Intrinsic and Contextual Data Quality: The Effect of Media and Personal Involvement
Intrinsic and Contextual Data Quality The Effect of Media and Personal Involvement
Andrew S. Borchers
Kettering University, USA
Copyright © 2003, Idea Group Inc. Copying or distributing in print or electronic forms without written permission of Idea Group Inc. is prohibited.
Abstract
This chapter introduces the concepts of intrinsic and contextual data quality and presents research results on how individual perceptions of data quality are impacted by media (World Wide Web versus print) and personal involvement with the topic. The author advances four hypotheses, which are tested with a randomized experiment (n=127), dealing with information on cancer. First, subjects perceive reputable information sources as having higher data quality than non-reputable sources. Second, subjects perceive web-based material to be more timely, but less believable and of lower reputation, accuracy and objectivity than printed material. Third, individuals with greater personal involvement will be better discriminators of data quality in viewing reputable and non-reputable cancer information. Fourth, women are better discriminators of data quality in viewing reputable and non-reputable information than men. The first hypothesis was supported and limited support was provided for the second hypothesis.
Introduction
This chapter introduces the concepts of intrinsic and contextual data quality as described in the literature and presents research results on how individual perceptions of data quality are impacted by media (World Wide Web versus print) and personal involvement with the topic. There is a rich base of literature, both in Information Systems and Journalism, on "data quality" and "media creditability." While developed separately, these streams of research provide a consistent picture of how people view the quality of information they receive from different sources. Research results shed further light on the topic.
The impact of the Internet revolution on information sharing is widely acknowledged. But this access comes with a challenge as stated by Gilster (as cited in Flanigan, 2000). "One of the challenges of Internet publishing is that it turns our conventional expectations, built upon years of experience with newspapers and magazines, on their head. We can no longer assume that the appearance of a publication is necessarily relevant to the quality of its information."
Background
The importance of data quality has been echoed among practitioners for many years. Redman (1998) summarizes the practical implications of poor quality. He points out the negative consequences of data quality problems on decision making, organizational mistrust, strategic planning and implementation, and customer satisfaction. In carefully studied situations, Redman finds increased cost of 8–12% due to poor data quality. Service organizations can find increased expenses of 40–60% (Redman, 1998). Strong, Yang & Wang (1997) support the seriousness of this issue in their study of 42 data quality projects in three organizations. Research by other authors note data quality issues in a number of settings, including airlines, health care (Strong, 1997), accounting (Xu, 2000; Kaplan, 1998), data warehousing (Ballou, 1999), and criminal justice (Laudon, 1986)
Over the years a number of authors have written conceptual articles on "data quality" (Wand, 1996; Wang, 1995, 1996; Strong, 1997). In these studies, it has become clear that data quality is a multidimensional concept (Wand, 1996) that can be viewed from a number of different perspectives. A panel discussion in 2000 (Lee, Bowen, Funk, Jarke, Madnick & Wand) found five different perspectives to discuss data quality. These included:
- Ontological perspective - This perspective deals with different views of reality that one can have based on actual observation, compared to what information systems tell a user is true. In Wand's work (1996), he identifies the potential for incomplete, ambiguous and meaningless representation between the real world and the information system representation of the real world.
- Architectural perspective - This view focuses in on system infrastructure (such as data warehouses, ERP systems, etc.), and how it refines and improves data quality.
- Context Mediation perspective - In this view, the focus is on how to connect heterogeneous databases and achieve communication across space and time.
- Time Based E-Commerce perspective - This perspective notes the impact that time has in the real-time world of the Internet. When firms use B2B e-commerce to closely couple supply chains, there is a real danger that time based data quality issues may arise.
- Information Product perspective - This perspective notes that for many organizations today, data is their product. The quality of data from an end user perspective is the key focus in this perspective.
In talking about "data quality," a key starting point is to determine just what one means by the term. Wang (1996) provides what is perhaps the definitive work in developing a conceptual framework for data quality. Using a two-stage survey and sorting process, Wang develops a hierarchical framework for data quality that includes four major areas: intrinsic, contextual, representational and accessibility.
