Using SLAMD, the Distributed Load Generation Engine
Using SLAMD , the Distributed Load Generation EngineThe directory server performance benchmark testing in this section is accomplished using the SLAMD application, which is a tool developed by Sun engineering for benchmarking the Sun ONE Directory Server product. It is important to understand that SLAMD was not designed to be used only for testing directory servers. It was intentionally designed in a somewhat abstract manner so that it could be used equally well for load testing and benchmarking virtually any kind of network application. Although most of the jobs provided with SLAMD are intended for use with LDAP directory servers, there are also jobs that can be used for testing the messaging, calendar, portal, identity, and web servers. The SLAMD environment is in essence a distributed computing system with a primary focus on load generation and performance assessment. Each unit of work is called a job, and a job may be processed concurrently on multiple systems, each of which reports results back to the SLAMD server where those results can be viewed and interpreted in a number of ways. The SLAMD environment comprises many components, each of which has a specific purpose. The components of the SLAMD environment include:
In this next section we take a look at SLAMD, which is an extremely useful Java application for benchmarking the Sun ONE Directory Server 5.x, but not limited to the Sun ONE Directory Server. This application is available for download. See "Obtaining the Downloadable Files for This Book" on page xxvii. SLAMD OverviewThe SLAMD Distributed Load Generation Engine is a Java-based application designed for stress testing and performance analysis of network-based applications. Unlike many other load generation utilities, SLAMD provides an easy way to schedule a job for execution, either immediately or at some point in the future, have that job information distributed to a number of client systems, and then executed concurrently on those clients to generate higher levels of load and more realistic usage patterns than a standalone application operating on a single system. Upon completing the assigned task, the clients report the results of their execution back to the server where the data is combined and summarized. Using an HTML-based administrative interface, you can view results, either in summary form or in varying levels of detail. You may also view graphs of the statistics collected and may even export that data into a format that can be imported into spreadsheets or other external applications for further analysis. The SLAMD environment is highly extensible. Custom jobs that interact with network applications and collect statistics can be developed either by writing Java class files or executed using the embedded scripting engine. The kinds of statistics that are collected while jobs are being executed can also be customized. The kinds of information that can be provided to a job to control the way in which it operates is also configurable. Although it was originally designed for assessing the performance of LDAP directory servers, SLAMD is well suited for interacting with any networkbased application that uses either TCP- or UDP-based transport protocols. This section provides information about installing and running the components of the SLAMD environment. Additional topics, like developing custom jobs for execution in the SLAMD environment, are not covered in this book. Installation PrerequisitesBefore SLAMD may be installed and used, a number of preliminary requirements must be satisfied:
Installing the SLAMD ServerOnce all the prerequisites have been filled, it is possible to install the SLAMD server. The following procedure assumes that you have acquired the slamd-1.5.1.tar.gz file. It is available as a downloadable file for this book (see "Obtaining the Downloadable Files for This Book" on page xxvii ) . To Install the SLAMD Server
SLAMD ClientsBecause SLAMD is a distributed load generation engine, the SLAMD server itself does not execute any of the jobs. Rather, the actual execution is performed by SLAMD clients, and the server merely coordinates the activity of those clients. Therefore, before any jobs can be executed, it is necessary to have clients connected to the server to run those jobs. The client application communicates with the SLAMD server using a TC-based protocol. Therefore, it is possible to install clients on different machines than the one on which the SLAMD server is installed. In fact, this is recommended so the client and server do not compete for the same system resources, which could interfere with the ability of the client to obtain accurate results. Further, it is possible to connect to the SLAMD server with a large number of clients to process multiple jobs concurrently. In such cases, it is best to have those clients distributed across as many machines as possible to avoid problems in which the clients are competing with each other for system resources. The following procedure assumes that you have the SLAMD client package called slamd_client-1.5.1.tar.gz . This file is available for download in two ways:
See "Obtaining the Downloadable Files for This Book" on page xxvii for download information. To Install the SLAMD Client
To Start the SLAMD Client
The SLAMD Administration InterfaceAll interaction with the SLAMD server is performed through an HTML administration interface. This interface provides a number of capabilities, including the ability to:
This section provides a brief overview of the administrative interface to describe how it can be used. By default, the administrative interface is accessed through the URL http:// address :8080/slamd , where address is the address of the system on which the SLAMD server is installed. Any browser that supports the HTML 4.01 standard should be able to use this interface, although different browsers may have differences in the way that the content is rendered. Provided that the SLAMD server is running, the left side of the page contains a navigation bar with links to the various tasks that can be performed. This navigation bar is divided into four major sections:
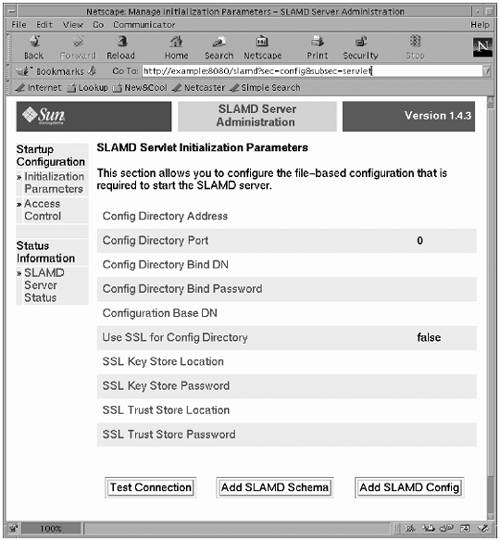
Note If access control is enabled in the administration interface, some sections or options may not be displayed if the current user does not have permission to use those features. Configuring the administrative interface to use access control is documented in a later section. FIGURE 9-10 illustrates the SLAMD administrative interface. Figure 9-10. SLAMD Administrative Interface The Manage Jobs section provides options to schedule new jobs for execution, view results of jobs that have already been completed, view information about jobs that are currently running or awaiting execution, and view the kinds of jobs that may be executed in the SLAMD environment. The Startup Configuration section provides options to edit settings in the configuration file that contain the information required to start the SLAMD server (by default, webapps/slamd/WEB-INF/slamd.conf ). These settings include specifying the settings used for communicating with the configuration directory and the settings used for access control. The SLAMD Configuration section provides options to edit the SLAMD server settings that are stored in the configuration directory. These settings include options to configure the various components of the SLAMD server, and to customize the appearance of the administrative interface. The SLAMD Server Status option provides the ability to view information about the current state of the SLAMD environment, including the number of jobs currently running and awaiting execution, the number of clients that are connected and what each of them is doing, and information about the Java Virtual Machine (JVM) software in which the SLAMD server is running. This section also provides administrators with the ability to start and stop the SLAMD server, and a means of interacting with the cache used for storing access control information. Scheduling Jobs for ExecutionOne of the most important capabilities of the SLAMD server is the ability to schedule jobs for execution. You can schedule them to execute immediately or at some point in the future, on one or more client systems, using one or more threads per client system, and with a number of other options. For a job to be available for processing, it must first be defined in the SLAMD server. You can develop your own job classes and add them to the SLAMD server so that they are executed by clients. The process for defining new job classes is discussed later, but the SLAMD server is provided with a number of default job classes that can be used to interact with an LDAP directory server. To schedule a job for execution, you must first follow the Schedule a Job link in the Manage Jobs section of the navigation sidebar. This displays a page containing a list of all job classes that have been defined to the server. To choose the type of job to execute, follow the link for that job class, and a new page is displayed containing a form in which the user may specify how the job is to be executed. Some of the parameters that can be specified are specific to the type of job that was chosen . The parameters specific to the default job classes are documented in a later section. However, some options are the same for every type of job. The common configuration parameters that are displayed by default are as follows :
The remaining parameters that appear on the form when scheduling a new job are specific to that job type. The default jobs are described later in this book. Regardless of the job type, following the link at the top of the page in the sentence Click here for help regarding these parameters displays a page with information on each of those parameters. Once all appropriate parameters are specified for the job, clicking the Schedule Job button causes those parameters to be validated . Provided that all the values provided were acceptable, the jobs are scheduled for execution. If any of the parameters are unacceptable, an error message is displayed indicating the reason that the provided value was inappropriate. A form is displayed allowing you to correct the problem. Managing Scheduled JobsOnce a job is scheduled for execution, it is added to the pending jobs queue to await execution. Once all of the criteria required to start the job are met (for example, the start time has arrived, the job is not disabled, all dependencies have been satisfied, and an appropriate set of clients is available), that job is moved from the pending jobs queue into the running jobs queue, and the job is sent out to the clients for processing. When the job completes execution, the job is removed from the running jobs queue, and the job information is updated in the configuration directory. As described previously, a job can be in one of three stages:
Viewing Job Execution ResultsOnce a job is executed and all clients have sent the results back to the SLAMD server, those results are made available through the administration interface. Those results are made available in a variety of forms, and the data collected can even be exported for use with external programs like spreadsheets or databases. When the job summary page is displayed for a particular job, all of the parameters used to schedule that job are displayed. If that job has completed execution, additional information is available about the results of that execution. That additional information falls into three categories:
Of these three sections, the one of most interest is that containing the job execution data, because it provides the actual results. Optimizing JobsWhen using SLAMD to run benchmarks against a network application, it is often desirable to find the configuration that yields the best performance. In many cases, this also involves trying different numbers of clients or threads per client to determine the optimal amount of load that can be placed on the server to yield the best results. To help automate this process, SLAMD offers optimizing jobs. An optimizing job is actually a collection of smaller jobs. It runs the same job repeatedly with increasing numbers of threads per client until it finds the number that yields the best performance for a particular statistic. At the present time, optimizing jobs do not alter the number of clients used to execute the job, although that option may be available in the future. There are two ways in which an optimizing job may be scheduled:
Organizing Job InformationAfter the SLAMD server is used to schedule and run a large number of jobs, the page that stores completed job information can grow quite large, and the process of displaying that page can take more time and consume more server resources. Therefore, for the purposes of both organization and conserving system resources, the server offers the ability to arrange jobs into folders. It is also possible to specify a variety of criteria that can be used to search for job information, regardless of the folder in which it is contained. This section provides information on using job folders and searching for job information. Real Job FoldersReal job folders correspond to the location of the job information in the configuration directory. As such, it is only possible for a job to exist in a single real folder. Real job folders are used to store information about jobs that have completed execution so that viewing completed job information does not become an expensive process. Virtual Job FoldersAlthough real job folders can be very beneficial for a number of reasons, they also have some drawbacks that prevent them from being useful in all circumstances. For that reason, the SLAMD server offers the ability to classify jobs in virtual folders in addition to real folders. Virtual job folders offer a number of advantages over real job folders:
The Default Job ClassesWhen the SLAMD server is installed, a number of default job classes are registered with the server. The majority of these job classes are used to generate load against LDAP directory servers, because that is the first intended purpose for SLAMD. However, it is quite possible to develop and execute jobs that communicate with any kind of network application that uses a TCP- or UDP-based protocol. The process for adding custom jobs to the SLAMD server is described later. The remainder of this section describes each of the jobs provided with the SLAMD server by default, including the kinds of parameters that are provided to customize their behavior. Null JobThe null job is a very simple job that does not perform any actual function. Its only purpose is to consume time. When combined with the job dependency feature, it provides the ability to insert a delay between jobs that would otherwise start immediately after the previous job had completed. It does not have any job-specific parameters. Exec JobThe exec job provides a means of executing a specified command on the client system and optionally capturing the output resulting from the execution of that command. It can be used for any purpose, although its original intent is to be used to execute a script that can perform setup or cleanup before or after processing another job (for example, to restore an LDAP directory server to a known state after a job that may have made changes to it). HTTP GetRate JobThe HTTP GetRate job is intended to generate load against web servers using the HTTP protocol. It works by repeatedly retrieving a specified URL using the HTTP GET method, and can simulate the kind of load that can be generated when a large number of users attempt to access the server concurrently using web browsers. LDAP SearchRate JobThe LDAP SearchRate job is intended to generate various kinds of search loads against an LDAP directory server. It is similar to the searchrate command-line utility included in the Sun ONE Directory Server Resource Kit software, but there are some differences in the set of configurable options, and the SLAMD version has support for additional features not included in the command-line version. Weighted LDAP SearchRate JobThe Weighted LDAP SearchRate job is very similar to the SearchRate job, with two exceptions: it is possible to specify two different filters to use when searching, and also to specify a percentage to use when determining which filter to issue for the search. If this is combined with the ability to use ranges of values in the filter, it is possible to implement a set of searches that conform to the 80/20 rule (80 percent of the searches are targeted at 20 percent of the entries in the directory) or some other ratio. This makes it possible to more accurately simulate real-world search loads on large directories in which it is not possible to cache the entire contents of the directory in memory. LDAP Prime JobThe LDAP prime job is a specialized kind of SearchRate job that can be used to easily prime an LDAP directory server (retrieve all or a significant part of the entries contained in the directory so that they may be placed in the server's entry cache, allowing them to be retrieved more quickly in the future). It is true that the process of priming a directory server can often be achieved by a whole subtree search with a filter of (objectClass=*) . However, this job offers two distinct advantages over using that method. The first is that it allows multiple clients and multiple client threads to be used concurrently to perform