| By default, an XML parser assumes that XML documents are written in the UTF-8 encoding of Unicode. However, documents may be written instead in any character set the XML processor understands, provided that there's either some external metadata like an HTTP header or internal metadata like a byte-order mark or an encoding declaration that specifies the character set. For example, a document written in the Latin-5 character set would need this XML declaration: <?xml version="1.0" encoding="ISO-8859-9"?>
Most good XML processors understand many common character sets. The XML specification recommends the character names shown in Table 27-1. When using any of these character sets, you should use these names. Of these character sets, only UTF-8 and UTF-16 must be supported by all XML processors, although many XML processors support all character sets listed here, and many support additional character sets besides. When using character sets not listed here, you should use the names specified in the IANA character sets registry at http://www.iana.org/assignments/character-sets. Table 27-1. Character set names defined by the XML specification | Name | Character set | | UTF-8 | The default encoding used in XML documents, unless an encoding declaration, byte-order mark, or external metadata specifies otherwise ; a variable-width encoding of Unicode that uses one to four bytes per character. UTF-8 is designed such that all ASCII documents are legal UTF-8 documents, which is not true for other character sets, such as UTF-16 and Latin-1. This character set is normally the best encoding choice for XML documents that don't contain a lot of Chinese, Japanese, or Korean. | | UTF-16 | A two-byte encoding of Unicode in which all Unicode characters defined in Unicode 3.0 and earlier (including the ASCII characters) occupy exactly two bytes. However, characters from planes 1 through 14, added in Unicode 3.1 and later, are encoded using surrogate pairs of four bytes each. This encoding is the best choice if your XML documents contain substantial amounts of Chinese, Japanese, or Korean. | | ISO-10646-UCS-2 | The Basic Multilingual Plane of Unicode, i.e., plane 0. This character set is the same as UTF-16, except that it does not allow surrogate pairs to represent characters with code points beyond 65,535. The difference is only significant in Unicode 3.1 and later. Each Unicode character is represented as exactly one two-byte, unsigned integer. Determining endianness requires a byte-order mark at the beginning of the file. | | ISO-10646-UCS-4 | A four-byte encoding of Unicode in which each Unicode character is represented as exactly one four-byte, unsigned integer. Determining endianness requires a byte-order mark at the beginning of the file. | | ISO-8859-1 | Latin-1, ASCII plus the characters needed for most Western European languages, including Danish, Dutch, English, Faroese, Finnish, Flemish, German, Icelandic, Irish, Italian, Norwegian, Portuguese, Spanish, and Swedish. Some non-European languages, such as Hawaiian, Indonesian, and Swahili, also use these characters. | | ISO-8859-2 | Latin-2, ASCII plus the characters needed for most Central European languages, including Croatian, Czech, Hungarian, Polish, Slovak, and Slovenian. | | ISO-8859-3 | Latin-3, ASCII plus the characters needed for Esperanto, Maltese, Turkish, and Galician. Latin-5, ISO-8859-9, however, is now preferred for Turkish. | | ISO-8859-4 | Latin-4, ASCII plus the characters needed for the Baltic languages Latvian, Lithuanian, Greenlandic, and Lappish. Now largely replaced by ISO-8859-10, Latin-6. | | ISO-8859-5 | ASCII plus the Cyrillic characters used for Byelorussian, Bulgarian, Macedonian, Russian, Serbian, and Ukrainian. | | ISO-8859-6 | ASCII plus Arabic | | ISO-8859-7 | ASCII plus modern Greek. | | ISO-8859-8 | ASCII plus Hebrew. | | ISO-8859-9 | Latin-5, which is essentially the same as Latin-1 (ASCII plus Western Europe), except that the Turkish letters 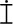 , 1 , , 1 , 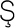 , , 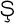 , , 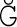 , and , and 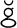 replace the less-commonly used Icelandic letters replace the less-commonly used Icelandic letters 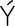 , , 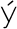 , , 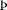 , ,  , , 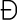 , and , and 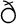 . . | | ISO-8859-10 | Latin-6, which covers the characters needed for the Northern European languages Estonian, Lithuanian, Greenlandic, Icelandic, Inuit, and Lappish. It's similar to Latin-4, but drops some symbols and the Latvian letter, 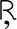 adds a few extra letters needed for Inuit and Lappish, and moves various characters around. ISO-8859-13 now supersedes this character set. adds a few extra letters needed for Inuit and Lappish, and moves various characters around. ISO-8859-13 now supersedes this character set. | | ISO-8859-11 | Adds the Thai alphabet to basic ASCII. However, it is not well supported by current XML parsers, and you're probably better off using Unicode instead. | | ISO-8859-12 | Not yet in existence and unlikely to exist in the foreseeable future. At one point, this character set was considered for Devanagari, so the number was reserved. However, this effort is not yet off the ground, and it now seems likely that the increasing acceptance of Unicode will make such a character set unnecessary. | | ISO-8859-13 | Another character set designed to cover the Baltic languages. This set adds back in the Latvian letter and other symbols dropped from Latin-6. | | ISO-8859-14 | Latin-8; a variant of Latin-1 with extra letters needed for Gaelic and Welsh, such as 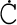 , ,  , and , and 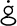 . These letters mostly replace punctuation marks, such as x and . . These letters mostly replace punctuation marks, such as x and . | | ISO-8859-15 | Known officially as Latin-9 and unofficially as Latin-0; a revision of Latin-1 that replaces the international currency symbol with the Euro sign 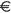 . It also replaces the seldom-used fraction characters 1 / 4 , 1 / 2 , and 3 / 4 with the uncommon French letters , . It also replaces the seldom-used fraction characters 1 / 4 , 1 / 2 , and 3 / 4 with the uncommon French letters , 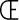 , , 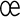 , , 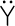 and the , and the , 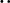 , and ' symbols with the Finnish letters , and ' symbols with the Finnish letters 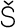 , , 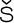 , and , and  . Otherwise, it's identical to ISO-8859-1. . Otherwise, it's identical to ISO-8859-1. | | ISO-8859-16 | Latin-10; intended primarily for Romanian. | | ISO-2022-JP | A seven-bit encoding of the character set defined in the Japanese national standard JIS X-0208-1997 used on web pages and in email; see RFC 1468. | | Shift_JIS | The encoding of the Japanese national standard character set JIS X-0208-1997 used in Microsoft Windows. | | EUC-JP | The encoding of the Japanese national standard character set JIS X-0208-1997 used by most Unixes. |
Some parsers do not understand all these encodings. Specifically, parsers based on James Clark's expat often support only UTF-8, UTF-16, ISO-8859-1, and US-ASCII encodings. Xerces-C supports ASCII, UTF-8, UTF-16, UCS4, IBM037, IBM1140, ISO-8859-1, and Windows-1252. IBM's XML4C parser, derived from the Xerces codebase , adds over 100 more encodings, including ISO-8859 character sets 1 through 9 and 15. However, for maximum cross-parser compatibility, you should convert your documents to either UTF-8 or UTF-16 before publishing them, even if you author them in another character set. |