Intrinsic data quality refers to the concept that "data have quality in their own right" (Wang, 1996). Intrinsic dimensions include accuracy, objectivity, believability and reputation. Contextual data quality is based on the idea that data does not exist in a vacuum - it is driven by context. Contextual dimensions include relevancy, timeliness and appropriate amount of data. Representational data quality relates to the "format of the data (concise and consistent representation) and meaning of data (interpretability and ease of understanding)." Accessibility refers to the ease with which one can get to data (Wang, 1996).
This study focuses on intrinsic and contextual data quality for two reasons. First, the attributes studied were found to be significantly different between WWW and print media by a prior researcher (Klein, 1999, 2001). In one study, Klein (1999) found web based material to be more timely, but less believable and of lower reputation, accuracy and objectivity than printed material. In a more formal result (2001), Klein found traditional text sources to be perceived as more accurate, objective and to have higher reputation and representational consistency. Internet sources were found to be stronger in timeliness and appropriate amount.
The second reason for focusing on intrinsic and contextual data quality comes from a different literature base. Beyond the information systems literature, there is a body of literature among journalism scholars about the perceptions of Internet credibility (Flanagin, 2000; Johnson, 1998). The major thrust of this literature is in comparing the Internet to traditional sources with respect to credibility. Note that when referring to "credibility," these authors say, "the most consistent dimension of media credibility is believability, but accuracy, trustworthiness, bias and completeness of information are other dimensions commonly used by researchers" (Flanagin, 2000, p. 521). Hence, there is a rough correspondence of thinking about "credibility" in the journalism literature to the concept of "intrinsic" and "contextual" data quality in the information systems literature. Flanagin's work focuses in three areas. First, he looks at the perceived credibility of television, newspapers, radio and magazines compared to the Internet. The major finding, unlike Klein, is that there is little difference in credibility between media. Second, Flanagin looks at the extent to which Internet users verify what they receive. Third, and most important to this work, Flanagin looks at whether perceived credibility varies depending on the type of information being sought. Flanagin cites Gunther in suggesting that "greater involvement with the message results in, first, a wider latitude of rejection."
Finally, health care literature forms a final basis for this work. Bates (2000) notes the role of "word of mouth," and the Internet in particular, in providing consumers with health care information. Others have noted gender differences within many families when it comes to health information. Women are most often the conduit through which health care information is filtered, with men less involved. Further, they are the chief decision maker in health care matters in many families (Looker, 2001).
Research Approach and Hypothesis
The literature cited above suggests a number of interesting hypotheses. The author set out to investigate the topic using an experimental approach, where subjects were shown information about cancer from a "reputable" and a "disreputable" source using traditional print and the Internet as media. In this study the "reputable" source was a well-known national organization devoted to fighting cancer. The "disreputable" source was a WWW site that recommended alternative cancer treatments and abandoning traditional cancer treatment by doctors. Using this vehicle to study these relationships, the author posits the following hypotheses:
|
H1: |
Subjects will perceive web based material to be more timely, but less believable and of lower reputation, accuracy and objectivity than printed material. |
|
H2: |
Individuals with greater personal involvement in cancer will be better discriminators of data quality in viewing reputable and non-reputable cancer information. |
|
H3: |
Women are better discriminators of data quality in viewing reputable and non-reputable cancer information than men. |
Further, since the experiment is premised on a source being "reputable" and "disreputable," the author tested an initial hypothesis (H0) that posits the "reputable" source has significantly greater intrinsic and contextual data quality than the "disreputable" source.
Figure 1 below demonstrates what the author hoped to find. H0, the initial hypothesis, is that the perception of low creditable sources is significantly less than high creditable sources. Hence, the two lines for Internet based and print based text should have a positive slope. H1 suggests a significant gap between the lines for Internet based sources and text based sources on the timeliness, believability, reputation, accuracy and objectivity dimensions. This assertion was based on prior literature by Klein (1999). H2 would suggest that the slope of the lines should vary based on one's personal involvement in cancer. Finally, H3 suggests that women are better able to differentiate credible from non-credible sources. Hence, the slope of the lines should vary based on gender.
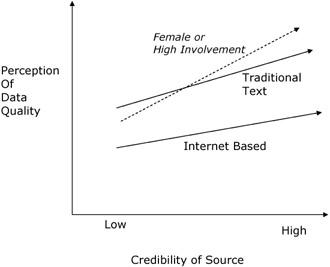
Figure 1: Research Design
Methodology
In this research, subjects (n=127) reviewed information on cancer and answered a questionnaire. Subjects were drawn from mid-career students in MBA and MSIS classes at a Mid-western university. The sample is strongly multi-cultural with significant U.S., Indian and Chinese representation. Subjects were randomly assigned to one of four groups.
