Section 2.7. The System Task in MINIX 3
2.7. The System Task in MINIX 3A consequence of making major system components independent processes outside the kernel is that they are forbidden from doing actual I/O, manipulating kernel tables and doing other things operating system functions normally do. For example, the fork system call is handled by the process manager. When a new process is created, the kernel must know about it, in order to schedule it. How can the process manager tell the kernel? The solution to this problem is to have a kernel offer a set of services to the drivers and servers. These services, which are not available to ordinary user processes, allow the drivers and servers to do actual I/O, access kernel tables, and do other things they need to, all without being inside the kernel. These special services are handled by the system task, which is shown in layer 1 in Fig. 2-29. Although it is compiled into the kernel binary program, it is really a separate process and is scheduled as such. The job of the system task is to accept all the requests for special kernel services from the drivers and servers and carry them out. Since the system task is part of the kernel's address space, it makes sense to study it here. Earlier in this chapter we saw an example of a service provided by the system task. In the discussion of interrupt handling we described how a user-space device driver uses sys_irqctl to send a message to the system task to ask for installation of an interrupt handler. A user-space driver cannot access the kernel data structure where addresses of interrupt service routines are placed, but the system task is able to do this. Furthermore, since the interrupt service routine must also be in the kernel's address space, the address stored is the address of a function provided by the system task, generic_handler. This function responds to an interrupt by sending a notification message to the device driver. This is a good place to clarify some terminology. In a conventional operating system with a monolithic kernel, the term system call is used to refer to all calls for services provided by the kernel. In a modern UNIX-like operating system the POSIX standard describes the system calls available to processes. There may be some nonstandard extensions to POSIX, of course, and a programmer taking advantage of a system call will generally reference a function defined in the C libraries, which may provide an easy-to-use programming interface. Also, sometimes separate library functions that appear to the programmer to be distinct "system calls" actually use the same access to the kernel. In MINIX 3 the landscape is different; components of the operating system run in user space, although they have special privileges as system processes. We will still use the name "system call" for any of the POSIX-defined system calls (and a few MINIX extensions) listed in Fig. 1-9, but user processes do not request services directly of the kernel. In MINIX 3 system calls by user processes are transformed into messages to server processes. Server processes communicate with each other, with device drivers, and with the kernel by messages. The subject of this section, the system task, receives all requests for kernel services. Loosely speaking, we could call these requests system calls, but to be more exact we will refer to them as kernel calls. Kernel calls cannot be made by user processes. In many cases a system call that originates with a user process results in a kernel call with a similar name being made by a server. This is always because some part of the service being requested can only be dealt with by the kernel. For instance a fork system call by a user process goes to the process manager, which does some of the work. But a fork requires changes in the kernel part of the process table, and to complete the action the process manager makes a sys_fork call to the system task, which can manipulate data in kernel space. Not all kernel calls have such a clear connection to a single system call. For instance, there is a sys_devio kernel call to read or write I/O ports. This kernel call comes from a device driver. More than half of all the system calls listed in Fig. 1-9 could result in a device driver being activated and making one or more sys_devio calls. Technically speaking, a third category of calls (besides system calls and kernel-calls) should be distinguished. The message primitives used for interprocess communication such as send, receive, and notify can be thought of as system-call-like. We have probably called them that in various places in this bookafter all, they do call the system. But they should properly be called something different from both system calls and kernel calls. Other terms may be used. IPC primitive is sometimes used, as well as trap, and both of these may be found in some comments in the source code. You can think of a message primitive as being like the carrier wave in a radio communications system. Modulation is usually needed to make a radio wave useful; the message type and other components of a message structure allow the message call to convey information. In a few cases an unmodulated radio wave is useful; for instance, a radio beacon to guide airplanes to an airport. This is analogous to the notify message primitive, which conveys little information other than its origin. 2.7.1. Overview of the System TaskThe system task accepts 28 kinds of messages, shown in Fig. 2-45. Each of these can be considered a kernel call, although, as we shall see, in some cases there are multiple macros defined with different names that all result in just one of the message types shown in the figure. And in some other cases more than one of the message types in the figure are handled by a single procedure that does the work.
