Section 10.2. Tunneling Techniques
10.2. Tunneling TechniquesTunneling mechanisms can be used to deploy an IPv6 forwarding infrastructure while the overall IPv4 infrastructure is still the basis and either should not or cannot be modified or upgraded. Tunneling is also called encapsulation . With encapsulation, one protocol (in our case, IPv6) is encapsulated in the header of another protocol (in our case, IPv4) and forwarded over the infrastructure of the second protocol (IPv4). The process of encapsulation has three components:
So tunneling can be used to carry IPv6 traffic by encapsulating it in IPv4 packets and tunneling it over the IPv4 routing infrastructure. For instance, if your provider still has an IPv4-only infrastructure, tunneling allows you to have a corporate IPv6 network and tunnel through your ISP's IPv4 network to reach other IPv6 hosts or networks. Or you can deploy IPv6 islands in your corporate network while the backbone is still IPv4. IPv6 packets traveling from one IPv6 island to another can traverse the backbone encapsulated in IPv4 packets. The tunneling techniques and the encapsulation of IPv6 packets in IPv4 packets are defined in several RFCs, such as RFC 2473, "Generic Packet Tunneling in IPv6 Specification," RFC 4213, "Basic Transition Mechanisms for IPv6 Hosts and Routers," and RFC 3056, "Connection of IPv6 Domains via IPv4 Clouds (6to4)," which differentiate two general types of tunneling:
10.2.1. How Tunneling WorksThe concepts discussed in this section apply to tunneling in general. The next two paragraphs discuss the difference between configured tunnels and automatic tunneling. Figure 10-1 shows two IPv6 networks connected through an IPv4-only network. Figure 10-1. Encapsulation and tunneling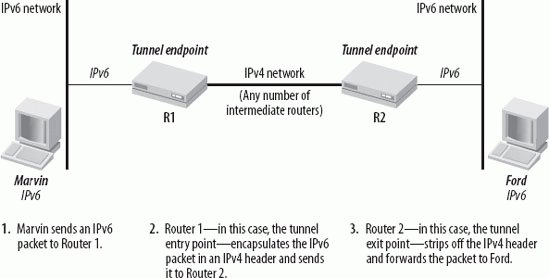 Host Marvin is on an IPv6 network and wants to send an IPv6 packet to host Ford on another IPv6 network. The network between router R1 and router R2 is an IPv4-only network. Router R1 is the tunnel entry point . Marvin sends the IPv6 packet to router R1 (step 1 in Figure 10-1). When router R1 receives the packet addressed to Ford, it encapsulates the packet in an IPv4 header and forwards it to router R2 (step 2 in Figure 10-1), which is the tunnel exit point . Router R2 decapsulates the packet and forwards it to its final destination (step 3 in Figure 10-1). Between R1 and R2, any number of IPv4 routers is possible. A tunnel has two endpoints: the tunnel entry point and the tunnel exit point. In the scenario in Figure 10-1, the tunnel end points are two routers, but the tunnel can be configured in different ways. It can be set up router-to-router, host-to-router, host-to-host, or router-to-host. Depending on which scenario is used, the tunnel entry and exit point can be either a host or a router. The steps for the encapsulation of the IPv6 packet are the following:
Figure 10-2 shows the encapsulation of an IPv6 packet in an IPv4 packet. Figure 10-2. Encapsulation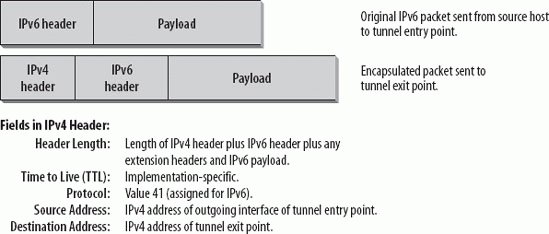 The following fields in the IPv4 header are interesting to note: the Total Length field in the IPv4 header contains the length of the IPv4 header plus the length of the IPv6 packet, which is treated as the payload. If the encapsulated packet has to be fragmented, there will be corresponding values in the Flags and Fragment Offset fields. The value of the Time to Live (TTL) field depends on the implementation used. The Protocol Number is set to 41, the value assigned for IPv6. Thus, if you want to analyze your tunneled IPv6 traffic, you can set a filter in your analyzer to display the packets containing the value 41 in the Protocol Number field. The IPv4 Source address is usually the address of the outgoing interface of the tunnel entry point. It should also be configurable for cases where automatic address selection may produce different results over time (multiple addresses/interfaces). The IPv4 Destination address is the IPv4 address of the tunnel exit point. The IPv6-over-IPv4 tunnel is considered a single hop. The Hop Limit field in the IPv6 header is therefore decremented by one. This hides the existence of a tunnel to the end user, and is not detectable by common tools such as traceroute. Figure 10-3 shows an encapsulated IPv6 packet in the trace file. Figure 10-3. Encapsulation in the trace file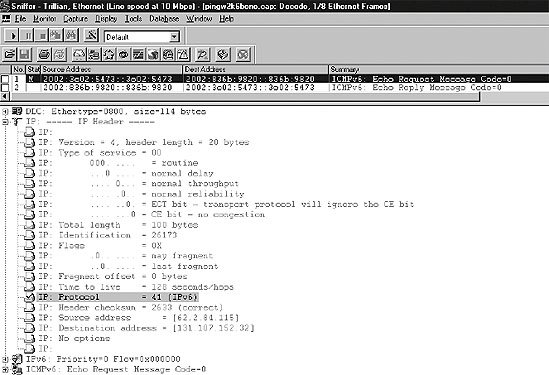 This is a ping generated on Marvin, our Windows host. We were pinging a host on the 6Bone. The TTL is set to 128. The Protocol field shows value 41 for IPv6, which identifies this packet as an encapsulated packet. The Source address 62.2.84.115 is the IPv4 address of Marvin, which was configured for this address by a DHCP server. It is the tunnel entry point. The Destination address is the IPv4 address of a 6to4 relay router (explained later in this chapter) in the 6Bone, the tunnel exit point. This router can forward the packet to an IPv6 network, the 6Bone in this case. Compare these IPv4 addresses with the IPv6 Source and Destination addresses (which can be seen in the highlighted summary line above the detail screen). Use your Windows calculator to find out that the IPv6 Source and Destination addresses have the 6to4 prefix of 2002 plus the IPv4 address in hexadecimal notation in the low-order 32 bits. This is an example of a host-to-host automatic tunnel because we were actually pinging the 6to4 router. If an IPv4 router from within the tunnel generates an ICMPv4 error message, the router sends the message to the tunnel entry point because that host is the source of that packet. If the packet contains enough information about the original, encapsulated IPv6 packet, the tunnel entry point may send an ICMPv6 message back to the original source of the packet. When the tunnel exit point receives an IPv4 datagram with a protocol value of 41, it knows that this packet has been encapsulated. Before forwarding a decapsulated IPv6 packet, the tunnel endpoint must verify that the tunnel Source address is acceptable. Thus, unacceptable ingress into the network can be avoided. If the tunnel is a bidirectional configured tunnel, this check is done by comparing the Source address of the encapsulated packet with the configured address of the other side of the tunnel. For unidirectional configured tunnels, the tunnel must be configured with a list of source IPv4 address prefixes that are acceptable. By default, this list is empty, which means that the tunnel endpoint has to be explicitly configured to allow forwarding of decapsulated packets. In the case of fragmentation, it reassembles the packets and removes the IPv4 header. Before delivering the IPv6 packet to the final destination, it checks to see if the IPv6 Source address is valid. The following Source addresses are considered invalid:
Both tunnel endpoints need to have a link-local IPv6 address. The IPv4 address of that same interface may be the interface identifier for the IPv6 address. For example, a host with an IPv4 address of 192.168.0.2 may have a link-local address of FE80::192.168.0.2/64. The specification contains rules that apply tunnel Source address verification and ingress filtering (RFCs 2827 and 3704) in general to packets before they are decapsulated. If further security mechanisms are desirable, a tunneling scheme with authentication can be usedfor example, IPsec (preferable) or Generic Routing Encapsulation (GRE) with a preconfigured secret key (RFC 2890). Since the configured tunnels are set up manually, setting up the keying material is not a problem. 10.2.2. Automatic TunnelingAutomatic tunneling allows IPv6/IPv4 nodes to communicate over an IPv4 infrastructure without the need for tunnel destination preconfiguration. In a previous specification (RFC 2893, obsoleted by RFC 4213), the tunnel endpoint address was determined by an IPv4-compatible Destination address. RFC 4213 removes the description of automatic tunneling and IPv4-compatible addresses and refers to 6to4 (discussed later in this chapter), which does not use IPv4-compatible IPv6 addresses. 6to4 has its own IPv6 address format, which includes the IPv4 address of the tunnel endpoint in the prefix and therefore allows for automatic tunneling. 10.2.3. Configured Tunneling (RFC 4213)Configured tunneling is IPv6-over-IPv4 tunneling where the IPv4 tunnel endpoint addresses are determined by configuration information on the tunnel endpoints. All tunnels are assumed to be bidirectional. The tunnel provides a virtual point-to-point link to the IPv6 layer using the configured IPv4 addresses as the lower layer endpoint addresses. The administrative work to manage configured tunnels is higher than with automatic tunnels, but for security reasons, it may be desirable, as it provides more possibilities to control the forwarding path of IPv6 packets. RFC 4213 discusses the configuration and issues to be taken care of, such as determination of valid tunnel endpoint addresses (ingress filtering), how to deal with ICMPv4 or ICMPv6 messages, tunnel MTU sizes, fragmentation, the header fields, Neighbor Discovery (ND) over tunnels, and security considerations. IPv6/IPv4 hosts connected to network segments with no IPv6 routers can be configured with a static route to an IPv6 router in the Internet at the other side of an IPv4 tunnel; this enables communication with a remote IPv6 world. In this case, the IPv6 address of an IPv6/IPv4 router at the other end of the tunnel is added into the routing table as a default route. Now all IPv6 Destination addresses match the route and can be tunneled through the IPv4 infrastructure. This default route has a mask of zero and is used only if there are no other routes with a more specific matching mask. 10.2.4. Encapsulation in IPv6 (RFC 2473)RFC 2473 specifies the model and the generic mechanisms for encapsulation with IPv6. Most of the rules discussed in this chapter about tunneling in IPv4 apply to