11.5 Capacity planning
|
| < Day Day Up > |
|
In this process, based on the planned growth rate of the enterprise, the growth rate in the number of users as a result of increased business is determined. Based on these growth rates, the appropriate hardware configurations are selected.
After analyzing the business requirements and their current application, database configuration, and the growth requirements, careful analysis should be performed to quantify the benefits of switching to a RAC environment. In the case of a new application and database configuration, a similar analysis should also be performed to quantify if RAC would be necessary to meet the requirements of the current and future business needs.
The first step in the quantification process is to analyze the current business requirements such as:
-
Are there requirements that justify or require the systems to be up and running 24 hours a day, every day of the year?
-
Are there sufficient business projections on the number of users that would be accessing the system, and what will the user growth rate be?
-
Will there be a steady growth rate that would indicate that the current system configurations might not be sufficient?
Once answers to these questions have been determined, a simulation model should be constructed to establish the scalability requirements for the planning or requirements team, and the architecture should be considered. These issues need to be resolved before moving to the next step.
Chapter 2 (Hardware Concepts) discusses in detail various technology options, like SMP, MPP, NUMA, and clustered SMP. The simulation should determine if any of these hardware architectures would be required or would be ideal for the implementation of the system. During this initial hardware architecture evaluation, the question should arise as to whether a single instance configuration would be sufficient or a clustered solution would be required. If a single instance configuration is deemed sufficient, then whether the system would need to be protected from disasters would need to be determined. If disaster protection is a requirement, then, protection could be provided by using the Oracle Data Guard feature (called Oracle Standby prior to Version 9.0).
Other considerations are:
-
Are there any reporting requirements? If so, what is the plan to accomplish them?
-
If the data guard solution is not sufficient, a more reliable, high- availability solution may be required.
-
Is clustered configuration a requirement? If so, what conditions necessitate this?
The application could be either the user-defined application used to perform a basic business function, such as a customer management system, or it could be a third-party product like the RDBMS. In both cases, consi deration should be given to validating that ''clusterizing'' is the only option.
Applications to run in a clustered configuration (e.g., clustered SMP, NUMA clusters) should be clusterizable such that the benefits could be measured in terms of global performance or availability. (Availability basically refers to availability to service clients.) From the performance aspect, the initial measurements would be to determine the required throughput of the application. Under normal scenarios, performance is measured by the number of transactions that the system could process per second or the number of records that could be inserted into the system per hour. Performance can also be measured by the throughput of the system, utilizing a simple formula like the following:
THROUGHPUT = No: of Operations Performed by the Application
Unit of Time Used for Measurement
There are two levels of throughput measurement: the minimum throughput expectation and the maximum throughput required. To complicate things a bit further, there could also be the ideal throughput required from the application, which is normally the average throughput. Lastly, the requirement could be twisted further by stating the percentage increase in throughput required to meet the expectations.
Another measurement of throughput can be determined by establishing the number of concurrent users or the maximum number of jobs that the application can handle. This measurement could be based on the following:
-
The typical interaction between the user and the application, or job, that has been mentioned in the business requirements.
-
Length of this typical interaction to complete the request or job by the user measured as the acceptable response time, which is measured in units of time.
So the throughput measurement based on the number of users could be:
THROUGHPUT = No: of Concurrent Users (per Requirements
User Acceptable Response Time (UART)
If this formula is applied to the current application or to the simulation model, then throughput of the system could be measured for the application (which is the inverse of the above formula):
UART = Throughput x No. of Concurrent Users Supported
The throughput derived above could be increased on the system in many different ways, such as:
-
Through changes made to the application; normally an expensive process because it may result in a rewriting of the entire application.
-
Increase of power of the hardware running the application; a situation of vertical scalability, and could also be an expensive process because hardware limitations could repeat after the current estimated users have been reached.
-
Clusterizing the application; probably the best opportunity in this situation due to the provision of horizontal scalability. Clusterizing enables the administrator to meet the increased demand of users as the business grows and requirements change (with higher numbers of concurrent users) by adding additional nodes to the cluster to help scale the application. This is done while providing the same amount of throughput and UART.
Once the clustering options have been decided upon, the next step will be to determine how this will be done. It is imperative to consider or create a goal that this activity will accomplish before establishing the best method to incorporate. It is often argued that maintenance should be simple; however, from the overall management perspective, the ultimate focus of the operation should be performance.
While maintenance is an important feature, performance plays a more important role in this process. Some options to consider during the clustering process are as follows. Is the application designed to be:
-
Multiplexed: Do multiple copies of the application run on each of the nodes in the cluster?
-
Partitioned: Is the application designed in such a manner that it could be broken up into several pieces based on functionality and mode of operation? For example, partitioning could be based on functionality like accounts payable, accounts receivable, and payroll, all based on the departments that will be accessing these functionalities. The other alternative is to partition the application by the mode of operation like OLTP and batch or application behavior.
-
Hybrid scenario: Is a combination of the above two options a way to get the best results of both worlds? A possible combination would be to partition the application based on one of the criteria best suited for the application and business, then to multiplex the partitioned pieces.