The main program of the system task is structured like other tasks. After doing necessary initialization it runs in a loop. It gets a message, dispatches to the appropriate service procedure, and then sends a reply. A few general support functions are found in the main file, system.c, but the main loop dispatches to a procedure in a separate file in the kernel/system/ directory to process each kernel call. We will see how this works and the reason for this organization when we discuss the implementation of the system task. First we will briefly describe the function of each kernel call. The message types in Fig. 2-45 fall into several categories. The first few are involved with process management. Sys_fork, sys_exec, sys_exit, and sys_trace are obviously closely related to standard POSIX system calls. Although nice is not a POSIX-required system call, the command ultimately results in a sys_nice kernel call to change the priority of a process. The only one of this group that is likely to be unfamiliar is sys_privctl. It is used by the reincarnation server (RS), the MINIX 3 component responsible for converting processes started as ordinary user processes into system processes. Sys_privctl changes the privileges of a process, for instance, to allow it to make kernel calls. Sys_privctl is used when drivers and servers that are not part of the boot image are started by the /etc/rc script. MINIX 3 drivers also can be started (or restarted) at any time; privilege changes are needed whenever this is done. The next group of kernel calls are related to signals. Sys_kill is related to the user-accessible (and misnamed) system call kill. The others in this group, sys_getksig, sys_endksig, sys_sigsend, and sys_sigreturn are all used by the process manager to get the kernel's help in handling signals. The sys_irqctl, sys_devio, sys_sdevio, and sys_vdevio kernel calls are unique to MINIX 3. These provide the support needed for user-space device drivers. We mentioned sys_irqctl at the start of this section. One of its functions is to set a hardware interrupt handler and enable interrupts on behalf of a user-space driver. Sys_devio allows a user-space driver to ask the system task to read or write from an I/O port. This is obviously essential; it also should be obvious that it involves more overhead than would be the case if the driver were running in kernel space. The next two kernel calls offer a higher level of I/O device support. Sys_sdevio can be used when a sequence of bytes or words, i.e., a string, is to be read from or written to a single I/O address, as might be the case when accessing a serial port. Sys_vdevio is used to send a vector of I/O requests to the system task. By a vector is meant a series of (port, value) pairs. Earlier in this chapter, we described the intr_init function that initializes the Intel i8259 interrupt controllers. On lines 8140 to 8152 a series of instructions writes a series of byte values. For each of the two i8259 chips, there is a control port that sets the mode and another port that receives a sequence of four bytes in the initialization sequence. Of course, this code executes in the kernel, so no support from the system task is needed. But if this were being done by a user-space process a single message passing the address to a buffer containing 10 (port, value) pairs would be much more efficient than 10 messages each passing one port address and a value to be written. The next three kernel calls shown in Fig. 2-45 involve memory in distinct ways. The first, sys_newmap, is called by the process manager when the memory used by a process changes, so the kernel's part of the process table can be updated. Sys_segctl and sys_memset provide a safe way to provide a process with access to memory outside its own data space. The memory area from 0xa0000 to 0xfffff is reserved for I/O devices, as we mentioned in the discussion of startup of the MINIX 3 system. Some devices use part of this memory region for I/Ofor instance, video display cards expect to have data to be displayed written into memory on the card which is mapped here. Sys_segctl is used by a device driver to obtain a segment selector that will allow it to address memory in this range. The other call, sys_memset, is used when a server wants to write data into an area of memory that does not belong to it. It is used by the process manager to zero out memory when a new process is started, to prevent the new process from reading data left by another process. The next group of kernel calls is for copying memory. Sys_umap converts virtual addresses to physical addresses. Sys_vircopy and sys_physcopy copy regions of memory, using either virtual or physical addresses. The next two calls, sys_virvcopy and sys_physvcopy are vector versions of the previous two. As with vectored I/O requests, these allow making a request to the system task for a series of memory copy operations. Sys_times obviously has to do with time, and corresponds to the POSIX times system call. Sys_setalarm is related to the POSIX alarm system call, but the relation is a distant one. The POSIX call is mostly handled by the process manager, which maintains a queue of timers on behalf of user processes. The process manager uses a sys_setalarm kernel call when it needs to have a timer set on its behalf in the kernel. This is done only when there is a change at the head of the queue managed by the PM, and does not necessarily follow every alarm call from a user process. The final two kernel calls listed in Fig. 2-45 are for system control. Sys_abort can originate in the process manager, after a normal request to shutdown the system or after a panic. It can also originate from the tty device driver, in response to a user pressing the Ctrl-Alt-Del key combination. Finally, sys_getinfo is a catch-all that handles a diverse range of requests for information from the kernel. If you search through the MINIX 3 C source files you will, in fact, find very few references to this call by its own name. But if you extend your search to the header directories you will find no less than 13 macros in include/minix/syslib.h that give another name to Sys_getinfo. An example is sys_getkinfo(dst) sys_getinfo(GET_KINFO, dst, 0, 0, 0) which is used to return the kinfo structure (defined in include/minix/type.h on lines 2875 to 2893) to the process manager for use during system startup. The same information may be needed at other times. For instance, the user command ps needs to know the location of the kernel's part of the process table to display information about the status of all processes. It asks the PM, which in turn uses the sys_getkinfo variant of sys_getinfo to get the information. Before we leave this overview of kernel call types, we should mention that sys_getinfo is not the only kernel call that is invoked by a number of different names defined as macros in include/minix/syslib.h. For example, the sys_sdevio call is usually invoked by one of the macros sys_insb, sys_insw, sys_outsb, or sys_outsw. The names were devised to make it easy to see whether the operation is input or output, with data types byte or word. Similarly, the sys_irqctl call is usually invoked by a macro like sys_irqenable, sys_irqdisable, or one of several others. Such macros make the meaning clearer to a person reading the code. They also help the programmer by automatically generating constant arguments. 2.7.2. Implementation of the System TaskThe system task is compiled from a header, system.h, and a C source file, system.c, in the main kernel/ directory. In addition there is a specialized library built from source files in a subdirectory, kernel/system/. There is a reason for this organization. Although MINIX 3 as we describe it here is a general-purpose operating system, it is also potentially useful for special purposes, such as embedded support in a portable device. In such cases a stripped-down version of the operating system might be adequate. For instance, a device without a disk might not need a file system. We saw in kernel/config.h that compilation of kernel calls can be selectively enabled and disabled. Having the code that supports each kernel call linked from the library as the last stage of compilation makes it easier to build a customized system. Putting support for each kernel call in a separate file simplifies maintenance of the software. But there is some redundancy between these files, and listing all of them would add 40 pages to the length of this book. Thus we will list in Appendix B and describe in the text only a few of the files in the kernel/system/ directory. However, all the files are on the CD-ROM and the MINIX 3 Web site. We will begin by looking at the header file, kernel/system.h (line 9600). It provides prototypes for functions corresponding to most of the kernel calls listed in Fig. 2-45. In addition there is a prototype for do_unused, the function that is invoked if an unsupported kernel call is made. Some of the message types in Fig. 2-45 correspond to macros defined here. These are on lines 9625 to 9630. These are cases where one function can handle more than one call. Before looking at the code in system.c, note the declaration of the call vector call_vec, and the definition of the macro map on lines 9745 to 9749. Call_vec is an array of pointers to functions, which provides a mechanism for dispatching to the function needed to service a particular message by using the message type, expressed as a number, as an index into the array. This is a technique we will see used elsewhere in MINIX 3. The map macro is a convenient way to initialize such an array. The macro is defined in such a way that trying to expand it with an invalid argument will result in declaring an array with a negative size, which is, of course, impossible, and will cause a compiler error. The top level of the system task is the procedure sys_task. After a call to initialize an array of pointers to functions, sys_task runs in a loop. It waits for a message, makes a few tests to validate the