tunneling in IPv6. The main difference is that in tunneling in IPv6, the packets are encapsulated in an IPv6 header and sent through an IPv6 network. The packet being encapsulated can be an IPv4 packet, an IPv6 packet, or any other protocol. The tunnel entry point prepends the IPv6 header and, if needed, one or a set of Extension headers in front of the original packet header. Whatever the tunnel entry point prepends are called the Tunnel IPv6 headers. Figure 10-4 shows the Tunnel IPv6 headers in the packet view. Figure 10-4. Tunnel IPv6 headers from the packet view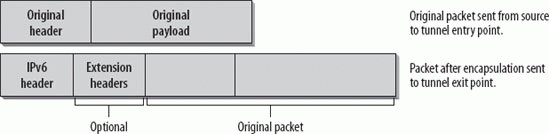 In the IPv6 header applied by the tunnel entry point, the Source address is the address of the tunnel entry point node, and the Destination address is the address of the tunnel exit point node. The source node of the original packet can be the same node as the tunnel entry point. The original packet, including its header, becomes the payload of the encapsulated packet. The header of the original packet is treated according to standard forwarding rules. If the header is an IPv4 header, the TTL field is decremented by one. If it is an IPv6 header, the Hop Limit field is decremented by one. The network between the tunnel entry point and the tunnel exit point is thus virtually just one hop, no matter how many actual hops there are in between. The Tunnel IPv6 header is processed according to the IPv6 protocol rules. Extension headers, if added, are processed as though the packet were a standard IPv6 packet. For example, a Hop-by-Hop Options header would be processed by every node listed in the Hop-by-Hop Options field. A Destination Options header would be processed by the destination hosti.e., the tunnel exit point. All these options are configured on the tunnel entry point. An example of the use of a Destination Options header is the configuration of a Tunnel Encapsulation Limit Option (RFC 2473). This option may be used when tunnels are nested. One hop of a tunnel can be the entry point of another tunnel. In this case, we have nested tunnels . The first tunnel is called the outer tunnel, and the second tunnel is called the inner tunnel. The inner tunnel entry point treats the whole packet received from the outer tunnel as the original packet and applies the same rules as shown in Figure 10-6. The only natural limit to the number of nested tunnels is the maximum IPv6 packet size. Every encapsulation adds the size of the tunnel IPv6 headers. This would allow for something around 1,600 nested tunnels, which is not realistic. Also, consider the case in which the packet has to be fragmented. If it has to be fragmented again because the additional tunnel IPv6 headers have increased the packet size, the number of fragments is doubled. So a mechanism was needed to limit the number of nested tunnels. It is specified in RFC 2473 and is called the Tunnel Encapsulation Limit Option. This option is carried in a Destination Option header and has the format shown in Figure 10-5. Figure 10-5. Format of the Tunnel Encapsulation Limit Option The Option Type field has 1 byte and the decimal value 4, specifying the Tunnel Encapsulation Limit Option. The Option Data Length field has the decimal value 1, specifying the length of the following Option field. In this case, the Option field has a size of 1 byte and contains the actual value for the Tunnel Encapsulation Limit Option. The value in this field specifies how many further levels of encapsulation are permitted. If the value is zero, the packet is discarded and an ICMP Parameter Problem message is sent back to the source (the tunnel entry point of the previous tunnel). If the value is nonzero, the packet is encapsulated and forwarded. In this case, a new Tunnel Encapsulation Limit Option has to be applied with a value of one less than the limit received in the packet being encapsulated. If the packet received does not have a tunnel encapsulation limit, but this tunnel entry point has one configured, the tunnel entry point must apply a destination options header and include the configured value. Loopback encapsulation should be avoided. Loopback encapsulation happens when a node encapsulates a packet originating from itself and destined to itself. IPv6 implementations should prevent this by checking and rejecting configurations of tunnels where both the entry and exit points belong to the same host. Another undesirable situation is a routing-loop nested encapsulation . This situation happens if a packet from an inner tunnel reenters an outer tunnel from which it has not yet exited. This can be controlled only by a combination of the original packet's hop limit and the configuration of tunnel encapsulation limits. Let's have a closer look at a Tunnel IPv6 Header (Figure 10-6). Figure 10-6. The Tunnel IPv6 header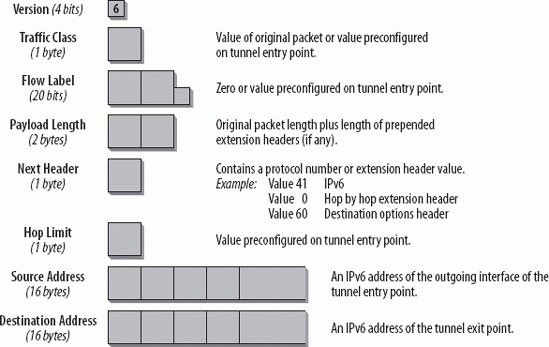 The fields of a standard IPv6 header were discussed in Chapter 2. Interesting values here