These four groups were shown cancer information based on two sources of information presented in two different formats. As noted, one source was a website of a highly credible national cancer organization. The second source of cancer information was a website of low creditability, a site that touted alternative medical treatments. The third and fourth sources were identical to the first two, with the exception that they were presented in printed form by way of a color document. Subjects were then asked about their perceptions of the data that they have viewed using Wang's intrinsic data quality dimensions (accuracy, objectivity, believability and reputation), as well as contextual dimensions (timeliness, relevancy and appropriate amount of information) and ease of use. Further, subjects were asked about their personal and family experience with cancer as well as demographic questions (gender, age and country of birth).
Findings
After the data was collected, the author analyzed it in two different ways. First, the reliability of the four multi-item dimensions was appraised using Cronbach Alpha. Table 1 below shows the result. Note that each dimension has an Alpha value of at least .80.
|
Dimension |
Cronbach's Alpha for Internet Sources |
Cronbach's Alpha for Text Sources |
|---|---|---|
|
Relevant (relevant, interesting and usable) |
.8453 |
.8349 |
|
Accuracy (error-free, reliable and precise) |
.9044 |
.8402 |
|
Objectivity (unbiased and objective) |
.8933 |
.9141 |
|
Ease of Understanding (easily understood and readable) |
.8218 |
.9106 |
The author generated a second set of statistics using a univariate ANOVA procedure to test each of the research hypotheses. H0 was tested for all eight measured data quality dimensions, using the source reputation (high or low) and media (print or WWW) as fixed factors. In testing H2 and H3, cancer involvement or gender were added as random factors. The hypotheses were tested by looking at the product term for source reputation and cancer involvement (H2) or Gender (H3). Table 2 below summarizes the findings:
|
Hypothesis |
Dimension |
F ratio |
Significance |
|---|---|---|---|
|
H0 - Initial difference due to reputation |
Believable, Accuracy, Reputation, Objectivity and Appropriate Amount |
10.526 to 24.489 |
.000 to .002 |
|
H0 - Initial difference due to reputation |
Timeliness, Relevance, Ease of Use |
< 1.4 |
> .35 |
|
H1 - WWW compared to print |
Timeliness Believable Reputation Accuracy Objectivity Appropriate Amount Relevance Ease Of Use |
2.587 1.036 .340 .483 1.132 .617 .030 .620 |
.110 .311 .561 .489 .290 .484 .865 .484 |
|
H2 - Personal involvement with cancer |
Timeliness Believable Reputation Accuracy Objectivity Appropriate Amount Relevance Ease of Use |
With all respondents F ratio < 4 US-only respondents had significant interaction on believability and reputation |
With all respondents F > .05 US-only respondents were significant on believability and reputation |
|
H3 - Gender |
Believable Accuracy Reputation Objectivity Appropriate Amount Relevance Ease of Use |
All < 4 |
All > .05 |
Conclusions and Future Trends
This research begins a line of work that seeks to understand the underlying factors behind different dimensions of perceived data quality. The experimental design appears to work reasonably. Note that the first hypothesis (H0) is supported for all four of the intrinsic data quality dimensions (believability, accuracy, objectivity and reputation) and one contextual dimension, appropriate amount. It did not hold for two contextual dimensions (relevancy and timeliness) and a representational dimension (ease of use). The researcher observed that these findings held true for all respondents, but that by limiting the sample to U.S. born respondents, the F ratios were significantly higher.
Do people perceive data quality differently depending on the media that data is presented in? The results of this paper suggest, as Flanigan (2000) did, that media is not a significant factor. This comes in contrast to Klein's work (1999; 2001), which suggested the contrary on five dimensions studied here: accuracy, objectivity, reputation, timeliness, and appropriate amount. It should be noted that there are differences in research approach in this paper and Klein's work. Here subjects saw exactly the same material in both Internet and text formats. In Klein's work, subjects were asked in general about Internet and text based sources used for a course project.
Do people become more discriminating of data quality for topics that they are personally involved in? This study provides, at least for cancer information, only limited support. When working with the full dataset, no interactions were found. When limited to U.S. born and raised subjects, there was an interaction effect on believability and reputation between media, reputation and cancer experience. However, family experience with cancer was not significant by itself. Finally, does gender play a role in one's ability to discriminate between reputable and non-reputable sources? This study would suggest that this is not so.
There are several limitations in this study and further areas for research. First, the author intended this work as only a first study and a vehicle to begin to understand the issues. Second, the personal involvement with cancer concept bears rework. The subject population included mostly younger adults. Fully half of the sample was in the age range of 26–35. It may be that their "involvement" in cancer is so remote that it has little impact on their perception of data quality. Further, the questions employed here focused only on one's family experience with cancer and did not elicit subjects' experience with cancer among friends or work associates.
Third, the author needs to revisit the data collection instrument used here (including the cancer literature). Although it was created using the terminology of Wang (1996), it may have lost some of its meaning with the multinational sample used in this work. Finally, this research data was collected in tandem with another survey instrument. The resulting form was four pages long and may have fatigued the participants.
Having noted these limitations and future areas of work, this line of research is important for several reasons. First, the Internet has become a de facto standard source of information for younger generations. Their perceptions of data quality, particularly compared to print, are a key factor in understanding how people will interpret what they see. The question of personal involvement in another interesting topic - do people become more discriminating in evaluating data quality on topics that have significant impact on them? Finally, there does appear to be an intersection of research in data quality that crosses between the information systems and journalism disciplines.
References
Bates, D.W., & Gawande, A.A. (2000). The impact of the Internet on quality measurement. Health Affairs, 19 (6), 104-114.
Flanagin, A. J., & Metzger, M. J. (2000). Perceptions of Internet information credibility. Journalism and Mass Communications Quarterly, 77 (3), 515–540.
Looker, P.A., & Stichler, J. F. (2001). Getting to know the women's health care segment. Marketing Health Services, 21 (3), 33–34.
Johnson, T. J., & Kaye, B. K. Cruising is Believing?: Comparing Internet and Traditional Sources on Media Credibility Measures. Journalism and Mass Communications Quarterly, 75 (2), 325–340.
Kaplan, D., Krishnan, R., Padman, R., & Peters, J. (1998). Assessing data quality in accounting information systems. Communications of the ACM, 41 (2).
Klein, B. D. (1999, October ). Information quality and the WWW. Applied Business in Technology Conference. Rochester, MI: Oakland University.
Klein, B. D. (2001, Summer). User perceptions of data quality: Internet and traditional text sources. Journal of Computer Information Systems, 41 (4).
Laudon, K. C. (1986, January). Data quality and due process in large interorganizational record systems. Communications of the ACM, 29 (1).
Smith, S. E. (1998). Reliable cancer resources on the Internet. Information Today, 15 (6), 23, 28+.
Strong, D. M., Lee, Y. W., & Wang, R. Y. (1997). Data quality in context. Communications of the ACM, 40 (5), 103–110.
Wand, Y., & Wang, R. Y. (1996). Anchoring data quality dimensions in ontological foundations. Communications of the ACM, 39 (11), 86–95.
Wang, R., Reddy, M.P., & Kon, H.B. (1995). Towards quality data: An attribute-based approach. Decision Support Systems, 13 (3/4), 349–372.
Wang, R. Y., & Strong, D. M. (1996). Beyond accuracy: What data quality means to data consumers. Journal of Management Information Systems, 12 (4), 5–33.
Xu, H. (2000, December). Managing accounting information quality. Proceedings of the 21st International Conference on Information Systems.
Yang (Chair). (2000, December). Data quality in Internet time, space, and communities. Proceedings of the 21st International Conference on Information Systems.
Part I - ERP Systems and Enterprise Integration
- ERP Systems Impact on Organizations
- Challenging the Unpredictable: Changeable Order Management Systems
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- The Second Wave ERP Market: An Australian Viewpoint
- Enterprise Application Integration: New Solutions for a Solved Problem or a Challenging Research Field?
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Context Management of ERP Processes in Virtual Communities
Part II - Data Warehousing and Data Utilization
- Distributed Data Warehouse for Geo-spatial Services
- Data Mining for Business Process Reengineering
- Intrinsic and Contextual Data Quality: The Effect of Media and Personal Involvement
- Healthcare Information: From Administrative to Practice Databases
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare
- Development of Interactive Web Sites to Enhance Police/Community Relations
EAN: 2147483647
Pages: 174
