8.8. The Local Filestore The final two sections of this chapter describe the organization and management of data on storage media. Historically FreeBSD provided three different filestore managers: the traditional Berkeley Fast Filesystem (FFS), the Log-Structured Filesystem, and the Memory-based Filesystem. FreeBSD 5.2 supports only FFS, although the other filesystems continue to be supported by NetBSD. The FFS filestore was designed on the assumption that file caches would be small and thus that files would need to be read often. It tries to place files likely to be accessed together in the same general location on the disk. Overview of the Filestore The operations defined for doing the datastore filesystem operations are shown in Table 8.11. These operators are fewer and semantically simpler than are those used for managing the name space. Table 8.11. Datastore filesystem operations.Operation Done | Operator Names |
|---|
object creation and deletion | valloc, vfree | attribute update | Update | object read and write | vget, blkatoff, read, write, fsync | change in space allocation | truncate |
There are two operators for allocating and freeing objects. The valloc operator creates a new object. The identity of the object is a number returned by the operator. The mapping of this number to a name is the responsibility of the namespace code. An object is freed by the vfree operator. The object to be freed is identified by only its number. The attributes of an object are changed by the update operator. This layer does no interpretation of these attributes; they are simply fixed-size auxiliary data stored outside the main data area of the object. They are typically file attributes, such as the owner, group, permissions, and so on. Note that the extended attribute space is updated using the read and write interface as that interface is already prepared to read and write arbitrary length data to and from user-level processes. There are five operators for manipulating existing objects. The vget operator retrieves an existing object from the filestore. The object is identified by its number and must have been created previously by valloc. The read operator copies data from an object to a location described by a uio structure. The blkatoff operator is similar to the read operator, except that the blkatoff operator simply returns a pointer to a kernel memory buffer with the requested data, instead of copying the data. This operator is designed to increase the efficiency of operations where the name-space code interprets the contents of an object (i.e., directories), instead of just returning the contents to a user process. The write operator copies data to an object from a location described by a uio structure. The fsync operator requests that all data associated with the object be moved to stable storage (usually by their all being written to disk). There is no need for an analog of blkatoff for writing, as the kernel can simply modify a buffer that it received from blkatoff, mark that buffer as dirty, and then do an fsync operation to have the buffer written back. The final datastore operation is truncate. This operation changes the amount of space associated with an object. Historically, it could be used only to decrease the size of an object. In FreeBSD, it can be used both to increase and decrease the size of an object. When the size of a file is increased, a hole in the file is created. Usually, no additional disk space is allocated; the only change is to update the inode to reflect the larger file size. When read, holes are treated by the system as zero-valued bytes. Each disk drive has one or more subdivisions, or partitions. Each such partition can contain only one filestore, and a filestore never spans multiple partitions. While a filesystem may use multiple disk partitions to do striping or RAID, the aggregation and management of the parts that make up the filesystem are managed by a lower-level driver in the kernel. The filesystem code always has the view of operating on a single contiguous partition. The filestore is responsible for the management of the space within its disk partition. Within that space, its responsibility is the creation, storage, retrieval, and removal of files. It operates in a flat name space. When asked to create a new file, it allocates an inode for that file and returns the assigned number. The naming, access control, locking, and attribute manipulation for the file are all handled by the hierarchical filesystem-management layer above the filestore. The filestore also handles the allocation of new blocks to files as the latter grow. Simple filesystem implementations, such as those used by early microcomputer systems, allocate files contiguously, one after the next, until the files reach the end of the disk. As files are removed, holes occur. To reuse the freed space, the system must compact the disk to move all the free space to the end. Files can be created only one at a time; for the size of a file other than the final one on the disk to be increased, the file must be copied to the end, then expanded. As we saw in Section 8.2, each file in a filestore is described by an inode; the locations of its data blocks are given by the block pointers in its inode. Although the filestore may cluster the blocks of a file to improve I/O performance, the inode can reference blocks scattered anywhere throughout the partition. Thus, multiple files can be written simultaneously, and all the disk space can be used without the need for compaction. The filestore implementation converts from the user abstraction of a file as an array of bytes to the structure imposed by the underlying physical medium. Consider a typical medium of a magnetic disk with fixed-sized sectoring. Although the user may wish to write a single byte to a file, the disk supports