Pre-Installation Decisions
| Most of the choices you make during the installation process can be changed later, although some are harder to change than others. In this section, I'll discuss three of the most important decisions you'll need to make during the installation, and I strongly suggest that you think about each of them before running SQL Server Setup. Security and the User ContextTo install SQL Server on a machine, you need not be an administrator of the domain, but you must have administrator privileges on the machine. Users can install most of the SQL Server client utilities without administrator privileges. Before you set up your system, give some thought to the user context in which SQL Server and SQL Server Agent will run. A new SQL Server installation can set up the SQL Server engine to run in the context of the special system (LocalSystem) account. This account is typically used to run services, but it has no privileges on other machines, nor can it be granted such privileges. The Local System account option is provided for backward compatibility only. The Local System account has permissions that SQL Server Agent does not require. Avoid running SQL Server Agent as the Local System account whenever possible. It is recommended to have the SQL Server service and the SQL Server Agent service run in the context of a domain account. This allows SQL Server to more easily perform tasks that require an external security context, such as backing up to another machine or using replication. If you don't have access to a domain account and set up SQL Server to run in the context of the Local System account, you should be aware that this account is automatically added to the SQL Server sysadmin role by default. This will still give SQL Server sufficient privileges to run on the local machine but may not be as secure as using a domain account with appropriate privileges. If you're not going to use the LocalSystem account, it's a good idea to change the account under which SQL Server will run to a user account that you've created just for this purpose (rather than use an actual local or domain account of a real user). The account must be in the local Administrators group if you're installing SQL Server on Windows 2000 or Windows 2003. You can create this account before you begin installing SQL Server, or you can change the account under which SQL Server runs at a later time. Changing the accounts for the SQL Server services should never be done directly via the Service or through the Services Control Panel. It is very important to use the SQL Server Configuration Manager utility to make all changes to the services associated with SQL Server. This utility ensures that all changes to the account name or password are properly dealt with across all the components involved. By making the change directly in the control panel, you can prevent the services from starting or operating properly. When you choose or create a user account for running SQL Server, be sure to configure the account so the password never expires; if the password expires, SQL Server won't start until the information for the service is updated. By default, the installation program chooses to use the same account for both the SQL Server and the SQL Server Agent services. SQL Server Agent needs a domain-level security context to connect to other computers more often than does SQL Server. For example, if you plan to publish data for replication, SQL Server Agent needs a security context to connect to the subscribing machines. If you specify a domain account but the domain controller cannot validate the account (because the domain controller is temporarily unavailable, for example), go ahead and install using the LocalSystem account and change it later using the SQL Server Configuration Manager (available through the Start menu). During installation, you are given the option to set up SQL Server to allow connections using Windows Authentication Mode only or using Mixed Mode security. If you select Windows Authentication Only, SQL Server will allow access only if the connection already has been authenticated by Windows and has a valid Security ID (SID). The Windows-authenticated SID determines the level of access the connection will have in SQL Server. With Windows Authentication, you cannot choose to connect under a different SQL Server logon name than the one indicated by your Windows logon. If you choose Mixed Mode security during installation, each client will specify when a connection is made, whether it is connecting using Windows Authentication or SQL Server Authentication. If the client requests SQL Server Authentication, a SQL Server login name and password must be supplied. During installation, if you choose Mixed Mode authentication, it means that you can log on using the SQL Server system administrator (sa) login; you are then asked to specify a password for that all-powerful login name. Unlike in SQL Server 2000, a password is required for the sa login and it cannot be left blank. Be sure to pick a password you'll remember because, by design, there is no way to read a password (it is stored in encrypted form)it can only be changed to something else. A strong password is requiredone that contains at least six characters and includes a combination of uppercase and lowercase letters, digits, and special characters. For example, to use a query window to change the password to 1ceCre@m, you would issue the following command: ALTER LOGIN sa WITH PASSWORD = '1ceCre@m'Using Object Explorer, you can change the password from the SQL Server Security folder. Open the Logins folder under Security, and then double-click the entry for sa. A dialog box will open that allows you to change the password. Warning
Note that the way the actual password is stored is different in SQL Server 2005 than it was in SQL Server 2000. Passwords are now always case-sensitive regardless of the server collation. Characters and CollationAnother decision you should consider before installation is the collation for your SQL Server, which includes both the character set and sort order you want SQL Server to use for your system databases. Although user databases can be installed with different collation than the system databases, and individual character columns can have their own collation, it can make database management more complex if you have to keep track of multiple collations. You should also consider the collation you choose during installation to be the permanent collation for the system databases because it can be a very complex operation to change on an existing SQL Server. Most non-Unicode characters are stored in SQL Server as a single byte (8 bits), which means that 256 (28) different characters can be represented. But the combined total of characters in all the world's languages is more than 256. So if you don't want to store all your data as Unicode, which takes twice as much storage space, you must choose a character set that contains all the characters (referred to as the repertoire) that you need to work with. For installations in the Western Hemisphere and Western Europe, the ISO character set (also often referred to as Windows Characters, ISO 8859-1, Latin-1, or ANSI) is the default and is compatible with the character set used by all versions of Windows in those regions. (Technically, there is a slight difference between the Windows character set and ISO 8859-1.) If you choose ISO, you might want to skip the rest of this section on character sets, but you should still familiarize yourself with sort order issues. You should also ensure that all your client workstations use a character set that is consistent with the characters used by your installation of SQL Server. If, for example, the character ¥, the symbol for Japanese yen, is entered by a client application using the standard Windows character set, internally SQL Server stores a byte value (also known as a code point) of 165 (0xA5). If an MS-DOS-based application using code page 437 retrieves that value, that application will display the character Ñ. (MS-DOS uses the term code pages to mean character sets; you can think of the terms as interchangeable.) In both cases, the internal value of 165 is stored, but the Windows character set and the MS-DOS code page 437 render it differently. You must consider whether the ordering of characters is what is semantically expected (as discussed later in the "Sort Orders" section) and whether the character will be rendered on the application monitor (or other output device) as expected. SQL Server provides services in the OLE DB provider and the ODBC driver that use Windows services to perform character set conversions. Conversions cannot always be exact, however, because by definition, each character set has a somewhat different repertoire of characters. For example, there is no exact match in code page 437 for the Windows character Õ, so the conversion must give a close, but different, character. Windows 2000, Windows 2003, and SQL Server 2005 also support 2-byte characters that allow representation of virtually every character used in any language. This is known as Unicode, and it provides many benefitswith some costs. The principal cost is that 2 bytes instead of 1 are needed to store a character. SQL Server allows storage of Unicode data by using the datatypes nchar, nvarchar, and ntext. I'll discuss these in more detail when I talk about datatypes in Chapter 6. The use of Unicode characters for certain data does not affect the character set chosen for non-Unicode data, which is stored using the datatypes char, varchar, and text.
Versions of SQL Server before SQL Server 2000 did not support Unicode, but they did support double-byte character sets (DBCS). DBCS is a hybrid approach and is the most common way for applications to support Asian languages such as Japanese and Chinese. With DBCS encoding, some characters are 1 byte and others are 2 bytes. The first bit in the character indicates whether the character is a 1-byte or a 2-byte character. (In non-Unicode datatypes, each character is considered 1 byte for storage; in Unicode datatypes, every character is 2 bytes.) To store two DBCS characters, a field would need to be declared as char(4) instead of char(2). SQL Server correctly parses and understands DBCS characters in its string functions. The DBCS characters are still available for backward compatibility, but for new applications that need more flexibility in character representation, you should consider using the Unicode datatypes exclusively. Sort OrdersThe specific character set used might not be important in many sites where most of the available character sets can represent the full range of English and Western European characters. However, in nearly every site, whether you realize it or not, the basics of sort order (which is more properly called collating sequence) is important. Sort order determines how characters compare and assign their values. It determines whether your SQL operations are case sensitive. For example, is an uppercase A considered identical to a lowercase a? If your sort order is case sensitive, these two characters are not equivalent, and SQL Server will sort A before a because the byte value for A is less than that for a. If your sort order is case insensitive, whether A sorts before or after a is unpredictable unless you also specify a preference value. Uppercase preference can be specified only with a case-insensitive sort