Section 7.1. Network-Layer Routing
7.1. Network-Layer RoutingRouting algorithms create procedures for routing packets from their sources to their destinations. Routers are responsible mainly for implementing routing algorithms. These routing tasks are essentially methods of finding the best paths for packet transfer in a network. The choice of routing protocol determines the best algorithm for a specific routing task. As seen in Figure 7.1, a host and a server are two end points connected through routers R4, R7, and R1. Each end point belongs to a separate LAN. In such scenarios, a layer 3 (network) route must be set up for IP packets (datagrams); all devices, including end users and routers, process the route at the third layer of the protocol stack, as shown in the figure. Figure 7.1. End-to-end communication between a client host and a server at the network layer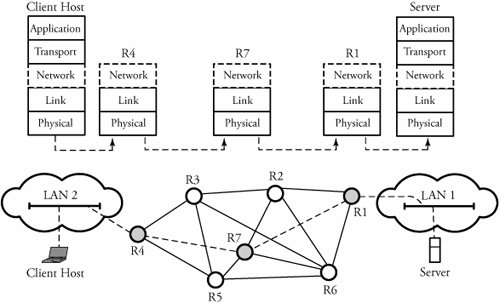 Routing algorithms can be differentiated on several key characteristics:
In practice, this list is used to determine how efficiently a route is selected. The first factor to account for determining the best path to a destination is the volume of traffic ahead. 7.1.1. Assigning Addresses to Hosts and Routers, and DHCPSuppose that LAN 1 in Figure 7.1 has an Internet service provider denoted by ISP 1 and that LAN 2 has an ISP denoted by ISP 2. Assume that ISP 1 handles the LAN 1 networking tasks of two independent local departments with IP address blocks 205.101.8.0/23 and 205.101.10.0/23, respectively. Similarly, ISP 2 handles the LAN 2 networking tasks of two independent local departments with IP address blocks 145.76.12.0/22 and 145.76.14.0/22, respectively. (Recall from Chapter 2 the CIDR IP addressing scheme being used here.) In this scenario, ISP 1 clearly advertises to its outside domains through router R1 that it can process any datagram (IP packet) whose first 22 address bits exactly match 205.101.8.0/22. Note that the outside domains need not know the contents of these two address blocks, as the internal routing within each LAN is handled by an internal server. Similarly, ISP 2 advertises to its outside domains through router R4 that it can process any datagram whose first 21 address bits exactly match 145.76.12.0/22. If for any reason ISP 1 and ISP 2 merge, the least costly solution to avoid changing the address blocks of ISPs is to keep all address blocks unchanged and to have both R1 and R2 advertise to their outside domains that each can process any datagram whose first 22 address bits exactly match 205.101.8.0/22 or whose first 21 address bits exactly match 145.76.12.0/22. IP addresses are organized by the Internet Corporation for Assigned Names and Numbers (ICANN). An ISP can request a block of addresses from ICANN. Then, an organization can also request a block of addresses from its ISP. A block of addresses obtained from an ISP can be assigned over hosts, servers, and router interfaces by a network manager. Note that always a unique IP address must always be assigned to each host as client or server or router interface (input port or output port). However, under some circumstances, a globally unique IP address assignment can be avoided (Section 7.1.2). Dynamic Host Configuration Protocol (DHCP)A different method of assigning addresses to a host is called Dynamic Host Configuration Protocol (DHCP), whereby a host is allocated an IP address automatically. DHCP allows a host to learn its subnet mask, the address of its first-hop router, or even the address of other major local servers. Because this addressing automation lets a host learn several key pieces of information in a network, DHCP is sometimes called a plug-and-play protocol, whereby hosts can join or leave a network without requiring configuration by network managers. The convenience of this method of address assignment gives DHCP multiple uses of IP addresses. If any ISP manager does not have a sufficient number of IP addresses, DHCP is used to assign each of its connecting hosts a temporary IP address. When a host joins or leaves, the management server must update its list of available IP addresses. If a host joins the network, the server assigns an available IP address; each time a host leaves , its address is included in the pool of available addresses. DHCP is especially useful in mobile IP, with mobile hosts joining and leaving an ISP frequently. 7.1.2. Network Address Translation (NAT)Any IP-type device requires a unique IP address. Because of the growing number of Internet users and devices, each requiring a unique IP address, the issue is critical, especially when a new LAN needs to be added to a community network despite a limited number of IP addresses available for that community. Even in very small residential networks, the issue arises when new devices are added to the network. Although the numbers of users, servers, or subnets expands over time, the total allocated IP addresses are still limited to a certain level by the associated ISP. Besides the popularity of IPv6, explained in Chapter 2, an alternative solution, called network address translation (NAT), can be used to overcome the challenge presented by this issue. The idea behind NAT is that all the users and hosts of a private network do not need to have a globally unique addresses. Instead, they can be assigned private and unique addresses within their own private networks, and a NAT-enabled router that connects the private network to the outside world can translate these addresses to globally unique addresses. The NAT-enabled router hides from the outside world the details of the private network. The router acts as a single networking device with a single IP address to the outside world. For example, assume that a private network with a NAT-enabled router is connecting to the outside world. Suppose that all the machines in this network are internally assigned 128.0.0.0/9 and that the output port of the router is assigned an IP address of 197.36.32.4. Now, this network has the advantage that additional machines or even LANs can be added to it and that each can use an address in the block 128.0.0.0/9. Therefore, users and servers within the network can easily use 128.0.0.0/9 addressing to transmit packets to each other, but packets forwarded beyond the network into the Internet clearly do not use these addresses. This way, thousands of other networks can use the same block of addresses internally. Given a datagram received by the NAT-enabled router, we now need to know how the router knows to which internal host it should deliver the datagram. The answer lies in the use of a port number and a NAT translation table in the router.
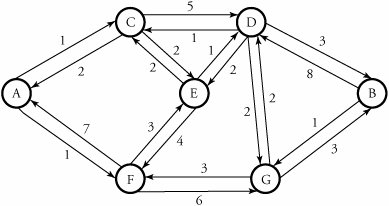
7.1.3. Route CostA packet-switched network consists of nodesrouters or switchesthat are connected by links. A link cost between a pair of source and destination nodes refers to the number of packets currently waiting ahead in the destination node. The goal is to choose a routing based on the minimum number of hops , or least-cost path . For example, Figure 7.2 shows a network in which the lines between each two nodes represent a link and its cost in its corresponding direction. Figure 7.2. A packet-switched network and all link costs The least-cost path between each pair of nodes is the minimum cost of the routing between the two nodes, taking into account all possible links between the two nodes. For example, the least-cost path in Figure 7.2 between nodes A and D is not A-C-D. The calculated cost of this path is 1 + 5 = 6. This is true because the better path is A-C-E-D, with a calculated cost of 1 + 2 + 1 = 4. Thus, the second case has more paths, but it has a lower cost than the first case, which has a shorter path but a higher cost. 7.1.4. Classification of Routing AlgorithmsRouting algorithms can be classified in several ways. One way is to classify them as either least-cost path , whereby the lowest -cost path must be determined for routing, or non-least-cost path , whereby the determination of a route is not based on the cost of a path. Another way is based on whether an algorithm is distributed or centralized . In distributed routing, all nodes contribute in making the routing decision for each packet. In other words, an algorithm in distributed routing allows a node to gain information from all the nodes, but the least-cost path is determined locally. In centralized routing, only a designated node can make a decision. This central node uses the information gained from all nodes, but if the central node fails, the routing function in the network may be interrupted . A special case of centralized routing is source routing , whereby the routing decision is made only by the source server rather than by a network node. The outcome is then communicated to other nodes. Routing can also be classified as either static or dynamic . In static routing, a network establishes an initial topology of paths. Addresses of initial paths are loaded onto routing tables at each node for a certain period of time. The main disadvantage of static routing is that the size of the network has to be small enough to be controllable. Also, if a failure happens in the network, it is unable to react immediately. In dynamic routing, the state of the network is learned through the communication of each router with its neighbors. Thus, the state of each region in the network is propagated throughout the network after all nodes finally update their routing tables. Each router can find the best path to a destination by receiving updated information from surrounding nodes. |
EAN: 2147483647
Pages: 211