17. DOEIntroduction Overview The Lean Sigma roadmaps are primarily based on understanding the key Xs in a process and understanding how they drive the performance of the process through the equation Y = f(X1,X2,..., Xn), where Y is the performance characteristic in question. Early tools (Process Variables Map, Fishbone Diagram) in the roadmap identify all the Xs and then subsequent tools narrow the Xs down, first through the application of Team experience (Cause & Effect Matrix, Failure Mode & Effects Analysis) and then through the analysis of data sampled passively from the process (Multi-Vari Study). At this point, the likely key Xs have been identified and what is required is a tool or series of tools to determine exactly what the equation Y = f(X1,X2,..., Xn) is. This is done in Lean Sigma with Design of Experiments (DOE), where the Xs are actively manipulated and the resulting behavior is modeled using mathematical equations to determine which Xs truly are driving the Y or Ys and how. This active manipulation probably includes stopping the line to conduct the DOE, and it could mean that the process generates scrap or lower grade output for some experiments. Clearly the Process Owner(s) need this explanation, and the whole DOE activity requires considerable organizational support. The biggest mistake Belts make with Designed Experiments is to apply them too early in the projectby far the best approach is to follow the roadmap! By validating the measurement system, identifying all the Xs and then narrowing them down using Team experience and passive data collection analysis (Multi-Vari) significantly reduces wasted effort at the experimental stage. Too often Teams sit and brainstorm Xs to try in the Designed Experiment, rather than letting the roadmap guide them to the best Xstrying to guess important Xs is an almost surefire way to miss an X and expend time and money investigating unimportant Xs! Designed Experiments are not a single tool, but rather a series of tools falling into three main categories: Screening Designs Used to reduce the set of Xs to a manageable number. These designs are purposely constructed to be highly efficient, but in being so, they give up some (or in some cases a great deal of) information content. Characterizing Designs After a manageable number of Xs are identified (either from earlier Lean Sigma tools or from a Screening Design), these Designs are used to create a full detailed model of the data to understand which Xs contribute what and any interactions that might occur between Xs. Characterizing Designs are less efficient than Screening Designs. Optimizing Designs After the Xs are characterized, the Team might want to optimize the process to gain the best performance. These Designs require many data points, but provide detailed insight into the behavior of the process. Optimization is really an optional element in many projects. Often a solid enough result is gained from a Characterizing Design and tuning to a higher degree is not required or not worth the effort that would be expended.
It is highly recommended that before performing a Designed Experiment of any form, the Belt read this section fully, followed by "DOECharacterizing," then "DOEScreening" (Screening Designs are a derivative of Characterizing Designs, so that order makes most sense), and finally "DOEOptimizing" all in this chapter. This gives enough grounding in the bigger picture of DOE use and ensures that the Belt isn't "dangerous." DOE is a broad subject area and fortunately many good texts are available covering the theory and some of the practical considerations.[28] Before a Belt or Team performs the first DOE, it is highly recommended that they receive input from an expert, such as a Consultant or Master Black Belt, just to validate their approach. [28] A reference here is Statistics for Experimenters by Box, Hunter & Hunter.
The key to successful use of DOE in Lean Sigma is to have good planning and to keep the application practically based. As with all tools, some theory does help to understand what the tool does, and more importantly how to apply itremember, the aim here is to understand the practical implications, so the theory here is minimal. In DOE, the objective is to create a good model of data points collected from the process and then make practical conclusions based on the model. Models are generally of the form Y = β0 + (β1X1 + β2X2 + β3X3) + (β12X1X2 + β13X1X3 + β23X2X3) + β123X1X2X3 Where the βs are coefficients in the equation, the Xs are the process Xs, and the Y is the performance characteristic in question. Two Xs appearing together (in fact multiplied together in the equation) represent an interaction in the process between those two Xs. The effect of one X changes the effect of another X. A simple example of this might be time and temperature in an oven. For low temperatures, the time needs to be high, but for high temperature, the time should be low. Interactions between two Xs are extremely common in most industrial processes and common in processes in general. Three Xs appearing together represent an interaction between three Xs. This can be explained as the interaction of two of the Xs changes depending on the value of the other X. Interactions between three Xs are rare, less than one in 500, and if they do occur they tend to be in processes where some chemistry is involved. The preceding equation might look fairly abstract and probably a little alien to some readers. An example might be for three Xs in an Industrial process:[29] [29] DOE is equally at home in healthcare, service, and transactional processes.
Y: Yield X1:Temperature X2: Pressure X3: Volume
The equation would be Yield = β0 + (β1Temp + β2Press + β3Vol) + (β12Temp x Press + β13Temp x Vol + ... At this point the equation can represent any data points captured for the Y and the Xs. A sample of reality is captured from the process and from the data the βs would be calculated. There are eight βs in the equation, so at least eight data points are required to calculate these "unknowns." In theory any eight data points (within reason) would suffice, but there are configurations of data points that give the best information content for the expended effort. These tend to form common geometric shapes, such as squares and cubes, as shown in Figure 7.17.1. For eight data points, a cube would give an efficient means of getting information on the relative change in three Xs. Two settings would be selected for each X, such as high and low, and all combinations of highs and lows for each X become the eight data points. All the data points must be captured (don't stop when a reasonable result is gained) or the analysis cannot be completed. This is the second big mistake in DOE, stopping before all the data is collected. Figure 7.17.1. An example of a data point configuration for three Xs.[30] 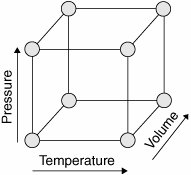
[30] This type of point configuration is typical of a Full Factorial Design and is described in "DOECharacterizing" in this chapter.
If additional data points were captured (above and beyond the eight in the cube) then either: A higher degree of confidence is gained in the values of the calculated βs that represent the size of the effects of each X or interaction between Xs. A higher order mathematical model (quadratic, cubic, and so on) could be used to represent curvature rather than straight lines. This is covered in detail in "DOEOptimization" in this chapter.
Some βs might even be zero or so small they are considered negligible. After the βs are calculated and substituted in the equation, it might look something like: Yield = 67.22 + (8.5 x Temp 3.75 x Press + 0.003 x Vol) + (0.0054 x Temp x Press + ... Now, if the actual values of temperature, pressure, and volume are known, they can be substituted in the equation and the associated actual yield is predicted. The equation itself gives an indication of the most influential Xs and interactions, because they have the largest coefficients (βs), negative or positive. Fortunately, statistical software packages do the hard analysis work and calculate what the βs are and the associated equation. All that the user needs to provide is their selection of design, what the Y and Xs are called, along with the data points collected from the process. The word "all" in the previous sentence could be entirely misleadingthat is all that is required to conduct an analysis, DOE is much more involved as is described in this section. Another mistake in DOE is to assume that it is merely a case of grabbing a few data points and calculating an equationrigor is everything. DOE is thus a systematic (structured design) series of tests (data points) in which various Xs are directly manipulated and the effects on the Ys are observed. This helps determine DOE has its own terminology which can cause some confusion with novice Belts, as follows: Ys are known as Responses Xs that can be controlled are known as Factors Xs that cannot be controlled are known as (Noise) Variables
DOE is not just a single tool, and in fact, it is best not to conduct a single experiment to understand a process. The best approach is to use what is known as sequential experimentation. Simple experiments are conducted first, and after completed, the information they generate is used to plan the next experiment. Table 7.17.1 shows the typical sequence of experimentation. Table 7.17.1. Order of Sequential Experimentation[31]1) Start with a Screening Design. These are efficient Designs and allow the Belt to eliminate some Xs before examining the remainder in detail. The Screening Designs recommended here are known as Fractional Factorials; instead of conducting all of the combinations of high and low, a partial fraction (a half or quarter) is completed. For more detail see "DOEScreening" in this chapter. | 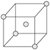 | 2) Move the study to a new location. Often, the initial study indicates that the experiment was focused in entirely the wrong region. The first study guides the direction to move. Sometimes the second study directs a subsequent region change. |  | 3) Add runs to the Screening Design to isolate ambiguous effects. A Screening Design is efficient and does not give major insight into the Xs, it just guides which Xs to keep. To understand more, the partial fraction should be made up to the whole set of combinations. It becomes known as a Full Factorial. For more detail see "DOECharacterizing"in this chapter. |  | 4) Rescale the levels. If the Y does not change significantly across the range of an X, it might be appropriate to stretch the position of the data points (known as Levels) apart. | 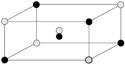 | 5) Drop and add Factors. This really is not recommended in Lean Sigma, because the Xs should come directly from previous tools. If an X should be considered, it should be included in an earlier Screening Design. | 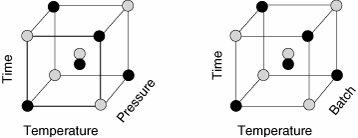 | 6) Replicate runs. If a longer term understanding of the process is required, the approach is to replicate the whole experiment or some of its runs at a later time. |  | 7) Augment designs with additional points. This changes the Design from a Characterizing Design to an Optimizing Design. The additional points allow the investigation of curvature in the solution space to identify peaks and troughs. |  |
[31] Adapted from SBTI's Lean Sigma training material.
Sequential experimentation is the most efficient way to understand a process. Belts often make the mistake of trying to answer all of the questions in the first experiment and construct a large complex (and expensive) design. As can be seen in the second step in Table 7.17.1, the design could be in entirely the wrong region, which would make any points above and beyond the simplest design a waste of resources. The general rule here is only expend 25% of the experimental budget in the first experiment. As mentioned previously, good planning is crucial in DOE. A well-designed experiment eliminates all possible causes except the one being tested. If a change occurs on the Y, then it can be tied directly to the Xs that were directly manipulated. With this in mind, any Noise Variables in the process must be controlled or accounted for so that they don't interfere with understanding the key controllable Factors (Xs). Noise Variables can be managed by Randomizing experimental runs This smears the effect of the Noise Variable across the whole experiment, rather than letting it concentrate on an X that would interfere with understanding. Try to keep the Noise Variables constant Many Noise Variables can be held constant for a short period of time during which the data points are collected (run it on one machine, in a single day or shift and use the same operators throughout). Blocking Make the Noise Variable part of the experiment by letting it be another X in the Design. For example, it is possible to add day, shift, or batch as a Factor to the experiment by replicating the experiment each day or shift.
Other techniques used in DOEs are known as Repetition and Replication, which help provide estimates of the natural variability in the experimental system: Both can be used in the same experiment, but both require additional data points to be run and can quickly push up the size and associated cost of the experiment. In terms of understanding process behavior, both Repetition and Replication push the experiment away from being a snapshot in time to more of a longer term; obviously Replication to a greater degree. The snapshot study forms what is known as Narrow Inference, where the focus is only on one shift, one operator, one machine, one batch, and so on. Narrow inference studies are not as affected by Noise variables. Broad Inference on the other hand usually addresses entire process (all machines, all shifts, all operators, and so on), and thus, more data is taken during a longer period of time. Broad Inference studies are affected by Noise variables and are the means of taking the effect of Noise Variables into account. It is better to perform Narrow Inference studies initially until the controllable Xs are understood and then follow these with Broad Inference studies to understand the robustness of the process. Logistics Planning, designing the experiment, and data collection require participation of the whole Team. The planning and design can usually be achieved in a 12 hour meeting. Data captured depends heavily on the process complexity and time taken to measure the Y. The Belt alone can conduct the analysis, but the results should be fed back as soon as possible to the Team. Roadmap The roadmap to planning, designing, and conducting a sequence of Designed Experiments is as follows: Step 1. | Review initial information from previous studies and Lean Sigma tools. Collect all available information on key Xs and performance data for Ys. A Capability Study for the Ys should be conducted prior to this point.
| | | Step 2. | Identify Ys and Xs to be part of the study. These should not just be brainstormed at this point. The Ys should have come from earlier VOC work, specifically from the Customer Requirements Tree (see "KPOVs and Data" in this chapter). The Xs should come from earlier Lean Sigma tools, which focus on narrowing them. DOE is an expensive and time-consuming way to examine guessed Xs.
| Step 3. | Verify measurement systems for the Ys and Xs. The Ys should have been examined before using a Capability Study. The Xs might have been examined earlier, if not then ensure that data on Xs is reliable (see "MSAValidity," "MSAAttribute," and "MSAContinuous" in this chapter).
| Step 4. | Select the Design type based on the number of Xs. This generally follows the path of sequential experimentation (refer to Table 7.17.1), so in the early stages, perform more efficient screening designs to get an initial idea of the important variables before moving to more complex detailed designs. Don't try to answer all the questions in one study, rely on a series of studies. Two-level designs are efficient designs and are well suited for Screening and Characterizing in Lean Sigma projects.
Current baseline conditions or the best setup should be included in the experiment by the use of Centerpoints, for example, points in the body-center of the cube for a three Factor Design.
For each experiment, it is important to either incorporate or exclude Noise Variables. This can be done with randomization or by blocking the Noise Variable into the experiment (as explained in "Overview" in this section).