message, dispatches to the function that handles the call that corresponds to the message type, possibly generating a reply message, and repeats the cycle as long as MINIX 3 is running (lines 9768 to 9796). The tests consists of a check of the priv table entry for the caller to determine that it is allowed to make this type of call and making sure that this type of call is valid. The dispatch to the function that does the work is done on line 9783. The index into the call_vec array is the call number, the function called is the one whose address is in that cell of the array, the argument to the function is a pointer to the message, and the return value is a status code. A function may return a EDONTREPLY status, meaning no reply message is required, otherwise a reply message is sent at line 9792. As you may have noticed in Fig. 2-43, when MINIX 3 starts up the system task is at the head of the highest priority queue, so it makes sense that the system task's initialize function initializes the array of interrupt hooks and the list of alarm timers (lines 9808 to 9815). In any case, as we noted earlier, the system task is used to enable interrupts on behalf of user-space drivers that need to respond to interrupts, so it makes sense to have it prepare the table. The system task is used to set up timers when synchronous alarms are requested by other system processes, so initializing the timer lists is also appropriate here. Continuing with initialization, on lines 9822 to 9824 all slots in the call_vec array are filled with the address of the procedure do_unused, called if an unsupported kernel call is made. Then the rest of the file lines 9827 to 9867, consists of multiple expansions of the map macro, each one of which installs the address of a function into the proper slot in call_vec. The rest of system.c consists of functions that are declared PUBLIC and that may be used by more than one of the routines that service kernel calls, or by other parts of the kernel. For instance, the first such function, get_priv (line 9872), is used by do_privctl, which supports the sys_privctl kernel call. It is also called by the kernel itself while constructing process table entries for processes in the boot image. The name is a perhaps a bit misleading. Get_priv does not retrieve information about privileges already assigned, it finds an available priv structure and assigns it to the caller. There are two casessystem processes each get their own entry in the priv table. If one is not available then the process cannot become a system process. User processes all share the same entry in the table. Get_randomness (line 9899) is used to get seed numbers for the random number generator, which is a implemented as a character device in MINIX 3. The newest Pentium-class processors include an internal cycle counter and provide an assembly language instruction that can read it. This is used if available, otherwise a function is called which reads a register in the clock chip. Send_sig generates a notification to a system process after setting a bit in the s_sig_pending bitmap of the process to be signaled. The bit is set on line 9942. Note that because the s_sig_pending bitmap is part of a priv structure, this mechanism can only be used to notify system processes. All user processes share a common priv table entry, and therefore fields like the s_sig_pending bitmap cannot be shared and are not used by user processes. Verification that the target is a system process is made before send_sig is called. The call comes either as a result of a sys_kill kernel call, or from the kernel when kprintf is sending a string of characters. In the former case the caller determines whether or not the target is a system process. In the latter case the kernel only prints to the configured output process, which is either the console driver or the log driver, both of which are system processes. The next function, cause_sig (line 9949), is called to send a signal to a user process. It is used when a sys_kill kernel call targets a user process. It is here in system.c because it also may be called directly by the kernel in response to an exception triggered by the user process. As with send_sig a bit must be set in the recipient's bitmap for pending signals, but for user processes this is not in the priv table, it is in the process table. The target process must also be made not ready by a call to lock_dequeue, and its flags (also in the process table) updated to indicate it is going to be signaled. Then a message is sentbut not to the target process. The message is sent to the process manager, which takes care of all of the aspects of signaling a process that can be dealt with by a user-space system process. Next come three functions which all support the sys_umap kernel call. Processes normally deal with virtual addresses, relative to the base of a particular segment. But sometimes they need to know the absolute (physical) address of a region of memory, for instance, if a request is going to be made for copying between memory regions belonging to two different segments. There are three ways a virtual memory address might be specified. The normal one for a process is relative to one of the memory segments, text, data, or stack, assigned to a process and recorded in