are the following: the values for Traffic Class, Flow Label, and Hop Limit can be preconfigured on the tunnel entry point. The Payload Length has the value for the packet length of the original packet plus the size of any Extension headers prepended by the tunnel entry point. The Source and Destination Addresses of the Tunnel IPv6 header contain the IPv6 addresses of the tunnel entry and exit points, respectively. Note that a host configured as a tunnel entry point must support fragmentation of packets that it encapsulates. Encapsulated packets may exceed the Path MTU of the tunnel. Because the tunnel entry point is considered the source of the encapsulated packet, it must fragment it if needed. The tunnel exit point node will reassemble the packet. If the original packet is an IPv4 packet with the Don't Fragment bit set, the tunnel entry point discards the packet and sends an ICMP Destination Unreachable message with the code "fragmentation needed and DF set" back to the source of the packet. 10.2.5. Transition MechanismsThe next sections describe other transition mechanisms available today. They are to be seen as a toolbox. Analyze your environment and your requirements to find the optimal tools or combination of tools that meet your goals. Some of these mechanisms are already standardized, such as 6to4 and Teredo; others, such as DSTM, are still in draft. 10.2.5.1. 6to4 (RFC 3056)RFC 3056, "Connection of IPv6 Domains via IPv4 Clouds," specifies a mechanism for IPv6 sites to communicate with each other over the IPv4 network without explicit tunnel setup. This mechanism is called 6to4. The wide area IPv4 network is treated as a unicast point-to-point link layer, and the native IPv6 domains communicate via 6to4 routers, also referred to as 6to4 gateways. Note that only the gateway needs to be 6to4 aware. No changes have to be made to the hosts within the 6to4 network. This is intended as a transition mechanism used during the period of coexistence of IPv4 and IPv6. It will not be used as a permanent solution. The IPv6 packets are encapsulated in IPv4 at the 6to4 gateway. At least one globally unique IPv4 unicast address is required for this configuration. The IANA has assigned a special prefix for the 6to4 scheme: 2002::/16. Figure 10-7 shows the format of the 6to4 prefix in detail. Figure 10-7. Format of the 6to4 prefix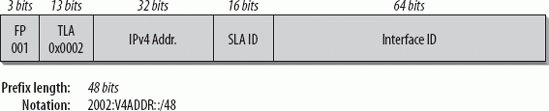 The 32 bits after the prefix 2002::/16 are the IPv4 address of the gateway in hex representation. This leaves you with 80 bits of address space for your internal network. 16 bits are used for the local network addressing, so you can create 65,536 networks! The remaining 64 bits are used for the interface identifier of the nodes on your network; that is, 264 nodes per network. It looks like getting familiar with the extended address space has some advantages. Now all the hosts on your network can communicate with other 6to4 hosts on the Internet.
When a node in a 6to4 network wants to communicate with a node in another 6to4 network, no tunnel configuration is necessary. The tunnel entry point takes the IPv4 address of the tunnel exit point from the IPv6 address of the destination. To communicate with an IPv6 node in a remote IPv6 network, you need a 6to4 relay router. The relay router is a router configured for 6to4 and IPv6. It connects your 6to4 network to the native IPv6 network. It announces the 6to4 prefix of 2002::/16 into the native IPv6 network. Figure 10-8 shows the 6to4 components and how they play together. Figure 10-8. 6to4 components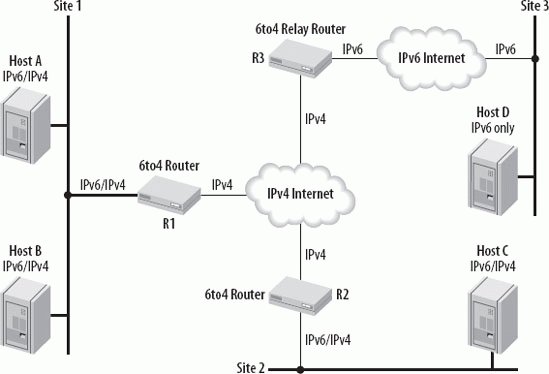 The figure shows the different possible communication paths. Within site 1, hosts A and B can communicate using IPv6. To communicate with host C in site 2 (another 6to4 site), the packets are sent to router R1 in site 1. Router R1 encapsulates them in IPv4 and forwards them to Router R2 in site 2. Router R1 learns the IPv4 address of Router R2 from the IPv6 Destination address. Router R2 decapsulates the packet and forwards the original IPv6 packet to host C. To communicate with an IPv6-only host in the Internet, host A or B sends its IPv6 packets to Router R1. Router R1 encapsulates them in IPv4 and forwards them to the Relay Router R3. Router R3 decapsulates the packet and forwards the original IPv6 packet over the IPv6 routing infrastructure to host D. Router R1 internally advertises the 6to4 prefix in its Router Advertisements (if configured to do so). The IPv6 hosts in site 1 can use the RA for Stateless autoconfiguration of their IPv6 address. The prefix announced has the format 2002:IPv4-address-R1:subnet::/64. To connect a 6to4 network with the IPv6 Internet, a convenient 6to4 relay can be evaluated and manually configured. The manual configuration has the advantage of providing control over the relays used but creates more administrative work. In case the preconfigured relay is not available, another relay needs to be configured.
RFC 3068 defines a 6to4 relay router anycast address to simplify the configuration of 6to4 gateways that need a default route to find a 6to4 relay router on the Internet. IANA assigned an IPv4 6to4 Relay anycast prefix of 192.88.99.0/24. The assigned anycast address corresponds to the first node in the prefix, e.g., 192.88.99.1. The 6to4 routers have to be configured with a default route pointing to this anycast address. Using this address means that 6to4 packets are routed to the nearest available 6to4 relay router automatically. If one 6to4 relay goes down, you do not need to reconfigure your 6to4 gateway; packets will automatically be rerouted to the next available relay. With the ongoing deployment of IPv6 in commercial networks, the number of public 6to4 relay routers will increase. If a host wishes to communicate with a node on a native IPv6 subnet (i.e., Destination address 3ffe:b00:c18:1::10), the IPv4 header Destination address will be the reserved anycast address 192.88.99.1 and will be delivered to the nearest 6to4 relay router. In the reverse, a native IPv6 host that wants to send packets to a host in a 6to4 cloud will route its packets to the nearest 6to4 relay router advertising the prefix 2002::/16. 10.2.5.2. ISATAPThe Intra-Site Automatic Tunnel Addressing Protocol (ISATAP) is designed to provide IPv6 connectivity for dual-stack nodes over an IPv4-based network. It treats the IPv4 network as one large link-layer network and allows those dual-stack nodes to automatically tunnel between themselves. You can use this automatic tunneling mechanism regardless of whether you have global or private IPv4 addresses. ISATAP addresses embed an IPv4 address in the EUI-64 interface identifier. Note that all nodes in an ISATAP network need to support ISATAP. ISATAP is experimental and specified in RFC 4214. Figure 10-9 shows the format of the ISATAP address. Figure 10-9. The format of the ISATAP address The ISATAP address has a standard 64-bit prefix that can be link-local, site-local, a 6to4 prefix, or can belong to the global unicast range. The Interface identifier is built using the IANA OUI 00-00-5E, which follows the prefix. The following byte is a type field, and the value FE indicates that this address contains an embedded IPv4 address. The last four bytes contain the IPv4 address, which can be written in dotted decimal notation. The format of the address can thus be summarized as 64bitPrefix:5EFE:IPv4address. For instance, if you have an assigned prefix of 2001:DB8:510::/64 and an IPv4 address of 62.2.84.115, your ISATAP address is 2001:DB8:510::200:5EFE:3e02:5473. Alternatively, you can write 2001:DB8:510::200:5EFE:62.2.84.115. The corresponding link-local address would be FE80::200:5EFE:62.2.84.115. ISATAP interfaces form ISATAP interface identifiers from their IPv4 addresses and use them to create link-local ISATAP addresses. The neighbor discovery mechanisms specified in RFC 2461 are used (router and prefix discovery). Using ISATAP, IPv6 hosts within an IPv4 intranet can communicate with each other. If they want to communicate with IPv6 hosts on the Internet, such as 6Bone hosts, a border router must be configured; it can be an ISATAP router or a 6to4 gateway. The IPv4 addresses of the hosts within the site do not need to be public. They are embedded in the address with the standard prefix and are therefore unique and routable. Large numbers of ISATAP hosts can be assigned to one ISATAP prefix. If you deploy IPv6 on a segment in your corporate network, you configure one of the native IPv6 nodes with an ISATAP interface, and it acts as a router between the native IPv6 segment and ISATAP hosts in the IPv4 segments. 10.2.5.3. Teredo6to4 makes IPv6 available over an IPv4 infrastructure using public IPv4 addresses. ISATAP enables deployment of IPv6 hosts within a site regardless of whether it uses public or private IPv4 addresses. Teredo is designed to make IPv6 available to hosts through one or more layers of NAT by tunneling packets over UDP. It is specified in RFC 4380. Many Internet users, especially many home users, can access the Internet only through NATs (Network Address Translation). NATs create issues when tunneling IPv6 over an IPv4 infrastructure mainly for two reasons: first, NAT users have a private IPv4 address, and second, many NATs are configured to perform ingress filtering and do not allow many types of payload to go through. With tunneling, the IPv6 packet is the payload of IPv4. Mechanisms such as 6to4 often fail in these environments because they require a public IPv4 address. 6to4 can be used in NAT environments if the 6to4 router runs on the same box as NAT. In all other cases, other mechanisms have to be chosen. In our future IPv6 world, we will no longer need NATs, but for the coming transition time, we will have to deal with them. Therefore, IPv6 developers are working on mechanisms to allow users sitting behind NATs to access the IPv6 world by tunneling IPv6 packets in UDP. One of these mechanisms is Teredo. The following terms are used with Teredo:
The Teredo service transports IPv6 packets a payload of UDP, which has been chosen over TCP for performance reasons. Research has shown that most implemented NATs are either of type Cone NAT or Restricted Cone NAT. Teredo supports Cone NATs, Restricted Cone NATS, and Port-restricted Cone NATs. Symmetric NATs are not supported by Teredo.
