2.4 Clustered systems
|
| < Day Day Up > |
|
A clustered system is a number of things of the same sort organized together, or growing together, to form or represent a group of their respective kind. For example, a number of people, flowers, or things grouped together forms a cluster. Similarly, a group of independent hardware systems or nodes that are interconnected to provide a single computer source is referred to as a hardware cluster. Unlike flowers and other objects, if one node in a cluster fails, its workload is automatically distributed among the surviving nodes. This process of automatically distributing the workload to other available nodes reduces downtime of the entire system. Clustering is an architecture that keeps systems running in the event of a single system failure. Clustering provides maximum scalability by grouping separate servers into a single computing facility. Clusters have the potential to provide excellent price/performance advantages over traditional mainframe systems in many areas, such as availability, scalability, manageability, and recoverability. Clustering plays an essential role in various computing paradigms such as Internets, Intranets, and systems that require uninterrupted high-availability solutions.
Digital Equipment Corporation (now acquired by HP) was an early pioneer in clustering. Its primary operating system, VMS, offered built-in clustering support. There are thousands of companies still successfully running Digital VAXClusters. The VMS operating system offered a single system view of the cluster and allowed both the users and the system administrator to use any node indistinguishably from any other. The proprietary nature of VMS (even after Digital pasted the word ''open'' in front of the operating system name) along with the evolution of super-cheap hardware makes VMS a less demanding product.
2.4.1 Types of clustering
When businesses start small and have low capital budget to invest, it is probable that configurations are minimal, consisting of one or two machines with a storage array to support the database implementation. However, as the business grows, expansion follows and consequently the current configuration (single node, storage system) is not able to handle the increased load due to increased business. It is typical at this point to either upgrade the current hardware by adding more CPUs and other required resources or to add multiple systems to work as a cohesive unit/cluster. However, increasing resources is similar to placing a temporary bandage on the system as it solves the current situation of increased business and demand, but only shifts the issue to be dealt with to a future date as the workload will invariably increase once again. Instead of adding more memory, or CPU, to the existing configuration, which could be referred to as vertical scaling, another system(s) should be added to provide load balancing, workload distribution, and availability. This functionality is achieved by scaling the boxes horizontally, or in a linear fashion, and by configuring these systems to work as a single cohesive unit or a cluster.
Figure 2.5 illustrates the advantages of horizontal scalability over vertical scalability. The growth potential on a vertically scalable system is limited and, as explained earlier, reaches a point where the addition of resources does not provide proportionally improved results. Because clusters offer both horizontal (linear) and vertical scalability, the cluster model provides investment protection. Horizontal scalability is the ability to add more nodes to the cluster to provide more functionality. These nodes may be relatively small and/or inexpensive, offering economical upgradeability options that might offer enhancements to a single large system. Vertical scalability is the ability to upgrade individual nodes to higher specifications.
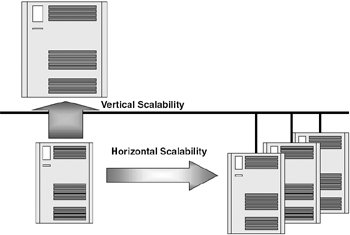
Figure 2.5: Vertical and horizontal/linear scalability representation.
2.4.2 Clustered SMP
A clustered SMP configuration is two SMP systems combined together and managed by one operating system. Working as a cluster provides a single cohesive unit of equipment. Under this configuration, each system has its own processor and memory; however, the storage or disk subsystem is shared between the various systems that participate in the cluster.
Clustering has proven to be a successful architecture of choice for providing high availability and scalability in business-critical computing applications. Clients interact with a cluster as though it were a single entity, or a single high-performance, highly reliable server. If a cluster fails, its workload is automatically distributed among the surviving nodes.
A clustered system is highly integrated by tightly or loosely coupled multiprocessor configurations (or nodes) and storage subsystems commu nicating with one another for the purpose of sharing data and other resources. In Figure 2.6 it should be noted that each system, or node, has its own CPUs, memory controllers, etc.; however, each shares one common disk system. Such a configuration is best suited for an Oracle Parallel Server (OPS, available with Oracle Versions 7.3 and 8.1) and its successor, Real Application Cluster (RAC, available with Oracle 9i).
