3.2 Implementing an HACMP cluster
|
| < Day Day Up > |
|
3.2 Implementing an HACMP cluster
HACMP is a clustering software provided by IBM for implementing high availability solutions on AIX platforms. In the following sections we describe the process of planning, designing, and implementing a high availability scenario using HACMP. For each implementation procedure discussed in this section, we provide examples by planning an HACMP cluster for IBM Tivoli Workload Scheduler high availability scenario.
3.2.1 HACMP hardware considerations
As mentioned in Chapter 2, "High level design and architecture" on page 31, the ultimate goal in implementing an HA cluster is to eliminate all possible single points of failure. Keep in mind that cluster software alone does not provide high availability; appropriate hardware configuration is also required to implement a highly available cluster. This applies to HACMP as well. For general hardware considerations about an HA cluster, refer to 2.2, "Hardware configurations" on page 43.
3.2.2 HACMP software considerations
HACMP not only provides high availability solutions for hardware, but for mission-critical applications that utilize those hardware resources as well. Consider the following before you plan high availability for your applications in an HACMP cluster:
-
Application behavior
-
Licensing
-
Dependencies
-
Automation
-
Robustness
-
Fallback policy
For details on what you should consider for each criteria, refer to 2.1.2, "Software considerations" on page 39.
3.2.3 Planning and designing an HACMP cluster
As mentioned in Chapter 2, "High level design and architecture" on page 31, the sole purpose of implementing an HACMP cluster is to eliminate possible single points of failure in order to provide high availability for both hardware and software. Thoroughly planning the use of both hardware and software components is required prior to HACMP installation.
To plan our HACMP cluster, we followed the steps described in HACMP for AIX Version 5.1, Planning and Installation Guide, SC23-4861. Because we cannot cover all possible high availability scenarios, in this section we discuss only the planning tasks needed to run IBM Tivoli Workload Scheduler in a mutual takeover scenario. Planning tasks for a mutual takeover scenario can be extended for a hot standby scenario.
The following planning tasks are described in this section.
-
Planning the cluster nodes
-
Planning applications for high availability
-
Planning the cluster network
-
Planning the shared disk device
-
Planning the shared LVM components
-
Planning the resource groups
-
Planning the cluster event processing
Use planning worksheets
A set of offline and online planning worksheets is provided for HACMP 5.1. For a complete and detailed description of planning an HACMP cluster using these worksheets, refer to HACMP for AIX Version 5.1, Planning and Installation Guide, SC23-4861.
By filling out these worksheets, you will be able to plan your HACMP cluster easily. Here we describe some of the offline worksheets. (Note, however, that our description is limited to the worksheets and fields that we used; fields and worksheets that were not essential to our cluster plan are omitted.)
Draw a cluster diagram
In addition to using these worksheets, it is also advisable to draw a diagram of your cluster as you plan. A cluster diagram should provide an image of where your cluster resources are located. In the following planning tasks, we show diagrams of what we planned in each task.
Planning the cluster nodes
The initial step in planning an HACMP cluster is to plan the size of your cluster. This is the phase where you define how many nodes and disk subsystems you need in order to provide high availability for your applications. If you plan high availability for one application, a cluster of two nodes and one disk subsystem may be sufficient. If you are planning high availability for two or more applications installed on several servers, you may want to add more than one nodes to provide high availability. You may also need more than one disk subsystem, depending on the amount of data you plan to store on external disks.
For our scenario of a mutual takeover, we plan a cluster with two AIX platforms and an SSA disk subsystem to share. Machine types used in the scenario are a given environment in our lab. When planning for a mutual takeover configuration, make sure that each node has sufficient machine power to perform the job of its own and the job of the other node in the event that a fallover occurs. Otherwise, you may not achieve maximum application performance during a fallover.
Figure 3-3 shows a diagram of our cluster node plan. The cluster name is cltivoli. There are two nodes in the cluster, tivaix1 and tivaix2, sharing an external disk subsystem. Each node will run one business application and one instance of IBM Tivoli Workload Scheduler to manage that application. Note that we left some blank space in the diagram for adding cluster resources to this diagram as we plan.
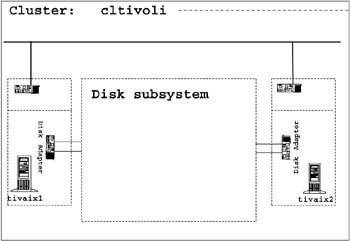
Figure 3-3: Cluster node plan
In this section and the following sections, we describe the procedures to plan an HACMP cluster using our scenario as an example. Some of the planning tasks may be extended to configure high availability for other applications; however, we are not aware of application-specific considerations and high availability requirements.
Planning applications for high availability
After you have planned the cluster nodes, the next step is to define where your application executables and data should be located, and how you would like HACMP to control them in the event of a fallover or fallback. For each business application or any other software packages that you plan to make highly available, create an application definition and an application server.
Application definition means giving a user-defined name to your application, and then defining the location of your application and how it should be handled in the event of fallover. An application server is a cluster resource that associates the application and the names of specially written scripts to start and stop the application. Defining an application server enables HACMP to resume application processing on the takeover node when a fallover occurs.
When planning for applications, the following HACMP worksheets may help to record any required information.
-
Application Worksheet
-
Application Server Worksheet
Completing the Application Worksheet
The Application Worksheet helps you to define which applications should be controlled by HACMP, and how they should be controlled. After completing this worksheet, you should have at least the following information defined:
| Application Name | Assign a name for each application you plan to put under HACMP control. This is a user-defined name associated with an application. |
| Location of Key Application Files | For each application, define the following information for the executables and data. Make sure you enter the full path when specifying the path of the application files.
|
| Cluster Name | Name of the cluster where the application resides. |
| Node Relationship | Specify the takeover relationship of the nodes in the cluster (choose from cascading, concurrent, or rotating). For a description of each takeover relationship, refer to HACMP for AIX Version 5.1, Concepts and Facilities Guide, SC23-4864. |
| Fallover Strategy | Define the fallover strategy for the application. Specify which node would be the primary and which node will be the takeover.
|
| Start Commands/Procedures | Specify the commands or procedures for starting the application. This is the command or procedure you will write in your application start script. HACMP invokes the application start script in the event of a cluster start or a fallover. |
| Verification Commands | Specify the commands to verify that your application is up or running. |
| Stop Commands/Procedures | Specify the commands or procedures for stopping the application. This is the command or procedure you will write in your application stop script. HACMP will invoke the application stop script in the event of a cluster shutdown or a fallover. |
| Verification Commands | Specify the commands to verify that your application has stopped. |
| Note | Start, stop, and verification commands specified in this worksheet should not require operator intervention; otherwise, cluster startup, shutdown, fallover, and fallback may halt. |
Table 3-1 on page 72 and Table 3-2 on page 73 show examples of how we planned IBM Tivoli Workload Scheduler for high availability. Because we plan to have two instances of IBM Tivoli Workload Scheduler running in one cluster, we defined two applications, TWS1 and TWS2. In normal production, TWS1 resides on node tivaix1, while TWS2 resides on node tivaix2.
| Items to define | Value |
|---|---|
| Application Name | TWS1 |
| Location of Key Application Files
|
|
| Cluster Name | cltivoli |
| Node Relationship | cascading |
| Fallover Strategy | tivaix1: primary tivaix2: takeover |
| Start Commands/Procedures |
|
| Verification Commands |
|
| Stop Commands/Procedures |
|
| Verification Commands |
|
| Items to define | Value |
|---|---|
| Application Name | TWS2 |
| Location of Key Application Files
|
|
| Cluster Name | cltivoli |
| Node Relationship | cascading |
| Fallover Strategy | tivaix2: primary tivaix1: takeover |
| Start Commands/Procedures |
|
| Verification Commands |
|
| Stop Commands/Procedures |
|
| Verification Commands |
|
| Note | If you are installing an IBM Tivoli Workstation Scheduler version older than 8.2, you cannot use /usr/maestro and /usr/maestro2 as the installation directories. Why? Because in such a case, both installations would use the same Unison directory—and the Unison directory should be unique for each installation. Therefore, if installing a version older than 8.2, we suggest using /usr/maestro1/TWS and /usr/maestro2/TWS as the installation directories, which will make the Unison directory unique. For Version 8.2, this is not important, since the Unison directory is not used in this version. |
Notice that we placed the IBM Tivoli Workload Scheduler file systems on the external shared disk, because both nodes must be able to access the two IBM Tivoli Workload Scheduler instances for fallover. The two instances of IBM Tivoli Workload Scheduler should be located in different file systems to allow both instances of IBM Tivoli Workload Scheduler to run on the same node. Node relationship is set to cascading because each IBM Tivoli Workload Scheduler instance should return to its primary node when it rejoins the cluster.
Completing the Application Server Worksheet
This worksheet helps you to plan the application server cluster resource. Define an application server resource for each application that you defined in the Application Worksheet. If you plan to have more than one application server in a cluster, then add a server name and define the corresponding start/stop script for each application server.
| Cluster Name | Enter the name of the cluster. This must be the same name you specified for Cluster Name in the Application Worksheet. |
| Server Name | For each application in the cluster, specify an application server name. |
| Start Script | Specify the name of the application start script for the application server in full path. |
| Stop Script | Specify the name of the application stop script for the application server in full path. |
We defined two application servers, tws_svr1 and tws_svr2 in our cluster; tws_svr1 is for controlling application TWS1, and tws_svr2 is for controlling application TWS2. Table 3-3 shows the values we defined for tws_svr1.
| Items to define | Value |
|---|---|
| Cluster Name | cltivoli |
| Server Name | tws_svr1 |
| Start Script | /usr/es/sbin/cluster/scripts/start_tws1.sh |
| Stop Script | /usr/es/sbin/cluster/scripts/stop_tws1.sh |
Table 3-4 shows the values we defined for tws_svr2.
| Items to define | Value |
|---|---|
| Cluster Name | cltivoli |
| Server Name | tws_svr2 |
| Start Script | /usr/es/sbin/cluster/scripts/start_tws2.sh |
| Stop Script | /usr/es/sbin/cluster/scripts/stop_tws2.sh |
After planning your application, add the information about your applications into your diagram. Figure 3-4 shows an example of our cluster diagram populated with our application plan. We omitted specifics such as start scripts and stop scripts, because the purpose of the diagram is to show the names and locations of cluster resources.
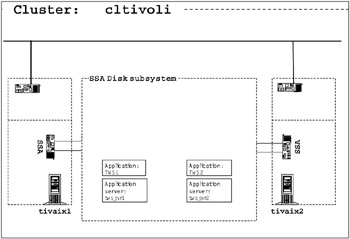
Figure 3-4: Cluster diagram with applications added
Planning the cluster network
The cluster network must be planned so that network components (network, network interface cards, TCP/IP subsystems) are eliminated as a single point of failure. When planning the cluster network, complete the following tasks:
-
Design the cluster network topology.
Network topology is the combination of IP and non-IP (point-to-point) networks to connect the cluster nodes and the number of connections each node has to each network.
-
Determine whether service IP labels will be made highly available with IP Address Takeover (IPAT) via IP aliases or IPAT via IP Replacement. Also determine whether IPAT will be done with or without hardware address takeover.
Service IP labels are relocatable virtual IP label HACMP uses to ensure client connectivity in the event of a fallover. Service IP labels are not bound to a particular network adapter. They can be moved from one adapter to another, or from one node to another.
We used the TCP/IP Network Worksheet, TCP/IP Network Interface Worksheet, and Point-to-point Networks Worksheet to plan our cluster network.
Completing the TCP/IP Network Worksheet
Enter information about all elements of your TCP/IP network that you plan to have in your cluster. The following items should be identified when you complete this worksheet.
| Cluster Name | The name of your cluster. |
Then, for each network, specify the following.
| Network Name | Assign a name for the network. |
| Network Type | Enter the type of the network (Ethernet, Token Ring, and so on.) |
| Netmask | Enter the subnet mask for the network. |
| Node Names | Enter the names of the nodes you plan to include in the network. |
| IPAT via IP Aliases | Choose whether to enable IP Address Takeover (IPAT) over IP Aliases or not. If you do not enable IPAT over IP Aliases, it will be IPAT via IP Replacement. For descriptions of the two types of IPAT, refer to HACMP for AIX Version 5.1, Planning and Installation Guide, SC23-4861. |
| IP Address Offset for Heartbeating over IP Aliases | Complete this field if you plan heartbeating over IP Aliases. For a detailed description, refer to HACMP for AIX Version 5.1, Planning and Installation Guide, SC23-4861. |
Table 3-5 on page 81 lists the values we specified in the worksheet. We defined one TCP/IP network called net_ether_01.
| Cluster Name | cltivoli | ||||
|---|---|---|---|---|---|
| Network Name | Network Type | Netmask | Node Names | IPAT via IP Aliases | IP Address Offset for Heartbeating over IP Aliases |
| net_ether_01 | Ethernet | 255.255.255.0 | tivaix1, tivaix2 | enable | 172.16.100.1 |
| Note | A network in HACMP is a group of network adapters that will share one or more service IP labels. Include all physical and logical network that act as a backup for one another in one network. For example, if two nodes are connected to two redundant physical networks, then define one network to include the two physical networks. |
Completing the TCP/IP Network Interface Worksheet
After you have planned your TCP/IP network definition, plan your network Interface. Associate your IP labels and IP address to network interface. When you complete this worksheet, the following items should be defined. Complete this worksheet for each node you plan to have in your cluster.
| Node Name | Enter the node name. |
| IP Label | Assign an IP label for each IP Address you plan to have for the node. |
| Network Interface | Assign a physical network interface (for example, en0, en1) to the IP label. |
| Network Name | Assign an HACMP network name. This network name must be one of the networks you defined in the TCP/IP Network Worksheet. |
| Interface Function | Specify the function of the interface and whether the interface is service, boot or persistent. |
| Note | In HACMP, there are several kinds of IP labels you can define. A boot IP label is a label that is bound to one particular network adapter. This label is used when the system starts. A Service IP label is a label that is associated with a resource group and is able to move from one adapter to another on the same node, or from one node to another. It floats among the physical TCP/IP network interfaces to provide IP address consistency to an application serviced by HACMP. This IP label exists only when cluster is active. A Persistent IP label is a label bound to a particular node. This IP label also floats among two or more adapters in one node, to provide constant access to a node, regardless of the cluster state. |
| IP Address | Associate an IP address to the IP label. |
| Netmask | Enter the netmask. |
| Hardware Address | Specify hardware address of the network adapter if you plan IPAT with hardware address takeover. |
Table 3-6 and Table 3-7 show the values we entered in our worksheet. We omitted hardware address because we do not plan to have hardware address takeover.
| Node Name | tivaix1 | ||||
|---|---|---|---|---|---|
| IP Label | Network Interface | Network Name | Interface Function | IP Address | Netmask |
| tivaix1_svc | - | net_ether_01 | service | 9.3.4.3 | 255.255.254.0 |
| tivaix1_bt1 | en0 | net_ether_01 | boot | 192.168.100.101 | 255.255.254.0 |
| tivaix1_bt2 | en1 | net_ether_01 | boot | 10.1.1.101 | 255.255.254.0 |
| tivaix1 | - | net_ether_01 | persistent | 9.3.4.194 | 255.255.254.0 |
| Node Name | tivaix2 | ||||
|---|---|---|---|---|---|
| IP Label | Network Interface | Network Name | Interface Function | IP Address | Netmask |
| tivaix2_svc | - | net_ether_01 | service | 9.3.4.4 | 255.255.254.0 |
| tivaix2_bt1 | en0 | net_ether_01 | boot | 192.168.100.102 | 255.255.254.0 |
| tivaix2_bt1 | en1 | net_ether_01 | boot | 10.1.1.102 | 255.255.254.0 |
| tivaix2 | - | net_ether_01 | persistent | 9.3.4.195 | 255.255.254.0 |
Completing the Point-to-Point Networks Worksheet
You may need a non-TCP/IP point-to-point network in the event of a TCP/IP subsystem failure. The Point-to-Point Networks Worksheet helps you to plan non-TCP/IP point-to-point networks. When you complete this worksheet, you should have the following items defined.
| Cluster name | Enter the name of your cluster. |
Then, for each of your point-to-point networks, enter the values for the following items:
| Network Name | Enter the name of your point-to-point network. |
| Network Type | Enter the type of your network (disk heartbeat, Target Mode SCSI, Target Mode SSA, and so on). Refer to HACMP for AIX Version 5.1, Planning and Installation Guide, SC23-4861, for more information. |
| Node Names | Enter the name of the nodes you plan to connect with the network. |
| Hdisk | Enter the name of the physical disk (required only for disk heartbeat networks). |
Table 3-8 on page 91 lists the definition for point-to-point network we planned in our scenario. We omitted the value for Hdisk because we did not plan disk heartbeats.
| Cluster Name | cltivoli | |
|---|---|---|
| Network Name | Network Type | Node Names |
| net_tmssa_01 | Target Mode SSA | tivaix1, tivaix2 |
After you have planned your network, add your network plans to the diagram. Figure 3-5 on page 81 shows our cluster diagram with our cluster network plans added. There is a TCP/IP network definition net_ether_01. For a point-to-point network, we added net_tmssa_01. For each node, we have two boot IP labels, a service IP label and a persistent IP label.
