The SELECT Statement and Its Clauses
The SELECT Statement and Its ClausesWe just saw that, if you wanted to retrieve all values stored in a base table, you could do so by executing a SELECT statement that looks something like this: SELECT * FROM [ TableName ] But what if you only wanted to see the values stored in two columns of a table? Or what if you wanted the data retrieved to be ordered alphabetically in ascending order (data is stored in a table in no particular order, and unless otherwise specified, a query only returns data in the order in which it is found)? How do you construct a query using a SELECT SQL statement that only retrieves certain data values and returns those values in a very specific format? You do so by using a more advanced form of the SELECT SQL statement to construct your query. The syntax used to construct more advanced forms of the SELECT SQL statement is: SELECT <DISTINCT> [* [ Expression ] <<AS> [ NewColumnName ]> ,...] FROM [[ TableName ] [ ViewName ] <<AS> [ CorrelationName ]> ,...] < WhereClause > < GroupByClause > < HavingClause > < OrderByClause > < FetchFirstClause > where:
If the DISTINCT clause is specified with the SELECT statement, duplicate rows are removed from the final result data set returned. (Two rows are only considered to be duplicates of one another if each value in the first row is identical to the corresponding value of the second row. For the purpose of determining whether or not two rows are identical, null values are considered equal.) However, if the DISTINCT clause is used, the result data set produced must not contain columns that hold LONG VARCHAR, LONG VARGRAPHIC, DATALINK, BLOB, CLOB, or DBCLOB data. So if you wanted to retrieve all values for the columns named WORKDEPT and JOB from a table named EMPLOYEES , you could do so by executing a SELECT statement that looks something like this: SELECT WORKDEPT, JOB FROM EMPLOYEES And when this SELECT statement is executed, you might see a result data set that looks something like this: WORKDEPT JOB -------- -------- A00 PRES B01 MANAGER C01 MANAGER E01 MANAGER D11 MANAGER D21 MANAGER E11 MANAGER E21 MANAGER A00 SALESREP A00 CLERK C01 ANALYST C01 ANALYST D11 DESIGNER D11 DESIGNER D11 DESIGNER D11 DESIGNER D11 DESIGNER D11 DESIGNER D11 DESIGNER D11 DESIGNER D21 CLERK D21 CLERK D21 CLERK D21 CLERK D21 CLERK E11 OPERATOR E11 OPERATOR E11 OPERATOR E11 OPERATOR E21 FIELDREP E21 FIELDREP E21 FIELDREP 32 record(s) selected. On the other hand, if you wanted to retrieve the same data values, but remove all duplicate records found, you could do so by executing the same SELECT statement using the DISTINCT clause. The resulting SELECT statement would look something like this: SELECT DISTINCT WORKDEPT, JOB FROM EMPLOYEES This time, when the SELECT statement is executed you should see a result data set that looks something like this: WORKDEPT JOB -------- -------- C01 ANALYST A00 CLERK D21 CLERK D11 DESIGNER E21 FIELDREP B01 MANAGER C01 MANAGER D11 MANAGER D21 MANAGER E01 MANAGER E11 MANAGER E21 MANAGER E11 OPERATOR A00 PRES A00 SALESREP 15 record(s) selected. Now suppose you wanted to retrieve all unique values (no duplicates) for the column named JOB from a table named EMPLOYEES, and you wanted to change the name of the JOB column in the result data set produced to TITLES. You could do so by executing a SELECT statement that looks something like this: SELECT DISTINCT JOB AS TITLE FROM EMPLOYEES When this SELECT statement is executed, you should see a result set that looks something like this: TITLE -------- ANALYST CLERK DESIGNER FIELDREP MANAGER OPERATOR PRES SALESREP 8 record(s) selected. You could also produce the same result data set by executing the same SELECT SQL statement, using the correlation name "EMP" for the table named EMPLOYEES. The only difference is that, the SELECT statement would look something like this: SELECT DISTINCT EMP.JOB AS TITLE FROM EMPLOYEES AS EMP Notice that the column named JOB is qualified with the same correlation name assigned to the table named EMPLOYEES. For this example, this is not really necessary, since data is only being retrieved from one table and no two columns in a table can have the same name. However, if data was being retrieved from two or more tables and if columns in different tables had the same name, the qualifier would be needed to tell the DB2 Database Manager which table to retrieve data for that particular column from. If you were counting when we examined the syntax for the SELECT statement earlier, you may have noticed that a single SELECT statement can contain up to seven different clauses. These clauses are:
(Incidentally, these clauses are processed in the order shown.) We have already seen how the DISTINCT clause and the FROM clause are used, in the previous SELECT statement examples provided. Now let's turn our attention to the other clauses the SELECT statement recognizes. The WHERE ClauseThe WHERE clause is used to tell the DB2 Database Manager how to select the rows that are to be returned in the result data set produced in response to a query. When specified, the WHERE clause is followed by a search condition which is essentially a simple test that, when applied to a row of data, will evaluate to TRUE, FALSE, or Unknown. If this test evaluates to TRUE, the row is to be returned in the result data set produced; if the test evaluates to FALSE or Unknown, the row is skipped . The search condition of a WHERE clause is made up of one or more predicates that are used to compare the contents of a column with a constant value, the contents of a column with the contents of another column from the same table, or the contents of a column in one table with the contents of a column from another table (just to name a few). DB2 UDB recognizes six common types of WHERE clause predicates. They are:
Each of these predicates can be used alone, or one or more can be combined by using parentheses or Boolean operators such as AND, OR, and NOT. Relational predicatesThe relational predicates (or comparison operators ) consist of a set of special operators used to define a comparison relationship between the contents of a column and a constant value, the contents of two columns from the same table, or the contents of a column in one table with the contents of a column from another table. The following comparison operators are available:
Typically, relational predicates are used to include or exclude specific rows from the final result data set produced in response to a query. Thus, if you wanted to retrieve values for the columns named EMPNO and SALARY in a table named EMPLOYEES where the value for the SALARY column is greater than or equal to $40,000.00, you could do so by executing a SELECT statement that looks something like this: SELECT EMPNO, SALARY FROM EMPLOYEES WHERE SALARY >= 40000.00 When this SELECT statement is executed, you might see a result data set that looks something like this: EMPNO SALARY ------ ----------- 000010 52750.00 000020 41250.00 000050 40175.00 000110 46500.00 4 record(s) selected. It is important to note that the data types of all items involved in a relational predicate comparison must be compatible or the comparison will fail. If necessary, scalar functions can be used (to make the necessary conversions) in conjunction with the relational predicate to meet this requirement. The BETWEEN predicateThe BETWEEN predicate is used to define a comparison relationship in which contents of a column are checked to see whether or not they fall within a range of values. As with relational predicates, the BETWEEN predicate is used to include or exclude specific rows from the result data set produced in response to a query. So, if you wanted to retrieve values for the columns named EMPNO and SALARY in a table named EMPLOYEES where the value for the SALARY column is greater than or equal to $10,000.00 and less than or equal to $20,000.00, you could do so by executing a SELECT statement that looks something like this: SELECT EMPNO, SALARY FROM EMPLOYEES WHERE SALARY BETWEEN 10000.00 AND 20000.00 When this SELECT statement is executed, you might see a result data set that looks something like this: EMPNO SALARY ------ ----------- 000210 18270.00 000250 19180.00 000260 17250.00 000290 15340.00 000300 17750.00 000310 15900.00 000320 19950.00 7 record(s) selected. If the NOT (negation) operator is used in conjunction with the BETWEEN predicate (or with any other predicate, for that matter), the meaning of the predicate is reversed . (In the case of the BETWEEN predicate, contents of a column are checked, and only values that fall outside the range of values specified are returned to the final result data set produced.) Thus, if you wanted to retrieve values for the columns named EMPNO and SALARY in a table named EMPLOYEES where the value for the SALARY column is less than $10,000.00 and more than $30,000.00, you could do so by executing a SELECT statement that looks something like this: SELECT EMPNO, SALARY FROM EMPLOYEES WHERE SALARY NOT BETWEEN 10000.00 AND 30000.00 When this SELECT statement is executed, you might see a result data set that looks something like this: EMPNO SALARY ------ ----------- 000010 52750.00 000020 41250.00 000030 38250.00 000050 40175.00 000060 32250.00 000070 36170.00 000110 46500.00 7 record(s) selected. The LIKE predicateThe LIKE predicate is used to define a comparison relationship in which a character value is checked to see whether or not it contains a specific pattern of characters. The pattern of characters specified can consist of regular alphanumeric characters and/or special metacharacters that DB2 UDB recognizes, which are interpreted as follows :
Thus, if you wanted to retrieve values for the columns named EMPNO and LASTNAME in a table named EMPLOYEES where the value for the LASTNAME column begins with the letter "S", you could do so by executing a SELECT statement that looks something like this: SELECT EMPNO, LASTNAME FROM EMPLOYEES WHERE LASTNAME LIKE 'S%' And when this SELECT statement is executed, you might see a result data set that looks something like this: EMPNO LASTNAME ------ --------------- 000060 STERN 000100 SPENSER 000180 SCOUTTEN 000250 SMITH 000280 SCHNEIDER 000300 SMITH 000310 SETRIGHT 7 record(s) selected. When using wild card characters, care must be taken to ensure that they are placed in the appropriate location in the pattern string specified. Note that in the previous example, only records for employees whose last name begins with the letter "S" are returned. If the character string pattern specified had been "%S%", records for employees whose last name contains the character "S" ( anywhere in the name) would have been returned and the result data set produced might have looked something like this instead: EMPNO LASTNAME ------ --------------- 000010 HAAS 000020 THOMPSON 000060 STERN 000070 PULASKI 000090 HENDERSON 000100 SPENSER 000110 LUCCHESSI 000140 NICHOLLS 000150 ADAMSON 000170 YOSHIMURA 000180 SCOUTTEN 000210 JONES 000230 JEFFERSON 000250 SMITH 000260 JOHNSON 000280 SCHNEIDER 000300 SMITH 000310 SETRIGHT 18 record(s) selected. Likewise, you must also be careful about using uppercase and lowercase characters in pattern strings; if the data being examined is stored in a case-sensitive manner, the characters used in a pattern string must match the case that was used to store the data in the column being searched, or no corresponding records will be found.
The IN predicateThe IN predicate is used to define a comparison relationship in which a value is checked to see whether or not it matches a value in a finite set of values. This finite set of values can consist of one or more literal values that are coded directly in the SELECT statement, or it can be composed of the non-null values found in the result data set generated by a second SELECT statement (otherwise known as a subquery ).
Thus, if you wanted to retrieve values for the columns named EMPNO and WORKDEPT in a table named EMPLOYEES where the value for the WORKDEPT column matches a value in a list of department codes, you could do so by executing a SELECT statement that looks something like this: SELECT LASTNAME, WORKDEPT FROM EMPLOYEES WHERE WORKDEPT IN ('E11', 'E21') When this SELECT statement is executed, you might see a result data set that looks something like this: LASTNAME WORKDEPT --------------- -------- HENDERSON E11 SPENSER E21 SCHNEIDER E11 PARKER E11 SMITH E11 SETRIGHT E11 MEHTA E21 LEE E21 GOUNOT E21 9 record(s) selected. Assuming we don't know that the values 'E11' and 'E21' have been assigned to the departments named "OPERATIONS" and "SOFTWARE SUPPORT" but we do know that department names and numbers are stored in a table named DEPARTMENTS (for normalization) that has two columns named DEPNO and DEPNAME, we could produce the same result data set by executing a SELECT statement that looks like this: SELECT LASTNAME, WORKDEPT FROM EMPLOYEES WHERE WORKDEPT IN (SELECT DEPTNO FROM DEPARTMENTS WHERE DEPTNAME = 'OPERATIONS' OR DEPTNO = 'SOFTWARE SUPPORT') In this case, the subquery SELECT DEPTNO FROM DEPARTMENTS WHERE DEPTNAME = 'OPERATIONS' OR DEPTNO = 'SOFTWARE SUPPORT' produces a result data set that contains the values 'E11' and 'E21', and the main query evaluates each value found in the WORKDEPT column of the EMPLOYEES table to determine whether or not it matches one of the values in the result data set produced by the subquery. The EXISTS predicateThe EXISTS predicate is used to determine whether or not a particular value exists in a given table. The EXISTS predicate is always followed by a subquery, and it returns either TRUE or FALSE to indicate whether a specific value is found in the result data set produced by the subquery. Thus, if you wanted to find out which values found in the column named DEPTNO in a table named DEPARTMENT are used in the column named WORKDEPT found in a table named EMPLOYEES, you could do so by executing a SELECT statement that looks something like this: SELECT DEPTNO, DEPTNAME FROM DEPARTMENT WHERE EXISTS (SELECT WORKDEPT FROM EMPLOYEES WHERE WORKDEPT = DEPTNO) When this SELECT statement is executed, you might see a result data set that looks something like this: DEPTNO DEPTNAME ------ ----------------------------- A00 SPIFFY COMPUTER SERVICE DIV. B01 PLANNING C01 INFORMATION CENTER D11 MANUFACTURING SYSTEMS D21 ADMINISTRATION SYSTEMS E01 SUPPORT SERVICES E11 OPERATIONS E21 SOFTWARE SUPPORT 8 record(s) selected. In most situations, EXISTS predicates are AND-ed with other predicates to determine final row selection. The NULL predicateThe NULL predicate is used to determine whether or not a particular value is a NULL value. Therefore, if you wanted to retrieve values for the columns named FIRSTNAME, MIDINIT, and LASTNAME in a table named EMPLOYEES where the value for the MIDINIT column is a NULL value, you could do so by executing a SELECT statement that looks something like this: SELECT FIRSTNME, MIDINIT, LASTNAME FROM EMPLOYEES WHERE MIDINIT IS NULL When this SELECT statement is executed, you might see a result data set that looks something like this: FIRSTNME MIDINIT LASTNAME ------------ ------- --------------- SEAN - O'CONNELL BRUCE - ADAMSON DAVID - BROWN WING - LEE 4 record(s) selected. When using the NULL predicate, it is important to keep in mind that NULL, zero (0), and blank (" ") are not the same value. NULL is a special marker that is used to represent missing information, while zero and blank (empty string) are actual values that can be stored in a column to indicate a specific value (or lack thereof). Furthermore, some columns accept NULL values, while other columns do not, depending upon their definition. So, before writing SQL statements that check for NULL values, make sure that the NULL value is supported by the column(s) being specified. The GROUP BY ClauseThe GROUP BY clause is used to tell the DB2 Database Manager how to organize the rows of data returned in the result data set produced in response to a query. In its simplest form, the GROUP BY clause is followed by a grouping expression that is usually one or more column names (that correspond to column names found in the result data set to be organized by the GROUP BY clause). The GROUP BY clause is also used to specify what columns are to be grouped together to provide input to aggregate functions such as SUM() and AVG() . Thus, if you wanted to obtain the average salary for all departments found in the column named DEPTNAME in a table named DEPARTMENTS using salary information stored in a table named EMPLOYEES, and you wanted to organize the data retrieved by department, you could do so by executing a SELECT statement that looks something like this: SELECT DEPTNAME, AVG(SALARY) AS AVG_SALARY FROM DEPARTMENT D, EMPLOYEES E WHERE E.WORKDEPT = D.DEPTNO GROUP BY DEPTNAME When this SELECT statement is executed, you might see a result data set that looks something like this: DEPTNAME AVG_SALARY ----------------------------- ----------- ADMINISTRATION SYSTEMS 25153.33 INFORMATION CENTER 30156.66 MANUFACTURING SYSTEMS 24677.77 OPERATIONS 20998.00 PLANNING 41250.00 SOFTWARE SUPPORT 23827.50 SPIFFY COMPUTER SERVICE DIV. 42833.33 SUPPORT SERVICES 40175.00 8 record(s) selected. In this example, each row in the result data set produced contains the department name and the average salary for individuals who work in that department.
The GROUP BY ROLLUP clauseThe GROUP BY ROLLUP clause is used to analyze a collection of data in a single (hierarchal) dimension, but at more than one level of detail. For example you could group data by successively larger organizational units, such as team, department, and division, or by successively larger geographical units, such as city, county, state or province , country, and continent . Thus, if you were to execute a SELECT statement that looks something like this: SELECT WORKDEPT AS DEPARTMENT, AVG(SALARY) AS AVG_SALARY FROM EMPLOYEES GROUP BY ROLLUP (WORKDEPT) you might see a result data set that looks something like this: DEPARTMENT AVERAGE_SALARY ---------- -------------- - 27303.59 A00 42833.33 B01 41250.00 C01 30156.66 D11 24677.77 D21 25153.33 E01 40175.00 E11 20998.00 E21 23827.50 9 record(s) selected. This result data set contains average salary information for all employees found in the table named EMPLOYEES regardless of which department they work in (the first line in the result data set returned), as well as average salary information for each department available (the remaining lines in the result data set returned). In this example, only one expression (known as the grouping expression ) is specified in the GROUP BY ROLLUP clause (in this case, the grouping expression is WORKDEPT). However, one or more grouping expressions can be specified in a single GROUP BY ROLLUP clause (for example, GROUP BY ROLLUP (WORKDEPT, DIVISION) ). When multiple grouping expressions are specified, the DB2 Database Manager groups the data by all grouping expressions used, then by all but the last grouping expression used, and so on. Then, it makes one final grouping that consists of the entire contents of the specified table. In addition, when specifying multiple grouping expressions, it is important to ensure that they are listed in the appropriate orderif one kind of group is logically contained inside another (for example departments within a division), then that group should be listed after the group that it is contained in (i.e., GROUP BY ROLLUP (DEPARTMENTS, DIVISION) ), never before. The GROUP BY CUBE clauseThe GROUP BY CUBE clause is used to analyze a collection of data by organizing it into groups in multiple dimensions. Thus, if you were to execute a SELECT statement that looks something like this: SELECT SEX, WORKDEPT, AVG(SALARY) AS AVG_SALARY FROM EMPLOYEES GROUP BY CUBE (SEX, WORKDEPT) you might see a result data set that looks something like this: SEX WORKDEPT AVG_SALARY --- -------- ----------- - A00 42833.33 - B01 41250.00 - C01 30156.66 - D11 24677.77 - D21 25153.33 - E01 40175.00 - E11 20998.00 - E21 23827.50 - - 27303.59 F - 28411.53 M - 26545.52 F A00 52750.00 F C01 30156.66 F D11 24476.66 F D21 26933.33 F E11 23966.66 M A00 37875.00 M B01 41250.00 M D11 24778.33 M D21 23373.33 M E01 40175.00 M E11 16545.00 M E21 23827.50 23 record(s) selected. This result set contains average salary information for each department found in the table named EMPLOYEES (the lines that contain a null value in the SEX column and a value in the WORKDEPT column of the result data set returned), average salary information for all employees found in the table named EMPLOYEES regardless of which department they work in (the line that contains a NULL value for both the SEX and the WORKDEPT column of the result data set returned), average salary information for each sex (the lines that contain a value in the SEX column and a NULL value in the WORKDEPT column of the result data set returned), and average salary information for each sex in each department available (the remaining lines in the result data set returned). In other words, the data in the result data set produced is grouped:
The term CUBE is intended to suggest that data is being analyzed in more than one dimension. And as you can see in the previous example, data analysis was actually performed in two dimensions, which resulted in four types of groupings. If the SELECT statement: SELECT SEX, WORKDEPT, JOB, AVG(SALARY) AS AVG_SALARY FROM EMPLOYEES GROUP BY CUBE (SEX, WORKDEPT, JOB) had been used instead, data analysis would have been performed in three dimensions, and the data would have been broken into eight types of groupings. Thus, the number of types of groups produced by a CUBE operation can be determined by the formula: 2 n where n is the number of expressions used in the GROUP BY CUBE clause. The HAVING ClauseThe HAVING clause is used to apply further selection criteria to columns referenced in a GROUP BY clause. This clause behaves like the WHERE clause, except that it refers to data that has already been grouped by a GROUP BY clause (the HAVING clause is used to tell the DB2 Database Manager how to select the rows to be returned in a result data set from rows that have already been grouped). And like the WHERE clause, the HAVING clause is followed by a search condition that acts as a simple test that, when applied to a row of data, will evaluate to TRUE, FALSE, or Unknown. If this test evaluates to TRUE, the row is to be returned in the result data set produced; if the test evaluates to FALSE or Unknown, the row is skipped. In addition, the search condition of a HAVING clause can consist of the same predicates that are recognized by the WHERE clause. Thus, if you wanted to obtain the average salary for all departments found in the column named DEPTNAME in a table named DEPARTMENTS using salary information stored in a table named EMPLOYEES, and you wanted to organize the data retrieved by department, but you are only interested in departments whose average salary is greater than $30,000.00, you could do so by executing a SELECT statement that looks something like this: SELECT DEPTNAME, AVG(SALARY) AS AVG_SALARY FROM DEPARTMENT D, EMPLOYEES E WHERE E.WORKDEPT = D.DEPTNO GROUP BY DEPTNAME HAVING AVG(SALARY) > 30000.00 When this SELECT statement is executed, you might see a result data set that looks something like this: DEPTNAME AVG_SALARY ----------------------------- ----------- INFORMATION CENTER 30156.66 PLANNING 41250.00 SPIFFY COMPUTER SERVICE DIV. 42833.33 SUPPORT SERVICES 40175.00 4 record(s) selected. In this example, each row in the result data set produced contains the department name for every department whose average salary for individuals working in that department is greater than $30,000.00, along with the actual average salary for each department. The ORDER BY ClauseThe ORDER BY clause is used to tell the DB2 Database Manager how to sort and order the rows that are to be returned in a result data set produced in response to a query. When specified, the ORDER BY clause is followed by the name of the column(s) whose data values are to be sorted. Multiple columns can be used for sorting, and each column used can be ordered in either ascending or descending order. If the keyword ASC follows the column's name, ascending order is used, and if the keyword DESC follows the column name, descending order is used. Furthermore, when more than one column is identified in an ORDER BY clause, the corresponding result data set is sorted by the first column specified (the primary sort), then the sorted data is sorted again by the next column specified, and so on until the data has been sorted by each column specified. Thus, if you wanted to retrieve values for the columns named LASTNAME, FIRSTNME, and EMPNO in a table named EMPLOYEES where the value for the EMPNO column is greater than '000200', and you wanted the information sorted by LASTNAME followed by FIRSTNME, you could do so by executing a SELECT statement that looks something like this: SELECT LASTNAME, FIRSTNME, EMPNO FROM EMPLOYEES WHERE EMPNO > '000200' ORDER BY LASTNAME ASC, FIRSTNME ASC When this SELECT statement is executed, you might see a result data set that looks something like this: LASTNAME FIRSTNME EMPNO --------------- ------------ ------ GOUNOT JASON 000340 JEFFERSON JAMES 000230 JOHNSON SYBIL 000260 JONES WILLIAM 000210 LEE WING 000330 LUTZ JENNIFER 000220 MARINO SALVATORE 000240 MEHTA RAMLAL 000320 PARKER JOHN 000290 PEREZ MARIA 000270 SCHNEIDER ETHEL 000280 SETRIGHT MAUDE 000310 SMITH DANIEL 000250 SMITH PHILIP 000300 14 record(s) selected. As you can see, the data returned is ordered by employee last names and employee first names (the LASTNAME values are placed in ascending alphabetical order, and the FIRSTNME values are also placed in ascending alphabetical order). Using the ORDER BY clause is easy if the result data set is comprised entirely of named columns. But what happens if the result data set produced needs to be ordered by a summary column or a result column that cannot be specified by name? Because these types of situations can exist, an integer value that corresponds to a particular column's number can be used in place of the column name with the ORDER BY clause. When integer values are used, the first or leftmost column in the result data set produced is treated as column 1, the next is column 2, and so on. Therefore, you could have produced the same result data set generated earlier by executing a SELECT statement that looks like this: SELECT LASTNAME, FIRSTNME, EMPNO FROM EMPLOYEES WHERE EMPNO > '000200' ORDER BY 1 ASC, 2 ASC It is important to note that even though integer values are primarily used in the ORDER BY clause to specify columns that cannot be specified by name, they can be used in place of any valid column name as well. The FETCH FIRST ClauseThe FETCH FIRST clause is used to limit the number of rows returned to the result data set produced in response to a query. When used, the FETCH FIRST clause is followed by a positive integer value and the words ROWS ONLY . This tells the DB2 Database Manager that the user /application executing the query does not want to see more than n number of rows, regardless of how many rows might exist in the result data set that would be produced were the FETCH FIRST clause not specified. Thus, if you wanted to retrieve the first 10 values for the columns named WORKDEPT and JOB from a table named EMPLOYEES, you could do so by executing a SELECT statement that looks something like this: SELECT WORKDEPT, JOB FROM EMPLOYEES FETCH FIRST 10 ROWS ONLY And when this SELECT statement is executed, you might see a result data set that looks something like this: WORKDEPT JOB -------- -------- A00 PRES B01 MANAGER C01 MANAGER E01 MANAGER D11 MANAGER D21 MANAGER E11 MANAGER E21 MANAGER A00 SALESREP A00 CLERK 10 record(s) selected. Joining TablesMost of the examples we have looked at so far have involved only one table. However, one of the more powerful features of the SELECT statement (and the element that makes data normalization possible) is the ability to retrieve data from two or more tables by performing what is known as a join operation. (If you go back through the examples that have been presented so far, you will see an occasional " sneak preview" of a join operationparticularly in the examples provided for the IN predicate and the HAVING and GROUP BY clauses.) In its simplest form, the syntax for a SELECT statement that performs a join operation is: SELECT * FROM [ [ TableName ] [ ViewName ] ,...] where:
Consequently, if you wanted to retrieve all values stored in a base table named DEPARTMENT and all values stored in a base table named ORG, you could do so by executing a SELECT statement that looks something like this: SELECT * FROM DEPARTMENT, ORG When such a SELECT statement is executed, the result data set produced will contain all possible combinations of the rows found in each table specified (otherwise known as the Cartesian product). Every row in the result data set produced is a row from the first table referenced concatenated with a row from the second table referenced, concatenated in turn with a row from the third table referenced, and so on. The total number of rows found in the result data set produced is the product of the number of rows in all the individual table-references. Thus, if the table named DEPARTMENT in our previous example contains five rows and the table named ORG contains two rows, the result data set produced by the statement SELECT * FROM DEPARTMENT, ORG will consist of 10 rows (2 x 5 = 10). A more common join operation involves collecting data from two or more tables that have one specific column in common and combining the results to create an intermediate result table that contains the values needed to resolve a query. The syntax for a SELECT statement that performs this type of join operation is: SELECT [* [ Expression ] <<AS> [ NewColumnName ]> ,...] FROM [[ TableName ] <<AS> [ CorrelationName ]> ,...] [ JoinCondition ] where:
Thus, a simple join operation could be conducted by executing a SELECT statement that looks something like this: SELECT LASTNAME, DEPTNAME FROM EMPLOYEES E, DEPARTMENT D WHERE E.WORKDEPT = D.DEPTNO And when this SELECT statement is executed, you might see a result data set that looks something like this: LASTNAME DEPTNAME --------------- ----------------------------- HAAS SPIFFY COMPUTER SERVICE DIV. THOMPSON PLANNING KWAN INFORMATION CENTER GEYER SUPPORT SERVICES STERN MANUFACTURING SYSTEMS PULASKI ADMINISTRATION SYSTEMS HENDERSON OPERATIONS SPENSER SOFTWARE SUPPORT LUCCHESSI SPIFFY COMPUTER SERVICE DIV. O'CONNELL SPIFFY COMPUTER SERVICE DIV. QUINTANA INFORMATION CENTER NICHOLLS INFORMATION CENTER ADAMSON MANUFACTURING SYSTEMS LUTZ MANUFACTURING SYSTEMS SMITH ADMINISTRATION SYSTEMS PEREZ ADMINISTRATION SYSTEMS SCHNEIDER OPERATIONS PARKER OPERATIONS SETRIGHT OPERATIONS MEHTA SOFTWARE SUPPORT GOUNOT SOFTWARE SUPPORT 21 record(s) selected. This type of join is referred to as an inner join. Aside from a Cartesian product, only two types of joins can exist: inner joins and outer joins. And as you might imagine, there is a significant difference between the two.
Inner joinsAn inner join is the simplest type of join operation that can be performed. An inner join can be thought of as the cross product of two tables, in which every row in one table that has a corresponding row in another table is combined with that row to produce a new record. This type of join works well as long as every row in the first table has a corresponding row in the second table. However, if this is not the case, the result table produced may be missing rows found in either or both of the tables that were joined. Earlier, we saw the most common SELECT statement syntax used to perform an inner join operation. The following syntax can also be used to create a SELECT statement that performs an inner join operation: SELECT [* [ Expression ] <<AS> [ NewColumnName ]> ,...] FROM [[ TableName1 ] <<AS> [ CorrelationName1 ]>] <INNER> JOIN [[ TableName2 ] <<AS> [ CorrelationName2 ]>] ON [ JoinCondition ] where:
Consequently, the same inner join operation we looked at earlier could be conducted by executing a SELECT statement that looks something like this: SELECT LASTNAME, DEPTNAME FROM EMPLOYEES E INNER JOIN DEPARTMENT D ON E.WORKDEPT = D.DEPTNO Figure 5-23 illustrates how such an inner join operation would work. Figure 5-23. A simple inner join operation. Outer joinsOuter joins operations are used when a join operation is needed and any rows that would normally be eliminated by an inner join operation need to be preserved. With DB2 UDB, three types of outer joins are available:
To understand the basic principles behind an outer join operation, it helps to look at an example. Suppose Table A and Table B are joined by an ordinary inner join operation. Any row in either Table A or Table B that does not have a matching row in the other table (according to the rules of the join condition) is eliminated from the final result data set produced. By contrast, if Table A and Table B are joined by an outer join, any row in either Table A or Table B that does not contain a matching row in the other table is included in the result data set (exactly once), and columns in that row that would have contained matching values from the other table are empty. Thus, an outer join operation adds nonmatching rows to the final result data set produced where an inner join operation excludes them. A left outer join of Table A with Table B preserves all nonmatching rows found in Table A, a right outer join of Table A with Table B preserves all nonmatching rows found in Table B, and a full outer join preserves nonmatching rows found in both Table A and Table B. The basic syntax for a SELECT statement used to perform an outer join operation is: SELECT [* [ Expression ] <<AS> [ NewColumnName ]> ,...] FROM [[ TableName1 ] <<AS> [ CorrelationName1 ]>] [LEFT RIGHT FULL] OUTER JOIN [[ TableName2 ] <<AS> [ CorrelationName2 ]>] ON [JoinCondition] where:
Thus, a simple left outer join operation could be conducted by executing a SELECT statement that looks something like this: SELECT LASTNAME, DEPTNAME FROM EMPLOYEES E LEFT OUTER JOIN DEPARTMENT D ON E.WORKDEPT = D.DEPTNO The same query could be used to perform a right outer join operation or a full outer join operation by substituting the keyword RIGHT or FULL for the keyword LEFT . Figure 5-24 illustrates how such a left outer join operation would work; Figure 5-25 illustrates how such a right outer join operation would work; and Figure 5-26 illustrates how such a full join operation would work. Figure 5-24. A simple left outer join operation. Figure 5-25. A simple right outer join operation. Combining Two or More Queries with a Set OperatorWith DB2 UDB, it is possible to combine two or more queries into a single query by using a special operator known as a set operator. When a set operator is used, the results of each query executed are combined in a specific manner to produce a single result data set. The following set operators are available:
In order for two result data sets to be combined with a set operator, both must have the same number of columns, and each of those columns must have the exact same data types assigned to them. So when would you want to combine the results of two queries using a set operator? Suppose your company keeps individual employee expense account information in a table whose contents are archived at the end of each fiscal year. When a new fiscal year begins, expenditures for that year are essentially recorded in a new table. Now suppose, for tax purposes, you need a record of all employees' expenses for the last two years . To obtain this information, each archived table must be queried, and the results must then be combined. Rather than do this by running individual queries against the archived tables and storing the results in some kind of temporary table, this operation could be performed simply by using the UNION set operator, along with two SELECT SQL statements. Such a set of SELECT statements might look something like this: SELECT * FROM EMP_EXP_02 UNION SELECT * FROM EMP_EXP_01 ORDER BY EXPENSES DESC Figure 5-27 illustrates how such a set operation would work. Figure 5-27. A simple UNION set operation. The same set of queries could be combined using the UNION ALL , EXCEPT , EXCEPT ALL , INTERSECT , or INTERSECT ALL set operator simply by substituting the appropriate keyword for the keyword UNION . However, the results of each operation would be significantly different. Using SQL Functions to Transform DataAlong with a rich set of SQL statements, DB2 UDB comes with a set of built-in functions that can return a single result value or convert data values from one data type to another. (A function is an operation denoted by a function name followed by a pair of parentheses enclosing zero or more arguments.) Most of the built-in functions provided by DB2 UDB are classified as being either aggregate, or columnar (because they work on all values of a column), or scalar (because they work on a single value in a table or view). The argument of a columnar function is a collection of like values. A columnar function returns a single value (possibly null), and can be specified in an SQL statement wherever an expression can be used. Some of the more common columnar functions include:
The arguments of a scalar function are individual scalar values, which can be of different data types and can have different meanings. A scalar function returns a single value (possibly null) and can be specified in an SQL statement wherever an expression can be used. Some of the more common scalar functions include:
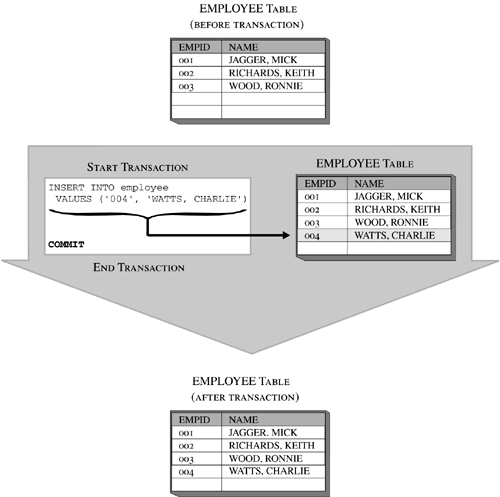
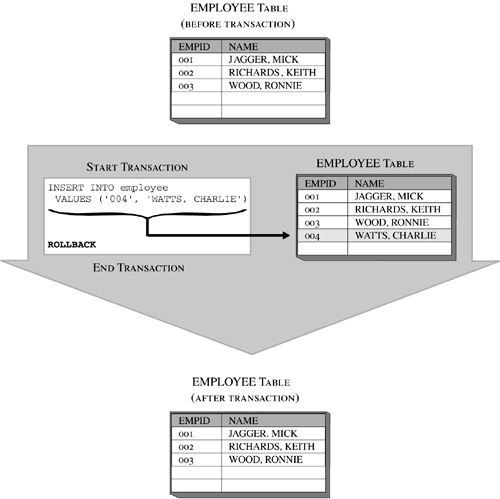
Retrieving Rows from a Result Data Set Using a CursorWhen a query is executed from within an application, DB2 UDB uses a mechanism known as a cursor to retrieve data values from the result data set produced. The name cursor probably originated from the blinking cursor found on early computer screens, and just as that cursor indicated the current position on the screen and identified where typed words would appear next, a DB2 UDB cursor indicates the current position in the result data set (i.e. the current row) and identifies which row of data will be returned to the application next. The steps involved in using a cursor in an application program are as follows:
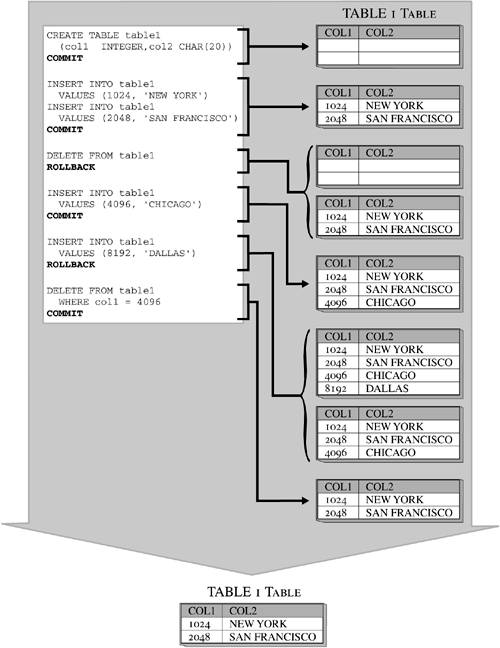
For example, an application written in the C programming language designed to retrieve data from a table using a cursor might look something like this: #include <stdio.h> #include <stdlib.h> #include <sql.h> void main() { /* Include The SQLCA Data Structure Variable */ EXEC SQL INCLUDE SQLCA; /* Declare The SQL Host Memory Variables */ EXEC SQL BEGIN DECLARE SECTION; char EmployeeNo[7]; char LastName[16]; EXEC SQL END DECLARE SECTION; /* Connect To The SAMPLE Database */ EXEC SQL CONNECT TO SAMPLE USER; /* Declare A Cursor */ EXEC SQL DECLARE C1 CURSOR FOR SELECT EMPNO, LASTNAME FROM EMPLOYEE WHERE JOB = 'DESIGNER'; /* Open The Cursor */ EXEC SQL OPEN C1; /* Fetch The Records */ while (sqlca.sqlcode == SQL_RC_OK) { /* Retrieve A Record */ EXEC SQL FETCH C1 INTO :EmployeeNo, :LastName /* Print The Information Retrieved */ if (sqlca.sqlcode == SQL_RC_OK) printf("%s, %s\n", EmployeeNo, LastName); } /* Close The Cursor */ EXEC SQL CLOSE C1; /* Issue A COMMIT To Free All Locks */ EXEC SQL COMMIT; /* Disconnect From The SAMPLE Database */ EXEC SQL DISCONNECT CURRENT; } An application can use several cursors concurrently; however, each cursor must have its own unique name and its own set of DECLARE CURSOR , OPEN , FETCH , and CLOSE SQL statements. TransactionsA transaction (also known as a unit of work ) is a sequence of one or more SQL operations grouped together as a single unit, usually within an application process. Such a unit is called "atomic" because, like atoms (before fission and fusion were discovered ), it is indivisibleeither all of its work is carried out or none of its work is carried out. A given transaction can perform any number of SQL operationsfrom a single operation to many hundreds or even thousands, depending upon what is considered a "single step" within your business logic. (It is important to note that the longer a transaction is, the more database concurrency decreases and the more resource locks are acquired ; this is usually considered the sign of a poorly written application.) The initiation and termination of a single transaction defines points of data consistency within a database (we'll take a closer look at data consistency in Chapter 7, "Database Concurrency"); either the effects of all operations performed within a transaction are applied to the database and made permanent (committed), or the effects of all operations performed are backed out (rolled back) and the database is returned to the state it was in before the transaction was initiated. In most cases, transactions are initiated the first time an executable SQL statement is executed after a connection to a database has been made or immediately after a pre-existing transaction has been terminated. Once initiated, transactions can be implicitly terminated, using a feature known as "automatic commit" (in which case, each executable SQL statement is treated as a single transaction, and any changes made by that statement are applied to the database if the statement executes successfully or discarded if the statement fails) or they can be explicitly terminated by executing the COMMIT or the ROLLBACK SQL statement. The basic syntax for these two statements is: COMMIT <WORK> and ROLLBACK <WORK> When the COMMIT statement is used to terminate a transaction, all changes made to the database since the transaction began are made permanent. On the other hand, when the ROLLBACK statement is used, all changes made are backed out and the database is returned to the state it was in just before the transaction began. Figure 5-28 shows the effects of a transaction that was terminated with a COMMIT statement; Figure 5-29 shows the effects of a transaction that was terminated with a ROLLBACK statement. Figure 5-28. Terminating a transaction with the COMMIT SQL statement. Figure 5-29. Terminating a transaction with the ROLLBACK SQL statement. It is important to remember that commit and rollback operations only have an effect on changes that have been made within the transaction they terminate. So in order to evaluate the effects of a series of transactions, you must be able to identify where each transaction begins, as well as when and how each transaction is terminated. Figure 5-30 shows how the effects of a series of transactions can be evaluated. Figure 5-30. Evaluating the effects of a series of transactions. Changes made by a transaction that have not been committed are usually inaccessible to other users and applications (there are exceptions which we will look at in Chapter 7, "Database Concurrency," when we look at "dirty reads" and the Uncommitted Read isolation level), and can be backed out with a rollback operation. However, once changes made by a transaction have been committed, they become accessible to all other users and/or applications and can only be removed by executing new SQL statements (within a new transaction). So what happens if a system failure occurs before a transaction's changes can be committed? If only the user/application is disconnected (for example, because of a network failure), the DB2 Database Manager backs out all uncommitted changes (by replaying information stored in the transaction log files), and the database is returned to the state it was in just before the transaction that was terminated unexpectedly began. On the other hand, if the database or the DB2 Database Manager is terminated (for example, because of a hard disk failure or a loss of power), the DB2 Database Manager will try to roll back all open transactions it finds in the transaction log file the next time the database is restarted (which will take place automatically the next time a user attempts to connect to the database if the database