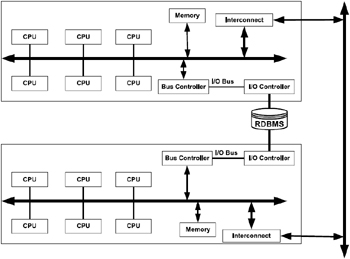
Figure 2.6: Clustered SMP configuration model.
2.4.3 Tightly vs. loosely coupled
Multiprocessing systems can be either tightly or loosely coupled, depending on how hardware resources are allocated among the processors. Tightly coupled systems share system resources. This makes tightly coupled systems less scalable for applications relying on independent processes and data because of the overhead associated with resource sharing. Tightly coupled clustered configurations do not provide any inherent fault-tolerance. The failure of a single critical component, such as the CPU, could bring the entire system down. Tightly coupled systems are more scalable for applications relying on dependent processes and data because through resource sharing their interprocess communications costs are lower.
The opposite of tightly coupled configurations are the loosely coupled configurations or systems. Loosely coupled clusters eliminate some of the drawbacks of SMP systems, providing improved fault tolerance and easier incremental system growth. These loosely coupled SMP clusters comprise multiple nodes, with each node consisting of a single processing unit (SMP unit) and its own dedicated system memory. The storage systems can be configured as ''share nothing'' or ''shared disk'' cluster system with each node having direct access to the disk.
Some of the distinguishing attributes between tightly coupled and loosely coupled multiprocessor configurations are shown in Table 2.1.
| Tightly Coupled | Loosely Coupled |
|---|---|
| Processors in a tightly coupled system share certain hardware resources in a manner that makes interprocessor timing and synchronization absolutely critical. Thus, the processors that make up the CPU of a tightly coupled system typically conform to the same architecture and execute the same instruction set. | In a loosely coupled configuration, processors can conform to different architectures and therefore can execute different operating systems. |
| Processors that make up the CPU resource in a tightly coupled configuration typically execute the same operating system. This enforces the same policies for resource allocation, utilization and control. | Loosely coupled configuration processors can conform to different architectures and therefore can execute different operating systems. |
| Processors in a tightly coupled configuration share hardware resources in a manner that requires all the CPU resources of such a system to be confined to a relatively small area. | In a loosely coupled configuration, the CPU resources are more widely spread apart and lend themselves to a more distributed model. |
| In a tightly coupled system, resources are generally accessible to all processes in that system. A tightly coupled configuration is usually treated as a single management and security domain. | In the case of a loosely coupled configuration each system has its own security domain, management console and could potentially have a different operating system. This makes it very difficult to manage, support, and operate. |
Figure 2.7 represents a two-node cluster configuration. In the figure, two nodes participate in the cluster configuration; sharing Disk1 and Disk2 as a single disk configuration on a single bus and communication between the nodes A and B is through a high-speed cluster interconnect.
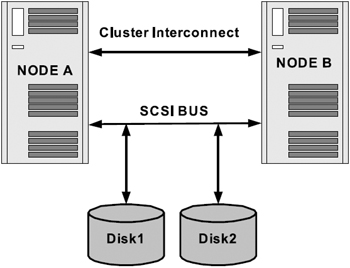
Figure 2.7: Two-node cluster configuration.
This enables users to transparently exploit all available resources on a tightly coupled system. For example, in a loosely coupled implementation of a car rental operation (fully deployed using Oracle products), if the online car availability database system fails, rentals cannot be made, service ultimately suffers, customers are disappointed, and the agency eventually loses business. However, in a tightly clustered configuration, if the system that runs the car availability database system fails, users are transferred to the available node, delivering maximum system availability.
In order to obtain an understanding of ''true'' clustering, the features in each type of configuration must be understood. To help understand these differences it would be advantageous to compare and contrast the behavior of the following areas under tightly and loosely coupled configurations:
-
Resource sharing
-
Common system disk
-
Cost-effective utilization of resources
-
CPU processor composition
-
Operating system composition
-
File system flexibility
-
Flexible user environment
-
High availability
-
Disaster tolerance
-
System management and security
-
Failover
-
Growth potential and scalability
Resource sharing
In today's high-availability, highly scalable environments, availability of resources is a key concern. Systems in the cluster help in cost-effective measures by saving resources through sharing storage devices, printers, and CPU processors. For example:
-
Disk storage is used for read/write operation from the nodes participating in the clustered configuration. Nodes that are not configured to write directly to the storage devices can access the storage devices through one of the other nodes that are defined to provide this service.
-
Printers can be configured such that print jobs can be execute from any of the nodes participating in the clustered configuration.
-
CPU processors on one or more systems can synchronize their access to shared resources. For example, three C programs can simulta neously update a file on a shared disk, and a mixture of C, COBOL, and Java programs can update a common shared disk file. Similarly, four CPU processors can concurrently run independent programs that read and update into the same open file.
Common system disk
Every system or computer, clustered or non-clustered, has disks allocated that contain the system files (or the operating system files), which are essential for regular operation of the system. When nodes are coupled together to form a cluster, each node can still have its own system disk, or the operating system disk, or can share a common disk that contains one single copy of the operating system. While there are positives and negatives in either approach, it is ideal to have separate copies of the operating system for each system to provide availability during any disk failure of any one system in the cluster.
We will discuss the storage subsystems in more detail later in this chapter.
Cost-effective utilization of resources
On regular systems, a certain number of disks are assigned or attached to the system. These disks are often backed up and data from them is deleted to create more space for more data. Under circumstances where the data is critical and cannot be deleted, the standard option would be to purchase more storage disks and attach them to the node that requires more space. Similarly, when the system is fully utilized, the options available are to shut down certain processes that are consuming the CPU or to buy more CPUs and plug them into the nodes. Buying such resources is expensive, and the money could be utilized more effectively in other areas.
A loosely coupled clustering configuration provides a solution to this. If the disks are utilized over the limit, and the other disk(s) are idle, then the other disks could be shared amongst the nodes that need more disk storage. Please note that in today's deployment scenarios, on most systems, the disks are available to all nodes in the cluster. This is also true with the utilization of resources such as the CPU. If one node of a two-node clustered configuration has its CPUs utilized to the maximum, then certain processors could be transferred to the node that has CPU resources available and executed from there.
CPU processor composition
Timing and synchronization are critical among processors in a single, tightly coupled multiprocessor system. These processors usually conform to the same architecture. Consequently, if a system has two CPUs they should be of the same type and execute the same instruction set, sharing a common in-memory copy of the operating system.
A loosely coupled configuration can incorporate multiple processor types with varying processor types from system to system. In spite of this support being available, this option is seldom practiced, as it is more of a theoretical concept rather than a practical solution. Normally, all nodes in a clustered configuration have the same sets or number of CPUs and are of the same processor types. This helps in load balancing and compatibility in execution of processors when one system fails and users or processes are transferred to the other node in the cluster.
Operating system and file system flexibility
In the case of loosely coupled systems, different operating systems could run on each node in the cluster. These types of configuration add complexity from many aspects. Most operating systems have a different read/write structure and the shared disks cannot share the files across both operating systems. For example, if one node has the Unix operating system and the other has VMS, there could be considerable incompatibility in the file systems for both operating systems. Thus, when a process executing on the VMS system creates a file, it has a specific storage structure based on the internals of the VMS operating system. A process compiled and executing on another operating system, such as Unix, could not normally read this.
However, when both the operating systems are of the same type (for example, Unix is located on both machines), then the file system is compatible. This could create a situation in which the files may be read to or written from either or both nodes 100% of the time.
The same rule holds true in the case of security and protection mechanisms. Varying the operating system could create detrimental situations for system managers and may cause them to deal with multiple security and authentication rules for both operating systems. However, when all nodes participating in the cluster have the same operating system, the difference will not exist and operability is much more simple and convenient.
