2.3 Multiprocessor model
|
| < Day Day Up > |
|
The multiprocessor model is an extension of the uniprocessor model as it has multiple processors and memory subsystems. The most common model under this category is the symmetric multiprocessor (SMP) model. In addition to the SMP model, the multiprocessor model has further extensions such as the massively parallel processing (MPP) model, the non uniform memory access (NUMA) model, and the clustered SMP model.
In the subsequent sections the following multiprocessor architectures will be briefly discussed:
-
Symmetric multiprocessor (SMP)
-
Massively parallel processor (MPP)
-
Non-uniform memory access (NUMA)
SMP and MPP systems can also be classified under the category of uniform memory access systems.
2.3.1 Symmetric multiprocessor (SMP) architecture
This model is an extension of the uniprocessor model and is the first in the series of multiprocessor models. SMP (symmetric multiprocessing) is the processing of programs by multiple processors that share a common operating system and memory (i.e., all of the memory in the system is directly accessible as local memory by all processors).
In symmetric, or ''tightly coupled,'' multiprocessing, the processors share memory and the I/O bus or data path. A single copy of the operating system is in charge of all the processors. SMP systems are also called ''shared everything configuration.'' The advantages of a shared everything/ tightly coupled system will be discussed in detail later in this chapter.
Due to the shared everything architecture, SMP systems are suitable for online transaction processing (OLTP), where many users access the same shared I/O and data paths to the disk systems with a relatively simple set of transactions.
Figure 2.2 illustrates the SMP architecture, where the I/O, memory, bus controllers, and storage systems are shareable. Unlike the uniprocessor machines, these systems can hold multiple CPUs and memory buses, thus providing scalability of the architecture. For this reason they are appropriate for multiprocess systems like Oracle, which has multiple foreground and background processes and is best suited for the SMP architecture.
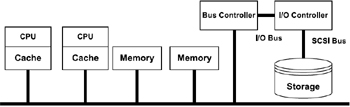
Figure 2.2: Symmetric multiprocessor (SMP) architec ture.
Another notable advantage of the SMP model is that multiple SMP systems could be clustered together to work as a single unit. The advantages and disadvantages of the clustered SMP model will be discussed in detail later in this chapter following explanation of the MPP and NUMA architectures.
2.3.2 Massively parallel processing (MPP) architecture
A massively parallel processor (MPP) is also known as the ''shared nothing configuration.'' In an MPP configuration, each processor has private, non- shared memory, and possibly its own disk or storage subsystem. MPP architecture allows accessibility from all nodes in the system to local disks. An MPP node has its own operating system, CPUs, disk, and memory. Data is communicated through a message-passing network. MPP systems are considered better than SMP systems for applications that require scaling to a very large database. These include decision support and warehousing applications.
2.3.3 Non-uniform memory access (NUMA)
Non-uniform Memory Access (NUMA) is described as a cross between an SMP and an MPP system. Systems with NUMA architecture have a single operating system and database instance, and provide a single memory address space similar to SMP. CPUs of the local processor node or group are connected to local memory and local disks via a local shared bus and to other processor groups via a high-speed interconnect.
NUMA indicates that it will take longer to access some regions of memory than others. This is due to the fact that some regions of memory are physically on different buses. This may result in poor performance of some programs that are not NUMA-aware. It also introduces the concept of local and remote memory. The memory globally available to the entire cluster is typically the union of all the physical memory banks attached to each physical node (i.e., if node 1 has 2 GB, node 2 has 2 GB, and node 3 has 3 GB, then the collective memory available for the entire cluster is 7 GB of global memory).
With NUMA architecture, the access to a memory location is not uniform in that the memory may be local or remote with respect to the location of which CPU is running the code. The memory is local when the code references physical memory attached to the same node bus where the CPU is attached. The memory is remote when the physical memory referenced is attached to another node.
Shared memory sections map the virtual address spaces of different processes to the same physical address space. In NUMA, the physical address space is spanned among the physical nodes defining the cluster. This allows the shared memory segment to be striped among the available physical nodes.
The NUMA architecture was designed to surpass the scalability limits of the SMP architecture. With SMP, all memory access is posted to the same shared memory bus. This performs well for a relatively small number of CPUs; however, problems arise with the shared bus when there are dozens of CPUs competing for access to the shared memory bus. NUMA alleviates these bottlenecks by limiting the number of CPUs on any one-memory bus, thus connecting the various nodes by means of a high-speed interconnect.
The main benefit of NUMA, as mentioned above, is scalability. It is extremely difficult to scale SMP systems past 8–12 CPUs. Utilizing that many number of CPUs places the single shared memory bus under heavy contention. Using a NUMA-based solution is one way of reducing the number of CPUs competing for access to a shared memory bus. Figure 2.3 represents the NUMA architecture displaying multiple nodes, with each node having its own set of CPUs and other resources, including the storage systems.
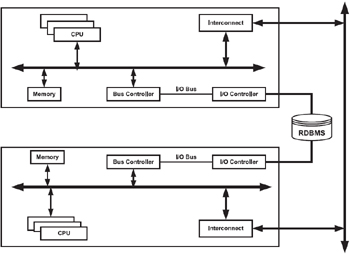
Figure 2.3: Non-uniform memory access (NUMA) archi tecture.
The implementation of Oracle on NUMA architecture may not provide the expected results for many reasons. Firstly, Oracle is a large consumer of shared memory segments. Oracle's architecture comprises multiple background and foreground processors that map to the shared memory segments, or SGA, to access structures like buffer cache, library cache, etc. With the striped concept of memory management in NUMA architecture, the SGA will be striped equally among the physical nodes. This will result in the background and foreground processes running on different CPUs.
Figure 2.4 represents implementation of Oracle on a three-node cluster using the NUMA architecture and illustrates the memory management across multiple nodes. In the figure, Oracle background and foreground processors are running on different CPUs. Also illustrated is the shared memory, which is striped across all the three nodes in the cluster. I/O peripherals such as disks are physically attached to I/O modules accessed by nodes.
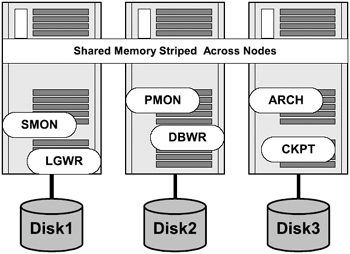
Figure 2.4: Oracle on three- node cluster using NUMA.
While NUMA architecture provides great benefit for processor sharing and efficiency in a clustered configuration, industry maturity on this model is low.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174