SEQUENTIAL TEST PLANS
Sequential test plans can also be used for variables demonstration tests. The sequential test leads to a shorter average number of part hours of test exposure if the population MTBF is near s , d (i.e., close to the specified or design MTBF).
EXPONENTIAL DISTRIBUTION SEQUENTIAL TEST PLAN
This test plan can be used when:
-
The demonstration test is based upon time-to-failure data.
-
The underlying probability distribution is exponential.
The method to be used for the exponential distribution is to:
-
Identify s , d , ± , and ²
-
Calculate accept/reject decision points
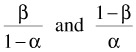
Evaluate the following expression for the exponential distribution:
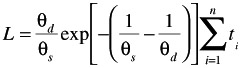
where t i = time to failure of the ith unit tested and n = number tested .
If L > ![]() , the test is failed.
, the test is failed.
If L < ![]() , the test is passed.
, the test is passed.
If 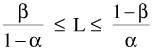 , the test should be continued . -a a
, the test should be continued . -a a
A graphical solution can also be used by plotting decision lines:
nb - h 1 and nb + h 2
where n = number tested; ![]()
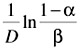 .
.
Let t i equal time to failure for the ith item. Make conclusions based on the following:
If ![]() < nb “ h 1 , the test has failed.
< nb “ h 1 , the test has failed.
If ![]() ‰ nb + h 2 , the test is passed.
‰ nb + h 2 , the test is passed.
If nb “ h 1 ‰ ![]() < nb + h 2 , continue the test.
< nb + h 2 , continue the test.
| |
Assume you are interested in testing a new product to see whether it meets a specified MTBF of 500 hours with a consumer's risk of 0.10. Further, specify a design MTBF of 1000 hours for a producer's risk of 0.05. Run tests to determine whether the product meets the criteria.
Determine D based on the known criteria:
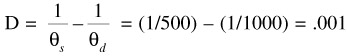
Then calculate
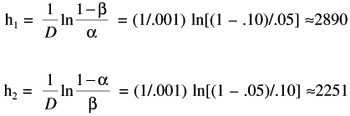
Now solve for b
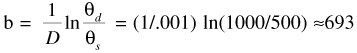
Using these results, we can determine at which points we can make a decision, by using the following:
If ![]() < nb - h 1 , 693n - 2890, the test has failed.
< nb - h 1 , 693n - 2890, the test has failed.
If ![]() ‰ nb + h 2 , 693n + 2251, the test is passed.
‰ nb + h 2 , 693n + 2251, the test is passed.
| |
If nb - h 1 ‰ ![]() < nb + h 2 , 693n - 2890 ‰
< nb + h 2 , 693n - 2890 ‰ ![]() < 693n + 2251, continue the test.
< 693n + 2251, continue the test.
WEIBULL AND NORMAL DISTRIBUTIONS
Sequential test methods have also been developed for the Weibull distribution and for the normal distribution. If you are interested in pursuing the sequential tests for either of these distributions, see the selected bibliography
INTERFERENCE (TAIL) TESTING
Interference demonstration testing can sometimes be used when the stress and strength distributions are accurately known. If a random sample of the population is obtained, it can be tested at a point stress that corresponds to a specific percentile of the stress distribution. By knowing the stress and strength distributions, the required reliability, the desired confidence level, and the number of allowable failures, it is possible to determine the sample size required.
RELIABILITY VISION
Reliability is valued by the organization and is a primary consideration in all decision making. Reliability techniques and disciplines are integrated into system and component planning, design, development, manufacturing, supply, delivery, and service processes. The reliability process is tailored to fit individual business unit requirements and is based on common concepts that are focused on producing reliable products and systems, not just components .
RELIABILITY BLOCK DIAGRAMS
Reliability block diagrams are used to break down a system into smaller elements and to show their relationship from a reliability perspective. There are three types of reliability block diagrams: series, parallel, and complex (combination of series and parallel).
-
A typical series block diagram is shown in Figure 7.2 with each of the three components having R1, R2, and R3 reliability respectively.