reading and writing only in multiples of sectors. Here, the system must read in the sector containing the byte to be modified, replace the affected byte, and write the sector back to the disk. This operation converting random access to an array of bytes to reads and writes of disk sectors is called block I/O. First, the system breaks the user's request into a set of operations to be done on logical blocks of the file. Logical blocks describe block-sized pieces of a file. The system calculates the logical blocks by dividing the array of bytes into filestore-sized pieces. Thus, if a filestore's block size is 8192 bytes, then logical block 0 would contain bytes 0 to 8191, logical block 1 would contain bytes 8192 to 16,383, and so on. The data in each logical block are stored in a physical block on the disk. A physical block is the location on the disk to which the system maps a logical block. A physical disk block is constructed from one or more contiguous sectors. For a disk with 512-byte sectors, an 8192-byte filestore block would be built up from 16 contiguous sectors. Although the contents of a logical block are contiguous on disk, the logical blocks of the file do not need to be laid out contiguously. The data structure used by the system to convert from logical blocks to physical blocks is described in Section 8.2. User I/O to a File Although the user may wish to write a single byte to a file, the disk hardware can read and write only in multiples of sectors. Hence, the system must arrange to read in the sector containing the byte to be modified, to replace the affected byte, and to write back the sector to the disk. This operation of converting random access to an array of bytes to reads and writes of disk sectors is known as block I/O. Processes may read data in sizes smaller than a disk block. The first time that a small read is required from a particular disk block, the block will be transferred from the disk into a kernel buffer. Later reads of parts of the same block then require only copying from the kernel buffer to the memory of the user process. Multiple small writes are treated similarly. A buffer is allocated from the cache when the first write to a disk block is made, and later writes to part of the same block are then likely to require only copying into the kernel buffer, and no disk I/O. In addition to providing the abstraction of arbitrary alignment of reads and writes, the block buffer cache reduces the number of disk I/O transfers required by filesystem accesses. Because system-parameter files, commands, and directories are read repeatedly, their data blocks are usually in the buffer cache when they are needed. Thus, the kernel does not need to read them from the disk every time that they are requested. Figure 8.30 shows the flow of information and work required to access a file on the disk. The abstraction shown to the user is an array of bytes. These bytes are collectively described by a file descriptor that refers to some location in the array. The user can request a write operation on the file by presenting the system with a pointer to a buffer, with a request for some number of bytes to be written. As Figure 8.30 shows, the requested data do not need to be aligned with the beginning or end of a logical block. Further, the size of the request is not constrained to a single logical block. In the example shown, the user has requested data to be written to parts of logical blocks 1 and 2. Since the disk can transfer data only in multiples of sectors, the filestore must first arrange to read in the data for any part of the block that is to be left unchanged. The system must arrange an intermediate staging area for the transfer. This staging is done through one or more system buffers, described in Section 6.6. Figure 8.30. The block I/O system. 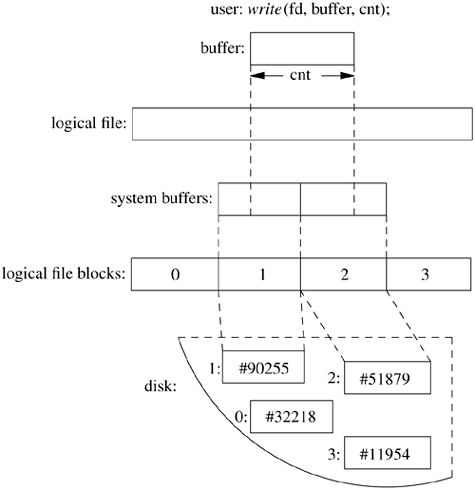
In our example, the user wishes to modify data in logical blocks 1 and 2. The operation iterates over five steps: - 1. Allocate a buffer.
- 2. Determine the location of the corresponding physical block on the disk.
- 3. Request the disk controller to read the contents of the physical block into the system buffer and wait for the transfer to complete.
- 4. Do a memory-to-memory copy from the beginning of the user's I/O buffer to the appropriate portion of the system buffer.
- 5. Write the block to the disk and continue without waiting for the transfer to complete.
If the user's request is incomplete, the process is repeated with the next logical block of the file. In our example, the system fetches logical block 2 of the file and is able to complete the user's request. Had an entire block been written, the system could have skipped step 3 and have simply written the data to the disk without first reading in the old contents. This incremental filling of the write request is transparent to the user's process because that process is blocked from running during the entire procedure. The filling is transparent to other processes; because the inode is locked during the process, any attempted access by any other process will be blocked until the write has completed. If the system crashes while data for a particular block are in the cache but have not yet been written to disk, the filesystem on the disk will be incorrect and those data will be lost. The consistency of critical filesystem data are maintained using the techniques described in Section 8.6, but it is still possible to lose recently written application data. So that lost data are minimized, writes are forced for dirty buffer blocks 30 seconds after they are written. There is also a system call, fsync, that a process can use to force all dirty blocks of a single file to be written to disk immediately; this synchronization is useful for ensuring database consistency or before removing an editor backup file. |