Flow Control Transforms
| The following category of transforms pushes data around, but rarely does much with the data directly. They're useful for combining, splitting, and creating new columns, input, and outputs. These transforms make it possible to combine data from different sources and formats, making the data flow incredibly flexible. Conditional SplitAs the name implies, the Conditional Split transform uses expression-based predicates to divide the incoming stream of rows into separate outputs. This is useful when you want to process rows differently based on their content. For example, you might want to remove rows with a date stamp older than a certain date or you might want to perform some special data processing on rows that are missing a value in a given column. Table 20.8 provides the profile for this component.
Setting Up the Conditional Split TransformThe Conditional Split transform directs rows to different outputs based on Boolean expressions. If the expression evaluates to trUE, the row is directed to the associated output. If not, the Conditional Split transform evaluates the next expression, if available, and directs the row based on the results and so on. If none of the expressions evaluate as trUE, the row is directed to the default output. In many ways, the Conditional Split transform resembles a Switch/Case statement in functional programming languages, such as C, VB, Pascal, or C#. Figure 20.14 shows the Conditional Split Transformation Editor with three conditional outputs. Figure 20.14. Redirecting rows based on EmailPromotion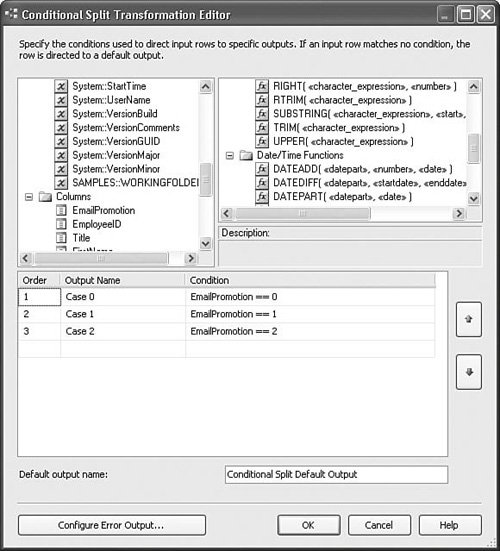 With the setup displayed in Figure 20.15, there are three conditional outputs and one default output. As you drag the outputs to the next transform or destination, a dialog box opens that gives you the option for which output to use. Figure 20.15 shows the dialog box. Figure 20.15. Selecting the Conditional Split output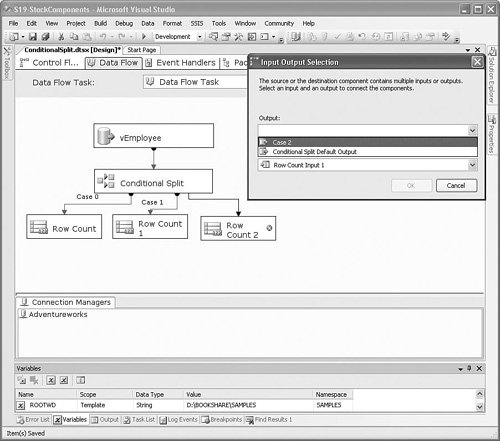 Derived ColumnLike the Conditional Split transform, the Derived Column transform uses expressions and has an expression builder as its editor. However, whereas the Conditional Split transform simply directs rows to different outputs, the Derived Column transform actually modifies row metadata and values. The Derived Column transform is used to generate new columns based on expressions that take columns and package variables as inputs. Using the Derived Column transform, it's possible to create a new column or replace an existing one with values derived from other columns and variables. Table 20.9 provides the profile for this component.