The Teredo design aims to provide robust access to IPv6 networks. This design creates some overhead. Teredo is only to be used if no other, more direct access is possible. For instance, if it is possible to implement a 6to4 gateway on a NAT, this is the preferable solution. A Teredo address has the format shown in Figure 10-10. Figure 10-10. Format of the Teredo Address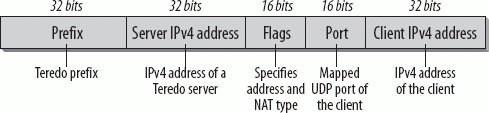 The Teredo Service Prefix has 32 bits and is 2001:0000::/32. The Server IPv4 field has a length of 32 bits and contains the IPv4 address of the Teredo server. The Flags field has 16 bits and defines the address and the NAT type used. The 16-bit Port field contains the mapped UDP port of the Teredo Service on the client; the Client IPv4 field contains the mapped IPv4 address of the client. The bits in the Port and Client address field are all obfuscated. Each bit in the address and port number is reversed. A Teredo client must be preconfigured with the IPv4 address of its Teredo Server. On booting, it sends a Router solicitation to the All-Routers multicast address from its link-local IPv6 address. The Router solicitation is sent to the IPv4 address of the Teredo server over UDP. The Router advertisement coming back from the Teredo Server contains the Teredo IPv6 Service prefix. The client builds its Teredo IPv6 address by combining the prefix with the reversed values for address and port. When the Teredo Server forwards packets from Teredo clients, it encapsulates the IPv6 packet in a UDP packet. It builds the IPv4 address and the UDP port for the destination from the destination IPv6 address. It uses its own IPv4 address as Source address and the Teredo UDP port (3544) as source port. The Teredo Server's job is to forward packets from Teredo clients over UDP to the right Destination address and to forward packets for Teredo clients coming from outside to the right client internally. The Teredo Relay is an IPv6 router announcing the Teredo Service prefix to the outside world using regular IPv6 routing mechanisms. 10.2.5.4. SilkroadSilkroad is a new mechanism under development that also allows nodes sitting behind a NAT to access the IPv6 Internet. It uses a Silkroad Navigator and a Silkroad Access router. The main difference from Teredo is that Silkroad supports all types of NAT, including Symmetric NATs, and does not need a special prefix. The Silkroad draft is in an early stage and we do not know of any implementations so far, so I don't go into more details in describing the specification. The future will show whether and how it is implemented and used. 10.2.5.5. Proto 41 ForwardingSome NAT implementations allow the configuration of IPv6 tunnels from inside of the private LAN to routers or tunnel servers in the Internet. This is a simple and helpful way to provide IPv6 nodes and IPv6 networks behind a NAT with access to the IPv6 Internet. This should only be used if no other mechanisms such as 6to4 or native IPv6 are possible. A tunnel client (host or router) with a private IPv4 address and a connection to the Internet through an IPv4-only NAT box can use a Tunnel Broker or an IPv6 router to create an IPv6 tunnel. Many NAT boxes can be configured to forward packets based on the protocol value of 41 (for IPv6) in the IPv4 header. This provides an opportunity to rapidly deploy a huge number of IPv6 nodes and networks. Most of the existing solutions for the transition to IPv6 rely in tunnels assuming that the client endpoint is an IPv6-capable router. However, nowadays the installed base of IPv4-only NAT boxes/routers is still quite large, while most of the client operating systems already support IPv6. 10.2.5.6. Tunnel BrokerTunnel Brokers can be seen as virtual IPv6 providers providing IPv6 Internet connectivity to users that already have an IPv4 connection to the Internet. The Tunnel Broker is specified in RFC 3053. Figure 10-11 illustrates how the Tunnel Broker works. Figure 10-11. How the Tunnel Broker works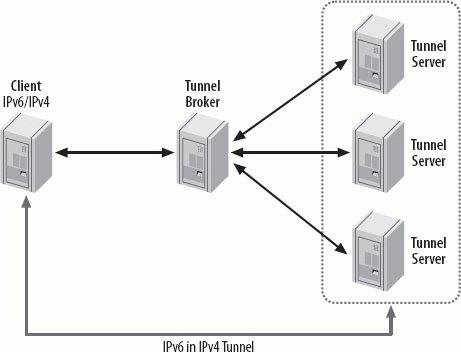 A user desiring an IPv6 connection registers with the Tunnel Broker. The Tunnel Broker manages the establishment, maintenance, and deletion of the tunnel on behalf of the user. The Tunnel Broker can share the data load across several Tunnel Servers. The Tunnel Broker sends the configuration information to a Tunnel Server when it wants to establish, change, or delete a tunnel. The