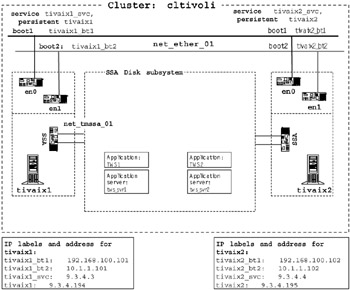
Figure 3-5: Cluster diagram with network topology added
Planning the shared disk device
Shared disk is an essential part of HACMP cluster. It is usually one or more external disks shared among two or more cluster nodes. In a non-concurrent configuration, only one node at a time has control of the disks. If a node fails in a cluster, the node with the next highest priority in the cluster acquires the ownership of the disks and restarts applications to restore mission-critical services. This ensures constant access to application executables and data stored on those disks. When you complete this task, at a minimum the following information should be defined:
-
Type of shared disk technology
-
The number of disks required
-
The number of disk adapters
HACMP supports several disk technologies, such as SCSI and SSA. For a complete list of supported disk device, consult your service provider. We used an SSA disk subsystem for our scenario, because this was the given environment of our lab.
Because we planned to have two instances of IBM Tivoli Workload Scheduler installed in separate volume groups, we needed at least two physical disks. Mirroring SSA disks is recommended, as mirroring an SSA disk enables the replacement of a failed disk drive without powering off entire system. Mirroring requires an additional disk for each physical disk, so the minimum number of disks would be four physical disks.
To avoid having disk adapters become single points of failure, redundant disk adapters are recommended. In our scenario, we had one disk adapter for each node, due to the limitations of our lab environment.
Figure 3-6 on page 83 shows a cluster diagram with at least four available disks in the SSA subsystem. While more than one disk adapter per node is recommended, we only have one disk adapter on each node due to the limitations of our environment.
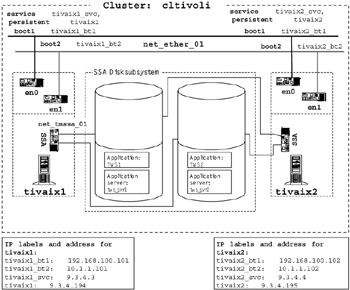
Figure 3-6: Cluster diagram with disks added
Planning the shared LVM components
AIX uses Logical Volume Manager (LVM) to manage disks. LVM components (physical volumes, volume groups, logical volumes, file systems) maps data between physical and logical storage. For more information on AIX LVM, refer to AIX System Management Guide.
To share and control data in an HACMP cluster, you need to define LVM components. When planning for LVM components, we used the Shared Volume Group/Filesystem Worksheet.
Completing the Shared Volume Group/Filesystem Worksheet
For each field in the worksheet, you should have at least the following information defined. This worksheet should be completed for each shared volume group you plan to have in your cluster.
| Node Names | Record the node name of the each node in the cluster. |
| Shared Volume Group Name | Specify a name for the volume group shared by the nodes in the cluster. |
| Major Number | Record the planned major number for the volume group. This field could be left blank to use the system default if you do not plan to have NFS exported filesystem. |
| When configuring shared volume group, take note of the major number. You may need this when importing volume groups on peer nodes. | |
| Log Logical Volume Name | Specify a name for the log logical volume (jfslog). The name of the jfslog must be unique in the cluster. (Do not use the system default name, because a log logical name on another node may be assigned the identical name.) When creating jfslog, make sure you rename it to the name defined in this worksheet. |
| Physical Volumes | For each node, record the names of physical volumes you plan to include in the volume group. Physical volume names may differ by node, but PVIDs (16-digit IDs for physical volumes) for the shared physical volume must be the same on all nodes. To check the PVID, use the lspv command. |
Then, for each logical volume you plan to include in the volume group, fill out the following information:
| Logical Volume Name | Assign a name for the logical volume. |
| Number of Copies of Logical Partition | Specify the number of copies of the logical volume. This number is needed for mirroring the logical volume. If you plan mirroring, the number of copies must be 2 or 3. |
| Filesystem Mount Point | Assign a mount point for the logical volume name. |
| Size | Specify the size of the file system in 512-byte blocks. |
Table 3-9 and Table 3-10 show the definition of volume groups planned for our scenario. Because we plan to have shared volume groups for each instance of IBM Tivoli Workload Scheduler, we defined volume groups tiv_vg1 and tiv_vg2. Then, we defined one logical volume in each of the volume groups to host a file system. We assigned major numbers instead of using system default, but this is not mandatory when you are not using NFS exported file systems.
| Items to define | Value |
|---|---|
| Node Names | tivaix1, tivaix2 |
| Shared Volume Group Name | tiv_vg1 |
| Major Number | 45 |
| Log Logical Volume name | lvtws1_log |
| Physical Volume son tivaix1 | hdisk6 |
| Physical Volumes on tivaix2 | hdisk7 |
| Logical Volume Name | lvtws1 |
| Number of Copies | 2 |
| Filesystem Mount point | /usr/maestro |
| Size | 1048576 |
| Items to define | Value |
|---|---|
| Node Names | tivaix1, tivaix2 |
| Shared Volume Group Name | tiv_vg2 |
| Major Number | 46 |
| Log Logical Volume name | lvtws2_log |
| Physical Volumes on tivaix1 | hdisk7 |
| Physical Volumes on tivaix2 | hdisk20 |
| Logical Volume Name | lvtws2 |
| Number of Copies | 2 |
| Filesystem Mount point | /usr/maestro2 |
| Size 1048576 |
Figure 3-8 on page 91 shows the cluster diagram with shared LVM components added.
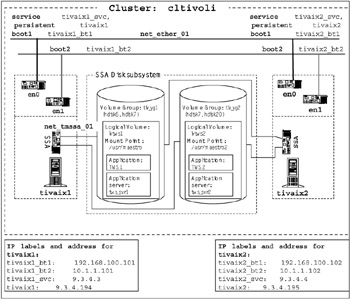
Figure 3-7: Cluster diagram with shared LVM added
Planning the resource groups
A resource group refers to a set of resources that will move from one node to another in the event of an HACMP fallover or a fallback. A resource group usually consists of volume groups and service IP address. For this task, we used the Resource Group Worksheet. One worksheet must be completed for each resource group that you plan. The following items should be defined when you complete the worksheet.
| Cluster Name | Specify the name of the cluster where the resource group reside. This should be the name that you have defined when planning the cluster nodes. |
| Resource Group Name | Assign a name for the resource group you are planning. |
| Management Policy | Choose the management policy of the resource group (Cascading, Rotating, Concurrent or Custom). For details on management policy, refer to HACMP for AIX Version 5.1, Concepts and Facilities Guide, SC23-4864. |
| Participating Nodes/Default Node Priority | Specify the name of nodes that may acquire the resource group. When specifying the nodes, make sure the nodes are listed in the order of their priority (nodes with higher priority should be listed first.) |
| Service IP Label | Specify the service IP label for IP Address Takeover (IPAT). This IP label is associated to the resource group, and it is transferred to another adapter or a node in the event of a resource group fallover. |
| Volume Groups | Specify the name of the volume group(s) to include in the resource group. |
| Filesystems | Specify the name of the file systems to include in the resource group. |
| Filesystems Consistency Check | Specify fsck or logredo. This is the method to check consistency of the file system. |
| Filesystem Recovery Method | Specify parallel or sequential. This is the recovery method for the file systems. |
| Automatically Import Volume Groups | Set it to true if you wish to have volume group imported automatically to any cluster nodes in the resource chain. |
| Inactive Takeover | Set it to true or false. If you want the resource groups acquired only by the primary node, set this attribute to false. |
| Cascading Without Fallback Activated | Set it to true or false. If you set this to true, then a resource group that has failed over to another node will not fall back automatically in the event that its primary node rejoins the cluster. This option is useful if you do not want HACMP to move resource groups during application processing. |
| Disk Fencing Activated | Set it to true or false. |
| File systems Mounted before IP Configured | Set it true or false. |
| Note | There is no need to specify file system names if you have specified a name of a volume group, because all the file systems in the specified volume group will be mounted by default. In the worksheet, leave the file system field blank unless you need to include individual file systems. |
Table 3-11 on page 89 and Table 3-12 on page 89 show how we planned our resource groups. We defined one resource group for each of the two instances of IBM Tivoli Workload Scheduler, rg1 and rg2.
| Items to define | Value |
|---|---|
| Cluster Name | cltivoli |
| Resource Group Name | rg1 |
| Management policy | cascading |
| Participating Nodes/Default Node Priority | tivaix1, tivaix2 |
| Service IP Label | tivaix1_svc |
| Volume Groups | tiv_vg1 |
| Filesystems Consistency Check | fsck |
| Filesystem Recovery Method | sequential |
| Automatically Import Volume Groups | false |
| Inactive Takeover Activated | false |
| Cascading Without Fallback Activated | true |
| Disk Fencing Activated | false |
| File systems Mounted before IP Configured | false |
| Items to define | Value |
|---|---|
| Cluster Name | cltivoli |
| Resource Group Name | rg1 |
| Management policy | cascading |
| Participating Nodes/Default Node Priority | tivaix2, tivaix1 |
| Service IP Label | tivaix2_svc |
| Volume Groups | tiv_vg2 |
| Filesystems Consistency Check | fsck |
| Filesystem Recovery Method | sequential |
| Automatically Import Volume Groups | false |
| Inactive Takeover Activated | false |
| Cascading Without Fallback Activated | true |
| Disk Fencing Activated | false |
| File systems Mounted before IP Configured | false |
Notice that we set Inactive Takeover Activated to false, because we want the resource group to always be acquired by the node that has the highest priority in the resource chain.