Examples of Derived Column OperationsHere are some examples of derived column operations:
Setting Up the Derived Column TransformSetting up the Derived Column transform is a matter of deciding which columns you want to create and building the expression to generate the output value the new column will contain. The Derived Column transform has synchronous outputs, so every row is processed in order, row by row. The metadata of the resulting output might be virtually identical to the input metadata or drastically different, depending on how many new columns you create and how many columns you overwrite. Figure 20.16 shows the Derived Column Transformation Editor from the DerivedColumn.dtsx package in the StockComponents sample solution. Figure 20.16. The Derived Column Transformation Editor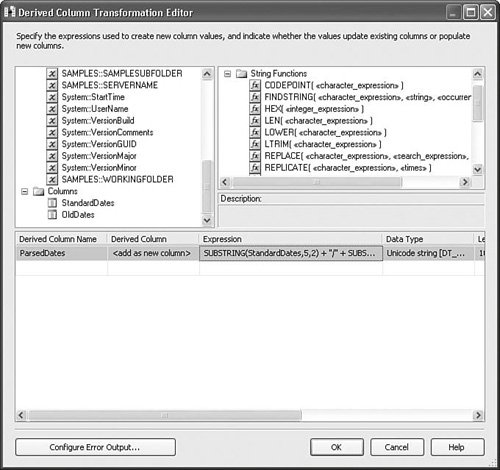 The upper-left window contains columns and variables. The upper-right window contains functions, operators, and type casts. These two windows are identical to the Expression Editor found in other parts of the product, such as the Stock Task Editors, and use the same expression engine. The lower window contains the Derived Column Transformation Editorspecific columns, as follows:
Caution The Derived Column Transformation Editor attempts to discover the data type from the expression. Generally, it is successful and the feature is helpful. However, you must be careful to check the data type any time you modify the expression because it always attempts to modify the type, even when you don't want it to do so. Building the ExpressionTo build the expression, you drag and drop variables, columns, and functions from the upper windows down to the Expression field. It is helpful to have all the expression functions in one place, so Appendix B contains an Expression Evaluator cheat sheet for your reference. To give you an idea how to build expressions, here's a simple example: SUBSTRING(StandardDates,5,2) + "/" + SUBSTRING(StandardDates,7,2) + "/" + SUBSTRING(StandardDates,1,4) This is the expression from the sample package that takes a string column containing a date in the form YYYYMMDD and converts it to the form MM/DD/YYYY. The SUBSTRING function has the following signature: SUBSTRING( <<character_expression>>, <<start>>, <<length>> ) The first parameter character_expression can be a column, a variable, or another expression. All three must be of type String (DT_WSTR or DT_STR). In the preceding expression, the StandardDates is a column of type DT_WSTR. The second parameter, start, is the 1-based index into the string. The third parameter, length, specifies the length of the output string and the Expression Evaluator uses it to allocate space for the resulting string value. The sample package uses the Derived Column transform to parse a date string from an Excel-formatted flat file into two different popular date formats and then converts the date strings into date types using the Data Convert transform. The following four date values represent a row that was generated with the sample package and shows the original or derived values of each of the columns. OldDates StandardDates ParsedDates ConvertedDates 09/24/04 20040924 09/24/2004 9/24/2004 12:00:00 AM This is an example of the kinds of common data manipulation you can do with a simple expression. Tip I've seen some very complex expressions used in Derived Column transforms. Sometimes, they can be extremely complex. Although the Expression Evaluator is capable of handling those expressions, one wonders "Why?" A good rule of thumb is if the expression is too complex to edit in the Derived Column Transformation Editor, chances are, you should be using a Script transform. The environment for the Script transform is much more favorable for building complex logic. The Derived Column transform is ideal for simple operations, but is very difficult to maintain when the expressions are more than a few lines long. Expression and Friendly Expression PropertiesIn general, people don't remember numbers as well as names. Names have meaning and association. Numbers are mostly symbolic and are difficult to recall. Therefore, the Derived Column and Conditional Split transforms have two properties, the expression and the friendly expression. The expression is the actual string that gets passed to the Expression Evaluator. It contains the ID numbers of any columns that it references. Friendly expressions replace the column ID numbers with the names of the columns. The expression shown previously for parsing a date is the friendly expression. The actual value for the expression property is as follows: [SUBSTRING](#40,5,2) + "/" + [SUBSTRING](#40,7,2) + "/" + [SUBSTRING](#40,1,4) The expression property value is hidden in the custom editors for the Derived Column and Conditional Split transforms. However, you can find these two properties together in the Advanced Editor for either transform. Open the Advanced Editor, select an output, and look in the property grid in the Custom Properties grouping. MergeThe Merge transform combines exactly two sorted inputs into one sorted output. The Merge transform is useful when you want to retain the sorted order of rows even when the rows must be processed in different execution paths; for example, you might want to process records based on a differentiator key, such as State or County columns. Table 20.10 provides the profile for this component.
Depending on the business rules, the rows might have different processing requirements. With the Merge transform, further down the data flow, you can recombine the rows while retaining the sorted order. Figure 20.17 shows the Merge Transformation Editor. Figure 20.17. The Merge Transformation Editor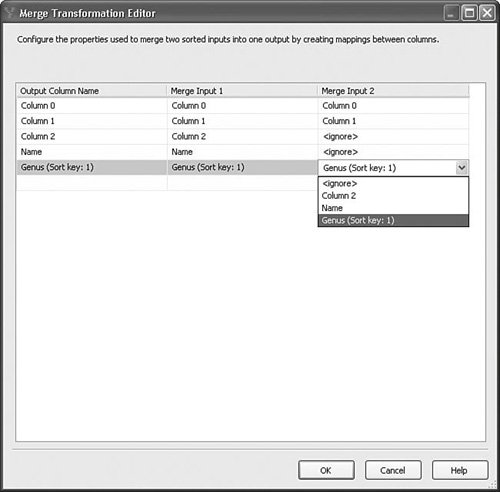 Setting Up the Merge TransformSetting up the Merge transform is simply a matter of dropping the transform onto the designer and creating paths to it, and then dragging the single output to the next transform. However, if the metadata for a column on the two inputs is not exactly identical, by default, the Merge transform ignores the column and it does not flow through to the output. Also, if you attempt to map two columns of different types or metadata, the Merge transform fails validation. Therefore, it is very important if you want to retain the column that the column metadata matches. Also, the output of the preceding transforms must be sorted. As discussed earlier in this chapter, the IsSorted property of the outputs must be trUE, at least one column on each output must have its SortKeyPosition property correctly configured, and each sorted column must have the same SortKeyPosition as its mapped column. Note As Figure 20.17 shows, columns can be mapped to differently named columns. However, because the metadata must match exactly, typically the two inputs are derived from the same output on some upstream transform, so it is uncommon that the names will be different. Merge JoinThe Merge Join transform is similar to the Merge transform in that it requires the inputs to be sorted and combines the rows from the inputs into one output. However, whereas the Merge transform always produces the same amount of rows as the number flowing into both inputs, the Merge Join transform provides the added ability to do joins, which might increase or decrease the total resulting row count. Table 20.11 provides the profile for this component.
Setting Up the Merge Join TransformThe Merge Join transform supports three types of joins:
You can join on multiple columns, but each of the columns must have identical metadata. Figure 20.18 shows the Merge Join Transformation Editor for the MergeJoin.dtsx package in the sample solution for this chapter. Figure 20.18. Use the Merge Join transform to join inputs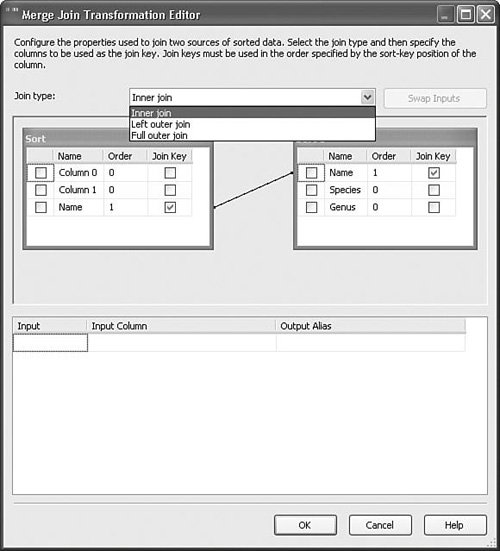 Try changing the join type and running the package to see the difference in the resultset in the data viewer. MulticastThe Multicast transform provides a simple way to split a data flow path into multiple identical paths. The Multicast transform essentially duplicates the data from the input for every output. Table 20.12 provides the profile for this component.
Tip The Multicast transform is also useful for easily terminating a data flow path without requiring a variable or connection manager. This comes in really handy when prototyping data flows. Just make sure the RunInOptimizedMode property is set to FALSE so the Execution Engine won't trim the Multicast's upstream execution tree. Setting Up the Multicast TransformSetting up the Multicast transform is quite simple. Just drop it on the designer and start dragging the paths to the various destinations. Paths can be created at any time, and there is no functional limit to the number you can create. Figure 20.19 shows the editor for the Multicast transform. Figure 20.19. The Multicast transform is useful for splitting the data flow into identical outputs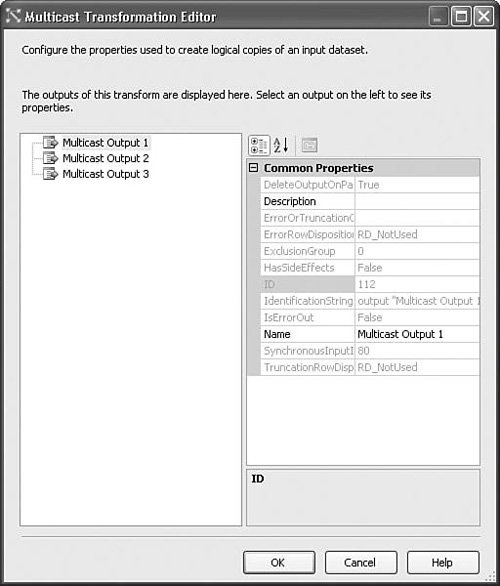 Union AllThe Union All transform provides a way to combine multiple data flows into one. It does not have any requirements to be sorted like the Merge transform. The Union All transform is useful for rejoining previously split paths, for example, paths that were split upstream by a Conditional Split or Multicast transform. Table 20.13 provides the profile for this component.
Setting Up the Union All TransformSetting up the Union All transform is simple. Drop it on the surface and drag paths to it. However, you must ensure that the inputs all have the same column metadata or, at least, those columns you want to combine must have the same column metadata. Figure 20.20 shows the Union All Transformation Editor from the UnionAll.dtsx sample package in the S20-StockComponents solution. Figure 20.20. The Union All Transformation Editor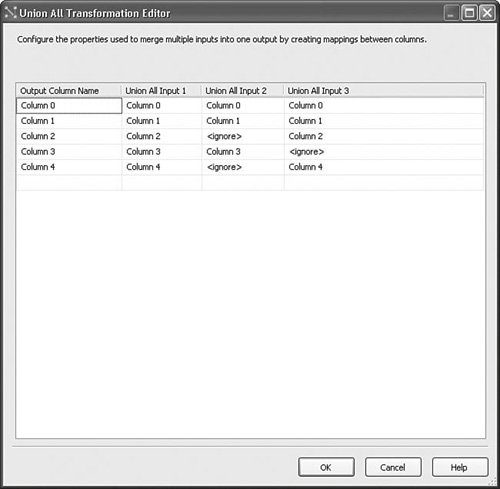 There are three inputs on this Union All transform and the mappings as shown were automatically created. Notice that there are some columns in Input 2 and Input 3 that have been marked "<ignore>". This happens whenever there are columns with nonmatching metadata, for example, if the types or length don't match the first input attached to the Union All. For string types of different lengths, if you correct the mapping, for example, you change column 3 on Input 3 from "<ignore>" to "Column 3," the Union All adjusts the column width to match the length of Column 3 in Input 1. Rows from inputs with columns that are left marked ignore will have NULL values on the output. LookupThe Lookup transform provides a way to detect if a given key exists in a reference table. One way the Lookup transform is used is for upserting. Upserting is when you insert a row if it doesn't exist or update it if it does. A classic case of upserting is when checking if a dimension already exists for a given business key when attempting to update or insert a dimension. If you find the key in the reference table, you might want to insert the row if it does not already exist, or update it if it does. Table 20.14 provides the profile for this component.
Setting Up the Lookup TransformTo set up the Lookup transform, you need to have a source input and a reference table. The source input must have one or more keys with the same metadata (for example, type and length) as the lookup key(s) in the reference table. The Lookup transform tries to match the incoming keys with the keys in the lookup table or reference set. If it finds the key in the reference set, the Lookup transform pushes the row down the normal output. If it does not find the key, however, it pushes the row out the error output. The Lookup.dtsx package in the sample solution for this chapter shows the basic setup for the Lookup transform. Figure 20.21 shows the first of three tabs in the Lookup Transformation Editor. Figure 20.21. The Lookup Transformation Editor Reference Table tab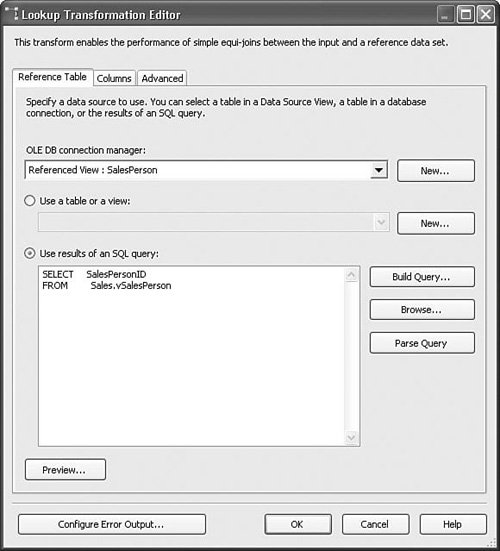 The Reference Table tab allows you to select the data you want to use for the reference set either via a query or by referencing a lookup table. It is generally better to use a query for retrieving the reference set so that you retrieve only what you need, keeping the result size small. Figure 20.22 shows the Columns tab. You use this tab to specify which column or columns should be used for the lookup. In this case, only one column is selected in the results query. But, it is possible to use more than one column for more complex lookups. To create the lookup, drag and drop an input column onto a lookup column of the exact same metadata. The line between them indicates that if the value in the input column matches the value in the corresponding lookup column, the lookup succeeded. If not, the lookup failed. If the lookup succeeds, you have the option to add a new column with the value of the selected lookup column, or replace an input column as selected in the Lookup Operation in the grid. Figure 20.22. The Lookup Transformation Editor Columns tab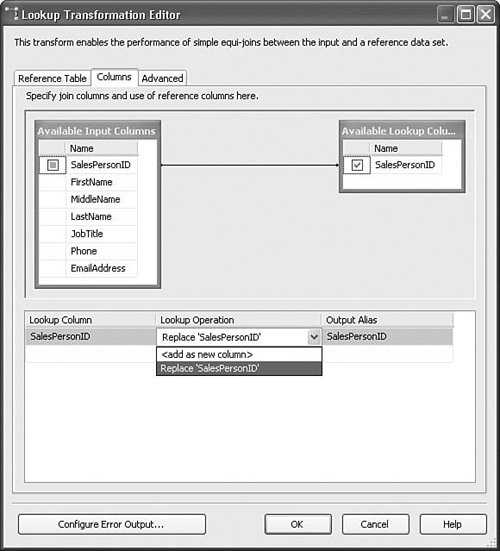 Handling Error Rows (Failed Lookups)If you click on the Configure Error Output button, the Configure Error Output dialog box opens, as shown in Figure 20.23. Figure 20.23. The Configure Error Output dialog box for the Lookup transform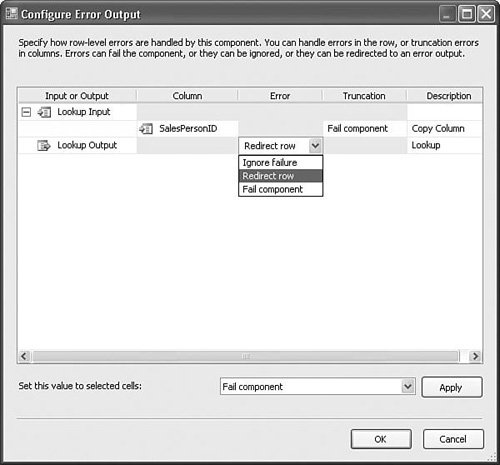 As it turns out, this is the same dialog box as for other components. However, the meaning of an error is slightly different. For the Lookup transform, an error can be just like any other error. For example, unexpected types or truncations are still errors. But, failed lookups are also considered errors. So, the option to redirect a row has additional meaning for lookups because failed lookups flow down the error output. The Advanced Tab, Configuring Reference CachingDepending on the lookup table or reference set size, you might want to cache the reference set differently. The Advanced tab, shown in Figure 20.24, provides several options from which to choose. Figure 20.24. The Lookup Transformation Editor Advanced tab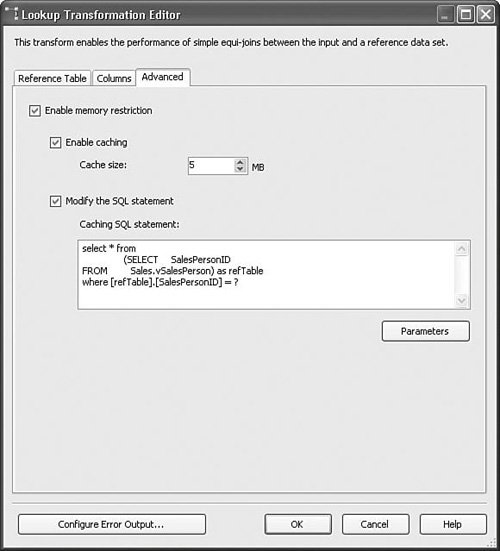 There are three basic options for how the Lookup transform caches the reference set:
You can set the cache type directly using the CacheType property in the properties grid for the Lookup transform or you can modify the values on the Advanced tab, which indirectly sets those values. Because it's not obvious which settings result in which CacheType, when using the full cache option, the newly added row is not added to the cache because the Lookup transform currently provides no way to update the cache with new rows. However, when using the partial and no cache setting, the new row might possibly be found depending on if the inserted row was committed on insert. Table 20.15 clarifies which CacheType settings map to which Editor settings.