the priming, which allows it to complete in significantly less time and with significantly less resource consumption on the directory server system. The second is that this job makes it possible to prime the server with only a subset of the data, whereas an (objectClass=*) filter results in the retrieval of the entire data set. One requirement of the LDAP prime job is that it requires that the directory server be populated with a somewhat contrived data set. Each entry should contain an attribute (indexed for equality) whose value is a sequentially incrementing integer. As such, while it can easily be used with data sets intended for benchmarking the performance of the directory server, it is probably not adequate for use on a directory loaded with actual production data. LDAP ModRate JobThe LDAP ModRate job is intended to generate various kinds of modify load against an LDAP directory server. It is similar to the modrate command-line utility included in the Sun ONE Directory Server Resource Kit software, but there are some differences in the set of configurable options. The SLAMD version also has support for additional features not included in the command-line version. LDAP ModRate with Replica Latency JobThe LDAP ModRate with replica latency job is intended to generate various kinds of modify load against an LDAP directory server while tracking the time required to replicate those changes to another directory server. It accomplishes this by registering a persistent search against the consumer directory server and using it to detect changes to an entry that is periodically modified in the supplier directory. The time between the change made on the supplier and its appearance on the consumer is recorded to the nearest millisecond. It is important to note that this job works through sampling. The replication latency is not measured for most of the changes made in the supplier server. Rather, updates are periodically made to a separate entry and only changes to that entry are measured. This should allow the change detection to be more accurate for those changes that are measured, and provide a measurement of the overall replication latency. However, it does not measure the latency of changes made to other entries by other worker threads. Therefore, it is not possible to guarantee that the maximum or minimum latency for all changes is measured. LDAP AddRate JobThe LDAP AddRate job is intended to generate various kinds of add load against an LDAP directory server. It is similar to the infadd command-line utility included in the Sun ONE Directory Server Resource Kit software, but there are some differences in the set of configurable options. The SLAMD version also has support for additional features not included in the command-line version, such as the ability to use SSL and the ability to specify additional attributes to include in the generated entries. Note Because individual clients are unaware of each other when asked to process a job, this job class should never be run with multiple clients. If this job is run on multiple clients, most operations fail because all clients attempt to add the same entries. However, alternatives do exist. It is possible to use one client with many threads because threads running on the same client can be made aware of each other. Additionally, it is possible to create multiple copies of the same job, each intended to run on one client (with any number of threads) but operating on a different range of entries. LDAP AddRate with Replica Latency JobThe LDAP AddRate with replica latency job is intended to generate various kinds of add load against an LDAP directory server while measuring the time required to replicate those changes to another directory server. It is very similar to the LDAP AddRate job, although it does not provide support for communicating over SSL. The process for monitoring replication latency in this job is identical to the method used by the LDAP ModRate job that tests replica latency. That is, a persistent search is registered against a specified entry on the consumer and periodic modifications are performed against that entry on the master directory. The fact that this job performs adds while the test to measure replication latency is based on modify operations is not significant because replicated changes are performed in the order that they occurred regardless of the type of operation (that is, add, modify, delete, and modify RDN operations all have the same priority). Note Because individual clients are unaware of each other when asked to process a job, this job class should never be run with multiple clients. If this job is run on multiple clients, most operations fail because all clients attempt to add the same entries. However, alternatives do exist. It is possible to use one client with many threads because threads running on the same client can be made aware of each other. Additionally, it is possible to create multiple copies of the same job, each intended to run on one client (with any number of threads) but operating on a different range of entries. LDAP DelRate JobThe LDAP DelRate job is intended to generate delete load against an LDAP directory server. It is similar to the ldapdelete command-line utility included in the Sun ONE Directory Server Resource Kit software, but it has many additional features, including the ability to use multiple concurrent threads to perform the delete operations. Note Because individual clients are unaware of each other when asked to process a job, this job class should never be run with multiple clients. If this job is run on multiple clients, most operations fail because all clients attempt to delete the same entries. However, alternatives do exist. It is possible to use one client with many threads because threads running on the same client can be made aware of each