Developing a Troubleshooting Checklist
| There is an old saying that when you practice what you need to do in the time of a crisis, when the crisis occurs the reaction tends to be automatic. When the firewall is down is not the time to try to figure out what you should be looking at to resolve the problem. Instead, develop a troubleshooting checklist in advance. The reason is simple: There will already be enough stress and confusion as a result of the failure; there is no need to increase either by not having a plan. Your troubleshooting checklist is that plan. Obviously, you cannot plan for every failure that will occur, but you can put together a strategy that, if executed properly, increases the likelihood of being able to isolate the problem more rapidly. The primary objective of the troubleshooting checklist is to provide a methodical and logical approach to troubleshoot the problem. After all, computer systems (including firewalls) are binary devices, they are on or off. The logic is simple, and the devices always do exactly what they are supposed toeven when they fail. A troubleshooting checklist should guide you through that logical troubleshooting process. I often use an analogy of eating an elephant when I talk about troubleshooting. Trying to eat an elephant introduces a big, big problem. If you try to sit down and eat the elephant all at once, you are going to quickly find yourself overwhelmed with the task at hand. Troubleshooting is no different. If you try to troubleshoot the entire problem all at once, you are going to quickly find yourself overwhelmed with the task at hand. However, instead of trying to deal with the whole elephant, if you chop it into smaller, easier-to-manage steak-sized pieces, you will find the task of eating the elephant more manageable. Troubleshooting is no different, and after you have developed a checklist of methodical and logical approaches to troubleshooting a problem, a secondary objective of a troubleshooting checklist is to use the results obtained by following the checklist to narrow down the potential causes of whatever failure is occurring. Keeping in mind that every firewall, environment, and problem is unique, the following represent a good baseline troubleshooting checklist:
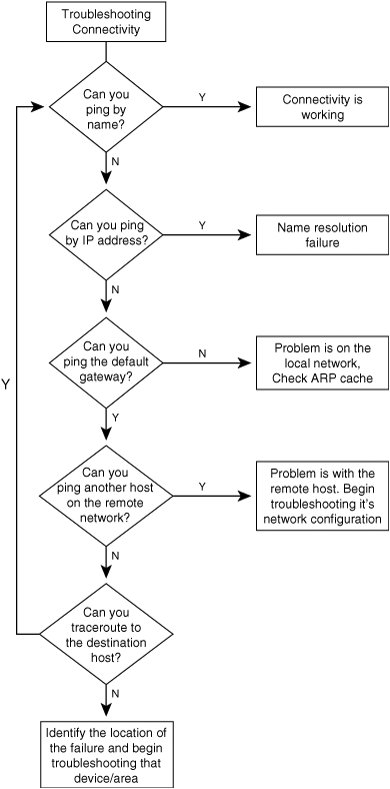
Step1: Verify the Problem ReportedOne of the most overlooked steps in troubleshooting is to actually verify that the problem that was reported is occurring as it was reported. Far too often, people report what they suspect the problem is without being for certain that the problem is indeed related to the firewall. I have lost count of how many times I have heard "I cannot access this server, the firewall must be down" only to discover that the server itself was down. So before you begin the actual troubleshooting process, ensure that the problem has been reported accurately and that you understand and if possible can reproduce or see the problem as it is occurring. The old saying "To know where you are going, you need to know where you are at" holds true in troubleshooting. Before you can troubleshoot a problem, you need to make sure you know what the problem is. Another aspect of verifying the problem is to make sure you treat the problem, not the symptoms. This is similar to treating a medical patient. If a person comes in with a fever and all you do is treat the fever (the symptom), you have done nothing to fix the problem (the illness causing the fever). Accordingly, when the problem is reported, try to distinguish between the symptoms of the problem (which are normally what is reported) and the problem itself. The reason for this is simple. If all you do is treat the symptoms, you may eliminate the cause for the problem being reported, but you have not fixed the problem itself, and a good chance exists that it will reappear at some point in the future. This is particularly true when it comes to dealing with performance-related issues. It is easy to lose sight of the problem, treat the symptom, and move on without ever addressing the root cause of the performance problem. Step2: Test ConnectivityIn the realm of networking and firewalls, one of the most important and first questions to ask is this: Is the device up? This is where testing connectivity comes into play. Although this step is not applicable to every situation, it is usually a good idea to try to connect to the firewall or system protected by the firewall just to make sure it is up. There are a number of ways to do this. Using Ping to Test ConnectivityThe de facto standard method of testing connectivity is to send a ping to the target host. There are a couple of ways that this can be done that will provide additional information based on the response. To help with understanding the process and the interaction of each step, see the connectivity testing flowchart in Figure 13-1. Figure 13-1. Connectivity Testing Flowchart The first step is to attempt to ping the target host by its host name. If this succeeds, it validates that everything from name resolution to physical delivery of the data is functioning properly. If this is not successful, the next step is to attempt to ping the target host by its IP address. This eliminates name resolution as part of the problem. If this succeeds, the problem is likely going to be related to name resolution (either Domain Name System [DNS] resolution or NetBIOS name resolution). Perhaps the DNS server is down or the target host name is not known. If this does not succeed, it is possible that the target host is inaccessible for some reason (regardless, however, the problem warrants more attention). If the target host is remote, the next step is to attempt to ping the default gateway of the source machine as well as another host on the same network as the remote machine (it is a good idea to use the remote machines default gateway as the destination). If you can physically access the target machine, repeat this process in the other direction. These steps validate that both hosts are able to communicate with their local routers as well as validating that you can reach something on the remote network. If they cannot, a good chance exists that the problem exists between the host and its router. It is possible that there is an invalid Address Resolution Protocol (ARP) entry on either the host or the router. If the hosts can successfully ping their respective routers, and you are unable to ping another host on the remote network, the next step is to perform a traceroute from the source to the target host. This will enable you to determine the approximate location where the problem is occurring. In a complex routed environment, it is generally a good idea to have some baseline results of a functional traceroute because the traceroute is typically unable to provide the IP address of the failing hop. Only by knowing what the next hop from the last successful hop is can you have an idea of what specific router might be the cause. Testing Connectivity Without Using PingOne thing to keep in mind when testing connectivity is that many firewalls, by design, do not allow ICMP traffic to traverse the firewall, and thus render the use of ICMP to test connectivity worthless. You have a couple of options in this event. For one, you can permit the ICMP traffic for the purposes of troubleshooting the problem and then disable it again when you are finished. Another option is to use another protocol to determine whether the remote system is responding at all. For example, just telnetting to many TCP ports will either confirm or deny whether a remote host is accessible, as shown in Example 13-1. Example 13-1. Telnetting to TCP port 80 to Test Connectivity
By just telnetting to TCP port 80 and typing GET / HTTP/1.0 and then pressing Enter a few times, I can retrieve the default web page for the server, which at least verifies that the target host is properly connected to and communicating with the network and at best will tell me exactly what web server software is being run as shown on the 5th line from end, "Server: Microsoft-IIS/6.0. Step3: Physically Check the FirewallOne of the most common failures on a network is a physical failure. From bumped power cords to incorrectly seated network cables, you can often quickly identify and remedy the problem by paying a visit to the physical machine. In addition, many network devices, including firewalls, provide visual indicators regarding the status of the system. For example, if you do not see a link light on an interface, that is usually a good indicator that the network cable is not plugged in. In some cases (for example, remote firewalls), it is just not feasible to check the firewall yourself. If you have a trusted person at that remote site, however, you can ask that person to check on the firewall on your behalf. As firewall administrators, many of us have gotten used to being able to do most of our work remotely from our desk. As much of an annoyance as it may be to have to walk over to where the firewall is to check on it, that pales in comparison to spending time trying to troubleshoot a connectivity problem only to find that someone bumped the power cord on the firewall. Step4: Check for Recent ChangesRecent changes are not always responsible for problems that occur, but they should always be examined as a potential cause of the problems. The reason for this is simple: Today's networks are so complex that it is difficult to ensure that a change does not cause a problem for a dependent system. Consequentially, it is critical that you have a means of tracking and monitoring the changes that are made in your environment so that you have something that you can refer back to. Good change control is more than just "busy work." It provides a methodical means of answering the questions of who, what, and when:
It is important to view recent changes as a culprit for problems with a skeptical eye, however. Before spending time undoing the changes, examine the change in the context of the problem and make sure that it makes sense for the changes that were made to be a cause of the problem. For example, one time I watched a company roll back a series of virus Digital Audio Tape (DAT) files because they were the last change made on the network before authentication errors started occurring. Now, anyone who knows anything about DAT updates knows that they have pretty much nothing to do with authentication, and this case was no different. When it was all said and done, the DAT updates were rolled back and the problem still existed, but the company lost hours of time that could have been spent fixing the problem. It was subsequently discovered that a domain controller in error was causing the problems. The point is, make sure that the changes appear to be relevant before devoting full attention to them. Just because there were recent changes does not mean that they are responsible for the problem. This is particularly true with firewalls, where it seems like if a change has been made to a firewall within six months of a problem occurring, someone will immediately question whether the firewall is the problemeven if the problem traffic in question never goes through the firewall. Step 5: Check the Firewall Logs for ErrorsAs you saw in Chapter 12, "What Is My Firewall Telling Me?," a wealth of information is available in most firewalls logs and logging systems. Therefore, always review your firewall logs as a routine troubleshooting step. To assist in using the logs as a troubleshooting tool, you can increase the level of logging detail, perhaps changing to informational or even debugging level or selecting to log specific error messages to help isolate the issue. When examining the logs, pay particular attention to the following types of events:
Step 6: Verify the Firewall ConfigurationThere are two elements to verifying the firewall configuration. The first is to compare the current configuration to a known good configuration. The second is to verify that the firewall configuration is accurate with no typos or other errors. Every time that the firewall configuration is changed (in addition to the first time the firewall is configured), a copy of the new configuration should be saved for archival purposes. This archive represents the last known working configuration. In the event that the firewall is changed, having this archive allows you to compare the current configuration to the archive in an attempt to identify whether any changes have been made to the configuration. If there have been, you can further investigate the changes to determine whether the changes are responsible for the problems that are occurring. Perhaps the most common source of problems with firewalls, however, comes from simple misconfigurations of the firewall. It is too easy to mistype a line, click the wrong element in a graphical user interface (GUI), or just apply the wrong command to the firewall, thus causing a problem on the network that must be troubleshot. This is particularly true when it comes to troubleshooting the firewall ruleset. It is easy to enter the wrong transport protocol (TCP when you meant UDP), IP address, or port number and thus cause the problem. A great example of this occurred when Cisco released the security advisory "Cisco IOS Interface Blocked by IPv4 Packets." As a workaround, it was recommended that, among other things, protocol 53 be blocked. Unfortunately, so many network administrators see "53" and automatically assume DNS (TCP and UDP ports 53), which resulted in folks implementing rulesets to block TCP and UDP port 53 (thus causing DNS traffic to stop being passed) instead of protocol 53, which is related to Cisco IPv4 Packet Processing Denial of Service (SWIPE). Step 7: Verify the Firewall RulesetAs mentioned in the previous section, the firewall ruleset deserves the most scrutiny of anything regarding a firewall during the troubleshooting process. After all, in most cases the firewall exists solely to filter traffic in accordance with the ruleset, which means that if there is a mistake in the ruleset it will almost certainly manifest itself as a problem on the network. The most common ruleset error is a simple typo. For this reason, I like having someone validate the ruleset other than the person making the changes. The reason for this is simple: The person making the changes generally knows what the changes should be and is more apt to read what he or she thinks the ruleset is supposed to contain, not what the ruleset actually contains. Putting a fresh set of eyes on the ruleset increases the odds that someone will notice that someone inadvertently configured the rule for TCP rather than UDP and so on. Another common error with rulesets is the processing order of the ruleset. You need to understand in what order your firewall processes the ruleset and then verify that you do not have a rule out of order which is causing the problem. For example, if the rules are processed top down until a match is made and you have a rule that denies traffic before a rule that permits traffic, the firewall is going to process the deny and then exit the ruleset because it found a match, never making it to the line that permits the traffic in question. Step 8: Verify That Any Dependent, Non-Firewall-Specific Systems Are Not the CulpritSomething else to consider in troubleshooting are the dependent services and systems that are not firewall specific or for which the firewall administrator might not be responsible. This includes the systems that are being protected by the firewall. Common services to examine are name resolution processes such as DNS and WINS. Many times, someone will attempt to access a resource by name through the firewall and when the request fails assume that the firewall is the problem. However, if name resolution is not working properly, the user may not be able to resolve the name of the resource requested to an IP address, which is the cause of the connection failure. Another common source of dependent problems are the systems that provide services to users through the firewall, such as web servers. These servers are frequently managed by a completely separate team that may or may not communicate the status of the servers with the firewall administrators. Therefore, the server administrators may take systems down for maintenance and so on without informing the firewall team. When a user attempts to access the resource, the request naturally failsnot because of the firewall but because the server behind the firewall providing the actual service is not online. External authentication servers such as RADIUS, TACACS+, and Microsoft Windows Domain Controllers can also be a source of problems. For example, if the access to a protected resource behind the firewall requires external authentication and the firewall cannot communicate with the authentication server, it may appear that the firewall is blocking traffic (and in a manner of speaking, it is), but the real problem is not the firewall but a failure of the authentication server. Step 9: Monitor the Network TrafficWhen all else has failed and you are left scratching your head regarding what the problem may be, it is a good time to monitor the actual network traffic and examine precisely how the systems are attempting to communicate to and through the firewall. Doing so can help to identify communications problems that may or may not have shown up in the firewall event logs or may have shown up in the firewall event logs but not have provided enough information to determine a course of action to correct the problem. As mentioned previously in this book, monitoring the network traffic with something like Ethereal, allowing you to view the raw packets and communications between hosts, is much like having a Rosetta stone to help decipher the network languages and communications processes that hosts are using to talk to each other. For example, a common ruleset error that people implement is to open TCP port 20 to their FTP servers because it has been commonly reported that FTP servers use both TCP port 20 and 21 for communications. Although this is true, most FTP clients and servers can communicate solely using TCP port 21, which can be validated by monitoring the traffic between the client and server. Having access to this kind of information will assist you in identifying and troubleshooting problems that do not exhibit symptoms anywhere else, be it in the firewall logs, configuration, or firewall ruleset. |
EAN: 2147483647
Pages: 147
- Challenging the Unpredictable: Changeable Order Management Systems
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Distributed Data Warehouse for Geo-spatial Services
- Data Mining for Business Process Reengineering
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare