Deriving Classes from Use Cases
|
Now we're ready for the hard part - deriving business classes from use cases. Part of the problem is that use cases are not object-oriented. They simply represent a list of everything users can do with the computer system. We need to examine the description of the use case and derive business classes from it. When using techniques such as CRC cards (which are not part of the UML), we are encouraged to look at the nouns in the use case description as possible candidates for use cases. Here's a list of some of these key nouns (ignoring nouns that are obviously attributes of other entities such as Borrower ID and Media ID):
This process can actually get you pretty far, but I've found from experience it doesn't take you far enough. If you start out with this list of entities, you start going down a particular path, and have to backtrack and rework your object model. Although reworking or refactoring your model is part of the process, we can get ourselves closer to a working object model by thinking about data.
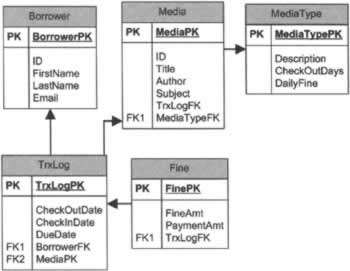
Thinking about DataWhy does thinking about our application's data help us in our object modeling efforts? As we mentioned earlier in this chapter, when we data model we often create tables representing real-world entities. Due to this relationship, you will often create a business object for each main table in your application, so thinking about data early is a wise decision. Although you want to start thinking about data, you don't want to get 'married' to a particular data model this early on. Use your data model to help you think things through, but don't set it in stone. Be willing to let your business object's behavior influence the data model. I have found data modeling helps shake the bugs out of an object model. Even if you wait to model data until after you've first tried to create your object model, you can test your model by creating test data, which you access from your business classes. In other cases, you may have a data structure you are forced to work with. In this case, you simply can't ignore the data structure. However, a good object model can help hide the flaws in an otherwise imperfect data model. So, let's start thinking about the structure of the data we need for our application. The following diagram shows a Visio data diagram containing tables we've started to flesh out for our library application: The first table in this diagram is the Borrower table. This is an easy place to start because our use case specifically mentions a Borrower ID. Notice the Borrower table has both a primary key field (BorrowerPK) and an ID field (ID). Most database designers agree it's important for all tables in your application to have a system-generated primary key used to uniquely identify each record in addition to any 'business' keys you may have. In this table, the ID field corresponds to the Borrower ID mentioned in the use case. This is the value manually entered by the Librarian or scanned from the Borrower's library card. However, the primary key is used when linking Borrower records to records in other tables. For good measure, we've also added a few obvious fields such as FirstName, LastName, and Email. We'll talk about the TrxLogFK foreign key field in just a bit. Media is another easy table. Obviously, we need to have a record of each media item borrowers can check out. Again, we have a situation where there is both a primary key field and an ID field. Again, we've added some obvious fields such as Title, Author, and Subject. There is also a foreign key pointer field (MediaTypeFK) to the MediaType table. Rather than storing the media type information directly in the Media table, we normalize our data by storing the information in a separate MediaType table. The MediaType table contains a description of the type of media (magazine, book, DVD), the number of days it can be checked out, and the daily fine if the item is overdue. The Transaction Log table (TrxLog) isn't as obvious. Our use cases specify we need to keep track of checked out media, whether or not it's overdue, as well as any unpaid fines. The easiest way to do this is to create a transaction log containing a record of each media check out/check in, including the media ID and the borrower ID. Although this information could be stored in the Media table, placing it there does not allow us to maintain a history, because these fields are overwritten the next time the media is checked out/in. The DueDate field provides a place where the media due date is stored. Although this information can be calculated dynamically, persisting it to the transaction record allows our system to account for any changes we make to the check out period rules. If the due date is calculated and saved when an item is checked out, even if the business rules change before the item is returned, we can still determine the correct due date for each piece of media. The Fine table contains fines applied to specific transaction log records. The TrxLogFK field is a foreign key pointer to the TrxLog table. The FineAmt field contains the amount of the fine and the PaymentAmt field contains any payment amount applied to this fine. I guarantee this accounting solution will bring tears to you financial wizards, but this simple solution works fine for our example.
| |||||||||||||||||||||||||||||||||||

EAN: N/A
Pages: 85