order; this means that although A and a are treated as equivalent for comparisons, A is sorted before a. If your data will include extended characters, you must also decide whether your data will be accent insensitive. For our purposes, accents refer to any diacritical marks. An accent-insensitive sort order treats a and ä as equivalent, for example. For certain character sets, you must also specify two other options. For double-byte character sets, you can specify width insensitivity, which means that equivalent characters represented in either 1 or 2 bytes are treated the same. For a Japanese sort order, you can specify kana insensitivity, which means that katakana characters are always unequal to hiragana characters. If you use only ASCII characters and no extended characters, you should simply decide whether you need case sensitivity and choose your collation settings accordingly. Sort order affects not only the ordering of a result set but also which rows of data qualify for that result set. If a query's search condition is WHERE name='SMITH' the case sensitivity determines whether a row with the name Smith qualifies. Character matching, string functions, and aggregate functions (MIN, MAX, COUNT (DISTINCT), GROUP BY, UNION, CUBE, LIKE, and ORDER BY) all behave differently with character data depending on the sort order specified. Sort Order SemanticsYou can think of characters as having primary, secondary, and tertiary sort values, which are different for different sort order choices. A character's primary sort value is used to distinguish it from other characters, without regard to case and diacritical marks. It is essentially an optimization: if two characters do not have the same primary sort value, they cannot be considered identical for either comparison or sorting and there is no reason to look further. The secondary sort value distinguishes two characters that share the same primary value. If the characters share the same primary and secondary values (for example, A = a), they are treated as identical for comparisons. The tertiary value allows the characters to compare identically but sort differently. Hence, based on A = a, apple and Apple are considered equal. However, Apple sorts before apple when a sort order with uppercase preference is used. If there is no uppercase preference, whether Apple or apple sorts first is simply a random event based on the order in which the data is encountered when retrieved. For example, a sort order specification of "case insensitive, accent sensitive, uppercase preference" defines all A-like values as having the same primary sort value. A and a not only have the same primary sort value, but they also have the same secondary sort value because they are defined as equal (case insensitive). The character à has the same primary value as A and a but is not declared equal to them (accent sensitive), so à has a different secondary value. And although A and a have the same primary and secondary sort values, with an uppercase preference sort order, each has a different tertiary sort value, which allows it to compare identically but sort differently. If the sort order doesn't have uppercase preference, A and a will have the same primary, secondary, and tertiary sort values. Some sort order choices allow for accent insensitivity. This means that extended characters with diacritics are defined with primary and secondary values equivalent to those without. If you want a search of name ='Jose' to find both Jose and José, you should choose accent insensitivity. Such a sort order defines all E-like characters as equal: E=e=è=É=é=ê=ë Note
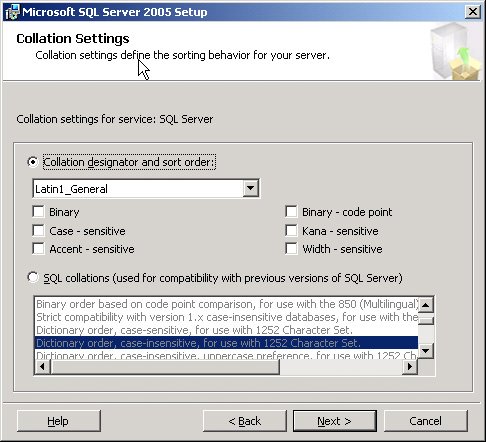
Binary SortingAs an alternative to specifying case or accent sensitivity, you can choose a binary sorting option, in which characters are sorted based on their internal byte representation. If you look at a chart for the character set, you see the characters ordered by this numeric value. In a binary sort, the characters are sorted according to their position by value, just as they are in the chart. Hence, by definition, a binary sort is always case sensitive and accent sensitive and every character has a unique byte value. Binary sorting is the fastest sorting option because all that is required internally is a simple byte-by-byte comparison of the values. But if you use extended characters, binary sorting is not always semantically desirable. Characters that are A-like, such as Ä, ä, Å, and å, all sort after Z because the extended character A's are in the top 128 characters and Z is a standard ASCII character in the lower 128. If you deal with only ASCII characters (or otherwise don't care about the sort order of extended characters), you want case sensitivity, and you don't care about "dictionary" sorting, binary sorting is an ideal choice. In case-sensitive dictionary sorting, the letters abcxyzABCXYZ sort as AaBbCcXxYyZz. In binary sorting, all uppercase letters appear before any lowercase lettersfor example, ABCXYZabcxyz. Specifying a CollationDuring the installation of SQL Server 2005, you are asked to specify a default collation for your server. This is the collation that your system databases will use, and any new database you create will use this collation by default. In Chapter 4, I'll describe how you can create a database with a different collation than the one chosen during installation. Two types of collation are available; the documentation calls them Windows Collation and SQL Collation. Figure 1-3 shows the installation dialog box in which you choose your collation. The two choices can be described as Windows Locale Collation Designator and SQL Collation. The dialog box doesn't use the term Windows Local Collation Designator; as you can see, it is described only as Collation Designator. Figure 1-3. Two installation choices for collation and sort order SQL Collation is intended for backward compatibility and basically addresses all three collation issues in a single description string: the code page for non-Unicode data, the sort order for non-Unicode data, and the sort order for Unicode data. In Figure 1-3, you can see that a SQL Collation is highlighted in the lower window, even though I selected a collation from the top window by using the option button. The highlighted SQL Collation is actually the default for SQL Server 2005 installation on a U.S. English SQL Server, and the description of the SQL Collation is "Dictionary Order, Case-Insensitive, For Use With 1252 Character Set." The code page for non-Unicode data is 1252, the sort order for non-Unicode data is case insensitive, and the sort order for Unicode is Dictionary Order. The actual name of this collation is SQL_Latin1_General_CP1_CI_AS, and you can use this name when referring to this collation by using SQL statements, as you'll see in later chapters. The prefix SQL indicates that this is a SQL Collation as opposed to a Windows Collation. The Latin1_General part indicates that the Unicode sort order corresponds to dictionary order, CP1 indicates the default code page 1252, and CI_AS indicates case insensitive, accent sensitive. Other collation names use the full code page number; only 1252 has the special abbreviation CP1. For example, SQL_Scandinavian_CP850_CS_AS is the SQL Collation using Scandinavian sort order for Unicode data, code page 850 for non-Unicode data, and a case-sensitive, accent-sensitive sort order. The SQL Collations are intended only for backward compatibility with previous SQL Server versions. There is a fixed list of possible values for SQL Collations, and not every combination of sort orders, Unicode collations, and code pages is possible. Some combinations don't make any sense, and others are omitted just to keep the list of possible values manageable. As an alternative to a SQL Collation for compatibility with a previous installation, you can define a collation based on a Windows locale. In Windows Collation, the Unicode data types always have the same sorting behavior as non-Unicode data types. A Windows Collation is the default for non-English SQL Server installations, with the specific default value for the collation taken from your Windows operating system configuration. You can choose to always sort by byte values for a binary sort, or you can choose case sensitivity and accent sensitivity. Performance ConsiderationsBinary sorting uses significantly fewer CPU instructions than sort orders with defined sort values. So binary sorting is ideal if it fulfills your semantic needs. However, you won't pay a noticeable penalty for using either a simple case-insensitive sort order (for example, Dictionary Order, Case Insensitive) or a case-sensitive choice that offers better support than binary sorting for extended characters. Most large sorts in SQL Server tend to be I/O-bound, not CPU-bound, so the fact that fewer CPU instructions are used by binary sorting doesn't typically translate to a significant performance difference. When you sort a small amount of data that is not I/O-bound, the difference is minimal; the sort will be fast in both cases. A more significant performance difference results if you choose a sort order of Case Insensitive, Uppercase Preference. Recall that this choice considers all values as equal for comparisons, which also includes indexing. Characters retain a unique tertiary sort order, however, so they might be treated differently by an ORDER BY clause. Uppercase Preference, therefore, can often require an additional sort operation in queries. Consider a query that specifies WHERE last_name >= 'Jackson' ORDER BY last_name. If an index exists on the last_name field, the query optimizer will likely use it to find rows whose last_name value is greater than or equal to Jackson. If your application has no need to use Uppercase Preference, the optimizer knows that because SQL Server will be retrieving records based on the order of last_name, there will be no need to physically sort the rows because they will be found in the index in the proper order and will be extracted in that order already. Jackson, jackson, and JACKSON are all qualifying rows. All are indexed and treated identically, and they simply appear in the result set in the order in which they were encountered. If Uppercase Preference is required for sorting, a subsequent sort of the qualifying rows is required to differentiate the rows even though the index can still be used for selecting qualifying rows. If many qualifying rows are present, the performance difference between the two cases (one needs an additional sort operation) can be dramatic. This doesn't mean you shouldn't choose Uppercase Preference. If your application requires those semantics, performance might well be a secondary concern. But you should be aware of the trade-off and decide which is most important to you. Installing Multiple Instances of SQL ServerThe last pre-installation decision I will discuss here is whether to install a default SQL Server instance or a named instance. SQL Server 2005 allows you to install multiple instances of SQL Server on a single computer. One instance of SQL Server can be referred to as the default instance, and all others must have names and are referred to as named instances. Each instance is installed separately and has its own default collation, its own system administrator password, and its own set of databases and valid users. If you are upgrading from SQL Server version 7.0, the upgraded instance is a default instance. The ability to install multiple instances on a single machine provides benefits in a few different areas. First is the area of application hosting. One site can provide machine resources and administration services for multiple companies. These might be small companies that don't have the time or resources (human or machine) to manage and maintain their own SQL servers. They might want to hire another company to "host" their SQL Server private or public applications. Each company needs full administrative privileges over its own data. However, if each company's data were stored in a separate database on a single SQL server, any SQL Server system administrator (sa) would be able to access any of the databases. Installing each company's data on a separate SQL Server instance allows each company to have full sa privileges for its own data but no access to any other company's data. In fact, each company might be totally unaware that other companies are using the same application server. A second area in which multiple instances provide great benefits is server consolidation. Instead of having 10 separate machines to run 10 separate applications within a company, all the applications can be combined on one machine. With separate instances, each application can still have its own administrator and its own set of users and permissions. For the company, this means fewer boxes to administer and fewer operating system licenses required. For example, one Windows 2003 Advanced Server with 10 SQL Server instances costs less than 10 separate server boxes. An added benefit to running multiple instances on one big computer is that you are more likely to take care of a more powerful computer, which will lead to greater reliability. With the kind of investment required to buy a machine capable of running 10 SQL Server 2005 instances, you'll probably want to set it up in its own climate-controlled data center instead of next to someone's desk. You'll meticulously maintain both the hardware and the software and let only trained engineers get near it. This means that reliability and availability will be greatly enhanced. The third area in which multiple instances are beneficial is testing and support. Because the separate instances can be different versions of SQL Server or even the same version with different service packs installed, you can use one box for reproducing problem reports or testing bug fixes. You can verify which versions the problems can be reproduced on and which versions they can't. A support center can similarly use multiple instances to make sure that it can use exactly the same version that the customer has installed. Installing Named Instances of SQL ServerWhen you install multiple SQL Server instances on a single machine, only one instance is the "default" instance. This is the SQL Server that is accessed by supplying the machine name as the name of the SQL Server. For example, to use SQL Server Management Studio to access the default SQL Server on my machine called TENAR, I simply type TENAR in the SQL Server text box in the Connect To SQL Server dialog box. Any other instances on the same machine will have an additional name, which must be specified along with the machine name. I can install a second SQL Server instance with its own namefor example, INSTANCE1. Then I must enter TENAR\INSTANCE1 in the initial text box to connect with Management Studio. Note
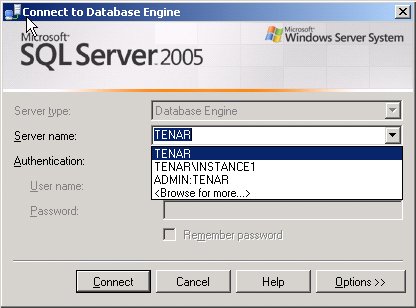
Figure 1-4 shows the connection box with the names of the two instances on my machine called TENAR. The default instance is just called TENAR, and my named instance, which I called INSTANCE1, must be specified as TENAR\INSTANCE1. Figure 1-4. Choosing which instance of SQL Server to connect to Your default instance can be SQL Server 7.0, SQL Server 2000, or SQL Server 2005. Named instances can be either SQL Server 2000 or SQL Server 2005. Microsoft specifies that you can have up to 50 instances of SQL Server 2005 Enterprise Edition or Developer Edition on a single machine, and up to 16 instances of other editions or versions. But this is only the supported limit. Nothing is hardcoded into the system to prevent you from installing additional instances as long as you have the resources on the machine to support them. Each instance has its own separate directory for storing the server executables, and each instance's data files can be placed wherever you choose. During installation, you can specify the desired path for the program files and the data files. Each instance also has its own SQL Server Agent service. The service names for the default instance do not changethey are MSSQLServer and SQLServerAgent. For an instance named INSTANCE1, the services are named MSSQL$ INSTANCE1 and SQLAGENT$ INSTANCE1. However, only one installation of the tools is used for all instances of the same version of SQL Server. That is, you will have only one set of tools to use with all your SQL Server 2005 instances and one to use for all your SQL Server 2000 instances. Some of the services are instance-aware, and you'll get a separate service for each instance for each of the following:
Instance-unaware services are shared among all installed SQL Server instances; they are not associated with a specific instance, are installed only once, and cannot be installed side by side. Instance-unaware services in SQL Server 2005 include:
|
EAN: 2147483647
Pages: 115
- Chapter I e-Search: A Conceptual Framework of Online Consumer Behavior
- Chapter II Information Search on the Internet: A Causal Model
- Chapter III Two Models of Online Patronage: Why Do Consumers Shop on the Internet?
- Chapter V Consumer Complaint Behavior in the Online Environment
- Chapter XVII Internet Markets and E-Loyalty