Import ColumnThe Import Column transform provides a way to insert files from the file system into a column, one file per column. This is useful when you need to get files into a table, for example, when building a real estate website with pictures of homes for sale. Table 20.16 provides a profile for this component.
Setting Up the Import Column TransformYou need to have a table or flat file with the names of the files you want to insert, or as shown in the sample package, you can have the source adapter generate rows that contain the filenames. The source adapter reads the filenames from a MultiFile Connection Manager into a column. Then, the Import Column transform reads the filename in each row and loads the file into an output column. The Import Column transformation has two custom properties found on its input columns called ExpectBOM and FileDataColumnID.
To set up the Import Column transform, drag a path from a source adapter or transform with a column that contains rows with filenames. In the sample package, a script component source generates a new name for every file in the samples subdirectory and has two columns on its output, one with the original names of the files and one with the generated output names. Open the Import Column Transformation Editor and select the Input Columns tab. Check the box to the left of the column with the filenames. Select the Input and Output Properties tab. Open the Import Column Output node, select the Output Columns node, and click the Add Column button. In the sample package, the new output column is called BitmapColumn. Open the Import Column Input node and select the input column you checked earlier. In the FileDataColumnID property, type in the ID for the new output column you just created. Figure 20.25 shows the Advanced Editor with the Input Columns tab selected and the Input Files column checked. This tells the Import Column transform that the Input Files column is the one that contains the names of files to import. For each column you select on this tab, you need to later specify the name of a column on the output that will contain imported files. If you want a column to simply pass through unreferenced, do not put a check in the check box. Figure 20.25. Selecting the column with filenames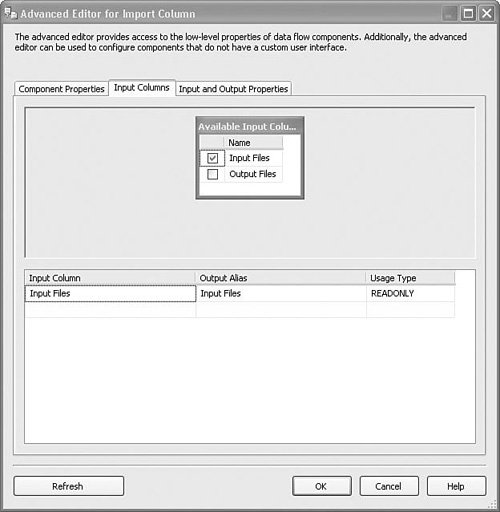 Figure 20.26 shows the Advanced Editor for the import column with the Input and Output properties showing. A new output column called BitmapColumn was created by selecting the Output Columns node, clicking the Add Column button, and typing in the new name. Note the value of the ID property; in the sample project, it is 699. Figure 