The Design of the experiment is heavily affected by its purpose. Determine up front what inferences are required based on the results. A certain amount of redundant data points help provide a better estimate for error in the analysis and give greater confidence in the inferences. To gain redundancy, it is necessary to either repeat each run or replicate the experiment. Repetition allows some short-term variation to creep in; Replication allows longer-term variation. Sample size is a key consideration in determining how many redundant data points are included. A good approach is to include about 25% Repeated or Replicated points. It is usually best to keep redundancy reasonably low until the design appears to at least be in the right region of the solution space.
| | | Step 5. | Create and submit a DOE Proposal to gain signoff to proceed. DOE runs require time and money to conduct, and the decision to run them should be made in the same way any other business spending is considered. The Champion and Process Owners want to understand
The measurable objective How the DOE results tie into Business Metrics The experimentation cost Involvement of internal and external Customers The time needed to conduct the runs What analysis is planned What was learned and subsequently remedied from the pilot runs
The simplest way to communicate this information to the appropriate parties is to create a DOE Proposal that contains the following:
Problem Statement Links to a major business metric or metrics (sometimes known as a strategic driver or business pillar) Experiment objective(s) Ys Measurement System Analysis results for Ys Xs Overview of the Design selected and the data collection plan Budget and deadlines Team Members involved
| Step 6. | Assign clear responsibilities for proper data collection.
| Step 7. | Perform a pilot run to verify and improve data collection procedures.
| Step 8. | Capture data using the improved data collection procedures. Identify and record any extraneous sources of variation or changes in condition.
| | | Step 9. | Analyze the collected data promptly and thoroughly, for more detail see "DOEScreening," "DOECharacterizing," and "DOEOptimizing" in this chapter. Analysis generally follows the following path:
Graphical Descriptive Inferential
Typically, analysis initially involves considering all Factors and Interactions and then eliminating unimportant elements and rerunning the reduced model. This procedure is repeated until an acceptable model is developed.
| Step 10. | Always run one or more verification runs to confirm the results. It is often useful to go from a Narrow to Broad inference study (short-term to longer-term). More noise is apparent in the longer-term study so be ready to accept changes.
| Step 11. | Create a DOE final report, which typically contains
Executive Summary or Abstract Problem Statement and Background Study Objectives Output Variables (Ys) Input Variables (Xs) Study Design Procedures Results and Data Analysis Conclusions Appendices
| Step 12. | Plan the next experiment based on the learning from this experiment. The best time to design an experiment is after the previous one is finished. The roadmap does not have to be completely restarted from Step 1, because the objectives and so on remain the same. Go to Step 4 and repeat Step 4 through Step 12 until the Team thinks the solution is in hand. Sequential experimentation steps might include (as per Table 7.17.1)
Adding runs to isolate any ambiguous (confounded) effects Folding over to complete the next runs of a factorial Constructing the full factorial Moving the factorial toward the optimum Performing a response surface to identify the optimum process window
In general, the approach is to move from simple, efficient designs to more detailed designs involving more redundant points and from first order to second order models.
|
Other Considerations Management plays a key role in any DOE work, but the DOE approach often presents difficulties to traditional management styles. As a Team, it is important to help managers understand Focus should be on the DOE process, which might not deliver the solution after the first experiment. Progress depends on previous experiments and the approach is not linear. Improvements cannot be made until the whole path has been followed. It is difficult to set deadlines for results when the exact path for the sequential experimentation will not be known from the outset. Focus should be on the timely completion of sequential studies and trust that the results will come. Systematic experimentation should be encouraged and expected. Experiments increase knowledge but do not always solve the problem. Experiments stimulate unconventional thinking. Experimentation is a catalyst for engineering, not a replacement.
Given the complexity of the tool, it is no surprise, that there are a number of ways that it can go wrong: Factor levels are put too close together or too far apart. If the high and low values for the Xs are too close together then no effect might be seen for that X and its importance could be incorrectly discounted. If the levels are chosen too far apart, then it is possible that a significant area of interest is not examined between the levels and again the X might be incorrectly discounted. Choosing the levels is discussed more in "DOEScreening," "DOECharacterizing," and "DOEOptimizing" in this chapter. Nonrandom experiments produce spurious results. Randomization spreads the effect of Noise Variables across the whole experiment and prevent them being associated with just one X. The Sample Size is too small. The recommendation is to replicate at least 25% of the data points to gain a good understanding of experimental error and more confidence in the significance of the Xs. Measurement Systems are not adequate. This is typically the biggest mistake Belts make. If a Measurement System has too much noise in it, it can completely overshadow important X effects. All Measurement Systems (specifically on the Ys) need to be validated as capable before any DOE work commences. Measurement systems do not measure what the Team thinks they do. No pilot run is done and experimental runs are flawed because of lack of discipline. Confirmation runs are not done to verify results. Even the best Belt can analyze data incorrectly. Small-scale confirmation runs ensure no full-scale mishaps occur. Data or experimental entities are lost. Be sure to keep track of all data and samples and get any data into electronic form and backed up as soon as possible.
|