The cluster file system makes all files visible to and accessible by all cluster members such that all members participating in the clustered configuration hold the same view.
Flexible user environment
Users and resources can easily be distributed to meet the specific needs of the environment, and they can easily be redistributed as those needs change over time.
Certain clustered configurations such as Tru64 Unix clusters[1] allow users to log into a cluster level address called a cluster alias (a cluster alias is an Internet Protocol (IP) address that makes some or all of the systems in the cluster look like a single system) and the cluster load balance distributes the user to the appropriate node in the cluster based on availability of resources. The load-balancing feature at the operating system level helps in workload distribution and removes the need for load balancing routers at the hardware level. The load balancing option frees up the clients from having to connect to a specific cluster member for services. In clustered systems that are set up to use cluster aliases, each system in a cluster explicitly joins with the aliases to which it wants to belong. If a member of an alias is unavailable, the cluster stops sending packets to that member and routes packets to active members of that alias.
The cluster alias supports load balancing between the nodes participating in the clustered configuration. The load balancing can be achieved in many different ways; however, the simplest solution is round- robin Domain Name Service (DNS). A round-robin DNS is where a single DNS name is shared among several IP addresses. When a query is made to the DNS server, it reuses the returned IP addresses.
Another major benefit of this configuration is that a client is able to interact with a cluster as though the cluster is a single server, even though many servers may be part of the cluster. The cluster provides a single management entity. As discussed earlier, clustering provides increased availability, greater scalability, and easier management.
High availability
High availability has various meanings in today's computing environ ment, which differ from person to person. The term ''availability,'' in the context of a computer system, implies that the system is available for use. Availability of a system is probably the most important property that the computer system should have. If a system is not available to run the workloads it is intended to run and to perform the tasks that are vital to the business, then it does not matter how fast it is or how much memory it has, it basically becomes an expensive pile of useless material.
The term ''high availability'' means that the system is available most of the time. In today's Internet-based computing environment, this require ment has been defined at 99.999% (or five-nine availability). This means that systems have a continuous uptime including nights and weekends, days, months, and years.
In the fiercely competitive arena of the Internet business, if the web site is not available, or the system is unable to process an order because the backend server is down, it is highly probable that the customer would attempt to access the site a second time, but probably not a third time. This could mean a loss of a potential new customer or damaged relationship with an existing one. All businesses, large and small, need increased availability to stay competitive. Running a business 7 days a week for 24 hours a day has become the standard and a necessity for a company at all levels (small, medium, or large).
High availability is configured in today's systems by providing redundancy at all levels of the system, including connections, network, controllers, nodes, disks, etc. Figure 2.8 represents a two-node total redundancy system with failover options at every level of the equipment. This type of totally redundant configuration supports and provides a higher availability and includes the following functions:
-
When a system leaves the cluster, the remaining systems go through a cluster state transition and, during this phase, automatically adjusts the new cluster membership.
-
When one path to the storage device fails, the device can be accessed through an alternate path.
-
If one communication path fails, systems that are part of the clustered configuration can still exchange information on the remaining communication paths.
-
Using volume shadowing and a mirrored disks option provides availability at the disk subsystem/storage level. This means when one disk fails, the information is still available on the other mirrored disk. For example, in a RAID 1 configuration, which is mirror only, a copy of the data is simultaneously saved on disks; that is, the original disk and the mirrored disk. When one of the disks is unusable, the system continues operation by accessing the other disk as if no loss was encountered. Because of this, users are not affected.
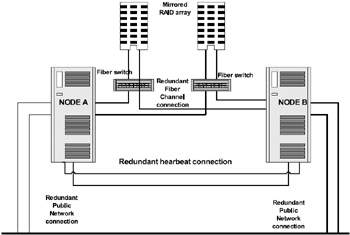
Figure 2.8: Various levels of redundancy for high-availability systems.
The high-availability scenario also applies to application systems accessing the clustered configuration. In the event of a server failure (due to hardware, application, or operator fault) another node, configured as the secondary node, automatically assumes the responsibilities of the primary node. At this point, users are switched to that node without operator intervention. This switch minimizes downtime.