20.26. Adding a new column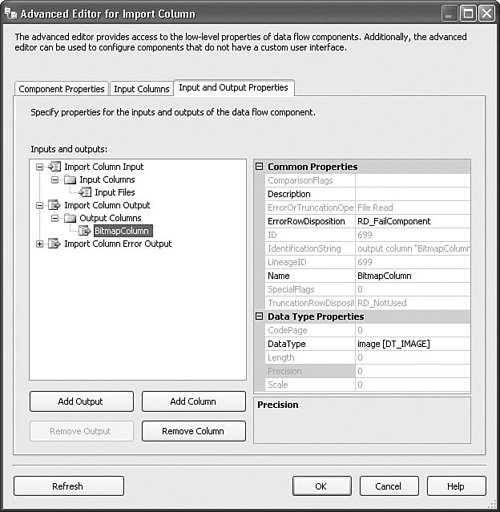 Figure 20.27 shows the correct settings so that the files specified in the Input Files column will be loaded into the output column with the ID of 699 as specified in the FileDataColumnID. To see the sample package, open the S20-StockComponents sample solution and open the ImportExportColumn.dtsx package. Figure 20.27. Connecting the output column with the filenames column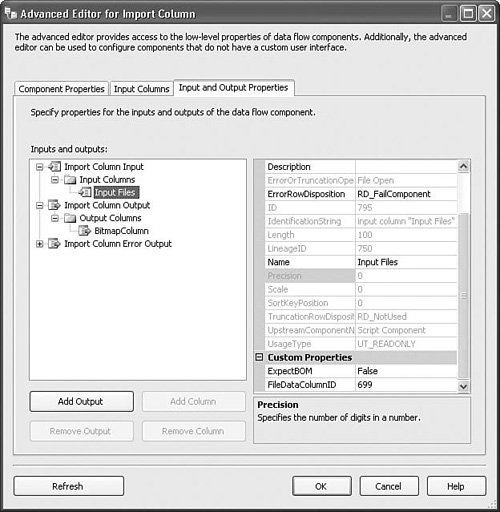 Export ColumnThe Export Column transform is the converse of the Import Column transform. You use it to export data from a column into files and it requires that there be at least two input columns: one with the data to export into files and the other with the names of the files to create to hold the exported data. Table 20.17 provides a profile for this component.
Setting Up the ComponentBecause the Export Column transform has a custom editor, setting it up is a matter of selecting the column containing the data to export and selecting the File Path Column. Figure 20.28 shows the editor with the correct settings from the sample package. Figure 20.28. The Export Column Transformation Editor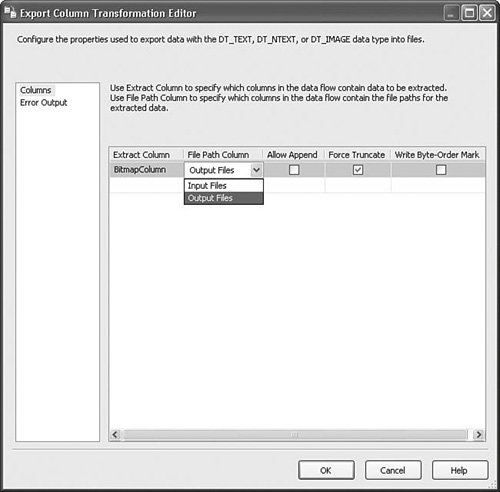 The following are the available settings:
Some Background on Byte-orderMarks Because microprocessors differ in the placement of the least significant byte, it is important to indicate which ordering was used when the Unicode text file was written. Intel and MIPS processors position the least significant byte first. Motorola processors position it last. At Microsoft, UTF-16/UCS-2 or "little endian" is used. You should always prefix Unicode plain text files with a byte-order mark. Byte-order marks do not control the byte order of the text; they simply inform an application reading the file what its byte ordering is. The Unicode byte-order mark character is not in any code page, so it disappears if Unicode text is converted to ANSI. Also, if a byte-order mark is found in the middle of a file, it is ignored. The Sample PackageThe sample package ImportExportColumn.dtsx in the S20-StockComponents solution uses both the Import and Export Column transforms. It uses a script component to enumerate the files in the location to which the "Files" File Connection Manager points. The Import Column transform imports the files to a column and the following Export Column transform exports the files to a similarly named file in the same folder. The default location for the files is the samples folder, but you can change the property expression on the "Files" Connection Manager to point to any folder. |
EAN: 2147483647
Pages: 200