT= SAS-data-set > keyword = name <. . . keyword = name > ;
The OUTPUT statement creates a new SAS data set containing statistics calculated after fitting the model. At least one specification of the form keyword = name is required.
All variables in the original data set are included in the new data set, along with the variables created as options to the OUTPUT statement. These new variables contain fitted values and estimated quantiles. If you want to create a permanent SAS data set, you must specify a two-level name (refer to SAS Language Reference: Concepts for more information on permanent SAS data sets). Each OUTPUT statement applies to the preceding MODEL statement. See Example 39.1 for illustrations of the OUTPUT statement.
The following specifications can appear in the OUTPUT statement:
| OUT= SAS-data-set | specifies the new data set. By default, the procedure uses the DATA n convention to name the new data set. |
| keyword=name | specifies the statistics to include in the output data set and gives names to the new variables. Specify a keyword for each desired statistic (see the following list of keywords), an equal sign, and the variable to contain the statistic. |
The keywords allowed and the statistics they represent are as follows:
| CENSORED | specifies an indicator variable to signal censoring. The variable takes on the value 1 if the observation is censored; otherwise, it is 0. | |
| CDF | specifies a variable to contain the estimates of the cumulative distribution function evaluated at the observed response. See the Predicted Values section on page 2114 for more information. | |
| CONTROL | specifies a variable in the input data set to control the estimation of quantiles. See Example 39.1 for an illustration. If the specified variable has the value of 1, estimates for all the values listed in the QUANTILE= list are computed for that observation in the input data set; otherwise, no estimates are computed. If no CONTROL= variable is specified, all quantiles are estimated for all observations. If the response variable in the MODEL statement is binomial, then this option has no effect. | |
| CRESIDUAL CRES | specifies a variable to contain the Cox-Snell residuals where S is the standard survival function and If the response variable in the corresponding model statement is binomial, then the residuals are not computed, and this variable contains missing values. | |
| SRESIDUAL SRES | specifies a variable to contain the standardized residuals If the response variable in the corresponding model statement is binomial, then the residuals are not computed, and this variable contains missing values. | |
| PREDICTED P | specifies a variable to contain the quantile estimates. If the response variable in the corresponding model statement is binomial, then this variable contains the estimated probabilities, 1 ˆ’ F ( ˆ’ x ² b ). | |
| QUANTILES QUANTILE Q | gives a list of values for which quantiles are calculated. The values must be between 0 and 1, noninclusive. For each value, a corresponding quantile is estimated. This option is not used if the response variable in the corresponding MODEL statement is binomial. The QUANTILES option can be specified as follows. | |
| Type of List | Specification | |
| list separated by blanks | .2 .4 .6 .8 | |
| list separated by commas | .2, .4, .6,.8 | |
| xtoy | .2 to .8 | |
| xtoybyz | .2 to .8 by .1 | |
| combination of methods | .1,.2 to .8 by .2 | |
| By default, QUANTILES=0.5. When the response is not binomial, a numeric variable, _ PROB_ , is added to the OUTPUT data set whenever the QUANTILES= option is specified. The variable _ PROB_ gives the probability value for the quantile estimates. These are the values taken from the QUANTILES= list and are given as values between 0 and 1, not as values between 0 and 100. | ||
| STD_ ERR STD | specifies a variable to contain the estimates of the standard errors of the estimated quantiles or x ² b . If the response used in the MODEL statement is a binomial response, then these are the standard errors of x ² b . Otherwise, they are the standard errors of the quantile estimates. These estimates can be used to compute confidence intervals for the quantiles. However, if the model is fitto the log of the event time, better confidence intervals can usually be computed by transforming the confidence intervals for the log response. See Example 39.1 for such a transformation. | |
| XBETA | specifies a variable to contain the computed value of x ² b , where x is the covariate vector and b is the vector of parameter estimates. | |
PROBPLOT Statement
-
PROBPLOT PPLOT < / options > ;
You can use the PROBPLOT statement to create a probability plot from lifetime data. The data can be uncensored, right-censored, or arbitrarily censored. You can specify any number of PROBPLOT statements after a MODEL statement. The syntax used for the response in the MODEL statement determines the type of censoring assumed in creating the probability plot. The model fit with the MODEL statement is plotted along with the data. If there are covariates in the model, they are set to constant values specified in the XDATA= data set when creating the probability plot. If no XDATA= data set is specified, continuous variables are set to their overall mean values and categorical variables specified in the CLASS statement are set to their highest levels.
You can specify the following options to control the content, layout, and appearance of a probability plot.
ANNOTATE= SAS-data-set
ANNO= SAS-data-set
-
specifies an ANNOTATE data set, as described in SAS/GRAPH Software: Reference , that enables you to add features to the probability plot. The ANNOTATE= data set you specify in the PROBPLOT statement is used for all plots created by the statement.
CAXIS= color
CAXES= color
-
specifies the color used for the axes and tick marks. This option overrides any COLOR= specifications in an AXIS statement. The default is the first color in the device color list.
CCENSOR= color
-
specifies the color for filling the censor plot area. The default is the first color in the device color list.
CENBIN
-
plots censored data as frequency counts (rounding-off for non-integer frequency) rather than as individual points.
CENCOLOR= color
-
specifies the color for the censor symbol. The default is the first color in the device color list.
CENSYMBOL= symbol ( symbol list )
-
specifies symbols for censored values. The symbol is one of the symbol names (plus, star, square, diamond, triangle, hash, paw, point, dot, and circle) or a letter (A_Z). If you do not specify the CENSYMBOL= option, the symbol used for censored values is the same as for failures.
CFIT= color
-
specifies the color for the fitted probability line and confidence curves. The default is the first color in the device color list.
CFRAME= color
CFR= color
-
specifies the color for the area enclosed by the axes and frame. This area is not shaded by default.
CGRID= color
-
specifies the color for grid lines. The default is the first color in the device color list.
CHREF= color
CH= color
-
specifies the color for lines requested by the HREF= option. The default is the first color in the device color list.
CTEXT= color
-
specifies the color for tick mark values and axis labels. The default is the color specified for the CTEXT= option in the most recent GOPTIONS statement.
CVREF= color
CV= color
-
specifies the color for lines requested by the VREF= option. The default is the first color in the device color list.
DESCRIPTION= string
DES= string
-
specifies a description, up to 40 characters, that appears in the PROC GREPLAY master menu. The default is the variable name.
FONT= font
-
specifies a software font for reference line and axis labels. You can also specify fonts for axis labels in an AXIS statement. The FONT= font takes precedence over the FTEXT= font specified in the most recent GOPTIONS statement. Hardware characters are used by default.
HCL
-
computes and draws confidence limits for the predicted probabilities in the horizontal direction.
HEIGHT = value
-
specifies the height of text used outside framed areas. The default value is 3.846 (in percentage).
HLOWER= value
-
specifies the lower limit on the lifetime axis scale. The HLOWER= option specifies value as the lower lifetime axis tick mark. The tick mark interval and the upper axis limit are determined automatically.
HOFFSET= value
-
specifies the offset for the horizontal axis. The default value is 1.
HUPPER= value
-
specifies value as the upper lifetime axis tick mark. The tick mark interval and the lower axis limit are determined automatically.
HREF < (INTERSECT) > = value-list
-
requests reference lines perpendicular to the horizontal axis. If (INTERSECT) is specified, a second reference line perpendicular to the vertical axis is drawn that intersects the fit line at the same point as the horizontal axis reference line. If a horizontal axis reference line label is specified, the intersecting vertical axis reference line is labeled with the vertical axis value. See also the CHREF=, HREFLABELS=, and LHREF= options.
HREFLABELS= label1 ... labeln
HREFLABEL= label1 ... labeln
HREFLAB= label1 ... labeln
-
specifies labels for the lines requested by the HREF= option. The number of labels must equal the number of lines. Enclose each label in quotes. Labels can be up to 16 characters.
HREFLABPOS= n
-
specifies the vertical position of labels for HREF= lines. The following table shows the valid values for n and the corresponding label placements.
n
label placement
1
top
2
staggered from top
3
bottom
4
staggered from bottom
5
alternating from top
6
alternating from bottom
INBORDER
-
requests a border around probability plots.
INTERTILE= value
-
specifies the distance between tiles.
ITPRINTEM
-
displays the iteration history for the Turnbull algorithm.
JITTER= value
-
specifies the amount to jitter overlaying plot symbols, in units of symbol width.
LFIT= linetype
-
specifies a line style for fitted curves and confidence limits. By default, fitted curves are drawn by connecting solid lines ( linetype = 1 ), and confidence limits are drawn by connecting dashed lines ( linetype = 3 ).
LGRID= linetype
-
specifies a line style for all grid lines. linetype is between 1 and 46. The default is 35.
LHREF= linetype
LH= linetype
-
specifies the line type for lines requested by the HREF= option. The default is 2, which produces a dashed line.
LVREF= linetype
LV = linetype
-
specifies the line type for lines requested by the VREF= option. The default is 2, which produces a dashed line.
MAXITEM= n1 <,n2> n1
-
specifies the maximum number of iterations allowed for the Turnbull algorithm. Iteration history will be displayed in increments of n2 if requested with the ITPRINTEM option. See the section Arbitrarily Censored Data on page 2119 for details.
NAME= string
-
specifies a name for the plot, up to eight characters, that appears in the PROC GREPLAY master menu. The default is LIFEREG .
NOCENPLOT
-
suppresses the plotting of censored data points.
NOCONF
-
suppresses the default percentile confidence bands on the probability plot.
NODATA
-
suppresses plotting of the estimated empirical probability plot.
NOFIT
-
suppresses the fitted probability (percentile) line and confidence bands.
NOFRAME
-
suppresses the frame around plotting areas.
NOGRID
-
suppresses grid lines.
NOHLABEL
-
suppresses horizontal labels.
NOHTICK
-
suppresses horizontal tick marks.
NOPOLISH
-
suppresses setting small interval probabilities to zero in the Turnbull algorithm.
NOVLABEL
-
suppresses vertical labels.
NOVTICK
-
suppresses vertical tick marks.
NPINTERVALS= interval type
-
specifies one of the two kinds of confidence limits for the estimated cumulative probabilities, pointwise (NPINTERVALS=POINT) or simultaneous (NPINTERVALS=SIMUL), requested by the PPOUT option to be displayed in the tabular output.
PCTLIST= value-list
-
specifies the list of percentages for which to compute percentile estimates. value-list must be a list of values separated by blanks or commas. Each value in the list must be between 0 and 100.
PLOWER= value
-
specifies the lower limit on the probability axis scale. The PLOWER= option specifies value as the lower probability axis tick mark. The tick mark interval and the upper axis limit are determined automatically.
PRINTPROBS
-
displays intervals and associated probabilities for the Turnbull algorithm.
PUPPER= value
-
specifies the upper limit on the probability axis scale. The PUPPER= option specifies value as the upper probability axis tick mark. The tick mark interval and the lower axis limit are determined automatically.
PPOS= character-list
-
specifies the plotting position type. See the section Probability Plotting on page 2116 for details.
PPOS
Method
EXPRANK
expected ranks
MEDRANK
median ranks
MEDRANK1
median ranks (exact formula)
KM
Kaplan-Meier
MKM
modified Kaplan-Meier (default)
PPOUT
-
specifies that a table of the cumulative probabilities plotted on the probability plot be displayed. Kaplan-Meier estimates of the cumulative probabilities are also displayed, along with standard errors and confidence limits. The confidence limits can be pointwise or simultaneous, as specified by the NPINTERVALS= option.
PROBLIST= value-list
-
specifies the list of initial values for the Turnbull algorithm.
ROTATE
-
requests probability plots with probability scale on the horizontal axis.
SQUARE
-
makes the layout of the probability plots square.
TOLLIKE= value
-
specifies the criterion for convergence in the Turnbull algorithm.
TOLPROB= value
-
specifies the criterion for setting the interval probability to zero in the Turnbull algorithm.
VAXISLABEL= ˜ string
-
specifies a label for the vertical axis.
VREF= value-list
-
requests reference lines perpendicular to the vertical axis. If (INTERSECT) is specified, a second reference line perpendicular to the horizontal axis is drawn that intersects the fit line at the same point as the vertical axis reference line. If a vertical axis reference line label is specified, the intersecting horizontal axis reference line is labeled with the horizontal axis value. See also the entries for the CVREF=, LVREF=, and VREFLABELS= options.
VREFLABELS= label1 ... labeln
VREFLABEL= label1 ... labeln
VREFLAB= label1 ... labeln
-
specifies labels for the lines requested by the VREF= option. The number of labels must equal the number of lines. Enclose each label in quotes. Labels can be up to 16 characters.
VREFLABPOS= n
-
specifies the horizontal position of labels for VREF= lines. The valid values for n and the corresponding label placements are shown in the following table.
n
label placement
1
left
2
right
WAXIS= n
-
specifies line thickness for axes and frame. The default value is 1.
WFIT= n
-
specifies line thickness for fitted curves. The default value is 1.
WGRID= n
-
specifies line thickness for grids. The default value is 1.
WREFL= n
-
specifies line thickness for reference lines. The default value is 1.
WEIGHT Statement
-
WEIGHT variable ;
If you want to use weights for each observation in the input data set, place the weights in a variable in the data set and specify the name in a WEIGHT statement. The values of the WEIGHT variable can be nonintegral and are not truncated. Observations with nonpositive or missing values for the weight variable do not contribute to the fitof the model. The WEIGHT variable multiplies the contribution to the log likelihood for each observation.
EAN: N/A
Pages: 105