A cluster is designed to avoid a single point of failure. Applications are distributed over more than one computer, achieving a degree of parallelism, failure recovery and providing high availability.
In a clustered configuration, applications can be configured or developed to run as:
-
Single instance applications
-
Multi-instance applications
-
Distributed applications
In a single instance application configuration, the application runs on only one node at a time. In case of failure of the original node, the cluster should provide for the starting of the application on the other available node, in order to meet the high-availability specification.
Where multiple instances of an application can run on multiple nodes simultaneously, failure of a single node does not affect the application.
In the case of failure of a single node on a distributed application, the failed node communicates with the cluster interconnect of the failure and coordinates a handshake operation to take care of continuing operations.
Disaster tolerance
An ''Act of God'' (such as fire, hurricane, tornado, earthquake, flood, or lightning strike) can destroy computer systems, which, in turn, detrimentally affects users, organizations, and customers, leaving them without access to business-critical applications and data.
Systems are disaster tolerant if they can survive the loss of a major computing site due to reasons mentioned above.
Systems may be protected from the ''Act of God'' scenarios in the clustered configuration when the systems are spread across a large geography.
Using interconnects such as Ethernet and FDDI, systems can be configured such that the computing and storage components are spread over a moderate-sized geography. Using volume shadowing or a RAID 1, data can be duplicated to different sites.
System management and security
Each system maintains its own identity in the cluster configuration. Nodes in the cluster are managed as a single system. Therefore, the systems that participate in the cluster configuration have the same security and system management. Additionally, security policies associated with one system in the cluster are applicable to all other systems participating in the clustered configuration.
For the reasons listed above, it would be ideal to configure all nodes participating in the cluster to have the same operating system. Doing so provides the same security and management structure and supports identical configuration of nodes. This helps the migration of users to the secondary node to be made without much difficulty and to be done in such a way that is transparent to the users.
Failover
On clustered hardware, many nodes access or share the same resources. For example, the database resides on shared disks, visible to two or more nodes. Clustering of nodes helps in node failover. When one node in a cluster fails, the users of the application are transferred to the other machine, or node, allowing the application continuous access (to the database, for example). This failover is done by the operating system and is managed by a cluster manager (CM). The CM provides a service intended primarily to provide failover support for applications such as databases, messaging systems, enterprise resource planning (ERP) applications, and file/print services.
In the event of hardware or software failure occurring in either node, the applications currently running on that node are migrated by the CM to the surviving node and then restarted.
Growth potential and scalability
Computers that perform adequately under current load and business circumstances may not necessarily perform adequately in the future. Any resource in a system is finite. Eventually, it is likely that, as workload increases or as the system is called upon to perform tasks other than those it was originally intended to, resources become constrained and performance is impacted.
As discussed in the early part of this chapter, one possibility in such situations is to increase the resources through options such as the addition of more memory, increasing the number of processors, or increasing further I/O capabilities (i.e., adapters or disks). Adding these additional resources constitutes the vertical scalability of the system and is within the available unit itself.
When considering the scenario where a system is unable to accept any more additional resources, two possible solutions become evident. The first solution, which could be rather costly, is to replace the hardware configurations with a later model that would allow for the expansion of resources. However, this solution could potentially postpone the problem to a later date, as it is probable that the upgraded system would reach maximum capacity too. The second solution would be to add another computer to the system and distribute the work across both machines.
Horizontal scalability provides the ability to add more computers linearly and to distribute work across them. This allows the entire system to scale well beyond the limitations of a single system. The vertical and horizontal/linear scalability of the systems is shown in Figure 2.5. When the computers are vertically scaled, the system configuration increases due to the computer now having additional resources compared to the original configuration. Under the horizontal/linear scalability, the size of the computer remains the same but another computer is added, almost doubling the resources and aiding in distribution of load between both computers. Horizontal scalability also provides higher availability because if one node fails users can be migrated to the other available computer.
[1]COMPAQTru64 Unix Version 5.1 and above when the clustering version is installed.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174