We set Cascading Without Fallback Activated to true because we do not want IBM Tivoli Workload Scheduler to fall back to the original node while jobs are running.
Figure 3-9 on page 85 shows the cluster diagram with resource groups added.
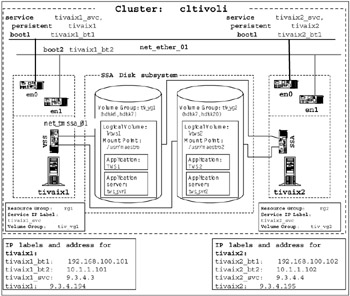
Figure 3-8: Cluster diagram with resource group added
Planning the cluster event processing
A cluster event is a change of status in the cluster. For example, if a node leaves the cluster, that is a cluster event. HACMP takes action based on these events by invoking scripts related to each event. A default set of cluster events and related scripts are provided. If you want some specific action to be taken on an occurrence of these events, you can define a command or script to execute before/after each event. You may also define events of your own. For details on cluster events and customizing events to tailor your needs, refer to HACMP documentation.
In this section, we give you an example of customized cluster event processing. In our scenario, we planned our resource group with CWOF because we do not want HACMP to fallback IBM Tivoli Workload Scheduler during job execution. However, this leaves two instances of IBM Tivoli Workload Scheduler running on one node, even after the failed node has reintegrated into the cluster. The resource group must be manually transferred to the reintegrated node, or some implementation must be done to automate this procedure.
Completing the Cluster Event Worksheet
To plan cluster event processing, you will need to define several items. The Cluster Event Worksheet helps you to plan your cluster events. Here we describe the items that we defined for our cluster events.
| Cluster Name | The name of the cluster. |
| Cluster Event Name | The name of the event you would like to configure. |
| Post-Event Command | The name of the command or script you would like to execute after the cluster event you specified in the Cluster Event Name field. |
Table 3-13 shows the values we defined for each item.
| Items to define | Value |
|---|---|
| Cluster Name | cltivoli |
| Cluster Event Name | node_up_complete |
| Post-Event Command | /usr/es/sbin/cluster/sh/quiesce_tws.sh |
3.2.4 Installing HACMP 5.1 on AIX 5.2
This section provides step-by-step instructions for installing HACMP 5.1 on AIX 5.2. First we cover the steps to prepare the system for installing HACMP, then we go through the installation and configuration steps.
Preparation
Before you install HACMP software, complete the following tasks:
-
Meet all hardware and software requirements
-
Configure the disk subsystems
-
Define the shared LVM components
-
Configure Network Adapters
Meet all hardware and software requirements
Make sure your system meets the hardware and software requirements for HACMP software. The requirements may vary based on the hardware type and software version that you use. Refer to the release notes for requirements.
Configure the disk subsystems
Disk subsystems are an essential part of an HACMP cluster. The external disk subsystems enable physically separate nodes to share the same set of disks. Disk subsystems must be cabled and configured properly so that all nodes in a cluster is able to access the same set of disks. Configuration may differ depending on the type of disk subsystems you use. In our scenario, we used IBM 7133 Serial Storage Architecture (SSA) Disk Subsystem Model 010.
Figure 3-9 shows how we cabled our 7133 SSA Disk Subsystem.
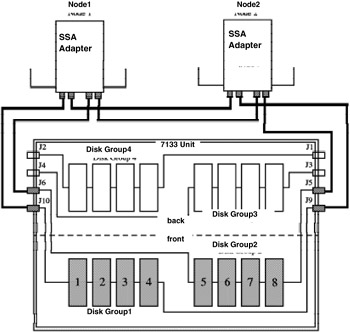
Figure 3-9: SSA Cabling for high availability scenario
The diagram shows a single 7133 disk subsystem containing eight disk drives connected between two nodes in a cluster. Each node has one SSA Four Port Adapter. The disk drives in the 7133 are cabled to the two machines in two loops. Notice that there is a loop that connects Disk Group1 and the two nodes, and another loop that connects Disk Group2 and the two nodes. Each loop is connected to a different port pair on the SSA Four Port Adapters, which enables the two nodes to share the same set of disks.
Once again, keep in mind that this is only an example scenario of a 7133 disk subsystem configuration. Configuration may vary depending on the hardware you use. Consult your system administrator for precise instruction on configuring your external disk device.
| Important: | In our scenario, we used only one SSA adapter per node. In actual production environments, we recommend that an additional SSA adapter be added to each node to eliminate single points of failure. |
Define the shared LVM components
Prior to installing HACMP, shared LVM components such as volume groups and file systems must be defined. In this section, we provide a step-by-step example of the following tasks:
-
Defining volume groups
-
Defining file systems
-
Renaming logical volumes
-
Importing volume groups
-
Testing volume group migrations
Defining volume groups
-
Log in as root user on tivaix1.
-
Open smitty. The following command takes you to the Volume Groups menu.
# smitty vg
-
In the Volume Groups menu, select Add a Volume Group as seen in Figure 3-10 on page 95.
Figure 3-10: Volume Group SMIT menu -
In the Add a Volume Group screen (Figure 3-11 on page 96), enter the following value for each field. Note that physical volume names and volume group major number may vary according to your system configuration.
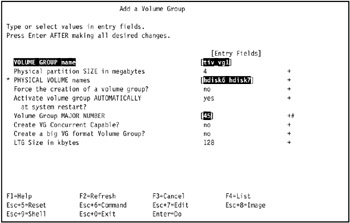
Figure 3-11: Defining a volume groupVOLUME GROUP Name:tivaix1
Physical Partition SIZE in megabytes:4
PHYSICAL VOLUME names:hdisk6, hdisk7
Activate volume group AUTOMATICALLY at system restart?: no
Volume Group MAJOR NUMBER:45
Create VG Concurrent Capable?:no
-
Verify that the volume group you specified in the previous step (step d) is successfully added and varied on.
# lsvg -o
Example 3-1 shows the command output. With the -o option, you will only see the volume groups that are successfully varied on. Notice that volume group tiv_vg1 is added and varied on.
Example 3-1: lvsg -o output

# lsvg -o tiv_vg1 rootvg
-
Defining file systems
-
To create a file system, enter the following command. This command takes you to the Add a Journaled File System menu.
# smitty crjfs
-
Select Add a Standard Journaled File System (Figure 3-12). You are prompted to select a volume group in which the shared filesystem should reside. Select the shared volume group that you defined previously, and proceed to the next step.
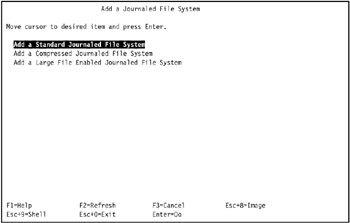
Figure 3-12: Add a Journaled File System menu -
Specify the following values for the new journaled file system.
Volume Group Name:tiv_vg1
SIZE of file system unit size:Megabytes
Number of Units:
512
MOUNT POINT:
/usr/maestro
Mount AUTOMATICALLY at system restart?:no
Start Disk Accounting: no
Note When creating a file system that will be put under control of HACMP, do not set the attribute of Mount AUTOMATICALLY at system restart to YES. HACMP will mount the file system after cluster start.
Figure 3-13 shows our selections.
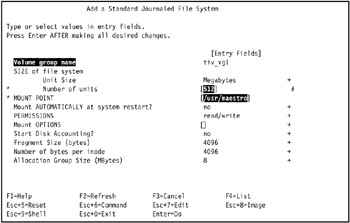
Figure 3-13: Defining a journaled file system -
Mount the file system using the following command:
# mount /usr/maestro
-
Using the following command, verify that the filesystem is successfully added and mounted:
# lsvg -l tiv_vg1
Example 3-1 on page 96 shows a sample of the command output.
Example 3-2: lsvg -l tiv_vg1 output
tiv_vg1: LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT loglv00 jfslog 1 1 1 open/syncd N/A lv06 jfs 1 1 1 open/syncd /usr/maestro
-
Unmount the file system using the following command:
# umount /usr/maestro
Renaming logical volumes
Before we proceed to configuring network adapters, we need to rename the logical volume name for the file system we created. This is because in an HACMP cluster, all shared logical volumes need to have a unique name.
-
Determine the name of the logical volume and the logical log volume by entering the following command.
# lsvg -l tiv_vg1
Example 3-3 shows the command output. Note that the logical volume name is loglv00, and the file system is lv06.
Example 3-3: lsvg -l tiv_vg1 output
# lsvg -l tiv_vg1 tiv_vg1: LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT loglv00 jfslog 1 1 1 closed/syncd N/A lv06 jfs 1 1 1 closed/syncd /usr/maestro
-
Enter the following command. This will take you to the Change a Logical Volume menu.
# smitty chlv
-
Select Rename a Logical Volume (see Figure 3-14 on page 100).
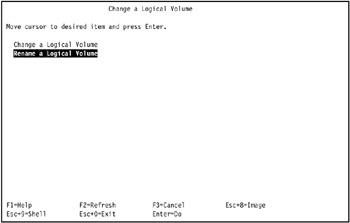
Figure 3-14: Changing a Logical Volume menu -
Select or type the current logical volume name, and enter the new logical volume name. In our example, we use lv06 for the current name, and lvtiv1 for the new name (see Figure 3-15 on page 101).
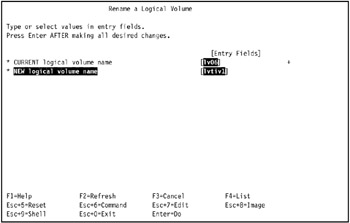
Figure 3-15: Renaming a logical volume -
Perform the steps 1 through 4 for the logical log volume. We specified the name of the current logical log volume name loglv00 and the new logical volume name as lvtiv1_log.
-
Verify that the logical volume name has been changed successfully by entering the following command.
# lsvg -l tiv_vg1
Example 3-4 shows the command output.
Example 3-4: Command output of lsvg
# lsvg -l tiv_vg1 tiv_vg1: LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT lvtws1_log jfslog 1 2 2 open/syncd N/A lvtws1 jfs 512 1024 2 open/syncd /usr/maestro
-
After renaming the logical volume and the logical log volume, check the entry for the file system in the /etc/filesystems file. Make sure the attributes dev and log reflect the change. The value for dev should be the new name for the logical volume, while the value for log should be the name of the jfs log volume. If the log attributes do not reflect the change, issue the following command. (We used /dev/lvtws1_log in our example.)
# chfs -a log=/dev/lvtws1_log /usr/maestro
Example 3-5 shows how the entry for the file system should look in the /etc/filesystems file. Notice that the value for attribute dev is the new logical volume name(/dev/lvtws1), and the value for attribute log is the new logical log volume name (/dev/lvtws1_log).
Example 3-5: An entry in the /etc/filesystems file
/usr/maestro: dev = /dev/lvtws1 vfs = jfs log = /dev/lvtws1_log mount = false options = rw account = false
Importing the volume groups
At this point, you should have a volume group and a file system defined on one node. The next step is to set up the volume group and the file system so that the both nodes are able to access them. We do this by importing the volume groups from the source node to destination node. In our scenario, we import volume group tiv_vg1 to tivaix2.
The following steps describe how to import a volume group from one node to another. In these steps we refer to tivaix1 as the source server, and tivaix2 as the destination server.
-
Log in to the source server.
-
Check the physical volume name and the physical volume ID of the disk in which your volume group reside. In Example 3-6 on page 103, notice that the first column indicates the physical volume name, and the second column indicates the physical volume ID. The third column shows which volume group resides on each physical volume.
Example 3-6: Output of an lspv command
# lspv hdisk0 0001813fe67712b5 rootvg active hdisk1 0001813f1a43a54d rootvg active hdisk2 0001813f95b1b360 rootvg active hdisk3 0001813fc5966b71 rootvg active hdisk4 0001813fc5c48c43 None hdisk5 0001813fc5c48d8c None hdisk6 000900066116088b tiv_vg1 active hdisk7 000000000348a3d6 tiv_vg1 active hdisk8 00000000034d224b None hdisk9 none None hdisk10 none None hdisk11 none None hdisk12 00000000034d7fad None
Check the physical volume ID (shown in the second column) for the physical volumes related to your volume group, as this information is required in the following steps to come.
# lspv
Example 3-6 on page 103 shows example output from tivaix1. You can see that volume group tiv_vg1 resides on hdisk6 and hdisk7.
-
Vary off tiv_vg1 from the source node:
# varyoffvg tiv_vg1
-
Log into the destination node as root.
-
Check the physical volume name and ID on the destination node. Look for the same physical volume ID that you identified in step 2.).
Example 3-7 shows output of the lspv command run on node tivaix2. Note that hdisk5 has the same physical volume id as hdisk6 on tivaix1, and hdisk6 has the same physical volume ID as hdisk7 on tivaix1.
Example 3-7: Output of lspv on node tivaix2
# lspv hdisk0 0001814f62b2a74b rootvg active hdisk1 none None hdisk2 none None hdisk3 none None hdisk4 none None hdisk5 000900066116088b None hdisk6 000000000348a3d6 None1 hdisk7 00000000034d224b tiv_vg2 active hdisk16 0001814fe8d10853 None hdisk17 none None hdisk18 none None hdisk19 none None hdisk20 00000000034d7fad tiv_vg2 active
# lspv
Importing volume groups
To import a volume group, enter the following command. This will take you to the Import a Volume Group screen.
# smitty importvg
-
Specify the following values.
VOLUME GROUP name: tiv_vg1
PHYSICAL VOLUME name:hdisk5
Volume Group MAJOR NUMBER: 45
Note The physical volume name has to be the one with the same physical disk id that the importing volume group resides on. Also, note that the value for Volume Group MAJOR NUMBER should be the same value as specified when creating the volume group.
Our selections are shown in Figure 3-16 on page 105.
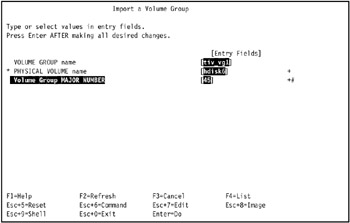
Figure 3-16: Import a Volume Group -
Use the following command to verify that the volume group is imported on the destination node.
# lsvg -o
-
Example 3-8 shows the command output on the destination node. Note that tiv_vg1 is now varied on to tivaix2 and is available.
Example 3-8: lsvg -o output
# lsvg -o tiv_vg1 rootvg
Note By default, the imported volume group is set to be varied on automatically at system restart. In an HACMP cluster, the HACMP software varies on the volume group. We need to change the property of the volume group so that it will not be automatically varied on at system restart.
-
-
Enter the following command.
# smitty chvg
-
Select the volume group imported in the previous step. In our example, we use tiv_vg1 (Figure 3-17).
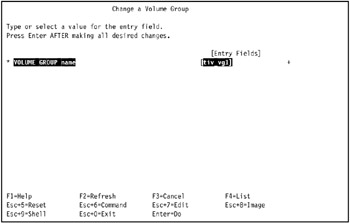
Figure 3-17: Changing a Volume Group screen -
Specify the following, as seen in Figure 3-18 on page 107.
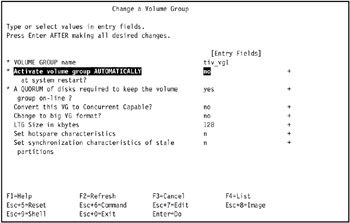
Figure 3-18: Changing the properties of a volume groupActivate volume group AUTOMATICALLY at system restart:
no
| Note | At this point, you should now have shared resources defined on one of the nodes. Perform steps "Defining the file systems" through "Testing volume group migrations" to define another set of shared resources that reside on the other node. |
Testing volume group migrations
You should manually test the migration of volume groups between cluster nodes before installing HACMP, to ensure each cluster node can use every volume group.
To test volume group migrations in our environment:
-
Log on to tivaix1 as root user.
-
Ensure all volume groups are available. Run the command lsvg. You should see local volume group(s) like rootvg, and all shared volume groups. In our environment, we see the shared volume groups tiv_vg1 and tiv_vg2 from the SSA disk subsystem, as shown in Example 3-9 on page 108.
Example 3-9: Verifying all shared volume groups are available on a cluster node
[root@tivaix1:/home/root] lsvg rootvg tiv_vg1 tiv_vg2
-
While all shared volume groups are available, they should not be online. Use the following command to verify that no shared volume groups are online:
lsvg -o
In our environment, the output from the command, as shown in Example 3-10, indicates only the local volume group rootvg is online.
Example 3-10: Verifying no shared volume groups are online on a cluster node
[root@tivaix1:/home/root] lsvg -o rootvg
If you do see shared volume groups listed, vary them offline by running the command:
varyoffvg volume_group_name
where volume_group_name is the name of the volume group.
-
Vary on all available shared volume groups. Run the command:
varyonvg volume_group_name
where volume_group_name is the name of the volume group, for each shared volume group.
Example 3-11 shows how we varied on all shared volume groups.
Example 3-11: How to vary on all shared volume groups on a cluster node
[root@tivaix1:/home/root] varyonvg tiv_vg1 [root@tivaix1:/home/root] lsvg -o tiv_vg1 rootvg [root@tivaix1:/home/root] varyonvg tiv_vg2 [root@tivaix1:/home/root] lsvg -o tiv_vg2 tiv_vg1 rootvg
Note how we used the lsvg command to verify at each step that the vary on operation succeeded.
-
Determine the corresponding logical volume(s) for each shared volume group varied on.
Use the following command to list the logical volume(s) of each volume group:
lsvg -l volume_group_name
where volume_group_name is the name of a shared volume group. As shown in Example 3-12, in our environment shared volume group tiv_vg1 has two logical volumes, lvtws1_log and lvtws1, and shared volume group tiv_vg2 has logical volumes lvtws2_log and lvtws2.
Example 3-12: Logical volumes in each shared volume group varied on in a cluster node
[root@tivaix1:/home/root] lsvg -l tiv_vg1 tiv_vg1: LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT lvtws1_log jfslog 1 2 2 closed/syncd N/A lvtws1 jfs 512 1024 2 closed/syncd /usr/maestro [root@tivaix1:/home/root] lsvg -l tiv_vg2 tiv_vg2: LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT lvtws2_log jfslog 1 2 2 closed/syncd N/A lvtws2 jfs 128 256 2 closed/syncd /usr/maestro2
-
Mount the corresponding JFS logical volume(s) for each shared volume group. Use the mount command to mount each JFS logical volume to its defined mount point. Example 3-13 shows how we mounted the JFS logical volumes in our environment.
Example 3-13: Mounts of logical volumes on shared volume groups on a cluster node
[root@tivaix1:/home/root] df /usr/maestro Filesystem 1024-blocks Free %Used Iused %Iused Mounted on /dev/hd2 2523136 148832 95% 51330 9% /usr [root@tivaix1:/home/root] mount /usr/maestro [root@tivaix1:/home/root] df /usr/maestro Filesystem 1024-blocks Free %Used Iused %Iused Mounted on /dev/lvtws1 2097152 1871112 11% 1439 1% /usr/maestro [root@tivaix1:/home/root] df /usr/maestro2 Filesystem 1024-blocks Free %Used Iused %Iused Mounted on /dev/hd2 2523136 148832 95% 51330 9% /usr [root@tivaix1:/home/root] mount /usr/maestro2 [root@tivaix1:/home/root] df /usr/maestro2 Filesystem 1024-blocks Free %Used Iused %Iused Mounted on /dev/lvtws1 524288 350484 34% 1437 2% /usr/maestro2
Note how we use the df command to verify that the mount point before the mount command is in one file system, and after the mount command is attached to a different filesystem. The different file systems before and after the mount commands are highlighted in bold in Example 3-13.
-
Unmount each logical volume on each shared volume group. Example 3-14 shows how we unmount all logical volumes from all shared volume groups.
Example 3-14: Unmount logical volumes on shared volume groups on a cluster node
[root@tivaix1:/home/root] umount /usr/maestro [root@tivaix1:/home/root] df /usr/maestro Filesystem 1024-blocks Free %Used Iused %Iused Mounted on /dev/hd2 2523136 148832 95% 51330 9% /usr [root@tivaix1:/home/root] umount /usr/maestro2 [root@tivaix1:/home/root] df /usr/maestro2 Filesystem 1024-blocks Free %Used Iused %Iused Mounted on /dev/hd2 2523136 148832 95% 51330 9% /usr
Again, note how we use the df command to verify a logical volume is unmounted from a shared volume group.
-
Vary off each shared volume group on the cluster node. Use the following command to vary off a shared volume group:
varyoffvg volume_group_name
where volume_group_name is the name of the volume group, for each shared volume group. The following example shows how we vary off the shared volume groups tiv_vg1 and tiv_vg2:
Example 3-15: How to vary off shared volume groups on a cluster node
[root@tivaix1:/home/root] varyoffvg tiv_vg1 [root@tivaix1:/home/root] lsvg -o tiv_vg2 rootvg [root@tivaix1:/home/root] varyoffvg tiv_vg2 [root@tivaix1:/home/root] lsvg -o rootvg
Note how we use the lsvg command to verify that a shared volume group is varied off.
-
-
Repeat this procedure for the remaining cluster nodes. You must test that all volume groups and logical volumes can be accessed through the appropriate varyonvg and mount commands on each cluster node.
You now know that if volume groups fail to migrate between cluster nodes after installing HACMP, then there is likely a problem with HACMP and not with the configuration of the volume groups themselves on the cluster nodes.
Configure Network Adapters
Network Adapters should be configured prior to installing HACMP.
| Important: | When configuring Network Adapters, bind only the boot IP address to each network adapter. No configuration for service IP address and persistent IP address is needed at this point. Do not bind a service or persistent IP address to any adapters. A service and persistent IP address is configured after HACMP is installed. |
-
Log in as root on the cluster node.
-
Enter the following command. This command will take you to the SMIT TCP/IP menu.
# smitty tcpip
-
From the TCP/IP menu, select Minimum Configuration & Startup (Figure 3-19 on page 112). You are prompted to select a network interface from the Available Network Interface list. Select the network interface you want to configure.
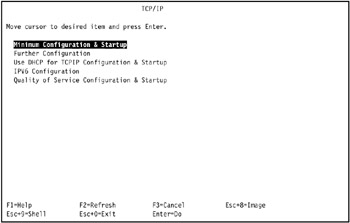
Figure 3-19: The TCP/IP SMIT menu -
For the network interface you have selected, specify the following items and press Enter. Figure 3-20 on page 113 shows the configuration for our cluster.
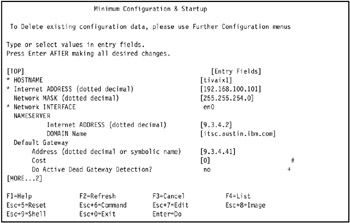
Figure 3-20: Configuring network adaptersHOSTNAME
Hostname for the node.
Internet ADDRESS
Enter the IP address for the adapter. This must be the boot address that you planned for the adapter.
Network MASK
Enter the network mask.
NAME SERVER
Enter the IP address and the domain name of your name server.
Default Gateway
Enter the IP address of the default Gateway.
-
Repeat steps 1 through 4 for all network adapters in the cluster.
| Attention: | To implement an HA cluster for IBM Tivoli Workload Scheduler, install IBM Tivoli Workload Scheduler before proceeding to 3.2.4, "Installing HACMP 5.1 on AIX 5.2" on page 92. For instructions on installing IBM Tivoli Workload Scheduler in an HA cluster environment, refer to 4.1, "Implementing IBM Tivoli Workload Scheduler in an HACMP cluster" on page 184. |
Install HACMP
The best results when installing HACMP are obtained if you plan the procedure before attempting it. We recommend that you read through the following installation procedures before undertaking them.
If you make a mistake, uninstall HACMP; refer to "Remove HACMP" on page 134.
| Tip | Install HACMP after all application servers are installed, configured, and verified operational. This simplifies troubleshooting because if the application server does not run after HACMP is installed, you know that addressing an HACMP issue will fix the error. You will not have to spend time identifying whether the problem is with your application or HACMP. |
The major steps to install HACMP are covered in the following sections:
-
"Preparation" on page 114
-
"Install base HACMP 5.1" on page 122
-
"Update HACMP 5.1" on page 126
-
(Optional, use only if installation or configuration fails) "Remove HACMP" on page 134
The details of each step follow.
Preparation
By now you should have all the requirements fulfilled and all the preparation completed. In this section, we provide a step-by-step description of how to install HACMP Version 5.1 on AIX Version 5.2. Installation procedures may differ depending on which version of HACMP software you use. For versions other than 5.1, refer to the installation guide for the HACMP version that you install.
Ensure that you are running AIX 5.2 Maintenance Level 02. To verify your current level of AIX, run the oslevel and lslpp commands, as shown in Example 3-16.
Example 3-16: Verifying the currently installed maintenance level of AIX 5.2
[root@tivaix1:/home/root] oslevel -r 5200-02 [root@tivaix1:/home/root] lslpp -l bos.rte.commands Fileset Level State Description ---------------------------------------------------------------------------- Path: /usr/lib/objrepos bos.rte.commands 5.2.0.12 COMMITTED Commands Path: /etc/objrepos bos.rte.commands 5.2.0.0 COMMITTED Commands
If you need to upgrade your version of AIX 5.2, visit the IBM Fix Central Web site:
-
http://www-912.ibm.com/eserver/support/fixes/fcgui.jsp
Be sure to upgrade from AIX 5.2.0.0 to Maintenance Level 01 first, then to Maintenance Level 02.
Figure 3-21 shows the IBM Fix Central Web page, and the settings you use to select the Web page with AIX 5.2 maintenance packages. (We show the entire Web page in Figure 3-21, but following figures omit the banners in the left-hand, upper, and bottom portions of the page.)
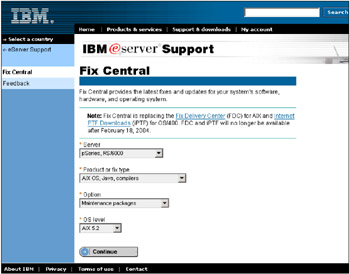
Figure 3-21: IBM Fix Central Web page for downloading AIX 5.2 maintenance packages
At the time of writing, Maintenance Level 02 is the latest available. We recommend that if you are currently running AIX Version 5.2, you upgrade to Maintenance Level 02.
Maintenance Level 01 can be downloaded from:
-
https://techsupport.services.ibm.com/server/mlfixes/52/01/00to01.html
Maintenance Level 02 can be downloaded from:
-
https://techsupport.services.ibm.com/server/mlfixes/52/02/01to02.html
| Note | Check the IBM Fix Central Web site before applying any maintenance packages. |
After you ensure the AIX prerequisites are satisfied, you may prepare HACMP 5.1 installation media. To prepare HACMP 5.1 installation media on a cluster node, follow these steps:
-
Copy the HACMP 5.1 media to the hard disk on the node. We used /tmp/hacmp on our nodes to hold the HACMP 5.1 media.
-
Copy the latest fixes for HACMP 5.1 to the hard disk on the node. We used /tmp/hacmp on our nodes to hold the HACMP 5.1 fixes.
-
If you do not have the latest fixes for HACMP 5.1, download them from the IBM Fix Central Web site:
http://www-912.ibm.com/eserver/support/fixes/fcgui.jsp
-
From this Web page, select pSeries, RS/6000 for the Server pop-up, AIX OS, Java™, compilers for the Product or fix type pop-up, Specific fixes for the Option pop-up, and AIX 5.2 for the OS level pop-up, then press Continue, as shown in Figure 3-22 on page 117.
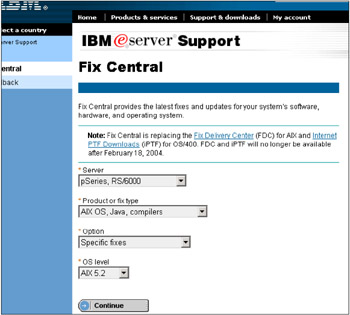
Figure 3-22: Using the IBM Fix Central Web page for downloading HACMP 5.1 patches -
The Select fixes Web page is displayed, as shown in Figure 3-23 on page 118.
Figure 3-23: Select fixes page of IBM Fix Central Web siteWe use this page to search for and download the fixes for APAR IY45695 and also the following PTF numbers:
U496114, U496115, U496116, U496117, U496118, U496119, U496120, U496121, U496122, U496123, U496124, U496125, U496126, U496127, U496128, U496129, U496130, U496138, U496274, U496275
We used /tmp/hacmp_fixes1 for storing the fix downloads of APAR IY45695, and /tmp/hacmp_fixes2 for storing the fix downloads of the individual PTFs.
-
To download the fixes for APAR IY45695, select APAR number or abstract for the Search by pop-up, enter IY45695 in the Search string field, and press Go. A browser dialog as shown in Figure 3-24 may appear, depending upon previous actions within IBM Fix Central. If it does appear, press OK to continue (Figure 3-24).
Figure 3-24: Confirmation dialog presented in IBM Fix Central Select fixes page -
The Select fixes page displays the fixes found, as shown in Figure 3-25 on page 119.
Figure 3-25: Select fixes page showing fixes found that match APAR IY45695 -
Highlight the APAR in the list box, then press the Add to my download list link. Press Continue, which displays the Packaging options page.
-
Select AIX 5200-01 for the Indicate your current maintenance level pop-up. At the time of writing, the only available download servers are in North America, so selecting a download server is an optional step. Select a download server if a more appropriate server is available in the pop-up. Now press Continue, as shown in Figure 3-26 on page 120.
Figure 3-26: Packaging options page for packaging fixes for APAR IY45695 -
The Download fixes page is displayed as shown in Figure 3-27 on page 121. Choose an appropriate option from the Download and delivery options section of the page, then follow the instructions given to download the fixes.

Figure 3-27: Download fixes page for fixes related to APAR IY45695 -
Downloading fixes for PTFs follows the same procedure as for downloading the fixes for APAR IY45695, except you select Fileset or PTF number in the Search by pop-up in the Select fixes Web page.
-
Copy the installation media to each cluster node or make it available via a remote filesystem like NFS, AFS®, or DFS™.
Install base HACMP 5.1
After the installation media is prepared on a cluster node, install the base HACMP 5.1 Licensed Program Products (LPPs):
-
Enter the command smitty install to start installing the software. The Software Installation and Maintenance SMIT panel is displayed as in Figure 3-28.

Figure 3-28: Screen displayed after running command smitty install -
Go to Install and Update Software > Install Software and press Enter. This brings up the Install Software SMIT panel (Figure 3-29 on page 123).
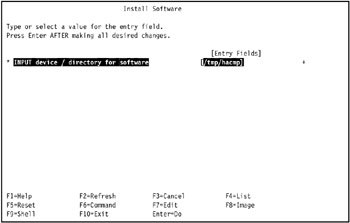
Figure 3-29: Filling out the INPUT device/directory for software field in the Install Software smit panel -
Enter the directory that the HACMP 5.1 software is stored under into the INPUT device / directory for software field and press Enter, as shown in Figure 3-29.
In our environment we entered the directory /tmp/hacmp into the field and pressed Enter.
This displays the Install Software SMIT panel with all the installation options (Figure 3-30 on page 124).
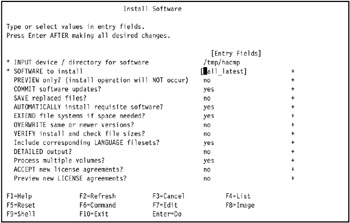
Figure 3-30: Install Software SMIT panel with all installation options -
Press Enter to install all HACMP 5.1 Licensed Program Products (LPPs) in the selected directory.
-
SMIT displays an installation confirmation dialog as shown in Figure 3-31 on page 125. Press Enter to continue. The COMMAND STATUS SMIT panel is displayed.
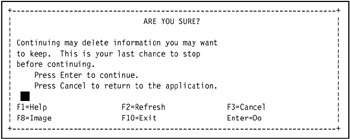
Figure 3-31: Installation confirmation dialog for SMITThroughout the rest of this redbook, if a SMIT confirmation dialog is displayed it is assumed you will know how to respond to it, so we do not show this step again.
-
The COMMAND STATUS SMIT panel displays the progress of the installation. Installation will take several minutes, depending upon the speed of your machine. When the installation completes, the panel looks similar to Figure 3-32.
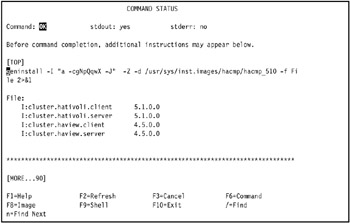
Figure 3-32: COMMAND STATUS SMIT panel showing successful installation of HACMP 5.1
Update HACMP 5.1
After installing the base HACMP 5.1 Licensed Program Products (LPPs), you must upgrade it to the latest fixes available. To update HACMP 5.1:
-
Enter the command smitty update to start updating HACMP 5.1. The Update Software by Fix (APAR) SMIT panel is displayed as shown in Figure 3-33.
Figure 3-33: Update Software by Fix (APAR) SMIT panel displayed by running command smitty update -
Enter in the INPUT device / directory for software field the directory that you used to store the fixes for APAR IY45695, then press Enter.
We used /tmp/hacmp_fixes1 in our environment, as shown in Figure 3-35 on page 128.
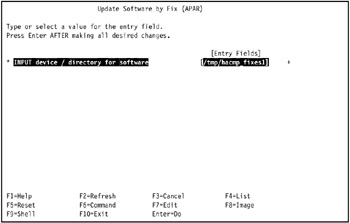
Figure 3-34: Entering directory of APAR IY45695 fixes into Update Software by Fix (APAR) SMIT panel -
The Update Software by Fix (APAR) SMIT panel is displayed with all the update options. Move the cursor to the FIXES to install item as shown in Figure 3-35 on page 128, and press F4 (or Esc 4) to select the HACMP fixes to update.
Figure 3-35: Preparing to select fixes for APAR IY45695 in Update Software by Fix (APAR) SMIT panel -
The FIXES to install SMIT dialog is displayed as in Figure 3-36 on page 129. This lists all the fixes for APAR IY45695 that can be applied.
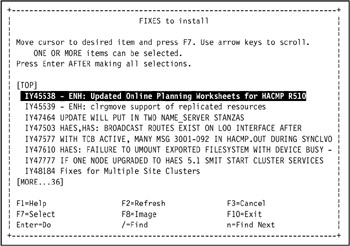
Figure 3-36: Selecting fixes for APAR IY45695 in FIXES to install SMIT dialog -
Select all fixes in the dialog by pressing F7 (or Esc 7) on each line so that a selection symbol (>) is added in front of each line as shown in Figure 3-37 on page 130.
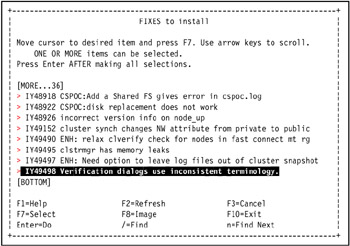
Figure 3-37: Selecting all fixes of APAR IY45695 in FIXES to install SMIT dialogPress Enter after all fixes are selected.
-
The Update Software by Fix (APAR) SMIT panel is displayed again (Figure 3-38 on page 131), showing all the selected fixes from the FIXES to install SMIT dialog in the FIXES to install field.
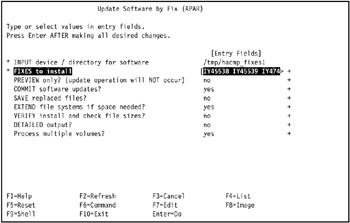
Figure 3-38: Applying all fixes of APAR IY45695 in Update Software by Fix (APAR) SMIT panelPress Enter to begin applying all fixes of APAR IY45695.
-
The COMMAND STATUS SMIT panel is displayed. It shows the progress of the selected fixes for APAR IY45695 applied to the system. A successful update will appear similar to Figure 3-39 on page 132.
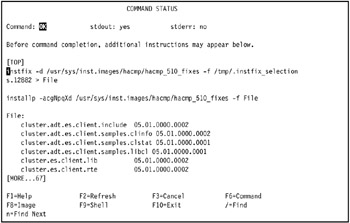
Figure 3-39: COMMAND STATUS SMIT panel showing all fixes of APAR IY45695 successfully applied -
Confirm that the fixes were installed by first exiting SMIT. Press F10 (or Esc 0) to exit SMIT. Then enter the following command:
lslpp -l "cluster.*"
The output should be similar to that shown in Example 3-17. Note that some of the Licensed Program Products (LPPs) show a version other than the 5.1.0.0 base version of HACMP. This confirms that the fixes were successfully installed.
Example 3-17: Confirming installation of fixes for APAR IY45695
[root@tivaix1:/home/root]lslpp -l "cluster.*" Fileset Level State Description ---------------------------------------------------------------------------- Path: /usr/lib/objrepos cluster.adt.es.client.demos 5.1.0.0 COMMITTED ES Client Demos cluster.adt.es.client.include 5.1.0.2 COMMITTED ES Client Include Files cluster.adt.es.client.samples.clinfo 5.1.0.2 COMMITTED ES Client CLINFO Samples cluster.adt.es.client.samples.clstat 5.1.0.1 COMMITTED ES Client Clstat Samples cluster.adt.es.client.samples.demos 5.1.0.0 COMMITTED ES Client Demos Samples cluster.adt.es.client.samples.libcl 5.1.0.1 COMMITTED ES Client LIBCL Samples cluster.adt.es.java.demo.monitor 5.1.0.0 COMMITTED ES Web Based Monitor Demo cluster.adt.es.server.demos 5.1.0.0 COMMITTED ES Server Demos cluster.adt.es.server.samples.demos 5.1.0.1 COMMITTED ES Server Sample Demos cluster.adt.es.server.samples.images 5.1.0.0 COMMITTED ES Server Sample Images cluster.doc.en_US.es.html 5.1.0.1 COMMITTED HAES Web-based HTML Documentation - U.S. English cluster.doc.en_US.es.pdf 5.1.0.1 COMMITTED HAES PDF Documentation - U.S. English cluster.es.cfs.rte 5.1.0.1 COMMITTED ES Cluster File System Support cluster.es.client.lib 5.1.0.2 COMMITTED ES Client Libraries cluster.es.client.rte 5.1.0.2 COMMITTED ES Client Runtime cluster.es.client.utils 5.1.0.2 COMMITTED ES Client Utilities cluster.es.clvm.rte 5.1.0.0 COMMITTED ES for AIX Concurrent Access cluster.es.cspoc.cmds 5.1.0.2 COMMITTED ES CSPOC Commands cluster.es.cspoc.dsh 5.1.0.0 COMMITTED ES CSPOC dsh cluster.es.cspoc.rte 5.1.0.2 COMMITTED ES CSPOC Runtime Commands cluster.es.plugins.dhcp 5.1.0.1 COMMITTED ES Plugins - dhcp cluster.es.plugins.dns 5.1.0.1 COMMITTED ES Plugins - Name Server cluster.es.plugins.printserver 5.1.0.1 COMMITTED ES Plugins - Print Server cluster.es.server.diag 5.1.0.2 COMMITTED ES Server Diags cluster.es.server.events 5.1.0.2 COMMITTED ES Server Events cluster.es.server.rte 5.1.0.2 COMMITTED ES Base Server Runtime cluster.es.server.utils 5.1.0.2 COMMITTED ES Server Utilities cluster.es.worksheets 5.1.0.2 COMMITTED Online Planning Worksheets cluster.license 5.1.0.0 COMMITTED HACMP Electronic License cluster.msg.en_US.cspoc 5.1.0.0 COMMITTED HACMP CSPOC Messages - U.S. English cluster.msg.en_US.es.client 5.1.0.0 COMMITTED ES Client Messages - U.S. English cluster.msg.en_US.es.server 5.1.0.0 COMMITTED ES Recovery Driver Messages - U.S. English Path: /etc/objrepos cluster.es.client.rte 5.1.0.0 COMMITTED ES Client Runtime cluster.es.clvm.rte 5.1.0.0 COMMITTED ES for AIX Concurrent Access cluster.es.server.diag 5.1.0.0 COMMITTED ES Server Diags cluster.es.server.events 5.1.0.0 COMMITTED ES Server Events cluster.es.server.rte 5.1.0.2 COMMITTED ES Base Server Runtime cluster.es.server.utils 5.1.0.0 COMMITTED ES Server Utilities Path: /usr/share/lib/objrepos cluster.man.en_US.es.data 5.1.0.2 COMMITTED ES Man Pages - U.S. English
-
Repeat this procedure for each node in the cluster to install the LPPs for APAR IY45695.
-
Repeat this entire procedure for all the fixes corresponding to the preceding PTFs. Enter the directory path these fixes are stored in into the INPUT device / directory for software field referred to by step 2. We used /tmp/hacmp_fixes2 in our environment.
Remove HACMP
If you make a mistake with the HACMP installation, or if subsequent configuration fails due to Object Data Manager (ODM) errors or another error that prevents successful configuration, you can remove HACMP to recover to a known state.
Removing resets all ODM entries, and removes all HACMP files. Re-installing will create new ODM entries, and often solve problems with corrupted HACMP ODM entries.
To remove HACMP:
-
Enter the command smitty remove.
-
The Remove Installed Software SMIT panel is displayed. Enter the following text in the SOFTWARE name field: cluster.*, as shown in Figure 3-40 on page 135.
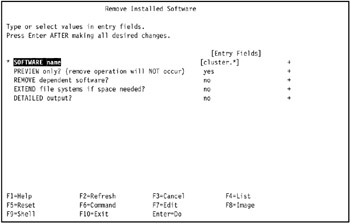
Figure 3-40: How to specify removal of HACMP in Remove Installed Software SMIT panel -
Move the cursor to the PREVIEW only? (remove operation will NOT occur) field and press Tab to change the value to no, change the EXTEND file systems if space needed? field to yes, and change the DETAILED output field to yes, as shown in Figure 3-41 on page 136.
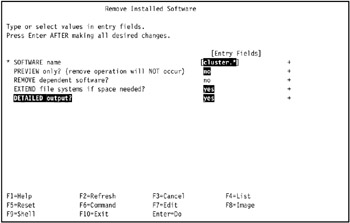
Figure 3-41: Set options for removal of HACMP in Installed Software SMIT panel -
Press Enter to start removal of HACMP. The COMMAND STATUS SMIT panel displays the progress and final status of the removal operation. A successful removal looks similar to Figure 3-42 on page 137.
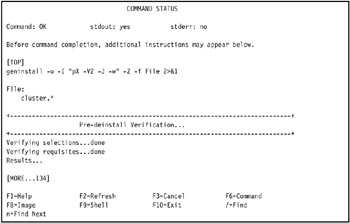
Figure 3-42: Successful removal of HACMP as shown by COMMAND STATUS SMIT panel -
Press F10 (or Esc 0) to exit SMIT.
When you finish the installation of HACMP, you need to configure it for the application servers you want to make highly available.
In this redbook, we show how to do this with IBM Tivoli Workload Scheduler first in 4.1.10, "Configure HACMP for IBM Tivoli Workload Scheduler" on page 210, then IBM Tivoli Management Framework in 4.1.11, "Add IBM Tivoli Management Framework" on page 303.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 92