Serialization -- What Is It?
The term "serialization" might be new to you, but it's already seen some use in the world of object-oriented programming. The idea is that objects can be persistent, which means they can be saved on disk when a program exits and then can be restored when the program is restarted. This process of saving and restoring objects is called serialization. In the Microsoft Foundation Class (MFC) library, designated classes have a member function named Serialize. When the application framework calls Serialize for a particular object—for example, an object of class CStudent—the data for the student is either saved on disk or read from disk.
In the MFC library, serialization is not a substitute for a database management system. All the objects associated with a document are sequentially read from or written to a single disk file. It's not possible to access individual objects at random disk file addresses. If you need database capability in your application, consider using the Microsoft Open Database Connectivity (ODBC) software or Data Access Objects (DAO). Chapter 31 and Chapter 32 show you how to use ODBC and DAO with the MFC application framework.
There's a storage option that fits between sequential files and a database: structured storage, described in Chapter 27. The MFC framework already uses structured storage for container programs that support embedded objects.
Disk Files and Archives
How do you know whether Serialize should read or write data? How is Serialize connected to a disk file? With the MFC library, objects of class CFile represent disk files. A CFile object encapsulates the binary file handle that you get through the Win32 function CreateFile. This is not the buffered FILE pointer that you'd get with a call to the C runtime fopen function; rather, it's a handle to a binary file. The application framework uses this file handle for Win32 ReadFile, WriteFile, and SetFilePointer calls.
If your application does no direct disk I/O but instead relies on the serialization process, you can avoid direct use of CFile objects. Between the Serialize function and the CFile object is an archive object (of class CArchive), as shown in Figure 17-1.
The CArchive object buffers data for the CFile object, and it maintains an internal flag that indicates whether the archive is storing (writing to disk) or loading (reading from disk). Only one active archive is associated with a file at any one time. The application framework takes care of constructing the CFile and CArchive objects, opening the disk file for the CFile object and associating the archive object with the file. All you have to do (in your Serialize function) is load data from or store data in the archive object. The application framework calls the document's Serialize function during the File Open and File Save processes.
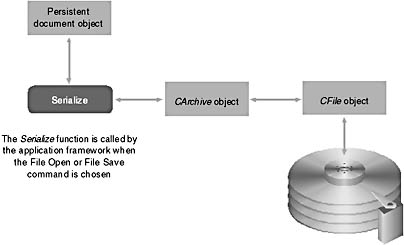
Figure 17-1. The serialization process.
Making a Class Serializable
A serializable class must be derived directly or indirectly from CObject. In addition (with some exceptions), the class declaration must contain the DECLARE_SERIAL macro call, and the class implementation file must con- tain the IMPLEMENT_SERIAL macro call. (See the Microsoft Foundation Class Reference for a description of these macros.) This chapter's CStudent class example is modified from the class in Chapter 16 to include these macros.
Writing a Serialize Function
In Chapter 16, you saw a CStudent class, derived from CObject, with these data members:
public: CString m_strName; int m_nGrade;
Now your job is to write a Serialize member function for CStudent. Because Serialize is a virtual member function of class CObject, you must be sure that the return value and parameter types match the CObject declaration. The Serialize function for the CStudent class is below.
void CStudent::Serialize(CArchive& ar) { TRACE("Entering CStudent::Serialize\n"); if (ar.IsStoring()) { ar << m_strName << m_nGrade; } else { ar >> m_strName >> m_nGrade; } } Most serialization functions call the Serialize functions of their base classes. If CStudent were derived from CPerson, for example, the first line of the Serialize function would be
CPerson::Serialize(ar);
The Serialize function for CObject (and for CDocument, which doesn't override it) doesn't do anything useful, so there's no need to call it.
Notice that ar is a CArchive reference parameter that identifies the application's archive object. The CArchive::IsStoring member function tells us whether the archive is currently being used for storing or loading. The CArchive class has overloaded insertion operators (<<) and extraction operators (>>) for many of the C++ built-in types, as shown in the following table.
| Type | Description |
| BYTE | 8 bits, unsigned |
| WORD | 16 bits, unsigned |
| LONG | 32 bits, signed |
| DWORD | 32 bits, unsigned |
| float | 32 bits |
| double | 64 bits, IEEE standard |
| int | 32 bits, signed |
| short | 16 bits, signed |
| char | 8 bits, unsigned |
| unsigned | 32 bits, unsigned |
The insertion operators are overloaded for values; the extraction operators are overloaded for references. Sometimes you must use a cast to satisfy the compiler. Suppose you have a data member m_nType that is an enumerated type. Here's the code you would use:
ar << (int) m_nType; ar >> (int&) m_nType;
MFC classes that are not derived from CObject, such as CString and CRect, have their own overloaded insertion and extraction operators for CArchive.