Tunnel Broker also registers the addresses in DNS if it is configured to do so. A Tunnel Broker must be reachable with an IPv4 address. It can also have an IPv6 address, but it is not required. The communication between Tunnel Broker and Tunnel Server can run over either IPv4 or IPv6. A Tunnel Server is a dual-stack router connected to the global Internet. When it receives configuration information from the Tunnel Broker, it establishes, changes, or deletes the server part of the tunnel. The client is a dual-stack host or router connected to the Internet over IPv4. When it wants to register for an IPv6 connection with the Tunnel Broker, it should authenticate with standard procedures (e.g., with RADIUS). This way, unauthorized use of the tunnel service can be avoided. So the Tunnel Broker provides access control to the tunnel service. Once the client is authorized, it provides its IPv4 address, a name for the registration of its IPv6 address in DNS, and an indication of whether it is a host or a router. If the client is a router, it should send additional information about the number of IPv6 addresses that it wants to be served. The Tunnel Broker needs this information in order to assign an appropriate prefix to the client. The Tunnel Broker fulfills the following tasks:
This concludes the tunnel configuration. The clients now have access to all IPv6 networks to which the Tunnel Server has access. There are a number of ISPs that offer Tunnel Broker services. Often, users can register through the browser by filling out a form and receiving the configuration information displayed or sent by email. The client can now manually configure its tunnel entry point or use script files from the provider, that automate the configuration process. The Tunnel Broker model is designed for smaller and isolated IPv6 networks and especially for single, isolated IPv6 hosts. It works only with public IPv4 addresses. If private addresses are used, another mechanism such as Teredo or Protocol 41 Forwarding must be used.
10.2.5.7. Dual-Stack IPv6 Dominant Transition Mechanism (DSTM)The Dual-Stack IPv6 Dominant Transition Mechanism (DSTM) allows the transport of IPv4 packets over an IPv6-dominant network by encapsulating the IPv4 packets in IPv6 packets. The specification defines a method to assign dual-stack nodes a temporary IPv4 address. DSTM is designed to allow IPv6 nodes the communication with IPv4 nodes and applications without using translation (NAT-PT). Find the current description in draft-bound-dstm-exp-04.txt. The main goal of this specification is in providing the possibility for early adopters to move to an IPv6-only network as soon as possible but still be able to support communication with the IPv4 world. The following terms are used with DSTM:
A DSTM Client acts as a tunnel endpoint (TEP) by encapsulating IPv4 packets in IPv6 packets and sending them to a DSTM Border Router, the other tunnel endpoint, which decapsulates the IPv6 packet and forwards the IPv4 packet to the IPv4 destination. The DSTM Border Router caches the IPv6 path for the IPv4 address back to the DSTM client to encapsulate incoming IPv4 packets and forward them to the DSTM client. The DSTM Address server manages the allocation of IPv4 addresses and configures the clients for the tunnel endpoint. The DSTM Server and Border Router software can be installed on the same hardware. This mechanism allows for the communication of IPv4 nodes with IPv4 applications without changing anything on the IPv4 side. The allocation of IPv4 addresses to DSTM clients can be done with the Tunnel Setup Protocol (TSP) described in the framework of the Tunnel Broker (draft-blanchet-v6ops-tunnelbroker-tsp-03.txt). With the DSTM Tunnel Endpoint option (draft-ietf-dhc-dhcpv6-opt-dstm-01.txt), the DSTM client can receive its tunnel endpoint configuration from DHCPv6. This is important, as DSTM is designed to support an IPv6-dominant infrastructure and to eliminate as many IPv4 dependencies as possible and as early as possible. Being able to use DHCPv6 for allocating IPv4 addresses to DSTM clients further reduces the dependency of IPv4 and therefore supports a quicker migration to an IPv6-dominant infrastructure while still supporting IPv4 applications and services. The advantage is that supporting an IPv6-dominant infrastructure is simpler and less costly than supporting a dual-stack infrastructure.
10.2.5.8. IPv4/IPv6 coexistence by using VLANsVLANs, which are quite common in enterprise networks, can be used to deploy IPv6 in a situation where IPv6-capable router and switch equipment is not available yet. The VLAN standard allows separate LANs to be deployed over a single bridged LAN. It uses virtual LAN tagging or membership information, which is inserted into the Ethernet frames. So to introduce IPv6 in such an environment, a parallel IPv6 routing infrastructure can be deployed, and the IPv6 links can be overlayed onto the IPv4 infrastructure by using VLAN technology. This setup doesn't require any changes to the IPv4 environment. Find a detailed description of this scenario and possible configurations in draft-ietf-v6ops-vlan-usage-01.txt. 10.2.5.9. IPv6 in MPLS networksDifferent universities in Europe have conducted studies about IPv6 in MPLS (Multiprotocol Label Switching) networks. Backbones that already have MPLS implemented can choose one of the following IPv6 scenarios:
The main sources of this information are documents from the 6net Project (http://www.6net.org). The 6net was a collaboration of approximately 15 European research and educational networks. IPv6 has been implemented and thoroughly tested by these partners. The detailed reports of their tests and findings are documented on the 6net web site. It is well worth going there; you will find a wealth of useful guides, reports, and cookbooks that help you to plan for and implement IPv6. Go to http://www.6net.org/publications/deliverables. The 6net project concluded in June 2005, but the dissemination and support activities continue in the 6DISS project (http://www.6diss.org). 10.2.5.10. Cisco's 6PEThe concept for 6PE is based on the hierarchical routing structure of MPLS shown in Figure 10-12. I do not aim to discuss general MPLS technology here; the goal is to show how MPLS can support an easy introduction of IPv6. Figure 10-12. MPLS routing hierarchy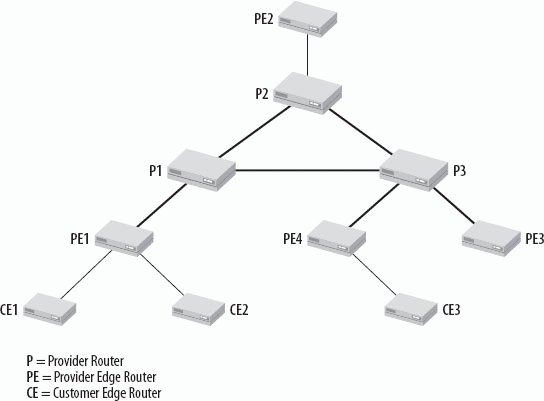 In the center of the MPLS network are the Provider routers (P). They switch the MPLS packets, which means that they do not process the layer 3 header. At the edge of the core network are the Provider Edge routers (PE). They receive regular IP packets from the Customer Edge routers (CE), apply an MPLS label, and forward them to the Provider routers. MPLS packets are sent only between Provider Edge routers and Provider routers in Figure 10-12. Routing works as follows:
IPv6 packets can then be routed over an MPLS infrastructure without configuring the Provider routers for IPv6. The Provider Edge routers need to be dual-stack. The Customer Edge routers can be dual-stack or IPv6-only. Find a detailed description of 6PE on the Cisco web site at http://www.cisco.com/ipv6. There are a lot of interesting publications there, including a data sheet on 6PE, case studies, and a series of white papers. The fact that MPLS can be used to transport IPv6 packets over IPv4 does not mean that you should implement MPLS for this purpose. If you do not have an MPLS infrastructure in place, other tunneling mechanisms may be better suited to reach your goal. But if you already have MPLS, it is a great starting point. 10.2.5.11. Generic Routing Encapsulation (GRE)Another Tunneling mechanism that can be used is Generic Routing Encapsulation (GRE). GRE is specified in RFC 2784 and is designed to encapsulate any protocol in another protocol. The protocol being encapsulatedin our case IPv6is called the Passenger Protocol. The protocol that is used to encapsulatein our case IPv4is called the Carrier Protocol. The configuration of a GRE tunnel is manual. On both tunnel endpoints (the GRE routers), the IPv4 address of the tunnel peer is preconfigured. So for each route where IPv6 has to be tunneled, a tunnel must be configured separately. In a more complex network, this can lead to a high initial configuration effort. A GRE tunnel cannot traverse NATs. It is useful when multiple protocols have to be tunneled through the same tunnel. 10.2.5.12. SSH (Secure SHell) TunnelsYou won't find SSH Tunnels as an official IPv6 transition mechanism, but they can be very practical and offer useful solutions in different situations. This section describes what they are and how you can use them in an IPv6 environment. The aim of two projects, the commercial OpenSSH (http://www.openssh.com) and the closed source SSH (http://www.ssh.com), was to eliminate the use of unencrypted protocols such as Telnet, rlogin, and rsh. This section is by no means a complete overview of SSH, but it shows how SSH tunnels can be used as a simple transition mechanism for IPv4 to IPv6 and vice versa.
Both projects allow for a practice called "port forwarding," which essentially allows TCP ports to be forwarded between machines. It is also loosely referred to as "The Poor Man's VPN." In the scenario shown in Figure 10-13, we have an IPv4-only client connecting to a dual-stacked host running either version of SSH (both versions of SSH are IPv6 compliant). Figure 10-13. IPv4 client connects to IPv6-only server through a dual-stacked SSH host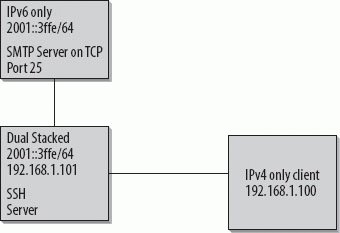 The IPv4 client wishes to send mail via the IPv6-only server. With SSH's flexibility, this can be accomplished one of two ways, described next. The examples that follow show how to do this using the command-line SSH client available from both vendors, but this can also be easily accomplished with GUI tools (please check your vendor's documentation for your GUI tool).
The flexibility of SSH tunnels allows for many other combinations, including the client being able to forward the port and the use of pregenerated keys for ease of administration (no logging in required). Disadvantages of using SSH as a transition mechanism include being able to forward only TCP connections and a possibility of high processing overhead in forwarding many ports using the same machine. |
