Implementing Hardware Redundancy Options
| The purpose of a server is to provide reliable network services to clients. In order for a server to be reliable, it must be available a large percentage of the time. Not every service must be operated 24 hours a day, 7 days a week, 52 weeks a yearbut in the age of global commerce and the Internet, many do. It's a fact that sooner or later, system components fail, and the more components you have in a system, the greater the chance of failure. Therefore, in order to build a more perfect server, you need to build in redundancies and have the capability to fail over to those systems when problems arise. The purpose of having hardware redundancies is to provide greater availability, which is another way of describing a server's fault tolerance. People measure the fault tolerance of their servers in terms of the amount of time that the server is available to clients. Thus a server that can be accessed 9 days out of 10 is 90% available, which is also referred to as "one nine" availability. You probably don't think you need to do much to have a server run 9 days out of 10, and you're right. If a hard drive fails, you can probably restore it within 1 day, and chances are that any network outage isn't going to last more than 1 day, either. An availability of "two nines," or 99.0%, is also something that isn't all that hard to achieve, as it means that your server is down only approximately 87.7 hours a year, or 3 days, 15 hours, and roughly 40 minutes. Most departmental servers with standard RAID systems run in the range of from 98% up to around 99% of the time, depending on what applications they run. Let's say that your website must be running 99.9% of the time, or "three nines." You've done the calculation that shows that if your system goes down for longer than that period, your business will lose so much money that you could have replaced your server entirely. With three-nines availability, your window to fix potential problems or outages shrinks to only 8 hours 45 minutes each year, which is uncomfortably close to just one single working day. You might be able to replace a drive once a year, but if your network goes down for longer than a working day, you've lost more money than your company can afford to lose. Therefore, additional measures are called for: extra drives, redundant network connections, readily available duplicate data sets, and so forth. Now let's consider the next step up: "four nines," or 99.99%. A system that is available at the level of four nines is referred to as "highly available." With a system of this type, your allowable downtime shrinks to just under an hour, or around 53 minutes. That's not enough time to deal with a network outage; it's probably not enough time to replace a disk and rebuild its data set. If your system must achieve four-nines availability and doesn't, you have just about enough time to catch lunch and consider new career options. To get to this level of availability, not only must every subsystem associated with the server be fully duplicated but failover to the redundant systems must be swift. At this level, you could sustain maybe one reboot a month or so. Many people refer to this level of availability as "mission critical," and almost all organizations can get by with four nines. This is the level that the big banks and financial houses aim for as their minimum. In rare instances, four nines isn't good enough: A system may be required to be up 100% of the time. This is the case when a system is needed for a life-and-death situation and when the cost of a system's downtime is so large that no downtime is really acceptable. Some of the very largest OLTP financial institutions that process millions of dollars of transactions each hour fit into that category. At this level, "five nines," your window for downtime is a little more than 5 minutes a year, which translates to roughly one reboot. At this level of fault tolerance, it is not adequate to duplicate all computer subsystems. The entire computer itself must be duplicated, as you might do in a clustered server system. A small number of companies sell servers that have been engineered to be "fault tolerant." Probably the best known of them are the Tandem (now part of Hewlett-Packard) NonStop systems (see http://h20223.www2.hp.com/nonstopcomputing/cache/76385-0-0-0-121.aspx), Stratus Computer's VOS and FT systems (www.stratus.com), and Marathon Computers (www.marathontechnologies.com). FTvirtual server is another example of a fault-tolerant system. Table 21.2 summarizes the basics of server fault tolerance.
Integrated NICs, Memory, and Power SuppliesWhen your buy server hardware, you should expect to pay extra for the parts you purchase. Some of that additional cost goes into hardening the equipment so that it is less likely to fail. Drives meant for servers are manufactured to a higher standard than drives meant for desktops and laptops. Another factor that adds cost is redundancies built into the equipment you buy. Server motherboards can contain a number of redundant features. One very useful feature is a dual set of memory banks. With such a system, when a memory stick fails or is about to fail, a diagnostic utility in the server BIOS detects the problem and takes that bank offline and enables the available spare memory. Not all server motherboards have this feature, but it's a very useful one. Another feature on some server motherboards is dual integrated NICs. The first generation of these multihomed cards comes with one fast NIC port and one slower NIC port, typically a GigE port and a Fast Ethernet port. The manufacturer intends for you to use the fast port for your standard network connection to the server and to use the slow port as a management connection. Even when you purchase a motherboard with two NICs integrated into it, you should still install an extra NIC into your server. The rationale for this is that NICs do not consume much power or system resources, and integrated NICs seem to have a high failure rate. With an extra NIC installed, you can more easily switch over to the extra card. You can also install a second GigE card if you need a second fast port for throughput, as you might if you were building a proxy server or a router. Today's enterprise OSs support fault-tolerant NICs that work as failover devices or clustered devices. They can be embedded, PCI, or PCI-X cards in many cases. It is possible to find servers that support multiple power supplies, which allows for failover if one supply stops working. Power supplies have a relatively long lifetime, but when they fail, they don't tend to simply stop working. Their output starts to vary, and you may find that your server starts to experience some very bizarre behavior. You may start getting STOP errors, see blue screens, have applications fail, and experience other problems that may seem to be unrelated. Having a second power source lets you swap over and diagnose the problem a lot more easily. Not many server motherboards support dual power supplies, but it's a great feature to have, and it is highly recommended for any critical server in your organization. Load BalancingThe highest level of availability is achieved when you duplicate entire computer systems. There are two approaches to creating this type of fault tolerance:
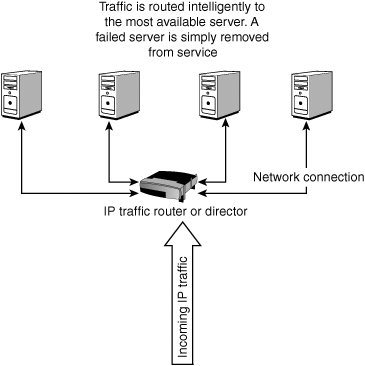
With load balancing, each server is a member of a domain, and the system is front-ended by a routing service either in hardware (such as a BigIP box) or implemented in software through a cluster service. An example of a cluster service is Microsoft Clustering Services (see www.microsoft.com/windowsserver2003/technologies/clustering/default.mspx), which appears in Windows Server 2003 as the Cluster service and Network Load Balancing service. A load-balanced set of computers is commonly referred to as a "server farm." When a computer fails in a server farm, the load balancing service simply removes the faulty server from the overall aggregate of servers. A user would notice a drop in service performance only if the server were operating at or near its rated load. When convenient, a new server can be added to the server farm to replace the one that was removed, and then it can be registered with the load balancing service. Figure 21.8 illustrates how load balancing works. Figure 21.8. How load balancing works. Load balancing is best used when a system is I/O limited and when you want to scale the system up by scaling out. A server farm is a highly reliable system with great redundancy. Server farms do not fail because of server failure; they typically fail because of problems with the infrastructure (for example, network connection or power failures). You can find server farms in enterprise websites such as Yahoo! or Google, in telecommunications systems where computers serve as switches and routers, and in many other places. Every network operating system you have read about in this book has a load balancing solution available for it either from the operating system vendor itself or from a third party. With NetWare 6.5, load balancing is built directly into the operating system. There are load balancing solutions for network operating system services such as DNS, DHCP, and others, as well as for applications running on servers. Because you can implement load balancing in both hardware and software, a very wide range of solutions are available in this area. Among the most notable solutions are the following:
This list includes only a very small portion of the available load balancing applications that are on the market today and is meant to be representative of the range of possibilities. Load Balancing Versus ClusteringMany people confuse load-balanced servers with clusters because both utilize multiple servers to the same end. Most of the time, when you load balance servers, each server retains its own separate identity as a computer, and when you cluster servers, they appear on the network as if they were a single computer. (We say most of the time because there are instances in which the software abstracts the different systems in a server farm from view, making it appear as if they are a single system; there are also times when a cluster appears to be multiple systems on the network, even if for the purpose of clustering only one logical entity can be addressed.) So if the situation is so cloudy, where is there a clear distinction? The answer lies in the mechanism involved in fault tolerance. In load-balanced situations, the system doesn't fail over when a member server fails; the capabilities of the failed server are simply removed from the service. A cluster, on the other hand, always fails over when a member server fails. The ability to always fail over quickly that characterizes a cluster also means that the mechanism for failover requires that the cluster have a rapid means of communications by which a failed server can be identified as failed and the control and activity of the cluster is then passed on to another server in the cluster. Different clustering products have different methods of communicating, but the predominant method is to have members of a cluster share a common bus and have a "heartbeat" signal poll the status of the cluster on a second-by-second basis. Figure 21.9 shows how a clustering works. Figure 21.9. How clustering works.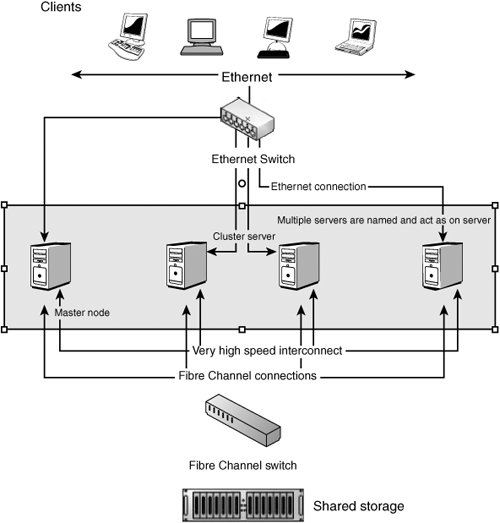 High-Performance ClustersMany different types of clusters are available in the market today, from two-node clusters on up. Broadly speaking, clusters can be classified into one of the following categories:
Let's consider these different possibilities a little more. The simplest cluster is a two-node cluster with failover. Examples of this architecture can be built with Microsoft Cluster Server and Linux-HA software. In the arrangement of a two-node cluster shown in Figure 21.10, two nodes of a cluster share a common RAID array where the data is stored. The RAID array is usually protected by being a 0+1 RAID level, which allows for both performance (0striping) and failover (1mirroring). Figure 21.10. An example of a two-node cluster with a shared storage array. A second SCSI bus connects one node directly to another, with a heartbeat signal running over that bus. When a server fails in this two-node arrangement, the second server takes over the host responsibility for the storage array and assumes the other duties of the cluster. The failed member is removed from the logical association until the administrator replaces it and adds the newly working system back into the cluster. The concept of polling in a cluster is called a "quorum" and can be extended to include a multinode cluster of any size. For more information about quorums, see www.windowsnetworking.com/articles_tutorials/Cluster-Quorums.html. A share-nothing cluster implies that the servers in a cluster operate independently, but a mechanism exists that allows failover of the cluster to another cluster node when a fault is determined. Share-nothing clusters are a variation on simple load balancing. Not many systems are built with the share-nothing approach because it is an expensive architecture, and for the cost, OEMs prefer to build share-everything systems. High-performance clusters are often built with many connected computer systems. These types of systems aren't new, but their application on lower-costs PC server platforms has popularized them. As early as 1977, Datapoint had developed ARCnet as a commercial cluster. The best known of the early implementations probably were the VAX/VMS VAXClusters that appeared in the 1980s. When you move beyond two nodes in a cluster, the most important characteristic of the cluster technology becomes the high-performance interconnect technology. Clusters and high-speed networking are intimately related. In a high-speed network, each cluster node on the network requires some sort of CPU offload technology to move network processing to very-high-speed ASICs on the networking card. Among the technologies that power the larger clusters today are GigaNet's CLAN, Myrinet, Quadrics, InfiniBand, and Tandem's ServerNet, among others. These networking technologies typically work in the 2Gbps range and are expected to move to the 10Gbps range in the near future. Working clusters with more than 100 servers have been built in the past. Note The Top500 organization publishes a list of the highest-performance computer systems in the world at www.top500.org/lists. The current list at the time of this writing had the following five systems at the top:
The top system used 131,072 processors to achieve a rating of 280.6 Tflop/s, which is a measure of how fast these system run the LINPACK Benchmark. LINPACK is a set of linear equations that measure the floating-point performance of a system. See www.top500.org/lists/linpack.php for more information. As you peruse this list, notice that quite a few of the listed supercomputers are built using PC-based servers as their building blocks, along with very-high-speed interconnect technologies. Among the products used to cluster PC servers are the following:
The next step beyond simple clusters is grid computing. What differentiates grid technology from traditional clusters is that although a grid gives you distributed processing through large numbers of computers, it is still just collections of computers that don't operate as a unit, don't form a domain or share security credentials, and don't have the fast failover of a high-performance computing (HPC) cluster. |

EAN: 2147483647
Pages: 240