String Handling
String Handling
WDM drivers can work with string data in any of four formats:
-
A Unicode string, normally described by a UNICODE_STRING structure, contains 16-bit characters. Unicode has sufficient code points to accommodate the language scripts used on this planet. A whimsical attempt to standardize code points for the Klingon language, reported in the first edition, has been rejected. A reader of the first edition sent me the following e-mail comment about this:
I suspect this is rude, and possibly obscene.
-
An ANSI string, normally described by an ANSI_STRING structure, contains 8-bit characters. A variant is an OEM_STRING, which also describes a string of 8-bit characters. The difference between the two is that an OEM string has characters whose graphic depends on the current code page, whereas an ANSI string has characters whose graphic is independent of code page. WDM drivers won t normally deal with OEM strings because they would have to originate in user mode, and some other kernel-mode component will have already translated them into Unicode strings by the time the driver sees them.
-
A null-terminated string of characters. You can express constants using normal C syntax, such as Hello, world! Strings employ 8-bit characters of type CHAR, which are assumed to be from the ANSI character set. The characters in string constants originate in whatever editor you used to create your source code. If you use an editor that relies on the then-current code page to display graphics in the editing window, be aware that some characters might have a different meaning when treated as part of the Windows ANSI character set.
-
A null-terminated string of wide characters (type WCHAR). You can express wide string constants using normal C syntax, such as L"Goodbye, cruel world!" Such strings look like Unicode constants, but, being ultimately derived from some text editor or another, actually use only the ASCII and Latin1 code points (0020-007F and 00A0-00FF) that correspond to the Windows ANSI set.
The UNICODE_STRING and ANSI_STRING data structures both have the layout depicted in Figure 3-13. The Buffer field of either structure points to a data area elsewhere in memory that contains the string data. MaximumLength gives the length of the buffer area, and Length provides the (current) length of the string without regard to any null terminator that might be present. Both length fields are in bytes, even for the UNICODE_STRING structure.
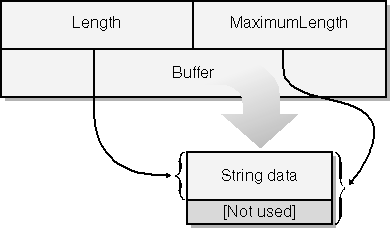
Figure 3-13. The UNICODE_STRING and ANSI_STRING structures.
The kernel defines three categories of functions for working with Unicode and ANSI strings. One category has names beginning with Rtl (for run-time library). Another category includes most of the functions that are in a standard C library for managing null-terminated strings. The third category includes the safe string functions from strsafe.h, which will hopefully be packaged in a DDK header named NtStrsafe.h by the time you read this. I can t add any value to the DDK documentation by repeating what it says about the RtlXxx functions. I have, however, distilled in Table 3-9 a list of now-deprecated standard C string functions and the recommended alternatives from NtStrsafe.h.
| Standard function (deprecated) | Safe UNICODE Alternative | Safe ANSI Alternative |
| strcpy, wcscpy, strncpy, wcsncpy | RtlStringCbCopyW, RtlStringCchCopyW | RtlStringCbCopyA, RtlString CchCopyA |
| strcat, wcscat, strncat, wcsncat | RtlStringCbCatW, RtlStringCchCatW | RtlStringCbCatA, RtlString CchCatA |
| sprintf, swprintf, _snprintf, _snwprintf | RtlStringCbPrintfW, RtlStringCchPrintfW | RtlStringCbPrintfA, RtlStringCchPrintfA |
| vsprintf, vswprintf, vsnprintf, _vsnwprintf | RtlStringCbVPrintfW, RtlStringCchVPrintfW | RtlStringCbVPrintfA, RtlStringCchVPrintfA |
| strlen, wcslen | RtlStringCbLengthW, RtlStringCchLengthW | RtlStringCbLengthA, RtlStringCchLengthA |
NOTE
I based the contents of Table 3-9 on a description of how one of the kernel developers planned to craft NtStrsafe.h from an existing user-mode header named strsafe.h. Don t trust me trust the contents of the DDK!
It s also okay, but not idiomatic, to use memcpy, memmove, memcmp, and memset in a driver. Nonetheless, most driver programmers use these RtlXxx functions in preference:
-
RtlCopyMemory or RtlCopyBytes instead of memcpy to copy a blob of bytes from one place to another. These functions are actually identical in the current Windows XP DDK. Furthermore, for Intel 32-bit targets, both are macro ed to memcpy, and memcpy is the subject of a #pragma intrinsic, so the compiler generates inline code to perform it.
-
RtlZeroMemory instead of memset to zero an area of memory. Rtl ZeroMemory is macro ed to memset for Intel 32-bit targets, and memset is mentioned in a #pragmaintrinsic.

-
The uncounted forms strcpy, strcat, sprintf, and vsprintf (and their Unicode equivalents) don t protect you against overrunning the target buffer. Neither does strncat (and its Unicode equivalent), wherein the length argument applies to the source string.
-
The strncpy and wcsncpy functions will fail to append a null terminator to the target if the source is at least as long as the specified length. In addition, these functions have the possibly expensive feature of filling any leftover portion of the target buffer with nulls.
-
Any of the deprecated functions has the potential to walk off the end of a memory page looking in vain for a null terminator. This trait makes them especially dangerous when dealing with string data coming to you from user mode.
-
As I write this, NtStrsafe.h doesn t currently define any comparison functions (strcmp, etc.). Keep your eye on the DDK for such functions. Note that case-insensitive comparisons of ANSI strings are tricky because they depend on localization settings that can vary from one session to another on the same computer.
Allocating and Releasing String Buffers
You often define UNICODE_STRING (or ANSI_STRING) structures as automatic variables or as parts of your own device extension. The string buffers to which these structures point usually occupy dynamically allocated memory, but you ll sometimes want to work with string constants too. Keeping track of who owns the memory to which a particular UNICODE_STRING or ANSI_STRING structure points can be a bit of a problem. Consider the following fragment of a function:
UNICODE_STRING foo; if (bArriving) RtlInitUnicodeString(&foo, "Hello, world!"); else { ANSI_STRING bar; RtlInitAnsiString(&bar, "Goodbye, cruel world!"); RtlAnsiStringToUnicodeString(&foo, &bar, TRUE); }  RtlFreeUnicodeString(&foo); // <== don't do this!
RtlFreeUnicodeString(&foo); // <== don't do this! In one case, we initialize foo.Length, foo.MaximumLength, and foo.Buffer to describe a wide character string constant in our driver. In another case, we ask the system (by means of the TRUE third argument to RtlAnsiStringToUnicodeString) to allocate memory for the Unicode translation of an ANSI string. In the first case, it s a mistake to call RtlFreeUnicodeString because it will unconditionally try to release a memory block that s part of our code or data. In the second case, it s mandatory to call RtlFreeUnicodeString eventually if we want to avoid a memory leak.
The moral of the preceding example is that you have to know where the memory comes from in any UNICODE_STRING structures you use so that you can release the memory only when necessary.
EAN: 2147483647
Pages: 119