other. Additionally, it is possible to create multiple copies of the same job, each intended to run on one client (with any number of threads) but operating on a different range of entries. LDAP DelRate with Replica Latency JobThe LDAP DelRate with replica latency job is intended to generate delete load against an LDAP directory server while measuring the time required to replicate those changes to another directory server. It is very similar to the LDAP DelRate job, although it does not provide support for communicating over SSL. The process for monitoring replication latency in this job is identical to the method used by the LDAP ModRate job that tests replica latency. That is, a persistent search is registered against a specified entry on the consumer and periodic modifications are performed against that entry on the master directory. The fact that this job performs deletes while the test to measure replication latency is based on modify operations is not significant because replicated changes are performed in the order that they occurred regardless of the type of operation (that is, add, modify, delete, and modify RDN operations all have the same priority). Note Because individual clients are unaware of each other when asked to process a job, this job class should never be run with multiple clients. If this job is run on multiple clients, most operations fail because all clients attempt to delete the same entries. However, alternatives do exist. It is possible to use one client with many threads because threads running on the same client can be made aware of each other. Additionally, it is possible to create multiple copies of the same job, each intended to run on one client (with any number of threads) but operating on a different range of entries. LDAP CompRate JobThe LDAP CompRate job is intended to generate various kinds of compare load against an LDAP directory server. The Sun ONE Directory Server Resource Kit software does not have a command-line utility capable of generating load for LDAP compare operations, although it does provide the ldapcmp utility that makes it possible to perform a single compare operation. LDAP AuthRate JobThe LDAP AuthRate job is intended to simulate the load generated against an LDAP directory server by various kinds of applications that use the directory server for authentication and authorization purposes. It first performs a search operation to find a user's entry based on a login ID value. Once the entry has been found, a bind is performed as that user to verify that the provided password is correct and to verify that the user's account has not been inactivated, that the password is not expired , or that the account is not otherwise inactivated. Upon a successful bind, it might optionally verify whether that user is a member of a specified static group, dynamic group , or role. Note The Sun ONE Directory Server Resource Kit software does contain a command-line authrate utility, but the behavior of that utility is significantly different because it only provides the capability to perform repeated bind operations as the same user. LDAP DIGEST-MD5 AuthRate JobThe LDAP DIGEST-MD5 AuthRate job is very similar to the LDAP AuthRate job, except that instead of binding using Simple authentication, binds are performed using the SASL DIGEST-MD5 mechanism. DIGEST-MD5 is a form of authentication in which a password is used to verify a user's identity, but rather than providing the password itself in the bind response (which could be available in clear text to anyone that might happen to be watching network traffic), the password, along with some other information agreed upon by the client and the server, is hashed in an MD5 digest. This prevents the password from being transferred over the network in clear text, although it does require that the server have access to the clear text password in its own database so that it can perform the same hash to verify the credentials provided by the client. Because the only difference between this job and the LDAP AuthRate job is the method used to bind to the directory server, all configurable parameters are exactly the same and are provided in exactly the same manner. LDAP Search and Modify Load Generator JobThe LDAP ModRate job makes it possible to generate modify-type load against an LDAP directory server. To accomplish this, the DNs of the entries to be modified must be explicitly specified, or the DNs of the entries must be constructed from a fixed string and a randomly chosen number. It is possible that neither of these methods are feasible in some environments, and in such cases, the LDAP search and modify job might be more appropriate. Rather than constructing or using an explicit list of DNs, the search and modify job performs searches in the directory server to find entries and performs modifications on the entries returned. LDAP Load Generator with Multiple Searches JobThe LDAP load generator with multiple searches job provides the capability to perform a number of operations in an LDAP directory server. Specifically, it is able to perform add, compare, delete, modify, modify RDN, and up to six different kinds of search operations in the directory with various relative frequencies. It is very similar to the LDAP load generator job, with the exception that it makes it possible to perform different kinds of searches to better simulate the different kinds of search load that applications can place on the directory. Note That the different kinds of searches to be performed should be specified using filter files it is not possible to specify filter patterns for them. Solaris OE LDAP Authentication Load Generator JobThe Solaris OE LDAP authentication load generator is a job that simulates the load that Solaris 9 OE clients place on the directory server when they are configured to use pam_ldap for authentication. Although this behavior can vary quite dramatically based on the configuration provided through the idsconfig and ldapclient utilities, many common configurations can be accommodated through the job parameters. In particular, the lookups can be configured to be performed either anonymously or through a proxy user, using either simple or DIGEST-MD5 authentication with or without SSL. The directory server against which the authentication is to be performed should be configured properly to process authentication requests from Solaris clients. It may be configured in this manner using the idsconfig and ldapaddent tools provided with the Solaris OE, with at least the passwd , shadow , and hosts databases imported into the directory. However, it may be more desirable to simulate this information. The appropriate information may be simulated using the MakeLDIF utility with the solaris.template template file. The data produced in that case is more suited for use by this job because all user accounts can be created with an incrementing numeric value in the user ID and with the same password, which makes it possible to simulate a much broader range of users authenticating to the directory server. The full set of parameters that may be used to customize the behavior of this job is as follows:
SiteMinder LDAP Load Simulator JobAs its name implies, the SiteMinder LDAP load simulation job attempts to simulate the load that Netegrity SiteMinder (with password services enabled) places on a directory server whenever a user authenticates. This simulation was based on information obtained by examining the directory server's access log during a time that SiteMinder was in use. POP CheckRate JobThe POP CheckRate job provides the capability to generate load against a messaging server that can communicate using POP3. It chooses a user ID, authenticates to the POP server as that user, retrieves a list of the messages in that user's mailbox, and disconnects from the server. IMAP CheckRate JobThe IMAP CheckRate job is very similar to the POP CheckRate job, except that it communicates with the messaging server over IMAPv4 instead of POP3. Like the POP CheckRate job, it chooses a user ID, authenticates to the POP server as that user, retrieves a list of the messages in that user's INBOX folder, and disconnects from the server. Calendar Initial Page Rate JobThe Calendar Initial Page Rate job provides the capability to generate load against the Sun ONE Calendar Server version 5.1.1. It does this by communicating with the Calendar Server over HTTP and simulating the interaction that a web-based client would have with the server when a user authenticates to the server and displays the initial schedule page. It is important to note that because of the way in which this job operates and the specific kinds of requests that are required, it may not work with any version of the Calendar Server other than version 5.1.1. At the time that this job was developed, version 5.1.1 was the most recent release available, but it is not possible to ensure that future versions of the Calendar Server will continue to behave in the same manner. Adding New Job ClassesThe SLAMD server was designed in such a way that it is very extensible. One of the ways this is evident is the ability for an end user to develop a new job class and add that class to the SLAMD server. Once that class has been added to the SLAMD server, it is immediately possible to schedule and run jobs that make use of that job class. It is not necessary to copy that job class to all client systems, as that is done automatically whenever a client is asked to run a job for which it does not have the appropriate job class. Note Although job classes are automatically transferred from the SLAMD server to clients as necessary, if a job class uses a Java library that is not already available to those client systems, that library must be manually copied to each client. Libraries in Java Archive (JAR) file form should be placed in the lib directory of the client installation, and libraries provided as individual class files should be placed under the classes directory (with all appropriate parent directories created in accordance with the package in which those classes reside). If any new versions of job classes are installed, it is necessary to manually update each client, as the client has no way of knowing that it would otherwise be using an outdated version of the job class. Using the Standalone ClientEven though jobs are designed to be scheduled and coordinated by the SLAMD server, it is possible to execute a job as a standalone entity. This is convenient if you want to run a job in an environment where there is no SLAMD server available, if you do not need advanced features like graphing results, or if you are developing a new job for use in the SLAMD environment and wish to test it without scheduling it through the SLAMD server. The standalone client is similar to the network-based client in that it is included in the same installation package as the network client and requires a Java environment (preferably 1.4.0) installed on the client system. However, because there is no communication with the SLAMD server, it is not necessary that the client address be resolvable or that any SLAMD server be accessible. Before the standalone client may be used, it is necessary to edit the standalone_client.sh script. This script may be used to run the standalone client, but it must first be edited so that the settings are correct for your system. Set the value of the JAVA_HOME variable to the location in which the Java 1.4.0 or higher runtime environment has been installed. You may also edit the INITIAL_MEMORY and MAX_MEMORY variables to specify the amount of memory in megabytes that the standalone client is allowed to consume. Finally, comment out or remove the two lines at the top of the file that provide the warning message indicating that the file has not been configured. Since the standalone client operates independently of the SLAMD server, it is not possible to use the administrative interface to define the parameters to use for the job. Instead, the standalone client reads the values of these parameters from a configuration file. In order to generate an appropriate configuration file, issue the command: $ ./standalone_client.sh -g job_class -f config_file where job_class is the fully-qualified name of the job class file (for example, com.example. slamd.example.SearchRateJobClass ), and config_file is the path and name of the configuration file to create. This creates a configuration file that can be read by the standalone client to execute the job. This configuration file likely needs to be modified before it can actually be used to run a job, but comments in the configuration file should explain the purpose and acceptable values for each parameter. Once an appropriate configuration file is available, the standalone client may be used to run the job. In its most basic form, it may be executed using the command $ ./standalone_client.sh -F config_file This reads the configuration file and executes the job defined in that configuration file using a single thread until the job completes. However, this default configuration is not sufficient for many jobs, and therefore there are additional command-line arguments that may be provided to further customize its behavior. Starting and Stopping SLAMDThe SLAMD server has been designed so that it should not need to be restarted frequently. Most of the configuration parameters that may be specified within the SLAMD server can be customized without the need to restart the server itself or the servlet engine that provides the administrative interface. However, some changes do require that the server be restarted for that change to take effect. This section describes the preferred ways of starting, stopping, and restarting the SLAMD server and the Tomcat servlet engine. Starting the Tomcat Servlet EngineBy default, SLAMD uses the Tomcat servlet engine to generate the HTML pages used for interacting with the SLAMD server. However, the servlet engine is responsible for not only generating these HTML pages, but actually for running the entire SLAMD server. All components of the server run inside the Java Virtual Machine used by the servlet engine. Therefore, unless the servlet engine is running, the SLAMD server is not available. As described earlier in this document in the discussion on installing the SLAMD server, the Tomcat servlet engine may be started by using the bin/startup.sh shell script provided in the installation archive. This shell script must be edited to specify the path of the Java installation, the amount of memory to use, and the location of an X server to use when generating graphs. Once that has been done, this shell script may be used to start the Tomcat servlet engine. Starting SLAMDBy default, the SLAMD server is loaded and started automatically when the servlet engine starts. However, if a problem is encountered when the servlet engine tries to start the SLAMD server (that is, if the configuration directory server is unavailable), the Tomcat servlet engine is started but SLAMD remains offline. If this occurs, a message is displayed indicating that the SLAMD server is unavailable, and this message should also include information that can help administrators diagnose and correct the problem. When the problem has been corrected, the SLAMD server may be started by following the SLAMD Server Status link at the bottom of the navigation bar and clicking the Start SLAMD button (this button is only visible if the SLAMD server is not running). This attempts to start the SLAMD server. If the attempt is successful, the full user interface is available. If the SLAMD server could not be started for some reason, it remains offline and an informational message describing the problem that occurred is displayed. Restarting SLAMDAs indicated earlier, a few configuration parameters require the SLAMD server to be restarted in order for changes to take effect. This can be done easily through the administrative interface without the need to restart the servlet engine. To do so, follow the SLAMD Server Status link at the bottom of the navigation bar and click the Restart SLAMD button on the status page (this button is only visible if the SLAMD server is currently running). This causes the SLAMD server to be stopped and immediately restarted. Stopping SLAMDRestarting the SLAMD server should be sufficient for cases in which it is only necessary to re-read configuration parameters, but in some cases it may be necessary to stop the SLAMD server and leave it offline for a period of time (for example, if the configuration directory server is taken offline for maintenance). This can be done by following the SLAMD Server Status link at the bottom of the navigation bar and clicking the Stop SLAMD button on the status page. This causes the SLAMD server to be stopped, and it remains offline until the Start SLAMD button is clicked or until the servlet engine is restarted. Note Stopping or restarting the SLAMD server (or the servlet engine in which it is running) disconnects all clients currently connected to the server. If any of those clients are actively processing jobs, an attempt is made to cancel those jobs and obtain at least partial results, but this cannot be guaranteed. Any jobs that are in the pending jobs queue are also stored in the configuration directory and are properly re-loaded when the SLAMD server is restarted. However, if the SLAMD server is offline for any significant period of time, the start times for some jobs may have passed, which could cause the pending jobs queue to become backlogged when the server is restarted. Stopping the Tomcat Servlet EngineIt should be possible to edit all of the SLAMD server's configuration without needing to restart the servlet engine in which SLAMD is running. However, if the configuration of the Tomcat servlet engine itself is to be modified, it is necessary to stop and restart Tomcat for those changes to take effect. Before stopping Tomcat, it is recommended that the SLAMD server be stopped first. To do this, follow the SLAMD Server Status link and click the Stop SLAMD button. Once the SLAMD server has been stopped, it is possible to stop the Tomcat servlet engine using the bin/shutdown.sh shell script. If the SLAMD server is not stopped before the attempt to stop the Tomcat servlet engine, it is possible (although unlikely ) that the Tomcat servlet engine will not stop properly. If that occurs, the servlet engine may be stopped by killing the Java process in which it is running (note that on Linux systems it may appear as multiple processes). The Tomcat startup scripts have been modified so that the process ID of the Tomcat process should be written into the logs/pid file. If Tomcat does not shut down properly, this PID may be used to determine which process or processes should be killed . If it is necessary to manually kill the Tomcat process, it should be done using the SIGTERM signal (the default signal used when the kill command is issued). A SIGKILL signal should only be used if the Tomcat process or processes do not respond to the SIGTERM signals. Tuning the Configuration DirectoryIn addition to storing the SLAMD configuration, the configuration directory is used to store information about all jobs that have been scheduled for execution in the SLAMD environment, including the statistical information gathered from jobs that have completed. Nearly all operations that can be performed in the administrative interface require some kind of interaction with the configuration directory. Therefore, properly tuning the configuration directory can dramatically improve the performance of the administrative interface and the SLAMD server in general. Further, entries that store statistical information may grow quite large and without proper configuration, it may not be possible to store this information in the directory. The changes that should be made to the directory server configuration are described below. Configuring for Large EntriesAll information about scheduled jobs is stored in the configuration directory. For completed jobs, this includes the statistical information gathered while those jobs were running. As a result, these entries can be required to store several megabytes of data, especially for those jobs with a large number of threads, with a long duration, or that maintain statistics for a number of items. This can cause a problem because by default the directory server is configured to allow only approximately two megabytes of information to be sent to the server in a single LDAP message. This limit is controlled by the nsslapd-maxbersize configuration attribute, which specifies the maximum allowed message size in bytes. A value of at least 100 megabytes (104857600 bytes) should be specified to prevent updates with large amounts of statistical information from being rejected, although it is possible that a job could return even more than 100 megabytes of data, particularly for jobs that run for a very long period of time and have a relatively short collection interval. Cache TuningThe directory server contains two caches that may be utilized to improve overall performance: the entry cache and the database cache. The entry cache holds copies of the most recently used entries in memory so they can be retrieved without having to access the database. The database cache holds pages of the database in memory so it is not necessary to access the data stored on the disk. By default, both of these caches are configured to store approximately ten megabytes of information. Increasing the sizes of these caches increases the amount of information stored in memory and therefore the overall performance when it is necessary to retrieve information from the directory server. Increasing the size of the database cache can also improve the performance of the server when writing information to the database. Proper IndexingWhenever the SLAMD server needs to retrieve information from the configuration directory, it issues an LDAP search request to the directory. If the directory server is properly indexed, the server is able to locate the matching entries more quickly. Adding indexes for the following attributes helps the directory server process the queries from SLAMD more efficiently :
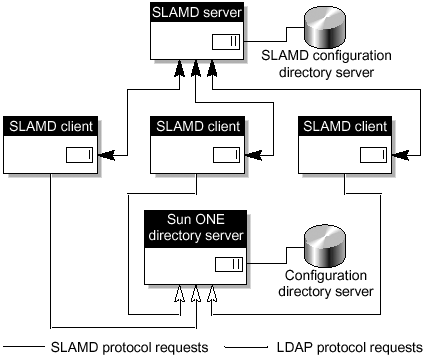
Typical SLAMD ArchitectureFIGURE 9-11 shows an example of how you might architect and deploy SLAMD. Figure 9-11. SLAMD Architecture The SLAMD Architecture figure depicts how the SLAMD clients are distributed amongst multiple machines, and how the clients receive what is termed as job data, from the SLAMD server. This information is related to how the Sun ONE Directory Server should be load tested by the SLAMD server. This results in data being sent as a report back to the SLAMD server when the job is done. This load testing of the Sun ONE Directory Server is achieved through LDAP protocol requests. In FIGURE 9-11, the clients are distributed, which means in order to obtain the average results, the SLAMD server must aggregate the results from all participating clients and present the results to the user as one single job. The SLAMD server also requires a directory server to store configuration and result data. A typical SLAMD server and its configuration directory are normally located on the same system, which could be a Sun Enterprise 420R. |
EAN: N/A
Pages: 87