Loading from an Archive—Embedded Objects vs. Pointers
Now suppose your CStudent object has other objects embedded in it, and these objects are not instances of standard classes such as CString, CSize, and CRect. Let's add a new data member to the CStudent class:
public: CTranscript m_transcript;
Assume that CTranscript is a custom class, derived from CObject, with its own Serialize member function. There's no overloaded << or >> operator for CObject, so the CStudent::Serialize function now becomes
void CStudent::Serialize(CArchive& ar) { if (ar.IsStoring()) { ar << m_strName << m_nGrade; } else { ar >> m_strName >> m_nGrade; } m_transcript.Serialize(ar); } Before the CStudent::Serialize function can be called to load a student record from the archive, a CStudent object must exist somewhere. The embedded CTranscript object m_transcript is constructed along with the CStudent object before the call to the CTranscript::Serialize function. When the virtual CTranscript::Serialize function does get called, it can load the archived transcript data into the embedded m_transcript object. If you're looking for a rule, here it is: always make a direct call to Serialize for embedded objects of classes derived from CObject.
Suppose that, instead of an embedded object, your CStudent object contained a CTranscript pointer data member such as this:
public: CTranscript* m_pTranscript;
You could use the Serialize function, as shown below, but as you can see, you must construct a new CTranscript object yourself.
void CStudent::Serialize(CArchive& ar) { if (ar.IsStoring()) ar << m_strName << m_nGrade; else { m_pTranscript = new CTranscript; ar >> m_strName >> m_nGrade; } m_pTranscript->Serialize(ar); } Because the CArchive insertion and extraction operators are indeed overloaded for CObject pointers, you could write Serialize this way instead:
void CStudent::Serialize(CArchive& ar) { if (ar.IsStoring()) ar << m_strName << m_nGrade << m_pTranscript; else ar >> m_strName >> m_nGrade >> m_pTranscript; } But how is the CTranscript object constructed when the data is loaded from the archive? That's where the DECLARE_SERIAL and IMPLEMENT_SERIAL macros in the CTranscript class come in.
When the CTranscript object is written to the archive, the macros ensure that the class name is written along with the data. When the archive is read, the class name is read in and an object of the correct class is dynamically constructed, under the control of code generated by the macros. Once the CTranscript object has been constructed, the overridden Serialize function for CTranscript can be called to do the work of reading the student data from the disk file. Finally the CTranscript pointer is stored in the m_pTranscript data member. To avoid a memory leak, you must be sure that m_pTranscript does not already contain a pointer to a CTranscript object. If the CStudent object was just constructed and thus was not previously loaded from the archive, the transcript pointer will be null.
The insertion and extraction operators do not work with embedded objects of classes derived from CObject, as shown here:
ar >> m_strName >> m_nGrade >> &m_transcript; // Don't try this
Serializing Collections
Because all collection classes are derived from the CObject class and the collection class declarations contain the DECLARE_SERIAL macro call, you can conveniently serialize collections with a call to the collection class's Serialize member function. If you call Serialize for a CObList collection of CStudent objects, for example, the Serialize function for each CStudent object will be called in turn. You should, however, remember the following specifics about loading collections from an archive:
- If a collection contains pointers to objects of mixed classes (all derived from CObject), the individual class names are stored in the archive so that the objects can be properly constructed with the appropriate class constructor.
- If a container object, such as a document, contains an embedded collection, loaded data is appended to the existing collection. You might need to empty the collection before loading from the archive. This is usually done in the document's virtual DeleteContents function, which is called by the application framework.
- When a collection of CObject pointers is loaded from an archive, the following processing steps take place for each object in the collection:
- The object's class is identified.
- Heap storage is allocated for the object.
- The object's data is loaded into the newly allocated storage.
- A pointer to the new object is stored in the collection.
The EX17A example shows serialization of an embedded collection of CStudent records.
The Serialize Function and the Application Framework
OK, so you know how to write Serialize functions, and you know that these function calls can be nested. But do you know when the first Serialize function gets called to start the serialization process? With the application framework, everything is keyed to the document (the object of a class derived from CDocument). When you choose Save or Open from the File menu, the application framework creates a CArchive object (and an underlying CFile object) and then calls your document class's Serialize function, passing a reference to the CArchive object. Your derived document class Serialize function then serializes each of its nontemporary data members.
If you take a close look at any AppWizard-generated document class, you'll notice that the class includes the DECLARE_DYNCREATE and IMPLEMENT_DYNCREATE macros rather than the DECLARE_SERIAL and IMPLEMENT_SERIAL macros. The SERIAL macros are unneeded because document objects are never used in conjunction with the CArchive extraction operator or included in collections; the application framework calls the document's Serialize member function directly. You should include the DECLARE_SERIAL and IMPLEMENT_SERIAL macros in all other serializable classes.
EAN: 2147483647
Pages: 332