10.4 Transforms and the Use of XPath
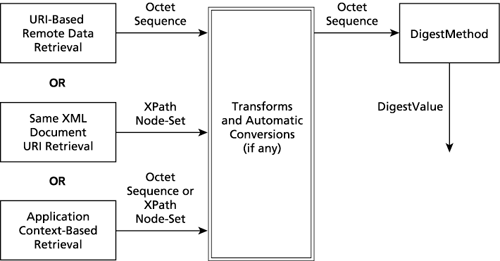
| The raw data retrieved, based on the URI attribute in the Reference element or application context, is passed along through a pipeline of the Transforms, if any. The DigestMethod, which is effectively the last step in this pipeline, produces the DigestValue. See Figure 10-6. At each stage in the pipeline, the data can take one of two forms: a sequence of octets or an XPath node-set. Each Transform algorithm requires one of these forms as implicit input; the final DigestMethod requires an octet sequence for input. Figure 10-6. The data pipeline
This process sounds straightforward, but some complexities arise. We consider them next. 10.4.1 The "XPath" Data ModelImplementation of XPath in an XMLDSIG application is recommended. Signature applications do not need to conform to the XPath specification [Xpath] to conform to XMLDSIG. The XPath data model definitions, such as node-sets, and XPath syntax are used within this chapter to describe functionality for applications that want to sign XML processed as XML, instead of as an octet stream for signature generation. This approach is almost always necessary when processing the SignedInfo element. An XPath implementation provides one way to implement these features, but it is not required. Applications can use a functional replacement for a node-set and implement only those XPath expression behaviors required for XMLDSIG. This book uses XPath terminology without including this qualification on every point. 10.4.2 Dereferencing the URIThe start of the data pipeline occurs when data are fetched, using the value of the URI attribute to the Reference element or based on application context. Two different cases arise in terms of the dereferencing of a Reference element URI:
Same-Document ReferencesIn this type of reference, the URI is null or consists of a fragment. It is the only type of reference that produces a node-set. For example: URI="" URI="#name" Dereferencing a same-document URI results in an XPath node-set suitable for use by Exclusive XML Canonicalization or Canonical XML. More precisely, dereferencing a null URI results in an XPath node-set that includes every noncomment node of the XML document containing a Reference element with this URI attribute. In a fragment URI, the characters after the number sign character ("#") conform to the XPointer syntax (see Chapter 7). The occurrence of a simple name as the fragment of a same document reference, such as "#name" in the preceding example, is a "bare name XPointer" and refers to every noncomment node of the XML subdocument whose apex is the element with that "name" as its ID. When processing an XPointer same-document reference, the application behaves as if the root node of the XML document containing the URI attri bute were used to initialize the XPointer evaluation context. The location-set result of the XPointer processing is converted to a node-set through the following steps:
Step 4 is necessary because XPointer typically indicates a subtree of an XML document's parse tree using just the element node at the root of the subtree. XML canonicalization treats a node-set as a set in which the absence of descendant nodes leads to the omission of their representative text from the canonical form. Step 5 is performed for null URIs, bare name XPointers, and child sequence XPointers. When Exclusive XML Canonicalization and Canonical XML are called with a node-set, they process the node-set as is. Only when they are called with an octet stream do they invoke their own XPath expressions, depending on whether the default or the "WithComments" version was called. To retain comments while selecting an element by an ID, use the following full XPointer: URI='#xpointer(id('name'))' To retain comments while selecting the entire document, use the following full XPointer: URI='#xpointer(/)' This XPointer contains a simple XPath expression that includes the root node, which Step 4 replaces with all nodes of the parse tree (all descendants, plus all attributes, plus all namespace nodes). Support for these two forms of simple XPointers is recommended for XML signature applications. All other XPointer support is optional. Other ReferencesAll other references produce an octet sequence. These references include all non-null URIs without a fragment specifier and fragment specifiers with non-null URI prefixes, even if to an XML document. If a following transform requires node-set input, however, the octet sequence will be parsed as XML. When a URI reference ends with a fragment specifier, the data's MIME type defines the meaning of the fragment. Even for XML documents, a proxy might perform the URI dereferencing including the fragment processing. If fragment processing is not performed in a standard way, the retrieved data could differ, thereby breaking signatures. Consequently, you should avoid URI attributes that include fragment identifiers and carry out the processing with an additional XPath Transform. You should support the same-document XPointers shown next as mentioned earlier, if you also intend to support any canonicalization that preserves comments. (Otherwise, you must use the "#foo" fragment form that will remove comments before the canonicalization can be invoked.) #xpointer(/) #xpointer(id('ID')) All other support for XPointers is optional, especially all support for bare name and other XPointers in external resources. After all, the application may not have control over how the fragment is generated (leading to inter operability problems and verification failures). The following examples demonstrate what the URI attribute identifies and how it is dereferenced: URI="http://example.com/foo.xml" This code identifies the octet sequence that represents the external resource "http://example.com/foo.xml." It is probably an XML document, given its file extension. URI="http://example.com/foo.xml#bar" This code identifies the element with ID attribute value "bar" of the external XML resource "http://example.com/foo.xml," provided as an octet stream. For the sake of interoperability, it would be better to obtain the "bar" element using an XPath transform rather than a URI fragment. The XML signature standard does not require support for bare name XPointer resolution. 10.4.3 The Data PipelineTable 10-1 shows what automatic transform, if any, occurs for all combinations of the output format from one stage of processing and required input to the next stage. In any case where the automatic transform is the wrong choice, you can add an explicit transform to bridge the data formats. This situation is most likely to occur when the automatic transform is Canonical XML, and its effect of stripping out comments or incorporating XML context is not desired. Thus, for some applications, you must specify Exclusive XML Canonicalization to make the signature more robust against changes in the XML context of signed XML. For others, you might need to specify the "with comments" version of either Canonical XML or Exclusive XML Canonicalization if the signature must cover comments.
10.4.4 Transforms Element SyntaxThe syntax for the Transforms element is as follows: <!-- Transforms DTD --> <!ELEMENT Transforms (Transform+)> <!ELEMENT Transform (#PCDATA|XPath %Transform.ANY;)* > <!ATTLIST Transform Algorithm CDATA #REQUIRED > <!ELEMENT XPath (#PCDATA) > In schema notation, it has the following form: <!-- Transforms Schema --> <element name="Transforms" type="ds:TransformsType"/> <complexType name="TransformsType"> <sequence> <element ref="ds:Transform" maxOccurs="unbounded"/> </sequence> </complexType> <element name="Transform" type="ds:TransformType"/> <complexType name="TransformType" mixed="true"> <choice minOccurs="0" maxOccurs="unbounded"> <any namespace="##other" processContents="lax"/> <!-- (1,1) elements from (0,unbounded) namespaces --> <element name="XPath" type="string"/> </choice> <attribute name="Algorithm" type="anyURI" use="required"/> </complexType> |
EAN: 2147483647
Pages: 186