Figure 7.2: A series block diagram.The system reliability for the series is
R total = (R 1 ) (R 2 ) (R 3 ) ... (Rn)
| |
If the reliability for R1 = .80, R2 = .99, and R3 = .99, the system reliability is: R total = (.80)(.99)(.99) = .78. Please notice that the total reliability is no more than the weakest component in the system. In this case, the total reliability is less than R1.
-
A parallel reliability block diagram shows a system that has built-in redundancy. A typical parallel system is shown in Figure 7.3. The system reliability is
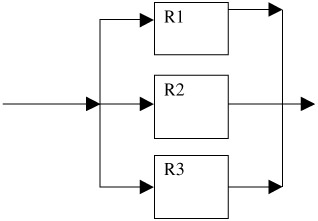
Figure 7.3: A parallel reliability block diagram.R total = 1 - [1 - R 1 (t) (1 - R 2 (t) (1 - R 3 )(t) ... (1 - R n (t)]
| |
| |
If the reliability for R1 = .80, R2 = .90, and R3 = .99, the system reliability is: R total = 1 - [(1 - .80)(1 - .90)(1 - .99)] = .9998 Please notice that the total reliability is more than that of the strongest component in the system. In this case, the total reliability is more than the R3.
-
Complex reliability block diagrams show systems that combine both series and parallel situations. A typical complex system is shown in Figure 7.4. The system reliability for this system is calculated in two steps:
-
Step 1. Calculate the parallel reliability.
-
Step 2. Calculate the series reliability ” which becomes the total reliability.
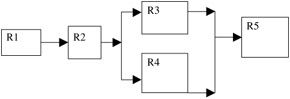
Figure 7.4: A complex reliability block diagram. -
| |
| |
If the reliability for R1 = .80, R2 = .90, R3 = .95, R4 = .98, and R5 = .99, what is the total reliability for the system?
-
Step 1. The parallel reliability for R3 and R4 is
-
R total = l - [1 - R 1 (t) (1 - R 2 (t) = 1 - [1 - .95) (1 - .98)] = .999
-
-
Step 2. The series reliability for R1, R2, (R3 & R4), and R5 is
-
R total = (R 1 ) (R 2 ) (R 3 & R 4 ) (R 5 ) = (.80)(.90)(.999)(.99) = .712
-
Please notice that the parallel reliability was actually converted into a single reliability and that is why it is used in the series as a single value.
| |
WEIBULL DISTRIBUTION ” INSTRUCTIONS FOR PLOTTING AND ANALYZING FAILURE DATA ON A WEIBULL PROBABILITY CHART
This technique is useful for analyzing test data and graphically displaying it on Weibull probability paper. The technique provides a means to estimate the percent failed at specific life characteristics together with the shape of the failure distribution. The following procedure presents a manual method of conducting the analysis, but many computer programs can do the same calculations and also plot the Weibull curve. Weibull analysis is one of the simpler analytical methods, but it is also one of the most beneficial. The technique can be utilized for other than just analyzing failure data. It can be used for comparing two or more sets of data such as different designs, materials, or processes. Following are the steps for conducting a Weibull analysis.
-
Gather the failure data (it can be in miles, hours, cycles, number of parts produced on a machine, etc.), then list in ascending order. For example: We conduct an experiment and the following failures (sample size of 10 failures) are identified (actual hours to failure): 95, 110, 140, 165, 190, 205, 215, 265, 275, and 330.
-
Using the table of median ranks (Table 7.2), find the column corresponding to the number of failures in the sample tested. In our example we have a sample size of ten, so we use the "sample size 10" column. The "% Median Ranks" are then read directly from the table.
-
Match the hours (or some other failure characteristic that is measured) with the median ranks from the sample size selected. For example:
Actual Hours to Failure
% Median Ranks
95
6.7
110
16.2
140
25.9
Sample size of 10 failures
165
35.5
190
45.2
205
54.8
215
64.5
265
74.1
275
83.8
330
93.3
-
In constructing the Weibull plot, label the "Life" on the horizontal log scale on the Weibull graph in the units in which the data were measured. Try to center the life data close to the center of the horizontal scale (Figure 7.5).
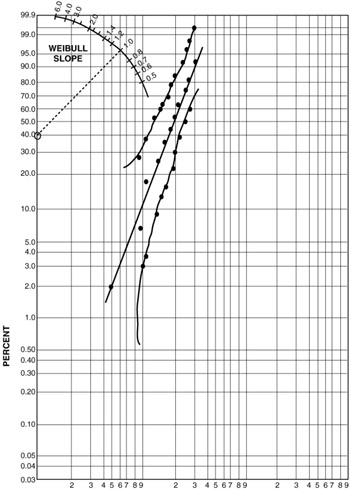
Figure 7.5: The Weibull distribution for the example. -
Plot each pair of "actual hours to failure" (on the horizontal logarithmic scale) and "% median rank" (on the vertical axis, which is a log-log scale) on the graph. The matching points are shown as dots (" s") on Figure 7.5. Draw a "line of best fit" ( generally a straight line) as close to the data pairs as possible. Half the data points should be on one side of the line, and the other half should be on the other side. No two people will generate the exact same line, but analysts should keep in mind that this is a visual estimate. (If the line is computer generated, it is actually calculated based on the "best fit" regression line.)
-
After the line of "best fit" is drawn, the life at a specific point can be found be going vertically to the "Weibull line" then going horizontally to the "Cumulative % Failed." In other words, this is the percent that is expected to fail at the life that was selected. In the example, 100 was selected as the life, then going up to the line and then across, we can see the expected % failed to be 10%. In this case, the life at 100 hours is also known as the B 10 life (or 90% reliability) and is the value at which we would expect 10% of the parts to fail when tested under similar conditions. (Please note that there is nothing secret about the B 10 life. Any B x life can be identified. It just happens that the B 10 is the conventional life that most engineers are accustomed to using.) In addition, we can plot the 5% and the 95% confidence using Tables 7.3 and 7.4 respectively.
Table 7.3: Five Percent Rank Table
Sample Size (n)
1
1
2
3
4
5
6
7
8
9
10
1
5.000
2.532
1.695
1.274
1.021
0.851
0.730
0.639
0.568
0.512
2
22.361
13.535
9.761
7.644
6.285
5.337
4.639
4.102
3.677
3
36.840
24.860
18.925
15.316
12.876
11.111
9.775
8.726
4
47.237
34.259
27.134
22.532
19.290
16.875
15.003
5
54.928
41.820
34.126
28.924
25.137
22.244
6
60.696
47.820
40.031
34.494
30.354
7
65.184
52.932
45.036
39.338
8
68.766
57.086
49.310
9
71.687
60584
10
74.113
Sample Size (n)
j
11
12
13
14
15
16
17
18
19
20
1
0.465
0.426
0.394
0.366
0.341
0.320
0.301
0.285
0.270
0.256
2
3.332
3.046
2.805
2.600
2.423
2.268
2.132
2.011
1.903
1.806
3
7.882
7.187
6.605
6.110
5.685
5.315
4.990
4.702
4.446
4.217
4
13.507
12.285
11.267
10.405
9.666
9.025
8.464
7.969
7.529
7.135
5
19.958
18.102
16.566
15.272
14.166
13.211
12.377
11.643
10.991
10.408
6
27.125
24.530
22.395
20.607
19.086
17.777
16.636
15.634
14.747
13.955
7
34.981
31.524
28.705
26.358
24.373
22.669
21.191
19.895
18.750
17.731
8
43.563
39.086
35.480
32.503
29.999
27.860
26.011
24.396
22.972
21.707
9
52.991
47.267
42.738
39.041
35.956
33.337
31.083
29.120
27.395
25.865
10
63.564
56.189
50.535
45.999
42.256
39.101
36.401
34.060
32.009
30.195
11
76.160
66.132
58.990
53.434
48.925
45.165
41.970
39.215
36.811
34.693
12
77.908
68.366
61.461
56.022
51.560
47.808
44.595
41.806
39358
13
79.418
70.327
63.656
58.343
53.945
50.217
47.003
44.197
14
80.736
72.060
65.617
60.436
56.112
52.420
49.218
15
81.896
73.604
67.381
62.332
58.088
54.442
16
82.925
74.988
68.974
64.057
59.897
17
83.843