its process table slot. Requesting conversion of virtual to physical memory in this case is done by a call to umap_local (line 9983). The second kind of memory reference is to a region of memory that is outside the text, data, or stack areas allocated to a process, but for which the process has some responsibility. Examples of this are a video driver or an Ethernet driver, where the video or Ethernet card might have a region of memory mapped in the region from 0xa0000 to 0xfffff which is reserved for I/O devices. Another example is the memory driver, which manages the ramdisk and also can provide access to any part of the memory through the devices /dev/mem and /dev/kmem. Requests for conversion of such memory references from virtual to physical are handled by umap_remote (line 10025). Finally, a memory reference may be to memory that is used by the BIOS. This is considered to include both the lowest 2 KB of memory, below where MINIX 3 is loaded, and the region from 0x90000 to 0xfffff, which includes some RAM above where MINIX 3 is loaded plus the region reserved for I/O devices. This could also be handled by umap_remote, but using the third function, umap_bios (line 10047), ensures that a check will be made that the memory being referenced is really in this region. The last function defined in system.c is virtual_copy (line 10071). Most of this function is a C switch which uses one of the three umap_* functions just described to convert virtual addresses to physical addresses. This is done for both the source and destination addresses. The actual copying is done (on line 10121) by a call to the assembly language routine phys_copy in klib386.s. 2.7.3. Implementation of the System LibraryEach of the functions with a name of the form do_xyz has its source code in a file in a subdirectory, kernel/system/do_xyz.c. In the kernel/ directory the Makefile contains a line cd system && $(MAKE) $(MAKEFLAGS) $@ which causes all of the files in kernel/system/ to be compiled into a library, system.a in the main kernel/ directory. When control returns to the main kernel directory another line in the Makefile cause this local library to be searched first when the kernel object files are linked. We have listed two files from the kernel/system/ directory in Appendix B. These were chosen because they represent two general classes of support that the system task provides. One category of support is access to kernel data structures on behalf of any user-space system process that needs such support. We will describe system/do_setalarm.c as an example of this category. The other general category is support for specific system calls that are mostly managed by user-space processes, but which need to carry out some actions in kernel space. We have chosen system/do_exec.c as our example. The sys_setalarm kernel call is somewhat similar to sys_irqenable, which we mentioned in the discussion of interrupt handling in the kernel. Sys_irqenable sets up an address to an interrupt handler to be called when an IRQ is activated. The handler is a function within the system task, generic_handler. It generates a notify message to the device driver process that should respond to the interrupt. System/do_setalarm.c (line 10200) contains code to manage timers in a way similar to how interrupts are managed. A sys_setalarm kernel call initializes a timer for a user-space system process that needs to receive a synchronous alarm, and it provides a function to be called to notify the user-space process when the timer expires. It can also ask for cancellation of a previously scheduled alarm by passing zero in the expiration time field of its request message. The operation is simpleon lines 10230 to 10232 information from the message is extracted. The most important items are the time when the timer should go off and the process that needs to know about it. Every system process has its own timer structure in the priv table. On lines 10237 to 10239 the timer structure is located and the process number and the address of a function, cause_alarm, to be executed when the timer expires, are entered. If the timer was already active, sys_setalarm returns the time remaining in its reply message. A return value of zero means the timer is not active. There are several possibilities to be considered. The timer might previously have been deactivateda timer is marked inactive by storing a special value, TMR_NEVER in its exp_time field . As far as the C code is concerned this is just a large integer, so an explicit test for this value is made as part of checking whether the expiration time has passed. The timer might indicate a time that has already passed. This is unlikley to happen, but it is easy to check. The timer might also indicate a time in the future. In either of the first two cases the reply value is zero, otherwise the time remaining is returned (lines 10242 to 10247). Finally, the timer is reset or set. At this level this is done putting the desired expiration time into the correct field of the timer structure and calling another function to do the work. Of course, resetting the timer does not require storing a value. We will see the functions reset and set soon, their code is in the source file for the clock task. But since the system task and the clock task