configuration parameter autorestart has been set accordingly ). Only after this succeeds will the database be placed online again (i.e., made accessible to users and applications). SQL ProceduresWhen you set up a remote DB2 UDB database server and access it from one or more DB2 UDB client workstations, you have, in essence, established a basic DB2 UDB client/server environment. In this environment, each time an SQL statement is executed against the database on the remote server, the statement itself is sent, through a network, from the client workstation to the database server. The database server then processes the statement, and the results are sent back, again through the network, to the client workstation. (This means that two messages must go through the network for every SQL statement that is executed.) If you have an application that contains one or more transactions that perform a relatively large amount of database activity with little or no user interaction, each transaction can be stored on the database server as what is known as a stored procedure. By using an SQL procedure (also known as a stored procedure), all database processing done by the transaction can be performed directly at the server workstation. And, because a stored procedure is invoked by a single SQL statement, fewer messages have to be transmitted across the networkonly the data that is actually needed at the client workstation has to be sent across. This architecture allows the code that interacts directly with a database to reside on a high-performance PC or minicomputer where computing power and centralized control can be used to provide quick, coordinated data access. At the same time, the application logic can reside on one or more smaller (client) workstations so that it can make effective use of all the resources the client workstation has to offer. Thus, the resources of both the client workstation and the server workstation are utilized to their fullest potential. Creating a Stored ProcedureTwo different types of stored procedures can be created and used with a DB2 UDB database. They are:
Regardless of whether a stored procedure is an external procedure or an SQL procedure, all procedures must be structured such that they performs three distinct tasks :
Before the source code for an external procedure actually becomes a usable stored procedure, unless the procedure was written with JDBC or DB2 CLI, the source code must be precompiled with the DB2 SQL Precompiler, then the precompiled source code must be compiled and linked to produce a library, and finally the library must be bound to the database. Typically, this binding takes place when the source code is precompiled. Once a library containing the stored procedure has been created, that library must be physically stored on the server workstation. (By default, the DB2 Database Manager looks for stored procedures in the \ sqllib \ function and \ sqllib \ function \ unfenced subdirectories.) Additionally, the system permissions for the library file containing the stored procedure must be modified so that all users can execute it. For example, in a UNIX environment, the chmod command is used to make a file executable; in a Windows environment, the attrib command is used to make a file executable. Both external procedures and SQL procedures must be registered with the database they are designed to interact with. This is done by executing the appropriate form of the CREATE PROCEDURE SQL statement. The basic syntax for this statement is: CREATE PROCEDURE [ ProcedureName ] ([ ParamType ] [ ParamName ] [ DataType ] ,...) <SPECIFIC [ SpecificName ]> <DYNAMIC RESULT SETS [ NumResultSets ]> <NO SQL CONTAINS SQL READS SQL DATA> <DETERMINISTIC NOT DETERMINISTIC> <CALLED ON NULL INPUT> <FEDERATED NOT FEDERATED> <LANGUAGE SQL> [ SQLStatements ] or CREATE PROCEDURE [ ProcedureName ] ([ ParamType ] [ ParamName ] [ DataType ] ,...) <SPECIFIC [ SpecificName ]> <DYNAMIC RESULT SETS [ NumResultSets ]> <NO SQL CONTAINS SQL READS SQL DATA> <DETERMINISTIC NOT DETERMINISTIC> <CALLED ON NULL INPUT> LANGUAGE [C JAVA COBOL OLE] EXTERNAL <NAME [ ExternalName ] [ Identifier ]> <FENCED <THREADSAFE NOT THREADSAFE> NOT FENCED <THREADSAFE>> PARAMETER STYLE [DB2GENERAL DB2SQL GENERAL GENERAL WITH NULLS JAVA SQL] <PROGRAM TYPE [SUB MAIN]> <DBINFO NO DBINFO> where:
Thus, a simple SQL procedure could be created by executing a CREATE PROCEDURE statement that looks something like this: CREATE PROCEDURE GET_SALES (IN QUOTA INTEGER, OUT RETCODE CHAR(5)) DYNAMIC RESULT SETS 1 LANGUAGE SQL BEGIN DECLARE RETCODE CHAR(5); DECLARE SALES_RESULTS CURSOR WITH RETURN FOR SELECT SALES_PERSON, SUM(SALES) AS TOTAL_SALES FROM SALES GROUP BY SALES_PERSON HAVING SUM(SALES) > QUOTA; OPEN SALES_RESULTS; SET RETCODE = SQLSTATE; END The resulting SQL procedure, called GET_SALES, accepts an integer input value (in an input parameter called QUOTA) and returns a character value (in an output parameter called RETCODE) that reports the success or failure of the SQL procedure. The procedure body consists of a single SELECT statement that returns the name and the total sales figures for each salesper son whose total sales exceed the quota specified. This procedure also returns one result data set. This is done by:
Calling an SQL ProcedureOnce a stored procedure has been registered with a database (by executing the CREATE PROCEDURE SQL statement), that procedure can be invoked, either interactively, using a utility such as the Command Line Processor, or from a client application. Registered stored procedures are invoked by executing the CALL SQL statement. The basic syntax for this statement is: CALL [ ProcedureName ] (<[ InputValue ] [ OutputParameter ] NULL> ,...) where:
Thus, the SQL procedure named GET_SALES that we created earlier could be invoked by connecting to the appropriate database and executing a CALL statement that looks something like this: CALL GET_SALES (25, ?) When this SELECT statement is executed, the value 25 is passed to the input parameter named QUOTA and a question mark (?) is used as a place-holder for the value that will be returned in the output parameter RETCODE. The procedure will then execute the SQL statements contained in it and return a result data set that looks something like this: SALES_PERSON TOTAL_SALES --------------- ----------- GOUNOT 50 LEE 91 2 record(s) selected. "GET_SALES" RETURN_STATUS: "0" Practice Questions
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





EAN: 2147483647
Pages: 68