76.234
70.420
65.634
18
84.668
77.363
71.738
19
85.413
78.389
20
86.089
Table 7.4: Ninety-five Percent Rank Table
Sample Size (n)
j
1
2
3
4
5
6
7
8
9
10
1
95.000
77.639
63.160
52.713
45.072
39.304
34.816
31.234
28.313
25.887
2
97.468
86.465
75.139
65.741
58.180
52.070
47.068
42.914
39.416
3
98.305
90.239
81.075
72.866
65.874
59.969
54.964
50.690
4
98.726
92.356
84.684
77.468
71.076
65.506
60.662
5
98.979
93.715
87.124
80.710
74.863
69.646
6
99.149
94.662
88.889
83.125
77.756
7
99.270
95.361
90.225
84.997
8
99.361
95.898
91.274
9
99.432
96.323
10
99.488
Sample Size (n)
j
11
12
13
14
15
16
17
18
19
20
1
23.840
22.092
20.582
19.264
18.104
17.075
16.157
15.332
14.587
13.911
2
36.436
33.868
31.634
29.673
27.940
26.396
25.012
23.766
22.637
21.611
3
47.009
43.811
41.010
38.539
36.344
34.383
32.619
31.026
29.580
28.262
4
56.437
52.733
49.465
46566
43.978
41.657
39.564
37.668
35.943
34366
5
65.019
60.914
57.262
54.000
51.075
48.440
46.055
43.888
41.912
40.103
6
72.875
68.476
64.520
60.928
57.744
54.835
52.192
49.783
47.580
45.558
7
80.042
75.470
71.295
67.497
64.043
60.899
58.029
55.404
52.997
50.782
8
86.492
81.898
77.604
73.641
70.001
66.663
63.599
60.784
58.194
55.803
9
92.118
87.715
83.434
79.393
75.627
72.140
68.917
65.940
63.188
60.641
10
96.668
92.813
88.733
84.728
80.913
77.331
73.989
70.880
67.991
65.307
11
99.535
96.954
93.395
89.595
85.834
82.223
78.809
75.604
72.605
69.805
12
99.573
97.195
93.890
90.334
86.789
83.364
80.105
77.028
74.135
13
99.606
97.400
94.315
90.975
87.623
84.366
81.250
78.293
14
99.634
97.577
94.685
91.535
88.357
85.253
82.269
15
99.659
97.732
95.010
92.030
89.009
86.045
16
99.680
97.868
95.297
92.471
89.592
17
99.699
97.989
95.553
92.865
18
99.715
98.097
95.783
19
99.730
98.193
20
99.744
The confidence lines are drawn for our example in Figure 7.5. The reader will notice that the confidence lines are not straight. That is because as we move in the fringes of the reliability we are less confident about the results.
-
The graph can be used for estimating the cumulative % failure at a specified life, or it can be used for determining the estimated life at a cumulative % failure. In the example, we would expect 63.2% of the test units to fail at 222 hours. This value at 63.2% is also known as the characteristic life or the mean time between failures (MTBF) for the example distribution. Or looking at the chart another way, we would like to estimate the failure hours at a specified % failure. For example at 95% cumulative % failed, the hours to failure are 325 hours. Once the Weibull plot is determined, an analyst can go either way.
-
The Weibull graph can also be used to estimate the reliability at a given life, using the equation of R(t) = 1 - F(t). A designer who wishes to estimate the reliability of life at 200 hours would go vertically to the Weibull line, then go horizontally to 52%, which is the percent expected to fail. The estimated reliability at 200 hours would be 1 - 0.52 = 0.48 or 48%. At 80 hours it would be 1 - 0.056 = 0.944 or 94.4%. The slope is obtained by drawing a line parallel to the Weibull line on the Weibull slope scale that is in the upper left corner of the chart.
-
If a computer program is used, the calculation for the line of best fit is determined by the computer. Some programs draw the graph and show the paired points, the line of best fit (using the least squares method or the maximum likelihood method), the reliability at a specified hour (or other designated parameter), and the slope of the line.
-
One of the interesting observations regarding the Weibull graph is the interpretations that can be made about the distribution by the portrayal of the slope. When the slope is:
-
Less than 1, this indicates a decreasing failure rate, early life, or infant mortality
-
Approximately 1, the distribution indicates a nearly constant failure rate (useful life or a multitude of random failures)
-
Exactly 1, the distribution has an exponential pattern
-
Greater than 1, the start of wear out
-
Approximately 3.55, a normal distribution pattern,
-
-
Weibull plots can be made if test data also include test samples that have not failed. Parts that have not failed (for whatever reason during the testing) can be included in the calculations together with the failed parts or assemblies. The non-failed data are referred to as suspended items. The method of determining the Weibull plot is shown in the next set of instructions.
INSTRUCTIONS FOR PLOTTING FAILURE AND SUSPENDED ITEMS DATA ON A WEIBULL PROBABILITY CHART
-
Gather the failure and suspended items data, then including the suspended items, list in ascending order.
Item Number
Hours to Failure or Suspension
Failure or Suspension Code [a]
1
95
F1
2
110
F2
3
140
F3
4
165
F4
Sample Size 13 10 failures 3 suspensions
5
185
S1
6
190
F5
7
205
F6
8
210
S2
9
215
F7
10
265
F8
11
275
F9
12
330
F10
13
350
S3
[a] Code items as failed (F) or suspended (S).
-
Calculate the mean order number of each failed unit. The mean order numbers before the first suspended item are the respective item numbers in the order of occurrence, i.e., 1, 2, 3, and 4. The mean order numbers after the suspended items are calculated by the following equations.
Mean order number = (previous mean order number) + (new number)
where, new increment =

and N = total sample size.
For example, to compensate for S1 (first suspended item), new increment = [(13 + 1) -4]/(1 + 8) = 1.111 and the mean order number of F5 (fifth failed item) = 4 + 1.111 = 5.111.
Note Only one new increment is found each time a suspended item is encountered . Mean order number of F6 = 5.111 + 1.111 = 6.222.
New increment for mean order number of F7 = [(13 + 1) - 6.222] (1 + 5) = 1.296.
Then, the mean order number of F7 (seventh failed item) is 6.222 + 1.296 = 7.518 (and so on for F8, F9, and F10).
This new increment also applies to mean order numbers:
Item Number
Hours to Failure or Suspension
Failure or Suspension Code
Mean Order Number
1
95
F1
1
2
110
F2
2
3
140
F3
3
4
165
F4
4
5
185
S1
”
6
190
F5
5.111
7
205
F6
6.222
8
210
S2
”
9
215
F7
7.518
10
265
F8
8.815
11
275
F9
10.111
12
330
F10
11.407
13
350
S3
”
-
A rough check on the calculations can be made by adding the last increment to the final mean order number. If the value is close to the total sample size, the numbers are correct. In our example, 11.407 + [11.407 - 10.111] = 11.407 + 1.296 = 12.702, which is a close approximation to the sample size of 13.
-
Using the table of median ranks for a sample size of 13 we can determine the median rank for the first four failures, or we can use the approximate median rank formula.
Median rank = [J - .3]/[N + .4]
where J = mean order number and N = total sample size.
For example, the median rank of F5 is:
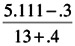 = 0.359
= 0.359 and, the remainder of the failures:
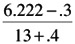 = 0.442
= 0.442 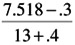 and so on.
and so on. Item Number
Hours to Failure or Suspension
Failure or Suspension Code
Mean Order Number
% Median Rank
1
95
F1
1
5.2
2
110
F2
2
12.6
3
140
F3
3
20.0
4
165
F4
4
27.5
5
185
S1
”
”
6
190
F5
5.111
35.9
7
205
F6
6.222
44.2
8
210
S2
”
”
9
215
F7
7.518
53.9
10
265
F8
8.815
63.5
11
275
F9
10.111
73.2
12
330
F10
11.407
82.9
13
350
S3
”
”
-
Label the "Life" on the horizontal log scale on the Weibull graph in the units in which the data were measured. Try to center the life data close to the center of the horizontal scale.
-
Plot each pair of "actual hours to failure" (on the horizontal scale) and "% median rank" (on the vertical scale) on the graph. Draw a "line of best fit" (generally a straight line) as close to the data pair as possible. Half the data points should be on one side of the line, and the other half should be on the other side.
-
Once the line is drawn, the life at a specific point can be found by going vertically to the "Weibull line" then going horizontally to the "Cumulative % failed." In other words, this is the percent that is expected to fail at the life that was selected. In the example, 200 hours was selected as the life, then going up to the line and then across, we can see the expected % failed to be 40%.
-
Other reliability parameters that can be read from the Weibull plot are:
MTBF
=
240 hours
B 10
=
105 hours
B
=
2.5
Reliability at 100 hours is 1 - 0.09 = 0.91 reading from the graph, or using the Weibull equation
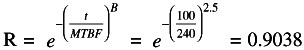
-
Comparing the two examples shows that the analysis with suspended items results in a slightly higher reliability characteristics. This is using the same failure data plus the three suspended items.
ADDITIONAL NOTES ON THE USE OF THE WEIBULL
-
Weibull plotting is an invaluable tool for analyzing life data; however, some precautions should be taken. Goodness-of-fit is one concern. This can be tested with various tests such as the Kolmogorov-Smirnov or Chisquare. The use of an adequate sample size is another concern. Generally a sample size should be greater than ten, but if the failure rate is in a tight pattern (with relatively low variability), this generality may be relaxed . Be suspicious of a curved line that best fits the data. This may indicate a mixed sample of failures or inappropriate sampling.
-
If the Weibull plot is made and a curvilinear relation develops for the connecting points, it usually indicates that two or more distributions are making up the data. This may be due to infant mortality failures being mixed with the data, failures due to components from two different machines or assembly operations, or some other underlying cause. If a curved relationship is indicated, the analyst should revisit the data and try to determine if the data are made up of two or more distributions and then manage each distribution separately.
-
There is another parameter in the Weibull analysis that was not discussed. Beside the shape or slope (b) of the Weibull line and the scale or characteristic life (the mean life or MTBF at the 63.2% cumulative percentage), there is the "location parameter." In most cases it is usually zero and should be of little concern. In effect, it states that the distribution of failure times starts at zero time, which is more often the case because it is difficult to imagine otherwise . The characteristic life splits the distribution in two areas of 0.632 before and 0.368 ( R ( ) =
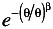 = e -1 = .368) after.
= e -1 = .368) after. -
One of the advantages of using the Weibull is that it is very flexible in its interpretations. A wealth of information can be derived from it. If the Weibull slope is equal to one, the distribution is the same as the exponential, or a constant failure rate. If the slope is in the vicinity of 3.5, it is a "near normal distribution." If the slope is greater than one, the plot starts to represent a wear out distribution, or an increasing hazard rate. A slope less than one generally indicates a decreasing hazard rate, or an infant mortality distribution.
-
Analysts should be careful about extrapolating beyond the data when making predictions . Remember that the failure points fall within certain bounds and that the analyst should have a valid reason when venturing beyond these bounds. When making projections over and above these confines, sound engineering judgment, statistical theory, and experience should all be taken into consideration.
-
The three-parameter Weibull is a distribution with non-zero minimum life. This means that the population of products goes for an initial period of time without failure. The reliability function for the three-parameter Weibull is given by
R(t) =
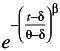 , t ‰
, t ‰ where t = time to failure (t ‰ ); = minimum life parameter ( ‰ 0); ² = Weibull slope ( ² > 0); and = characteristic life ( ‰ ).
For a given reliability
t = +( - ) —
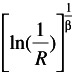
and the B 10 life is
B 10 = +( - ) —
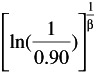
EAN: 2147483647
Pages: 235