are both compiled into the kernel image all functions declared PUBLIC are accessible. There is one other function defined in do_setalarm.c. This is cause_alarm, the watchdog function whose address is stored in each timer, so it can be called when the timer expires. It is simplicity itselfit generates a notify message to the process whose process number is also stored in the timer structure. Thus the synchronous alarm within the kernel is converted into a message to the system process that asked for an alarm. As an aside, note that when we talked about the initialization of timers a few pages back (and in this section as well) we referred to synchronous alarms requested by system processes. If that did not make complete sense at this point, and if you are wondering what is a synchronous alarm or what about timers for nonsystem processes, these questions will be dealt with in the next section, when we discuss the clock task. There are so many interconnected parts in an operating system that it is almost impossible to order all topics in a way that does not occasionally require a reference to a part that has not been already been explained. This is particularly true when discussing implementation. If we were not dealing with a real operating system we could probably avoid bringing up messy details like this. For that matter, a totally theoretical discussion of operating system principles would probably never mention a system task. In a theory book we could just wave our arms and ignore the problems of giving operating system components in user space limited and controlled access to privileged resources like interrupts and I/O ports. The last file in the kernel/system/ directory which we will discuss in detail is do_exec.c (line 10300). Most of the work of the exec system call is done within the process manager. The process manager sets up a stack for a new program that contains the arguments and the environment. Then it passes the resulting stack pointer to the kernel using sys_exec, which is handled by do_exec (line 10618). The stack pointer is set in the kernel part of the process table, and if the process being exec-ed is using an extra segment the assembly language phys_memset function defined in klib386.s is called to erase any data that might be left over from previous use of that memory region (line 10330). An exec call causes a slight anomaly. The process invoking the call sends a message to the process manager and blocks. With other system calls, the resulting reply would unblock it. With exec there is no reply, because the newly loaded core image is not expecting a reply. Therefore, do_exec unblocks the process itself on line 10333 The next line makes the new image ready to run, using the lock_enqueue function that protects against a possible race condition. Finally, the command string is saved so the process can be identified when the user invokes the ps command or presses a function key to display data from the process table. To finish our discussion of the system task, we will look at its role in handling a typical operating service, providing data in response to a read system call. When a user does a read call, the file system checks its cache to see if it has the block needed. If not, it sends a message to the appropriate disk driver to load it into the cache. Then the file system sends a message to the system task telling it to copy the block to the user process. In the worst case, eleven messages are needed to read a block; in the best case, four messages are needed. Both cases are shown in Fig. 2-46. In Fig. 2-46 (a), message 3 asks the system task to execute I/O instructions; 4 is the ACK. When a hardware interrupt occurs the system task tells the waiting driver about this event with message 5. Messages 6 and 7 are a request to copy the data to the FS cache and the reply, message 8 tells the FS the data is ready, and messages 9 and 10 are a request to copy the data from the cache to the user, and the reply. Finally message 11 is the reply to the user. In Fig. 2-46 (b), the data is already in the cache, messages 2 and 3 are the request to copy it to the user and the reply. These messages are a source of overhead in MINIX 3 and are the price paid for the highly modular design. Figure 2-46. (a) Worst case for reading a block requires eleven messages. (b) Best case for reading a block requires four messages.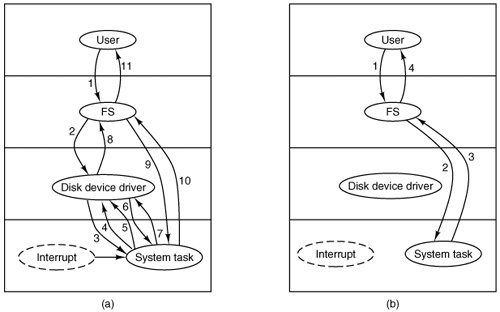 Kernel calls to request copying of data are probably the most heavily used ones in MINIX 3. We have already seen the part of the system task that ultimately does the work, the function virtual_copy. One way to deal with some of the inefficiency of the message passing mechanism is to pack multiple requests into a message. The sys_virvcopy and sys_physvcopy kernel calls do this. The content of a message that invokes one of these call is a pointer to a vector specifying multiple blocks to be copied between memory locations. Both are supported by do_vcopy, which executes a loop, extracting source and destination addresses and block lengths and calling phys_copy repeatedly until all the copies are complete. We will see in the next chapter that disk devices have a similar ability to handle multiple transfers based on a single request. |
EAN: 2147483647
Pages: 102