Items 1 and 2 above are true and feasible most of the time in the case of a business application or the client/server application. Because there are no specific protocols between clients, there is reliance on a central database server to serialize the transactions when maximizing the overall throughput and offering a consistent view of the database to all clients. This means that after the initial configuration, additional clients could be added without much difficulty; therefore, increasing linearly the client-side/application-side throughput.
The application server, the business application, or the client/server application is just one piece to the puzzle. The other main piece to the puzzle is the application or product that stores all the information and which contains the business rules: the database server. Very commonly, database, or RDBMS servers, are run on a single node and execute the application queries, packages, etc., and are not easily clusterizable. This is because the RDBMS constitutes instance structures (memory, processes) when accessing the database and has to guarantee the synchronization, serialization, consistency, and data reliability. Analyzing the implementa tion of Oracle in one of the three options above, multiplexing would require having multiple copies of the database on different storage systems so that the application would access one of the copies of the database. Normally, when such a configuration is implemented, the transferring of data between the many copies of the database is required to keep the database in sync. For such situations a replication tool comes as a choice. However, the synchronization overhead introduced to data contention and resolution can be so relevant that the application may scale down instead of scaling up.
Applying the second option listed above, partitioning of the database server would mean to physically find a common ground and make the databases into two separate databases. Each database would have a different data set or would support a specific business function. Imple mentation of such a configuration would entail that the clients are also partitioned, forcing certain clients to specific Oracle server nodes. This is feasible to a certain degree if there is a clear line between the various departments or organizations accessing these partitions. For example, accounts receivable, accounts payable, payroll, human resources, etc., could be partitioned to some extent. However, when consolidating these functions to provide a cohesive window of information to the manage ment, there could be difficulty because of cross-functional data requirements (e.g., accounts payable needs to look at the data of accounts receivable, etc.).
The third option listed above would be to enlist a combination of the first two options. Unfortunately, because both options have their own
limitations, a combined scenario would not be feasible either. Implementing a database application on a clustered environment would completely depend on the clustered RDBMS technology that is used. The database is the backbone of every enterprise system and to get the best performance from the application, the database should be compatible or designed to run on a clustered hardware configuration (e.g., clustered SMP or NUMA servers). OPS and now the RAC version of Oracle RDBMS allow Oracle-based applications to scale up in a clustered configuration smoothly. This allows multiple Oracle instances to share one common database, which provides the option for the application to run on multiple nodes accessing any of the Oracle instances that communicate with one common physical database.
11.5.1 How to measure scaling
When the application is configured to run on a clustered system, the throughput, or global throughput, of an N-node clustered configuration could be measured. This would basically be:
T(n) = SUMt(i)
where i = 1, ... , n and t(i) is the throughput measured on one node in the clustered configuration.
Following the above, with different values of n, the value of T will change. This will aid in defining the throughput curve of the application, which basically indicates the scalability factor in a clustered configuration.
Other factors that could hinder, improve, or contribute to the performance of the system must be considered. This includes the various resources and the power of the computational hardware. Resources and computational power apply to each node in the cluster. Each node could be of a different configuration (though not done this way for many reasons); hence, the values could be different and may affect the overall scalability matrix. Adding these factors to the formula above would result in the following:
T(n) ≈ nts(n)
where T(n) is the global throughput of the application running on all N nodes and is measured by unit of time; t, as we indicated above, is the throughput for one node in the cluster; n is the number of nodes participating in the clustered configuration; and s(n) is a coefficient that determines our overall cluster throughput.
This could be even further complicated, or more variables could be added to the puzzle, by studying factors such as the type of clustered hardware, the topology of the cluster, the type of application running on the clustered configuration, etc. Because certain hardware platforms perform better than others, these factors will also affect the scalability. For example, MPP architecture works well for a data warehouse implementa tion; however, for an OLTP implementation, a clustered SMP architecture would be better suited. With these factors added, the new formula would be:
T(n) ≈ nts(c, n, a, k)
where c is the type of clustered hardware, n is the node number, a is the type of application running on the clustered configuration, and k is the topology of the cluster.
Because all of these additional factors cannot be measured, only the previous formulas are used.
The best-case scenario of scalability of an application would be when the application scales up with a constant factor of one, providing a consistent linear growth. However, this kind of scalability is not realistic. Rather, it is typical for applications to have sublinear growth with the increase in nodes. The growth continues until a certain limit has been reached, after which adding additional nodes to the clustered configuration would not show any further advantage. This is demonstrated by the graph in Figure 11.1, which indicates that there is a linear scale-up with the addition of new nodes; however, after a certain percentage of scalability has been reached, a point of no return is reached on investment, and the scalability reduces with the addition of more nodes.
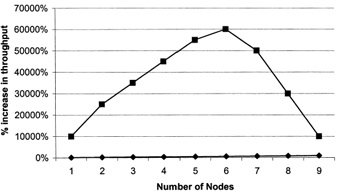
Figure 11.1: Capacity planning.
Capacity planning for an enterprise system takes many iterative steps. Every time there is a change in usage pattern, capacity planning has to be visited in some form or the other.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174
- Chapter I e-Search: A Conceptual Framework of Online Consumer Behavior
- Chapter VII Objective and Perceived Complexity and Their Impacts on Internet Communication
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior